
YoloV8详细训练教程.
相信各位都知道yolov8发布了,也是U神大作,而且V8还会出论文喔!
2023.1.17 更新 yolov8-grad-cam热力图可视化链接

2023.1.20 更新 YOLOV8改进-添加EIoU,SIoU,AlphaIoU,FocalEIoU 链接
2023.1.30 更新 如果你需要修改或者改进yolov8的代码 务必请看这个视频链接 因为修改代码需要用另外一种方式去使用yolov8,不可以把yolov8的代码装到python环境里面。 并支持同时使用yaml初始化模型并载入预训练权重!
2023.1.30 更新 B站教学视频链接 YOLOV8改进-添加注意力机制 附带几十种注意力机制代码.
2023.2.8 更新 B站教学视频链接 YOLOV8改进-添加Wise-IoU.
2023.2.12 更新 B站教学视频链接 YOLOV8改进-添加可变形卷积(DCNV2).
2023.2.16 更新 B站教学视频链接 YOLOV8重大更新-支持目标跟踪.
2023.2.26 更新 B站教学视频链接 YOLOV8教程-resume继续上一次的训练.
2023.2.26 更新 B站教学视频链接 可视化并统计预测结果的TP,FP,FN
2023.2.26 更新 B站教学视频链接 YOLOV8重大更新-支持Anchor-Free YOLOV5结构并make great again!!!
重磅!!!!! YOLO模型改进集合指南-CSDN
YoloV8精度和结构和改动简介
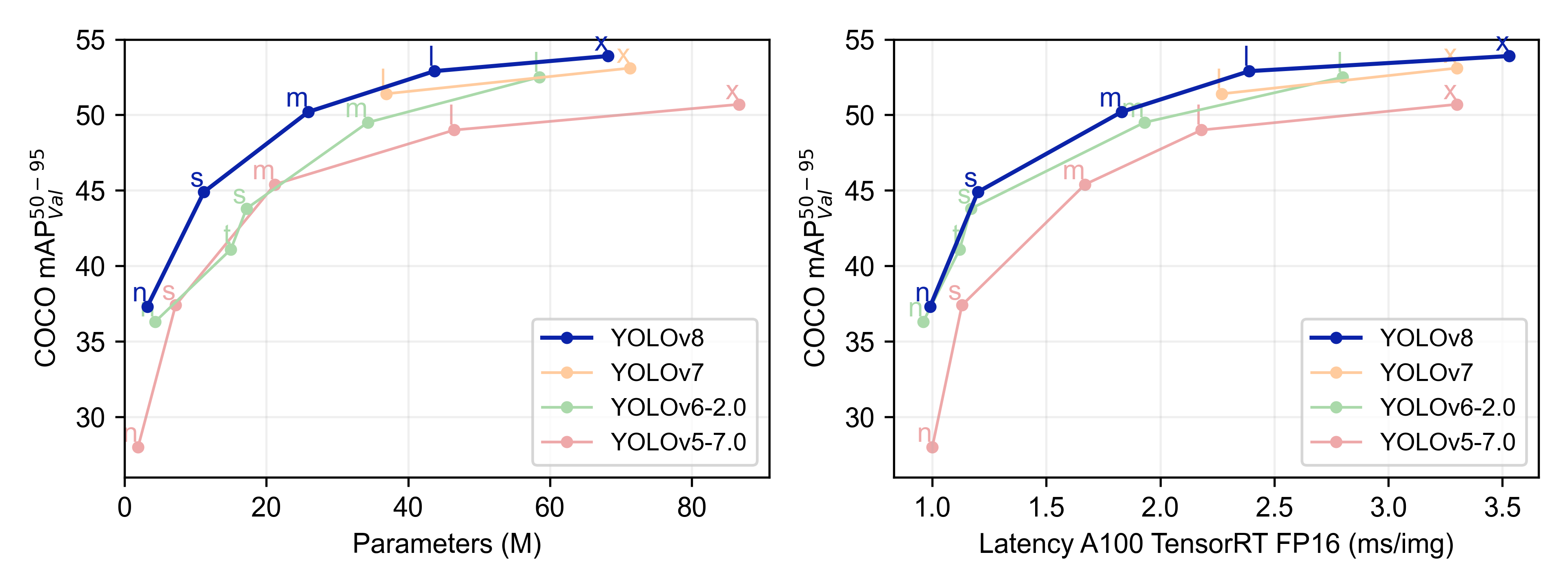
YoloV8精度对比:
Yolov8结构图:
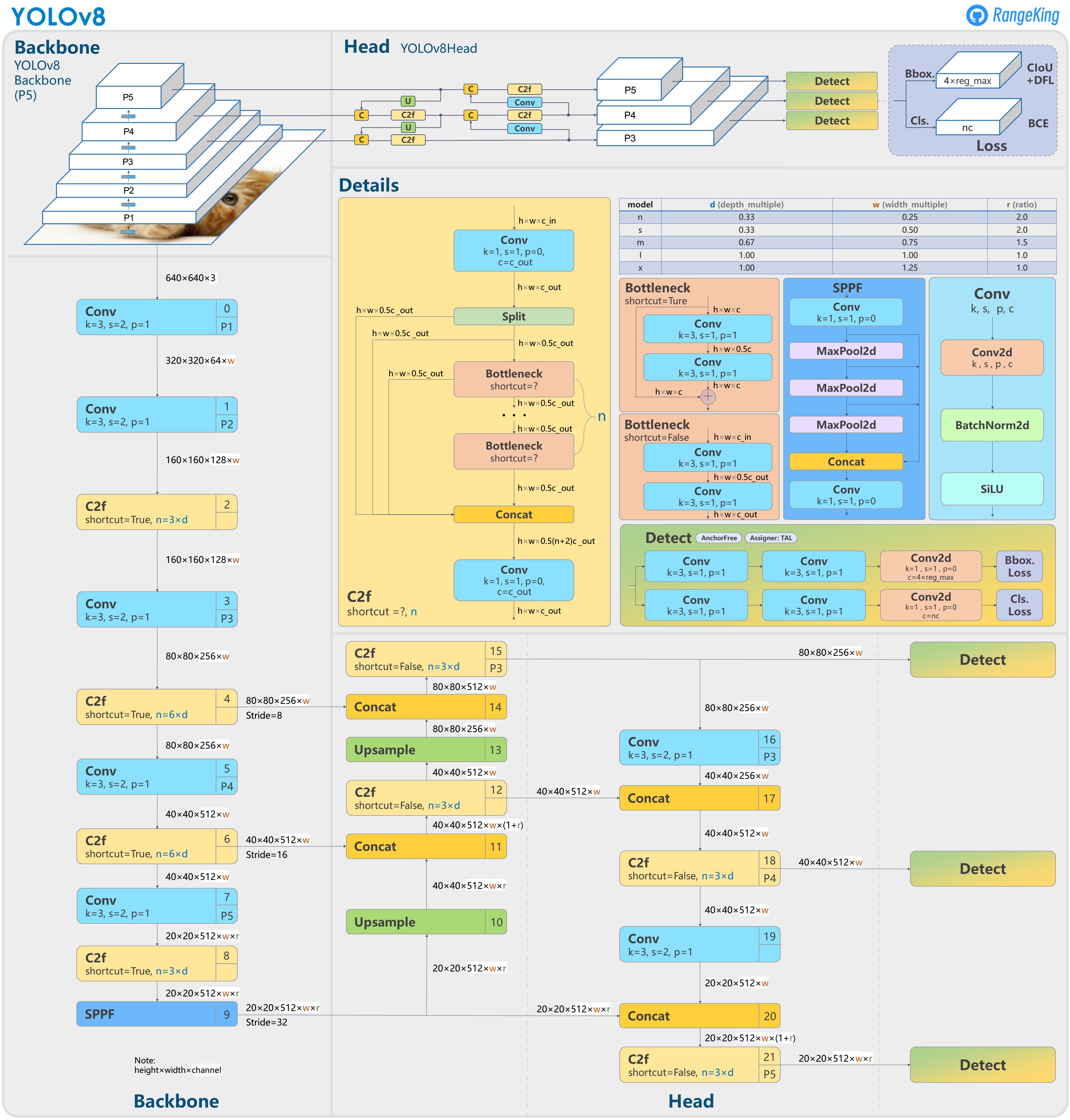
YoloV8相对于YoloV5的改进点:
- Replace the C3 module with the C2f module.
- Replace the first 6x6 Conv with 3x3 Conv in the Backbone.
- Delete two Convs (No.10 and No.14 in the YOLOv5 config).
- Replace the first 1x1 Conv with 3x3 Conv in the Bottleneck.
- Use decoupled head and delete the objectness branch.
- anchor free.
重点来了!如何训练我们的yolov8模型?
哔哩哔哩Yolov8视频教学地址(配合本博文,包你秒懂!) (不用修改yolov8 纯使用的话 看这个)
1. 下载源码和准备数据集
代码链接:yolov8_github,本次其github的名字没有直接命名为yolov8。
数据集本次博主准备了一个小数据集,关于口罩目标检测数据集,数据集方面只要是voc和yolo格式都可以,下面会有转换脚本的示例。那么各位看官使用自己的数据集就可以,我这里就不提供下载我的数据集了(偷个懒!)。
2. 配置环境(yolov8从0开始安装环境哔哩哔哩视频教学地址)
- 首先推荐使用anaconda作为你的python环境,代码工具可以使用vscode或者pycharm,这个根据使用者爱好,这边我使用的是pycharm,那么这里默认各位已经准备好anaconda和(vscode或者pycharm),不会安装的话可以百度一下,这方面的教程都非常丰富。
- 安装torch和torchvision 你可以在这个pytorch官网中找到对应的安装命令,这里版本要求推荐torch==1.12.0+,下面贴出torch==1.12.0的各项安装命令,各位看官可以根据自己的电脑情况进行选择CUDA 11.6 pip install torch==1.12.0+cu116 torchvision==0.13.0+cu116 --extra-index-url https://download.pytorch.org/whl/cu116**CUDA 11.3** pip install torch==1.12.0+cu113 torchvision==0.13.0+cu113 --extra-index-url https://download.pytorch.org/whl/cu113**CUDA 10.2** pip install torch==1.12.0+cu102 torchvision==0.13.0+cu102 --extra-index-url https://download.pytorch.org/whl/cu102**CPU only** pip install torch==1.12.0+cpu torchvision==0.13.0+cpu --extra-index-url https://download.pytorch.org/whl/cpu
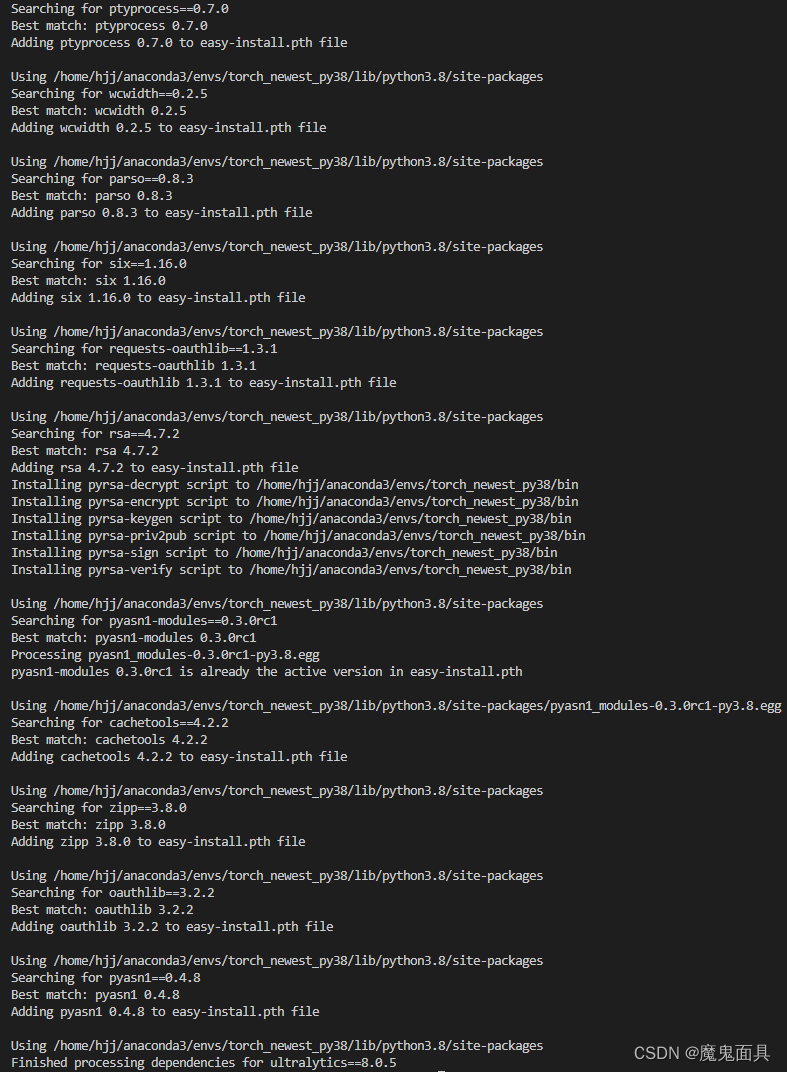
- 在代码目录下运行python setup.py install. 运行后其会安装一些其依赖的包,会输出比较多的信息,怎么判断自己是否安装成功,主要是看最后输出是否有Finished processing dependencies for ultralytics即可.
3. 处理数据集
本博主的github上有适用于yolov3,v5,v7,v8的数据集转换脚本,其使用教程如下:
VOC标注格式数据集使用示例
- 把图片存放在dataset\VOCdevkit\JPEGImages中,图片后缀需要一致,比如都是jpg或者png等等,不支持混合的图片后缀格式,比如一些是jpg,一些是png。
- 把VOC标注格式的XML文件存放在dataset\VOCdevkit\Annotations中。
- 运行xml2txt.py,在这个文件中其会把Annotations中的XML格式标注文件转换到txt中的yolo格式标注文件。其中xml2txt.py中的postfix参数是JPEGImages的图片后缀,修改成图片的后缀即可,默认为jpg。比如我的图片都是png后缀的,需要把postfix修改为png即可。其中运行这个文件的时候,输出信息会输出你的数据集的类别,你需要把类别列表复制到data.yaml中的names中,并且修改nc为你的类别数,也就是names中类别个数。
- 运行split_data.py,这个文件是划分训练、验证、测试集。其中支持修改val_size验证集比例和test_size测试集比例,可以在split_data.py中找到对应的参数进行修改,然后postfix参数也是你的图片数据集后缀格式,默认为jpg,如果你的图片后缀不是jpg结尾的话,需要修改一下这个参数。
YOLO标注格式数据集使用示例
- 把图片存放在dataset\VOCdevkit\JPEGImages中,图片后缀需要一致,比如都是jpg或者png等等,不支持混合的图片后缀格式,比如一些是jpg,一些是png。
- 把YOLO标注格式的TXT文件存放在dataset\VOCdevkit\txt中。
- 运行split_data.py,这个文件是划分训练、验证、测试集。其中支持修改val_size验证集比例和test_size测试集比例,可以在split_data.py中找到对应的参数进行修改,然后postfix参数也是你的图片数据集后缀格式,默认为jpg,如果你的图片后缀不是jpg结尾的话,需要修改一下这个参数。
- 在data.yaml中的names设置你的类别,其为一个list,比如我的YOLO标注格式数据集中,0代表face,1代表body,那在data.yaml中就是names:[‘face’, ‘body’],然后nc:2,nc就是类别个数。
VOC数据集操作示例
本博主准备的是voc标注格式的数据集,我们先把图片和VOC标注文件放到以下两个文件夹中: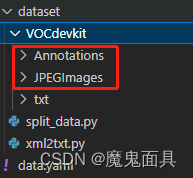
然后运行xml2txt.py,其中这个文件有一个postfix参数,其为你图像的后缀格式,默认为jpg,如果你的图像是bmp或者png可以修改这个参数,当然其不支持混合的后缀格式,其会导致输出文件找不到的错误信息,这个请大家注意!运行后会输出以下: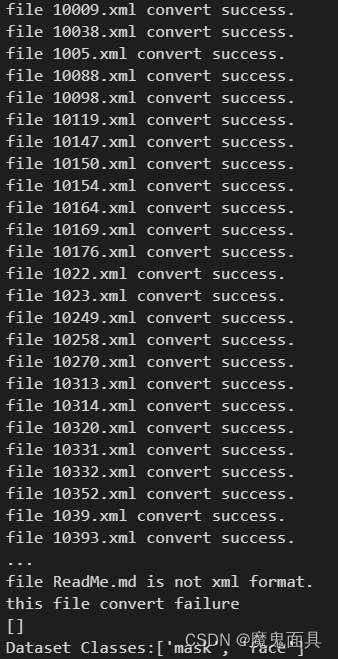
我们需要把最后的输出[‘mask’, ‘face’]复制到data.yaml的names中,并且nc修改为自己数据集的类别数,也就是names列表的长度,本数据集为2.如下所示: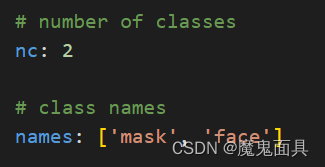
而且你会发现在dataset/VOCdevkit/txt里面会生成了对应的yolo格式的标注文件
YOLO数据集操作教程
对于yolo标注格式的数据集,我们直接把图像和对应的yolo标注文件放到dataset\VOCdevkit\JPEGImages和dataset\VOCdevkit\txt即可,然后在data.yaml中填写自己数据集的类别对应关系和类别数量即可。
分割数据集
无论对于VOC格式数据集还是YOLO格式数据集,按照上述步骤处理好后运行split_data.py,这个文件也有一个postfix参数,默认为jpg,如果自己的数据集不是jpg后缀的话,请自行修改,当然不支持混合后缀格式,请大家注意!split_data.py中还有val_size,test_size参数,其为比例系数,默认为0.1,0.2,如有需要请自行修改。运行成功后,其会自动创建下图这些文件夹,然后把对应的图片和标签文件复制到对应的文件夹中。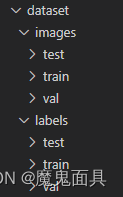
当你完成这一步的时候,数据集就处理完成。
4. 训练
训练过yolov5的都清楚,其会有一些配置文件和参数,但是这次v8稍有不同,其参数全部都存到一个yaml配置文件里面,就是其train.py是没有参数可以调整的,只需要在那个yaml配置文件里面进行修改即可,其路径为:ultralytics/yolo/configs/default.yaml,接下来对一些重点的参数进行讲解:
- model pt模型路径或者yaml模型配置文件路径。这次的v8稍有不同,这个model参数可以是pt也可以是yaml。 1. pt 相当于使用预训练权重进行训练,比如选择为yolov8n.pt,就是训练一个yolov8n模型,并且训练前导入这个pt的权重。2. yaml 相当于直接初始化一个模型进行训练,比如选择为yolov8n.yaml,就是训练一个yolov8n模型,权重是随机初始化。
- data 数据配置文件的路径,也就是第三点中的data.yaml。
- epochs 训练次数。
- patience 在精度持续一定epochs没有提升时,过早停止训练。也就是早停机制。
- batch batch size大小。
- imgsz 输入图像大小。
- save 是否保存模型。
- cache 是否采用ram进行数据载入,设置True会加快训练速度,但是这个参数非常吃内存,一般服务器才会设置。
- device 所选择的设备训练。
- workers 载入数据的线程数。windows一般为4,服务器可以大点,windows上这个参数可能会导致线程报错,发现有关线程报错,可以尝试减少这个参数,这个参数默认为8,大部分都是需要减少的。
- project project name.一个保存文件夹的名字,一般不用改动。
- name 训练保存的文件夹名字。
- exist_ok 是否覆盖现有的保存文件夹。
- pretrained 是否使用预训练模型,这个参数我并没有使用,因为在model参数中我直接设置pt模型路径。
- optimizer 优化器选择。直接SGD、Adam、AdamW、RMSProp。
- verbose 是否打印详细输出。
- seed 随机种子。
- deterministic 设置为True,保证实验的可复现性。
- single_cls 如果你的数据集是多类别,这个参数设置为True的话,其会当做一个类别来进行训练,相当于只负责识别目标,不负责识别类别。
- image_weights 使用加权图像选择进行训练。
- rect 是否采用矩形训练。这个参数不好解释,想了解的同学可以自行百度。
- cos_lr 是否采用cor lr调度器。
- close_mosaic 默认值为10,意思就是在最后10个epochs关闭马赛克数据增强,其思想来源于YOLOX。
- resume 是否继续上一次没完成的训练。
这次的yolo训练实在是太惊艳了,就是你只需要修改配置文件,其中在配置文件中有一个task和mode的参数,task就是选择detect,我们这边做的是目标检测,mode的话,你训练就是选择train,然后运行
yolo cfg=ultralytics/yolo/configs/default.yaml
即可开始训练,太好用了!示例如下: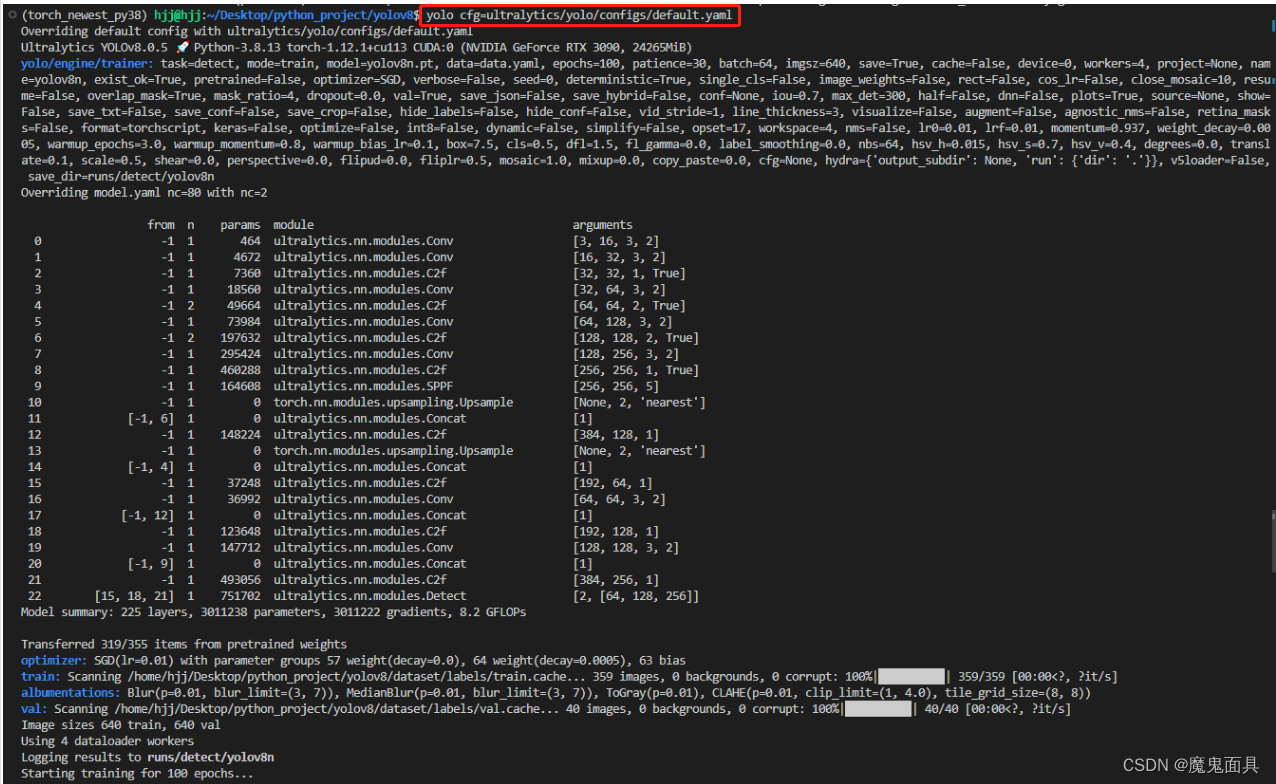
然后就开始训练,下面贴点训练过程输出的图: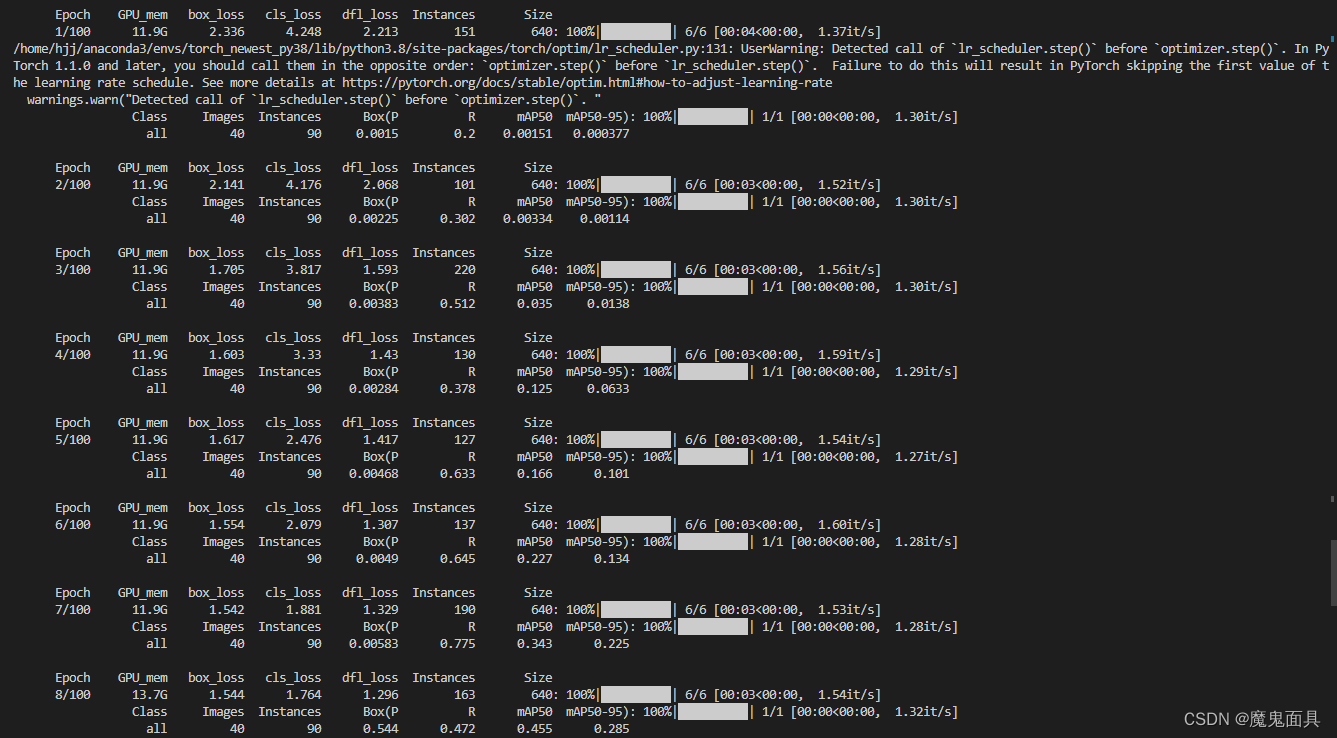
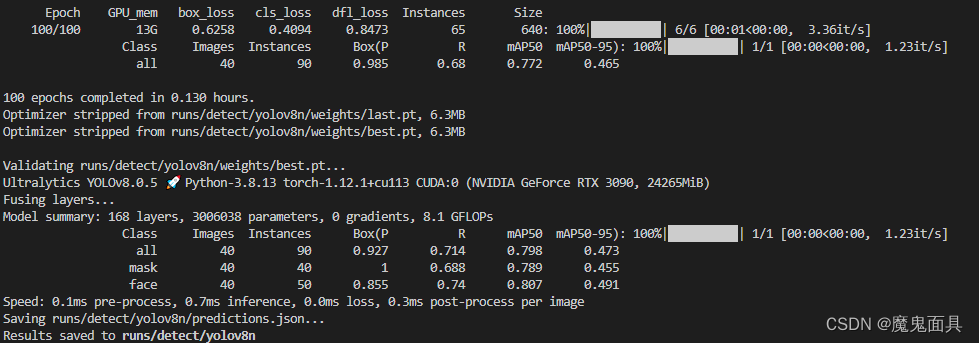
4. 测试
这次YOLOV8的测试参数比之前的少,其解释如下:
- val 我的理解是:设置为True就是计算验证集指标,设置为False就是计算测试集指标 但是我测试的时候无论是True或者False都是计算验证集,可能是一个bug,毕竟刚出不久,代码架构改动这么大,期待后续更新。
- save_json 是否把结果保存为json file。
- save_hybrid 是否把结果保存为hybrid version of labels。这个我也不知道什么来的,没用过,大家可以设置为True看看,估计就是一种保存的格式。
- conf 置信度。
- iou iou阈值。
- max_det 最大检测数量。
- half 是否使用fp16测试。
- dnn 使用opencv的dnn进行onnx推理。
- plots 配置文件中给的注释是show plots during training,有兴趣可以设置为True和False对比一下。 需要注意的是需要把mode改为val,然后Train settings中的model参数修改为你训练保存的模型文件,如下:
 验证集测试结果如下:
验证集测试结果如下:
5.推理
推理部分参数解释:
- source 这个参数跟之前的yolov5一致,可以输入图片路径,图片文件夹路径,视频路径。
- show 配置文件中给的解释是show results if possible,不太能理解,有兴趣可以设置为True or False进行对比看看。
- save_txt 是否把识别结果保存为txt。
- save_conf 保存为txt过程中是否保存目标的置信度。
- save_crop 是否把目标进行裁剪下来进行保存。
- hide_label 保存识别的图像时候是否隐藏label。
- hide_conf 保存识别的图像时候是否隐藏置信度。
- vid_stride 视频检测中的跳帧帧数。
- line_thickness 目标框中的线条粗细大小。
- visualize 配置文件中给的解释是visualize results,不太能理解,有兴趣可以设置为True or False进行对比看看。
- augment 是否使用测试数据增强。
- agnostic_nms 是否采用class-agnostic NMS。
- retina_masks 配置文件中给的解释是use retina masks for object detection,没了解过,有兴趣可以设置为True or False进行对比看看。
需要注意的是需要把mode改为detect,然后Train settings中的model参数修改为你训练保存的模型文件,即可进行推理: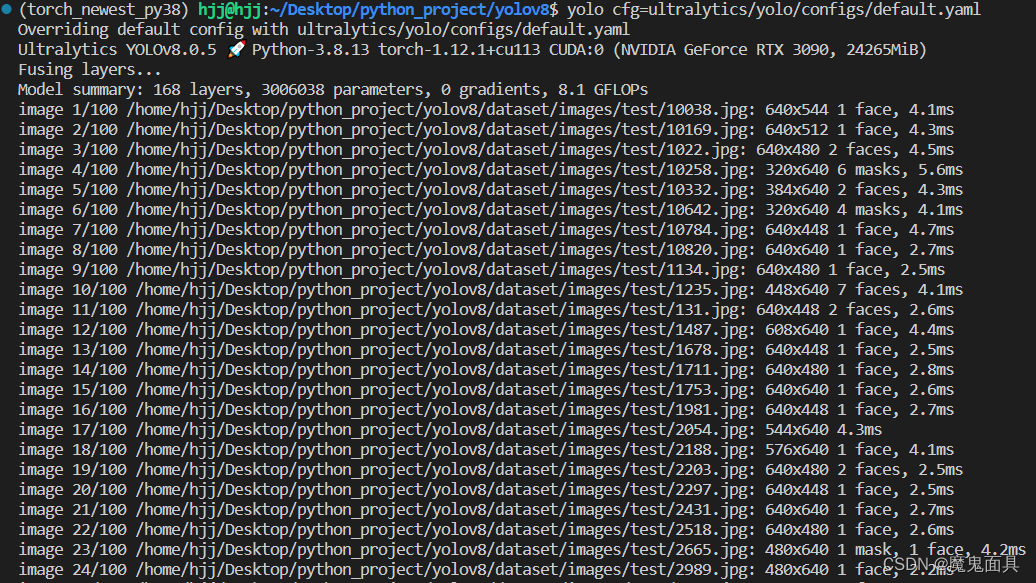
一些检测的效果图:
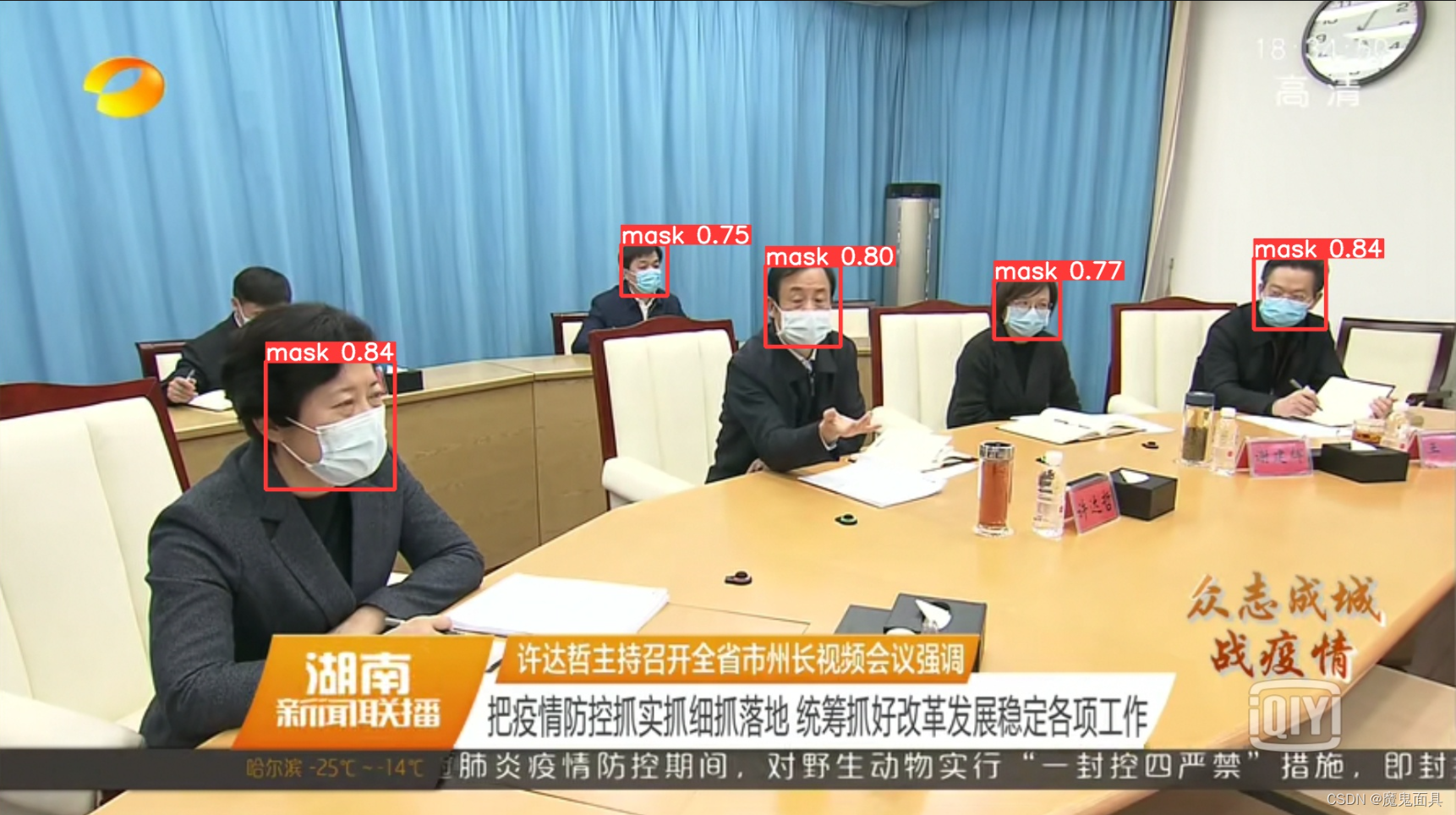

如果内容对你有帮助,麻烦点个赞,谢谢!
版权归原作者 魔鬼面具 所有, 如有侵权,请联系我们删除。