
文章目录
前言
最近重新接触Go语言以及对应框架,想借此机会深入下对应部分。
并分享一下最近学的过程很喜欢的一句话:
The limits of my language mean the limits of my world. by Ludwig Wittgenstein
我的语言之局限,即我的世界之局限。
一、是否一定要用框架来使用路由?
- 首先来介绍一下什么是路由。
路由是指确定请求应该由哪个处理程序处理的过程。在 Web 开发中,路由用于将请求映射到相应的处理程序或控制器。路由的种类通常包括以下几种:
- 静态路由: 静态路由是指将特定的 URL 路径映射到特定的处理程序或控制器的路由。这种路由是最基本的路由类型,通常用于处理固定的 URL 请求。例如一个简单的GET请求: /test/router
- 动态路由: 动态路由是指根据 URL 中的参数或模式进行匹配的路由。例如,可以使用动态路由来处理包含变量或参数的 URL 请求,以便根据请求的内容返回相应的结果。例如一个简单的GET请求: /test/:id
因为 Go 的 net/http 包提供了基础的路由函数组合与丰富的功能函数。所以在社区里流行一种用 Go 编写 API 不需要框架的观点,在我们看来,如果你的项目的路由在个位数、URI 固定且不通过 URI 来传递参数,那么确实使用官方库也就足够。
Go 的 Web 框架大致可以分为这么两类:
- Router 框架
- MVC 类框架
- 在框架的选择上,大多数情况下都是依照个人的喜好和公司的技术栈。例如公司有很多技术人员是 PHP 出身转go,那么他们一般会喜欢用 beego 这样的框架(典型的mvc架构),对于有些公司可能更喜欢轻量的框架那么则会使用gin,当然像字节这种内部则会去选择性能更高的kiteX作为web框架。
- 但如果公司有很多 C 程序员,那么他们的想法可能是越简单越好。比如很多大厂的 C 程序员甚至可能都会去用 C 语言去写很小的 CGI 程序,他们可能本身并没有什么意愿去学习 MVC 或者更复杂的 Web 框架,他们需要的只是一个非常简单的路由(甚至连路由都不需要,只需要一个基础的 HTTP 协议处理库来帮他省掉没什么意思的体力劳动)。
- 而对于一个简单的web服务利用官方库来编写也只需要短短的几行代码足矣:
package main
import(...)funcecho(wr http.ResponseWriter, r *http.Request){
msg, err := ioutil.ReadAll(r.Body)if err !=nil{
wr.Write([]byte("echo error"))return}
writeLen, err := wr.Write(msg)if err !=nil|| writeLen !=len(msg){
log.Println(err,"write len:", writeLen)}}funcmain(){
http.HandleFunc("/", echo)
err := http.ListenAndServe(":8080",nil)if err !=nil{
log.Fatal(err)}}
这个例子是为了说明在 Go 中写一个 HTTP 协议的小程序有多么简单。如果你面临的情况比较复杂,例如几十个接口的企业级应用,直接用 net/http 库就显得不太合适了。
例如来看早期开源社区中一个 Kafka 监控项目Burrow中的做法:
funcNewHttpServer(app *ApplicationContext)(*HttpServer,error){...
server.mux.HandleFunc("/", handleDefault)
server.mux.HandleFunc("/burrow/admin", handleAdmin)
server.mux.Handle("/v2/kafka", appHandler{server.app, handleClusterList})
server.mux.Handle("/v2/kafka/", appHandler{server.app, handleKafka})
server.mux.Handle("/v2/zookeeper", appHandler{server.app, handleClusterList})...}
看上去很简短,但是我们再深入进去:
funchandleKafka(app *ApplicationContext, w http.ResponseWriter, r *http.Request)(int,string){
pathParts := strings.Split(r.URL.Path[1:],"/")if_, ok := app.Config.Kafka[pathParts[2]];!ok {returnmakeErrorResponse(http.StatusNotFound,"cluster not found", w, r)}if pathParts[2]==""{// Allow a trailing / on requestsreturnhandleClusterList(app, w, r)}if(len(pathParts)==3)||(pathParts[3]==""){returnhandleClusterDetail(app, w, r, pathParts[2])}switch pathParts[3]{case"consumer":switch{case r.Method =="DELETE":switch{case(len(pathParts)==5)||(pathParts[5]==""):returnhandleConsumerDrop(app, w, r, pathParts[2], pathParts[4])default:returnmakeErrorResponse(http.StatusMethodNotAllowed,"request method not supported", w, r)}case r.Method =="GET":switch{case(len(pathParts)==4)||(pathParts[4]==""):returnhandleConsumerList(app, w, r, pathParts[2])case(len(pathParts)==5)||(pathParts[5]==""):// Consumer detail - list of consumer streams/hosts? Can be config info laterreturnmakeErrorResponse(http.StatusNotFound,"unknown API call", w, r)case pathParts[5]=="topic":switch{case(len(pathParts)==6)||(pathParts[6]==""):returnhandleConsumerTopicList(app, w, r, pathParts[2], pathParts[4])case(len(pathParts)==7)||(pathParts[7]==""):returnhandleConsumerTopicDetail(app, w, r, pathParts[2], pathParts[4], pathParts[6])}case pathParts[5]=="status":returnhandleConsumerStatus(app, w, r, pathParts[2], pathParts[4],false)case pathParts[5]=="lag":returnhandleConsumerStatus(app, w, r, pathParts[2], pathParts[4],true)}default:returnmakeErrorResponse(http.StatusMethodNotAllowed,"request method not supported", w, r)}case"topic":switch{case r.Method !="GET":returnmakeErrorResponse(http.StatusMethodNotAllowed,"request method not supported", w, r)case(len(pathParts)==4)||(pathParts[4]==""):returnhandleBrokerTopicList(app, w, r, pathParts[2])case(len(pathParts)==5)||(pathParts[5]==""):returnhandleBrokerTopicDetail(app, w, r, pathParts[2], pathParts[4])}case"offsets":// Reserving this endpoint to implement laterreturnmakeErrorResponse(http.StatusNotFound,"unknown API call", w, r)}// If we fell through, return a 404returnmakeErrorResponse(http.StatusNotFound,"unknown API call", w, r)}
这会发现这其中的这个handler扩展的比较复杂,这个原因是因为默认的 net/http 包中的 mux 不支持带参数的路由,所以 Burrow 这个项目使用了非常蹩脚的字符串 Split 和乱七八糟的 switch case 来达到自己的目的,但却让本来应该很集中的路由管理逻辑变得复杂,散落在系统的各处,难以维护和管理。但如今Burrow项目的路由已经重构为使用httpRouter。感兴趣的小伙伴可以自己再去看看相关源码:Burrow
type Coordinator struct{// App is a pointer to the application context. This stores the channel to the storage subsystem
App *protocol.ApplicationContext
// Log is a logger that has been configured for this module to use. Normally, this means it has been set up with// fields that are appropriate to identify this coordinator
Log *zap.Logger
router *httprouter.Router
servers map[string]*http.Server
theCert map[string]string
theKey map[string]string}
包括如今的web框架的路由部分也是由httprouter改造而成的,后续也会继续深入讲下这部分。
二、httprouter
在常见的 Web 框架中,router 是必备的组件。Go 语言圈子里 router 也时常被称为 http 的 multiplexer。如果开发 Web 系统对路径中带参数没什么兴趣的话,用 http 标准库中的 mux 就可以。而对于最近新起的Restful的api设计风格则基本重度依赖路径参数:
GET/repos/:owner/:repo/comments/:id/reactions
POST/projects/:project_id/columns
PUT/user/starred/:owner/:repo
DELETE/user/starred/:owner/:repo
如果我们的系统也想要这样的 URI 设计,使用之前标准库的 mux 显然就力不从心了。而这时候一般就会使用之前提到的httprouter。
2.1 httprouter介绍
地址:
https://github.com/julienschmidt/httprouter
https://godoc.org/github.com/julienschmidt/httprouter
因为 httprouter 中使用的是显式匹配,所以在设计路由的时候需要规避一些会导致路由冲突的情况,例如:
#冲突的情况:GET/user/info/:name
GET/user/:id
#不冲突的情况:GET/user/info/:name
POST/user/:id
简单来讲的话,如果两个路由拥有一致的 http 方法 (指 GET、POST、PUT、DELETE) 和请求路径前缀,且在某个位置出现了 A 路由是 带动态的参数(/:id),B 路由则是普通字符串,那么就会发生路由冲突。路由冲突会在初始化阶段直接 panic,如:
panic: wildcard route ':id' conflicts with existing children in path '/user/:id'
goroutine 1[running]:
github.com/cch123/httprouter.(*node).insertChild(0xc4200801e0, 0xc42004fc01, 0x126b177, 0x3, 0x126b171, 0x9, 0x127b668)
/Users/caochunhui/go_work/src/github.com/cch123/httprouter/tree.go:256 +0x841
github.com/cch123/httprouter.(*node).addRoute(0xc4200801e0, 0x126b171, 0x9, 0x127b668)
/Users/caochunhui/go_work/src/github.com/cch123/httprouter/tree.go:221 +0x22a
github.com/cch123/httprouter.(*Router).Handle(0xc42004ff38, 0x126a39b, 0x3, 0x126b171, 0x9, 0x127b668)
/Users/caochunhui/go_work/src/github.com/cch123/httprouter/router.go:262 +0xc3
github.com/cch123/httprouter.(*Router).GET(0xc42004ff38, 0x126b171, 0x9, 0x127b668)
/Users/caochunhui/go_work/src/github.com/cch123/httprouter/router.go:193 +0x5e
main.main()
/Users/caochunhui/test/go_web/httprouter_learn2.go:18 +0xaf
exit status 2
除支持路径中的 动态参数之外,httprouter 还可以支持 * 号来进行通配,不过 * 号开头的参数只能放在路由的结尾,例如下面这样:
Pattern: /src/*filepath
/src/ filepath =""
/src/somefile.go filepath ="somefile.go"
/src/subdir/somefile.go filepath ="subdir/somefile.go"
而这种场景主要是为了: httprouter 来做简单的 HTTP 静态文件服务器。
除了正常情况下的路由支持,httprouter 也支持对一些特殊情况下的回调函数进行定制,例如 404 的时候:
r := httprouter.New()
r.NotFound = http.HandlerFunc(func(w http.ResponseWriter, r *http.Request){
w.Write([]byte("oh no, not found"))})
或者内部 panic 的时候:
r := httprouter.New()
在r.PanicHandler =func(w http.ResponseWriter, r *http.Request, c interface{}){
log.Printf("Recovering from panic, Reason: %#v", c.(error))
w.WriteHeader(http.StatusInternalServerError)
w.Write([]byte(c.(error).Error()))}
2.2 httprouter原理
httprouter的使用在一开始时会使用New进行注册。对应函数为:
funcNew()*Router {return&Router{
RedirectTrailingSlash:true,
RedirectFixedPath:true,
HandleMethodNotAllowed:true,
HandleOPTIONS:true,}}
这四个参数的分别的作用为:
- RedirectTrailingSlash: 指定是否重定向带有尾部斜杠的 URL。如果设置为 true,则当用户访问没有斜杠结尾的 URL 时,httprouter 会将其重定向到带有斜杠结尾的 URL。例如,将 “/path” 重定向到 “/path/”。
- RedirectFixedPath: 指定是否重定向固定路径。如果设置为 true,则当用户访问具有固定路径的 URL 时,httprouter 会将其重定向到正确的固定路径。这对于确保 URL 的一致性和规范性非常有用。
- HandleMethodNotAllowed: 指定是否处理不允许的 HTTP 方法。如果设置为 true,则当用户使用不允许的 HTTP 方法访问 URL 时,httprouter 会返回 “405 Method Not Allowed” 错误。
- HandleOPTIONS: 指定是否处理 OPTIONS 方法。如果设置为 true,则当用户使用 OPTIONS 方法访问 URL 时,httprouter 会返回允许的 HTTP 方法列表。
更详细的可以参考源码注释。
除此之外Router中还有一个很重要的字段:
type Router struct{// ...
trees map[string]*node
// ...}
而这个字段则涉及到了底层的数据结构实现,阅读httprouter的源码注释可以简单知道:
Package httprouter is a trie based high performance HTTP request router.
- 因此httprouter的底层是用压缩字典树实现的,属于字典树的一个变种,在继续介绍这块之前简单做一个知识的补充:
- 字典树即前缀树(Trie树),又称单词查找树或键树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是: 利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较。 以下是一颗字典树的生成,分别插入app、apple、abcd、user、use、job。
字典树的生成
- 而压缩字典树(Radix)也很好理解,因为字典树的节点粒度是以一个字母,而像路由这种有规律的字符串完全可以把节点粒度加粗,减少了不必要的节点层级减少存储空间压缩字符,并且由于深度的降低,搜索的速度也会相对应的加快。例如做成如下这种形式::
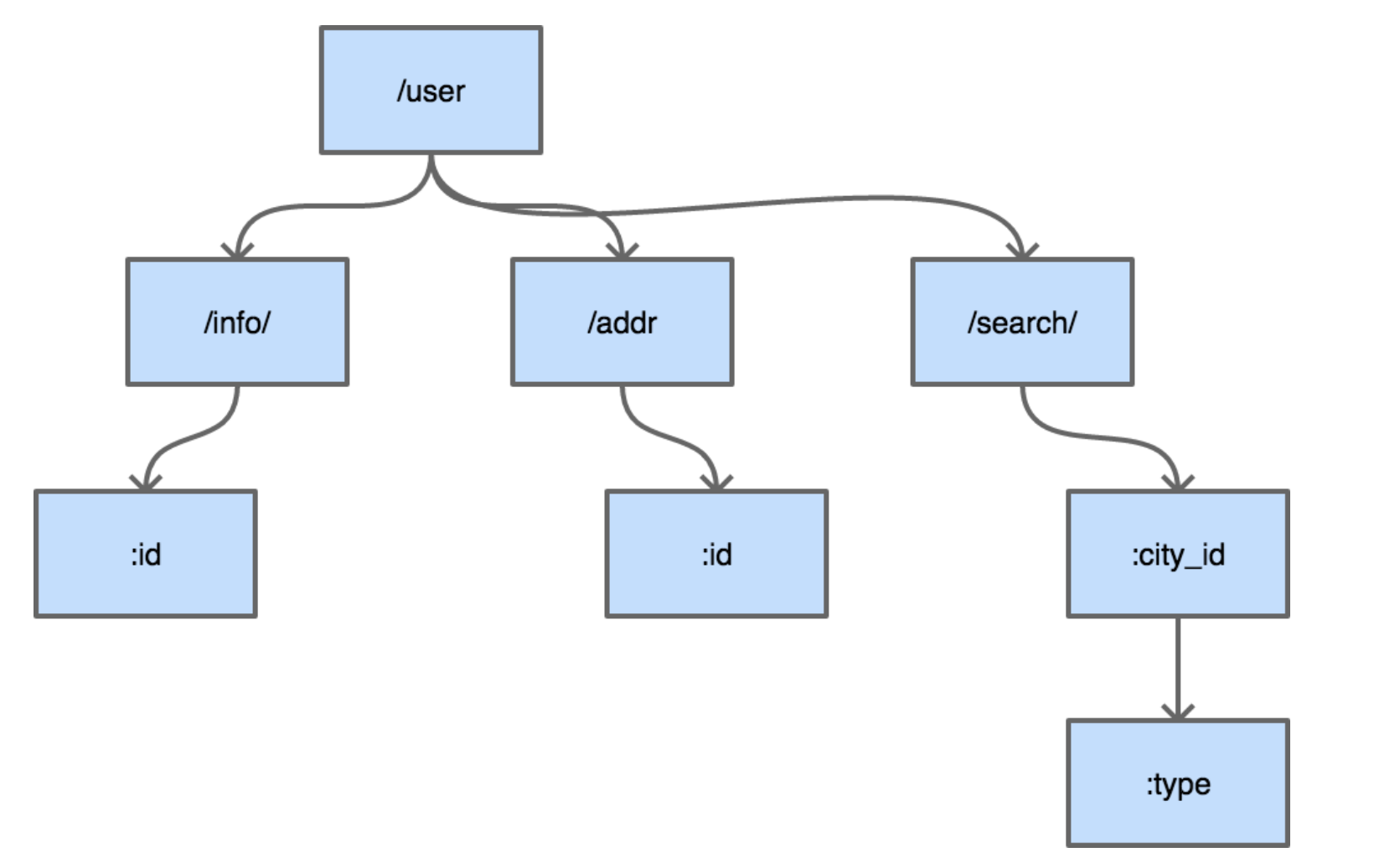 因此上述的Map其实存放的key 即为 HTTP 1.1 的 RFC 中定义的各种方法,而node则为各个方法下的root节点。
因此上述的Map其实存放的key 即为 HTTP 1.1 的 RFC 中定义的各种方法,而node则为各个方法下的root节点。GET、HEAD、OPTIONS、POST、PUT、PATCH、DELETE
因此每一种方法对应的都是一棵独立的压缩字典树,这些树彼此之间不共享数据。
- 对于node结构体:
type node struct{
path string
indices string
wildChild bool
nType nodeType
priority uint32
children []*node
handle Handle
}
参数分别代表的意思:
- path: 表示当前节点对应的路径中的字符串。例如,如果节点对应的路径是 “/user/:id”,那么 path 字段的值就是 “:id”。
- indices: 一个字符串,用于快速查找子节点。它包含了当前节点的所有子节点的第一个字符。为了加快路由匹配的速度。
- wildChild: 一个布尔值,表示子节点是否为参数节点,即 wildcard node,或者说像 “:id” 这种类型的节点。如果子节点是参数节点,则 wildChild 为 true,否则为 false。
- nType: 表示节点的类型,是一个枚举类型。它可以表示静态节点、参数节点或通配符节点等不同类型的节点。
- priority: 一个无符号整数,用于确定节点的优先级。这有助于在路由匹配时确定最佳匹配项。
- children: 一个指向子节点的指针数组。它包含了当前节点的所有子节点。
- handle: 表示与当前节点关联的处理函数(handler)。当路由匹配到当前节点时,将调用与之关联的处理函数来处理请求。
- 对于nodeType:
const(
static nodeType =iota// 非根节点的普通字符串节点
root // 根节点
param // 参数节点 如:id
catchAll // 通配符节点 如:*anyway)
而对于添加一个路由的过程基本在源码tree.go的addRoute的func中。大概得过程补充在注释中:
// 增加路由并且配置节点handle,因为中间的变量没有加锁,所以不保证并发安全,如children之间的优先级func(n *node)addRoute(path string, handle Handle){
fullPath := path
n.priority++// 空树的情况下插入一个root节点if n.path ==""&& n.indices ==""{
n.insertChild(path, fullPath, handle)
n.nType = root
return}
walk:for{// 找到最长的公共前缀。// 并且公共前缀中不会包含 no ':' or '*',因为公共前缀key不能包含这两个字符,遇到了则直接continue
i :=longestCommonPrefix(path, n.path)// 如果最长公共前缀小于 path 的长度,那么说明 path 无法与当前节点路径匹配,需要进行边的分裂// 例如:n 的路径是 "/user/profile",而当前需要插入的路径是 "/user/posts"if i <len(n.path){
child := node{
path: n.path[i:],
wildChild: n.wildChild,
nType: static,
indices: n.indices,
children: n.children,
handle: n.handle,
priority: n.priority -1,}
n.children =[]*node{&child}// []byte for proper unicode char conversion, see #65
n.indices =string([]byte{n.path[i]})
n.path = path[:i]
n.handle =nil
n.wildChild =false}// 处理剩下非公共前缀的部分if i <len(path){
path = path[i:]// 如果当前节点有通配符(wildChild),则会检查通配符是否匹配,如果匹配则继续向下匹配,否则会出现通配符冲突的情况,并抛出异常。if n.wildChild {
n = n.children[0]
n.priority++// Check if the wildcard matchesiflen(path)>=len(n.path)&& n.path == path[:len(n.path)]&&// Adding a child to a catchAll is not possible
n.nType != catchAll &&// Check for longer wildcard, e.g. :name and :names(len(n.path)>=len(path)|| path[len(n.path)]=='/'){continue walk
}else{// Wildcard conflict
pathSeg := path
if n.nType != catchAll {
pathSeg = strings.SplitN(pathSeg,"/",2)[0]}
prefix := fullPath[:strings.Index(fullPath, pathSeg)]+ n.path
panic("'"+ pathSeg +"' in new path '"+ fullPath +"' conflicts with existing wildcard '"+ n.path +"' in existing prefix '"+ prefix +"'")}}
idxc := path[0]// 如果当前节点是参数类型(param)并且路径中的下一个字符是 '/',并且当前节点只有一个子节点,则会继续向下匹配。if n.nType == param && idxc =='/'&&len(n.children)==1{
n = n.children[0]
n.priority++continue walk
}// 检查是否存在与路径中的下一个字符相匹配的子节点,如果有则继续向下匹配,否则会插入新的子节点来处理剩余的路径部分。for i, c :=range[]byte(n.indices){if c == idxc {
i = n.incrementChildPrio(i)
n = n.children[i]continue walk
}}if idxc !=':'&& idxc !='*'{// []byte for proper unicode char conversion, see #65
n.indices +=string([]byte{idxc})
child :=&node{}
n.children =append(n.children, child)
n.incrementChildPrio(len(n.indices)-1)
n = child
}
n.insertChild(path, fullPath, handle)return}// Otherwise add handle to current nodeif n.handle !=nil{panic("a handle is already registered for path '"+ fullPath +"'")}
n.handle = handle
return}}
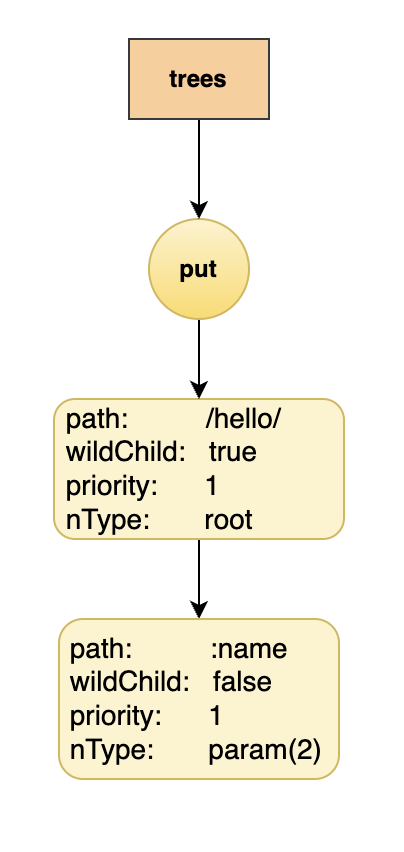
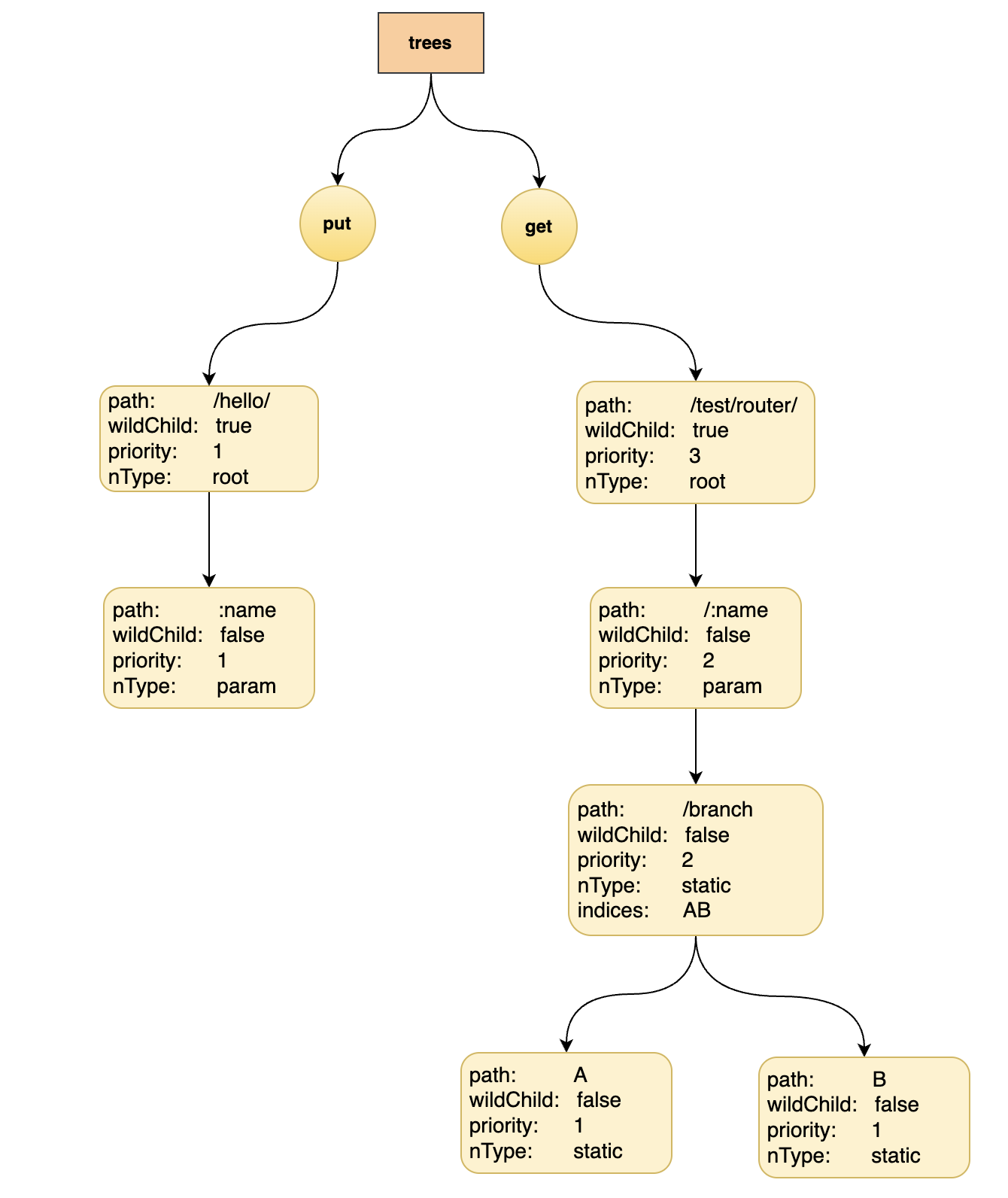
接下来以一个实际的案例,创建6个路由:
funcIndex(w http.ResponseWriter, r *http.Request,_ httprouter.Params){
fmt.Fprint(w,"Welcome!\n")}funcHello(w http.ResponseWriter, r *http.Request, ps httprouter.Params){
fmt.Fprintf(w,"hello, %s!\n", ps.ByName("name"))}funcmain(){
router := httprouter.New()
router.PUT("/hello/:name", Hello)
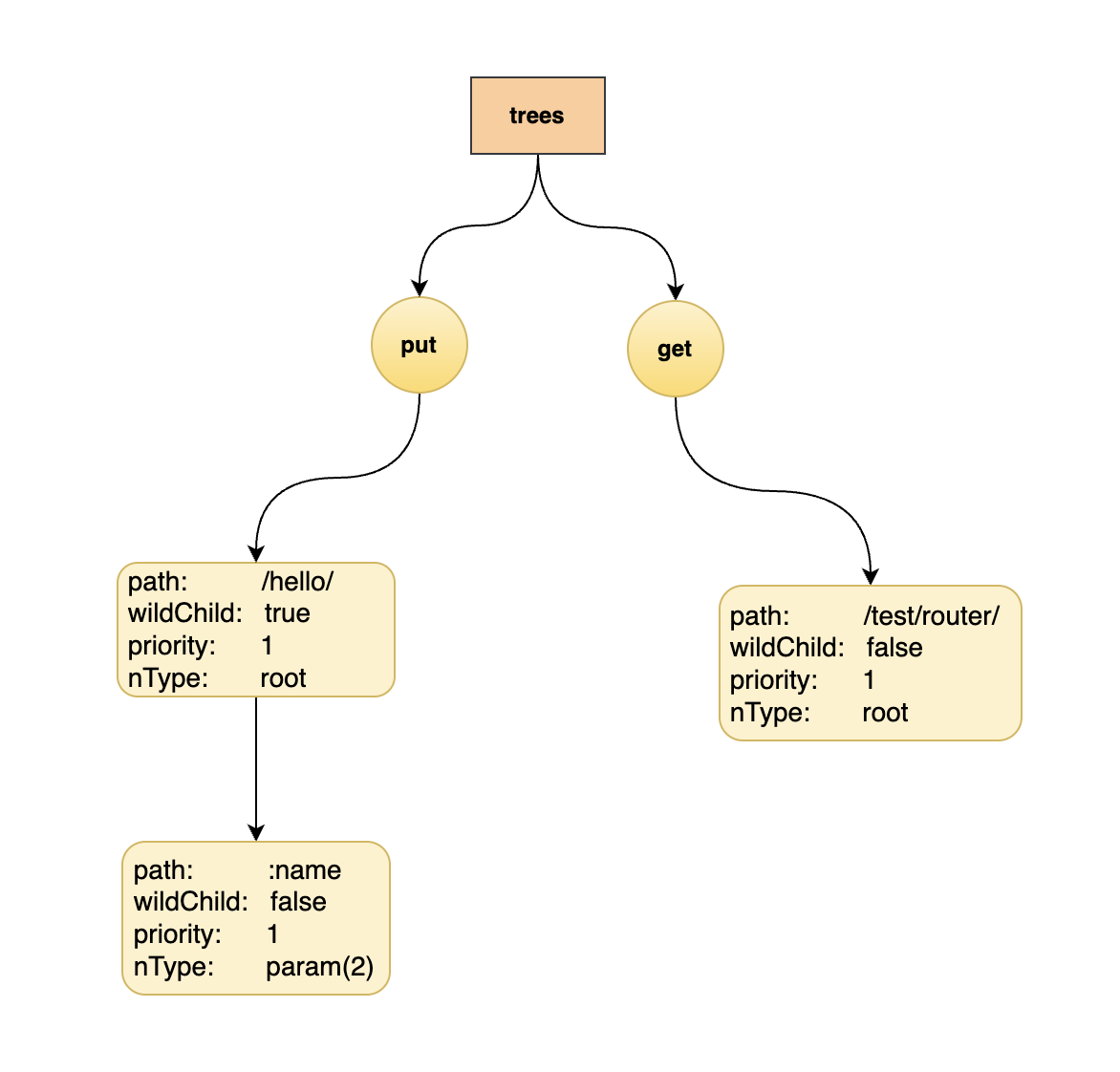
router.GET("/test/router/", Hello)
router.GET("/test/router/:name/branchA", Hello)
router.GET("/test/router/:name/branchB", Hello)
router.GET("status", Hello)
router.GET("searcher", Hello)
log.Fatal(http.ListenAndServe(":8080", router))}
- 插入 “/hello/:name”
- 插入 “/test/router/”
- 插入 “/test/router/:name/branchA”
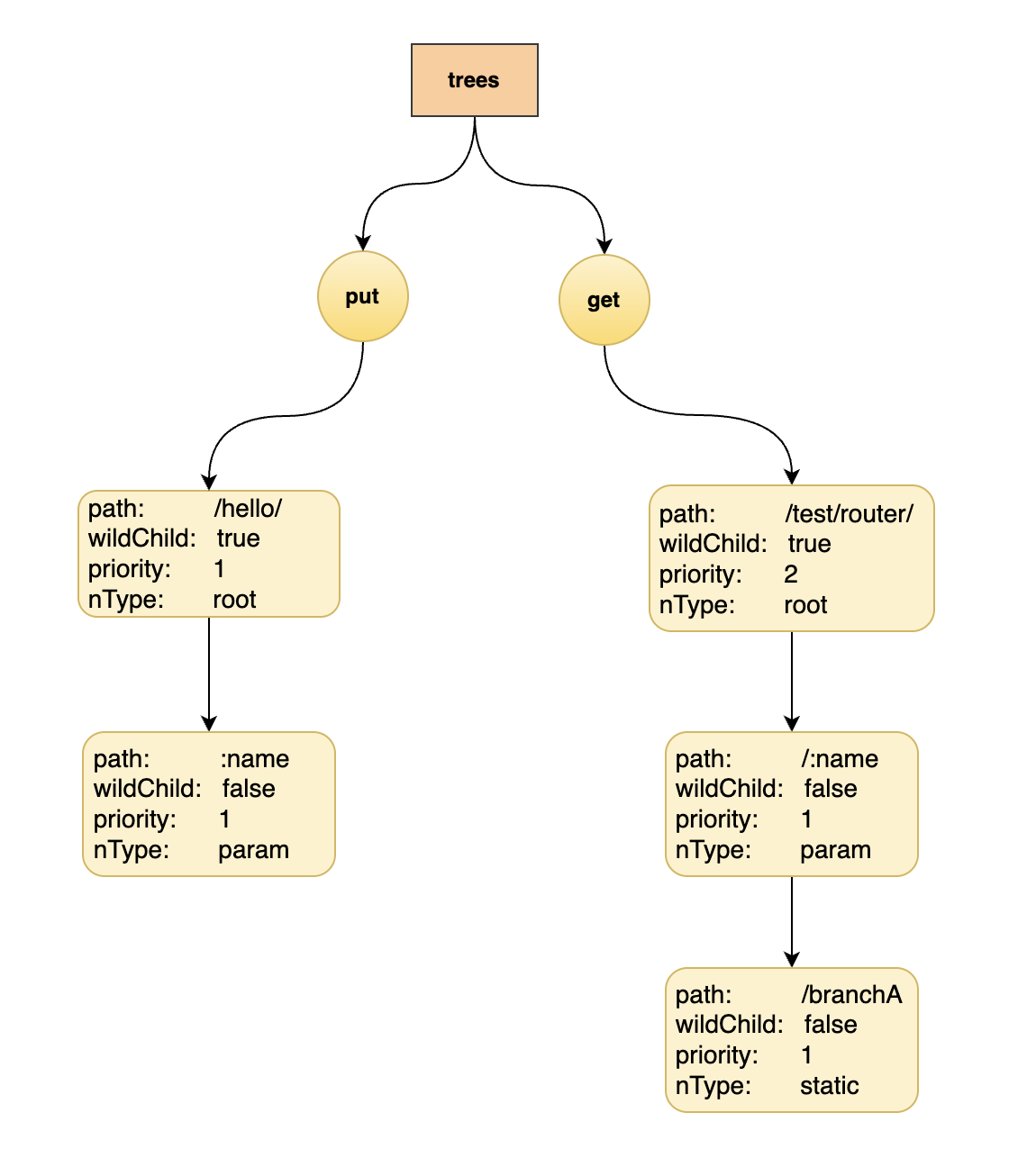
- 插入 “/test/router/:name/branchB”,此时由于/banch的孩子节点个数大于1,所以indices字段有作用,此时为两个孩子节点path的首字母
- 插入 “/status”
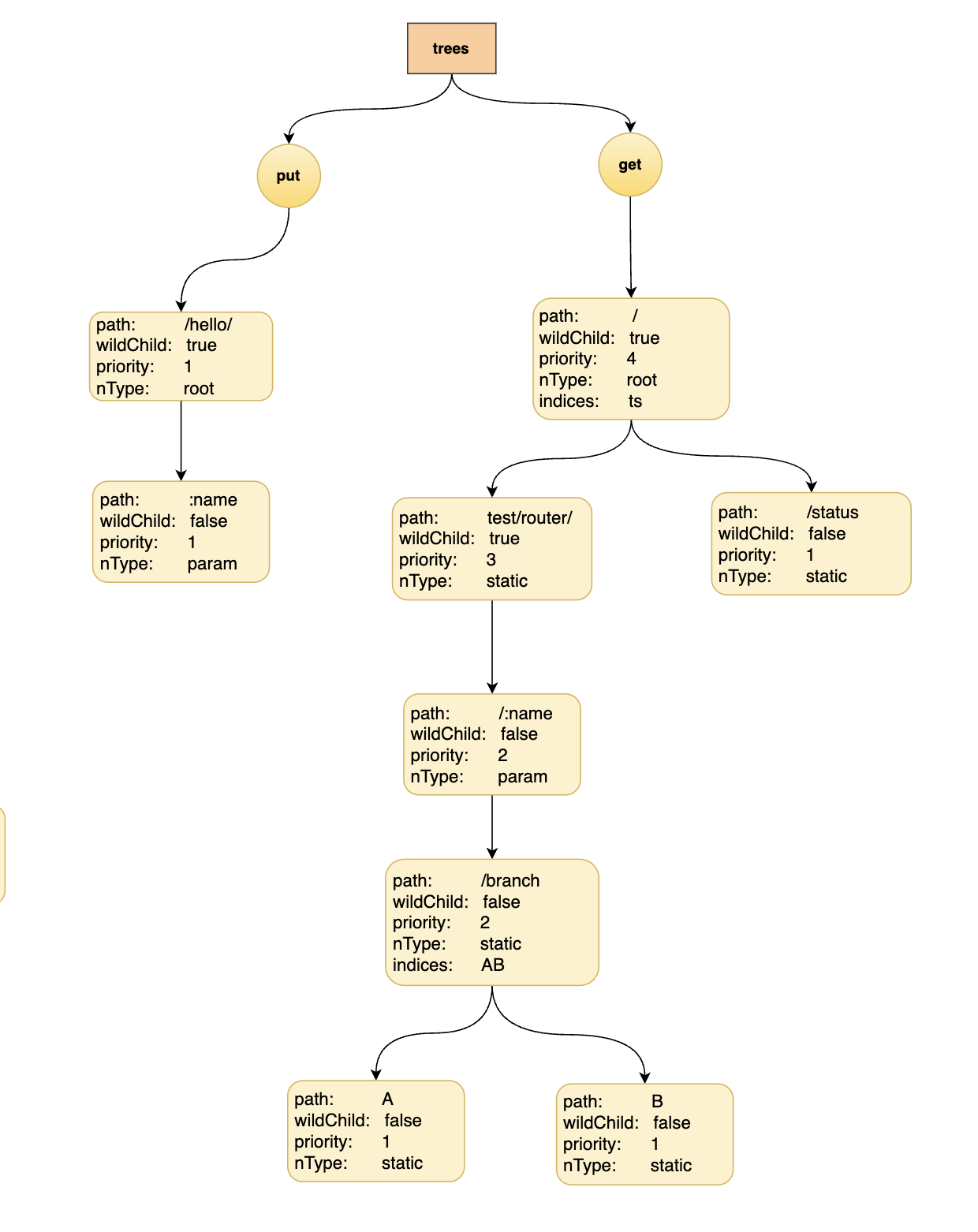
- 插入 “searcher”
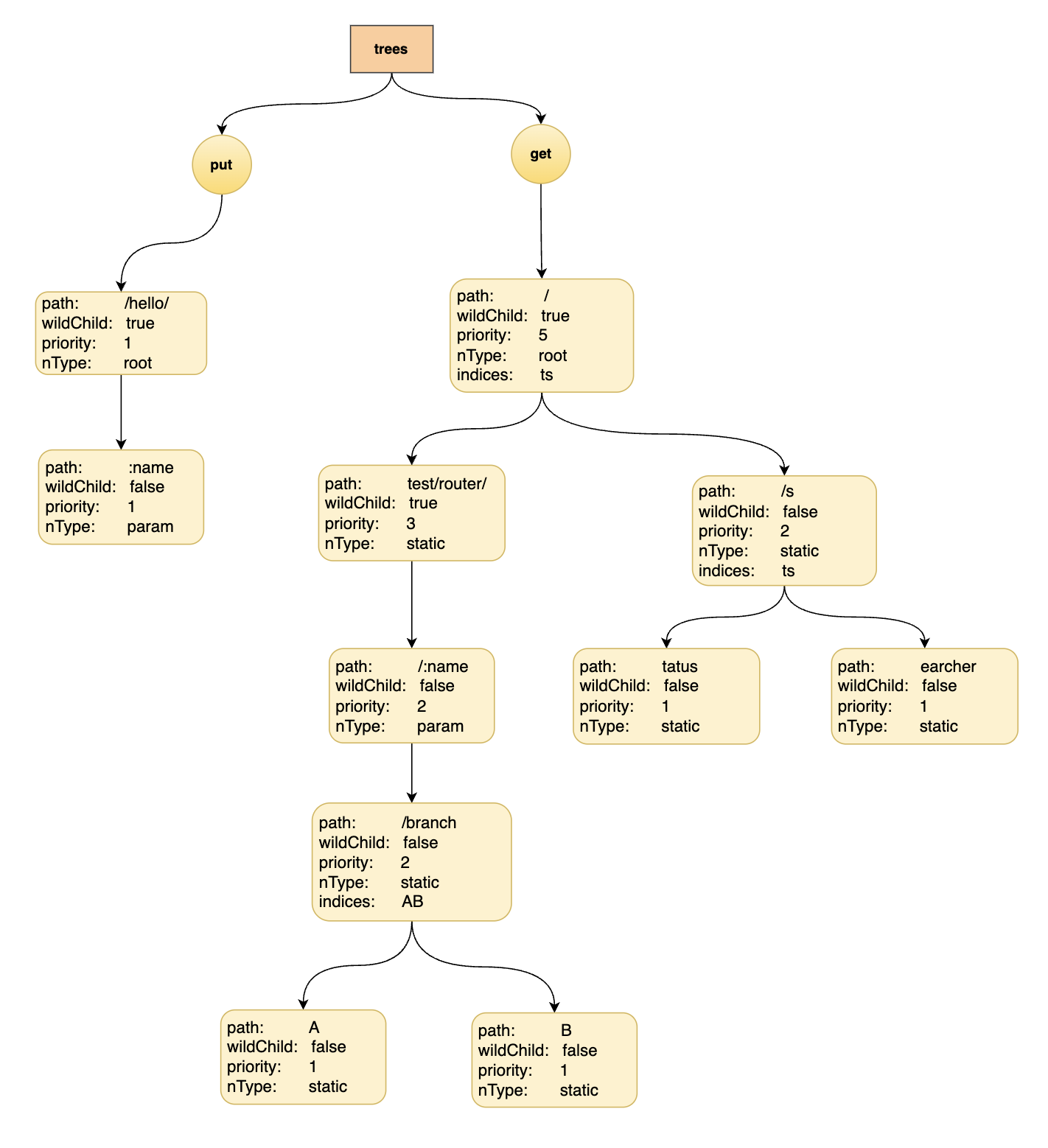
也因为底层数据结构的原因,所以为了不让树的深度过深,在初始化时会对参数的数量进行限制,所以在路由中的参数数目不能超过 255,否则会导致 httprouter 无法识别后续的参数。
2.3 路由冲突情况
所以路由本身只有字符串的情况下,不会发生任何冲突。只有当路由中含有 wildcard(类似 :id)或者 catchAll 的情况下才可能冲突。这在2.1中也提到过。
而子节点的冲突处理很简单,分几种情况:
- 在插入 wildcard 节点时,父节点的 children 数组非空且 wildChild 被设置为 false。
例如:GET /user/getAll 和 GET /user/:id/getAddr,或者 GET /user/*aaa 和 GET /user/:id。
- 在插入 wildcard 节点时,父节点的 children 数组非空且 wildChild 被设置为 true,但该父节点的 wildcard 子节点要插入的 wildcard 名字不一样。
例如:GET /user/:id/info 和 GET /user/:name/info。
- 在插入 catchAll 节点时,父节点的 children 非空。
例如:GET /src/abc 和 GET /src/*filename,或者 GET /src/:id 和 GET /src/*filename。
- 在插入 static 节点时,父节点的 wildChild 字段被设置为 true。
- 在插入 static 节点时,父节点的 children 非空,且子节点 nType 为 catchAll。
三、gin中的路由
之前提到过现在Star数最高的web框架gin中的router中的很多核心实现很多基于httprouter中的,具体的可以去gin项目中的tree.go文件看对应部分,这里主要讲一下gin的路由除此之外额外实现了什么。
gin项目地址链接
在gin进行初始化的时候,可以看到初始化的路由时它其实是初始化了一个路由组,而使用router对应的GET\PUT等方法时则是复用了这个默认的路由组,这里已经略过不相干代码。
r := gin.Default()funcDefault()*Engine {...
engine :=New()...}funcNew()*Engine {...
engine :=&Engine{
RouterGroup: RouterGroup{
Handlers:nil,
basePath:"/",
root:true,},......}// RouterGroup is used internally to configure router, a RouterGroup is associated with// a prefix and an array of handlers (middleware).type RouterGroup struct{
Handlers HandlersChain
basePath string
engine *Engine
root bool}
因此可以看出gin在底层实现上比普通的httprouter多出了一个路由组的概念。这个路由组的作用主要能对api进行分组授权。例如正常的业务逻辑很多需要登录授权,有的接口需要这个鉴权,有些则可以不用,这个时候就可以利用路由组的概念的去进行分组。
- 这里用一个最简单的例子去使用:
// 创建路由组
authorized := r.Group("/admin",func(c *gin.Context){// 在此处编写验证用户权限的逻辑// 如果用户未经授权,则可以使用 c.Abort() 中止请求并返回相应的错误信息})// 在路由组上添加需要授权的路径
authorized.GET("/dashboard", dashboardHandler)
authorized.POST("/settings", settingsHandler)
当然group源码中也可以传入一连串的handlers去进行前置的处理业务逻辑。
// Group creates a new router group. You should add all the routes that have common middlewares or the same path prefix.// For example, all the routes that use a common middleware for authorization could be grouped.func(group *RouterGroup)Group(relativePath string, handlers ...HandlerFunc)*RouterGroup {return&RouterGroup{
Handlers: group.combineHandlers(handlers),
basePath: group.calculateAbsolutePath(relativePath),
engine: group.engine,}}
对于正常的使用一个
而这个RouterGroup正如注释提到的RouterGroup is used internally to configure router,只是配置对应的路由,对应真正的路由树的结构还是在对应的engine的trees中的。与我们之前看的httprouter差不多
type methodTrees []methodTree
funcNew()*Engine {...
trees methodTrees
...}
所以总的来说,RouterGroup与Engine的关系是这样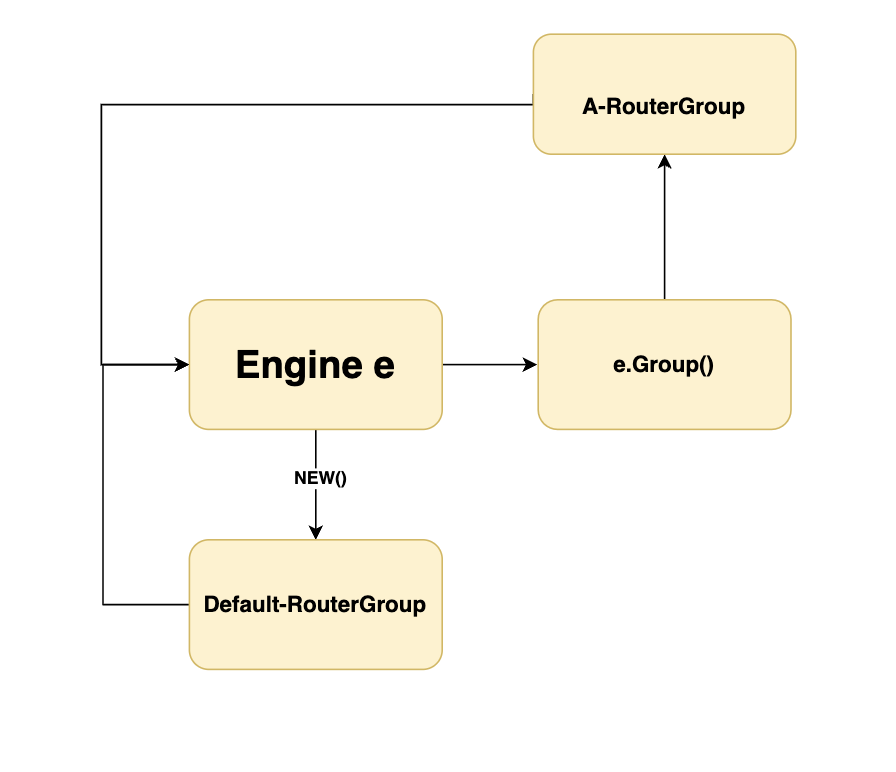
因此不管通过Engine实例对象可以创建多个routergroup,然后创建出来的routergroup都会再重新绑定上engine,而借助结构体的正交性组合的特点,新构建出来的组的路由组还可以继续使用engine继续创造新的路由组,而不管横向创造多少个,或者纵向创建多少个,改变的始终是唯一那个engine的路由树。而纵向创建group这种方式,则是gin中创建嵌套路由的使用方式。
package main
import("github.com/gin-gonic/gin")funcmain(){
router := gin.Default()// 创建父级路由组
v1 := router.Group("/v1"){// 在父级路由组中创建子级路由组
users := v1.Group("/users"){// 子级路由组中的路由
users.GET("/",func(c *gin.Context){
c.JSON(200, gin.H{"message":"Get all users"})})
users.POST("/",func(c *gin.Context){
c.JSON(200, gin.H{"message":"Create a new user"})})}}
router.Run(":8080")}
四、hertz中的路由
hertz是字节内部比较常用的web,而对于这一部分的router他做的结合优化主要有两种。
- 结合了httprouter的核心压缩字典树等理念,并且对冲突情况做了相应的解决。
- 结合了gin中路由分组管理的概念。
第二点其实和Gin差不多,这里不再赘述,主要讲下第一点。之前在httprouter中插入孩子节点的func会有很多wildcard的特殊处理,从而对应的冲突时会报错。这样做的原因是:
- 为了解决在同时遇到参数节点与静态节点的情况时,httprouter不需要考虑匹配的的优先级进行返回。直接不解决抛出异常即可,这样实现也会相应的简洁。 如:
func(n *node)insertChild(path, fullPath string, handle Handle){for{// 找到路径中第一个通配符前的前缀
wildcard, i, valid :=findWildcard(path)if i <0{// 没有找到通配符break}// 通配符名称不应包含 ':' 和 '*'if!valid {panic("only one wildcard per path segment is allowed, has: '"+
wildcard +"' in path '"+ fullPath +"'")}// 检查通配符是否有名称iflen(wildcard)<2{panic("wildcards must be named with a non-empty name in path '"+ fullPath +"'")}// 检查当前节点是否有现有子节点,否则插入通配符将导致无法到达iflen(n.children)>0{panic("wildcard segment '"+ wildcard +"' conflicts with existing children in path '"+ fullPath +"'")}// 参数通配符if wildcard[0]==':'{if i >0{// 在当前通配符之前插入前缀
n.path = path[:i]
path = path[i:]}
n.wildChild =true
child :=&node{
nType: param,
path: wildcard,}
n.children =[]*node{child}
n = child
n.priority++// 如果路径不以通配符结尾,那么会有另一个以 '/' 开头的非通配符子路径iflen(wildcard)<len(path){
path = path[len(wildcard):]
child :=&node{
priority:1,}
n.children =[]*node{child}
n = child
continue}// 否则完成。在新叶子节点中插入处理程序
n.handle = handle
return}// catchAll 通配符if i+len(wildcard)!=len(path){panic("catch-all routes are only allowed at the end of the path in path '"+ fullPath +"'")}iflen(n.path)>0&& n.path[len(n.path)-1]=='/'{panic("catch-all conflicts with existing handle for the path segment root in path '"+ fullPath +"'")}// 当前固定宽度为 1,表示 '/'
i--if path[i]!='/'{panic("no / before catch-all in path '"+ fullPath +"'")}
n.path = path[:i]// 第一个节点: 具有空路径的 catchAll 节点
child :=&node{
wildChild:true,
nType: catchAll,}
n.children =[]*node{child}
n.indices =string('/')
n = child
n.priority++// 第二个节点: 包含变量的节点
child =&node{
path: path[i:],
nType: catchAll,
handle: handle,
priority:1,}
n.children =[]*node{child}return}// 如果未找到通配符,直接插入路径和处理程序
n.path = path
n.handle = handle
}
而对于hertz来讲为了解决这个冲突,那么也是要将对应的wildcard概念进行淡化,例如之前httprouter的节点结构体中会有一个wildChild bool的参数,来判断下一个节点是否是参数的节点。而在hertz中则是淡化的相关的概念,完善了很多关于路由树的结构引用。对应的节点定义如下:
type(
node struct{
kind kind // 节点类型,标识节点是静态、参数还是通配符
label byte// 节点的标签,用于静态路由节点,表示路由的一部分
prefix string// 静态路由节点的前缀
parent *node // 父节点
children children // 子节点列表
ppath string// 原始路径
pnames []string// 参数名列表
handlers app.HandlersChain // 处理的handler链路
paramChild *node // 参数节点
anyChild *node // 通配符节点
isLeaf bool// 表示节点是否是叶子节点,即是否没有子路由节点}
kind uint8// 表示节点类型的枚举
children []*node // 子节点列表)
因此他在是插入的实现上也更多偏向于一个更通用的路由树。
// insert 将路由信息插入到路由树中。// path: 要插入的路由路径// h: 路由处理函数链// t: 节点类型(静态、参数、通配符)// ppath: 父节点的路径// pnames: 参数名列表(对于参数节点)func(r *router)insert(path string, h app.HandlersChain, t kind, ppath string, pnames []string){
currentNode := r.root
if currentNode ==nil{panic("hertz: invalid node")}
search := path
for{
searchLen :=len(search)
prefixLen :=len(currentNode.prefix)
lcpLen :=0
max := prefixLen
if searchLen < max {
max = searchLen
}// 计算最长公共前缀长度for; lcpLen < max && search[lcpLen]== currentNode.prefix[lcpLen]; lcpLen++{}if lcpLen ==0{// 根节点
currentNode.label = search[0]
currentNode.prefix = search
// 如果有处理函数,handler链路更新当前节点信息if h !=nil{
currentNode.kind = t
currentNode.handlers = h
currentNode.ppath = ppath
currentNode.pnames = pnames
}
currentNode.isLeaf = currentNode.children ==nil&& currentNode.paramChild ==nil&& currentNode.anyChild ==nil}elseif lcpLen < prefixLen {// 分裂节点
n :=newNode(
currentNode.kind,
currentNode.prefix[lcpLen:],
currentNode,
currentNode.children,
currentNode.handlers,
currentNode.ppath,
currentNode.pnames,
currentNode.paramChild,
currentNode.anyChild,)// 更新子节点的父节点信息for_, child :=range currentNode.children {
child.parent = n
}if currentNode.paramChild !=nil{
currentNode.paramChild.parent = n
}if currentNode.anyChild !=nil{
currentNode.anyChild.parent = n
}// 重置父节点信息
currentNode.kind = skind
currentNode.label = currentNode.prefix[0]
currentNode.prefix = currentNode.prefix[:lcpLen]
currentNode.children =nil
currentNode.handlers =nil
currentNode.ppath = nilString
currentNode.pnames =nil
currentNode.paramChild =nil
currentNode.anyChild =nil
currentNode.isLeaf =false// 只有静态子节点能够到达此处
currentNode.children =append(currentNode.children, n)if lcpLen == searchLen {// 在父节点处
currentNode.kind = t
currentNode.handlers = h
currentNode.ppath = ppath
currentNode.pnames = pnames
}else{// 创建子节点
n =newNode(t, search[lcpLen:], currentNode,nil, h, ppath, pnames,nil,nil)// 只有静态子节点能够到达此处
currentNode.children =append(currentNode.children, n)}
currentNode.isLeaf = currentNode.children ==nil&& currentNode.paramChild ==nil&& currentNode.anyChild ==nil}elseif lcpLen < searchLen {
search = search[lcpLen:]
c := currentNode.findChildWithLabel(search[0])if c !=nil{// 深入下一级
currentNode = c
continue}// 创建子节点
n :=newNode(t, search, currentNode,nil, h, ppath, pnames,nil,nil)switch t {case skind:
currentNode.children =append(currentNode.children, n)case pkind:
currentNode.paramChild = n
case akind:
currentNode.anyChild = n
}
currentNode.isLeaf = currentNode.children ==nil&& currentNode.paramChild ==nil&& currentNode.anyChild ==nil}else{// 节点已存在if currentNode.handlers !=nil&& h !=nil{panic("handlers are already registered for path '"+ ppath +"'")}if h !=nil{
currentNode.handlers = h
currentNode.ppath = ppath
currentNode.pnames = pnames
}}return}}
由于解决了冲突,使得参数节点与普通静态节点兼容。那么对于相应的查找肯定也是要做优先校验,先上结论,在同一级上它的优先级分别是:
- 静态节点(static)> 参数节点(param) > 通配符节点(any) ,如下是将这个过程简略后的代码:
func(r *router)find(path string, paramsPointer *param.Params, unescape bool)(res nodeValue){var(
cn = r.root // 当前节点
search = path // 当前路径
searchIndex =0// 当前路径的索引
paramIndex int// 参数索引
buf []byte// 字节缓冲区)// 回溯函数,每搜索的节点到尽头时没有搜索到结果就会调用此函数进行回溯到第一个可能得节点// 它的搜索优先级仍是静态节点(static)> 参数节点(param) > 通配符节点(any)
backtrackToNextNodeKind :=func(fromKind kind)(nextNodeKind kind, valid bool){...if previous.kind == akind {
nextNodeKind = skind
}else{
nextNodeKind = previous.kind +1}...}// 这是一个无限循环,因为在找到匹配节点之前,需要一直沿着路由树向下搜索// search order: static > param > anyfor{if cn.kind == skind {...// 如果当前节点是静态节点(skind),则尝试匹配当前节点的前缀,并进行切割iflen(search)>=len(cn.prefix)&& cn.prefix == search[:len(cn.prefix)]{// 匹配成功,将路径中已匹配的部分去除,更新路径为未匹配的部分。
search = search[len(cn.prefix):]// 更新搜索索引,表示已经匹配的部分的长度。
searchIndex = searchIndex +len(cn.prefix)}else{//根据不同条件执行相应的操作,如回溯到上一层节点。调用(backtrackToNextNodeKind)
nk, ok :=backtrackToNextNodeKind(skind)if!ok {return// No other possibilities on the decision path}elseif nk == pkind {goto Param
}else{// Not found (this should never be possible for static node we are looking currently)break}}}// 检查当前节点是否是终端节点(叶子节点),并且该节点有对应的handler(可以break跳出了)if search == nilString &&len(cn.handlers)!=0{...}// 当路径未完全匹配时,检查当前节点是否是静态节点if search != nilString {...}// 当路径完全匹配但仍有可能有子节点的情况if search == nilString {...}
Param:// Param node 节点处理情况...
Any:// Any node 节点处理情况...// 当前类型实在没有可能得结果了,回溯上一层
nk, ok :=backtrackToNextNodeKind(akind)if!ok {break// No other possibilities on the decision path}// 与backtrackToNextNodeKind(akind)中的情况进行对应,下一个节点类型的处理elseif nk == pkind {goto Param
}elseif nk == akind {goto Any
}else{// Not foundbreak}}...return}
因此可以看到整个搜索的过程其实是DFS+回溯遍历这个路由树的一个过程,然后在回溯的过程中不断地按照节点的类型进行优先级遍历,从而兼容了参数节点与静态节点的冲突。
总结
最后来进行一个总结:
- 如果你的项目的路由在个位数、URI 固定且不通过 URI 来传递参数,实现restful风格的api时,可以直接用官方库,net/http 。
- 大部分的web框架路由很多都是由httprouter改编而来的,httprouter的路由本质上是由压缩字典树作为数据结构实现的,但httprouter不能兼容参数节点与通配符节点同时存在的问题,会抛出panic。
- gin框架以此基础上实现了路由组的概念,一个gin的engine对象可以创建多个路由组(横向创建),而路由组的结构体中因为又绑定了原有engine,则可以继续嵌套创建路由(纵向创建),哪种创建方式最终指向的都是同一颗路由树。
- hertz结合了gin与httprouter的,搜索时通过回溯+DFS进行节点之间的优先级排序,兼容了参数节点与静态节点之间的冲突。
版权归原作者 幸平xp 所有, 如有侵权,请联系我们删除。