
前言
教程所用各版本说明
一 JDK环境配置
由于项目用的JDK17,所以单独给Hadoop配了JDK11,建议直接配置JAVA_HOME环境变量为JDK11,因为后面Spark需要用到JAVA_HOME
下载JDK11
链接:https://www.oracle.com/java/technologies/javase/jdk11-archive-downloads.html
目前Hadoop和Spark兼容JDK11和JDK8
单独修改Hadoop的话,需要在Hadoop目录下的etc\hadoop\文件夹中hadoop-env.cmd中添加一行
set JAVA_HOME=E:\Environment\jdk-11.0.13
(此处填写你的JDK路径)
注:JDK、Hadoop以及Spark的文件路径中不能出现空格和中文,类似于
Program Files这样的文件夹名是不被允许的
二 Hadoop配置
1 下载Hadoop
镜像链接:https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/core/hadoop-3.3.2/
选择hadoop-3.3.2.tar.gz
下载winutils.exe和hadoop.dll,Windows安装Hadoop需要这部分文件
链接:https://github.com/cdarlint/winutils
找到对应的版本对应bin目录中的文件,放入Hadoop下的bin 文件夹中
2 配置Hadoop环境变量
把Hadoop目录添加到系统变量
HADOOP_HOME
,并在系统变量
Path
中添加
%HADOOP_HOME%\bin

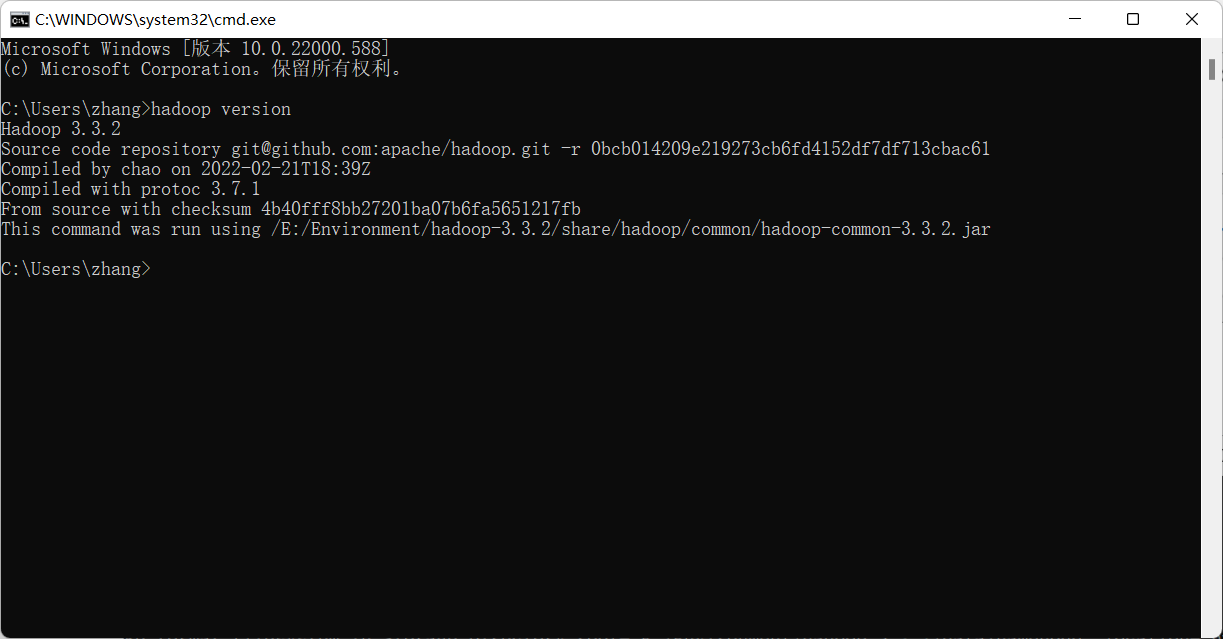
cmd输入
hadoop version
n
测试是否正常显示版本信息
3 配置hadoop
打开Hadoop所在目录下
etc\hadoop
的文件夹
修改
core-site.xml
:
先在Hadoop目录下创建data文件夹,配置文件中路径前需加"/"。HDFS可使用localhost,如果在hosts文件已经配置了主机映射,也可以直接填主机名
<configuration><property><name>hadoop.tmp.dir</name><value>/E:/Environment/hadoop-3.3.2/data/tmp</value> //注意前面部分路径修改为自己的
</property><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property></configuration>
修改
hdfs-site.xml
:
<configuration><!-- 这个参数设置为1,因为是单机版hadoop --><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><value>/E:/Environment/hadoop-3.3.2/data/namenode</value> //注意前面部分路径修改为自己的
</property><property><name>dfs.datanode.data.dir</name><value>/E:/Environment/hadoop-3.3.2/data/datanode</value> //注意前面部分路径修改为自己的
</property></configuration>
修改
mapred-site.xml
:
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapred.job.tracker</name><value>hdfs://localhost:9001</value></property></configuration>
修改
yarn-site.xml
:
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hahoop.mapred.ShuffleHandler</value></property></configuration>
4 节点格式化
打开cmd输入
hdfs namenode -format
出现类似下图说明成功。如果出错,可能原因有如:环境变量配置错误如路径出现空格,或者winutils版本不对或hadoop版本过高等,或hadoop的etc下文件配置有误

5 启动Hadoop
然后cmd切换到Hadoop下的sbin目录,输入
start-all.cmd
然后回车,此时会弹出4个cmd窗口,分别是NameNode、ResourceManager、NodeManager、DataNode。检查4个窗口有没有报错。在CMD执行jps看到这4个进程,启动成功
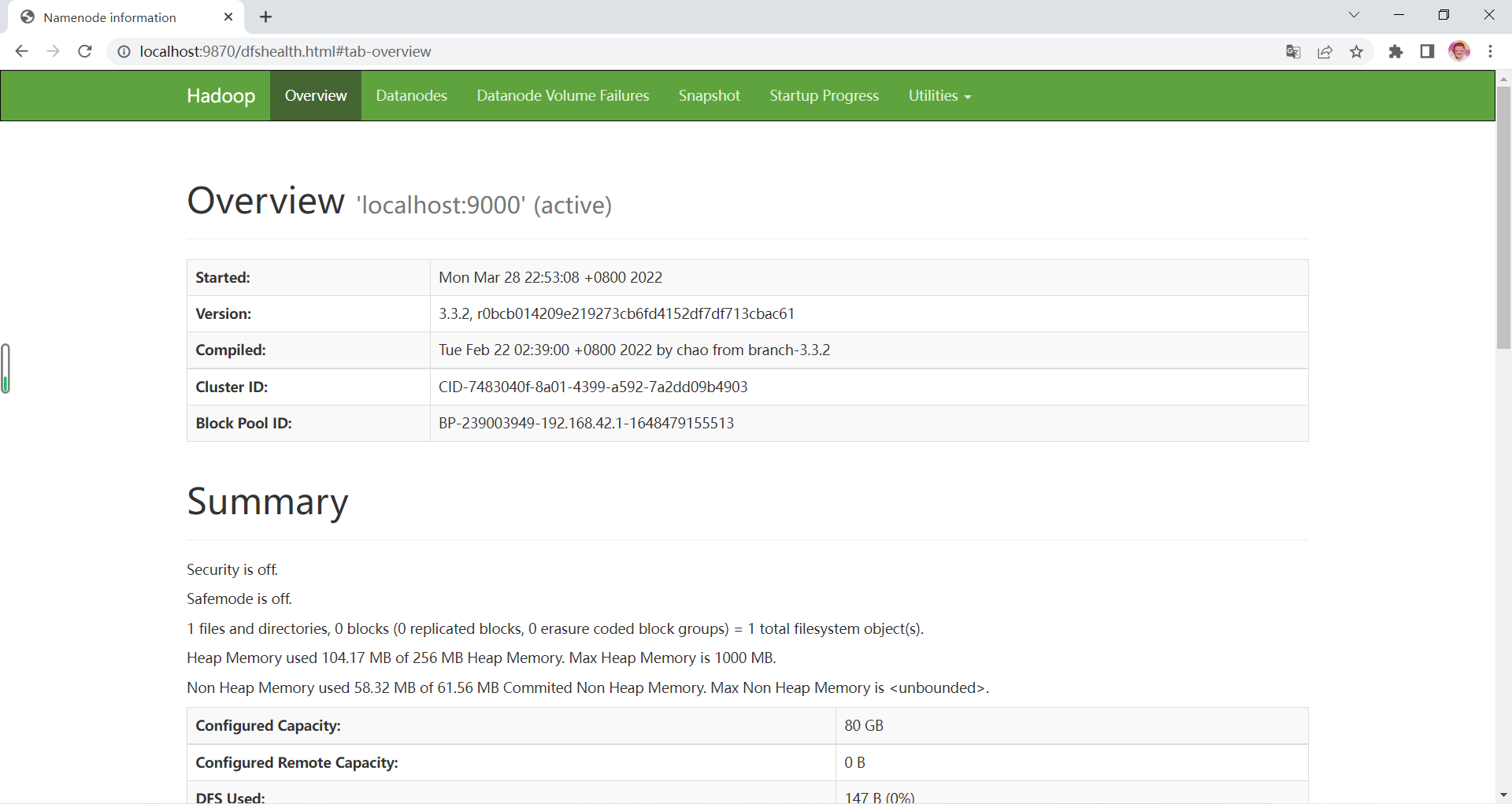
浏览器输入
localhost:9870
即进入访问HDFS的Web UI界面
浏览器输入
localhost:8088
即进入Yarn集群节点的Web UI界面

三 Spark配置
1 下载Scala
下载链接:https://www.scala-lang.org/download/2.13.8.html
选择scala-2.13.8.zip
2 配置Scala环境变量
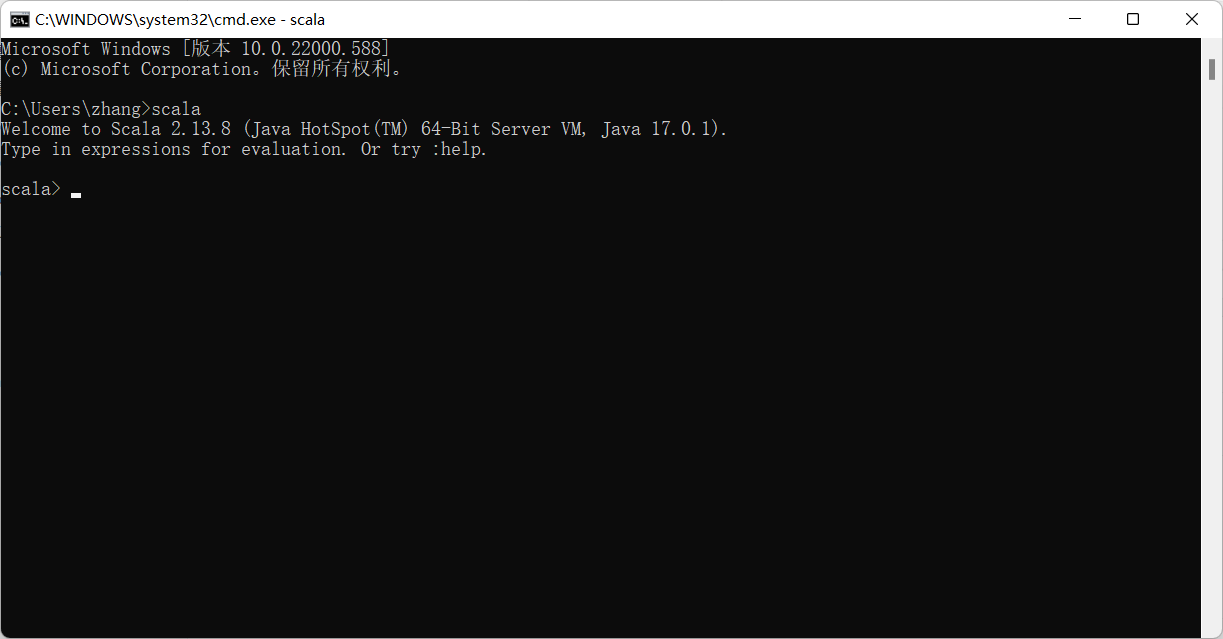
将解压后的Scala的bin目录添加到Path系统变量中,打开cmd输入
scala
然后回车,如果能够正常进入到Scala的交互命令环境则表明配置成功
3 下载Spark
由于spark-3.2.1版本在启动时会出现一点问题,具体原因没有深究。但尝试降低版本变成3.1.3版本后正常运行,所以就选择配置spark-3.1.3
Spark3.1.3和JDK11启动时会出现WARNING,更新到3.3.1和JDK17就好了
官网链接:https://dlcdn.apache.org/spark/spark-3.3.1/spark-3.3.1-bin-hadoop3-scala2.13.tgz
镜像链接:https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-3.3.1/spark-3.3.1-bin-hadoop3-scala2.13.tgz
「需要注意的是spark版本需要和hadoop版本对应.如果按照本文的配置即可忽略此行文字」
4 配置Spark环境变量
把Spark目录添加到系统变量
SPARK_HOME
,并在系统变量
Path
中添加
%SPARK_HOME%\bin

5 启动Spark
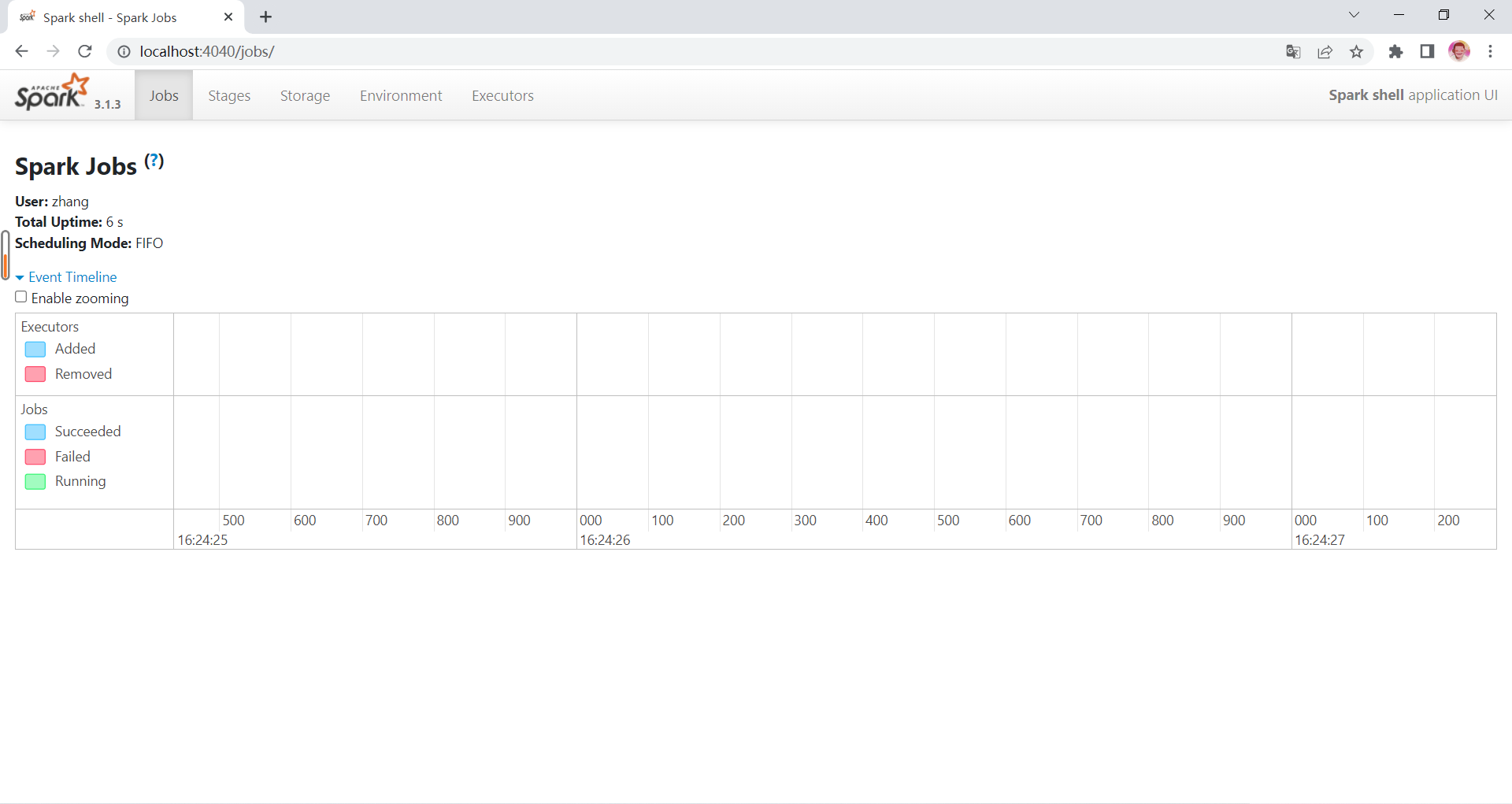
打开cmd窗口,输入
spark-shell
然后回车,如果能够正常进入到Spark的交互式命令行模式,则表明配置成功

浏览器输入
localhost:4040
即进入Spark的Web UI界面
版权归原作者 zhangz1z 所有, 如有侵权,请联系我们删除。