
** 对比了不同的方法, 感觉这两种方法还是不用太费劲就能下载数据,但是数据量大的话还是很慢。本人推荐用第一种因为数据格式可以转为geotif和nc,省去了hdf各种操作。**
总结:
第一种方法 AppEEARS
优点:可以选择范围,时间,变量,数据格式及投影,出来的数据就是已经拼接投影好的数据,
缺点:数据量大的话,很耗时。
第二种方法 pymodis
优点:简单易操作,工具很方便,涵盖了hdf前期处理需要的所有函数,这里只给了downmodis一个函数,其他如拼接投影啥的 都有,基本都是基于GDAL和proj.4库写的。可以去官网逛逛。
缺点:下载完还得自己拼接投影,速度也不快!
第一种方法:AppEEARS分为 point 和 area
网站:https://lpdaacsvc.cr.usgs.gov/appeears/

然后弹出该画面,选择第一个:
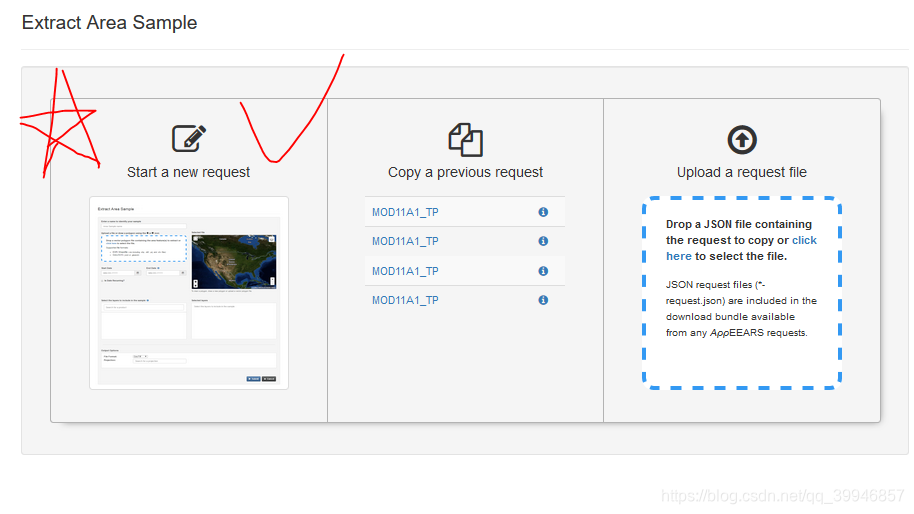
**这个是USGS自带的批量下载工具,和你下载EARTHDATA(GES CISC)上其他数据产品一样的操作,具体操作如下:**
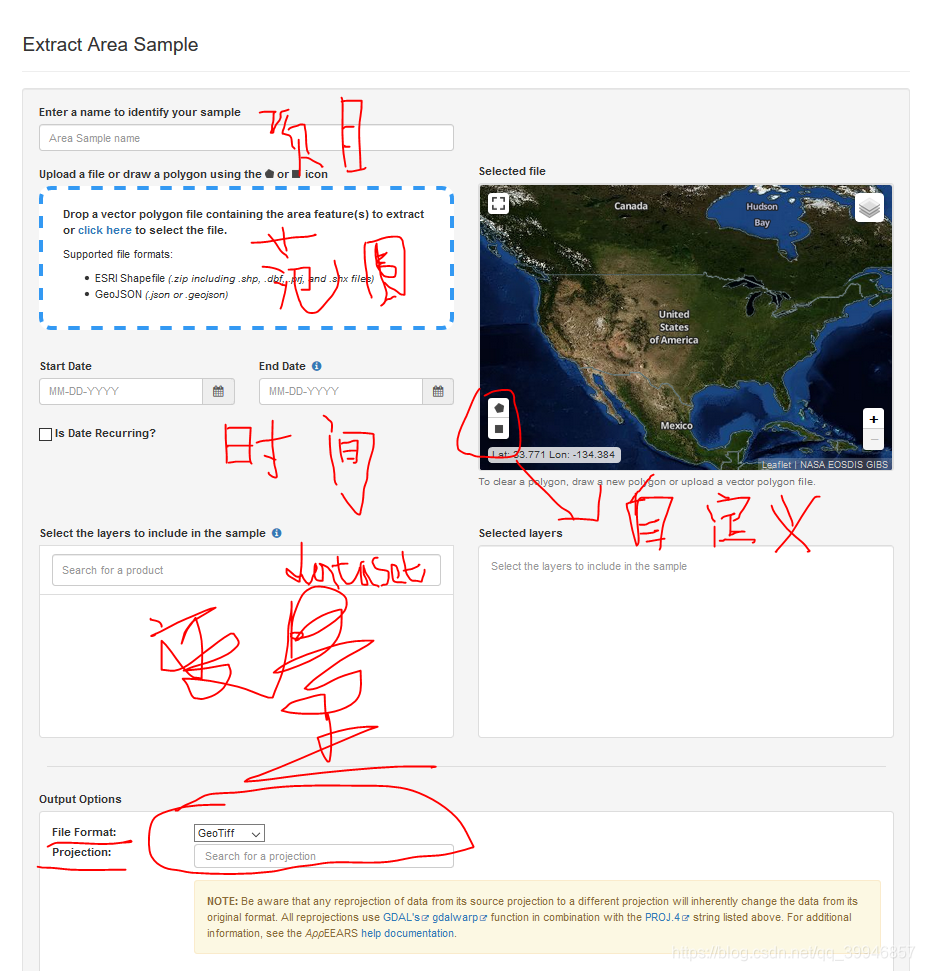
① 给下载项目取名
② 给定范围,可加载自己的shp,也可以用矩形框或者多边形框,后者是自带的
③选择时间,
④选择数据和变量
⑤选择输出格式,tif或者nc,指定投影或者地理坐标。用xarray 读写很方便
最后提交申请就行,
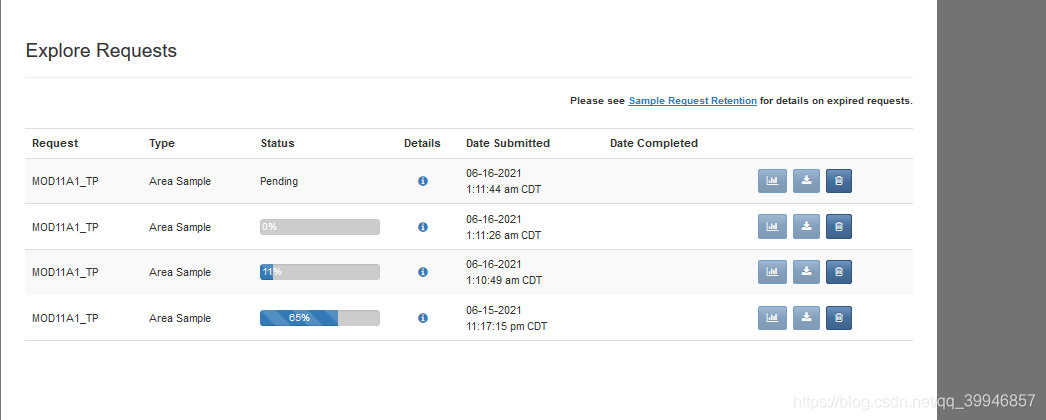
然后在explorer查看进度信息,
第二种方法:pymodis python的第三方库
**官方文档;http://www.pymodis.org/pymodis/downmodis.html **
modis_down = pymodis.downmodis.downModis(
** 下载本底的路径 destinationFolder='K:/MODIS_LST/',
EARTHDATA密码 password='xxxxxxxxxxx',
EARTHDATA用户名 user='xxxxxxxx',
数据所在地址 url='https://e4ftl01.cr.usgs.gov',
选择下载的tiles tiles=['h25v05','h25v06','h26v05','h26v06'],
数据地址和数据所在文件中间的目录 path='MOLA',
产品名称 product='MYD11A2.006',
开始时间 today='2021-05-31',
结束时间 enddate='2002-07-04',
其他默认 jpg=True,
debug=True,
timeout=30,
checkgdal=True)**
modis_down.connect() 连接数据,开始爬
modis_down.downloadsAllDay() 下载所有的数据
具体参数看文档,这里只展示代码了,很简单!
版权归原作者 维生素_A 所有, 如有侵权,请联系我们删除。