
一、简介
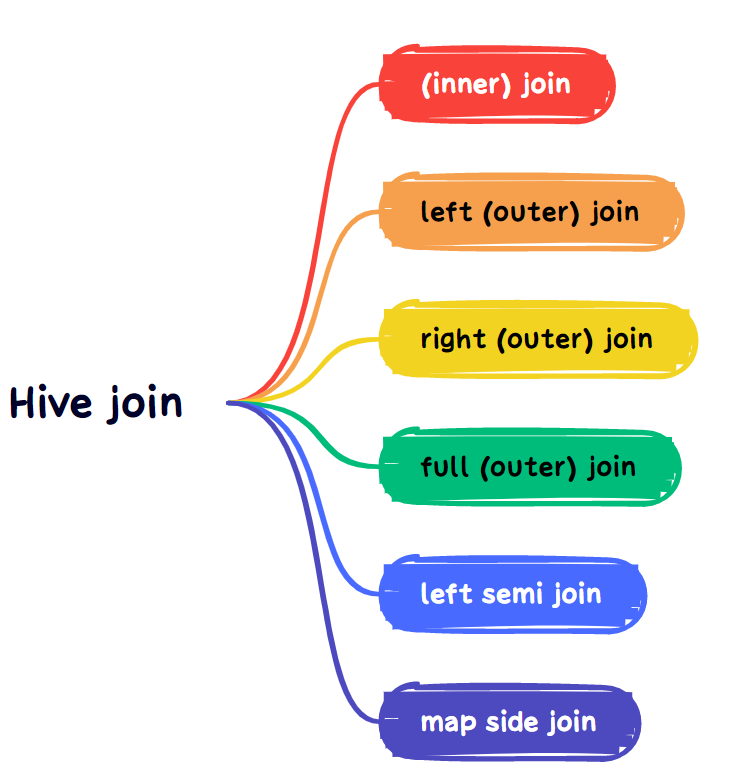
hive join 主要包括join(内连接)、left join(左连接)、right join(右连接)、full join(全连接)、left semi join(左半连接)、map side join(map端连接)六种用法,其中inner join 和 join等价,left outer join 和 left join等价,right outer join 和 right join 等价,full outer join 和 full join等价。 正确选择合适的join 类型在开发过程中可以提升效率。
二、创建数据
1、数据概览

2、创建hive表并插入数据
create table people(name string,age int) row format delimited fields terminated by ',';
insert into people(name,age) values('Lucy',29);
insert into people(name,age) values('Tom',26);
insert into people(name,age) values('Lina',22);
insert into people(name,age) values('Lili',18);
insert into people(name,age) values('Jack',26);
insert into people(name,age) values('Lihua',23);
create table info(name string,address string) row format delimited fields terminated by ',';
insert into info(name,address) values('Lucy','郑州');
insert into info(name,address) values('Lili','北京');
insert into info(name,address) values('Jack','上海');
insert into info(name,address) values('Alice','南京');
insert into info(name,address) values('Clarke','广州');
insert into info(name,address) values('Lonnie','三亚');
三、join连接测试
1、join(inner join)
这里join 和 inner join等价;
select t1.name,t1.age,t2.address from people t1 join info t2 on t1.name=t2.name;
Lucy 29 郑州
Lili 18 北京
Jack 26 上海
select t1.name,t1.age,t2.address from people t1 inner join info t2 on t1.name=t2.name;
Lucy 29 郑州
Lili 18 北京
Jack 26 上海
2、left join(left outer join)
这里left join 和 left outer join 等价;
select t1.name,t1.age,t2.address from people t1 left join info t2 on t1.name=t2.name;
Lucy 29 郑州
Lili 18 北京
Jack 26 上海
Tom 26 NULL
Lihua 23 NULL
Lina 22 NULL
select t1.name,t1.age,t2.address from people t1 left outer join info t2 on t1.name=t2.name;
Lucy 29 郑州
Lili 18 北京
Jack 26 上海
Tom 26 NULL
Lihua 23 NULL
Lina 22 NULL
3、right join(right outer join)
这里right join 和 right outer join 等价;
select t1.name,t1.age,t2.address from people t1 right join info t2 on t1.name=t2.name;
Lucy 29 郑州
NULL NULL 南京
NULL NULL 广州
Lili 18 北京
NULL NULL 三亚
Jack 26 上海
select t1.name,t1.age,t2.address from people t1 right outer join info t2 on t1.name=t2.name;
Lucy 29 郑州
NULL NULL 南京
NULL NULL 广州
Lili 18 北京
NULL NULL 三亚
Jack 26 上海
4、full join(full outer join)
这里full join 和 full outer join 等价;
select t1.name,t1.age,t2.name,t2.address from people t1 full join info t2 on t1.name=t2.name;
NULL NULL Alice 南京
NULL NULL Clarke 广州
Jack 26 Jack 上海
Lihua 23 NULL NULL
Lili 18 Lili 北京
Lina 22 NULL NULL
NULL NULL Lonnie 三亚
Lucy 29 Lucy 郑州
Tom 26 NULL NULL
select t1.name,t1.age,t2.name,t2.address from people t1 full outer join info t2 on t1.name=t2.name;
NULL NULL Alice 南京
NULL NULL Clarke 广州
Jack 26 Jack 上海
Lihua 23 NULL NULL
Lili 18 Lili 北京
Lina 22 NULL NULL
NULL NULL Lonnie 三亚
Lucy 29 Lucy 郑州
Tom 26 NULL NULL
5、left semi join
- left semi join是一个限制语句,join 右边表的字段不能出现在select或者where中。
- left semi join是IN/EXISTS子查询的一种更高效的实现。
- left semi join是in(keySet)的关系,遇到右表重复记录,左表会跳过,而 join 则会一直遍历。这就导致右表有重复值得情况下left semi join只产生一条,join会产生多条,所以left semi join的性能更高。
等价语句:
select t1.name,t1.age from people t1 left semi join info t2 on t1.name=t2.name;
<==>
select t1.name,t1.age from people t1 where t1.name in(select t2.name from info t2);
<==>
select t1.name,t1.age from people t1 where exists(select t2.name from info t2 where t1.name=t2.name);
Lucy 29
Lili 18
Jack 26
错误示范【select后面出现join右边表的字段】:
hive> select t1.name,t1.age,t2.name,t2.address from people t1
left semi join info t2 on t1.name=t2.name;
FAILED: SemanticException [Error 10004]: Line 1:22 Invalid table alias or
column reference 't2': (possible column names are: name, age)
6、map side join
- map side join使用场景是一个大表和一个小表的连接操作,其中,“小表”是指文件足够小,可以加载到内存中。该算法可以将join算子执行在Map端,无需经历shuffle和reduce等阶段,因此效率非常高。
- map side join 需要hive更改配置文件,hive2.11版本默认是开着的:
hive> set hive.auto.convert.join;
hive.auto.convert.join=true
hive> set hive.mapjoin.smalltable.filesize;
hive.mapjoin.smalltable.filesize=25000000
四、join 和 left semi join 的区别
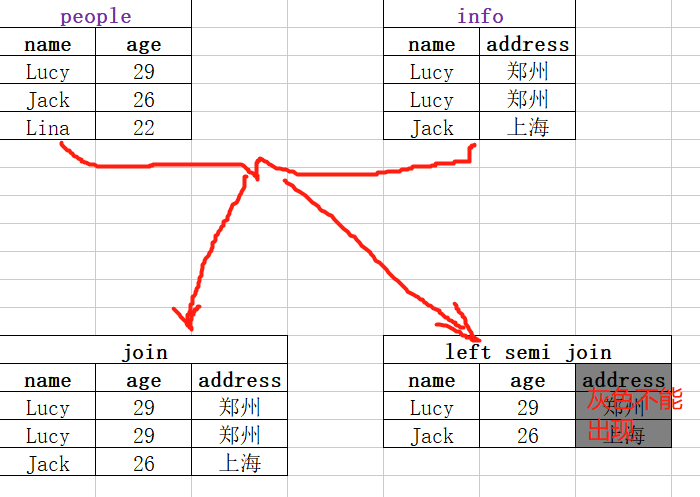
注意: left semi join是in(keySet)的关系,遇到右表重复记录,左表会跳过,而 join 则会一直遍历。这就导致右表有重复值得情况下left semi join只产生一条,join会产生多条,所以left semi join的性能更高。
本文转载自: https://blog.csdn.net/hyj_king/article/details/126656349
版权归原作者 郝少 所有, 如有侵权,请联系我们删除。
版权归原作者 郝少 所有, 如有侵权,请联系我们删除。