
HDFS 基本 shell 操作
1.1 创建目录
调用格式:
hdfs dfs -mkdir(-p) /目录
例如:
hdfs dfs -mkdir /data
hdfs dfs -mkdir-p /data/a/b/c

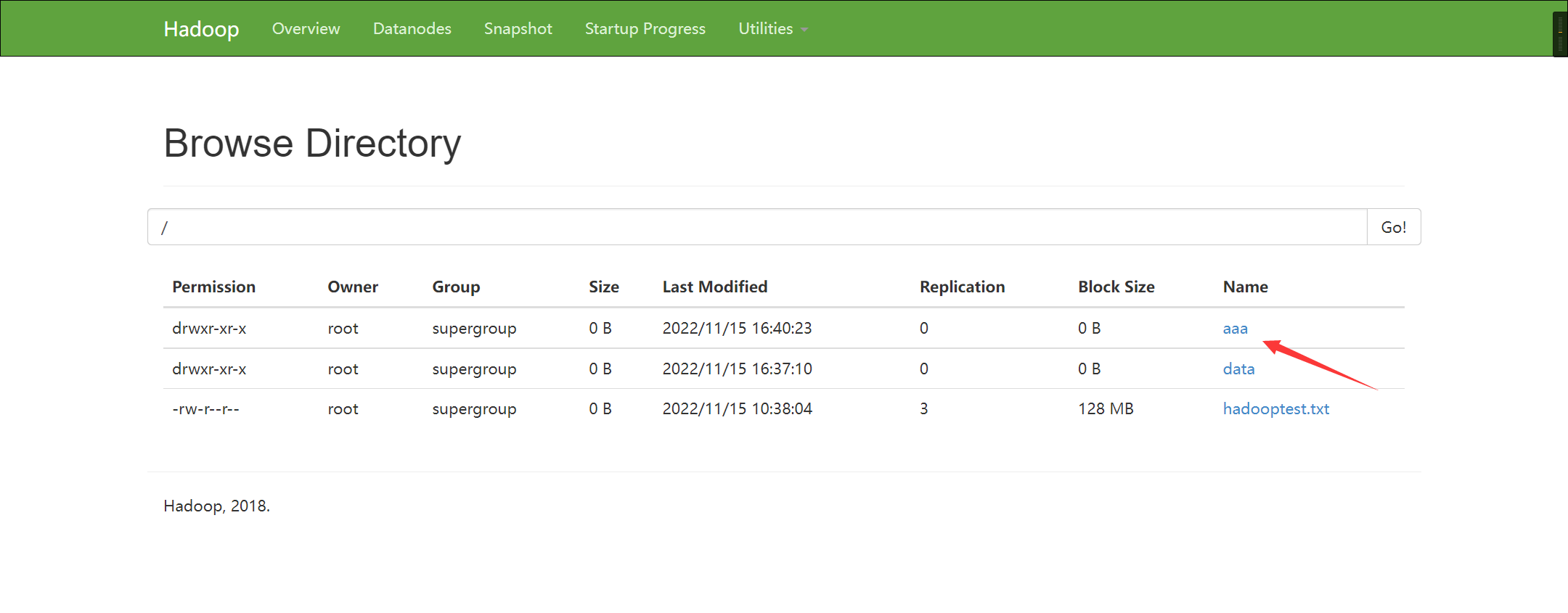
1.2 上传指令
调用格式:
hdfs dfs -put /本地文件 /分布式文件系统路径
注意: 直接写/是省略了文件系统的名称hdfs://ip:port。
例如:
hdfs dfs -put /root/a.txt /data/ # root 下的 a.txt 上传到 /data
hdfs dfs -put /root/logs/* /data/ # logs 下的所有文件上传到 /data

1.3 创建空文件
调用格式:
hdfs dfs -touchz /系统路径/文件名
例如:
hdfs dfs -touchz /hadooptest.txt

1.4 向分布式文件系统中的文件里追加内容
调用格式:
hdfs dfs -appendToFile 本地文件 hdfs上的文件
注意:
1)不支持在中间随意增删改操作
2)往空文件中追加就相当于直接写文件,所以能追加进去
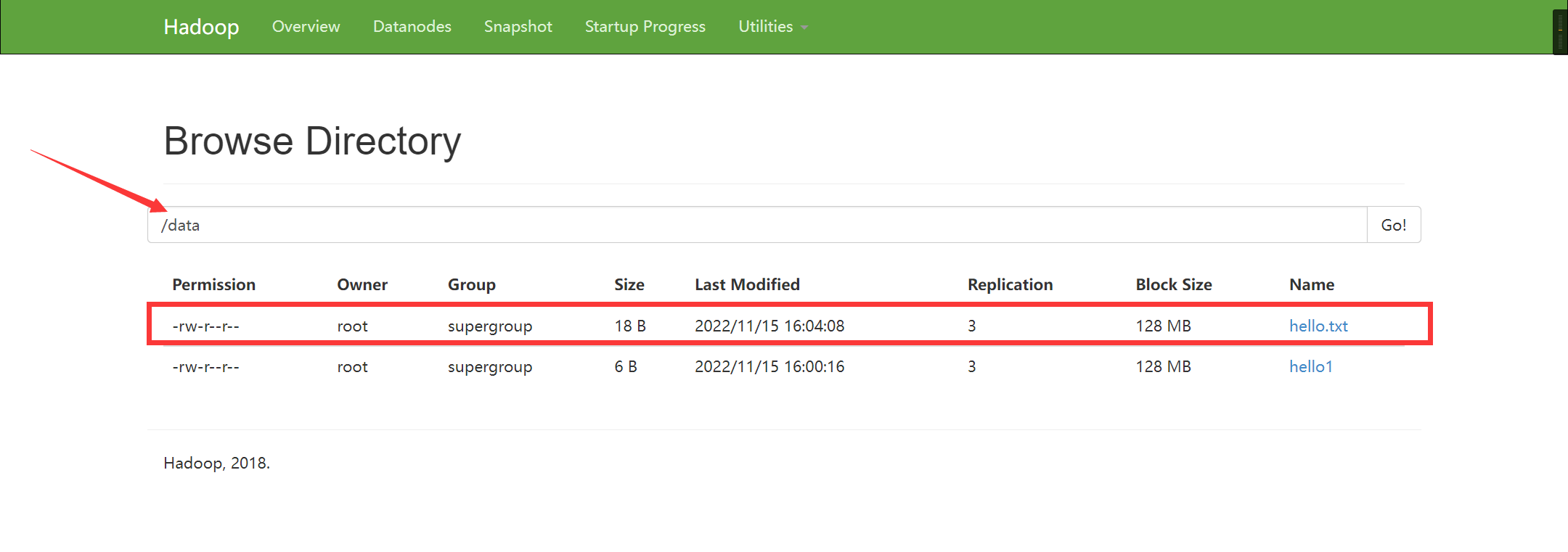
本地文件 hello1.txt 的内容追加到 hdfs 文件 hello.txt 的后面操作如下:

原 hello.txt:hello world
原 hello1.txt:hello
追加的 hello.txt 中内容如下

1.5 查看指令
查看分布式文件系统的目录里内容
调用格式:hdfs dfs -ls /

查看分布式文件系统的文件内容
调用格式:hdfs dfs -cat /xxx.txt


查看分布式文件系统的文件内容
调用格式:hdfs dfs -tail /xxx.txt
注意:默认最多查看1000行
1.6 下载指令
hdfs dfs -copyToLocal hdfs上的文件 本地路径
注意:本地路径的文件夹可以不存在
hdfs dfs -moveToLocal hdfs上的文件 本地路径
注意:从hdfs的某个路径将数据剪切到本地,已经被遗弃了
hdfs dfs -get hdfs上的文件 本地路径
调用格式:同copyToLoca
1.7 合并下载
调用格式:hdfs dfs -getmerge hdfs上面的路径 本地的路径
实例:hdfs dfs -getmerge /data/*.txt /root/c.txt(将hdfs上的a.txt和b.txt文件合并为c.txt保存在本地root目录下)
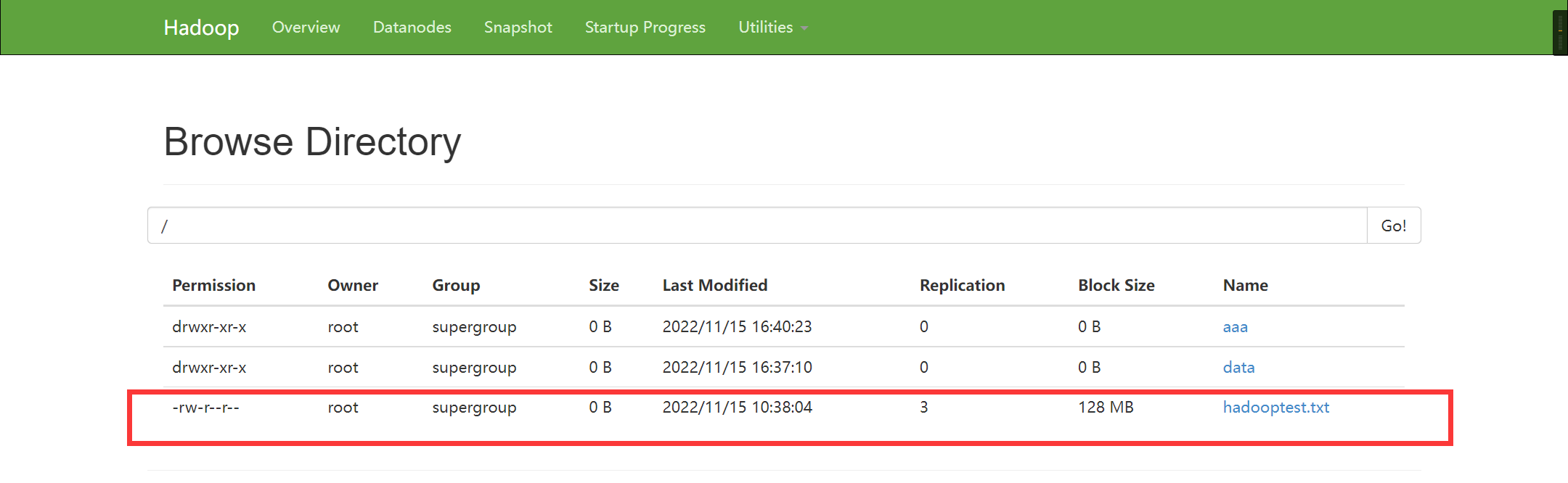
1.8 移动hdfs中的文件
调用格式:hdfs dfs -mv /hdfs的路径1 /hdfs的另一个路径2
实例:hfds dfs -mv /aaa /bbb 这里是将aaa整体移动到bbb中
原来目录如下:

把根目录下的 hello1 移动到 /data/ 后的目录如下

1.9 复制hdfs中的文件到hdfs的另一个目录
调用格式:hdfs dfs -cp 原路径 想要复制到的路径

1.10 删除命令
hfds dfs -rm[-f][-r|-R][-skipTrash]<src>...
注意:如果删除文件夹需要加-r
hfds dfs -rmdir[--ignore-fail-on-non-empty]<dir>...
注意:必须是空文件夹,如果非空必须使用rm删除
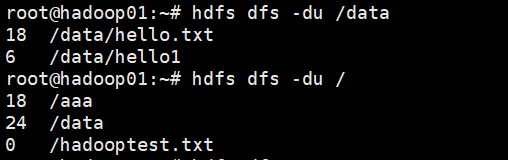
1.11 查看磁盘利用率和文件大小
hfds dfs -df[-h][<path>...]]#查看分布式系统的磁盘使用情况
hfds dfs -du[-s][-h]<path>... #查看分布式系统上当前路径下文件的情况 -h:human 以人类可读的方式显示

1.12 修改权限
跟本地的操作一致,-R是让子目录或文件也进行相应的修改
hfds dfs -chgrp[-R] GROUP PATH...
hfds dfs -chmod[-R]<MODE[,MODE]... | OCTALMODE>PATH...
hfds dfs -chown[-R][OWNER][:[GROUP]]PATH...
1.13 修改文件的副本数
调用格式:hadoop fs -setrep3 / 将hdfs根目录及子目录下的内容设置成3个副本
注意:当设置的副本数量与初始化时默认的副本数量不一致时,集群会作出反应,比原来多了会自动进行复制.
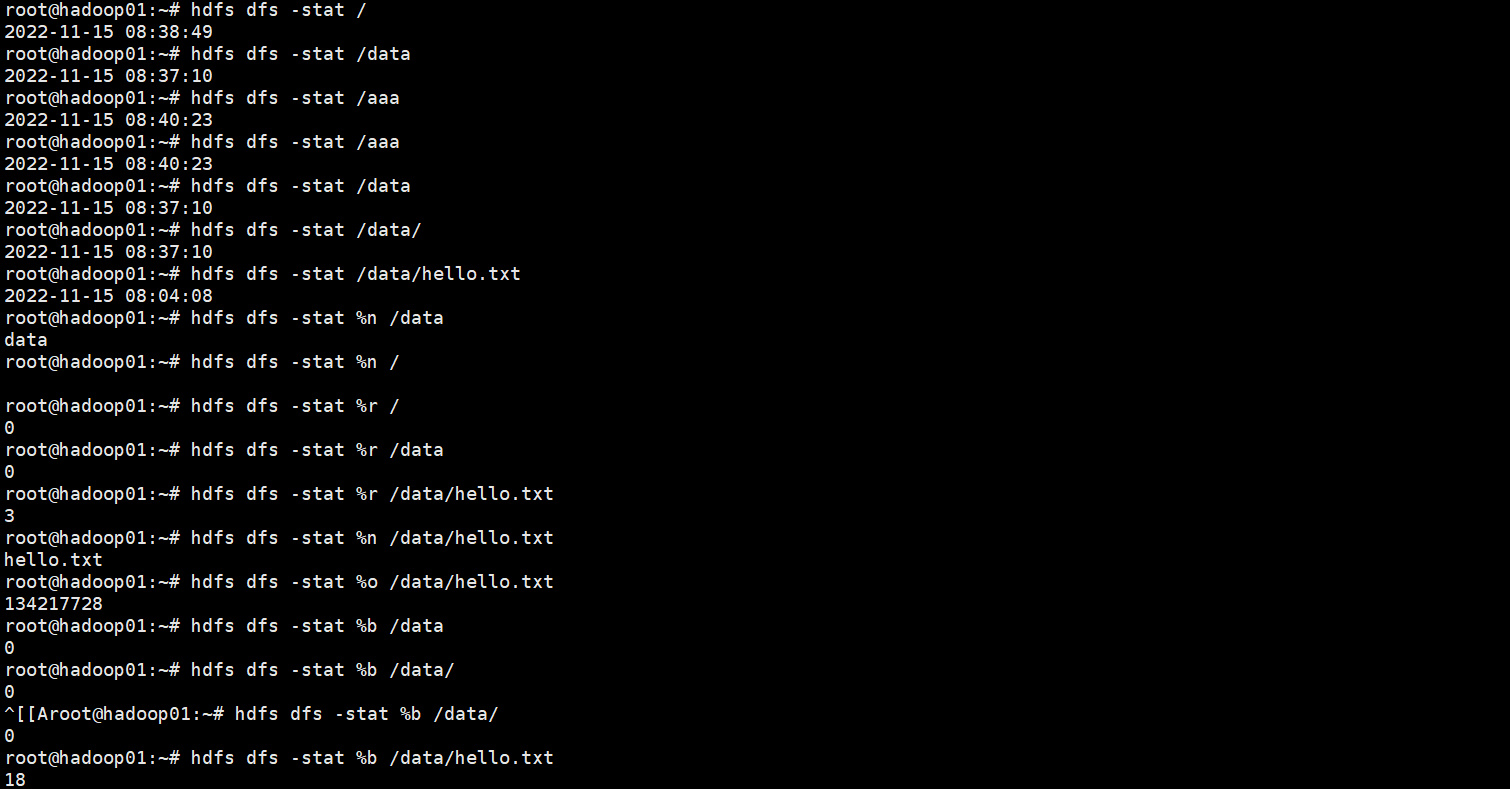
1.14 查看文件的状态
命令的作用:当向hdfs上写文件时,可以通过dfs.blocksize配置项来设置文件的block的大小。这就导致了hdfs上的不同的文件block的大小是不相同的。有时候想知道hdfs上某个文件的block大小,可以预先估算一下计算的task的个数。stat的意义:可以查看文件的一些属性。
调用格式:hdfs dfs -stat[format] 文件路径
format的形式:
%b:打印文件的大小(目录大小为0)
%n:打印文件名
%o:打印block的size
%r:打印副本数
%y:utc时间 yyyy-MM-dd HH:mm:ss
%Y:打印自1970年1月1日以来的utc的微秒数
%F:目录打印directory,文件打印regular file
注意:
# 当使用-stat命令但不指定format时,只打印创建时间,相当于%y# -stat 后面只跟目录,%r,%o等打印的都是0,只有文件才有副本和大小
1.15 测试
参数说明:
-e:文件是否存在 存在返回0
-z:文件是否为空 为空返回0
-d:是否是路径(目录) ,是返回0
调用格式:hdfs dfs -test-d 文件
实例:hdfs dfs -test-d /data/hello.txt &&echo"OK"||echo"no"
解释:测试当前的内容是否是文件夹 ,如果是返回ok,如果不是返回no

本文转载自: https://blog.csdn.net/a6661314/article/details/127869370
版权归原作者 跳舞的皮埃尔 所有, 如有侵权,请联系我们删除。
版权归原作者 跳舞的皮埃尔 所有, 如有侵权,请联系我们删除。