
此处的中文乱码和mysql的库表 编码 latin utf 无关。
直接上案例。
有时候我们需要自定义一列,有时是汉字有时是字母,结果遇到这种情况了。

说实话看到这真是糟心。这谁受得了。
单独select 没有任何问题。

这是怎么回事呢? 经过一番检查,发现有个地方类似与 "境内" as col但是没乱码,
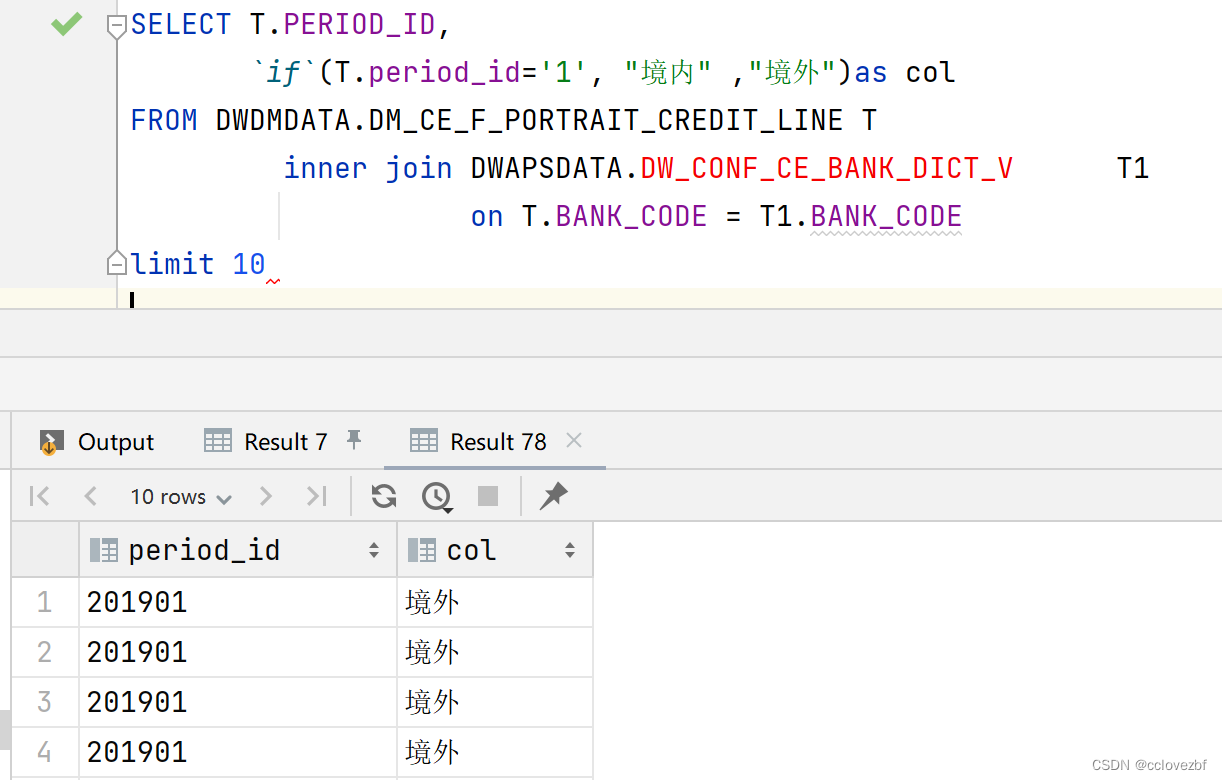
此时怀疑就是if 函数起了作用,但是一时间不知道是为啥。。
经过多方面测试 concat("境内") concat_ws("","境内")没用,
concat_ws("",arrary("境内")) 有用,此时也不知道如何下手,只有掏出大杀器 explain.
起作用的
Plan optimized by CBO.
""
Vertex dependency in root stage
Map 1 <- Map 3 (BROADCAST_EDGE)
Reducer 2 <- Map 1 (SIMPLE_EDGE)
""
Stage-0
Fetch Operator
limit:-1
Stage-1
Reducer 2
File Output Operator [FS_14]
Select Operator [SEL_13] (rows=105 width=273)
" Output:[""_col0"",""_col1"",""_col2"",""_col3"",""_col4"",""_col5"",""_col6"",""_col7""]"
Group By Operator [GBY_12] (rows=105 width=273)
" Output:[""_col0"",""_col1"",""_col2"",""_col3"",""_col4""],keys:KEY._col0, KEY._col1, KEY._col2, KEY._col3, KEY._col4"
<-Map 1 [SIMPLE_EDGE] vectorized
SHUFFLE [RS_28]
" PartitionCols:_col0, _col1, _col2, _col3, _col4"
Group By Operator [GBY_27] (rows=211 width=273)
" Output:[""_col0"",""_col1"",""_col2"",""_col3"",""_col4""],keys:_col1, _col2, _col3, _col4, _col5"
Map Join Operator [MAPJOIN_26] (rows=211 width=273)
" Conds:SEL_25._col0=RS_23._col0(Inner),Output:[""_col1"",""_col2"",""_col3"",""_col4"",""_col5""]"
<-Map 3 [BROADCAST_EDGE] vectorized
BROADCAST [RS_23]
PartitionCols:_col0
Select Operator [SEL_22] (rows=1 width=736)
" Output:[""_col0"",""_col1"",""_col2"",""_col3""]"
Filter Operator [FIL_21] (rows=1 width=736)
predicate:bank_code is not null
TableScan [TS_3] (rows=1 width=736)
" dwapsdata@dw_conf_ce_bank_dict_v,t1,Tbl:COMPLETE,Col:NONE,Output:[""bank_code"",""bank_name"",""bank_short_name"",""bank_onshore_flag""]"
<-Select Operator [SEL_25] (rows=192 width=273)
" Output:[""_col0"",""_col1""]"
Filter Operator [FIL_24] (rows=192 width=273)
predicate:bank_code is not null
TableScan [TS_0] (rows=192 width=273)
" dwdmdata@dm_ce_f_portrait_credit_line,t,Tbl:COMPLETE,Col:COMPLETE,Output:[""bank_code""]"
""
没有作用的
Plan optimized by CBO.
""
Vertex dependency in root stage
Map 1 <- Map 3 (BROADCAST_EDGE)
Reducer 2 <- Map 1 (SIMPLE_EDGE)
""
Stage-0
Fetch Operator
limit:-1
Stage-1
Reducer 2 vectorized
File Output Operator [FS_31]
Select Operator [SEL_30] (rows=105 width=273)
" Output:[""_col0"",""_col1"",""_col2"",""_col3"",""_col4"",""_col5"",""_col6""]"
Group By Operator [GBY_29] (rows=105 width=273)
" Output:[""_col0"",""_col1"",""_col2"",""_col3"",""_col4""],keys:KEY._col0, KEY._col1, KEY._col2, KEY._col3, KEY._col4"
<-Map 1 [SIMPLE_EDGE] vectorized
SHUFFLE [RS_28]
" PartitionCols:_col0, _col1, _col2, _col3, _col4"
Group By Operator [GBY_27] (rows=211 width=273)
" Output:[""_col0"",""_col1"",""_col2"",""_col3"",""_col4""],keys:_col1, _col2, _col3, _col4, _col5"
Map Join Operator [MAPJOIN_26] (rows=211 width=273)
" Conds:SEL_25._col0=RS_23._col0(Inner),Output:[""_col1"",""_col2"",""_col3"",""_col4"",""_col5""]"
<-Map 3 [BROADCAST_EDGE] vectorized
BROADCAST [RS_23]
PartitionCols:_col0
Select Operator [SEL_22] (rows=1 width=736)
" Output:[""_col0"",""_col1"",""_col2"",""_col3""]"
Filter Operator [FIL_21] (rows=1 width=736)
predicate:bank_code is not null
TableScan [TS_3] (rows=1 width=736)
" dwapsdata@dw_conf_ce_bank_dict_v,t1,Tbl:COMPLETE,Col:NONE,Output:[""bank_code"",""bank_name"",""bank_short_name"",""bank_onshore_flag""]"
<-Select Operator [SEL_25] (rows=192 width=273)
" Output:[""_col0"",""_col1""]"
Filter Operator [FIL_24] (rows=192 width=273)
predicate:bank_code is not null
TableScan [TS_0] (rows=192 width=273)
" dwdmdata@dm_ce_f_portrait_credit_line,t,Tbl:COMPLETE,Col:COMPLETE,Output:[""bank_code""]"
""
对比发现

vectorzied 这个单词一出来我就知道怎么回事了。
hive decimal bug, nvl(decimal,1)=0_cclovezbf的博客-CSDN博客
这个b参数好处没体会到一点,bug到是一堆。
**set hive.vectorized.execution.enabled=false; **即可解决中文乱码问题!!!!!!!
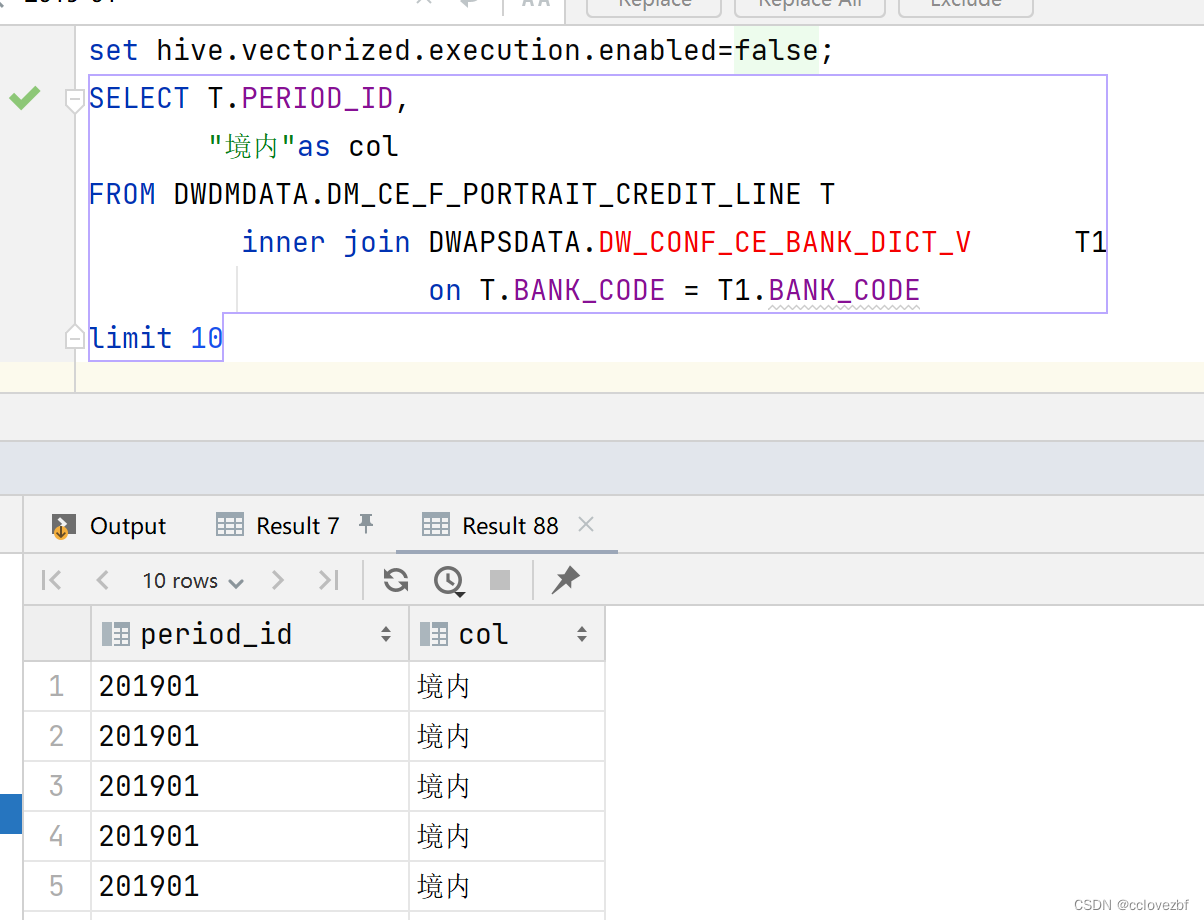
其实还有别的办法,但是和concat_ws(array(""))一样比较丑陋,我就不说了
版权归原作者 cclovezbf 所有, 如有侵权,请联系我们删除。