
文章目录
📄前言
本文是对初学 mybatis的知识总结,希望我的内容能给你带来一定的帮助。
一. Mybatis简介
✈️1. 什么是Mybatis
以下是来自 MyBatis中文网 对MyBatis的介绍:
MyBatis 是一款优秀的持久层框架,它支持自定义 SQL、存储过程以及高级映射。MyBatis 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作。MyBatis 可以通过简单的 XML 或注解来配置和映射原始类型、接口和 Java POJO(Plain Old Java Objects,普通老式 Java 对象)为数据库中的记录。
简单来说:Mybatis是一款用于日常开发中操作数据库的高级框架,它对 JDBC(传统用于访问关系型数据库的API)的操作进行了封装,使得数据库操作在Java程序变得更加简单和灵活,此外它还支持 关联查询和动态SQL等功能,极大提升了开发效率。
🚀2. 为什么使用Mybatis
为什么说 mybatis 是一款优秀的持久层框架呢?
原因其实很简单:简单,好用。我们可以回顾一下传统用于操作数据库的API——JDBC的使用步骤:
- 创建数据库连接池 DataSource
- 通过连接池 DataSource 获取数据库连接 Connection
- 编写带 ?占位符的SQL语句
- 通过Connection 和 SQL语句 创建PreparedStatement对象
- 通过PreparedStatement对象对 ?占位符逐一替换
- 执行SQL语句(查询操作或修改操作)
- 若执行查询操作,需要对返回的结果集对象(ResultSet)进行处理
- 释放资源(ResultSet,PreparedStatement和Connection等)
使用代码示例如下:
publicstaticvoidmain(String[] args)throwsSQLException{// 1. 创建 DataSourceDataSource dataSource =newMysqlDataSource();((MysqlDataSource) dataSource).setUrl("jdbc:mysql://127.0.0.1:3306/test?characterEncoding=utf8&useSSL=false");((MysqlDataSource) dataSource).setUser("root");((MysqlDataSource) dataSource).setPassword("0000");// 2. 与数据库建立连接Connection connection = dataSource.getConnection();// 3. 构造sql语句并创建 PreparedStatement 对象String sql ="select * from student";PreparedStatement statement = connection.prepareStatement(sql);// 4. 执行 sql ,接收返回的 ResultSet 对象ResultSet resultSet = statement.executeQuery();// 5. 遍历并处理结果集合,while(resultSet.next()){int id = resultSet.getInt("id");String name = resultSet.getString("name");System.out.println("id = "+ id +", name = "+ name);}// 6. 释放资源,后获取到的资源先释放
resultSet.close();
statement.close();
connection.close();}
而使用Mybatis操作数据库步骤如下:
- 在application.yml 或 application.properties 配置文件中进行数据库的参数配置(整个程序只需配置一次,等同于创建数据库连接池DataSource)
- 进行访问数据库方法的定义
- 使用 注解或XML 的方式编写SQL语句
- 使用定义的方法执行SQL语句(查询操作或修改操作)
- 若为查询操作,只需使用集合接收查询结果,无需对结果集进行处理
使用代码示例如下: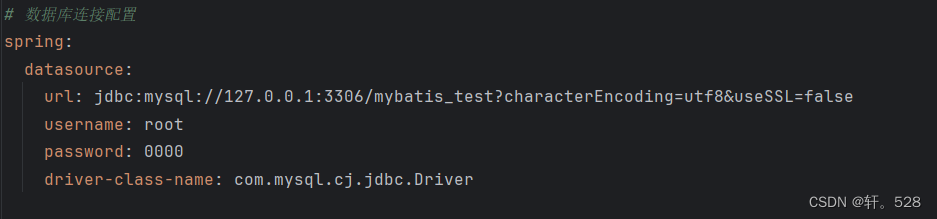
@Select("select * from userinfo where id = #{id} and username = #{name}")List<UserInfo>queryUserInfo(String name,IntegerId);
使用体验对比应该显而易见,使用Mybatis可以极大提高开发效率。
二. Mybatis快速入门
使用mybatis编写 sql 语句有 注解和XML两种方式,不管哪种方式都应该有一个接口来声明所要执行的 SQL 的方法,且一般这些持久层的代码都应放在mapper(dao)文件夹下。
在正式编写 sql 前我们需要进行一些准备工作。
🍆1. mybatis使用前准备
1.1 创建springboot项目并引入相关依赖
创建SpringBoot项目,在pom.xm文件中l引入mybatis相关依赖和mysql的驱动包(注意SpringBoot版本、JDK版本和 Mybatis相关依赖的版本要对应 )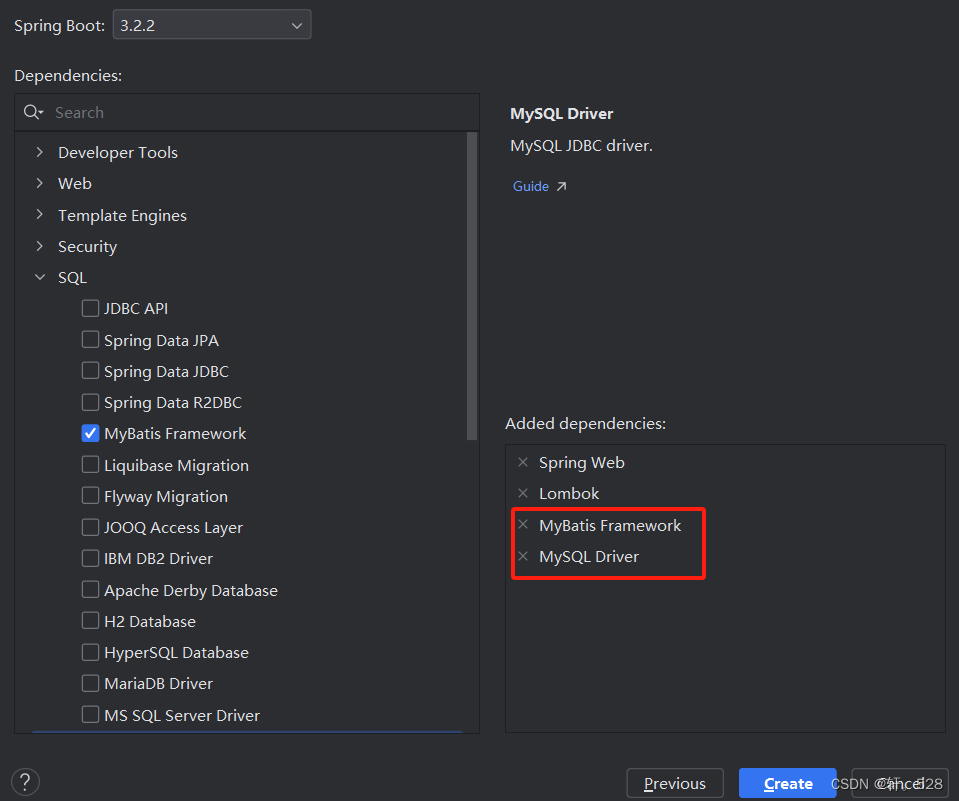
<dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>2.3.1</version></dependency><dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId><scope>runtime</scope></dependency>
1.2 在 application.ym中进行数据源的配置
注意:在 application.properties中配置同理
# 数据库连接配置spring:datasource:url: jdbc:mysql://127.0.0.1:3306/mybatis_test?characterEncoding=utf8&useSSL=falseusername: root
password: xxxxx
driver-class-name: com.mysql.cj.jdbc.Driver
1.3 创建数据表,准备表数据
CREATEtable stu(
id INTPRIMARYKEYAUTO_INCREMENT,
name VARCHAR(30)NOTNULL,
age Int,
gender VARCHAR(20),
phone VARCHAR(30)NOTNULL);
INSERTINTO stu (name, age, gender, phone )VALUES('admin',18,1,'18612340001'),('zhangsan',18,1,'18612340002'),('lisi',18,1,'18612340003'),('wangwu',18,1,'18612340004');
🍅2. 使用注解的方式编写 SQL
2.1 在mapper包下创建一个对应的 Mapper接口,并创建对应的实体类
注意:要在接口上加上@Mapper注解,这样我们编写接口才能被SpringBoot管理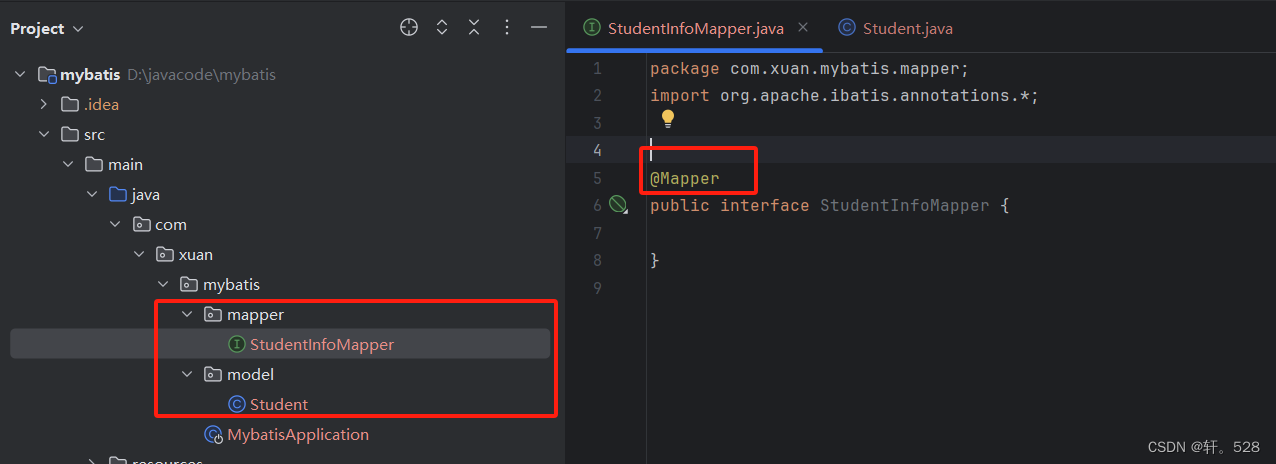
packagecom.xuan.mybatis.model;importlombok.Data;@DatapublicclassStudent{privateInteger id;privateString name;privateInteger age;privateString gender;privateString phone;}
2.2声明接口方法(参数,返回值)
注意:
- 接口的形参过多时,可以根据需要创建一个实体类,用对象作为参数
- 使用 select 从数据库查询记录时,通常使用对象或对象集合作为返回值,且对象的字段名与数据库的列名一一对应
packagecom.xuan.mybatis.mapper;importcom.xuan.mybatis.model.Student;importorg.apache.ibatis.annotations.*;importjava.util.List;@MapperpublicinterfaceStudentInfoMapper{// 查询操作List<Student>queryAllStudentInfo();// 新增操作Integerinsert(String name,Integer age,String phone);// 删除操作Integer deleteUser (String name,String phone);// 修改操作Integerupdate(Student studentInfo);}
2.3 在方法上加对应的注解并编写 sql
注意:
- @Select、@Insert、@Delete和@Update注解与 sql的增删改查的关键字作用是一样的,需在对应操作的方法上加上对应的注解
- 如需构造带参数的 SQL语句,可以使用 #{} 作为占位符,他相当于 JDBC中 PreparedStatement 的 ?占位符,程序执行时会将方法中的参数放在 { } 中,即 #{参数}。
- 使用对象作为方法参数构造的 SQL语句 同样只需使用 #{属性名} 作为参数。
packagecom.xuan.mybatis.mapper;importcom.xuan.mybatis.model.Student;importorg.apache.ibatis.annotations.*;importjava.util.List;@MapperpublicinterfaceStudentInfoMapper{// 查询操作@Select("select * from student")List<Student>queryAllStudentInfo();// 新增操作@Insert("insert into student (name, age, phone) values (#{name}, #{age}, #{phone})")Integerinsert(String name,Integer age,String phone);// 删除操作@Delete("delete from student where name = #{name} or phone = #{phone}")Integer deleteUser (String name,String phone);// 修改操作(使用对象作为参数,需提供getter方法)@Update("update student set phone = #{phone} where name = #{name}")Integerupdate(Student studentInfo);}
2.4 使用 Alt + insert 生成测试类并执行测试方法
注意:需在测试类加上 @SpringBootTest注解,并使用@Autowired 注入 StudentInfoMapper属性)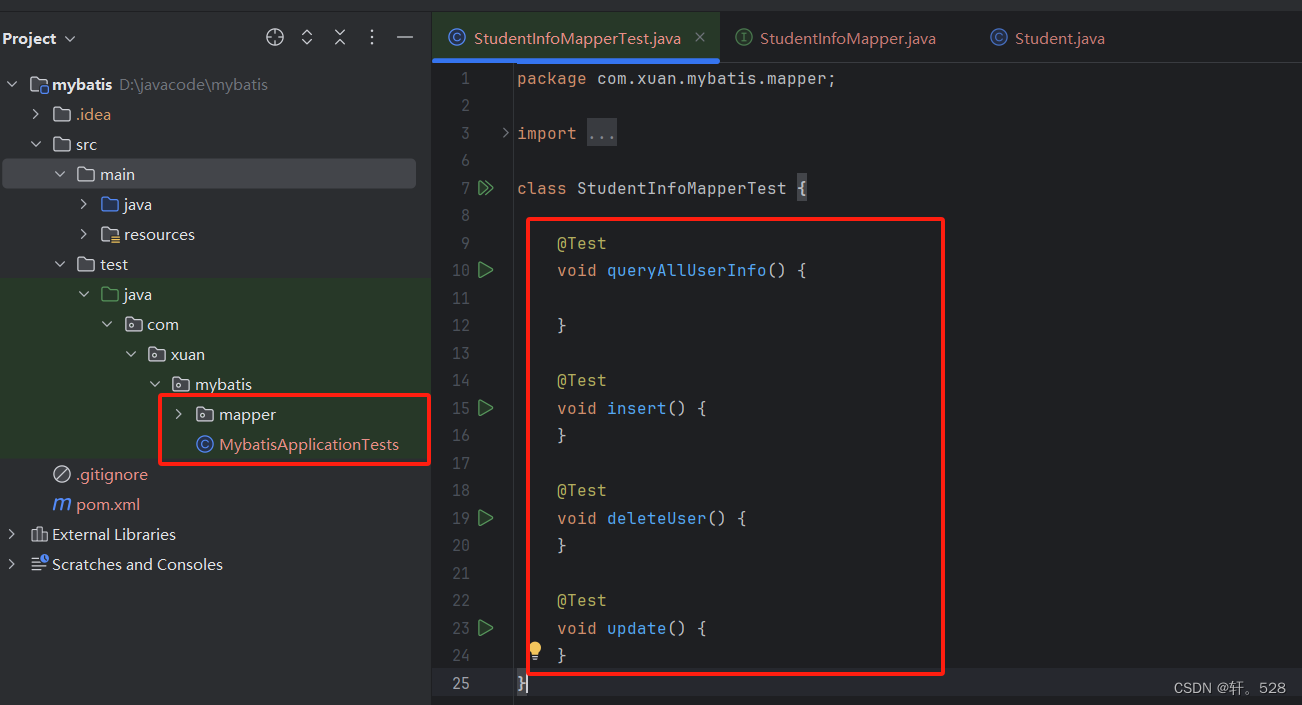
编写并执行测试代码:
packagecom.xuan.mybatis.mapper;importcom.xuan.mybatis.model.Student;importorg.junit.jupiter.api.Test;importorg.springframework.beans.factory.annotation.Autowired;importorg.springframework.boot.test.context.SpringBootTest;importstaticorg.junit.jupiter.api.Assertions.*;@SpringBootTestclassStudentInfoMapperTest{// 注入 StudentInfoMapper属性@AutowiredprivateStudentInfoMapper studentInfoMapper;@TestvoidqueryAllUserInfo(){System.out.println(studentInfoMapper.queryAllUserInfo());;}@Testvoidinsert(){
studentInfoMapper.insert("zhaoliu",16,"12345678900");}@TestvoiddeleteUser(){
studentInfoMapper.deleteUser("zhangsan","18612340002");}@Testvoidupdate(){Student student =newStudent();
student.setName("admin");
student.setPhone("00987654321");}}
执行代码前: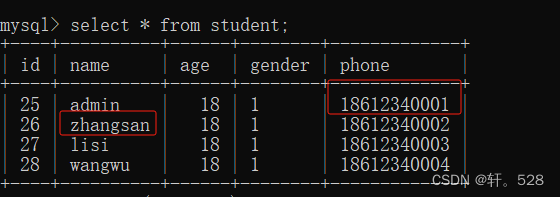
执行代码后结果如下:
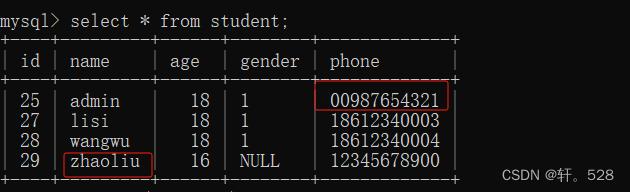
获取主键
在某些表中,我们通常设置 id 属性为表的自增主键,当我们在某次插入操作中想获取生成的 id 值该如何做呢?
答案是在方法上加上@Option注解: @Options(useGeneratedKeys = true, keyProperty = “id”)。
useGeneratedKeys = true 意思是将插入数据时自动生成的主键返回(默认值为 false);keyProperty = “id” 意思是将主键的值赋值给传入对象的 id属性。
接口和测试代码示例如下:
@Options(useGeneratedKeys =true, keyProperty ="id")@Insert("insert into student (name, age, phone) values (#{name}, #{age}, #{phone})")Integerinsert2(Student student);
@Testvoidinsert2(){Student student =newStudent();
student.setName("xiaoming");
student.setAge(15);
student.setPhone("123456");
studentInfoMapper.insert2(student);System.out.println("id: "+ student.getId());}
返回结果如下: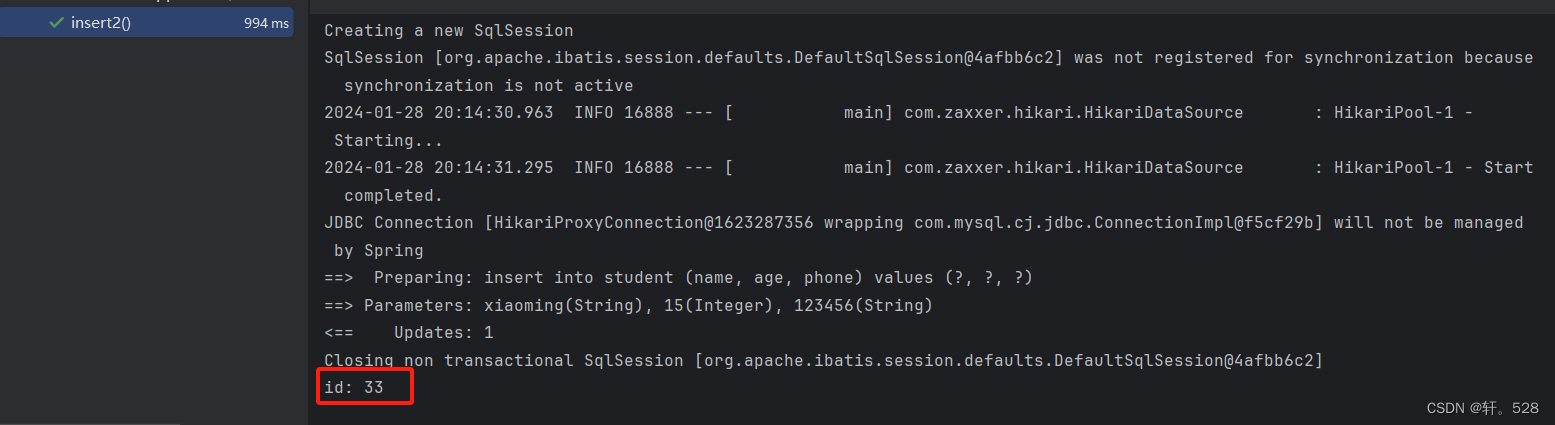
解决结果映射问题
什么是结果映射问题呢?
当数据库的表字段名与Java实体类对象的属性名不同时,通过 select查询语句 所得的结果集中,不同的字段会出现映射失败的现象,而且赋值为 null。(如下图所示)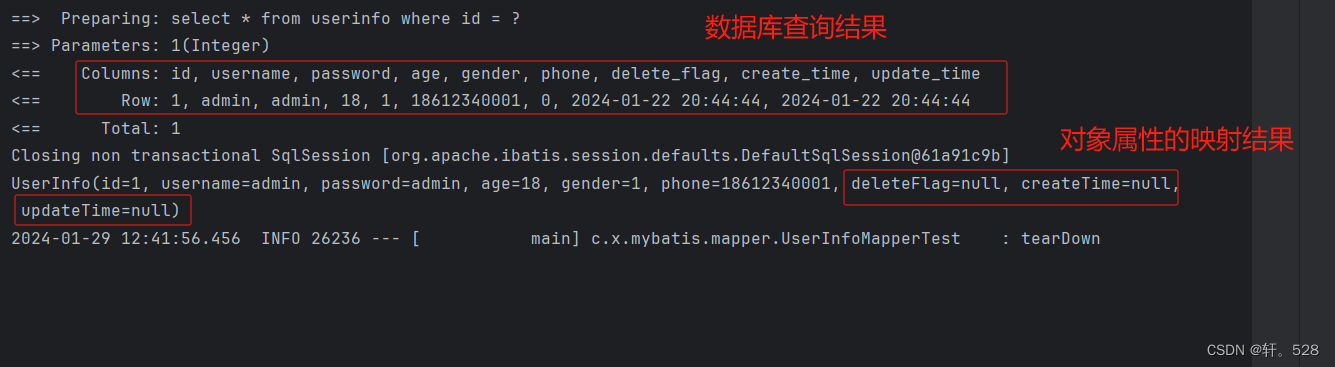
为什么会出现结果映射问题?
最直接的原因是字段名称不一致,但本质是Java中属性的命名规范(小驼峰)和 Mysql中字段的命名规范(用 _ 作为分隔符)不同。
如何解决结果映射问题呢?
- 最直接的方法是在构造 SQL语句时 使用 as 给返回结果的列起别名。(不推荐,因为每个 sql 语句都需要进行同样的操作)
- 使用注解的方式给所有需要映射字段作说明(可行,但不是最佳的方式)
- 在 application.yml 文件中进行相关配置,将两种命名方式进行自动映射(后面再介绍)
那么如何采用注解对所需字段进行映射呢?
在接口上添加@Results注解。注解的使用示例如下:
@Results(id ="BaseResult", value ={@Result(column ="delete_flag", property ="deleteFlag"),@Result(column ="create_time", property ="createTime"),@Result(column ="update_time", property ="updateTime")})
其中 value = { } 是对所有映射关系的描述。
id = “BaseResult” 中 id 的值是为该映射结果集起名,作用是其他的接口也想使用这些映射, 可以在接口上添加 @ResultMap(value = “BaseResult”) 就可完成这个映射结果集的复用。
@Result(column = “delete_flag”, property = “deleteFlag”) 是对每个对应字段映射的描述,其中 column 的值是数据库的字段名,property 的值是Java实体类的属性名。
代码与程序运行结果示例如下:
@Results(id ="BaseResult", value ={@Result(column ="delete_flag", property ="deleteFlag"),@Result(column ="create_time", property ="createTime"),@Result(column ="update_time", property ="updateTime")})@ResultMap(value ="BaseResult")@Select("select * from userinfo where id = #{id}")UserInfoqueryUserInfoById(Integer id);

🥦3. mybatis的其他配置
3.1 mybatis的日志打印
大家可以发现,在上面程序的运行结果中,打印了我们此次执行的 sql 语句的具体内容,传入的参数,sql的执行结果,影响行数等日志。
通过这些内容我们可以更加清晰地了解 sql 的执行情况,以及在程序执行出错时分析是否是 sql的书写出现了错误。
因此当我们需要这些信息时,可以在 application.yml 或 application.properties 文件中进行以下配置:
mybatis:configuration:log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
3.2 配置驼峰自动转换
若因为命名规范不同导致 数据库字段和Java实体类属性的命名不一致,且需要对这些属性进行正确映射时,可以在 application.yml 或 application.properties 文件中进行以下配置:
mybatis:configuration:map-underscore-to-camel-case:true
🍉4. 使用XML的方式编写 SQL
4.1 在mapper包下创建一个对应的 Mapper接口,并创建对应的实体类
4.2 声明接口方法(参数,返回值)
packagecom.xuan.mybatis.mapper;importcom.xuan.mybatis.model.Student;importorg.apache.ibatis.annotations.*;importjava.util.List;@MapperpublicinterfaceStudentInfoXmlMapper{// 查询操作List<Student>queryAllStudentInfo();// 新增操作Integerinsert(String name,Integer age,String phone);// 删除操作Integer deleteUser (String name,String phone);// 修改操作Integerupdate(Student studentInfo);}
4.3 创建 xml和yml 文件进行映射配置并编写 sql
首先我们需要在resource目录下创建一个 mapper文件夹,将创建的 xml 文件放在该文件夹下,并进行以下映射配置。
接下来进行 yml 文件的配置,使 xml 文件可以被正确找到。
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPEmapperPUBLIC"-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd"><mappernamespace="com.xuan.mybatis.mapper.StudentInfoXmlMapper"></mapper>
mybatis:
mapper-locations: classpath:mapper/**Mapper.xml
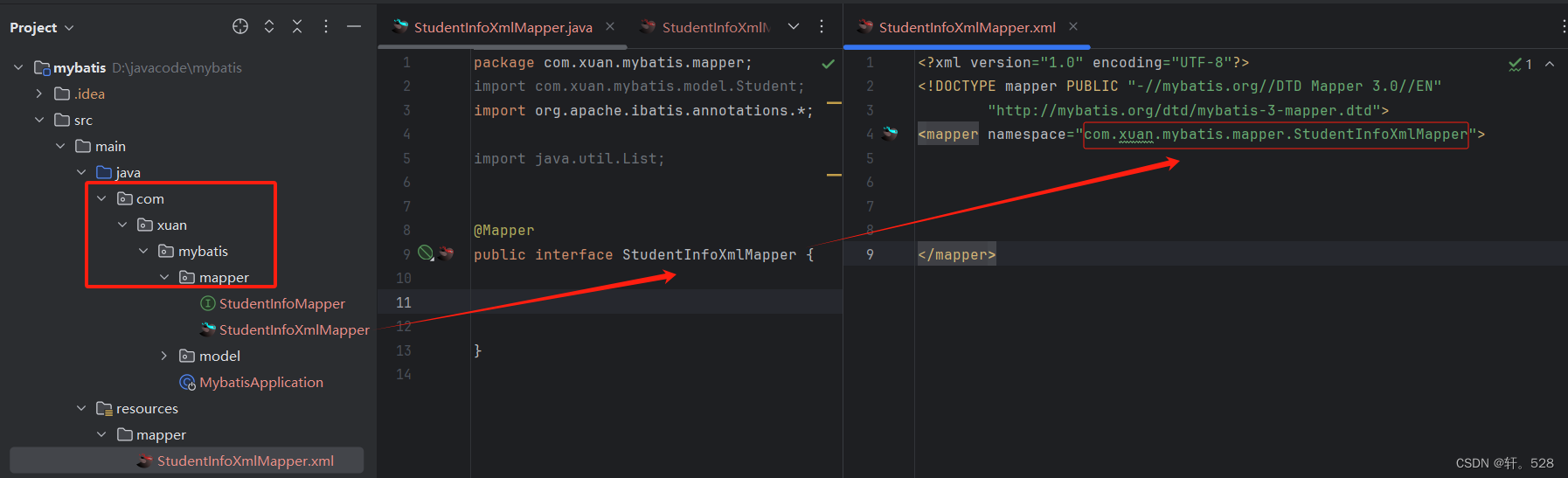
以上配置为固定的格式,其中在不同的XML文件中 namespace 的值不同,其值为:接口所在路径 + 接口名称。
============这是分隔线
注意:
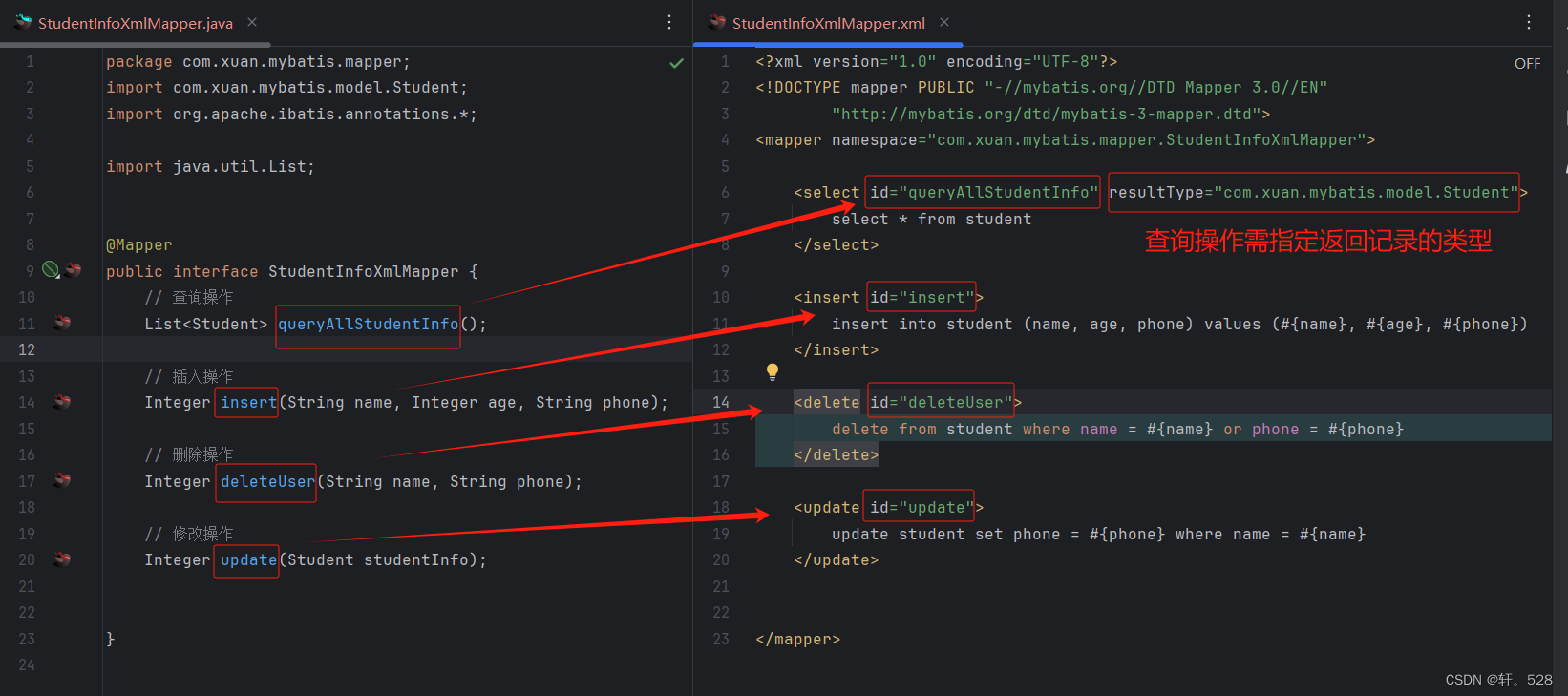
- 使用标签的编写 sql 语句与注解的方式类似,对于增删改查的 sql操作分别对应使用 insert、delete、update、select标签。
- 由于XML文件的映射配置只指定了接口所在的位置,因此我们在写每个方法对应的 sql 语句时需要使用 id 指定接口的方法名称。
- 因为修改操作(增删改)可以不用接收返回结果,而查询操作有返回结果集,因此使用 select 标签还需指定数据库返回的每条记录 对应的Java实体类的类型。
代码示例如下:
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPEmapperPUBLIC"-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd"><mappernamespace="com.xuan.mybatis.mapper.StudentInfoXmlMapper"><insertid="insert">
insert into student (name, age, phone) values (#{name}, #{age}, #{phone})
</insert><updateid="update">
update student set phone = #{phone} where name = #{name}
</update><deleteid="deleteUser">
delete from student where name = #{name} or phone = #{phone}
</delete><selectid="queryAllStudentInfo"resultType="com.xuan.mybatis.model.Student">
select * from student
</select></mapper>
4.4 使用 Alt + insert 生成测试类并执行测试方法
注意:需在测试类加上 @SpringBootTest注解,并使用@Autowired 注入 StudentInfoXmlMapper属性)
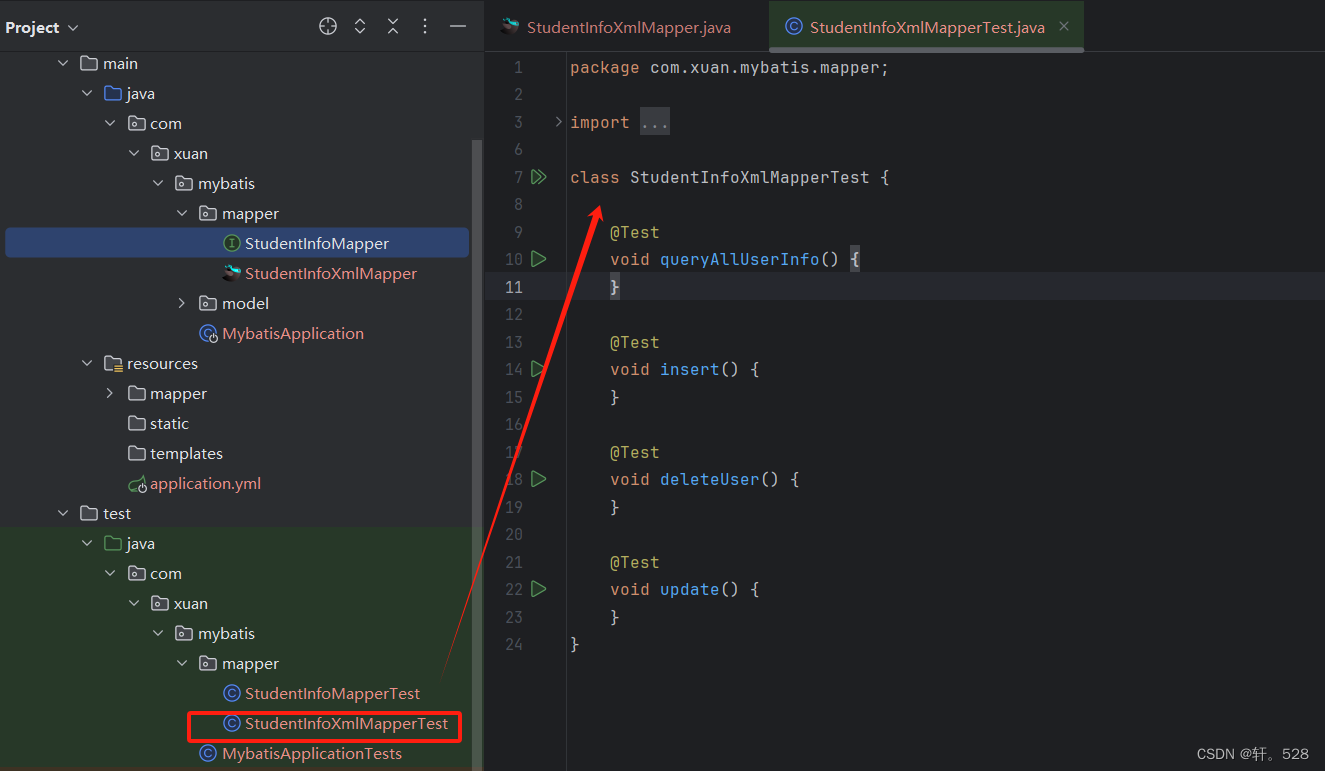
packagecom.xuan.mybatis.mapper;importcom.xuan.mybatis.model.Student;importorg.junit.jupiter.api.Test;importorg.springframework.beans.factory.annotation.Autowired;importorg.springframework.boot.test.context.SpringBootTest;importstaticorg.junit.jupiter.api.Assertions.*;@SpringBootTestclassStudentInfoXmlMapperTest{@AutowiredprivateStudentInfoXmlMapper studentInfoXmlMapper;@TestvoidqueryAllStudentInfo(){System.out.println(studentInfoXmlMapper.queryAllStudentInfo());;}@Testvoidinsert(){
studentInfoXmlMapper.insert("zhaoliu",16,"12345678900");System.out.println();}@TestvoiddeleteUser(){
studentInfoXmlMapper.deleteUser("zhangsan","18612340002");}@Testvoidupdate(){Student student =newStudent();
student.setName("admin");
student.setPhone("00987654321");
studentInfoXmlMapper.update(student);}}
程序的执行结果如下: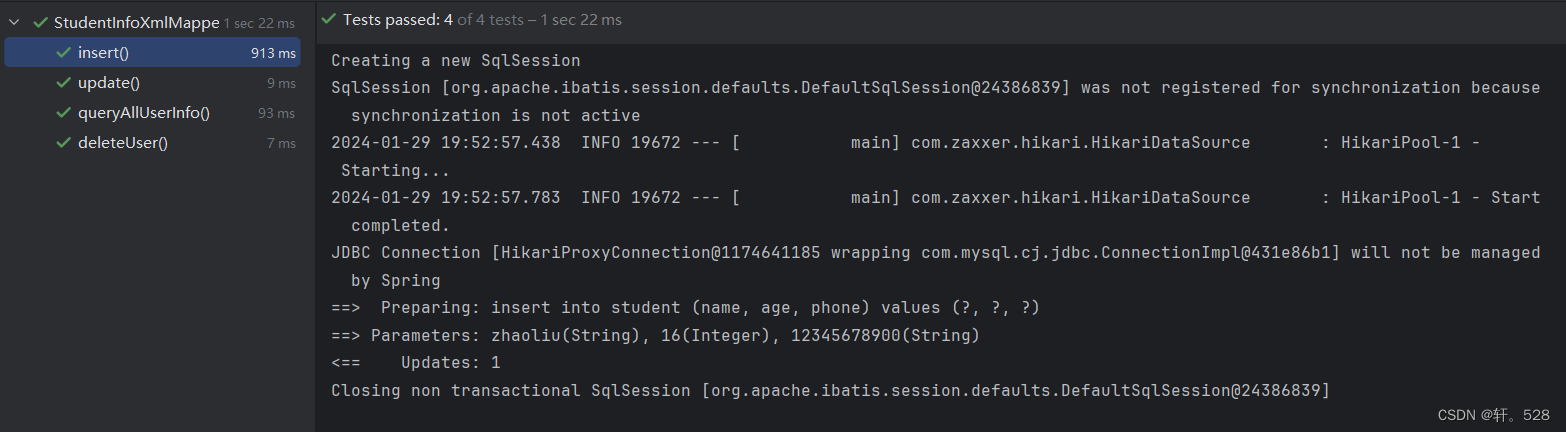
获取主键
使用 XML的方式获取主键与使用注解的方式类似,只需在 insert 标签中将 useGenerateKeys设置为 ture,并使用keyProperty将返回的主键值赋值给指定属性。
具体使用示例如下:
// 接口方法Integerinsert2(Student student);
// 测试类代码voidinsert2(){Student student =newStudent();
student.setName("xiaoming");
student.setAge(15);
student.setPhone("123456");
studentInfoXmlMapper.insert2(student);System.out.println("id: "+ student.getId());}
<insertid="insert2"useGeneratedKeys="true"keyProperty="id">
insert into student (name, age, phone) values (#{name}, #{age}, #{phone})
</insert>
程序运行结果如下: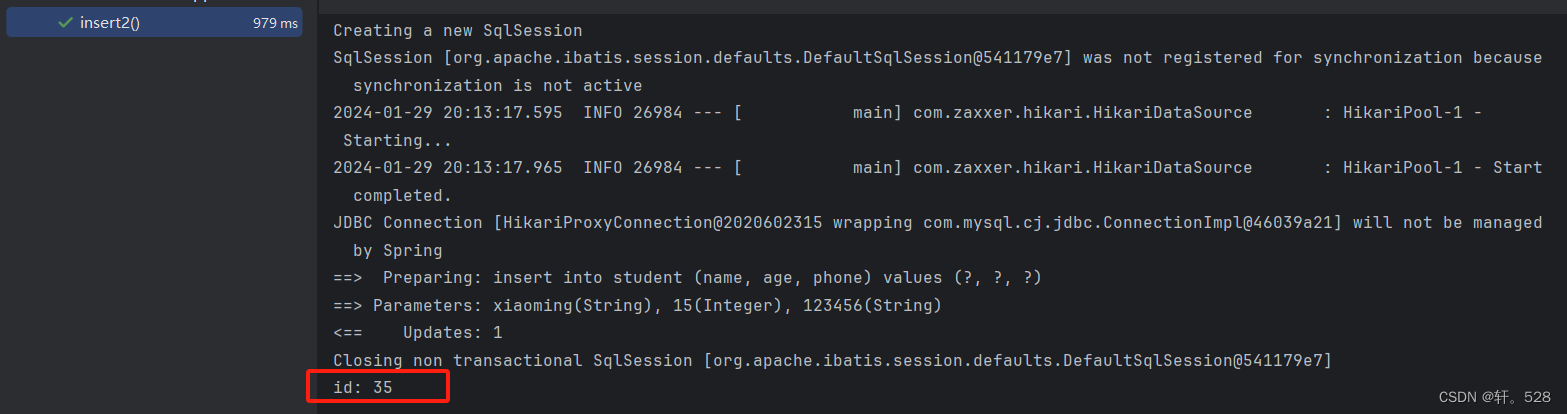
解决结果映射问题
在 XML 文件中解决结果映射的方式是使用 < resultMap> 标签,使用示例如下:
<resultMapid="baseMap"type="com.xuan.mybatis.model.UserInfo"><resultcolumn="delete_flag"property="deleteFlag"></result><resultcolumn="create_time"property="createTime"></result><resultcolumn="update_time"property="updateTime"></result></resultMap>
其中 id 为该映射结果集的名称,以便其他的查询操作进行复用; type的值 为返回结果映射的类型。在< resultMap> 标签下的 < result> 标签为每个属性的一一映射关系,column 为数据库字段的名称,property为 Java实体类属性的名称。
🍋5. #{} 和 ${}
在 sql语句 中传参的方式有两种:#{} 和 ${}。可以发现在之前的代码演示中都是使用 #{ }对参数进行传递,那么两种传参的方式有何区别呢?
当参数为 Integer类型时:
当参数为 String 类型时:
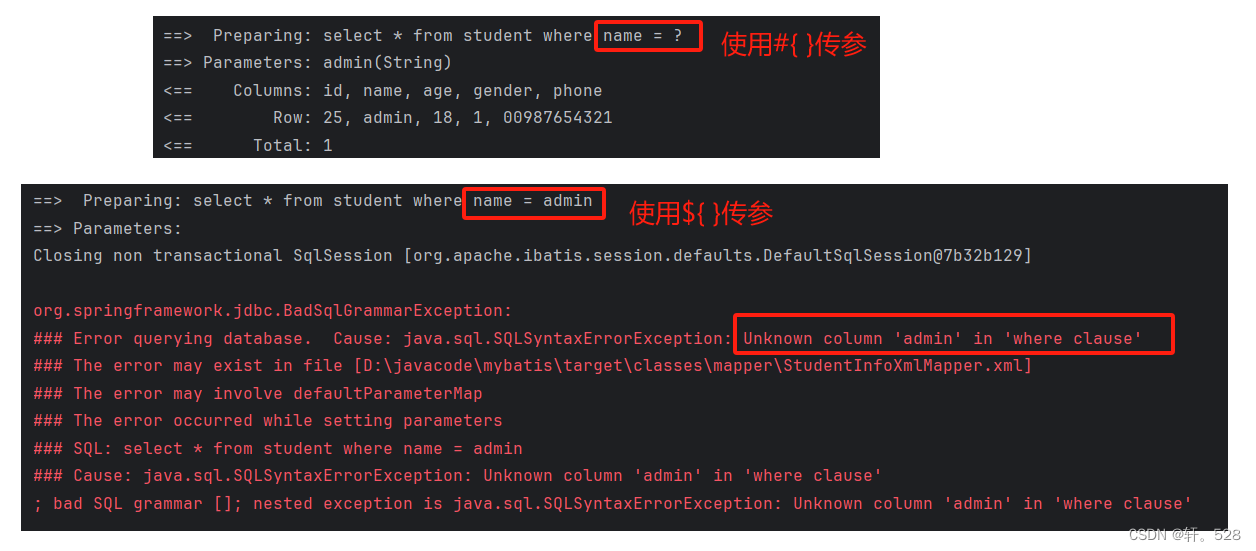
通过上面两个例子可以发现:
- #{ }传参是用 ?作为占位符,并用实际传入的参数替换 ?占位符。且当参数 Integer等类型时,构造的 sql 语句的方式是直接替换;当参数是 String 类型**时,构造 sql 语句的方式是将参数 放在" "中再进行替换==
- ==${ }传参方式是将参数进行直接拼接。
由于直接拼接的方式带来的 sql 缺陷,因此我们通常会使用#{ }对参数进行传递。但是使用#{ }并不是万能的,在某些场景下只能使用 ${ }才能构造一个正确的 sql 语句。
例如:
1.当我们要通过参数实现对查询返回结果进行 升序或降序 处理时,需要对 desc或asc 这两个字符串进行直接拼接,因此使用 #{ } 会使sql构造出错,并不能达到预期的效果。
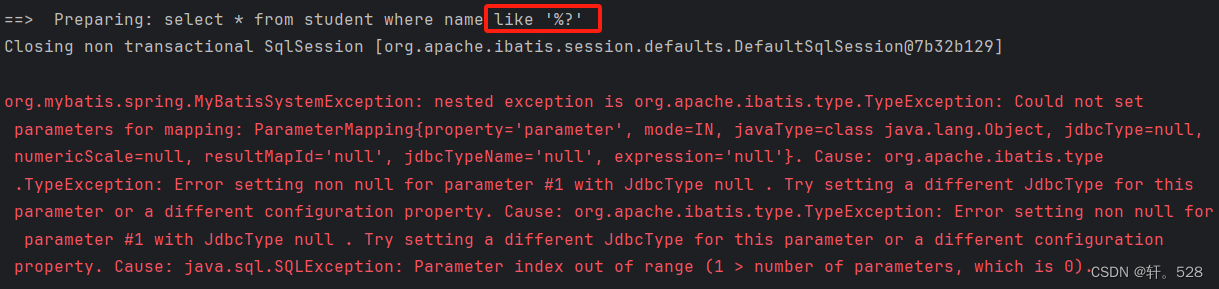
2.当我们要使用 like 关键字进行模糊查询时,使用 #{ }将参数进行替换会自动加上 " " ,因此导致程序报错。
错误代码演示如下: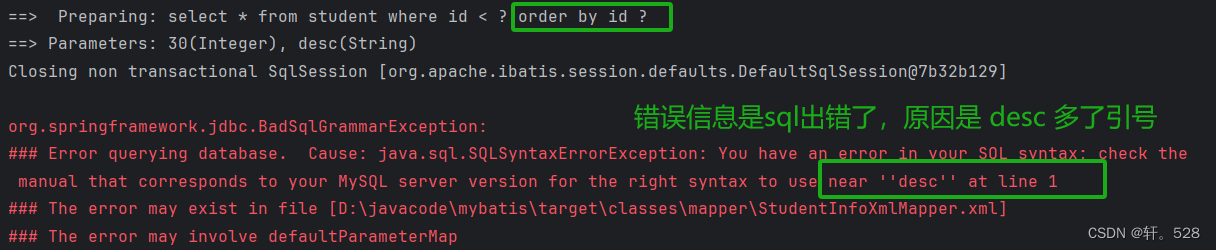
-
============这是分隔线
对于 #{ }和${ }的使用,其实上述这些区别 ${ }都可以通过手动加引号的方式进行改进,达到和 #{ }一样的效果,但它们之间其实还有一个最本质的区别:使用#{ }可以防止 SQL注入;而使用 ${ }因为参数是采用直接拼接的方式,因此如果没有严格的参数校验,比较容易发生 SQL注入的问题。(关于SQL注入攻击这里不展开叙述,大家可以自行去了解)
总结:
- #{ }传参是进行预编译处理,${ }传参是将参数进行直接拼接
- 需要进行模糊查询 或 对查询结果进行升降序排序 只能使用${ }完成
- #{ }可以防止SQL注入攻击,因此大部分情况下都使用 #{ }
三. 动态 SQL
动态 SQL 即可以根据参数具体的传递情况对 SQL语句进行动态拼接。
例如:在进行个人信息填写时,有些信息是必填项,部分信息则是选填项,可以根据实际情况决定是否填写,因此使用myabtis 提供的动态SQL 这一强大特性可以很好解决这一问题。
🍚if 标签
if 标签的使用示例如下:
<selectid="queryStudentByIdOrAge"resultType="com.xuan.mybatis.model.Student">
select * from student where id > #{id}
<iftest="age != null">
or age < #{age}
</if></select>
当 if 标签 test中的内容为true时, 标签内的内容会被拼接到 SQL语句中。(注意:由于 < 在XML为非法字符,不能直接出现在SQL语句中,故用 < ;来代替)
🍥trim 标签
trim标签的使用示例如下:
<insertid="insert2">
insert into student
<trimprefix="("suffix=")"prefixOverrides=","suffixOverrides=","><iftest="name != null">
name,
</if><iftest="age != null">
age
</if></trim>
values
<trimprefix="("suffix=")"prefixOverrides=","suffixOverrides=","><iftest="name != null">
#{name},
</if><iftest="age != null">
#{age}
</if></trim></insert>
当我们进行动态 SQL拼接时,若有部分字段没有进行传参,可以会出现前导或后缀的多余标点符号,trim 标签中 prefixOverrides和suffixOverrides 可以分别删除指定的前导和后缀符号;prefix 和 suffix可以分别添加前导和后缀符号,减少( )的添加,提供更加直观的 SQL语句。
🍭where 标签
where标签的使用示例如下:
<selectid="queryStudentByIdOrAge"resultType="com.xuan.mybatis.model.Student">
select * from student
<where><iftest="id != null">
id > #{id}
</if><iftest="age != null">
or age < #{age}
</if></where></select>
where 标签只有在子元素有内容时才添加 where关键字,且会自动去除子句开头多余的AND 或 OR 关键字。
where 标签页可使用 trim标签来替代:< trim prefix=“where” prefixOverrides=“and”> < /trim>。但是当子元素没有内容时,where关键字会保留,可能导致 SQL语句出现错误。
🍦set 标签
set标签使用示例如下:
<updateid="update">
update student
<set><iftest="phone != null">
phone = #{phone}
</if><iftest="gender != null">
,gender = #{gender}
</if></set>
where name = #{name}
</update>
set 标签用于 update语句中,可以更新指定的动态内容,并且会自动删除多余的前导或后缀逗号。
🧊foreach 标签
foreach标签使用示例如下:
<selectid="queryBatchStudent"resultType="com.xuan.mybatis.model.Student">
select * from student where id in
<foreachcollection="array"item="id"separator=","open="("close=")">
#{id}
</foreach></select>
foreach 标签通常搭配 in 关键字使用,foreach 传入的参数可以是任意可迭代的对象(List、Set等)、Map对象或 数组等;其中 collection为参数的名称,item 为每个元素的名称,seperator 为元素间的分隔符,open为添加前缀,close为添加后缀。
注意:当传入参数类型为List集合时 或 数组时,最好将参数名称命名为 list 或 array,因为在不同依赖下参数名若不为 list或array 可能导致报错。
🍬sql 和 include 标签
在 XML文件中,当很多的 SQL语句出现了重复的片段时,我们可以将重复的部分使用 sql 标签进行提取,再通过 include 标签对该片段进行引用。
sql 和 include 标签使用示例如下:
<sqlid="primaryColumn">
id, name, age, phone
</sql><selectid="queryAllStudentInfo"resultType="com.xuan.mybatis.model.Student">
select
<includerefid="primaryColumn"></include>
from student
</select>
sql 标签的作用是定义重复片段。id 的值为该片段的名称,作为引用的标识。
include 标签的作用是引用重复片段。refid 的值为引用片段的名称。
以上就是本篇文章的全部内容了,如果这篇文章对你有些许帮助,你的点赞、收藏和评论就是对我最大的支持。
另外,文章的不足之处,也希望你可以给我一点小小的建议,我会努力检查并改进。
版权归原作者 轩。528 所有, 如有侵权,请联系我们删除。