
一、Hive基础
详见语雀笔记:hive基础
二、Hive表操作
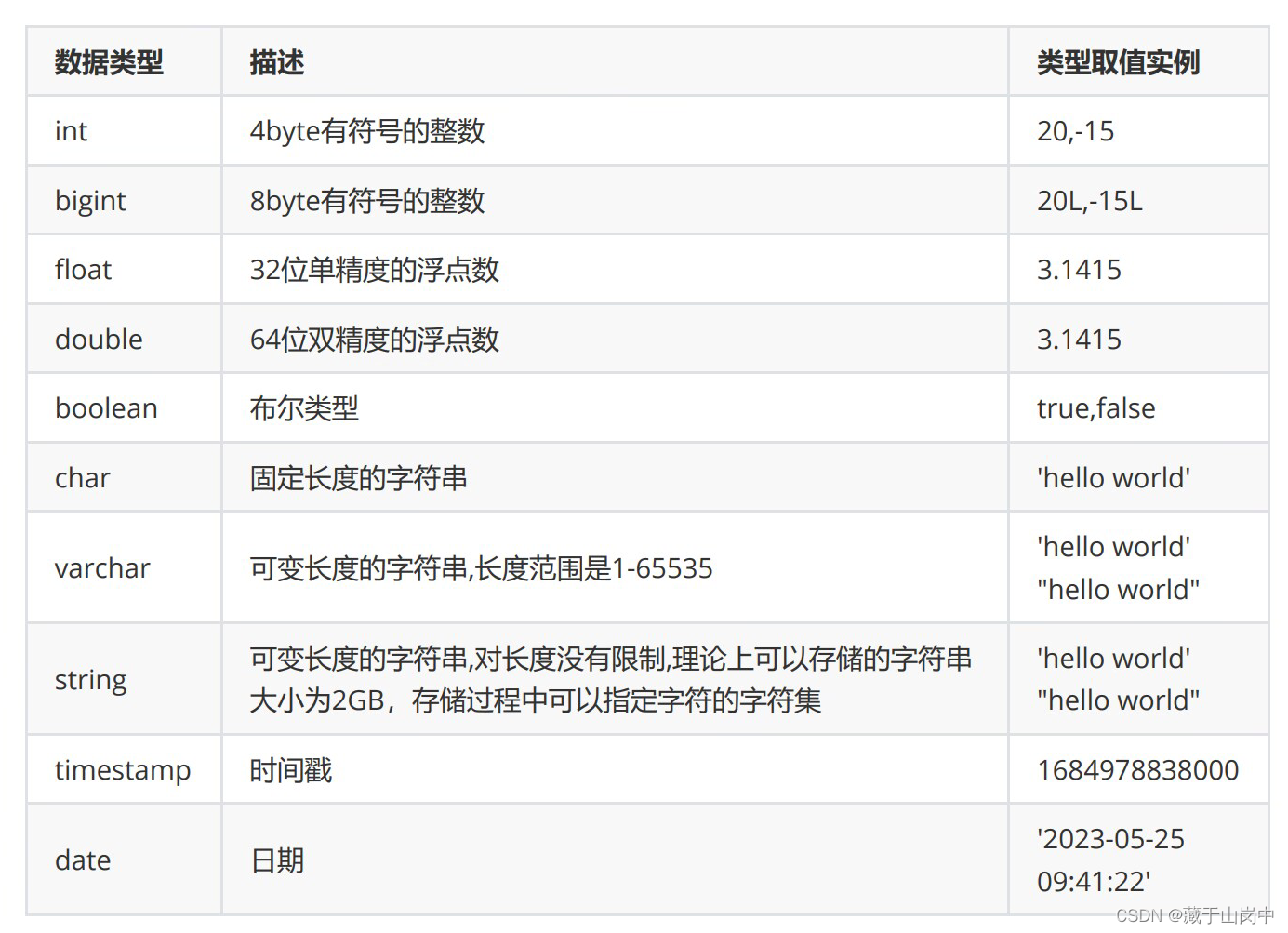
2.1 Hive中的数据类型(常见)
2.2 Hive完整的建表语句
CREATE[EXTERNAL]TABLE[IFNOTEXISTS] table_name
[(col_name data_type [COMMENT COL_COMMENT],.....)][COMMENT table_comment][PARTITIONED BY(col_name data_type [COMMENT col_comment],....)][CLUSTEREDBY(col_name,col_name,....)][SORTED BY(col_name [ASC|DESC],...)] INFO num_buckets BUCKETS][ROW FORMAT DELIMITED FIELDSTERMINATEDBY','][STORED AS file_format][LOCATION hdfs_path]
字段解释:
1.CREATETABLE创建一个**指定名字的表**。
2. 如果名字相同抛出异常,用户可以使用IFNOTEXISTS来忽略异常。
3.EXTERNAL关键字可以创建一个**外部表**,在建表的同时指定一个实际数据的路径(LOCATION),hive在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据
4.COMMENT是为表和列**添加注释**5.PARTITIONEDBY是**分区表**6.CLUSTEREDBY是**建分桶**(不常用)7.SORTEDBY是**指定字段进行排序**(不常用)8.ROWFORMATDELIMITEDFIELDSTERMINATEDBY','是指每行数据中列分隔符为"," 默认分隔符为" \001"89.STOREDAS指定存储文件类型,数据文件是纯文本,可以使用STOREDASTEXTFILE10.LOCATION指定表在HDFS上的存储位置,内部表不要指定。但是如果定义的是外部表,则需要直接指定一个路径。
2.3 Hive内部表
hive内部表被称为hive管理表,它是由hive进行元数据和数据管理的
内部表的特点:
- 在hive中删除内部表时,存储在HDFS上的数据和存储在MySQL中的表的元数据会被一同删除。
- 对内部标的任何更改都会对存储 在HDFS上的数据和存储在MySQL中的表的元数据产生影响。
2.3.1 创建语法最简洁的内部表
首先要先开启hdfs集群,开启hive,这里可以调用之前写的脚本来进行启动。
方法一:先切换数据库,再创建表。
--创建数据库createdatabaseifnotexists test;--在数据库test中创建emp1表,有两种方式--方法一:先切换数据库,再创建表。--写入在create_emp1.sql文件中use test;createtableifnotexists emp1(
emp_id int,
emp_name string,
department_id int)
STORED AS textfile
;--在beeline命令行中执行create_emp1.sql文件
source /opt/sql/create_emp1.sql;
方法二:直接在建表语句中指定对应的数据库(推荐)
--方法二:直接在建表语句中指定对应的数据库--写入在create_emp1.sql文件中createtableifnotexists test.emp1(
emp_id int,
emp_name string,
department_id int)
STORED AS textfile
;--在beeline命令行中执行create_emp1.sql文件
source /opt/sql/create_emp1.sql;
检查建表是否成功:
--检查一下test数据库下是否成功创建emp1表select current_database();showtables;
执行结果截图: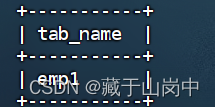
查询表的建表信息:
--查询表的建表信息--show create table 数据库名.表名;showcreatetable test.emp1;
执行结果截图: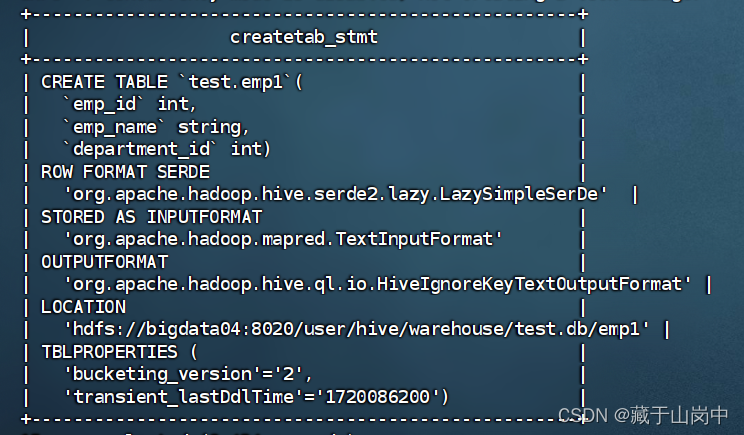
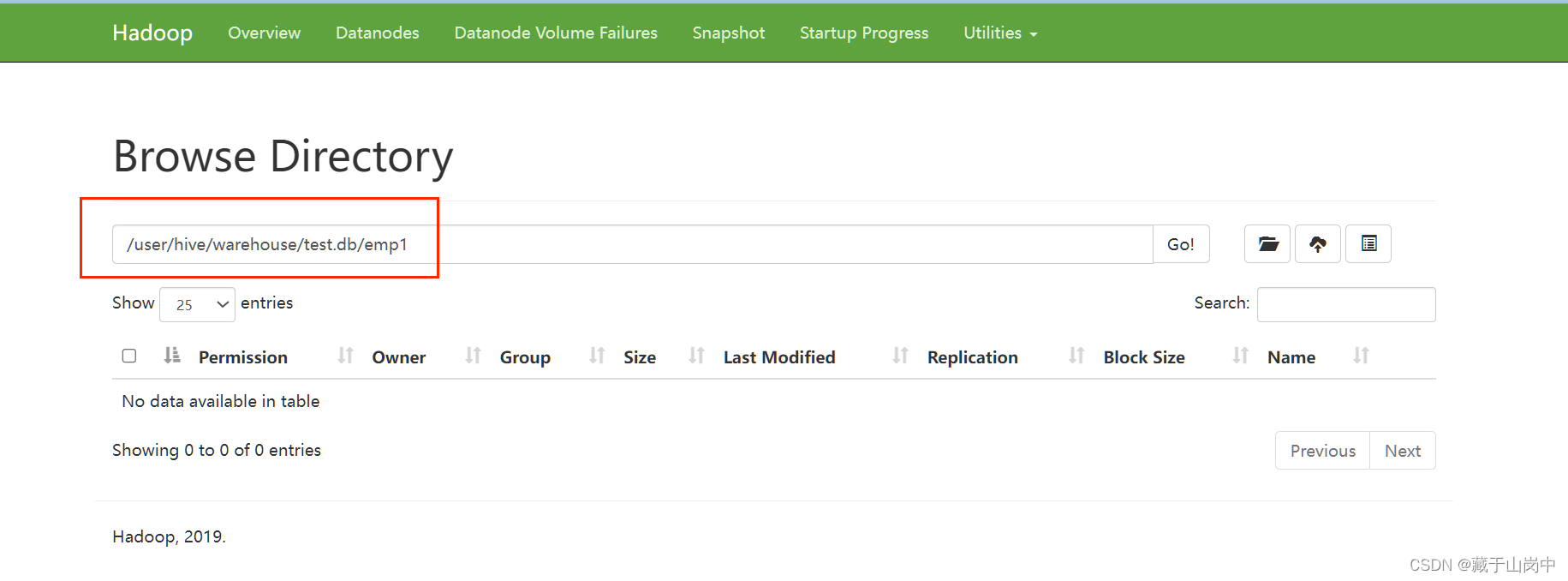
打开对应的Namenode information可以查看上面location对应的位置存储着数据库和表。
这是我的链接(http://bigdata04:9870/explorer.html#/user/hive/warehouse/test.db/emp1)。
之后存储在emp1表中的数据也会以文件的形式存储在该路径之下。
查看表的类型信息:
--查看表的类型信息--desc formatted 数据库名.表名;desc formatted test.emp1;
2.3.2 创建带注释的内部表
--创建带注释的内部表emp2--写入在create_emp2.sql文件中createtableifnotexists test.emp2(
emp_id intcomment"员工id",
emp_name string comment"员工姓名",
department_id intcomment"部门id")
STORED AS textfile
;--在beeline命令行中执行create_emp2.sql文件
source /opt/sql/create_emp2.sql;
查询表的建表信息:
--查询表的建表信息showcreatetable test.emp2;
执行结果截图:
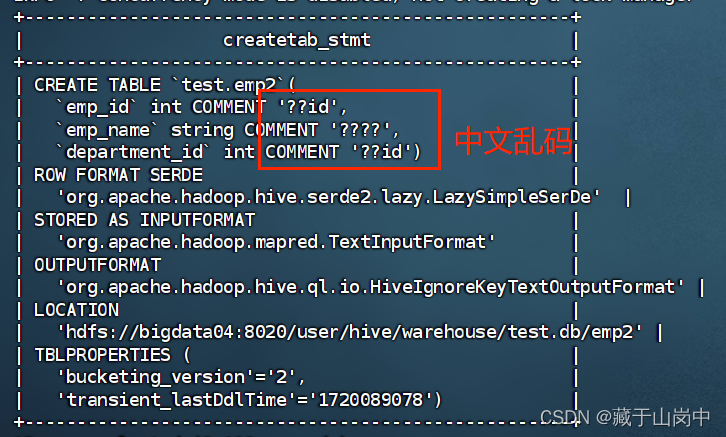
解决hive中字段注释和标注中文乱码问题
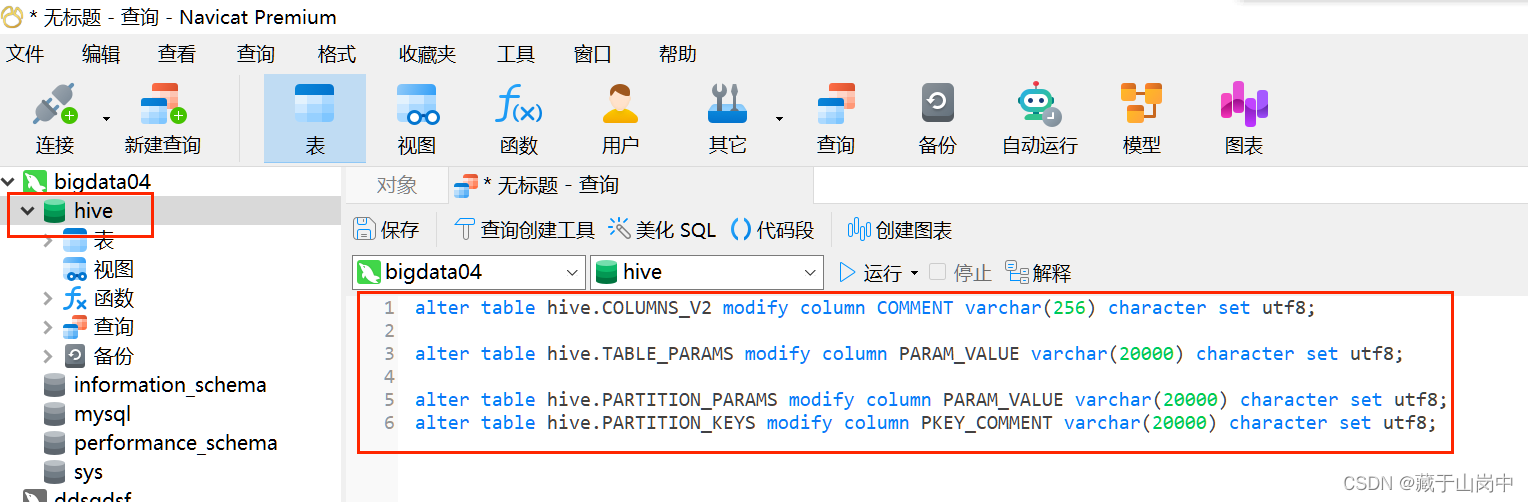
step1:登录mysql 执行如下命令 然后重启mysql
#修改字段注释字符集
alter table hive.COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;#修改表注释字符集
alter table hive.TABLE_PARAMS modify column PARAM_VALUE varchar(20000) character set utf8;#修改分区参数,支持分区建用中文表示
alter table hive.PARTITION_PARAMS modify column PARAM_VALUE varchar(20000) character set utf8;
alter table hive.PARTITION_KEYS modify column PKEY_COMMENT varchar(20000) character set utf8;
step2: 在hive-site.xml配置文件中修改如下配置
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://bigdata004:3306/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
这边设置好之后,再创建带有中文注释的内部表的时候就可以显示其中文的建表注释了,我们可以尝试一下重新创建一个带有中文注释的表emp2,再次执行查看表的建表信息,就可以正常显示中文注释咯!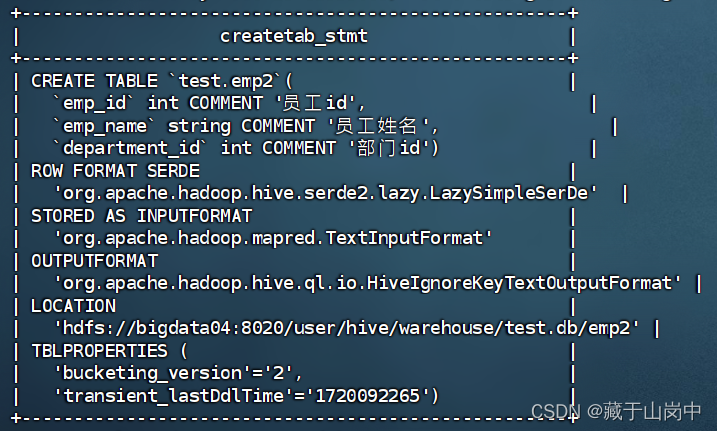
2.3.3 创建指定列分隔符的员工内部表emp3
--创建指定列分隔符的员工内部表emp3createtableifnotexists test.emp3(
emp_id intcomment"员工id",
emp_name string comment"员工姓名",
department_id intcomment"部门id")comment"员工内部表"row format delimited fieldsterminatedby','
stored as textfile
;--在beeline命令行中执行create_emp3.sql文件
source /opt/sql/create_emp3.sql;--查询表的建表信息showcreatetable test.emp3;--查看表的类型信息--desc formatted 数据库名.表名;desc formatted test.emp3;
2.4 Hive外部表
hive外部表的特点:
- 在hive中删除外部表的时候,只删除该表在MySQL中存储的元数据,而该表在hdfs上的表数据会得到保留。
- 在hive中对外部表的任何操作,不会对存储在hdfs上的额表数据产生任何影响,而只会影响MySQL中的元数据,所以不用担心数据损坏。
举个栗子:(创建部门外部表)
--创建部门外部表--写在/opt/sql/create_external_dept.sql中create external tableifnotexists test.dept(
dept_id intcomment"部门id",
dept_name string comment"部门名称")comment"部门外部表"row format delimited fieldsterminatedby','
stored as textfile
location "/hive_external_table/test.db/dept";;----在beeline命令行中执行sql文件
source /opt/sql/create_external_dept.sql;--查询表的建表信息showcreatetable test.dept;--查看表的类型信息--desc formatted 数据库名.表名;desc formatted test.dept;
2.5 Hive分区表
分区表的优势在于提高数据查询的效率,查询时可以通过筛选指定分区减少查询量。
2.5.1 静态分区表
静态分区表:在往分区中增加数据时。需要明确指定分区字段和分区值
举个栗子:(创建销售静态分区表)
--创建销售静态分区表createtableifnotexists test.sale_static(
sale_id intcomment"销售id",
goods_id intcomment"商品id",
sale_count intcomment"销售数量")comment"销售静态分区表"
partitioned by(year string,month string,day string)row format delimited fieldsterminatedby','
stored as textfile
;--在beeline命令行中执行sql文件
source /opt/sql/create_sale_static.sql;--查询表的建表信息showcreatetable test.sale_static;--查看表的类型信息--desc formatted 数据库名.表名;desc formatted test.sale_static;
2.6 Hive表的数据加载
通用的数据加载命令:
loaddata[local] inpath '数据文件路径'[overwrite]intotable dbname.tablename
[partition(分区字段1=分区值1,分区字段2=分区值2...)];
通用的hdfs上数据加载命令:
loaddata[local]'数据文件路径'[overwrite]intotable dbname.tablename
[partition(分区字段1=分区值1,分区字段2=分区值2...)];
2.6.1 静态分区表
创建数据文件init_sale_static_data.txt
100,1001,2
101,2008,5
102,2103,8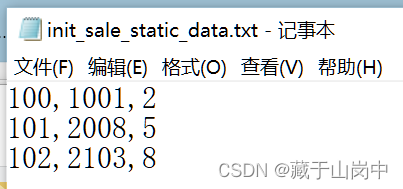
--向静态分区表test.sale_static中加载数据 数据是追加模式 数据文件存放在Linux文件系统loaddatalocal inpath '/opt/file/init_sale_static_data.txt'intotable test.sale_static partition(year='2024',month='07',day='01');
查看数据表中的数据:
假设再执行一次,则会追加在后面
--向静态分区表test.sale_static中加载数据 数据是覆盖模式 数据文件存放在Linux文件系统loaddatalocal inpath '/opt/file/init_sale_static_data.txt' overwrite intotable test.sale_static partition(year='2024',month='07',day='02');
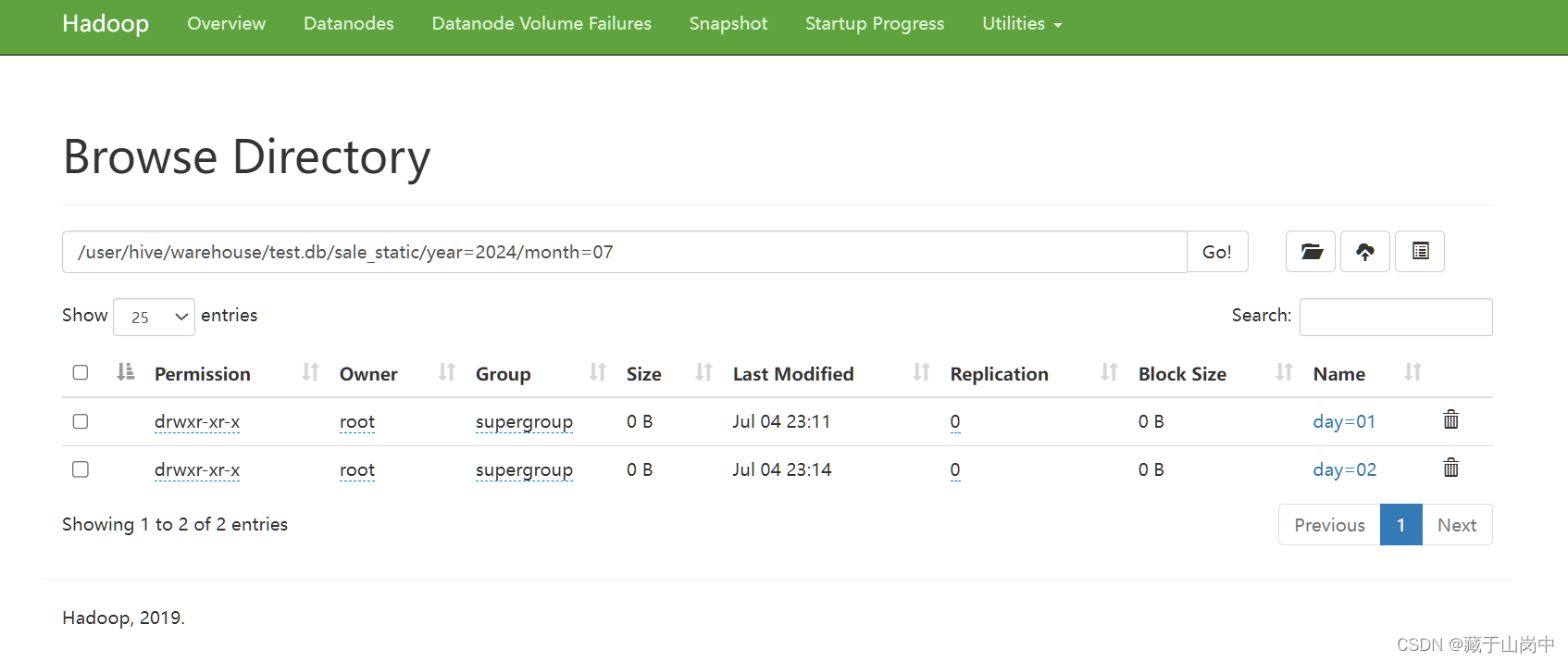
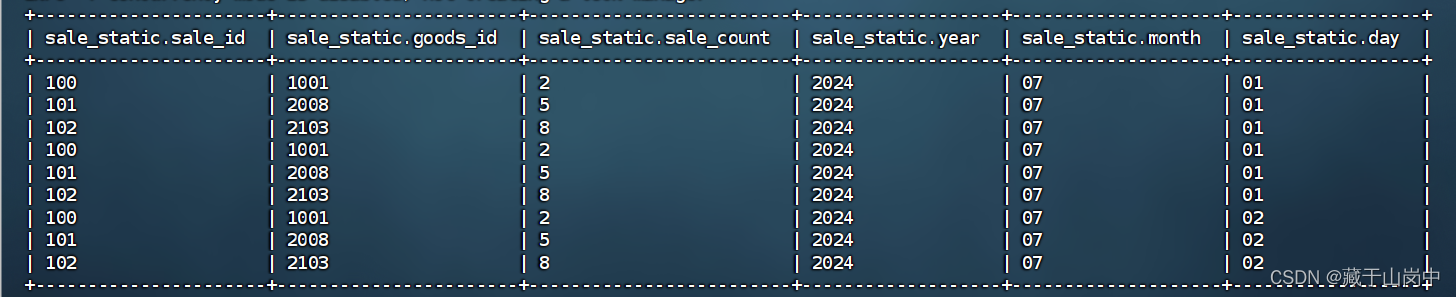
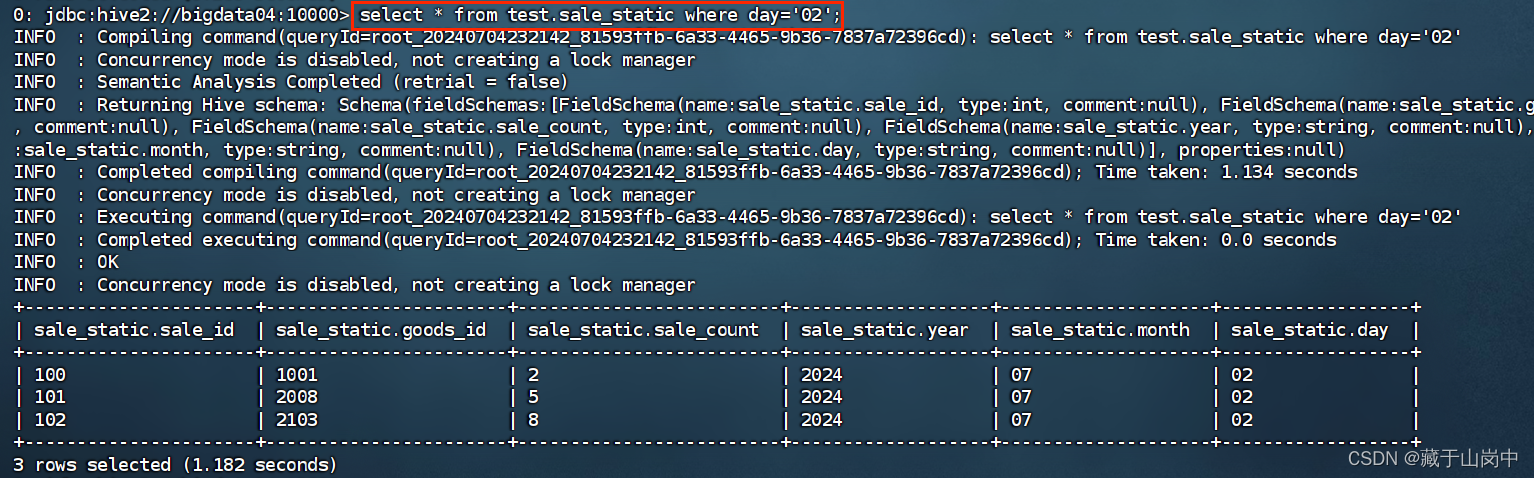
但这个时候再次执行overwrite那个时候就是覆盖,还是会展示这三条。
2.6.2 动态分区表
--创建销售动态分区表createtableifnotexists test.sale_dynamic(
sale_id intcomment"销售id",
goods_id intcomment"商品id",
sale_count intcomment"销售数量")comment"销售动态分区表"
partitioned by(year string,month string,day string)row format delimited fieldsterminatedby','
stored as textfile
;--在beeline命令行中执行sql文件
source /opt/sql/create_sale_dynamic.sql;
创建数据文件init_sale_pre_data.txt
100,1001,2,2024,06,29
101,2008,5,2024,07,01
102,2103,8,2024,07,02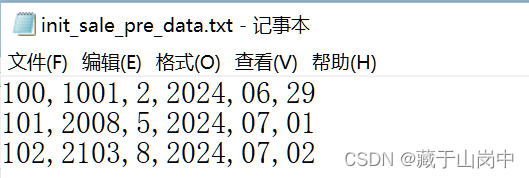
向动态分区表插入数据:
--向动态分区表插入数据 不能使用load data命令 按照以下方式进行--1. 创建一张前置表createtableifnotexists test.sale_pre(
sale_id intcomment"销售id",
goods_id intcomment"商品id",
sale_count intcomment"销售数量",year string comment"年",month string comment"月",day string comment"日")comment"销售前置表,用于向动态分区表插入数据"row format delimited fieldsterminatedby','
stored as textfile
;--在beeline命令行中执行sql文件
source /opt/sql/sale_pre.sql;--2.向前置表中加载数据loaddatalocal inpath '/opt/file/init_sale_pre_data.txt' overwrite intotable test.sale_pre;--3.将前置表中的数据插入到动态分区表中--ture:开启动态分区 false:关闭动态分区set hive.exec.dynamic.partition=true;--nonstrict:非严格模式(插入分区表时不需要指定静态分区) strict:严格模式(插入分区表时必须指定静态分区)set hive.exec.dynamic.partition.mode=nonstrict;--4.使用insert语句将前置表数据插入动态分区表insertintotable test.sale_dynamic partition(year,month,day)select
sale_id,
goods_id,
sale_count,year,month,dayfrom test.sale_pre;--在beeline命令行中执行sql文件
source /opt/sql/insert_sale_dynamic.sql;
查看sale_dynamic数据表中的数据: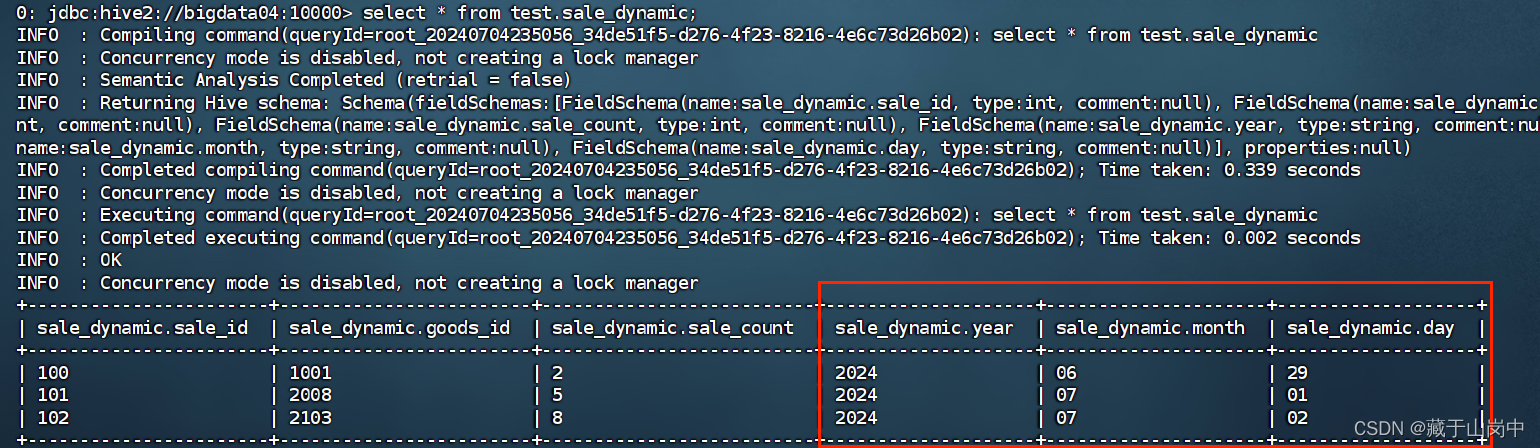
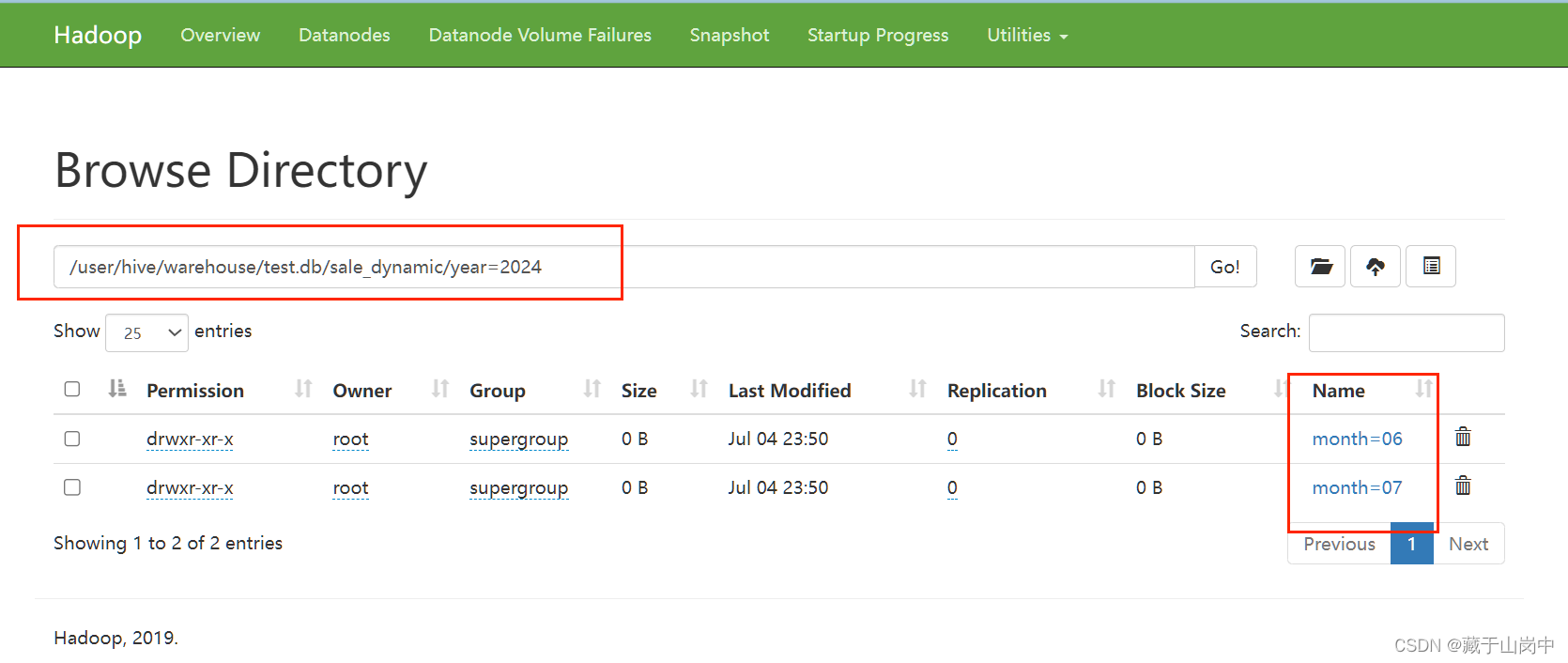
2.6.2 向外部表加载数据
--向外部表加载数据--1.使用load_data命令--2.将数据直接上传到外部表在hdfs上的路径
hadoop fs -put /opt/file/init_dept_data.txt /hive_external_table/test.db/dept;--查看外部表中的数据select*from dept;
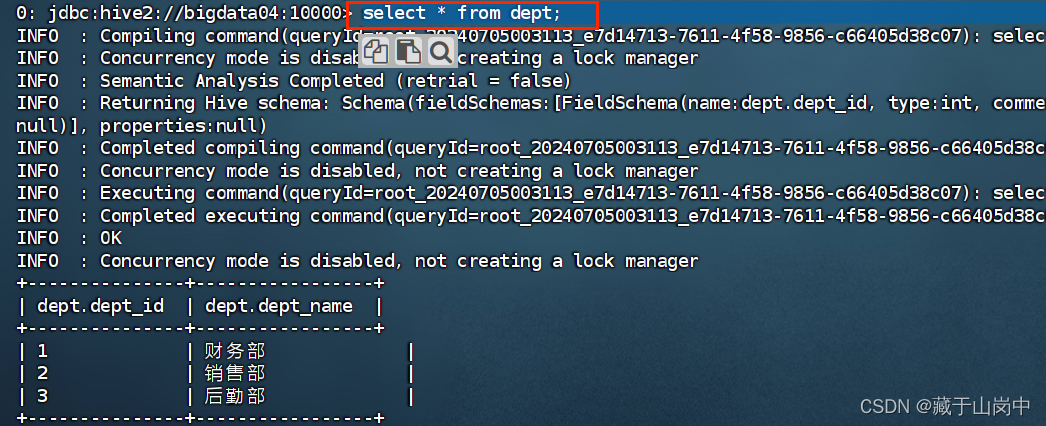
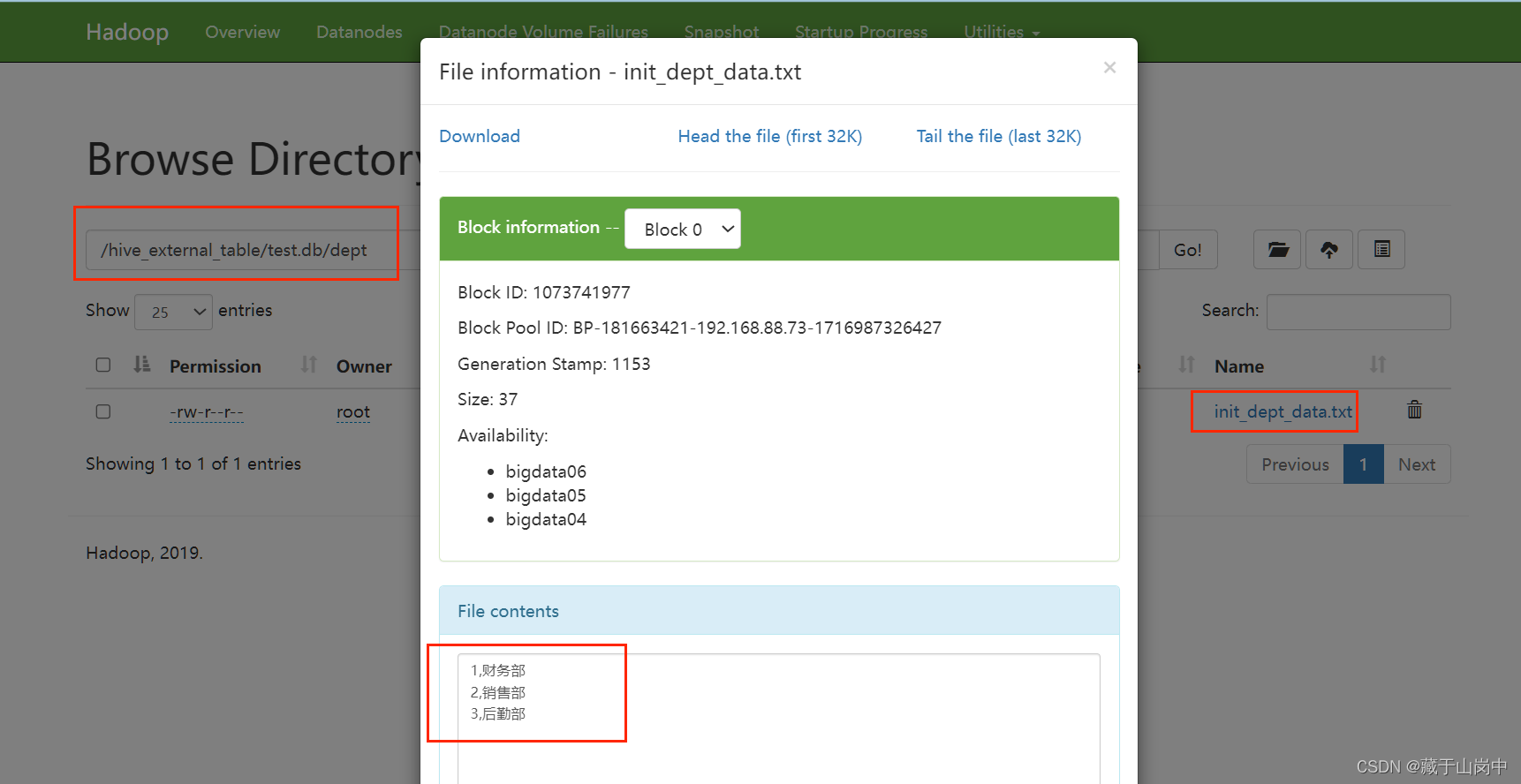
这个时候展示外部表和内部表的区别:
当我删除外部表的时候,在MySQL中元数据不见了,但是在hdfs中其实是存在的。
但删除内部表的时候,在MySQL中元数据不见之后,hdfs上也会一起删除。
不再赘述。
版权归原作者 藏于山岗中 所有, 如有侵权,请联系我们删除。