
如果不指定MapJoin或者不符合mapJoin的条件,那么HIve解析器会将Join操作转换成Common Join,也就是说在reduce阶完成Join容易发生数据倾斜。
mapJoin工作机制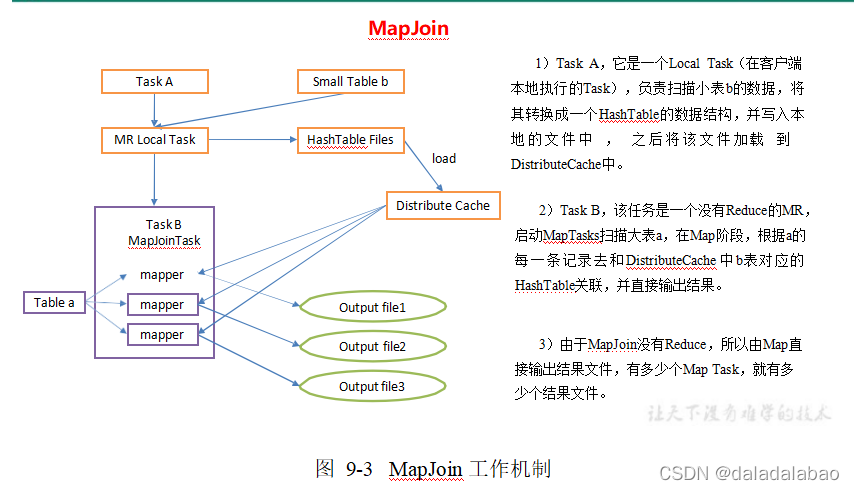
- 通过mapReduce Local Task,将小表读入到内存中生成HashTableFiles 上传到Distributed Cache中,对HashTableFiles进行压缩
- MapReduce Job在Map阶段,每个Mapper从Dristributed Cache 读取HashTableFiles 到内存,顺序扫描大表,在Map阶段直接进程Join,将数据传递给下一个MapReduce
本文转载自: https://blog.csdn.net/qq_45450889/article/details/123178353
版权归原作者 daladalabao 所有, 如有侵权,请联系我们删除。
版权归原作者 daladalabao 所有, 如有侵权,请联系我们删除。