
在日常的运维工作中,CPU负载高是一种常见的故障状况,它可能对系统的正常运行和性能产生不利影响。为了准确地定位具体的异常原因,掌握一些专业的工具和方法是至关重要的。本文将通过一个实际的案例,详细介绍如何排查在线上HBASE集群CPU飙高问题,并分享相关工具的使用技巧以及基本的排查思路。通过阅读本文,读者将能够更加全面地了解和应对CPU负载高的问题,提升运维工作的效率和准确性。
解析线上HBase集群CPU飙高的原因与解决方案
1.线上现象描述
业务侧反馈,客户调用hbase集群相关操作的接口出现超时现象。查看监控信息,对应hbase集群有CPU负载突增且持续飚高的告警。
cm的监控图表:分别是CPU、网络、磁盘、集群请求。
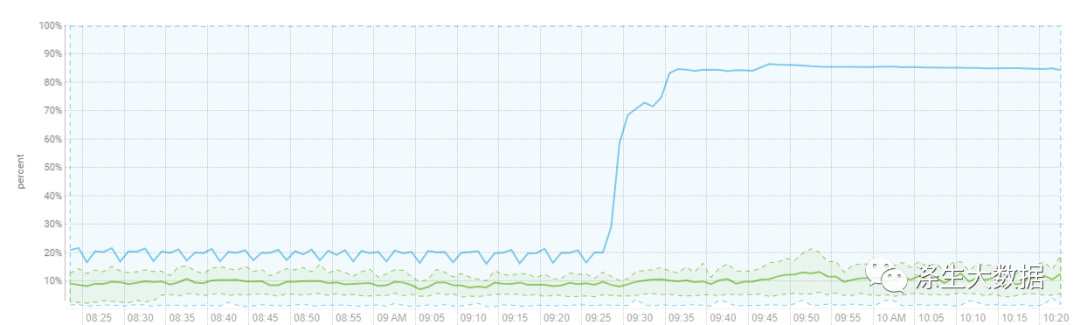
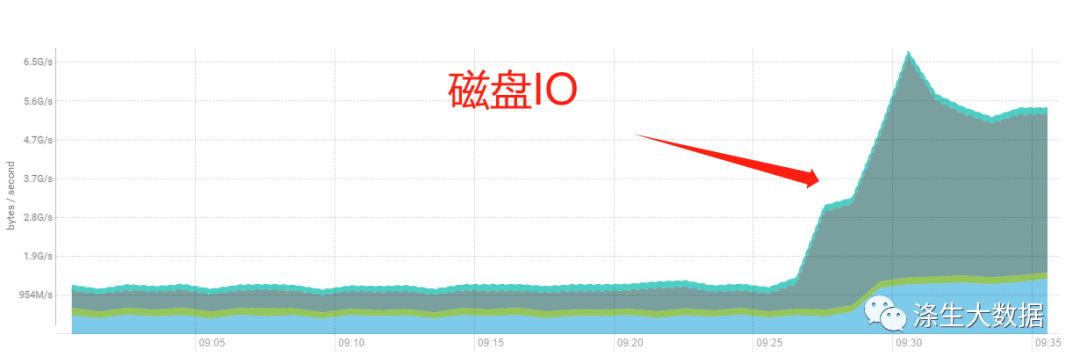
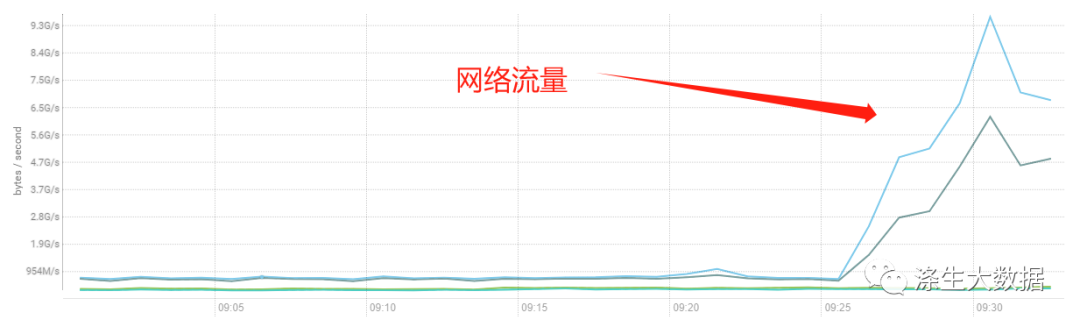
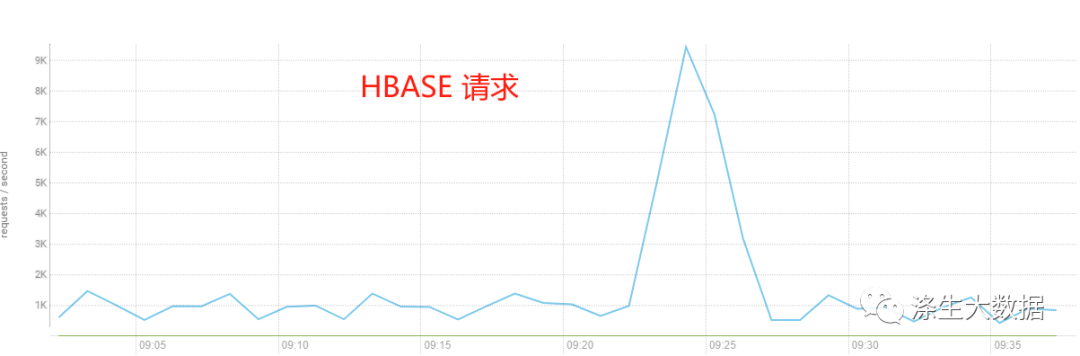
2.定位原因
一般出现上面cpu直接飙高的问题,最容易想到的排查方式就是到主机上查看单个主机cpu的状况,定位出单个主机CPU占比很高的进程;
主机高CPU的进程定位通常有以下几种方式
- 使用top命令:top命令可以实时监视系统的进程和资源使用情况。在top命令的输出中,按下"Shift + P"键,可以按照CPU使用率对进程进行排序,最高的进程将位于列表的顶部。
- 使用htop命令:htop是top命令的改进版,提供了更多的交互式功能。在htop命令的界面中,按下"F6"键,然后选择"PERCENT_CPU"选项,可以按照CPU使用率对进程进行排序。
- 使用ps命令:ps命令可以列出当前运行的进程。使用命令"ps -eo pid,ppid,%cpu,%mem,cmd"可以显示进程的PID、父进程ID、CPU使用率、内存使用率和命令行。
- 使用pidstat命令:pidstat命令可以提供有关进程的详细统计信息,包括CPU使用率。使用命令"pidstat -p <PID> -u"可以查看指定进程的CPU使用率。
- 使用perf工具:perf是一个功能强大的性能分析工具,可以用于定位高CPU占用的进程。使用perf可以获取进程的堆栈跟踪信息和性能计数器数据,帮助分析进程的性能瓶颈。
上面用的最多一般是top命令,本文也是结合top来做的分析:
下面是主机top下的截图:
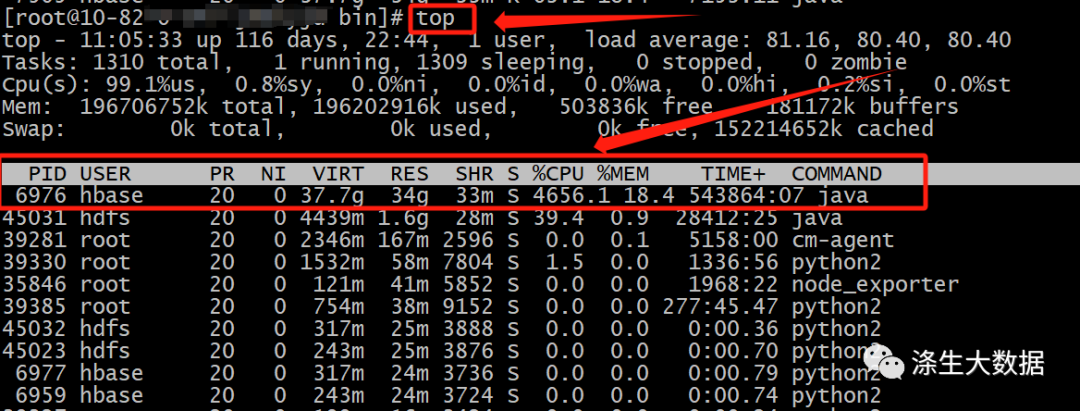
从上图中可以定位到cpu飙高是因为hbase用户的一个java进程导致,如果主机上用hbase用户启用了多个java进程,此时想定位具体的进程详细信息时,就需要借助于ps命令;

定位到具体的进程之后,我们只能看到进程级别的CPU使用情况,如果想具体的分析原因,还需要定位到进程中线程级别的cpu使用情况。此时就需要结合top的一些参数使用。
top -H -p <PID>
// 这个指令可以展示出指定进程的线程的资源使用情况;
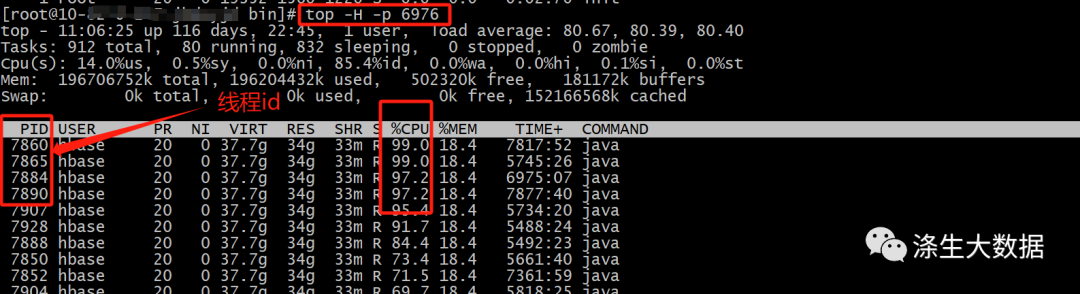
上面可以定位出具体的线程cpu使用情况,只能获取哪些线程占用较高的cpu,但是仅有一个线程id号,如果想知道具体线程的详细信息,就需要使用到java的堆栈分析工具jstack 。
jstack 介绍
jstack是Java开发工具包(JDK)中提供的一个命令行工具,用于生成Java虚拟机(JVM)中所有线程的堆栈跟踪信息。
使用jstack命令可以获取以下信息:
- 所有线程的堆栈跟踪:jstack命令会输出JVM中所有线程的堆栈跟踪信息,包括线程ID、状态、执行方法和行号等。这些信息可以用于分析线程的执行路径和可能的问题。
- 死锁检测:jstack命令可以检测并输出JVM中的死锁情况。它会显示死锁的线程以及导致死锁的资源。
tips:遇到java进程出现如死锁、死循环、长时间停顿等问题,都可以借助此工具来定位分析问题。

提示:在执行上面指令的时候,需要切换到进程启动的用户下,否则会有报错。
等指令运行完成,会输出所有线程的堆栈跟踪信息到指定的文件中,文件的大致内容格式如下:
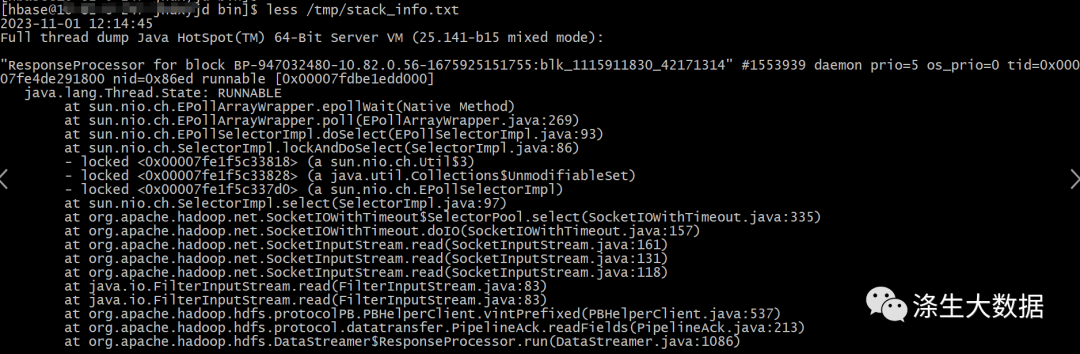
获取到内容还不可以根据线程的id直接来匹配线程的详细信息,这里需要将top 展示出来的线程id转换成16进制格式,转换的方式直接使用linux系统自带的格式输出工具 printf。

"printf "%x\n" 7888"命令将输出16进制整数30648的值,即1ed0。
最后就可以通过转换后的16进制的id值在上述文件中匹配到对应的线程信息;
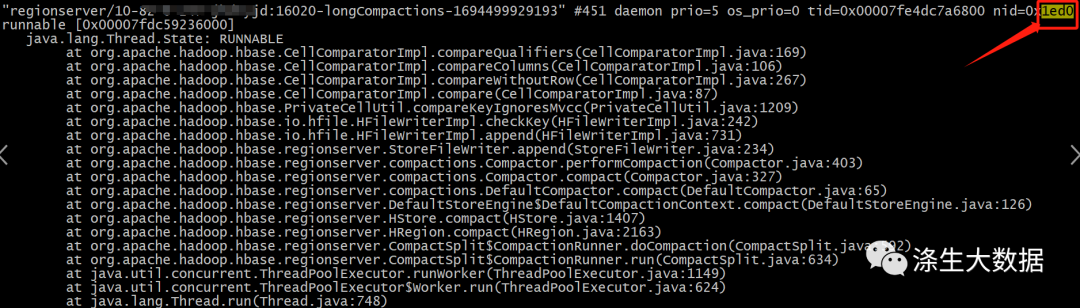
内容分析
- "regionserver/10-xxx-xxx:16020-longCompactions-1694499929193" #451 daemon prio=5 os_prio=0 tid=0x00007fe4dc7a6800 nid=0x1ed0 runnable [0x00007fdc59236000]:线程名称是"regionserver/10-xxx-xxx:16020-longCompactions-1694499929193",线程ID(TID)为0x00007fe4dc7a6800,线程优先级为5,是守护线程(daemon),线程状态为runnable,线程在内存中的地址为0x00007fdc59236000。
- java.lang.Thread.State: RUNNABLE:Java线程的状态为RUNNABLE(可运行)。
- at org.apache.hadoop.hbase.CellComparatorImpl.compareQualifiers(CellComparatorImpl.java:169):此行显示了线程正在执行的方法,即org.apache.hadoop.hbase.CellComparatorImpl.compareQualifiers,位于CellComparatorImpl.java文件的第169行。
- 其他的几行也是类似的,显示了线程在执行过程中经过的方法调用和对应的代码行号。
3.问题处理
通过以上方法的问题定位,最终知道导致集群cpu飙高的原因是Hbase集群在进行表的compaction导致的。
由此也知道hbase表的compaction操作确实是十分的损耗集群的性能的,但是这个又是Hbase集群的数据清理和优化的重要操作。所以需要集群的资源状态和结合业务的情况来合理的调起compaction。
版权归原作者 涤生大数据 所有, 如有侵权,请联系我们删除。