
文章目录
1.常规的索引分类
根据索引的不同类型,可以分为如下几类:
- 主键索引 - 针对表中的主键列创建的索引,当创建主键时,主建索引也会被创建,默认情况下主键索引是自动创建,并且只能创建一个。- 主键索引的关键字是PRIMARY。
- 唯一索引 - 唯一索引可以避免同一张表中,某列数据有重复值。- 唯一索引是在创建唯一约束时自动创建的,在一张表中可以存在多个唯一索引。- 唯一索引的关键字是UNIQUE。
- 常规索引 - 常规索引用于快速定位要查询的数据,应用的很多,在一张表中可以有多个常规索引。
- 全文索引 - 全文索引用于查询文本中包含的关键词,而不是比较的索引中的值,可以创建多个,应用的比较少。- 全文索引的关键字是FULLTEXT 。
2.索引存储形式的分类
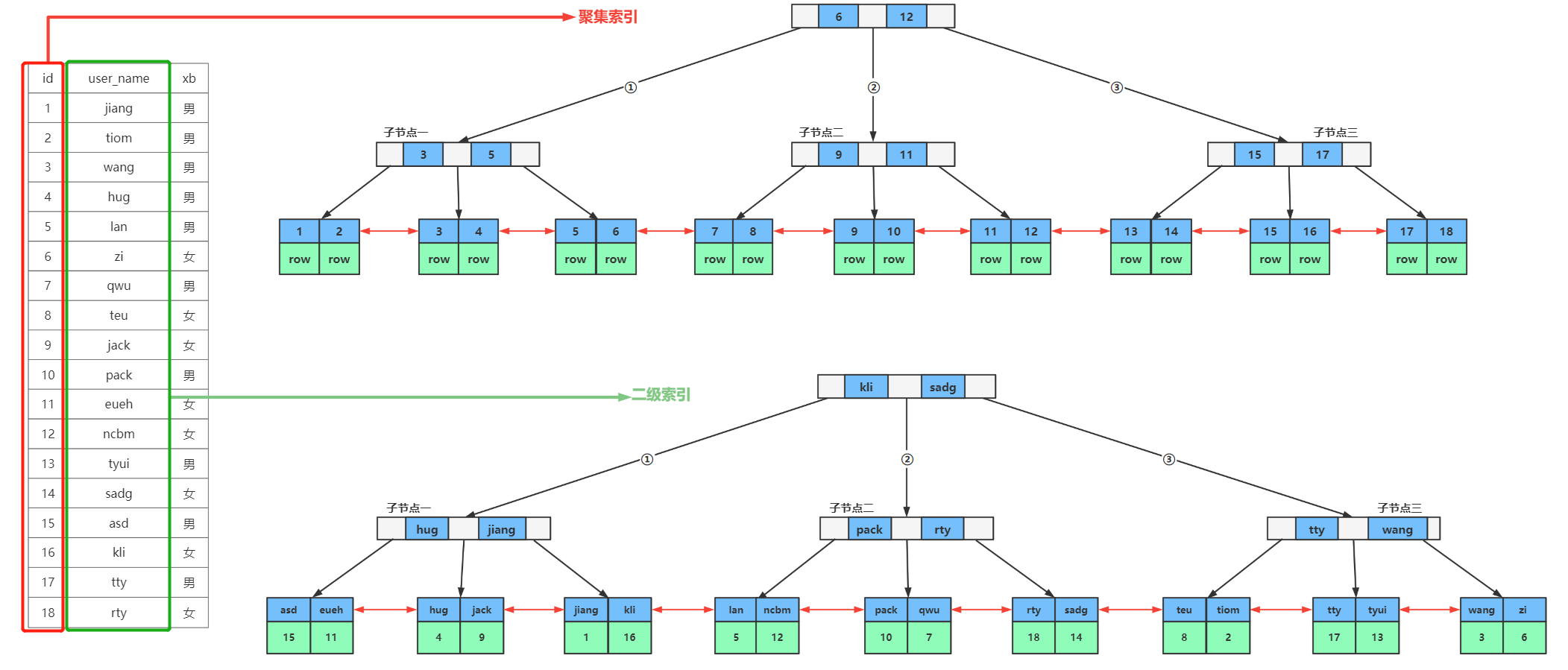
2.1.聚集索引和二级索引的概念
在InnoDB存储引擎中,根据索引的存储形式还可以进行分类:
- 聚集索引(Clustered Index) - 聚集索引主要是将完整的数据存储和索引都放在了一起,在索引结构的叶子节点中保存了该行的所有数据。- 简单理解,聚集索引就是保存了索引字段以及完整一行的所有数据。- 聚集索引必须要存在,并且只能包含一个,如果没有聚集索引,就无法找到要查询数据的完整数据内容。
- 二级索引(Secondary Index) - 二级索引是将数据和索引分开存储,主要保存索引部分,在索引结构的叶子几点中由索引去关联一条数据中的主键。- 简单来理解,二级索引在索引结构中包含索引和数据的主键字段,找到主键后,再通过回表查询的方式关联聚集索引中对应的主键,最后拿到完整的一行数据。- 二级索引可以存在多个。- 我们手动创建的索引都是二级索引。
我们之前创建表的时候,都没有指定聚集索引和二级索引,依然能够正常写入数据,这就要说说聚集索引的选举规则了。
- 如果表中有主键字段,那么主键索引就是聚集索引。
- 如果不存在主键,但是有唯一索引的情况下,第一个唯一索引将会作为聚集索引。
- 如果表中既没有主键也没有唯一索引,那么InnoDB会自动生成一个rowid作为隐藏的聚集索引。
聚集索引和二级索引是相辅相成、互相配合的一种使用方式。
聚集索引中包含索引的数据和表中某一行的所有数据,索引会有关联的某一行数据进行对应。
二级索引包含的主要是索引的数据,根据索引信息在二级索引的叶子节点中找到要关联数据的主键字段,将这个主键字段通过回表查询方式与聚集索引中一行数据的主键去关联, 最终拿到完整的一行数据。
2.2.聚集索引和二级索引的结构图
如下图所示,包含聚集索引和二级索引的结构。
1)聚集索引
左侧表中id一列被设置成了主键,这一列也就成为了表中的主键索引,根据选举规则,id一列会被选举为表中中的聚集索引,聚集索引的结构是一个B+Tree的数据结构,非叶子节点保存的是索引信息,每个key元素对应的就是id一列在字段值,叶子节点包括了索引的信息以及索引值所关联的表中一整行的数据。
聚集索引在一个表中只能包含一个。
聚集索引中叶子节点包含的数据是:
2)二级索引
我们给表中某列所创建的索引都是二级索引,我们为user_name一列创建了索引,这个索引就是二级索引,二级索引的结构也是B+Tree的数据结构,非叶子节点和聚集索引的结构一样,只包含索引的信息,在叶子节点中则包含所有的索引信息,以及索引所关联数据的主键字段,这种结构的都是二级索引的结构。
二级索引中叶子节点包含的数据是:索引所关联数据的主键字段的内容。
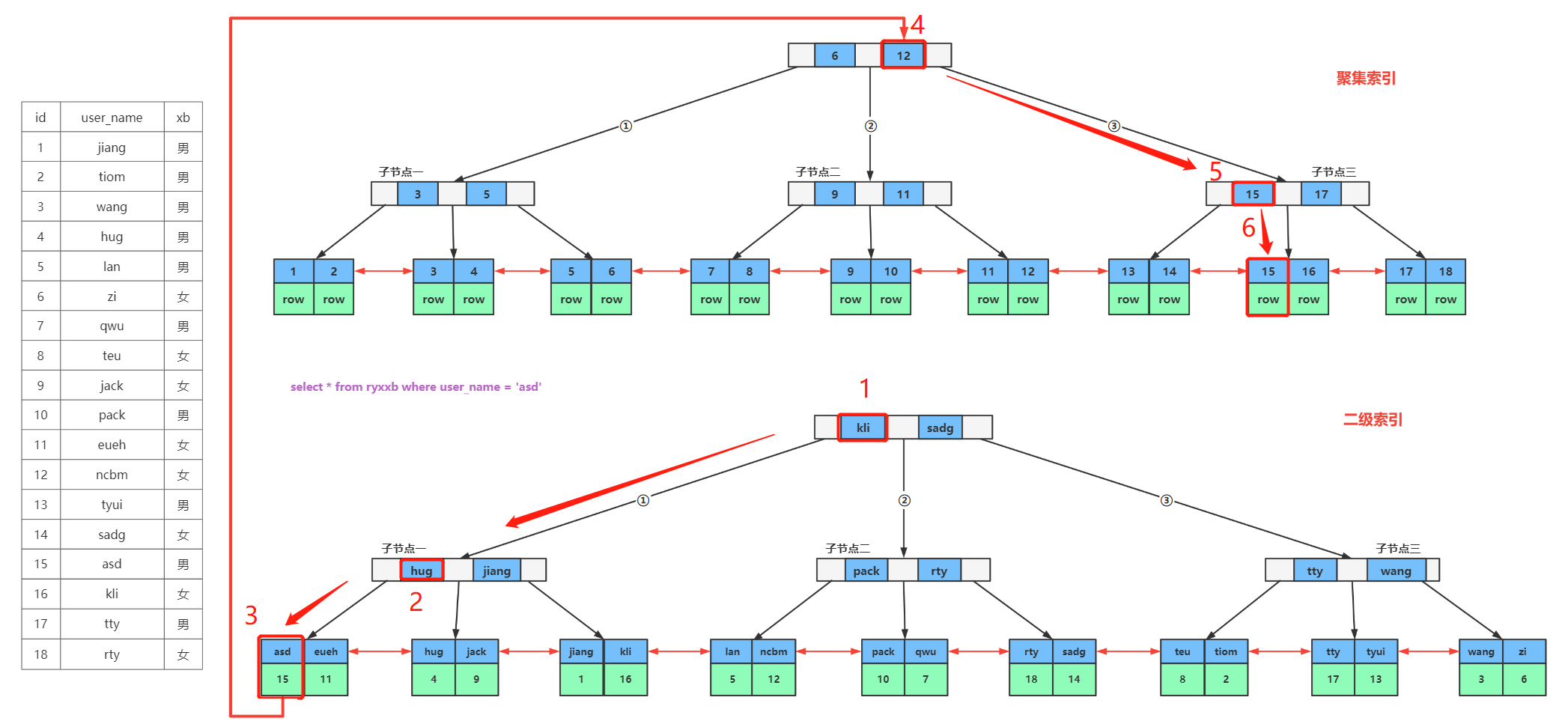
2.3.条件为索引字段的查询流程
查询user_name为asd的人员信息。
1)我们查询的条件是user_name这一列,这一列对应的是二级索引,因此首先回去二级索引中查询。
2)首先从最上面的节点开始检索,asd比kli小,走左侧节点,asd比hug小,依旧走左侧节点,最后找到了叶子节点中的asd元素,此时就可以取到asd元素索引关联数据中对应的主键字段了。
3)拿到主键字段的值后通过回表查询的方式找到聚集索引,主键字段的值是15,15比最上层节点的12要大,因此走右侧节点,一直深层往下检索,最后找到叶子节点中元素为15的索引,获取该索引关联的一行完整数据,最后返回给用户。
3.思考题
前面讲解完聚集索引和二级索引,一起来思考几个问题。
3.1.以下两条SQL,那个执行的效率高?
A:select * from ryxxb where id = 10 ;
B:select * from ryxxb where user_name = ‘asd’ ;
id字段是主键索引,user_name字段是二级索引。
答案是不用想一定是A。
原因:A语句是直接以主键id去查询的,主键索引在InnoDB中属于聚集索引结构,聚集索引结构在最上层,查询的时候会先找聚集索引进行筛选,因此A语句的查询速率是最快的,而B语句是根据user_name字段查询的,user_name字段是二级索引,二级索引的查询顺序是先检索完二级索引拿着主键ID去聚集索引中查询,多了一层,因此效率要比A语句慢。
3.2.InnoDB主键索引的B+Tree结构的高度有多高?
这个问题其实就是想计算出一个节点+一个子节点,能够承载多少个索引key元素,能够包含多少条数据,通过几步检索能够获取数据。
首先我们先来分析InnoDB B+Tree索引结构,在非叶子节点中,只包含索引数据,也就是索引元素,任何节点都是依托于页之上的,一个页的大小为16k,这是一个固定的值。
假如表中一行数据的大小为1k,那么一个页中可以存储16行这样的数据,无论是叶子节点还是非叶子节点,都包含指针,一个指针会占用6个字节的空间,主键索引一般都是数字类型的,int占用6字节,bigint占用8个字节。
我们不需要考虑叶子节点能承载多少个数据和索引元素,因为很明显,如果一行数据是1k,那么一个叶子节点也就能存放16条数据,还包括指针占用的空间,都会存储在页上,一个页只有16k。
我们想要计算出一个节点+一个子节点能包含多少个索引key元素,只需要计算非叶子节点即可。
一个节点+一个子节点高度就是2,计算公式如下:
n *8+(n +1)*6=16*1024
n的值约为1170
索引元素占用的空间+指针占用的空间=节点空间
其中n就表示能存放多少个索引key元素(设key的值为n),8表示主键使用的数据类型是bigint字节是8个。
- 计算页的总大小:一个节点依托于页,大小为16M,那么这个节点的空间就是
16X1024。 - 我们要计算能容纳key的个数,就可以设key为数学方程中的x,这里以n表示,设key的数量为n个,一个key占8个字节,那么就是
nX8。 - 指针个数是key的个数+1,一个指针占用6个字节,那么就是(n+1)X6,从而计算出指针所占用的空间。
key所占的空间+指针所占的空间=页总空间的大小,解方程之后,n的值就是1170,也就是说在高度为2,只包含一个节点和一个子节点的情况下,可以容纳1170个索引元素。
下面来计算高度为2的索引结构中,所能包含的多少条数据。
在叶子节点下,一条数据为1k,一个叶子节点能够承载16条数据,刚刚计算出来的1170个索引元素是要完全指向叶子节点的,也就是说每个叶子节点中都会包含至少16条数据,索引元素指向数据时通过指针的,所以用指针(1170+1)乘以16就可以计算出高度为2的索引结构能够容纳的数据条目,大约是18736条。
下面来计算高度为3的索引结构中,所能包含的多少条数据。
高度为2的结构中,包含一个非叶子节点和一个叶子节点,飞叶子节点中能容纳1170个索引元素。
高度为3的结构中,会包含2个非叶子节点和一个叶子节点,只有最下层的节点是叶子节点,1个非叶子节点能容纳1170个索引元素,那么2个非叶子节点就能容纳个1171X1171个索引元素,因为2个非叶子节点各自都能容纳1170个索引元素,每一个子节点需要指向另外的子节点,因此所能容纳的索引个数就是1171X1171个。
计算出容纳的索引元素个数后,乘以每个叶子节点所能容纳的数据条目,最终计算出高度为3的索引结构可以包含21939856条数据。
两千万条数据通过3层检索就可以获取到数据,效率肉眼可见的高。
版权归原作者 Jiangxl~ 所有, 如有侵权,请联系我们删除。