

文章目录
更多相关内容可查看
Kafka Stream 概述
Kafka Stream是Apache Kafka从0.10版本引入的一个新Feature。它是提供了对存储于Kafka内的数据进行流式处理和分析的功能。
Kafka Stream的特点如下:
- Kafka Stream提供了一个非常简单而轻量的Library,它可以非常方便地嵌入任意Java应用中,也可以任意方式打包和部署
- 除了Kafka外,无任何外部依赖
- 充分利用Kafka分区机制实现水平扩展和顺序性保证
- 通过可容错的state store实现高效的状态操作(如windowed join和aggregation)
- 支持正好一次处理语义
- 提供记录级的处理能力,从而实现毫秒级的低延迟
- 支持基于事件时间的窗口操作,并且可处理晚到的数据(late arrival of records)
- 同时提供底层的处理原语Processor(类似于Storm的spout和bolt),以及高层抽象的DSL(类似于Spark的map/group/reduce)
Kafka Stream 概念
- 源处理器(Source Processor):源处理器是一个没有任何上游处理器的特殊类型的流处理器。它从一个或多个kafka主题生成输入流。通过消费这些主题的消息并将它们转发到下游处理器。
- 处理拓扑 : 数据的处理流程 , 每一步处理流程就是一个处理拓扑
- Sink处理器:sink处理器是一个没有下游流处理器的特殊类型的流处理器。它接收上游流处理器的消息发送到一个指定的Kafka主题。

消息生产者 ----> Kafka Topic(原始数据) ------> Source Processor ------> 处理拓扑(很多步处理) ------> Sink Processor -----> Kafka Topic (运算结果) -----> 消费者(接收运行结果)
Kafka Stream 数据结构
Kafka数据结构类似于map,如下图,key-value键值对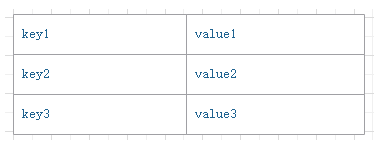
KStream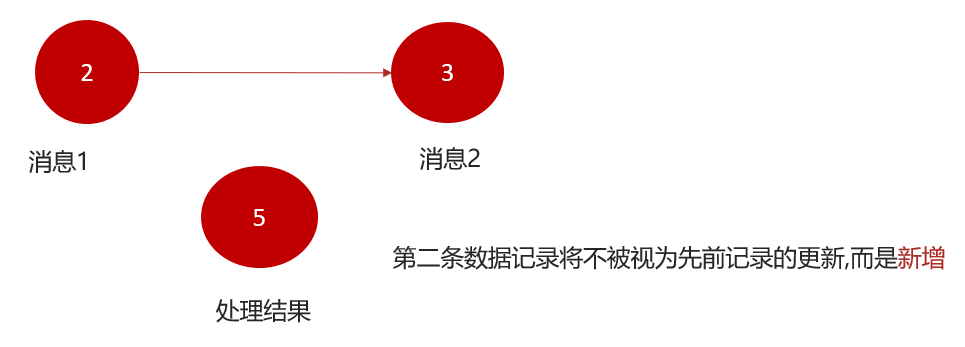
KStream数据流,即是一段顺序的,可以无限长,不断更新的数据集。KStream数据流中的每一条数据相当于一次插入
商品的行为分值运算(排行) :
{“type”:“like”,“count”:1}
{“type”:“like”,“count”:-1}
{“type”:“like”,“count”:1}
对上面的行为数据进行运算得到运算结果 :
{“type”:“like”,“count”:2}
KTable数据流 , 即是一段顺序的,可以无限长,不断更新的数据集。KTable数据流中的每一条数据相当于一次更新
公交车的运行数据
{“No”:“518”,“location”:“武湖新天地”}
{“No”:“518”,“location”:“潘森产业园”}
{“No”:“518”,“location”:“产业园”}
对上面的行为数据进行运算得到运算结果 :
{“No”:“518”,“location”:“产业园”}
入门案例一
需求描述与分析
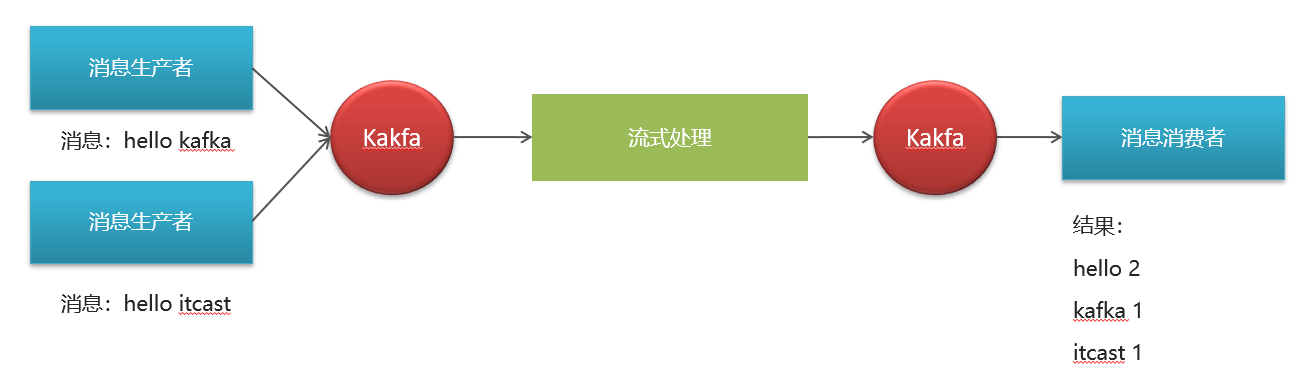
计算每个单词出现的次数
@TestvoidtestSend5(){List<String> strs =newArrayList<String>();
strs.add("hello word");
strs.add("hello kafka");
strs.add("hello spring kafka");
strs.add("kafka stream");
strs.add("spring kafka");
strs.stream().forEach(s ->{
kafkaTemplate.send("kafka.stream.topic1","10001", s);});}
配置KafkaStream
添加依赖
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-streams</artifactId></dependency>
开启KafkaStream功能
配置Kafka Stream
spring:application:name: kafka-consumer
kafka:bootstrap-servers: 118.25.197.221:9092consumer:key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
group-id: ${spring.application.name}enable-auto-commit:false# 关闭自动提交, 使用手动提交偏移量streams:application-id: ${spring.application.name}-application-id
client-id: ${spring.application.name}-client-id
properties:default:key:serde: org.apache.kafka.common.serialization.Serdes$StringSerde
value:serde: org.apache.kafka.common.serialization.Serdes$StringSerde
定义处理流程
packagecom.heima.kafka.stream;importorg.apache.kafka.common.serialization.Serdes;importorg.apache.kafka.streams.KeyValue;importorg.apache.kafka.streams.StreamsBuilder;importorg.apache.kafka.streams.kstream.Grouped;importorg.apache.kafka.streams.kstream.KStream;importorg.apache.kafka.streams.kstream.Materialized;importorg.apache.kafka.streams.kstream.TimeWindows;importorg.springframework.context.annotation.Bean;importorg.springframework.context.annotation.Configuration;importjava.time.Duration;importjava.util.Arrays;/**
* @Author Administrator
* @Date 2023/6/30
**/@ConfigurationpublicclassKafkaStreamConfig{/**
* 原始数据 ------
* 10001 hello word
* 10001 hello kafka
* 10001 hello spring kafka
* 10001 kafka stream
* 10001 spring kafka
*
* 对原始数据中的value字符串进行切割
* 10001 [hello,word]
* 10001 [hello,kafka]
* 10001 [hello,spring,kafka]
* 10001 [kafka,stream]
* 10001 [spring,kafka]
*
* 对value数组进行扁平化处理(将多维数组转化为一维数组)
* 10001 hello
* 10001 word
* 10001 hello
* 10001 kafka
* 10001 hello
* 10001 spring
* 10001 kafka
* 10001 stream
* 10001 spring
* 10001 kafka
*
* 对数据格式进行转化, 使用value作为key
* hello hello
* word word
* hello hello
* kafka kafka
* hello hello
* spring spring
* kafka kafka
* kafka kafka
* stream stream
* spring spring
* kafka kafka
*
* 对key进行分组
* hello hello
* hello hello
* hello hello
*
* word word
*
* kafka kafka
* kafka kafka
* kafka kafka
* kafka kafka
*
* spring spring
* spring spring
*
* stream stream
*
*计算组内单词数量 , 得到运算结果 -----
* hello 3
* word 1
* kafka 4
* spring 2
* stream 1
*
* @param builder
* @return
*/@BeanpublicKStream<String,String>kStream(StreamsBuilder builder){//1. 定义数据来源KStream<String,String> kStream = builder.<String,String>stream("kafka.stream.topic1");//2. 定义数据处理流程
kStream
//2.1 对原始数据中的value字符串进行切割 mapValues : 对流中数据的value进行处理转化.mapValues(value -> value.split(" "))//2.2 对value数组进行扁平化处理(将多维数组转化为一维数组) flatMapValues : 对流中数据的数组格式的value进行处理转化(多维转一维).flatMapValues(value ->Arrays.asList(value))//2.3 对数据格式进行转化, 使用value作为key map : 对流中数据的key和value进行处理转化.map(((key, value)->newKeyValue<>(value,value)))//2.4 对key进行分组 groupByKey : 根据key进行分组.groupByKey(Grouped.with(Serdes.String(),Serdes.String()))//设置聚合时间窗口, 在指定时间窗口范围之内的数据会进行一次运算, 输出运算结果.windowedBy(TimeWindows.of(Duration.ofSeconds(10)))//2.5 求每一个组中的单词数量 count : 组内计算元素数量.count(Materialized.with(Serdes.String(),Serdes.Long()))//2.6 将运算结果发送到另一个topic中 toStream : 将其他类型的流转化为 kStream.toStream().map((key, value)->newKeyValue<>(key.key(),value.toString()))//将运算结果发送到一个topic, 供消费者接收.to("kafka.stream.topic2");//3. 返回KStream对象return kStream;}}
声明Topic
KafkaStream不会自动帮助我们创建Topic ,所以我们需要自己声明消息来源的topic和消息发送的topic
@BeanpublicNewTopicstreamTopic1(){returnTopicBuilder.name("kafka.stream.topic1").build();}@BeanpublicNewTopicstreamTopic2(){returnTopicBuilder.name("kafka.stream.topic2").build();}
接收处理结果
定义一个消费者 , 从
to("kafka.stream.topic2")
中接收计算完毕的消息
@Component@Slf4jpublicclassKafkaStreamConsumerListener{@KafkaListener(topics ="kafka.stream.topic2", groupId ="steam")publicvoidlistenTopic1(ConsumerRecord<String,String> record){String key = record.key();String value = record.value();
log.info("单词:{} , 出现{}次", key, value);}}
发送消息测试
@SpringBootTest@Slf4jpublicclassKafkaStreamProducerTest{@ResourceprivateKafkaTemplate kafkaTemplate;@TestvoidtestSend5(){List<String> strs =newArrayList<String>();
strs.add("hello word");
strs.add("hello kafka");
strs.add("hello spring kafka");
strs.add("kafka stream");
strs.add("spring kafka");
strs.stream().forEach(s ->{
kafkaTemplate.send("kafka.stream.topic1","10001", s);});}}
入门案例二
需求描述与分析
现在有一组文章行为数据 , 使用
ArticleMessage
对象封装
packagecom.heima.kafka.pojos;importlombok.AllArgsConstructor;importlombok.Data;importlombok.NoArgsConstructor;/**
* @author Administrator
*/@Data@AllArgsConstructor@NoArgsConstructorpublicclassArticleMessage{/**
* 文章ID
*/privateLong articleId;/**
* 修改文章的字段类型
*/privateUpdateArticleType type;/**
* 修改数据的增量,可为正负
*/privateInteger add;publicenumUpdateArticleType{COLLECTION,COMMENT,LIKES,VIEWS;}}
模拟数据如下 :
@TestvoidtestSend6(){List<ArticleMessage> strs =newArrayList<ArticleMessage>();ArticleMessage message1 =newArticleMessage(1498972384605040641l,ArticleMessage.UpdateArticleType.LIKES,1);ArticleMessage message4 =newArticleMessage(1498972384605040641l,ArticleMessage.UpdateArticleType.LIKES,1);ArticleMessage message7 =newArticleMessage(1498972384605040641l,ArticleMessage.UpdateArticleType.LIKES,1);ArticleMessage message3 =newArticleMessage(1498972384605040641l,ArticleMessage.UpdateArticleType.LIKES,-1);ArticleMessage message2 =newArticleMessage(1498972384605040641l,ArticleMessage.UpdateArticleType.VIEWS,1);ArticleMessage message6 =newArticleMessage(1498973263815045122l,ArticleMessage.UpdateArticleType.COLLECTION,1);ArticleMessage message5 =newArticleMessage(1498973263815045122l,ArticleMessage.UpdateArticleType.COLLECTION,1);ArticleMessage message8 =newArticleMessage(1498973263815045122l,ArticleMessage.UpdateArticleType.COLLECTION,1);ArticleMessage message9 =newArticleMessage(1498972384605040641l,ArticleMessage.UpdateArticleType.COLLECTION,1);
strs.add(message1);
strs.add(message2);
strs.add(message3);
strs.add(message4);
strs.add(message5);
strs.add(message6);
strs.add(message7);
strs.add(message8);
strs.add(message9);
strs.stream().forEach(s ->{
kafkaTemplate.send("hot.article.score.topic",JSON.toJSONString(s));});}
需求如下 : 请计算出每个文章每种行为的次数 , 输出 :
文章ID : COLLECTION:10,COMMENT:20,LIKES:5,VIEWS:30
定义处理流程
/**
* @param builder
* @return
*/@BeanpublicKStream<String,String>kStream(StreamsBuilder builder){//获取KStream流对象KStream<String,String> kStream = builder.stream("hot.article.score.topic");//定义流处理拓扑
kStream
//JSON转化为Java对象.mapValues(value ->JSON.parseObject(value,ArticleMessage.class))//key和值处理 key: 文章ID , value : 行为类型:数量.map((key, value)->newKeyValue<>(value.getArticleId(), value.getType().name()+":"+ value.getAdd()))//根据key进行分组.groupByKey(Grouped.with(Serdes.Long(),Serdes.String()))//设置时间窗口.windowedBy(TimeWindows.of(Duration.ofMillis(10000)))//数据聚合.aggregate(()->"COLLECTION:0,COMMENT:0,LIKES:0,VIEWS:0",(key, value, aggValue)->{if(StringUtils.isBlank(value)){return aggValue;}String[] aggValues = aggValue.split(",");Map<String,Integer> map =newHashMap<>();for(String agg : aggValues){String[] strs = agg.split(":");
map.put(strs[0],Integer.valueOf(strs[1]));}String[] values = value.split(":");
map.put(values[0], map.get(values[0])+Integer.valueOf(values[1]));String format =String.format("COLLECTION:%s,COMMENT:%s,LIKES:%s,VIEWS:%s", map.get("COLLECTION"), map.get("COMMENT"), map.get("LIKES"), map.get("VIEWS"));return format;},Materialized.with(Serdes.Long(),Serdes.String()))//重新转化为kStream.toStream()//数据格式转换.map((key, value)->newKeyValue<>(key.key().toString(), value.toString())).to("hot.article.incr.handle.topic");return kStream;}
接收处理结果
@KafkaListener(topics ="hot.article.incr.handle.topic", groupId ="group3")publicvoidconsumer8(ConsumerRecord<String,String> record){String key = record.key();String value = record.value();System.out.println("consumer8接收到消息:"+ key +":"+ value);}
声明Topic
@BeanpublicNewTopictopic7(){returnTopicBuilder.name("kafka.topic7").build();}@BeanpublicNewTopicarticle(){returnTopicBuilder.name("hot.article.score.topic").build();}
版权归原作者 来一杯龙舌兰 所有, 如有侵权,请联系我们删除。