
AI应用开发相关目录
本专栏包括AI应用开发相关内容分享,包括不限于AI算法部署实施细节、AI应用后端分析服务相关概念及开发技巧、AI应用后端应用服务相关概念及开发技巧、AI应用前端实现路径及开发技巧
适用于具备一定算法及Python使用基础的人群
- AI应用开发流程概述
- Visual Studio Code及Remote Development插件远程开发
- git开源项目的一些问题及镜像解决办法
- python实现UDP报文通信
- python实现日志生成及定期清理
- Linux终端命令Screen常见用法
- python实现redis数据存储
- python字符串转字典
- python实现文本向量化及文本相似度计算
- python对MySQL数据的常见使用
- 一文总结python的异常数据处理示例
- 基于selenium和bs4的通用数据采集技术(附代码)
文章目录
一、前言
本文所说的数据采集技术即爬虫,爬虫技术用于从互联网上抓取大量数据。这些爬虫程序能够自动化地访问网页/公众号平台、解析内容,并提取所需的信息。在大数据和机器学习等领域,爬虫技术发挥着至关重要的作用。
数据采集技术为项目提供丰富的数据资源,根据这些信息进行产品设计和创新,持续改进和优化产品。
二、环境配置
pip install beautifulsoup4
pip install selenium
安装WebDriver:Selenium需要WebDriver来与浏览器进行交互。不同的浏览器需要不同的WebDriver。例如,如果你使用的是Chrome浏览器,你需要下载并安装chromedriver;如果你使用的是Firefox浏览器,你需要下载并安装geckodriver。请根据你的浏览器类型,从官方网站或相关源下载对应的WebDriver,并将其放置在系统路径下,以便Selenium能够找到并调用它。
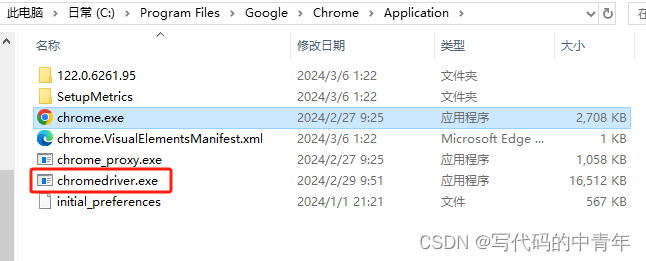
三、技术策略
http://ytzwfw.sd.gov.cn/yt/icity/project/index
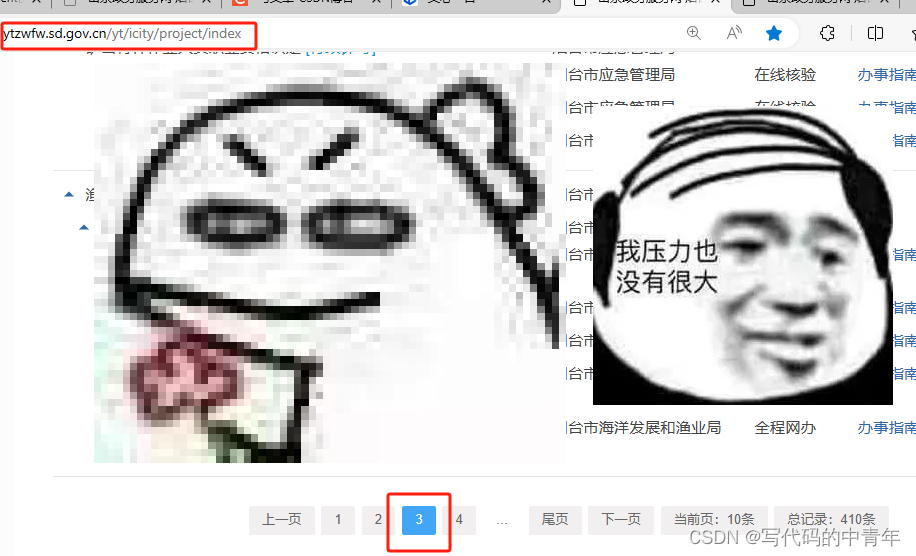
特性1:翻页后url无变化规律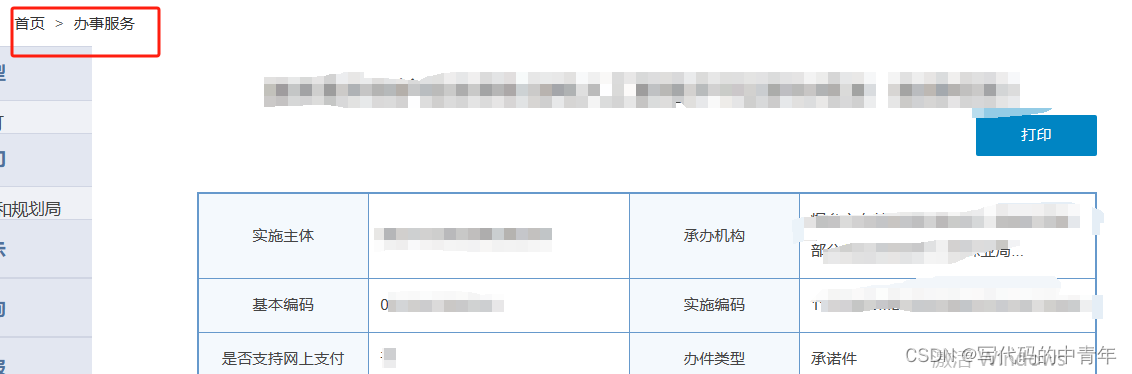
特性2:数据爬取分为2阶段,需要在url后再爬取具体数据项的url_son,再针对url_son设计程序采集。
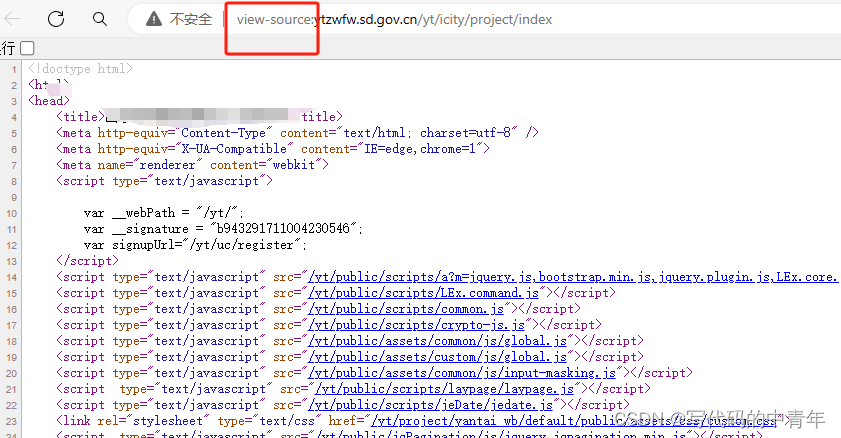
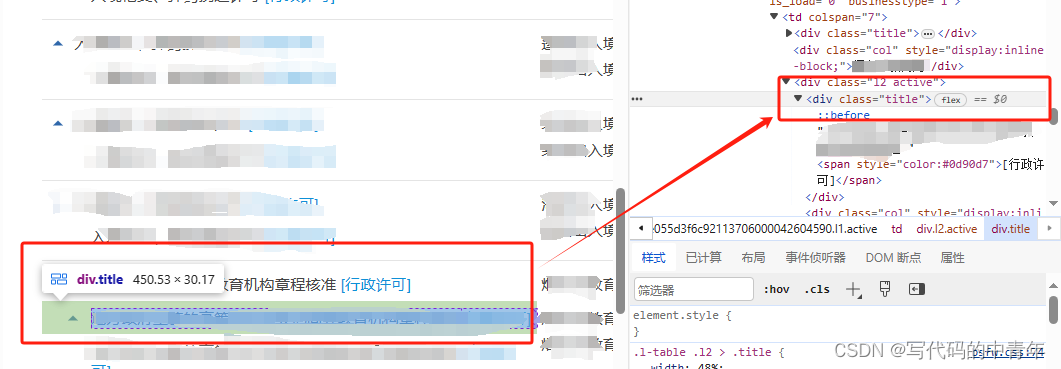
特性3:html源码中无法直接获取数据存在形式,仅开发者模式下才能观察到
由此可知该网站具备相当程度的反扒设计。
策略:
设计
两个阶段
的数据采集程序,克服
特点2
。
采取
selenium自动化框架
,克服
特点1
。
采取
bs4数据采集框架
,客服
特点3
。
四、代码实例
step1:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import time
defget_single_page_data():
result =[]for i inrange(10):try:
mid_title = driver.find_element(By.XPATH,'//*[@id="itemlist"]/div['+str(i +1)+']/div[1]/a[1]').text
mid_url = driver.find_element(By.XPATH,'//*[@id="itemlist"]/div['+str(i +1)+']/div[1]/a[1]').get_attribute('onclick')
mid =[mid_title,mid_title,mid_url.split("'")[-2]]# print(mid)
result.append(mid)except:print('data error!')return result
def
本文转载自: https://blog.csdn.net/qq_43128256/article/details/136907273
版权归原作者 写代码的中青年 所有, 如有侵权,请联系我们删除。
版权归原作者 写代码的中青年 所有, 如有侵权,请联系我们删除。