
一、下载安装
1.云盘下载地址:链接:https://pan.baidu.com/s/1KODKnjjpGVCqNBpQ0bnCGA
提取码:ovdx
2.其它下载地址:https://sourceforge.net/projects/dirbuster/files/latest/download
3.下载完成将压缩包解压至方便自己查找的位置
4.直接点击DirBuster-0.12-Setup.exe安装,为方便查找,可自定义安装路径
5.工具使用需要Java(Jre)环境,如已经具备Java环境,自行忽略掉云盘下载文件中的Jre文件,若没有Java环境,则自行将下载的Jre配置上或直接配置jave环境
二、简介
目录扫描工具DirBuster支持全部的Web目录扫描方式。它既支持网页爬虫方式扫描,也支持基于字典暴力扫描,还支持纯暴力扫描。该工具使用Java语言编写,提供命令行(Headless)和图形界面(GUI)两种模式。其中,图形界面模式功能更为强大。用户不仅可以指定纯暴力扫描的字符规则,还可以设置以URL模糊方式构建网页路径。同时,用户还对网页解析方式进行各种定制,提高网址解析效率。
三、基础用法
1、双击运行Dirbuster-0.9.8.jar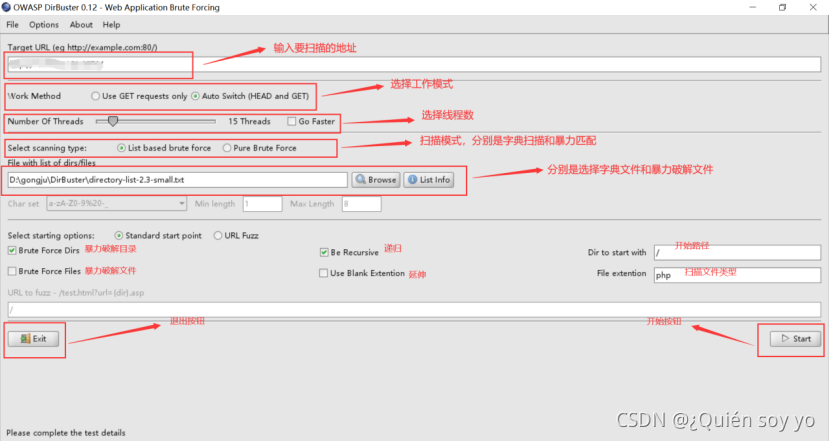
2、在target URL栏中输入要扫描的地址
3、在file with list of dirs/files 栏后点击browse,选择破解的字典库为directory-list-2.3-small.txt(用于基于列表的暴力破解的Word列表)
4、去除Burp Force Files选项
5、其他选项不变。点击右下角的start,启动目录查找
6、依次点击Response值为200的行,在出现的菜单中点击Open In Browser,分析单条扫描结果
注:如果你扫描的目标是http://www.xxx.com/admin/,那么在URL to fuzz里填写"/admin/{dir}",意思是在"{dir}“的前后可以随意拼接你想要的目录或者后缀,例如输入”: /admin/{dir}.php"就表示扫描admin目录下的所有php文件
7、扫描完成点击Report输出整体扫描结果以供分析(如:所有对目录的访问均不能打印出文件列表)
响应码(详细说明参照百度)
2xx成功。代表:200(请求成功)
3xx重定向。代表:302(重定向),304(访问缓存)
4xx客户端错误。代表:403(请求有效但服务器拒绝响应),404(请求路径没有对应的资源),405(请求中指定的方法不被允许)
5xx服务端错误。代表:500(服务器内部出现异常)
四、工具提供的功能
- 多线程记录的速度超过6000个请求每秒
- 通过HTTP和https均可以工作
- 扫描目录和文件
- 将以递归方式扫描到它找到的目录中
- 能够执行基于列表的扫描或纯暴力扫描
- DirBuster可以在任何目录下启动
- 可以添加自定义HTTP标头
- 代理支持
- 在HEAD和GET请求间自动切换
- 失败的尝试返回200时的内容分析模式
- 可以使用自定义文件拓展名
- 程序运行时可以调整性能
- 支持基本、摘要和NTLM身份验证
- 命令行/GUI界面
未完待续
版权归原作者 ¿Quién soy yo 所有, 如有侵权,请联系我们删除。