
Spark框架—RDD分区和缓存
AccessLogAgg.scala
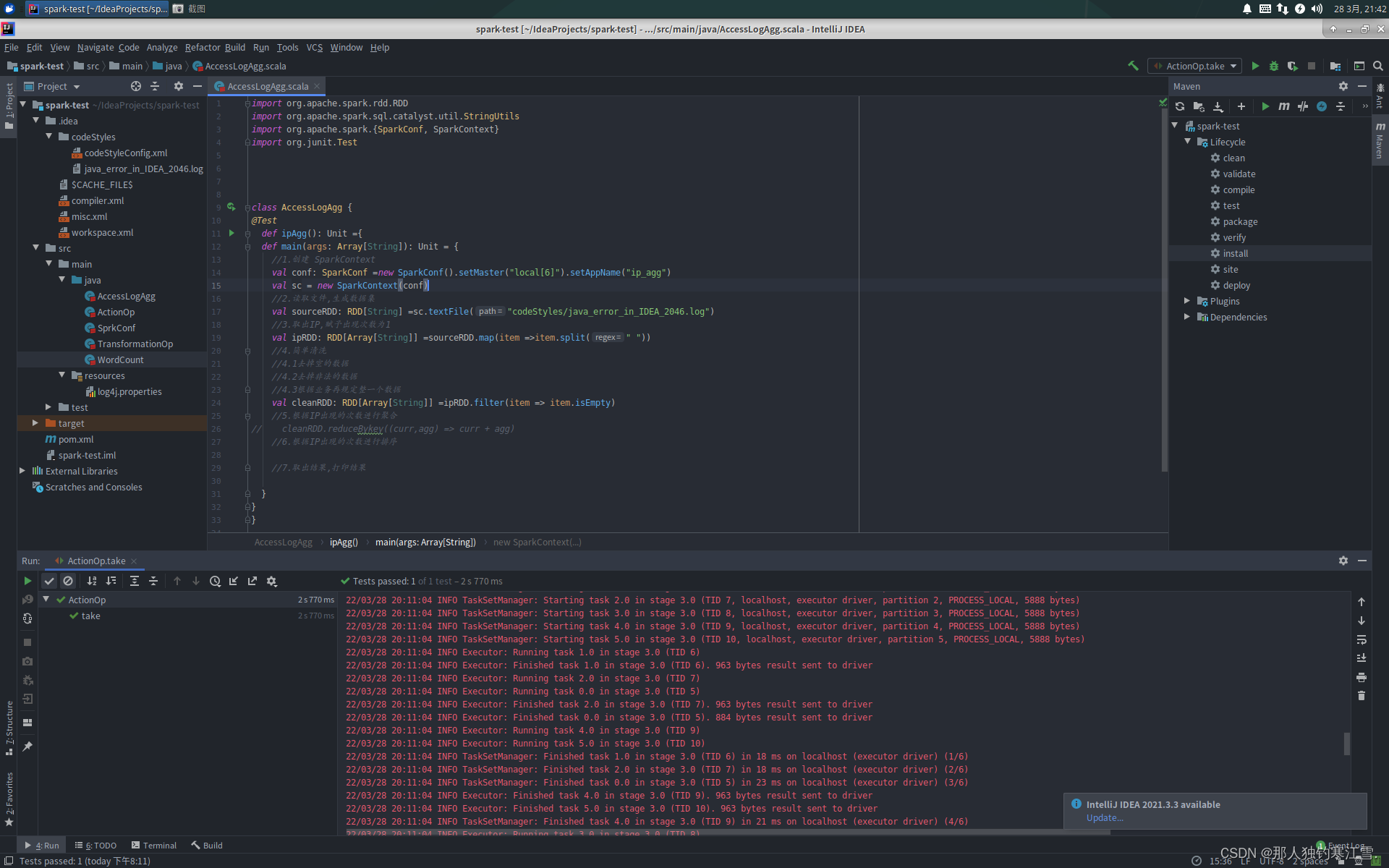
importorg.apache.spark.rdd.RDD
importorg.apache.spark.sql.catalyst.util.StringUtils
importorg.apache.spark.{SparkConf, SparkContext}importorg.junit.Test
class AccessLogAgg {@Testdef ipAgg():Unit={def main(args: Array[String]):Unit={//1.创建 SparkContextval conf: SparkConf =new SparkConf().setMaster("local[6]").setAppName("ip_agg")val sc =new SparkContext(conf)//2.读取文件,生成数据集val sourceRDD: RDD[String]=sc.textFile("codeStyles/java_error_in_IDEA_2046.log")//3.取出IP,赋予出现次数为1val ipRDD: RDD[Array[String]]=sourceRDD.map(item =>item.split(" "))//4.简单清洗//4.1去掉空的数据//4.2去掉非法的数据//4.3根据业务再规定整一个数据val cleanRDD: RDD[Array[String]]=ipRDD.filter(item => item.isEmpty)//5.根据IP出现的次数进行聚合// cleanRDD.reduceBykey((curr,agg) => curr + agg)//6.根据IP出现的次数进行排序//7.取出结果,打印结果}}}
ActionOp.scala
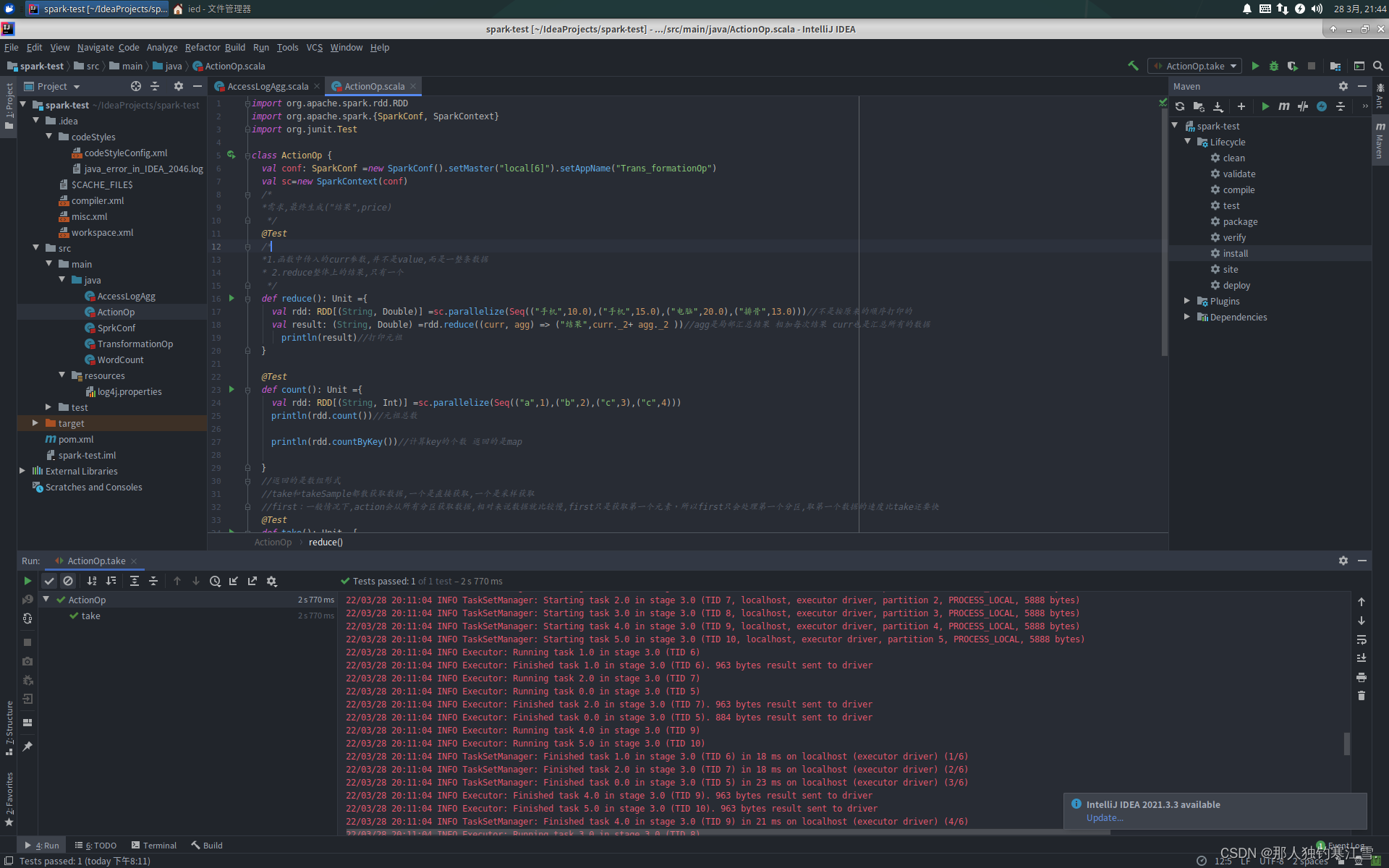
importorg.apache.spark.rdd.RDD
importorg.apache.spark.{SparkConf, SparkContext}importorg.junit.Test
class ActionOp {val conf: SparkConf =new SparkConf().setMaster("local[6]").setAppName("Trans_formationOp")val sc=new SparkContext(conf)/*
*需求,最终生成("结果",price)
*/@Test/*
*1.函数中传入的curr参数,并不是value,而是一整条数据
* 2.reduce整体上的结果,只有一个
*/def reduce():Unit={val rdd: RDD[(String,Double)]=sc.parallelize(Seq(("手机",10.0),("手机",15.0),("电脑",20.0),("排骨",13.0)))//不是按原来的顺序打印的val result:(String,Double)=rdd.reduce((curr, agg)=>("结果",curr._2+ agg._2 ))//agg是局部汇总结果 相加每次结果 curr也是汇总所有的数据
println(result)//打印元祖}@Testdef count():Unit={val rdd: RDD[(String,Int)]=sc.parallelize(Seq(("a",1),("b",2),("c",3),("c",4)))
println(rdd.count())//元祖总数
println(rdd.countByKey())//计算key的个数 返回的是map}//返回的是数组形式//take和takeSample都散获取数据,一个是直接获取,一个是采样获取//first:一般情况下,action会从所有分区获取数据,相对来说数据就比较慢,first只是获取第一个元素,所以first只会处理第一个分区,取第一个数据的速度比take还要快@Testdef take():Unit={val rdd: RDD[Int]=sc.parallelize(Seq(1,2,3,4,5,6))
rdd.take(3).foreach(item => println(item))//因为返回的是数组形式 所以用foreach
println(rdd.first())
rdd.takeSample(withReplacement =false,num =3).foreach(println(_))//取三个数,没有重复值}//数学计算//除了这四个支持意外,还有其他很多的支持,这些对于数字类型的支持都是Action@Testdef numberic():Unit={val rdd: RDD[Int]=sc.parallelize(Seq(1,2,3,4,10,20,30,50,100))
println(rdd.max())
println(rdd.min())
println(rdd.mean())//求均值
println(rdd.sum())}}
TransformationOp.scala
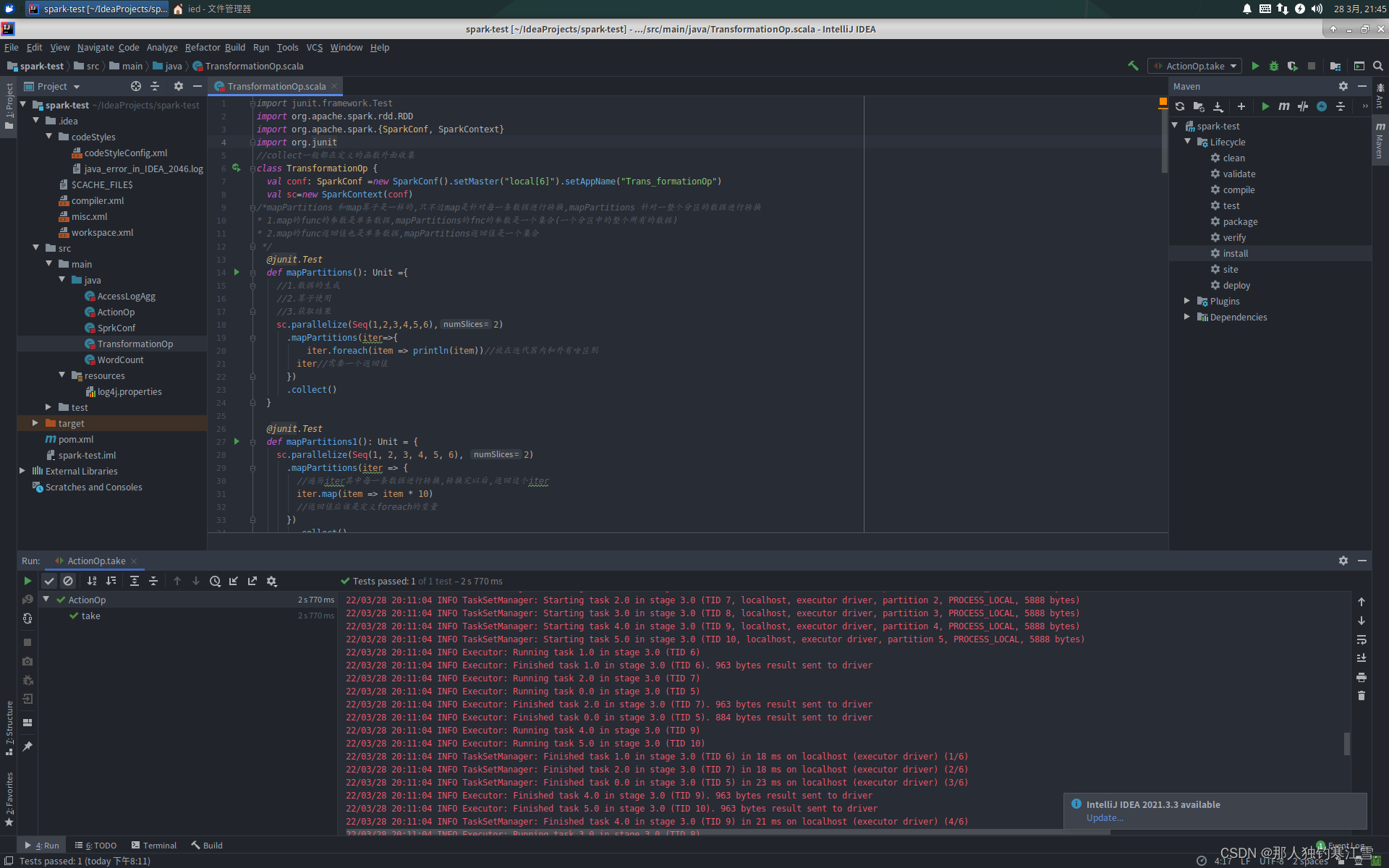
importjunit.framework.Test
importorg.apache.spark.rdd.RDD
importorg.apache.spark.{SparkConf, SparkContext}importorg.junit//collect一般都在定义的函数外面收集class TransformationOp {val conf: SparkConf =new SparkConf().setMaster("local[6]").setAppName("Trans_formationOp")val sc=new SparkContext(conf)/*mapPartitions 和map算子是一样的,只不过map是针对每一条数据进行转换,mapPartitions 针对一整个分区的数据进行转换
* 1.map的func的参数是单条数据,mapPartitions的fnc的参数是一个集合(一个分区中的整个所有的数据)
* 2.map的func返回值也是单条数据,mapPartitions返回值是一个集合
*/@junit.Testdef mapPartitions():Unit={//1.数据的生成//2.算子使用//3.获取结果
sc.parallelize(Seq(1,2,3,4,5,6),2).mapPartitions(iter=>{
iter.foreach(item => println(item))//放在迭代器内和外有啥区别
iter//需要一个返回值}).collect()}@junit.Testdef mapPartitions1():Unit={
sc.parallelize(Seq(1,2,3,4,5,6),2).mapPartitions(iter =>{//遍历iter其中每一条数据进行转换,转换完以后,返回这个iter
iter.map(item => item *10)//返回值应该是定义foreach的变量}).collect().foreach(item => println(item))//没有返回值}@junit.Testdef mapPartitionsWithIndex():Unit={
sc.parallelize(Seq(1,2,3,4,5,6),2).mapPartitionsWithIndex((index,iter)=>{
println("index:"+index)
iter.foreach(item=>println(item))
iter
}).collect()}@junit.Testdef map1():Unit={
sc.parallelize(Seq(1,2,3,4,5,6),2).mapPartitionsWithIndex((index,iter)=>{
println("index:"+index)
iter.map(item=> item *10)
iter.foreach(item => println(item))
iter
}).collect()}@junit.Test//1.定义集合//2.过滤数据//3.收集结果def filter():Unit={//filter相当于if结构
sc.parallelize(Seq(1,2,3,4,5,6,7,8,9,10)).filter(item => item %2==0).collect().foreach(item => println(item))}//sample 算子可以从一个数据集中抽样出来一部分,常用于减小数据集以保证运行速度,并且尽可能少规律的损失//1.第一个参数值为投入哦,则抽样出来的数据集中可能会有重复,2.sample接受第二个参数意为抽样的比例,3.seed随机数种子,用于sample内部随即生成//1.为true是有放回的,2.为false是无放回的@junit.Test//1.定义集合//2.过滤数据//3.收集结果def sample():Unit={//sample作用:把大数据集变小,尽可能的减少数据集规律的损失val rdd1: RDD[Int]=sc.parallelize(Seq(1,2,3,4,5,6,7,8,9,10),2)val rdd2: RDD[Int]=rdd1.sample(withReplacement =true,0.6)//第二个参数表示从10份里面抽取6份,true表示有返回值val result: Array[Int]=rdd2.collect()
result.foreach(item => println(item))}@junit.Testdef mapValues():Unit={
sc.parallelize(Seq(("a",1),("b",2),("c",3),("d",4))).mapValues(item => item *10).collect().foreach(println(_))}@junit.Testdef intersection():Unit={val rdd1: RDD[Int]=sc.parallelize(Seq(1,2,3,4,5))val rdd2: RDD[Int]=sc.parallelize(Seq(2,5,3,6))
rdd1.intersection(rdd2)//交集.collect().foreach(println(_))}@junit.Testdef union():Unit={//并集val rdd1: RDD[Int]=sc.parallelize(Seq(1,2,3,4,5,6))val rdd2: RDD[Int]=sc.parallelize(Seq(3,7,8))
rdd1.union(rdd2).collect().foreach(println(_))}@junit.Test//差集def subtract():Unit={val rdd1: RDD[Int]=sc.parallelize(Seq(1,2,3,4))val rdd2: RDD[Int]=sc.parallelize(Seq(1,3,4))
rdd1.subtract(rdd2).collect().foreach(println(_))}//groupByKey 能不能在map端做Combiner有没有意义?没有的 取出key值,按照Key分组,和ReduceByKey有点类似@junit.Testdef groupByKey():Unit={
sc.parallelize(Seq(("a",1),("a",2),("b",1))).groupByKey().collect().foreach(println(_))}@junit.Test//计算集合内的平均值def combineByKey():Unit={//1.准备集合val rdd: RDD[(String,Double)]=sc.parallelize(Seq(("zhangsan",99.0),("zhangsan",96.0),("lisi",97.0),("lisi",98.0),("zhangsan",97.0)))//2.算子操作//2.1createCombiner转换数据//2.2mergeValue分区上的聚合//2.3mergeCombiners把所有分区上的结果再次聚合,生成最终结果val combineResult: RDD[(String,(Double,Int))]=rdd.combineByKey(
createCombiner =(curr:Double)=>(curr,1),
mergeValue=(curr:(Double,Int),nextValue:Double)=>(curr._1+nextValue,curr._2+1),
mergeCombiners =(curr:(Double,Int),agg:(Double,Int))=>(curr._1+agg._1,curr._2+agg._2))//("zhangsan",(99+96+97,3))val resultRDD: RDD[(String,Double)]=combineResult.map(item=>(item._1,item._2._1/item._2._2))//3.获取结果,打印结果
resultRDD.collect().foreach(println(_))}//foldByKey和spark中的reduceByKey的区别是可以指定初始值//foldByKey和scala中的foldLeft或者foldRight区别是,这个初始值作用于每一个数据,而foldLeft只作用一次@junit.Testdef foldByKey():Unit={
sc.parallelize(Seq(("a",1),("a",1),("b",1))).foldByKey(10)((curr,agg)=> curr + agg)//agg是局部变量 10是单次增加不是全体增加.foreach(println(_))}//zeroValue:指定初始值//seqOp:作用于每一个元素,根据初始值,进行计算//combOp:将seqOp处理过的结果进行聚合//[email protected] aggregateByKey():Unit={val rdd: RDD[(String,Double)]= sc.parallelize(Seq(("手机",10.0),("手机",15.0),("电脑",20.0)))
rdd.aggregateByKey(0.8)((zeroValue, item)=> item * zeroValue,(curr, agg)=> curr + agg).collect().foreach(println(_))}@junit.Testdef join():Unit={val rdd1: RDD[(String,Int)]=sc.parallelize(Seq(("a",1),("a",2),("b",1)))val rdd2: RDD[(String,Int)]=sc.parallelize(Seq(("a",10),("a",11),("b",12)))
rdd1.join(rdd2)//两数组之间的交换.collect().foreach(println(_))}//sortBy可以作用于任何类型数据的RDD,sortByKey只有kv类型数据的RDD中才有//sortBy可以按照任何部分来排序,sortByKey只能按照key来排序//sortByKey写法简单,不用编写函数了@junit.Testdef sort():Unit={val rdd1: RDD[Int]=sc.parallelize(Seq(2,4,1,5,1,8))val rdd2: RDD[(String,Int)]=sc.parallelize(Seq(("a",1),("b",3),("c",2)))
rdd1.sortBy(item => item )//返回本身值.collect().foreach(println(_))
rdd2.sortBy(item => item._2).collect().foreach(println(_))//本来是求key值,但是嗯可以返回为value值
rdd2.sortByKey()// 按照key值来进行排序的
rdd2.map(item =>(item._2,item._1)).sortByKey().map(item =>(item._2,item._1)).collect().foreach(println(_))}@junit.Test/*
*repartition 进行重分区的时候,默认是shuffle的
* coalesce进行重分区的时候,默认是不Shuffle的,coalesce默认不能增大分区数
*/def partition():Unit={val rdd: RDD[Int]=sc.parallelize(Seq(1,2,3,4,5),2)//分区数为2//repartition
println(rdd.repartition(5).partitions.length)//分区个数,默认shuffle=true,使用length或者size都行//coalesce
println(rdd.coalesce(5,shuffle =true).partitions.length)//默认是没有shuffle}//转换:map,mapPartitions, mapValues//过滤:filter,sample//集合操作:intersection,union,subtract//聚合操作:reduceByKey,groupByKey,combineByKey,foldByKey,aggregateByKey,sortBy,sortByKey//重分区:repartition,coalesce}
WorldCount.scala
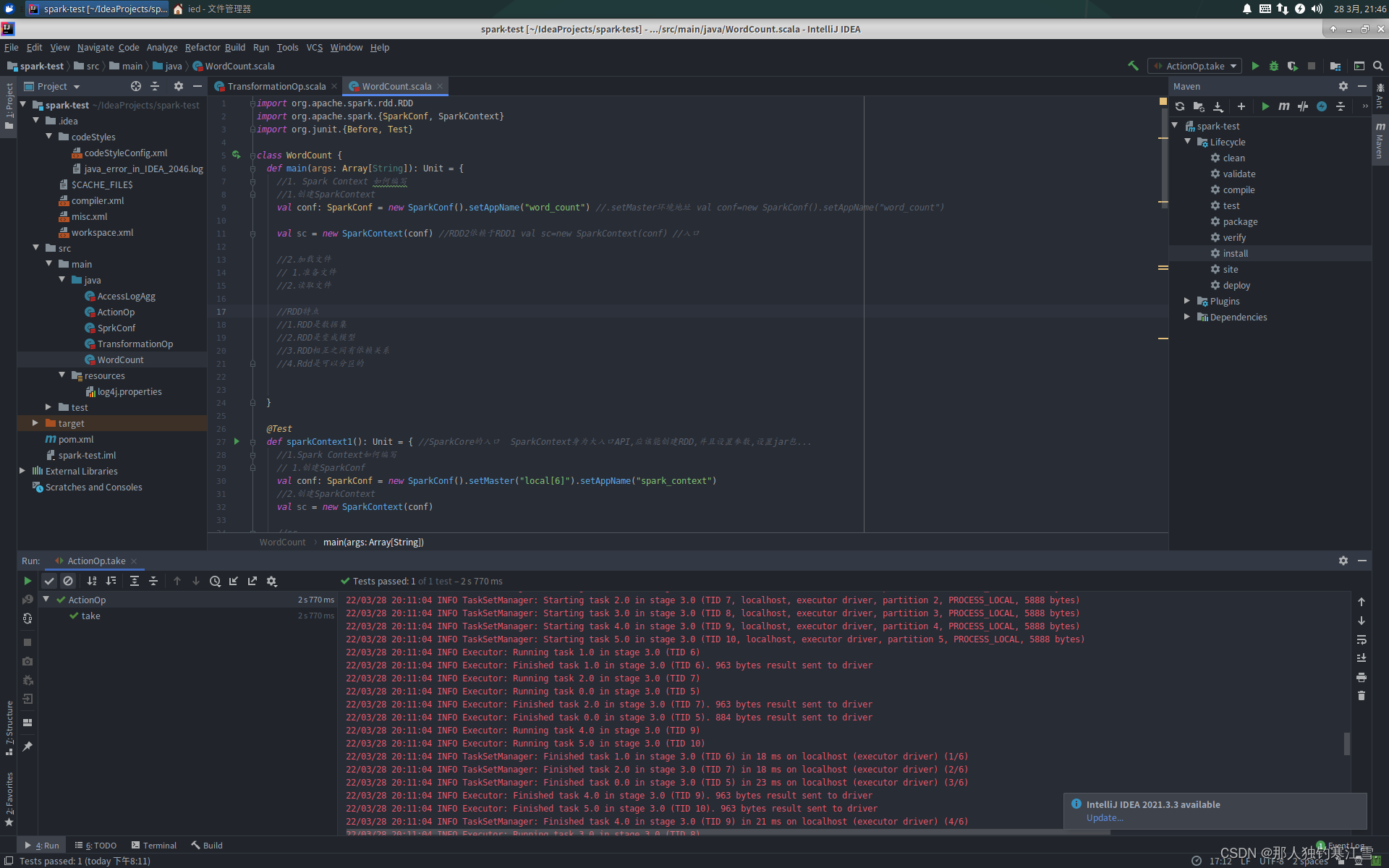
importorg.apache.spark.rdd.RDD
importorg.apache.spark.{SparkConf, SparkContext}importorg.junit.{Before, Test}class WordCount {def main(args: Array[String]):Unit={//1. Spark Context 如何编写//1.创建SparkContextval conf: SparkConf =new SparkConf().setAppName("word_count")//.setMaster环境地址 val conf=new SparkConf().setAppName("word_count")val sc =new SparkContext(conf)//RDD2依赖于RDD1 val sc=new SparkContext(conf) //入口//2.加载文件// 1.准备文件//2.读取文件//RDD特点//1.RDD是数据集//2.RDD是变成模型//3.RDD相互之间有依赖关系//4.Rdd是可以分区的}@Testdef sparkContext1():Unit={//SparkCore的入口 SparkContext身为大入口API,应该能创建RDD,并且设置参数,设置jar包...//1.Spark Context如何编写// 1.创建SparkConfval conf: SparkConf =new SparkConf().setMaster("local[6]").setAppName("spark_context")//2.创建SparkContextval sc =new SparkContext(conf)//sc...//2.关闭SparkContext,释放集群资源}var conf: SparkConf = _
// val sc:SparkContext =new SparkContext(conf)var sc: SparkContext = _
@Beforedef init():Unit={
conf =new SparkConf().setMaster("local[6]").setAppName("spark_context1")
sc =new SparkContext(conf)}//从本地集合创建@Test//注解def rddCreationLocal():Unit={val seq = Seq(1,2,3)//seq什么数据那么RDD就是什么类型val rdd1: RDD[Int]= sc.parallelize(seq,2)//本地集合的分区数val rdd2: RDD[Int]= sc.makeRDD(seq,2)}//从文件中创建@Testdef rddCreationFiles():Unit={
sc.textFile("file:///...")//1.txtFile传入的是什么//1.传入的是一个路径,读取路径,2.hdfs://file:// /.../...(这种方式分为在集群中执行还是在本地执行,如果在集群中,读的是hdfs,本地读的是文件)//2.是否支持分区//1.假如传入的path是hdfs:///... 2.分区是由HDFS的block决定的//3.支持什么平台//1.支持什么平台:支持aws和阿里云}@Testdef rddCreateFromRDD():Unit={val rdd1: RDD[Int]= sc.parallelize(Seq(1,2,3))//通过在rdd上执行算子操作,会生成新的rdd//原地计算//str.substr 返回新的字符串,非原地计算//和字符串中的方式很像,字符串是可变的吗?//RDD可变吗,不可变val rdd2: RDD[Int]= rdd1.map(item => item)}//Map算子@Testdef mapTest():Unit={//1.创建RDDval rdd1: RDD[Int]= sc.parallelize(Seq(1,2,3))//2.执行Map操作val rdd2: RDD[Int]= rdd1.map(item => item *10)//3.得到结果val result: Array[Int]= rdd2.collect()
result.foreach(goods => println(goods))}@Test//flatMap:1.把RDD中的数据转换为数据或者集合形式 2.把集合或者数组展开 3. 生成了多条数据 flatMap是一对多def flatMapTest():Unit={//1.创建RDDval rdd1: RDD[String]= sc.parallelize(Seq("hello lily","hello lucy","hello tim"))//2.处理数据val rdd2: RDD[String]= rdd1.flatMap(item => item.split(" "))//拆分数组为一个个单词//3.得到结果val result: Array[String]= rdd2.collect()
result.foreach(item => println(item))//4.关闭sc
sc.stop()}@Testdef reduceByKeyTest():Unit={//1.创建RDDval rdd1: RDD[String]= sc.parallelize(Seq("hello lily","hello lucy","hello tim"))//2.处理数据val rdd2: RDD[(String,Int)]= rdd1.flatMap(item => item.split(" ")).map(item =>(item,1))//元组的形式.reduceByKey((curr, agg)=> curr + agg)//curr代表第一次执行的value值,agg是局部结果 ,局部结果变成整体结果//reduceByKey第一步先按照key分组,然后对每一组进行聚合,得到结果//3.得到结果val result: Array[(String,Int)]= rdd2.collect()
result.foreach(item => println(item))//4.关闭sc
sc.stop()//下一级依赖上一级//Scala中的groupBy换成了reduceByKey//Transformation转换操作,例如map flatMap filter等//Action动作操作,例如 reduce collect show 等//注意:执行RDD的时候,在执行到转换操作的时候,并不会立刻执行,直到遇见了Action操作,才会触发真正的执行,这个特点叫做惰性求值}}
日志输出
/usr/lib/jvm/jdk1.8.0_202/bin/java -ea -Didea.test.cyclic.buffer.size=1048576 -javaagent:/home/ied/idea-IC-193.7288.26/lib/idea_rt.jar=40761:/home/ied/idea-IC-193.7288.26/bin -Dfile.encoding=UTF-8 -classpath /home/ied/idea-IC-193.7288.26/lib/idea_rt.jar:/home/ied/idea-IC-193.7288.26/plugins/junit/lib/junit5-rt.jar:/home/ied/idea-IC-193.7288.26/plugins/junit/lib/junit-rt.jar:/usr/lib/jvm/jdk1.8.0_202/jre/lib/charsets.jar:/usr/lib/jvm/jdk1.8.0_202/jre/lib/deploy.jar:/usr/lib/jvm/jdk1.8.0_202/jre/lib/ext/cldrdata.jar:/usr/lib/jvm/jdk1.8.0_202/jre/lib/ext/dnsns.jar:/usr/lib/jvm/jdk1.8.0_202/jre/lib/ext/jaccess.jar:/usr/lib/jvm/jdk1.8.0_202/jre/lib/ext/jfxrt.jar:/usr/lib/jvm/jdk1.8.0_202/jre/lib/ext/localedata.jar:/usr/lib/jvm/jdk1.8.0_202/jre/lib/ext/nashorn.jar:/usr/lib/jvm/jdk1.8.0_202/jre/lib/ext/sunec.jar:/usr/lib/jvm/jdk1.8.0_202/jre/lib/ext/sunjce_provider.jar:/usr/lib/jvm/jdk1.8.0_202/jre/lib/ext/sunpkcs11.jar:/usr/lib/jvm/jdk1.8.0_202/jre/lib/ext/zipfs.jar:/usr/lib/jvm/jdk1.8.0_202/jre/lib/javaws.jar:/usr/lib/jvm/jdk1.8.0_202/jre/lib/jce.jar:/usr/lib/jvm/jdk1.8.0_202/jre/lib/jfr.jar:/usr/lib/jvm/jdk1.8.0_202/jre/lib/jfxswt.jar:/usr/lib/jvm/jdk1.8.0_202/jre/lib/jsse.jar:/usr/lib/jvm/jdk1.8.0_202/jre/lib/management-agent.jar:/usr/lib/jvm/jdk1.8.0_202/jre/lib/plugin.jar:/usr/lib/jvm/jdk1.8.0_202/jre/lib/resources.jar:/usr/lib/jvm/jdk1.8.0_202/jre/lib/rt.jar:/home/ied/IdeaProjects/spark-test/target/classes:/home/ied/.ivy2/cache/org.scala-lang/scala-reflect/jars/scala-reflect-2.11.8.jar:/home/ied/.ivy2/cache/org.scala-lang/scala-library/jars/scala-library-2.11.8.jar:/home/ied/.ivy2/cache/org.scala-lang/scala-library/srcs/scala-library-2.11.8-sources.jar:/home/ied/.m2/repository/org/apache/spark/spark-core_2.11/2.1.1/spark-core_2.11-2.1.1.jar:/home/ied/.m2/repository/org/apache/avro/avro-mapred/1.7.7/avro-mapred-1.7.7-hadoop2.jar:/home/ied/.m2/repository/org/apache/avro/avro-ipc/1.7.7/avro-ipc-1.7.7.jar:/home/ied/.m2/repository/org/apache/avro/avro-ipc/1.7.7/avro-ipc-1.7.7-tests.jar:/home/ied/.m2/repository/org/codehaus/jackson/jackson-core-asl/1.9.13/jackson-core-asl-1.9.13.jar:/home/ied/.m2/repository/com/twitter/chill_2.11/0.8.0/chill_2.11-0.8.0.jar:/home/ied/.m2/repository/com/esotericsoftware/kryo-shaded/3.0.3/kryo-shaded-3.0.3.jar:/home/ied/.m2/repository/com/esotericsoftware/minlog/1.3.0/minlog-1.3.0.jar:/home/ied/.m2/repository/org/objenesis/objenesis/2.1/objenesis-2.1.jar:/home/ied/.m2/repository/com/twitter/chill-java/0.8.0/chill-java-0.8.0.jar:/home/ied/.m2/repository/org/apache/xbean/xbean-asm5-shaded/4.4/xbean-asm5-shaded-4.4.jar:/home/ied/.m2/repository/org/apache/hadoop/hadoop-client/2.2.0/hadoop-client-2.2.0.jar:/home/ied/.m2/repository/org/apache/hadoop/hadoop-common/2.2.0/hadoop-common-2.2.0.jar:/home/ied/.m2/repository/org/apache/commons/commons-math/2.1/commons-math-2.1.jar:/home/ied/.m2/repository/xmlenc/xmlenc/0.52/xmlenc-0.52.jar:/home/ied/.m2/repository/commons-configuration/commons-configuration/1.6/commons-configuration-1.6.jar:/home/ied/.m2/repository/commons-digester/commons-digester/1.8/commons-digester-1.8.jar:/home/ied/.m2/repository/commons-beanutils/commons-beanutils/1.7.0/commons-beanutils-1.7.0.jar:/home/ied/.m2/repository/commons-beanutils/commons-beanutils-core/1.8.0/commons-beanutils-core-1.8.0.jar:/home/ied/.m2/repository/com/google/protobuf/protobuf-java/2.5.0/protobuf-java-2.5.0.jar:/home/ied/.m2/repository/org/apache/hadoop/hadoop-auth/2.2.0/hadoop-auth-2.2.0.jar:/home/ied/.m2/repository/org/apache/hadoop/hadoop-hdfs/2.2.0/hadoop-hdfs-2.2.0.jar:/home/ied/.m2/repository/org/mortbay/jetty/jetty-util/6.1.26/jetty-util-6.1.26.jar:/home/ied/.m2/repository/org/apache/hadoop/hadoop-mapreduce-client-app/2.2.0/hadoop-mapreduce-client-app-2.2.0.jar:/home/ied/.m2/repository/org/apache/hadoop/hadoop-mapreduce-client-common/2.2.0/hadoop-mapreduce-client-common-2.2.0.jar:/home/ied/.m2/repository/org/apache/hadoop/hadoop-yarn-client/2.2.0/hadoop-yarn-client-2.2.0.jar:/home/ied/.m2/repository/com/google/inject/guice/3.0/guice-3.0.jar:/home/ied/.m2/repository/javax/inject/javax.inject/1/javax.inject-1.jar:/home/ied/.m2/repository/aopalliance/aopalliance/1.0/aopalliance-1.0.jar:/home/ied/.m2/repository/org/apache/hadoop/hadoop-yarn-server-common/2.2.0/hadoop-yarn-server-common-2.2.0.jar:/home/ied/.m2/repository/org/apache/hadoop/hadoop-mapreduce-client-shuffle/2.2.0/hadoop-mapreduce-client-shuffle-2.2.0.jar:/home/ied/.m2/repository/org/apache/hadoop/hadoop-yarn-api/2.2.0/hadoop-yarn-api-2.2.0.jar:/home/ied/.m2/repository/org/apache/hadoop/hadoop-mapreduce-client-core/2.2.0/hadoop-mapreduce-client-core-2.2.0.jar:/home/ied/.m2/repository/org/apache/hadoop/hadoop-yarn-common/2.2.0/hadoop-yarn-common-2.2.0.jar:/home/ied/.m2/repository/org/apache/hadoop/hadoop-mapreduce-client-jobclient/2.2.0/hadoop-mapreduce-client-jobclient-2.2.0.jar:/home/ied/.m2/repository/org/apache/hadoop/hadoop-annotations/2.2.0/hadoop-annotations-2.2.0.jar:/home/ied/.m2/repository/org/apache/spark/spark-launcher_2.11/2.1.1/spark-launcher_2.11-2.1.1.jar:/home/ied/.m2/repository/org/apache/spark/spark-network-common_2.11/2.1.1/spark-network-common_2.11-2.1.1.jar:/home/ied/.m2/repository/org/fusesource/leveldbjni/leveldbjni-all/1.8/leveldbjni-all-1.8.jar:/home/ied/.m2/repository/com/fasterxml/jackson/core/jackson-annotations/2.6.5/jackson-annotations-2.6.5.jar:/home/ied/.m2/repository/org/apache/spark/spark-network-shuffle_2.11/2.1.1/spark-network-shuffle_2.11-2.1.1.jar:/home/ied/.m2/repository/org/apache/spark/spark-unsafe_2.11/2.1.1/spark-unsafe_2.11-2.1.1.jar:/home/ied/.m2/repository/net/java/dev/jets3t/jets3t/0.7.1/jets3t-0.7.1.jar:/home/ied/.m2/repository/org/apache/curator/curator-recipes/2.4.0/curator-recipes-2.4.0.jar:/home/ied/.m2/repository/org/apache/curator/curator-framework/2.4.0/curator-framework-2.4.0.jar:/home/ied/.m2/repository/org/apache/curator/curator-client/2.4.0/curator-client-2.4.0.jar:/home/ied/.m2/repository/org/apache/zookeeper/zookeeper/3.4.5/zookeeper-3.4.5.jar:/home/ied/.m2/repository/com/google/guava/guava/14.0.1/guava-14.0.1.jar:/home/ied/.m2/repository/javax/servlet/javax.servlet-api/3.1.0/javax.servlet-api-3.1.0.jar:/home/ied/.m2/repository/org/apache/commons/commons-lang3/3.5/commons-lang3-3.5.jar:/home/ied/.m2/repository/org/apache/commons/commons-math3/3.4.1/commons-math3-3.4.1.jar:/home/ied/.m2/repository/com/google/code/findbugs/jsr305/1.3.9/jsr305-1.3.9.jar:/home/ied/.m2/repository/org/slf4j/slf4j-api/1.7.16/slf4j-api-1.7.16.jar:/home/ied/.m2/repository/org/slf4j/jul-to-slf4j/1.7.16/jul-to-slf4j-1.7.16.jar:/home/ied/.m2/repository/org/slf4j/jcl-over-slf4j/1.7.16/jcl-over-slf4j-1.7.16.jar:/home/ied/.m2/repository/log4j/log4j/1.2.17/log4j-1.2.17.jar:/home/ied/.m2/repository/org/slf4j/slf4j-log4j12/1.7.16/slf4j-log4j12-1.7.16.jar:/home/ied/.m2/repository/com/ning/compress-lzf/1.0.3/compress-lzf-1.0.3.jar:/home/ied/.m2/repository/org/xerial/snappy/snappy-java/1.1.2.6/snappy-java-1.1.2.6.jar:/home/ied/.m2/repository/net/jpountz/lz4/lz4/1.3.0/lz4-1.3.0.jar:/home/ied/.m2/repository/org/roaringbitmap/RoaringBitmap/0.5.11/RoaringBitmap-0.5.11.jar:/home/ied/.m2/repository/commons-net/commons-net/2.2/commons-net-2.2.jar:/home/ied/.m2/repository/org/scala-lang/scala-library/2.11.8/scala-library-2.11.8.jar:/home/ied/.m2/repository/org/json4s/json4s-jackson_2.11/3.2.11/json4s-jackson_2.11-3.2.11.jar:/home/ied/.m2/repository/org/json4s/json4s-core_2.11/3.2.11/json4s-core_2.11-3.2.11.jar:/home/ied/.m2/repository/org/json4s/json4s-ast_2.11/3.2.11/json4s-ast_2.11-3.2.11.jar:/home/ied/.m2/repository/org/scala-lang/scalap/2.11.0/scalap-2.11.0.jar:/home/ied/.m2/repository/org/glassfish/jersey/core/jersey-client/2.22.2/jersey-client-2.22.2.jar:/home/ied/.m2/repository/javax/ws/rs/javax.ws.rs-api/2.0.1/javax.ws.rs-api-2.0.1.jar:/home/ied/.m2/repository/org/glassfish/hk2/hk2-api/2.4.0-b34/hk2-api-2.4.0-b34.jar:/home/ied/.m2/repository/org/glassfish/hk2/hk2-utils/2.4.0-b34/hk2-utils-2.4.0-b34.jar:/home/ied/.m2/repository/org/glassfish/hk2/external/aopalliance-repackaged/2.4.0-b34/aopalliance-repackaged-2.4.0-b34.jar:/home/ied/.m2/repository/org/glassfish/hk2/external/javax.inject/2.4.0-b34/javax.inject-2.4.0-b34.jar:/home/ied/.m2/repository/org/glassfish/hk2/hk2-locator/2.4.0-b34/hk2-locator-2.4.0-b34.jar:/home/ied/.m2/repository/org/javassist/javassist/3.18.1-GA/javassist-3.18.1-GA.jar:/home/ied/.m2/repository/org/glassfish/jersey/core/jersey-common/2.22.2/jersey-common-2.22.2.jar:/home/ied/.m2/repository/javax/annotation/javax.annotation-api/1.2/javax.annotation-api-1.2.jar:/home/ied/.m2/repository/org/glassfish/jersey/bundles/repackaged/jersey-guava/2.22.2/jersey-guava-2.22.2.jar:/home/ied/.m2/repository/org/glassfish/hk2/osgi-resource-locator/1.0.1/osgi-resource-locator-1.0.1.jar:/home/ied/.m2/repository/org/glassfish/jersey/core/jersey-server/2.22.2/jersey-server-2.22.2.jar:/home/ied/.m2/repository/org/glassfish/jersey/media/jersey-media-jaxb/2.22.2/jersey-media-jaxb-2.22.2.jar:/home/ied/.m2/repository/javax/validation/validation-api/1.1.0.Final/validation-api-1.1.0.Final.jar:/home/ied/.m2/repository/org/glassfish/jersey/containers/jersey-container-servlet/2.22.2/jersey-container-servlet-2.22.2.jar:/home/ied/.m2/repository/org/glassfish/jersey/containers/jersey-container-servlet-core/2.22.2/jersey-container-servlet-core-2.22.2.jar:/home/ied/.m2/repository/io/netty/netty-all/4.0.42.Final/netty-all-4.0.42.Final.jar:/home/ied/.m2/repository/io/netty/netty/3.8.0.Final/netty-3.8.0.Final.jar:/home/ied/.m2/repository/com/clearspring/analytics/stream/2.7.0/stream-2.7.0.jar:/home/ied/.m2/repository/io/dropwizard/metrics/metrics-core/3.1.2/metrics-core-3.1.2.jar:/home/ied/.m2/repository/io/dropwizard/metrics/metrics-jvm/3.1.2/metrics-jvm-3.1.2.jar:/home/ied/.m2/repository/io/dropwizard/metrics/metrics-json/3.1.2/metrics-json-3.1.2.jar:/home/ied/.m2/repository/io/dropwizard/metrics/metrics-graphite/3.1.2/metrics-graphite-3.1.2.jar:/home/ied/.m2/repository/com/fasterxml/jackson/core/jackson-databind/2.6.5/jackson-databind-2.6.5.jar:/home/ied/.m2/repository/com/fasterxml/jackson/core/jackson-core/2.6.5/jackson-core-2.6.5.jar:/home/ied/.m2/repository/com/fasterxml/jackson/module/jackson-module-scala_2.11/2.6.5/jackson-module-scala_2.11-2.6.5.jar:/home/ied/.m2/repository/com/fasterxml/jackson/module/jackson-module-paranamer/2.6.5/jackson-module-paranamer-2.6.5.jar:/home/ied/.m2/repository/org/apache/ivy/ivy/2.4.0/ivy-2.4.0.jar:/home/ied/.m2/repository/oro/oro/2.0.8/oro-2.0.8.jar:/home/ied/.m2/repository/net/razorvine/pyrolite/4.13/pyrolite-4.13.jar:/home/ied/.m2/repository/net/sf/py4j/py4j/0.10.4/py4j-0.10.4.jar:/home/ied/.m2/repository/org/apache/spark/spark-tags_2.11/2.1.1/spark-tags_2.11-2.1.1.jar:/home/ied/.m2/repository/org/apache/commons/commons-crypto/1.0.0/commons-crypto-1.0.0.jar:/home/ied/.m2/repository/org/spark-project/spark/unused/1.0.0/unused-1.0.0.jar:/home/ied/.m2/repository/org/apache/spark/spark-sql_2.11/2.1.1/spark-sql_2.11-2.1.1.jar:/home/ied/.m2/repository/com/univocity/univocity-parsers/2.2.1/univocity-parsers-2.2.1.jar:/home/ied/.m2/repository/org/apache/spark/spark-sketch_2.11/2.1.1/spark-sketch_2.11-2.1.1.jar:/home/ied/.m2/repository/org/apache/spark/spark-catalyst_2.11/2.1.1/spark-catalyst_2.11-2.1.1.jar:/home/ied/.m2/repository/org/codehaus/janino/janino/3.0.0/janino-3.0.0.jar:/home/ied/.m2/repository/org/codehaus/janino/commons-compiler/3.0.0/commons-compiler-3.0.0.jar:/home/ied/.m2/repository/org/antlr/antlr4-runtime/4.5.3/antlr4-runtime-4.5.3.jar:/home/ied/.m2/repository/org/apache/parquet/parquet-column/1.8.1/parquet-column-1.8.1.jar:/home/ied/.m2/repository/org/apache/parquet/parquet-common/1.8.1/parquet-common-1.8.1.jar:/home/ied/.m2/repository/org/apache/parquet/parquet-encoding/1.8.1/parquet-encoding-1.8.1.jar:/home/ied/.m2/repository/org/apache/parquet/parquet-hadoop/1.8.1/parquet-hadoop-1.8.1.jar:/home/ied/.m2/repository/org/apache/parquet/parquet-format/2.3.0-incubating/parquet-format-2.3.0-incubating.jar:/home/ied/.m2/repository/org/apache/parquet/parquet-jackson/1.8.1/parquet-jackson-1.8.1.jar:/home/ied/.m2/repository/org/apache/spark/spark-hive_2.11/2.1.1/spark-hive_2.11-2.1.1.jar:/home/ied/.m2/repository/com/twitter/parquet-hadoop-bundle/1.6.0/parquet-hadoop-bundle-1.6.0.jar:/home/ied/.m2/repository/org/spark-project/hive/hive-exec/1.2.1.spark2/hive-exec-1.2.1.spark2.jar:/home/ied/.m2/repository/commons-io/commons-io/2.4/commons-io-2.4.jar:/home/ied/.m2/repository/commons-lang/commons-lang/2.6/commons-lang-2.6.jar:/home/ied/.m2/repository/javolution/javolution/5.5.1/javolution-5.5.1.jar:/home/ied/.m2/repository/log4j/apache-log4j-extras/1.2.17/apache-log4j-extras-1.2.17.jar:/home/ied/.m2/repository/org/antlr/antlr-runtime/3.4/antlr-runtime-3.4.jar:/home/ied/.m2/repository/org/antlr/stringtemplate/3.2.1/stringtemplate-3.2.1.jar:/home/ied/.m2/repository/antlr/antlr/2.7.7/antlr-2.7.7.jar:/home/ied/.m2/repository/org/antlr/ST4/4.0.4/ST4-4.0.4.jar:/home/ied/.m2/repository/org/apache/commons/commons-compress/1.4.1/commons-compress-1.4.1.jar:/home/ied/.m2/repository/org/tukaani/xz/1.0/xz-1.0.jar:/home/ied/.m2/repository/com/googlecode/javaewah/JavaEWAH/0.3.2/JavaEWAH-0.3.2.jar:/home/ied/.m2/repository/org/iq80/snappy/snappy/0.2/snappy-0.2.jar:/home/ied/.m2/repository/stax/stax-api/1.0.1/stax-api-1.0.1.jar:/home/ied/.m2/repository/net/sf/opencsv/opencsv/2.3/opencsv-2.3.jar:/home/ied/.m2/repository/org/spark-project/hive/hive-metastore/1.2.1.spark2/hive-metastore-1.2.1.spark2.jar:/home/ied/.m2/repository/com/jolbox/bonecp/0.8.0.RELEASE/bonecp-0.8.0.RELEASE.jar:/home/ied/.m2/repository/commons-cli/commons-cli/1.2/commons-cli-1.2.jar:/home/ied/.m2/repository/commons-logging/commons-logging/1.1.3/commons-logging-1.1.3.jar:/home/ied/.m2/repository/org/apache/derby/derby/10.10.2.0/derby-10.10.2.0.jar:/home/ied/.m2/repository/org/datanucleus/datanucleus-api-jdo/3.2.6/datanucleus-api-jdo-3.2.6.jar:/home/ied/.m2/repository/org/datanucleus/datanucleus-rdbms/3.2.9/datanucleus-rdbms-3.2.9.jar:/home/ied/.m2/repository/commons-pool/commons-pool/1.5.4/commons-pool-1.5.4.jar:/home/ied/.m2/repository/commons-dbcp/commons-dbcp/1.4/commons-dbcp-1.4.jar:/home/ied/.m2/repository/javax/jdo/jdo-api/3.0.1/jdo-api-3.0.1.jar:/home/ied/.m2/repository/javax/transaction/jta/1.1/jta-1.1.jar:/home/ied/.m2/repository/org/apache/avro/avro/1.7.7/avro-1.7.7.jar:/home/ied/.m2/repository/com/thoughtworks/paranamer/paranamer/2.3/paranamer-2.3.jar:/home/ied/.m2/repository/commons-httpclient/commons-httpclient/3.1/commons-httpclient-3.1.jar:/home/ied/.m2/repository/org/apache/calcite/calcite-avatica/1.2.0-incubating/calcite-avatica-1.2.0-incubating.jar:/home/ied/.m2/repository/org/apache/calcite/calcite-core/1.2.0-incubating/calcite-core-1.2.0-incubating.jar:/home/ied/.m2/repository/org/apache/calcite/calcite-linq4j/1.2.0-incubating/calcite-linq4j-1.2.0-incubating.jar:/home/ied/.m2/repository/net/hydromatic/eigenbase-properties/1.1.5/eigenbase-properties-1.1.5.jar:/home/ied/.m2/repository/org/apache/httpcomponents/httpclient/4.5.2/httpclient-4.5.2.jar:/home/ied/.m2/repository/org/apache/httpcomponents/httpcore/4.4.4/httpcore-4.4.4.jar:/home/ied/.m2/repository/org/codehaus/jackson/jackson-mapper-asl/1.9.13/jackson-mapper-asl-1.9.13.jar:/home/ied/.m2/repository/commons-codec/commons-codec/1.10/commons-codec-1.10.jar:/home/ied/.m2/repository/joda-time/joda-time/2.9.3/joda-time-2.9.3.jar:/home/ied/.m2/repository/org/jodd/jodd-core/3.5.2/jodd-core-3.5.2.jar:/home/ied/.m2/repository/org/datanucleus/datanucleus-core/3.2.10/datanucleus-core-3.2.10.jar:/home/ied/.m2/repository/org/apache/thrift/libthrift/0.9.3/libthrift-0.9.3.jar:/home/ied/.m2/repository/org/apache/thrift/libfb303/0.9.3/libfb303-0.9.3.jar:/home/ied/.m2/repository/mysql/mysql-connector-java/5.1.38/mysql-connector-java-5.1.38.jar:/home/ied/.m2/repository/org/apache/flink/flink-scala_2.11/1.10.2/flink-scala_2.11-1.10.2.jar:/home/ied/.m2/repository/org/apache/flink/flink-core/1.10.2/flink-core-1.10.2.jar:/home/ied/.m2/repository/org/apache/flink/flink-annotations/1.10.2/flink-annotations-1.10.2.jar:/home/ied/.m2/repository/org/apache/flink/flink-metrics-core/1.10.2/flink-metrics-core-1.10.2.jar:/home/ied/.m2/repository/com/esotericsoftware/kryo/kryo/2.24.0/kryo-2.24.0.jar:/home/ied/.m2/repository/com/esotericsoftware/minlog/minlog/1.2/minlog-1.2.jar:/home/ied/.m2/repository/commons-collections/commons-collections/3.2.2/commons-collections-3.2.2.jar:/home/ied/.m2/repository/org/apache/flink/flink-shaded-guava/18.0-9.0/flink-shaded-guava-18.0-9.0.jar:/home/ied/.m2/repository/org/apache/flink/flink-java/1.10.2/flink-java-1.10.2.jar:/home/ied/.m2/repository/org/apache/flink/flink-shaded-asm-7/7.1-9.0/flink-shaded-asm-7-7.1-9.0.jar:/home/ied/.m2/repository/org/scala-lang/scala-reflect/2.11.12/scala-reflect-2.11.12.jar:/home/ied/.m2/repository/org/scala-lang/scala-compiler/2.11.12/scala-compiler-2.11.12.jar:/home/ied/.m2/repository/org/scala-lang/modules/scala-xml_2.11/1.0.5/scala-xml_2.11-1.0.5.jar:/home/ied/.m2/repository/org/scala-lang/modules/scala-parser-combinators_2.11/1.0.4/scala-parser-combinators_2.11-1.0.4.jar:/home/ied/.m2/repository/org/apache/flink/force-shading/1.10.2/force-shading-1.10.2.jar:/home/ied/.m2/repository/org/apache/flink/flink-streaming-scala_2.11/1.10.2/flink-streaming-scala_2.11-1.10.2.jar:/home/ied/.m2/repository/org/apache/flink/flink-streaming-java_2.11/1.10.2/flink-streaming-java_2.11-1.10.2.jar:/home/ied/.m2/repository/org/apache/flink/flink-runtime_2.11/1.10.2/flink-runtime_2.11-1.10.2.jar:/home/ied/.m2/repository/org/apache/flink/flink-queryable-state-client-java/1.10.2/flink-queryable-state-client-java-1.10.2.jar:/home/ied/.m2/repository/org/apache/flink/flink-hadoop-fs/1.10.2/flink-hadoop-fs-1.10.2.jar:/home/ied/.m2/repository/org/apache/flink/flink-shaded-netty/4.1.39.Final-9.0/flink-shaded-netty-4.1.39.Final-9.0.jar:/home/ied/.m2/repository/org/apache/flink/flink-shaded-jackson/2.10.1-9.0/flink-shaded-jackson-2.10.1-9.0.jar:/home/ied/.m2/repository/com/typesafe/akka/akka-actor_2.11/2.5.21/akka-actor_2.11-2.5.21.jar:/home/ied/.m2/repository/com/typesafe/config/1.3.3/config-1.3.3.jar:/home/ied/.m2/repository/org/scala-lang/modules/scala-java8-compat_2.11/0.7.0/scala-java8-compat_2.11-0.7.0.jar:/home/ied/.m2/repository/com/typesafe/akka/akka-stream_2.11/2.5.21/akka-stream_2.11-2.5.21.jar:/home/ied/.m2/repository/org/reactivestreams/reactive-streams/1.0.2/reactive-streams-1.0.2.jar:/home/ied/.m2/repository/com/typesafe/ssl-config-core_2.11/0.3.7/ssl-config-core_2.11-0.3.7.jar:/home/ied/.m2/repository/com/typesafe/akka/akka-protobuf_2.11/2.5.21/akka-protobuf_2.11-2.5.21.jar:/home/ied/.m2/repository/com/typesafe/akka/akka-slf4j_2.11/2.5.21/akka-slf4j_2.11-2.5.21.jar:/home/ied/.m2/repository/org/clapper/grizzled-slf4j_2.11/1.3.2/grizzled-slf4j_2.11-1.3.2.jar:/home/ied/.m2/repository/com/github/scopt/scopt_2.11/3.5.0/scopt_2.11-3.5.0.jar:/home/ied/.m2/repository/org/lz4/lz4-java/1.5.0/lz4-java-1.5.0.jar:/home/ied/.m2/repository/org/apache/flink/flink-clients_2.11/1.10.2/flink-clients_2.11-1.10.2.jar:/home/ied/.m2/repository/org/apache/flink/flink-optimizer_2.11/1.10.2/flink-optimizer_2.11-1.10.2.jar:/home/ied/.m2/repository/org/apache/flink/flink-connector-kafka-0.11_2.11/1.10.2/flink-connector-kafka-0.11_2.11-1.10.2.jar:/home/ied/.m2/repository/org/apache/flink/flink-connector-kafka-0.10_2.11/1.10.2/flink-connector-kafka-0.10_2.11-1.10.2.jar:/home/ied/.m2/repository/org/apache/flink/flink-connector-kafka-0.9_2.11/1.10.2/flink-connector-kafka-0.9_2.11-1.10.2.jar:/home/ied/.m2/repository/org/apache/flink/flink-connector-kafka-base_2.11/1.10.2/flink-connector-kafka-base_2.11-1.10.2.jar:/home/ied/.m2/repository/org/apache/kafka/kafka-clients/0.11.0.2/kafka-clients-0.11.0.2.jar:/home/ied/.m2/repository/junit/junit/4.13.2/junit-4.13.2.jar:/home/ied/.m2/repository/org/hamcrest/hamcrest-core/1.3/hamcrest-core-1.3.jar com.intellij.rt.junit.JUnitStarter -ideVersion5 -junit4 ActionOp,take
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
22/03/28 20:11:02 INFO SparkContext: Running Spark version 2.1.1
22/03/28 20:11:02 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
22/03/28 20:11:02 INFO SecurityManager: Changing view acls to: ied
22/03/28 20:11:02 INFO SecurityManager: Changing modify acls to: ied
22/03/28 20:11:02 INFO SecurityManager: Changing view acls groups to:
22/03/28 20:11:02 INFO SecurityManager: Changing modify acls groups to:
22/03/28 20:11:02 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(ied); groups with view permissions: Set(); users with modify permissions: Set(ied); groups with modify permissions: Set()
22/03/28 20:11:03 INFO Utils: Successfully started service 'sparkDriver' on port 37947.
22/03/28 20:11:03 INFO SparkEnv: Registering MapOutputTracker
22/03/28 20:11:03 INFO SparkEnv: Registering BlockManagerMaster
22/03/28 20:11:03 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
22/03/28 20:11:03 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
22/03/28 20:11:03 INFO DiskBlockManager: Created local directory at /tmp/blockmgr-eec65e0b-a8aa-46d3-86c7-9d8f56afd5eb
22/03/28 20:11:03 INFO MemoryStore: MemoryStore started with capacity 612.6 MB
22/03/28 20:11:03 INFO SparkEnv: Registering OutputCommitCoordinator
22/03/28 20:11:03 INFO Utils: Successfully started service 'SparkUI' on port 4040.
22/03/28 20:11:03 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://192.168.177.166:4040
22/03/28 20:11:03 INFO Executor: Starting executor ID driver on host localhost
22/03/28 20:11:03 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 39689.
22/03/28 20:11:03 INFO NettyBlockTransferService: Server created on 192.168.177.166:39689
22/03/28 20:11:03 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
22/03/28 20:11:03 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, 192.168.177.166, 39689, None)22/03/28 20:11:03 INFO BlockManagerMasterEndpoint: Registering block manager 192.168.177.166:39689 with 612.6 MB RAM, BlockManagerId(driver, 192.168.177.166, 39689, None)22/03/28 20:11:03 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, 192.168.177.166, 39689, None)22/03/28 20:11:03 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, 192.168.177.166, 39689, None)22/03/28 20:11:04 INFO SparkContext: Starting job: take at ActionOp.scala:36
22/03/28 20:11:04 INFO DAGScheduler: Got job 0(take at ActionOp.scala:36) with 1 output partitions
22/03/28 20:11:04 INFO DAGScheduler: Final stage: ResultStage 0(take at ActionOp.scala:36)22/03/28 20:11:04 INFO DAGScheduler: Parents of final stage: List()22/03/28 20:11:04 INFO DAGScheduler: Missing parents: List()22/03/28 20:11:04 INFO DAGScheduler: Submitting ResultStage 0(ParallelCollectionRDD[0] at parallelize at ActionOp.scala:35), which has no missing parents
22/03/28 20:11:04 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 1408.0 B, free612.6 MB)22/03/28 20:11:04 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 952.0 B, free612.6 MB)22/03/28 20:11:04 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 192.168.177.166:39689 (size: 952.0 B, free: 612.6 MB)22/03/28 20:11:04 INFO SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:996
22/03/28 20:11:04 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 0(ParallelCollectionRDD[0] at parallelize at ActionOp.scala:35)22/03/28 20:11:04 INFO TaskSchedulerImpl: Adding task set0.0 with 1 tasks
22/03/28 20:11:04 INFO TaskSetManager: Starting task 0.0in stage 0.0(TID 0, localhost, executor driver, partition 0, PROCESS_LOCAL, 5882 bytes)22/03/28 20:11:04 INFO Executor: Running task 0.0in stage 0.0(TID 0)22/03/28 20:11:04 INFO Executor: Finished task 0.0in stage 0.0(TID 0). 912 bytes result sent to driver
22/03/28 20:11:04 INFO TaskSetManager: Finished task 0.0in stage 0.0(TID 0)in103 ms on localhost (executor driver)(1/1)22/03/28 20:11:04 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
22/03/28 20:11:04 INFO DAGScheduler: ResultStage 0(take at ActionOp.scala:36) finished in0.117 s
22/03/28 20:11:04 INFO DAGScheduler: Job 0 finished: take at ActionOp.scala:36, took 0.293447 s
22/03/28 20:11:04 INFO SparkContext: Starting job: take at ActionOp.scala:36
22/03/28 20:11:04 INFO DAGScheduler: Got job 1(take at ActionOp.scala:36) with 3 output partitions
22/03/28 20:11:04 INFO DAGScheduler: Final stage: ResultStage 1(take at ActionOp.scala:36)22/03/28 20:11:04 INFO DAGScheduler: Parents of final stage: List()22/03/28 20:11:04 INFO DAGScheduler: Missing parents: List()22/03/28 20:11:04 INFO DAGScheduler: Submitting ResultStage 1(ParallelCollectionRDD[0] at parallelize at ActionOp.scala:35), which has no missing parents
22/03/28 20:11:04 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 1408.0 B, free612.6 MB)22/03/28 20:11:04 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 952.0 B, free612.6 MB)22/03/28 20:11:04 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 192.168.177.166:39689 (size: 952.0 B, free: 612.6 MB)22/03/28 20:11:04 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:996
22/03/28 20:11:04 INFO DAGScheduler: Submitting 3 missing tasks from ResultStage 1(ParallelCollectionRDD[0] at parallelize at ActionOp.scala:35)22/03/28 20:11:04 INFO TaskSchedulerImpl: Adding task set1.0 with 3 tasks
22/03/28 20:11:04 INFO TaskSetManager: Starting task 0.0in stage 1.0(TID 1, localhost, executor driver, partition 1, PROCESS_LOCAL, 5882 bytes)22/03/28 20:11:04 INFO TaskSetManager: Starting task 1.0in stage 1.0(TID 2, localhost, executor driver, partition 2, PROCESS_LOCAL, 5882 bytes)22/03/28 20:11:04 INFO TaskSetManager: Starting task 2.0in stage 1.0(TID 3, localhost, executor driver, partition 3, PROCESS_LOCAL, 5882 bytes)22/03/28 20:11:04 INFO Executor: Running task 0.0in stage 1.0(TID 1)22/03/28 20:11:04 INFO Executor: Running task 1.0in stage 1.0(TID 2)22/03/28 20:11:04 INFO Executor: Finished task 0.0in stage 1.0(TID 1). 833 bytes result sent to driver
22/03/28 20:11:04 INFO Executor: Running task 2.0in stage 1.0(TID 3)22/03/28 20:11:04 INFO Executor: Finished task 1.0in stage 1.0(TID 2). 920 bytes result sent to driver
22/03/28 20:11:04 INFO TaskSetManager: Finished task 0.0in stage 1.0(TID 1)in21 ms on localhost (executor driver)(1/3)22/03/28 20:11:04 INFO TaskSetManager: Finished task 1.0in stage 1.0(TID 2)in21 ms on localhost (executor driver)(2/3)22/03/28 20:11:04 INFO Executor: Finished task 2.0in stage 1.0(TID 3). 912 bytes result sent to driver
22/03/28 20:11:04 INFO TaskSetManager: Finished task 2.0in stage 1.0(TID 3)in22 ms on localhost (executor driver)(3/3)22/03/28 20:11:04 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
22/03/28 20:11:04 INFO DAGScheduler: ResultStage 1(take at ActionOp.scala:36) finished in0.026 s
22/03/28 20:11:04 INFO DAGScheduler: Job 1 finished: take at ActionOp.scala:36, took 0.035426 s
12322/03/28 20:11:04 INFO SparkContext: Starting job: first at ActionOp.scala:37
22/03/28 20:11:04 INFO DAGScheduler: Got job 2(first at ActionOp.scala:37) with 1 output partitions
22/03/28 20:11:04 INFO DAGScheduler: Final stage: ResultStage 2(first at ActionOp.scala:37)22/03/28 20:11:04 INFO DAGScheduler: Parents of final stage: List()22/03/28 20:11:04 INFO DAGScheduler: Missing parents: List()22/03/28 20:11:04 INFO DAGScheduler: Submitting ResultStage 2(ParallelCollectionRDD[0] at parallelize at ActionOp.scala:35), which has no missing parents
22/03/28 20:11:04 INFO MemoryStore: Block broadcast_2 stored as values in memory (estimated size 1408.0 B, free612.6 MB)22/03/28 20:11:04 INFO MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 952.0 B, free612.6 MB)22/03/28 20:11:04 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on 192.168.177.166:39689 (size: 952.0 B, free: 612.6 MB)22/03/28 20:11:04 INFO SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:996
22/03/28 20:11:04 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 2(ParallelCollectionRDD[0] at parallelize at ActionOp.scala:35)22/03/28 20:11:04 INFO TaskSchedulerImpl: Adding task set2.0 with 1 tasks
22/03/28 20:11:04 INFO TaskSetManager: Starting task 0.0in stage 2.0(TID 4, localhost, executor driver, partition 0, PROCESS_LOCAL, 5883 bytes)22/03/28 20:11:04 INFO Executor: Running task 0.0in stage 2.0(TID 4)22/03/28 20:11:04 INFO Executor: Finished task 0.0in stage 2.0(TID 4). 912 bytes result sent to driver
22/03/28 20:11:04 INFO TaskSetManager: Finished task 0.0in stage 2.0(TID 4)in14 ms on localhost (executor driver)(1/1)22/03/28 20:11:04 INFO TaskSchedulerImpl: Removed TaskSet 2.0, whose tasks have all completed, from pool
22/03/28 20:11:04 INFO DAGScheduler: ResultStage 2(first at ActionOp.scala:37) finished in0.016 s
22/03/28 20:11:04 INFO DAGScheduler: Job 2 finished: first at ActionOp.scala:37, took 0.024304 s
122/03/28 20:11:04 INFO SparkContext: Starting job: takeSample at ActionOp.scala:38
22/03/28 20:11:04 INFO DAGScheduler: Got job 3(takeSample at ActionOp.scala:38) with 6 output partitions
22/03/28 20:11:04 INFO DAGScheduler: Final stage: ResultStage 3(takeSample at ActionOp.scala:38)22/03/28 20:11:04 INFO DAGScheduler: Parents of final stage: List()22/03/28 20:11:04 INFO DAGScheduler: Missing parents: List()22/03/28 20:11:04 INFO DAGScheduler: Submitting ResultStage 3(ParallelCollectionRDD[0] at parallelize at ActionOp.scala:35), which has no missing parents
22/03/28 20:11:04 INFO MemoryStore: Block broadcast_3 stored as values in memory (estimated size 1216.0 B, free612.6 MB)22/03/28 20:11:04 INFO MemoryStore: Block broadcast_3_piece0 stored as bytes in memory (estimated size 879.0 B, free612.6 MB)22/03/28 20:11:04 INFO BlockManagerInfo: Added broadcast_3_piece0 in memory on 192.168.177.166:39689 (size: 879.0 B, free: 612.6 MB)22/03/28 20:11:04 INFO SparkContext: Created broadcast 3 from broadcast at DAGScheduler.scala:996
22/03/28 20:11:04 INFO DAGScheduler: Submitting 6 missing tasks from ResultStage 3(ParallelCollectionRDD[0] at parallelize at ActionOp.scala:35)22/03/28 20:11:04 INFO TaskSchedulerImpl: Adding task set3.0 with 6 tasks
22/03/28 20:11:04 INFO TaskSetManager: Starting task 0.0in stage 3.0(TID 5, localhost, executor driver, partition 0, PROCESS_LOCAL, 5888 bytes)22/03/28 20:11:04 INFO TaskSetManager: Starting task 1.0in stage 3.0(TID 6, localhost, executor driver, partition 1, PROCESS_LOCAL, 5888 bytes)22/03/28 20:11:04 INFO TaskSetManager: Starting task 2.0in stage 3.0(TID 7, localhost, executor driver, partition 2, PROCESS_LOCAL, 5888 bytes)22/03/28 20:11:04 INFO TaskSetManager: Starting task 3.0in stage 3.0(TID 8, localhost, executor driver, partition 3, PROCESS_LOCAL, 5888 bytes)22/03/28 20:11:04 INFO TaskSetManager: Starting task 4.0in stage 3.0(TID 9, localhost, executor driver, partition 4, PROCESS_LOCAL, 5888 bytes)22/03/28 20:11:04 INFO TaskSetManager: Starting task 5.0in stage 3.0(TID 10, localhost, executor driver, partition 5, PROCESS_LOCAL, 5888 bytes)22/03/28 20:11:04 INFO Executor: Running task 1.0in stage 3.0(TID 6)22/03/28 20:11:04 INFO Executor: Finished task 1.0in stage 3.0(TID 6). 963 bytes result sent to driver
22/03/28 20:11:04 INFO Executor: Running task 2.0in stage 3.0(TID 7)22/03/28 20:11:04 INFO Executor: Running task 0.0in stage 3.0(TID 5)22/03/28 20:11:04 INFO Executor: Finished task 2.0in stage 3.0(TID 7). 963 bytes result sent to driver
22/03/28 20:11:04 INFO Executor: Finished task 0.0in stage 3.0(TID 5). 884 bytes result sent to driver
22/03/28 20:11:04 INFO Executor: Running task 4.0in stage 3.0(TID 9)22/03/28 20:11:04 INFO Executor: Running task 5.0in stage 3.0(TID 10)22/03/28 20:11:04 INFO TaskSetManager: Finished task 1.0in stage 3.0(TID 6)in18 ms on localhost (executor driver)(1/6)22/03/28 20:11:04 INFO TaskSetManager: Finished task 2.0in stage 3.0(TID 7)in18 ms on localhost (executor driver)(2/6)22/03/28 20:11:04 INFO TaskSetManager: Finished task 0.0in stage 3.0(TID 5)in23 ms on localhost (executor driver)(3/6)22/03/28 20:11:04 INFO Executor: Finished task 4.0in stage 3.0(TID 9). 963 bytes result sent to driver
22/03/28 20:11:04 INFO Executor: Finished task 5.0in stage 3.0(TID 10). 963 bytes result sent to driver
22/03/28 20:11:04 INFO TaskSetManager: Finished task 4.0in stage 3.0(TID 9)in21 ms on localhost (executor driver)(4/6)22/03/28 20:11:04 INFO Executor: Running task 3.0in stage 3.0(TID 8)22/03/28 20:11:04 INFO TaskSetManager: Finished task 5.0in stage 3.0(TID 10)in20 ms on localhost (executor driver)(5/6)22/03/28 20:11:04 INFO Executor: Finished task 3.0in stage 3.0(TID 8). 971 bytes result sent to driver
22/03/28 20:11:04 INFO TaskSetManager: Finished task 3.0in stage 3.0(TID 8)in34 ms on localhost (executor driver)(6/6)22/03/28 20:11:04 INFO TaskSchedulerImpl: Removed TaskSet 3.0, whose tasks have all completed, from pool
22/03/28 20:11:04 INFO DAGScheduler: ResultStage 3(takeSample at ActionOp.scala:38) finished in0.037 s
22/03/28 20:11:04 INFO DAGScheduler: Job 3 finished: takeSample at ActionOp.scala:38, took 0.045685 s
22/03/28 20:11:04 INFO SparkContext: Starting job: takeSample at ActionOp.scala:38
22/03/28 20:11:04 INFO DAGScheduler: Got job 4(takeSample at ActionOp.scala:38) with 6 output partitions
22/03/28 20:11:04 INFO DAGScheduler: Final stage: ResultStage 4(takeSample at ActionOp.scala:38)22/03/28 20:11:04 INFO DAGScheduler: Parents of final stage: List()22/03/28 20:11:04 INFO DAGScheduler: Missing parents: List()22/03/28 20:11:04 INFO DAGScheduler: Submitting ResultStage 4(PartitionwiseSampledRDD[1] at takeSample at ActionOp.scala:38), which has no missing parents
22/03/28 20:11:04 INFO MemoryStore: Block broadcast_4 stored as values in memory (estimated size 2.1 KB, free612.6 MB)22/03/28 20:11:04 INFO MemoryStore: Block broadcast_4_piece0 stored as bytes in memory (estimated size 1368.0 B, free612.6 MB)22/03/28 20:11:04 INFO BlockManagerInfo: Added broadcast_4_piece0 in memory on 192.168.177.166:39689 (size: 1368.0 B, free: 612.6 MB)22/03/28 20:11:04 INFO SparkContext: Created broadcast 4 from broadcast at DAGScheduler.scala:996
22/03/28 20:11:04 INFO DAGScheduler: Submitting 6 missing tasks from ResultStage 4(PartitionwiseSampledRDD[1] at takeSample at ActionOp.scala:38)22/03/28 20:11:04 INFO TaskSchedulerImpl: Adding task set4.0 with 6 tasks
22/03/28 20:11:04 INFO TaskSetManager: Starting task 0.0in stage 4.0(TID 11, localhost, executor driver, partition 0, PROCESS_LOCAL, 5997 bytes)22/03/28 20:11:04 INFO TaskSetManager: Starting task 1.0in stage 4.0(TID 12, localhost, executor driver, partition 1, PROCESS_LOCAL, 5997 bytes)22/03/28 20:11:04 INFO TaskSetManager: Starting task 2.0in stage 4.0(TID 13, localhost, executor driver, partition 2, PROCESS_LOCAL, 5997 bytes)22/03/28 20:11:04 INFO TaskSetManager: Starting task 3.0in stage 4.0(TID 14, localhost, executor driver, partition 3, PROCESS_LOCAL, 5997 bytes)22/03/28 20:11:04 INFO TaskSetManager: Starting task 4.0in stage 4.0(TID 15, localhost, executor driver, partition 4, PROCESS_LOCAL, 5997 bytes)22/03/28 20:11:04 INFO TaskSetManager: Starting task 5.0in stage 4.0(TID 16, localhost, executor driver, partition 5, PROCESS_LOCAL, 5997 bytes)22/03/28 20:11:04 INFO Executor: Running task 1.0in stage 4.0(TID 12)22/03/28 20:11:04 INFO Executor: Running task 0.0in stage 4.0(TID 11)22/03/28 20:11:04 INFO Executor: Finished task 1.0in stage 4.0(TID 12). 912 bytes result sent to driver
22/03/28 20:11:04 INFO Executor: Running task 3.0in stage 4.0(TID 14)22/03/28 20:11:04 INFO Executor: Finished task 3.0in stage 4.0(TID 14). 833 bytes result sent to driver
22/03/28 20:11:04 INFO Executor: Finished task 0.0in stage 4.0(TID 11). 912 bytes result sent to driver
22/03/28 20:11:04 INFO Executor: Running task 5.0in stage 4.0(TID 16)22/03/28 20:11:04 INFO TaskSetManager: Finished task 1.0in stage 4.0(TID 12)in12 ms on localhost (executor driver)(1/6)22/03/28 20:11:04 INFO Executor: Running task 4.0in stage 4.0(TID 15)22/03/28 20:11:04 INFO TaskSetManager: Finished task 3.0in stage 4.0(TID 14)in20 ms on localhost (executor driver)(2/6)22/03/28 20:11:04 INFO TaskSetManager: Finished task 0.0in stage 4.0(TID 11)in23 ms on localhost (executor driver)(3/6)22/03/28 20:11:04 INFO Executor: Running task 2.0in stage 4.0(TID 13)22/03/28 20:11:04 INFO Executor: Finished task 4.0in stage 4.0(TID 15). 912 bytes result sent to driver
22/03/28 20:11:04 INFO TaskSetManager: Finished task 4.0in stage 4.0(TID 15)in26 ms on localhost (executor driver)(4/6)22/03/28 20:11:04 INFO Executor: Finished task 2.0in stage 4.0(TID 13). 920 bytes result sent to driver
22/03/28 20:11:04 INFO TaskSetManager: Finished task 2.0in stage 4.0(TID 13)in29 ms on localhost (executor driver)(5/6)22/03/28 20:11:04 INFO Executor: Finished task 5.0in stage 4.0(TID 16). 912 bytes result sent to driver
22/03/28 20:11:04 INFO TaskSetManager: Finished task 5.0in stage 4.0(TID 16)in27 ms on localhost (executor driver)(6/6)22/03/28 20:11:04 INFO TaskSchedulerImpl: Removed TaskSet 4.0, whose tasks have all completed, from pool
22/03/28 20:11:04 INFO DAGScheduler: ResultStage 4(takeSample at ActionOp.scala:38) finished in0.036 s
22/03/28 20:11:04 INFO DAGScheduler: Job 4 finished: takeSample at ActionOp.scala:38, took 0.051696 s
31422/03/28 20:11:04 INFO SparkContext: Invoking stop() from shutdown hook
22/03/28 20:11:04 INFO SparkUI: Stopped Spark web UI at http://192.168.177.166:4040
22/03/28 20:11:04 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!22/03/28 20:11:04 INFO MemoryStore: MemoryStore cleared
22/03/28 20:11:04 INFO BlockManager: BlockManager stopped
22/03/28 20:11:04 INFO BlockManagerMaster: BlockManagerMaster stopped
22/03/28 20:11:04 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!22/03/28 20:11:04 INFO SparkContext: Successfully stopped SparkContext
22/03/28 20:11:04 INFO ShutdownHookManager: Shutdown hook called
22/03/28 20:11:04 INFO ShutdownHookManager: Deleting directory /tmp/spark-e6e06c4e-f0d0-42f3-872b-f5da8ad26a2c
Process finished with exit code 0
本文转载自: https://blog.csdn.net/m0_62491934/article/details/123806996
版权归原作者 那人独钓寒江雪. 所有, 如有侵权,请联系我们删除。
版权归原作者 那人独钓寒江雪. 所有, 如有侵权,请联系我们删除。