
一.Spark内存
在执行 Spark 的应用程序时,Spark 集群会启动 Driver 和 Executor 两种JVM进程。
Driver 程序主要负责:
- 创建 Spark上下文;
- 提交 Spark作业(Job)并将 Job 转化为计算任务(Task)交给 Executor 计算;
- 协调各个 Executor 进程间任务调度。
Executor 程序主要负责:
- 在工作节点上执行具体的计算任务(Task),并将计算结果返回给 Driver;
- 为需要持久化的 RDD 提供存储功能。
二.Executor内存管理
Executor 进程作为一个 JVM 进程,其内存管理建立在 JVM 的内存管理之上,整个大致包含两种方式:堆内内存和堆外内存。

一个Executor中包含多个task,一个 Executor 当中的所有 Task 是共享堆内内存的。一个 Work 中的多个 Executor 中的多个 Task 是共享堆外内存的。
默认的 Spark 是开启堆内内存的,配置参数:--executor-memory 指定的就是堆内内存大小。堆外内存默认不开启。
1.堆内内存管理
堆内内存的大小,由 Spark 应用程序启动时的
executormemory
或
spark.executor.memory
参数配置。
Executor 内运行的并发任务共享 JVM 堆内内存,这些任务在缓存 RDD 数据和广播(Broadcast)数据时占用的内存被规划为存储(Storage)内存,而这些任务在执行 Shuffle 时占用的内存被规划为执行(Execution)内存,剩余的部分不做特殊规划,那些 Spark 内部的对象实例,或者用户定义的 Spark 应用程序中的对象实例,均占用剩余的空间。不同的管理模式下,这三部分占用的空间大小各不相同
Spark 内存管理分为静态内存管理和统一内存管理,在 Spark 1.6 之前是采用的静态内存,之后的版本都是采用统一内存管理,与静态内存管理的区别在于 Storeage 内存和 Execution 内存共享统一块空间,可以动态占用对方的空闲区域。
Spark 统一内存模型:
- Storage 内存:主要用于存储 Spark 的 cache 数据,例如 RDD 的 cache,Broadcast 变量,Unroll 数据等。需要注意,unrolled 的数据如果内存不够,会存储在 driver 端。
- Execution 内存:用于存储 Spark task 执行过程中需要的对象,如 Shuffle、Join、Sort、Aggregation等计算过程中的临时数据。
- User 内存:分配 Spark Memory 剩余的内存,用户可以根据需要使用,可以存储 RDD transformations 需要的数据结构。
- Reserved 内存:这部分内存是预留给系统用的,固定不变。
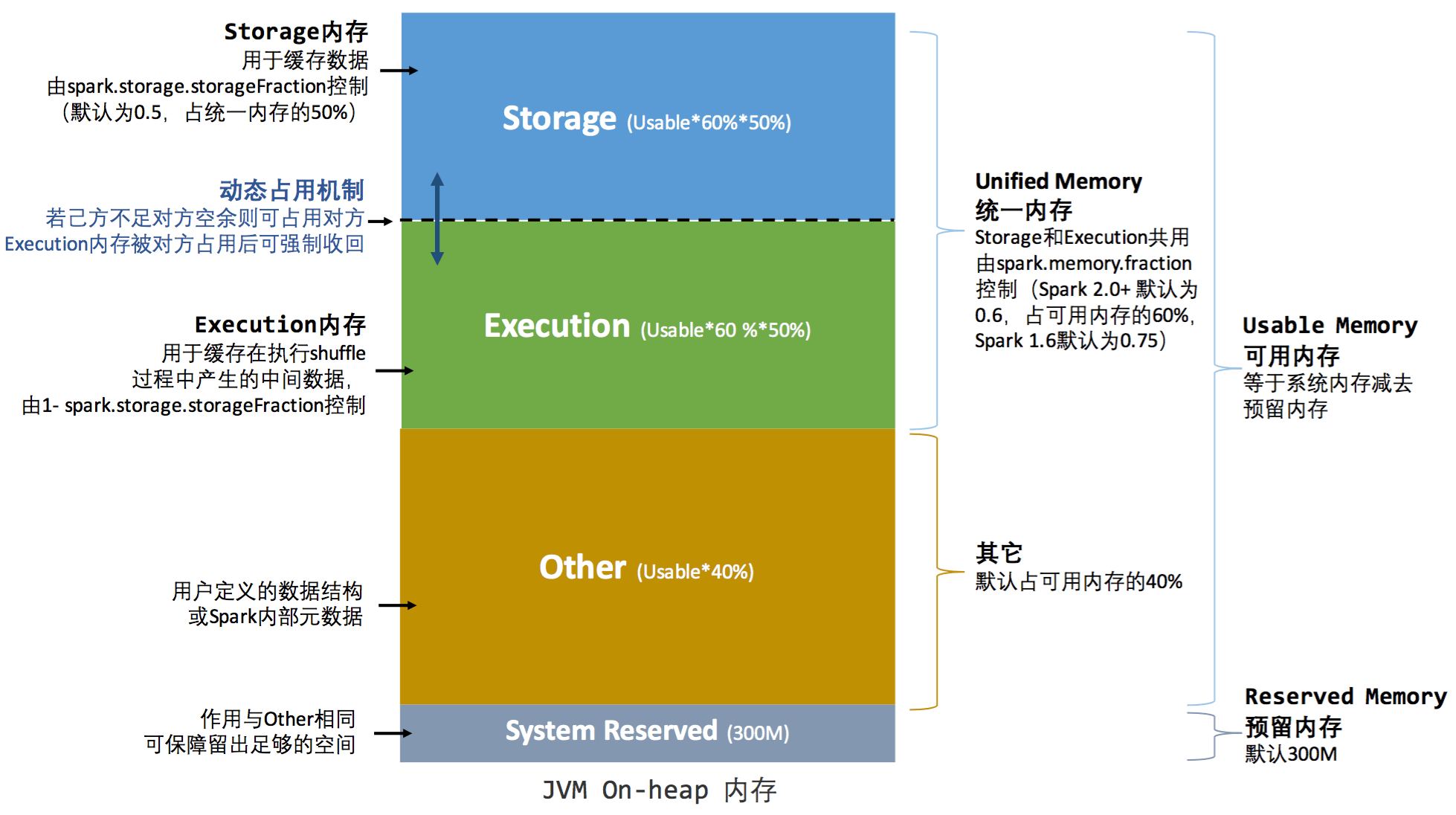
动态占用机制
- 在程序提交时,会根据spark.memory.storageFraction参数设置Storage内存区域和Execution内存区域。
- 在程序运行时,如果双方的空间不不足(存储空间不足以放下一个完整的Block),则按照LRU规则存储到磁盘;如果己方空间不足而对方空间有空余,则借用对方的空间。
- Storage占用对方内存,可将占用的部分转存到硬盘,然后”归还”借用的空间(Storage占用Execution内存,Execution需要使用被占用的内存时,会将存储在Execution中数据写入磁盘,归还占用的内存空间)。
- Execution占用对方内存,目前的实现是无法让对方”归还”的。因为Shuffle过程产生的文件在后面一定会被使用到,而Cache在内存的数据不一定在后面使用,归还内存可能会导致性能严重下降。
内存指定参数
备注
spark.memory.fraction
设置统一内存占堆内内存的占比
spark.memory.fraction=0.6
spark.memory.storageFraction
设置Execution内存占堆内内存的占比
spark.memory.storageFraction=0.5
2.2 堆外内存
为了进一步优化内存的使用以及提高 Shuffle 时排序的效率,Spark 引入了堆外(Off-heap)内存,使之可以直接在工作节点的系统内存中开辟空间,存储经过序列化的二进制数据。堆外内存意味着把内存对象分配在 Java 虚拟机的堆以外的内存,这些内存直接受操作系统管理(而不是虚拟机)。这样做的结果就是能保持一个较小的堆,以减少垃圾收集对应用的影响。
在默认情况下堆外内存并不启用,可通过配置 spark.memory.offHeap.enabled(true/false) 参数启用,并由spark.memory.offHeap.size(单位MB) 参数设定堆外空间的大小。除了没有 other 空间,堆外内存与堆内内存的划分方式相同如下图所示(以统一内存管理机制为例),所有运行中的并发任务共享存储内存和执行内存。
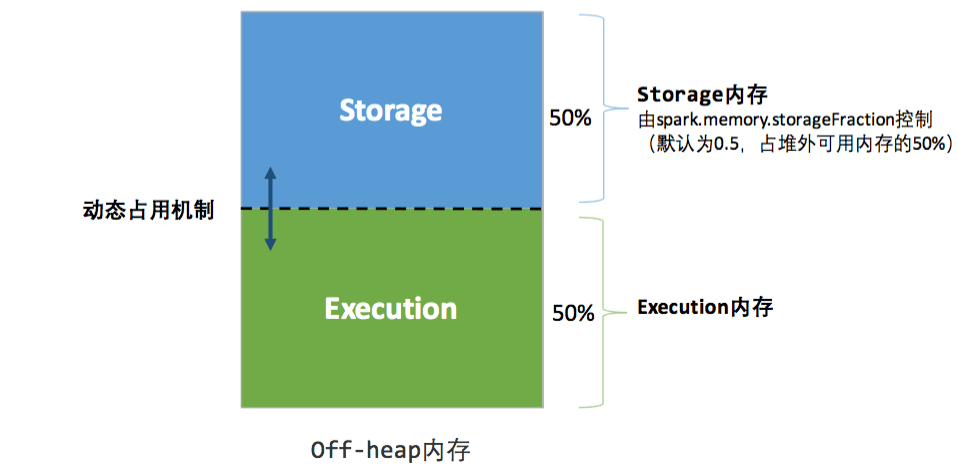
堆外内存分配参数:
spark.executor.memoryOverhead=3072 单位为MB
在spark 2.3 之前,参数命令为: spark.yarn.executor.memoryOverhead
spark.memory.offHeap.size 和spark.executor.memoryOverhead 都可以用于设置堆外内存,但实际是有差别的。
spark.memory.offHeap.size 真正作用于spark executor的堆外内存 spark.executor.memoryOverhead 作用于yarn,通知yarn使用堆外内存和使用内存的大小,相当于spark.memory.offHeap.size + spark.memory.offHeap.enabled,设置参数的大小并非实际使用内存大小
参考:
Spark 内存管理模型详解 - 走看看
Spark参数spark.executor.memoryOverhead与spark.memory.offHeap.size的区别_spark offheap 和overhead区别-CSDN博客
版权归原作者 Tom无敌宇宙猫 所有, 如有侵权,请联系我们删除。