
前言
此次我们选择的是通过在VMware虚拟机上面进行Hadoop的安装和配置,需要准备的东西如下:
系统环境:CentOS 7
镜像:CentOS-7-x86_64-DVD-2003
JDK:jdk-8u291-linux-x64.tar.gz
Hadoop:hadoop-3.1.3.tar.gz
Spark:spark-3.1.1-bin-hadoop2.7.tgz
上面所需的环境准备,我已经打包整理好全部放在了网盘,有需要的同学可以自行下载,点击下载
一、新建虚拟机
使用自定义类型的配置
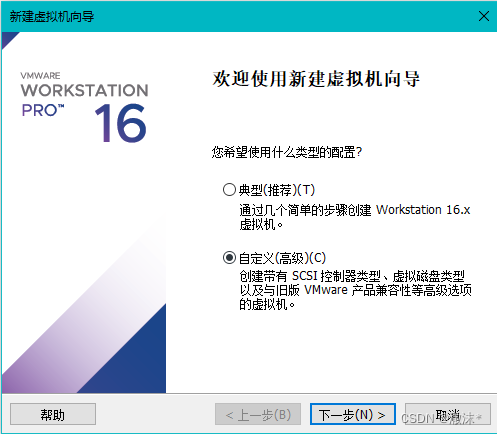
选择稍后安装操作系统
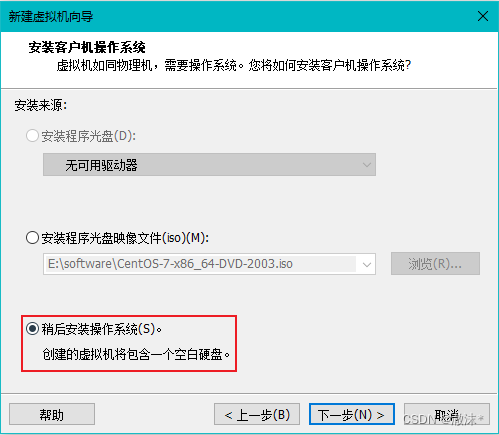
选择Linux操作系统,版本为Centos 7 64位
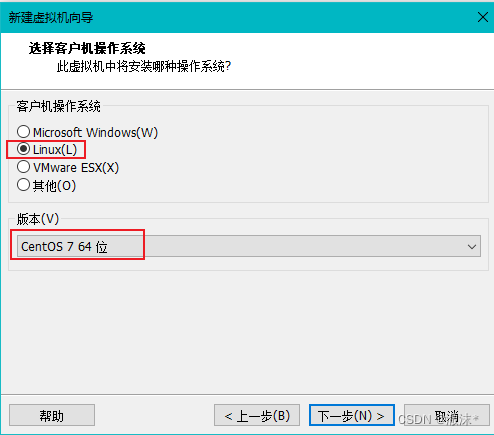
设置虚拟机名称,以及它的存放目录
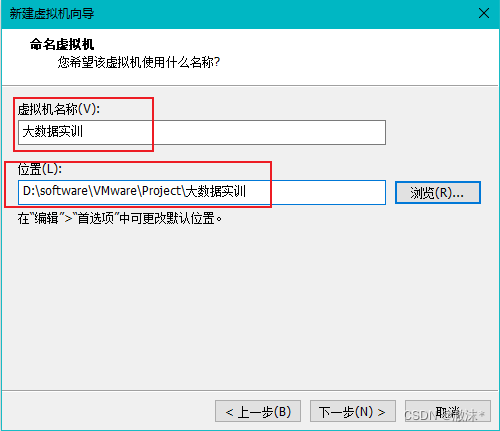
设置处理器数量,配置好的可以设置为2个
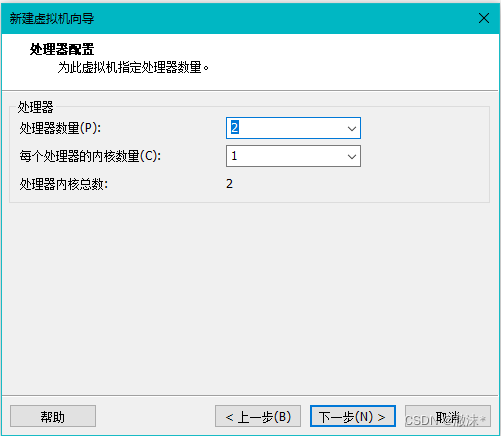
设置虚拟机内存为2G,注:电脑配置差的可以设置为1G
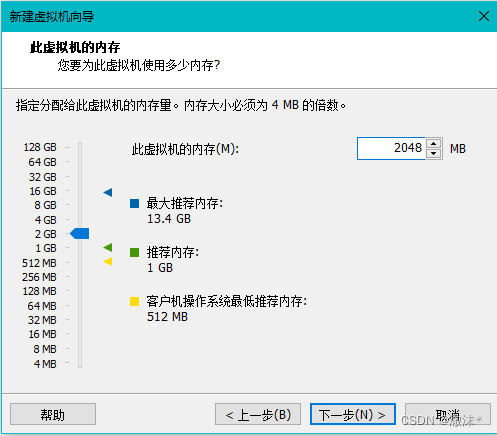
使用网络地址转换
默认,下一步
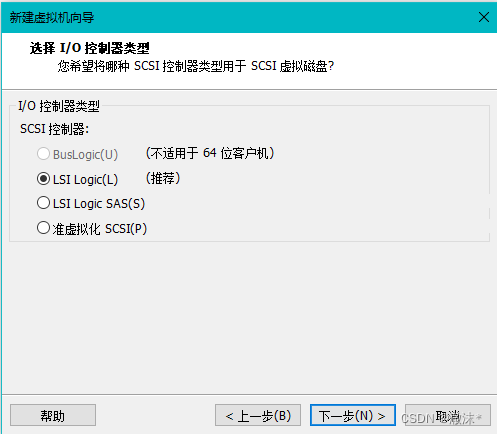
使用默认的磁盘类型
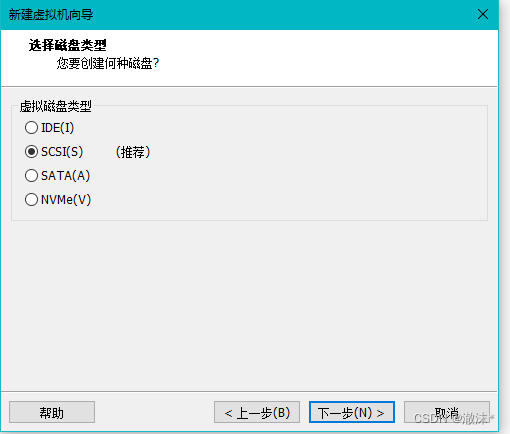
创建新的磁盘
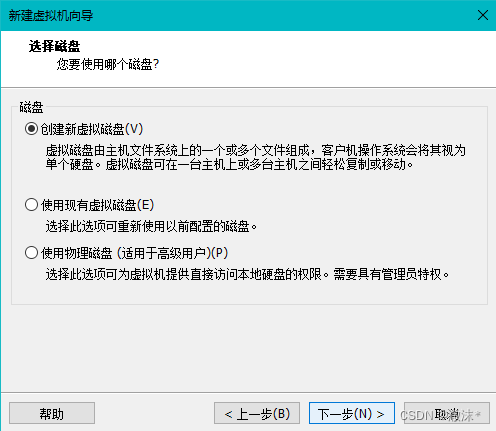
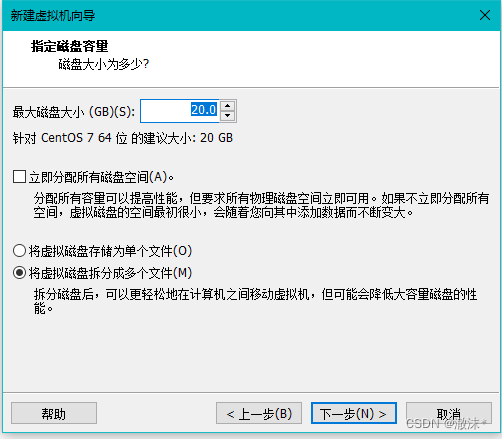
磁盘大小默认,点击下一步
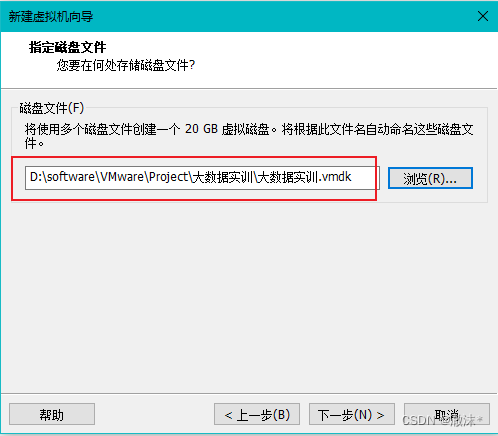
设置磁盘存储位置
创建完成,点击完成
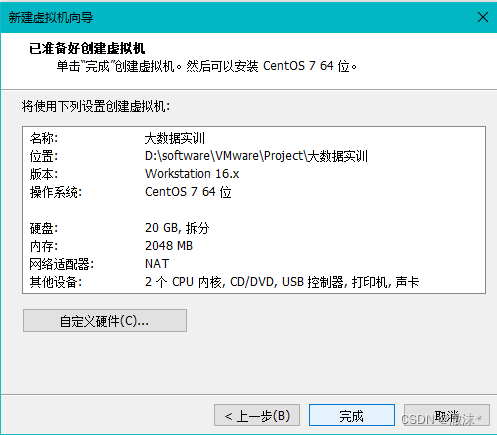
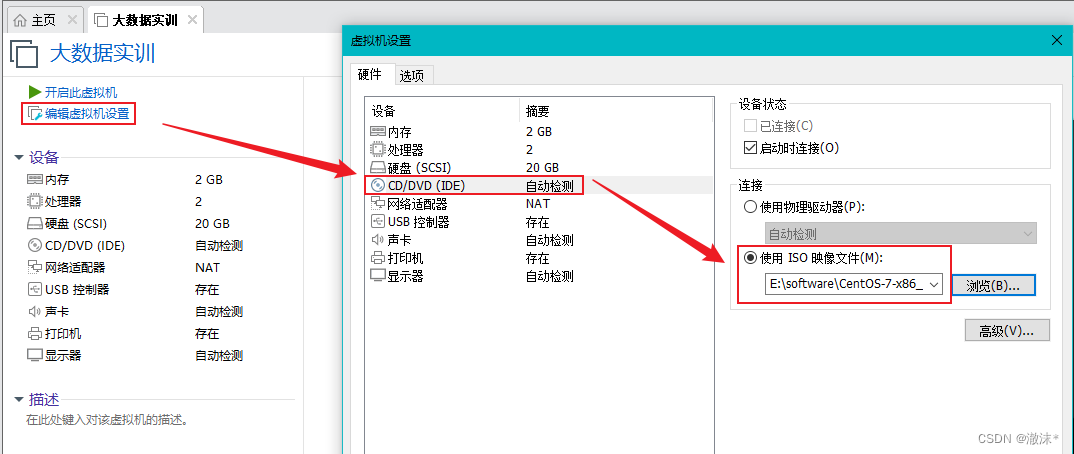
编辑虚拟机设置,选择Centos镜像地址
二、安装Centos系统
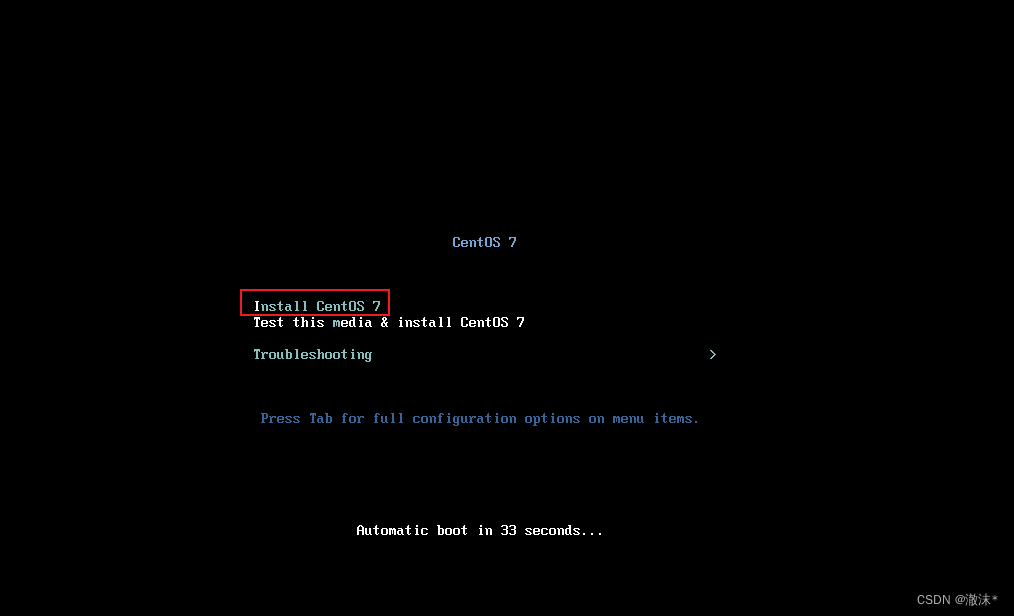
设置完成后点击开启虚拟机,鼠标点击安装页面,键盘方向键选择Install Centos7
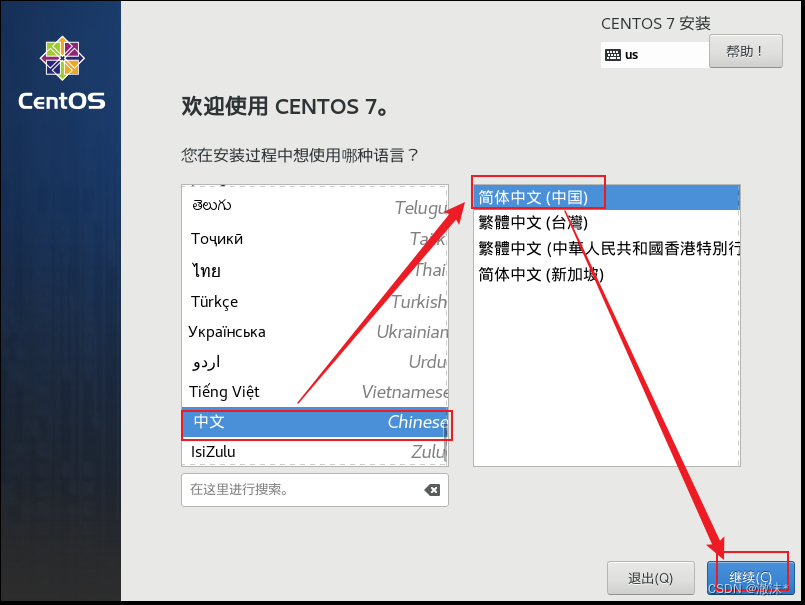
语言选择简体中文
软件选择,选择GNOME桌面
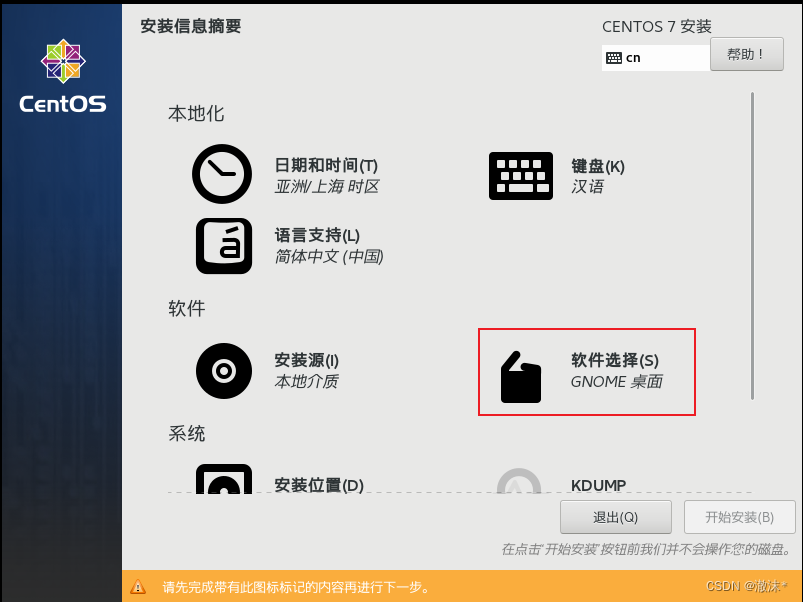
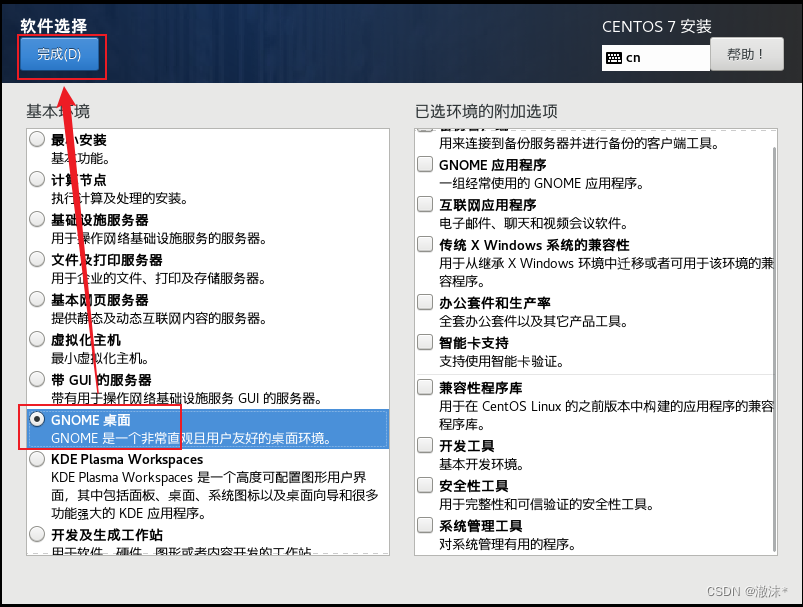
点击安装位置,进入之后点击完成

开始安装
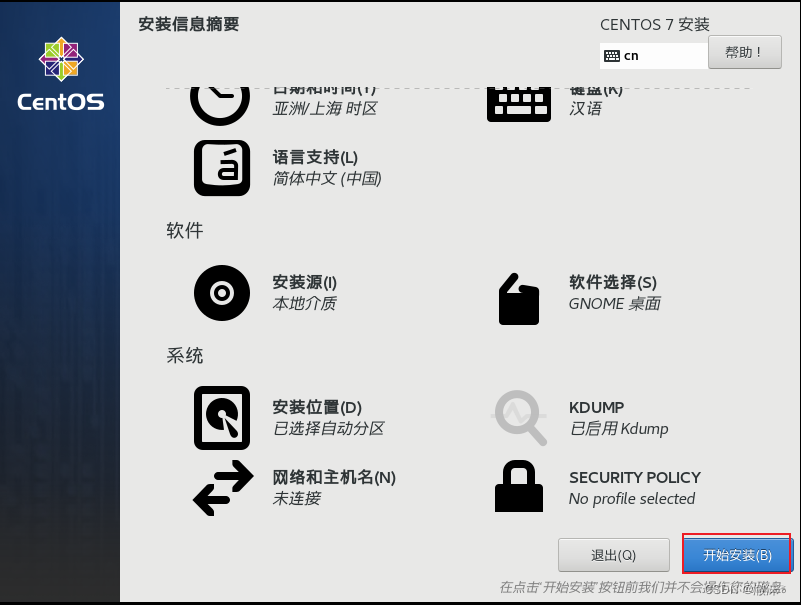
开始安装
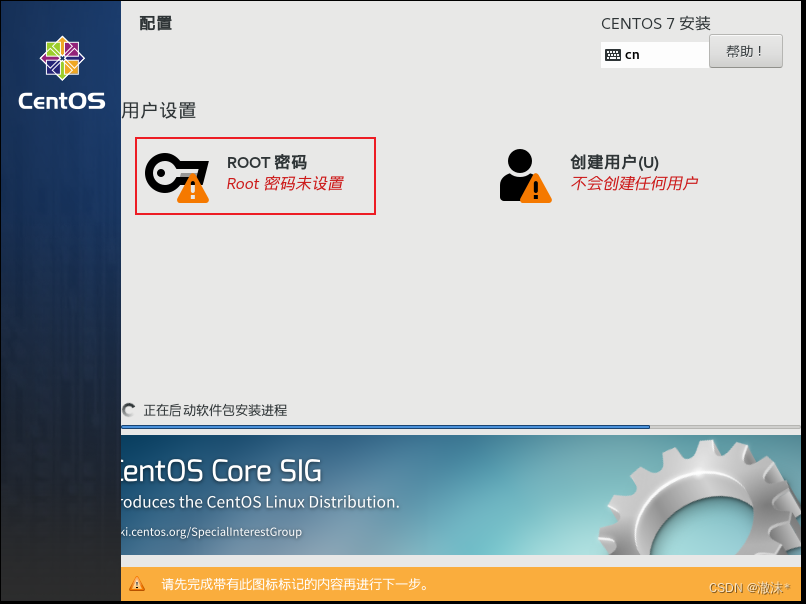
设置root密码为:123,点两下完成
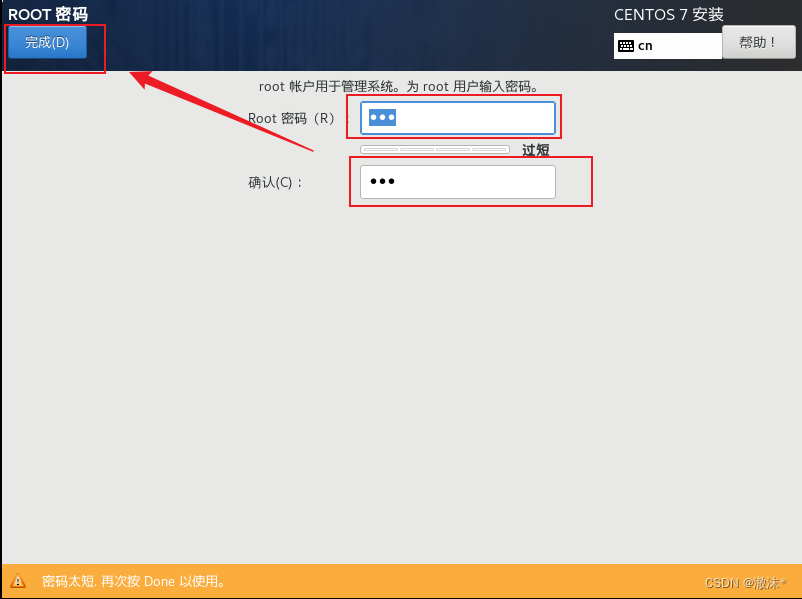
等待安装完成
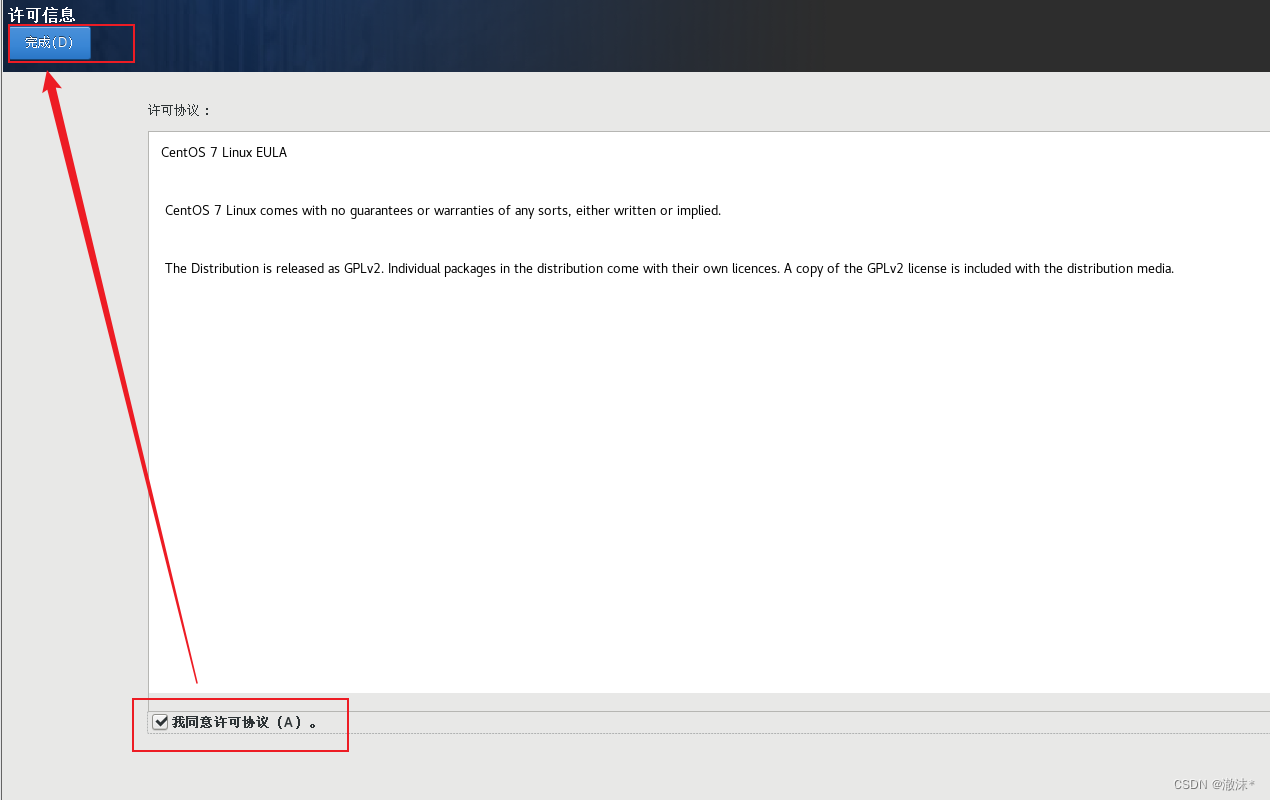
点击同意许可证

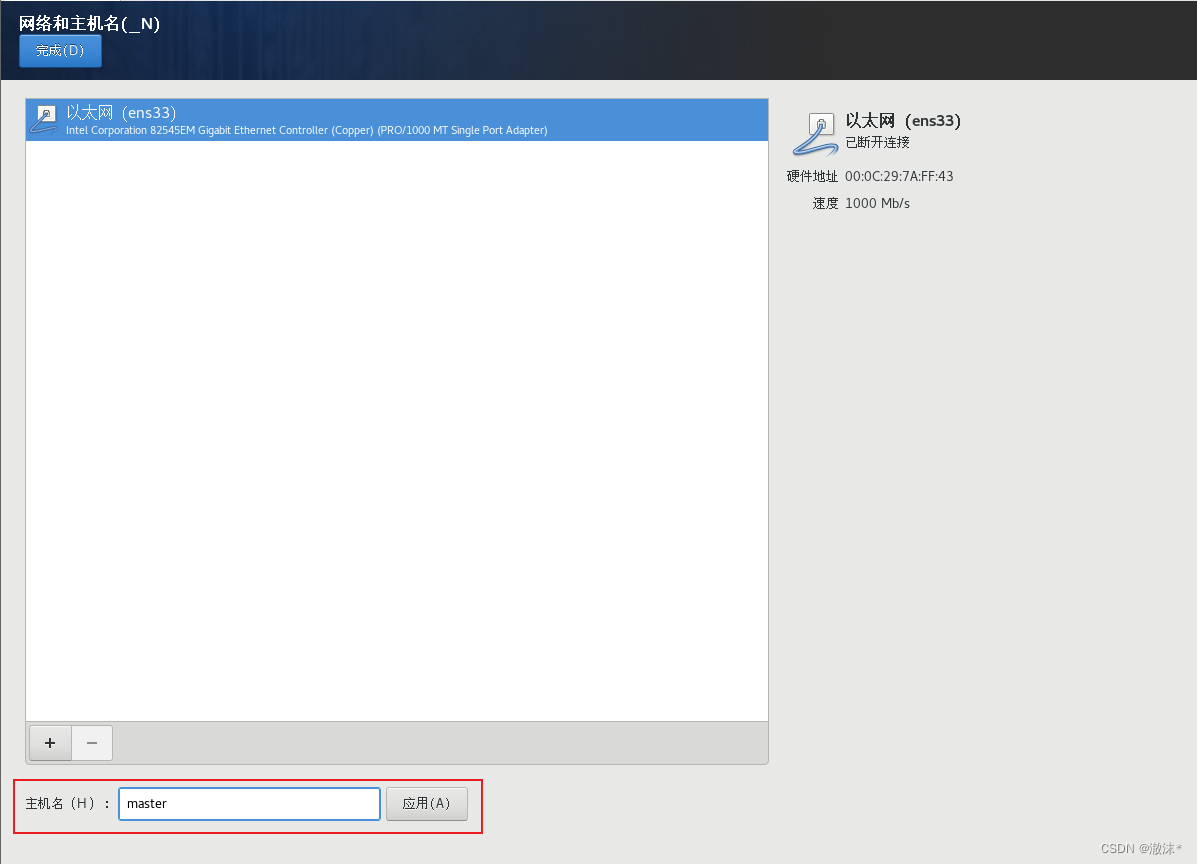
设置主机名位master,点击应用
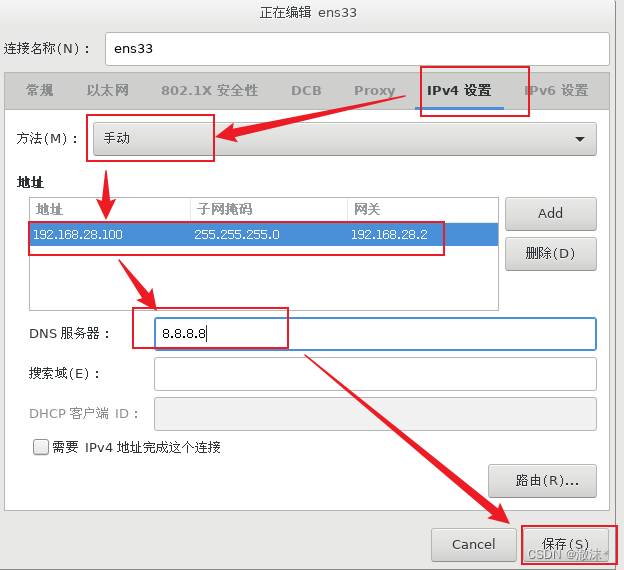
二、设置静态IP地址
点击编辑->虚拟网络编辑器
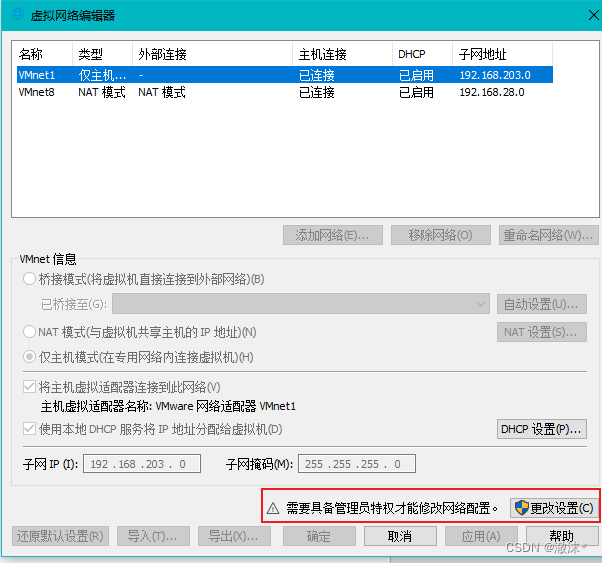
选择VMnet8,设置子网IP为:192.168.28.0,子网掩码为255.255.255.0,其他设置如图所示:
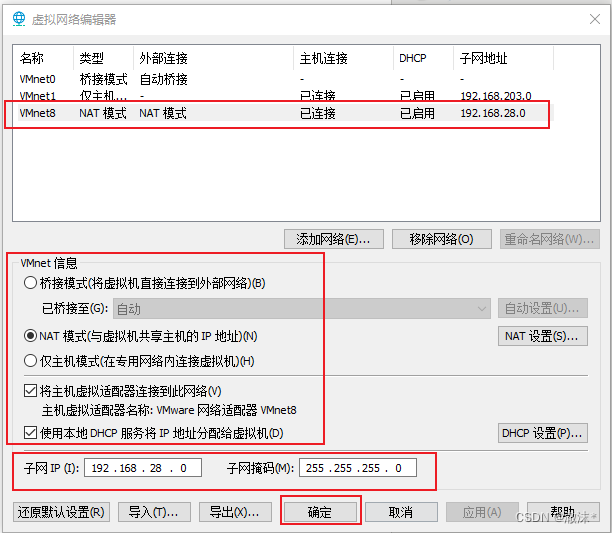
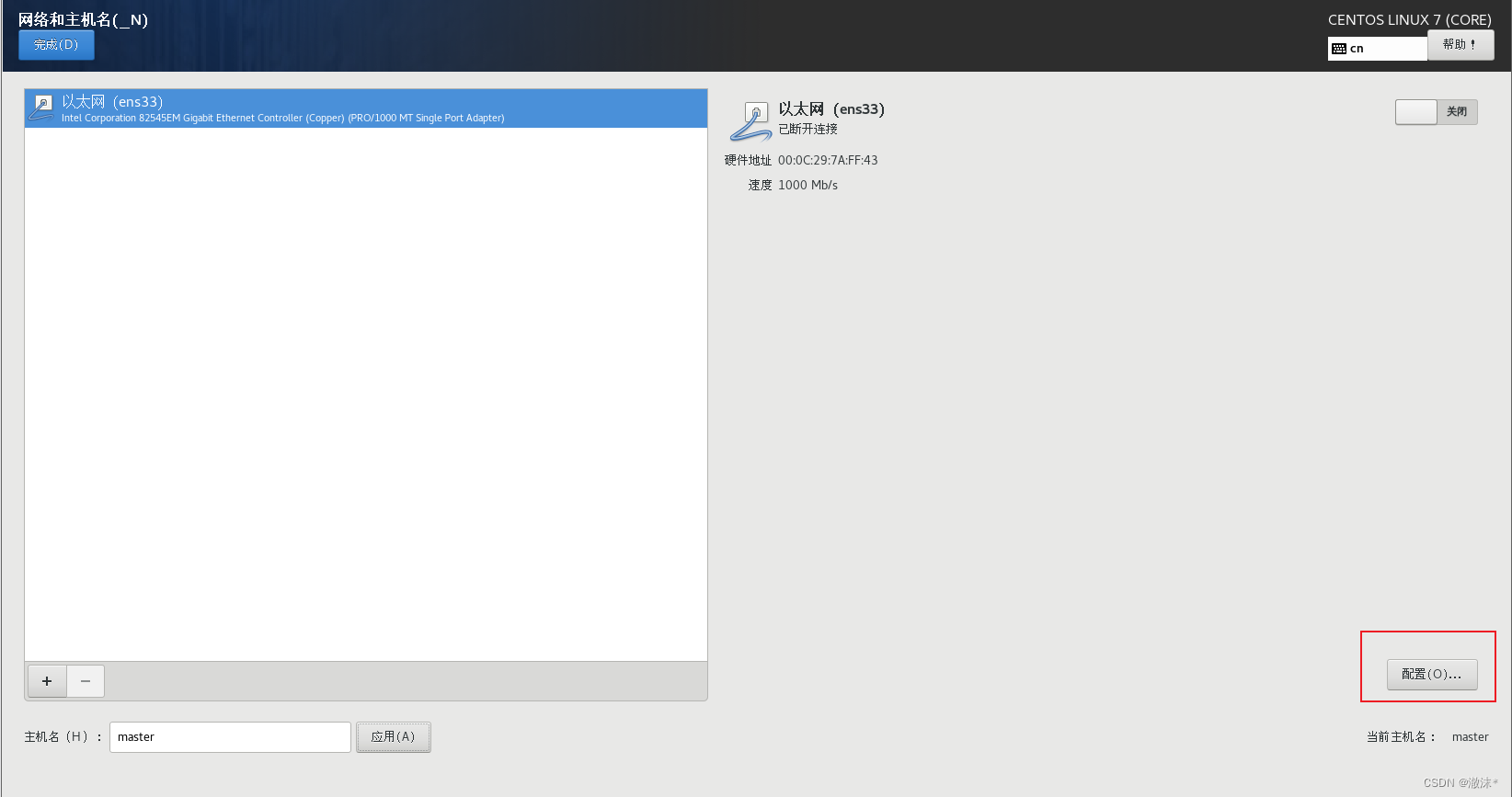
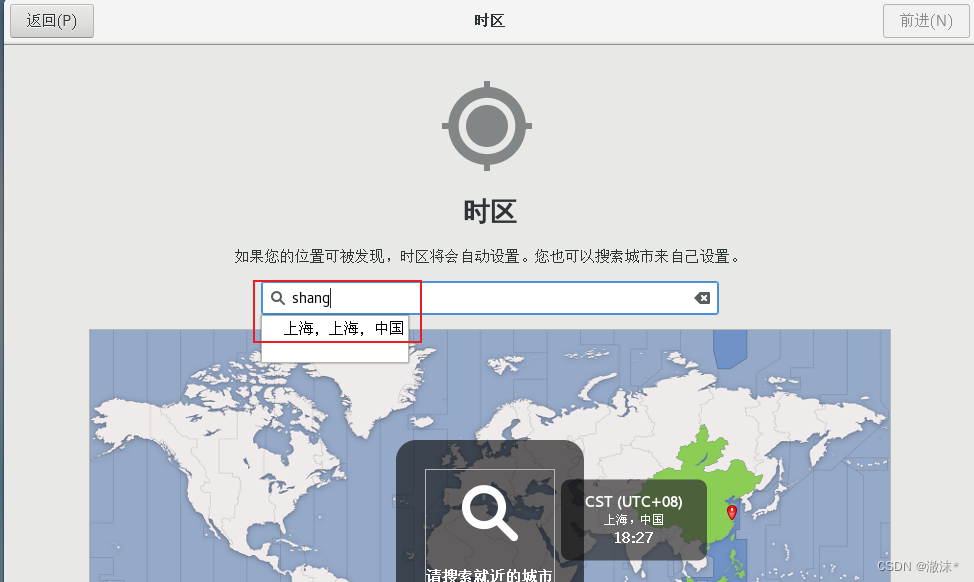
点击完成后,完成配置,选择时区为上海
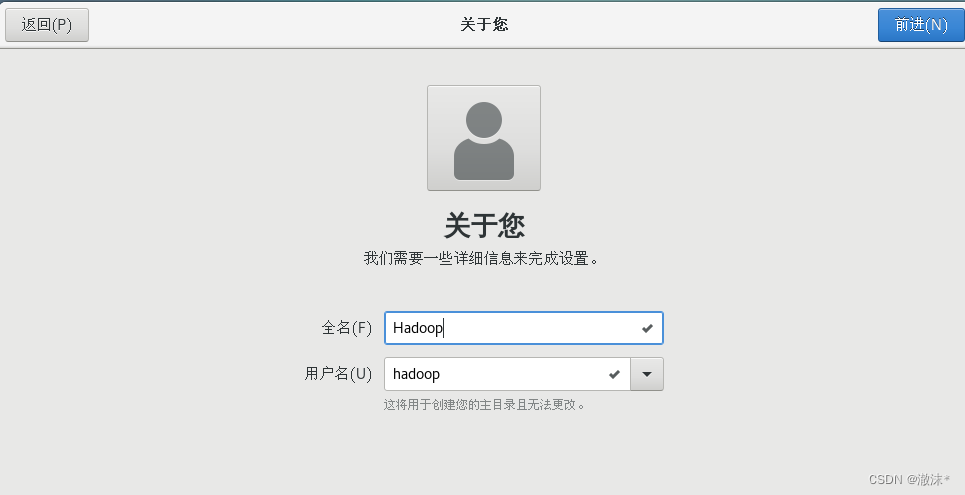
设置普通用户名
设置普通用户密码,这个一定记得
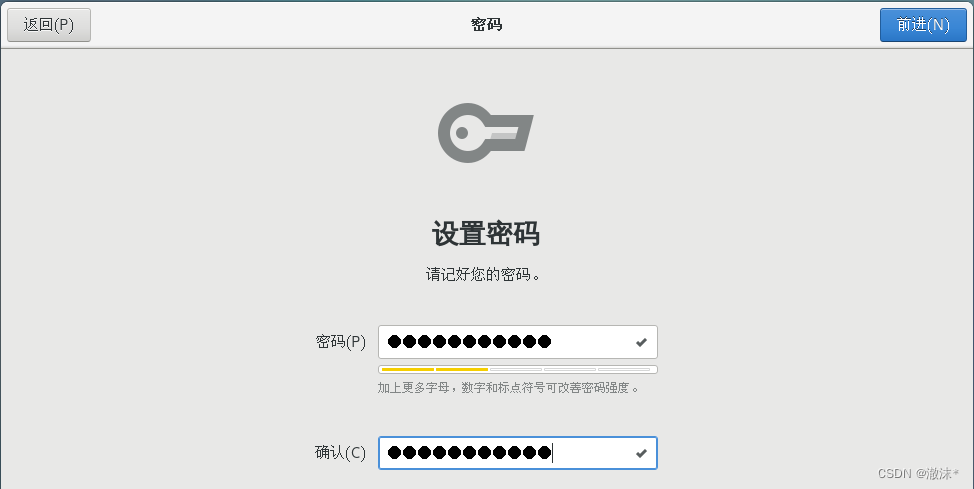
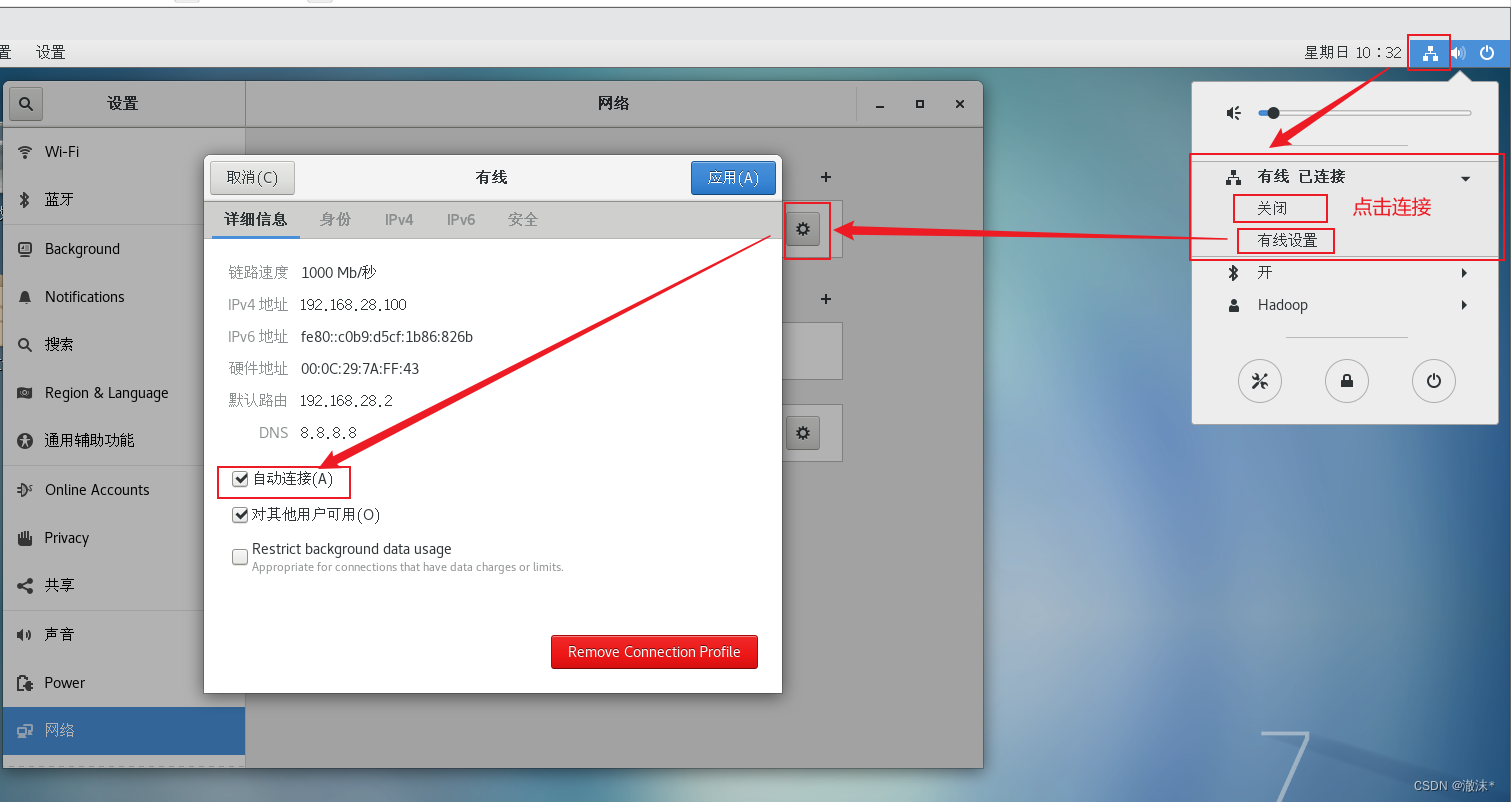
安装如图所示操作,点击应用
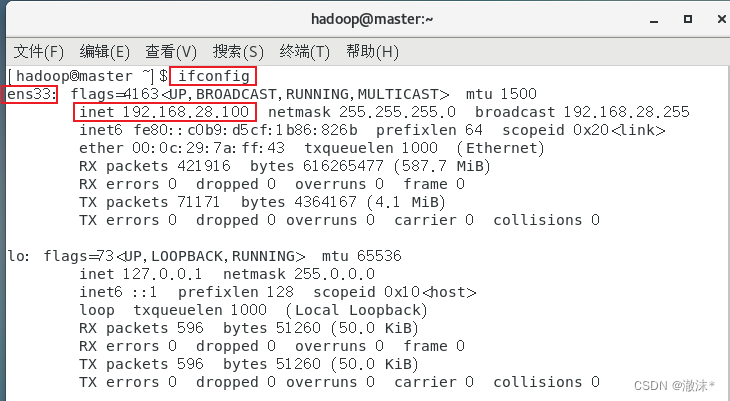
查看IP地址,如有ens33网卡为192.168.28.100,则配置成功
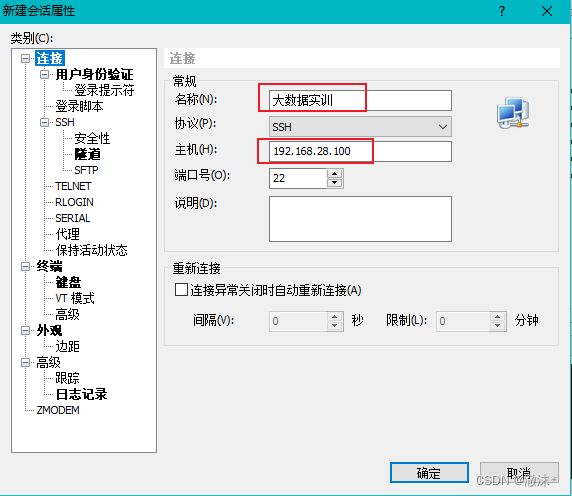
三、连接xshell

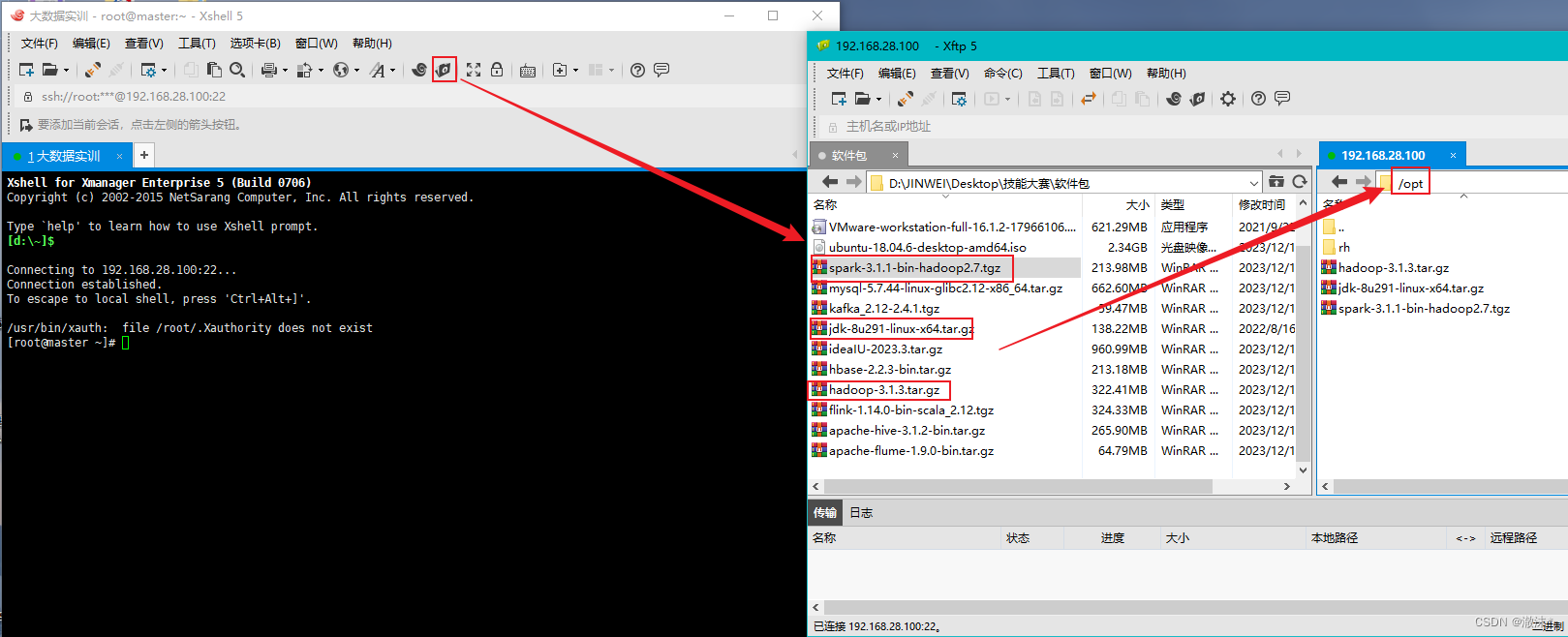
四、上传安装包
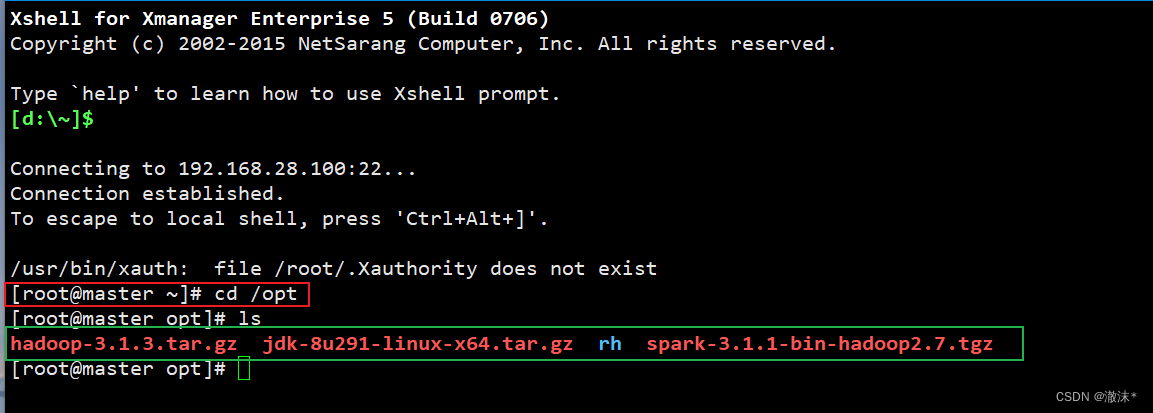
上传所需的安装包到opt目录下
五、安装JDK
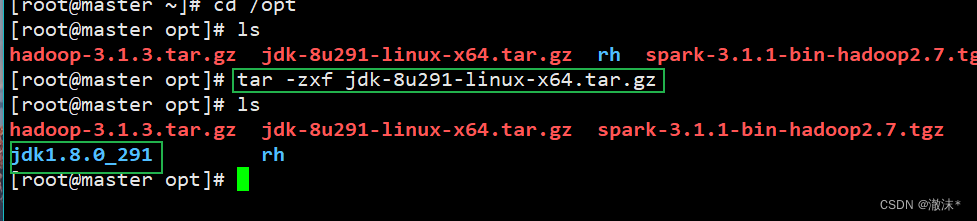
进入到opt目录下,解压JDK安装包
tar -zxf jdk-8u291-linux-x64.tar.gz
设置环境变量
vim /etc/profile
export JAVA_HOME=/opt/jdk1.8.0_291
export PATH=$JAVA_HOME/bin:$PATH
生效环境变量
source /etc/profile
查看JAVA版本,检验是否安装成功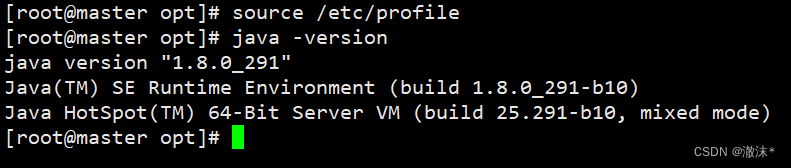
六、配置IP映射
查看主机名是否为master,若不是,则使用下面命令设置主机名
hostnamectl set-hostname master
bash刷新

进入hosts文件里面添加IP与主机别名的映射关系。
vim /etc/hosts
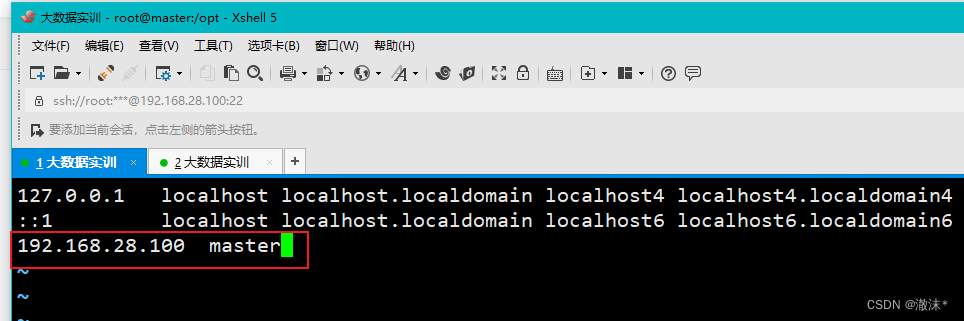
按esc,保存退出:wq
reboot重启

七、设置SSH免密登录
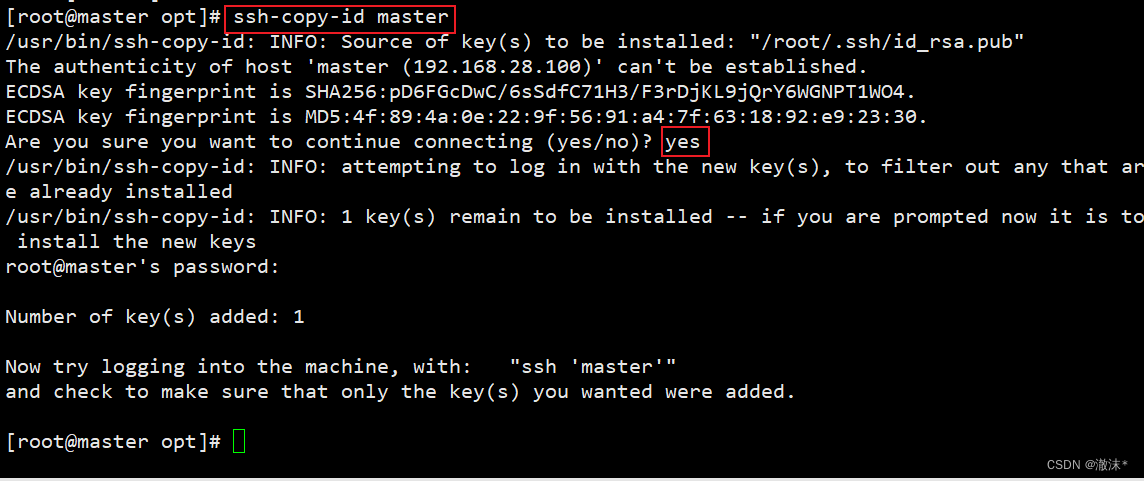
使用“ssh-keygen -t rsa”命令,接着按3次“Enter”键。ssh-keygen产生公钥与私钥(可以进入.ssh目录中查看,id_rsa:私钥,id_rsa.pub :公钥)。
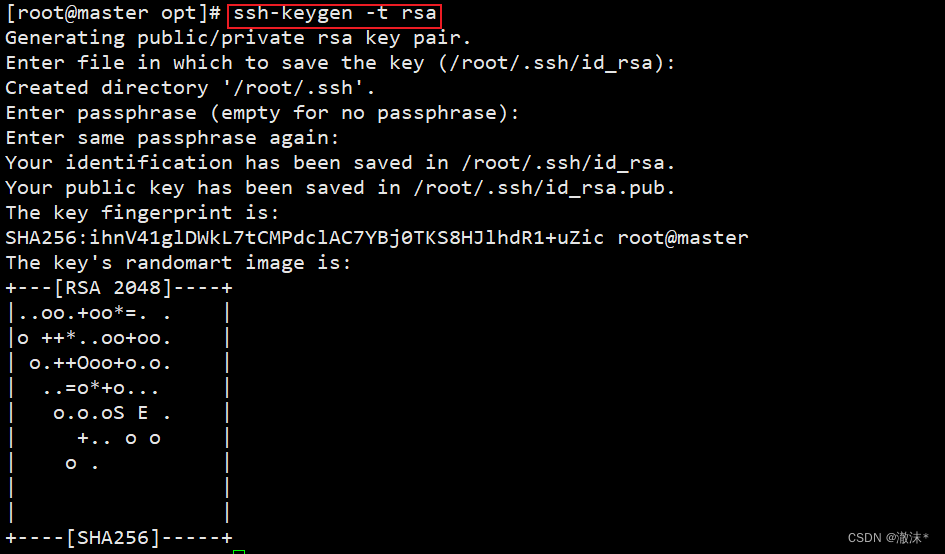
使用命令“ssh-copy-id”将公钥复制至master,输入ssh-copy-id master后,输入yes和密码。
验证免密登录是否成功,输入ssh master命令。
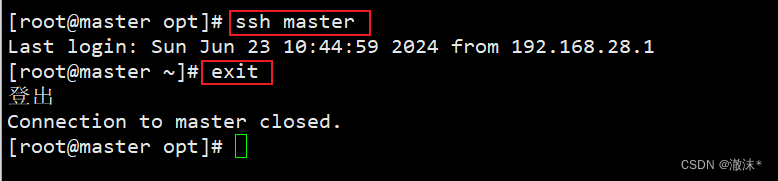
然后exit退出
七、安装Hadoop
解压安装包,在opt目录下
tar -zxf hadoop-3.1.3.tar.gz
修改环境变量
vim /etc/profile
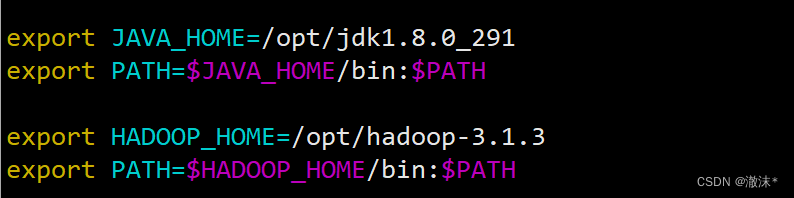
生效环境变量
source /etc/profile
进入/opt/hadoop-3.1.3/etc/hadoop目录
cd /opt/hadoop-3.1.3/etc/hadoop/
依次修改core-site.xml、hadoop-env.sh、hdfs-site.xml、mapred-site.xml、yarn-site.xml共5个配置文件的内容,具体操作步骤如下。
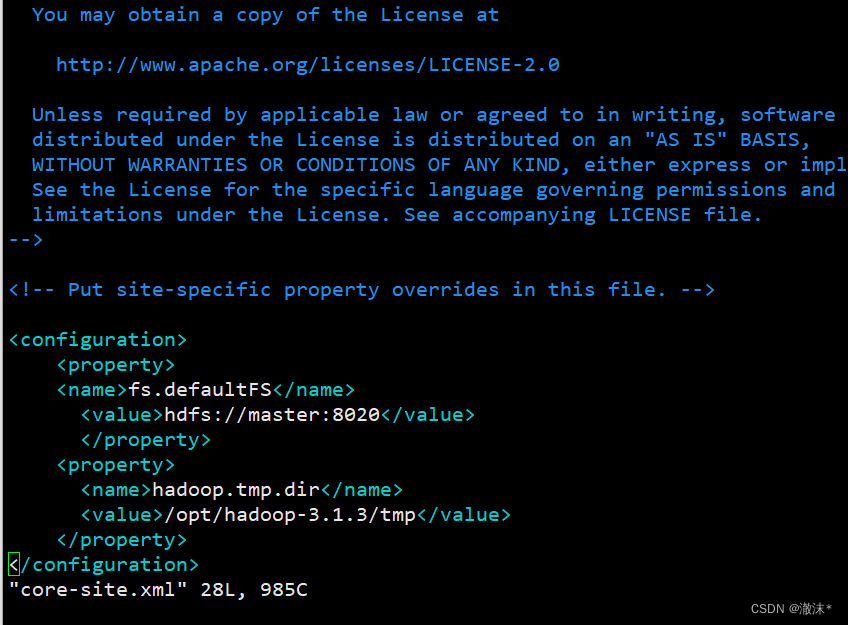
- 使用命令“vim core-site.xml”打开文件。hadoop.tmp.dir配置了Hadoop的临时文件的目录。添加的内容如下面代码所示。
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-3.1.3/tmp</value>
</property>
</configuration>
- 使用命令“*vim hadoop-env.sh”*打开文件。hadoop-env.sh文件设置了Hadoop运行基本环境的配置,需要修改JDK所在目录。在顶部添加如下代码。
export JAVA_HOME=/opt/jdk1.8.0_291
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root

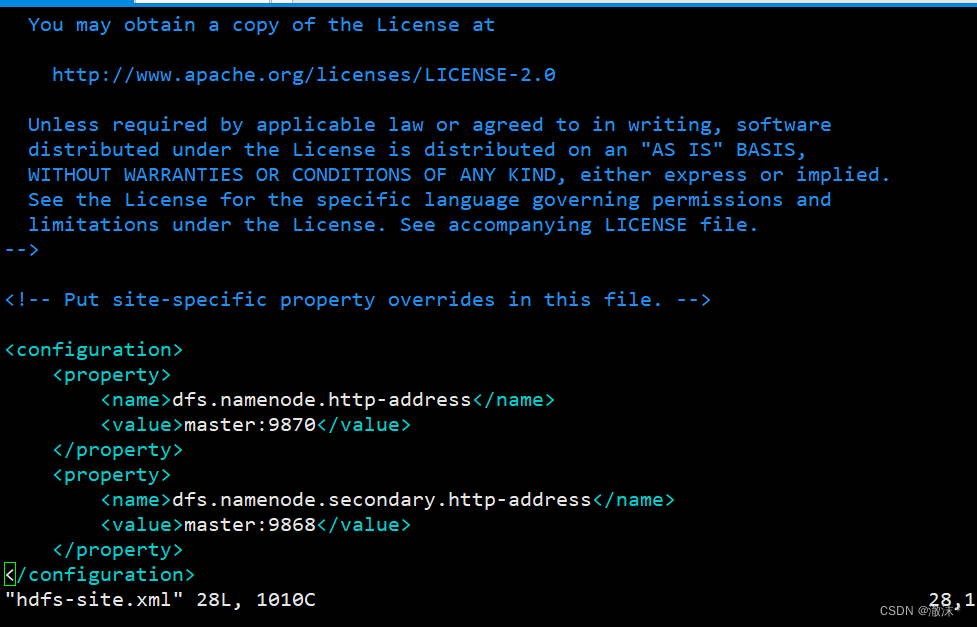
- 使用命“vim hdfs-site.xml”打开文件。hdfs-site.xml设置了HDFS相关的配置,修改内容如代码所示
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9868</value>
</property>
</configuration>
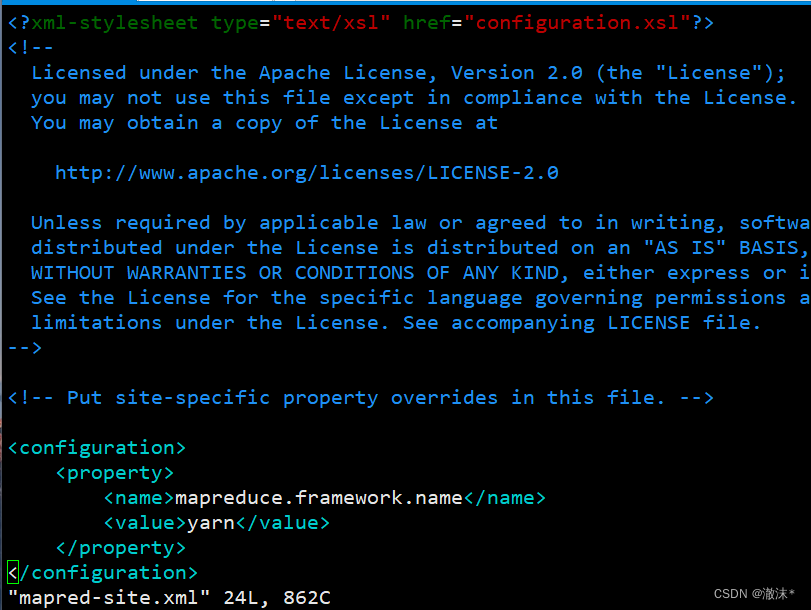
- 使用命令“*vim mapred-site.xml”*打开文件,mapred-site.xml文件添加的内容如代码所示。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
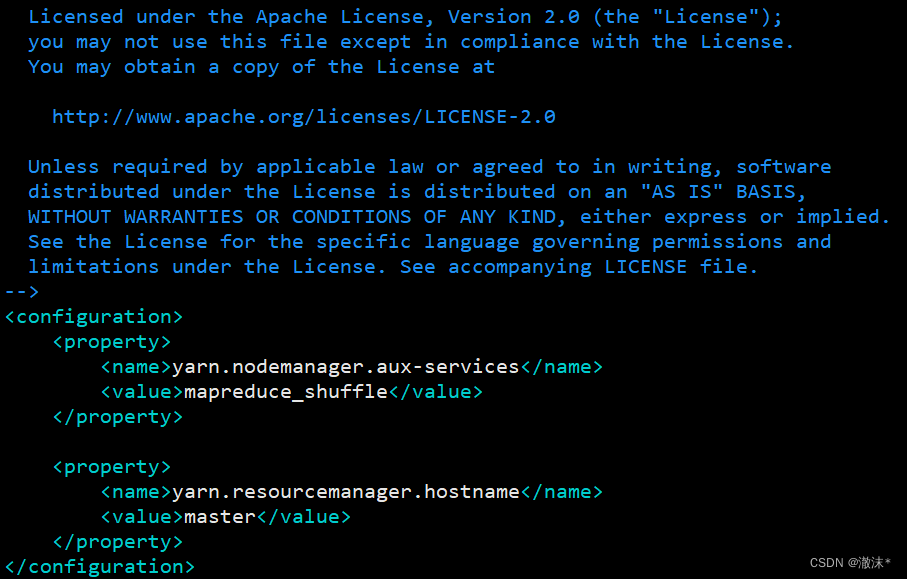
- 使用命令“*vi yarn-site.xml”*打开文件,yarn-site.xml文件修改的内容如代码所示。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>
**启动Hadoop **
(1)在首次启动签需要使用命令“hdfs namenode -format”格式化NameNode。
进入bin目录,执行格式化
cd /opt/hadoop-3.1.3/bin/

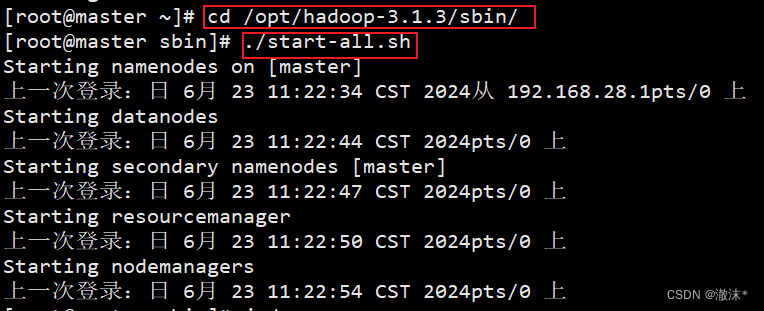
(2)格式化完成后即可启动Hadoop集群,使用命令“start-all.sh”可启动Hadoop集群。
进入sbin目录下,一键启动Hadoop
cd /opt/hadoop-3.1.3/sbin/
(3)集群启动之后,使用“jps”命令,出现如下图所示的6个进程信息,说明集群启动成功。

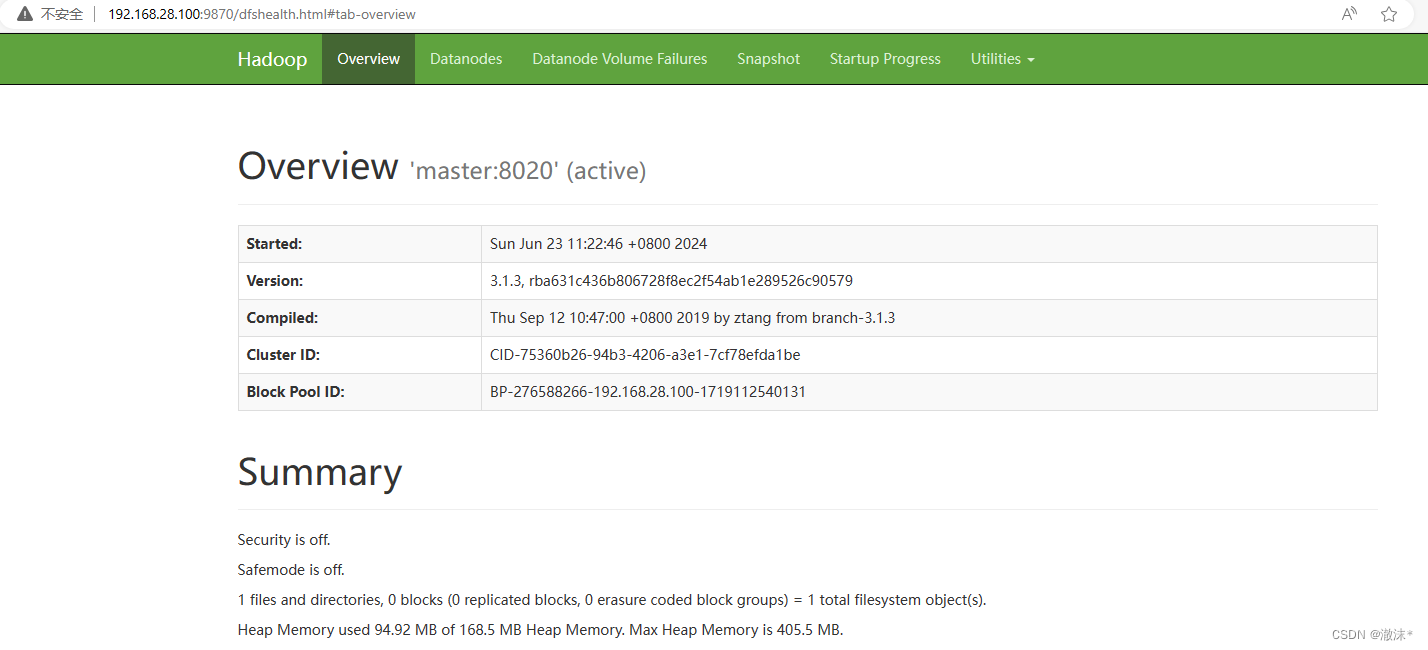
查看HDFS对应的webUI(必须要先关闭防火墙)
首先查看防火墙的状态:firewall-cmd --state
防火墙为running状态

需要关闭防火墙:systemctl stop firewalld.service
永久关闭:systemctl disable firewalld.service

浏览器输入网址:http://192.168.28.100:9870
八、安装Spark
进入/opt目录下,解压安装包

- 进入到Spark安装包的conf目录下,具体命令如下:
cd /opt/spark-3.1.1-bin-hadoop2.7/conf/
- 将spark-env.sh.template复制为spark-env.sh,具体命令如下:
cp spark-env.sh.template spark-env.sh
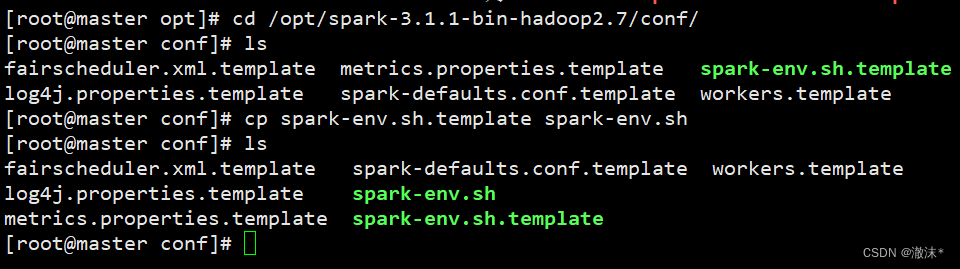
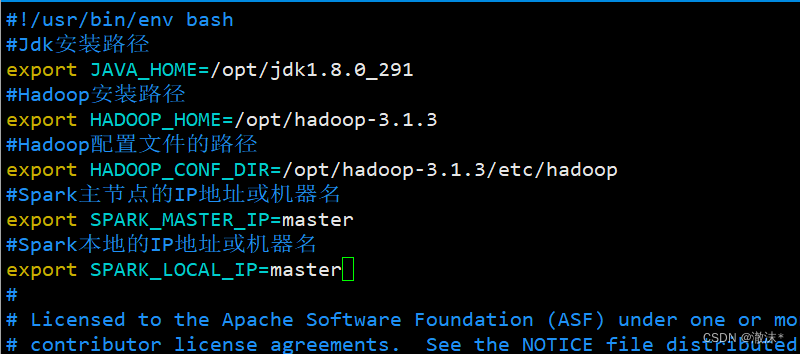
- 输入“vim spark-env.sh”命令,打开文件,在文件顶部添加如下代码:
#Jdk安装路径
export JAVA_HOME=/opt/jdk1.8.0_291
#Hadoop安装路径
export HADOOP_HOME=/opt/hadoop-3.1.3
#Hadoop配置文件的路径
export HADOOP_CONF_DIR=/opt/hadoop-3.1.3/etc/hadoop
#Spark主节点的IP地址或机器名
export SPARK_MASTER_IP=master
#Spark本地的IP地址或机器名
export SPARK_LOCAL_IP=master
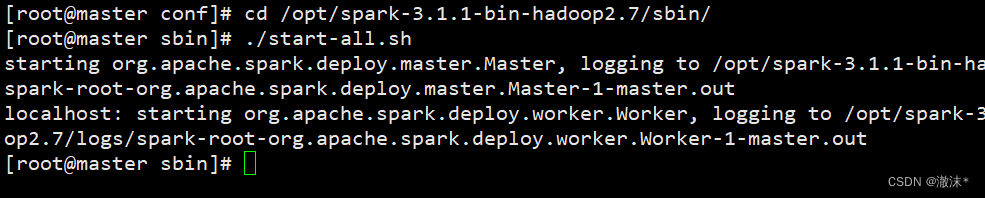
**启动测试Spark集群 **
目录切换到sbin目录下启动集群。
cd /opt/spark-3.1.1-bin-hadoop2.7/sbin/
./start-all.sh
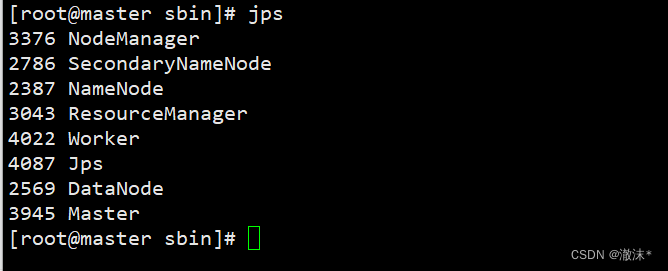
jps查看进程。
切换到Spark安装包的/bin目录下(cd /opt/spark-3.1.1-bin-hadoop2.7/bin),使用SparkPi来计算Pi的值。
#切换到Spark安装包的/bin目录下
cd /opt/spark-3.1.1-bin-hadoop2.7/bin
#运行程序
./run-example SparkPi 2

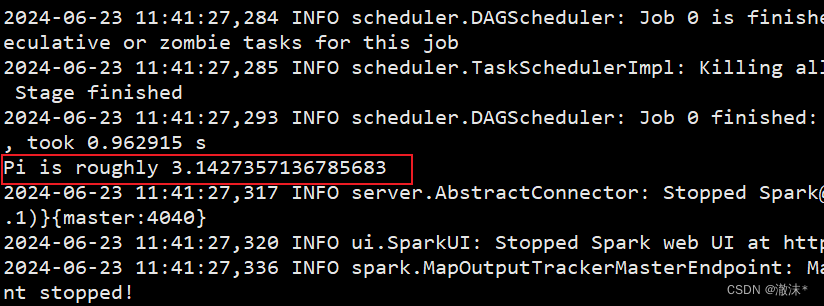
打开浏览器访问Spark自带web页面 浏览器输入网址:http://192.168.28.100:8080/

九、安装MySQL
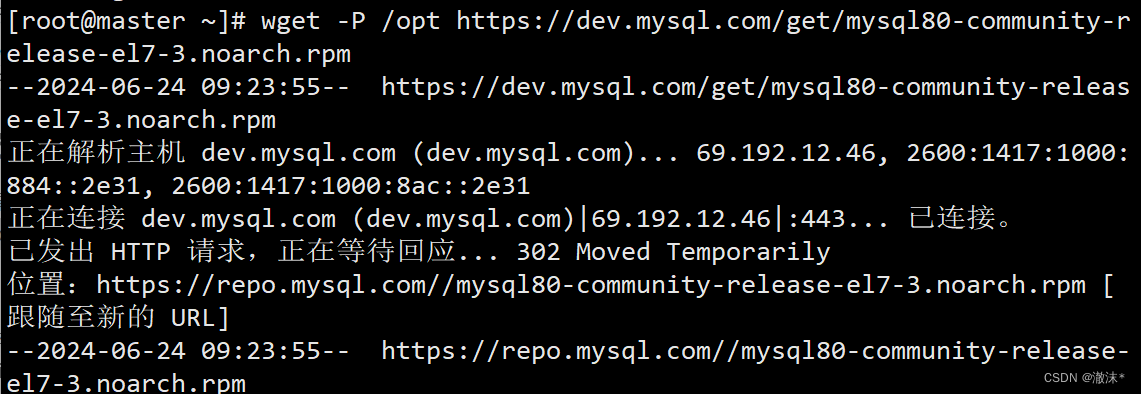
1.wegt下载mysql8.x源或上传rpm包到master节点
wget -P /opt https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm
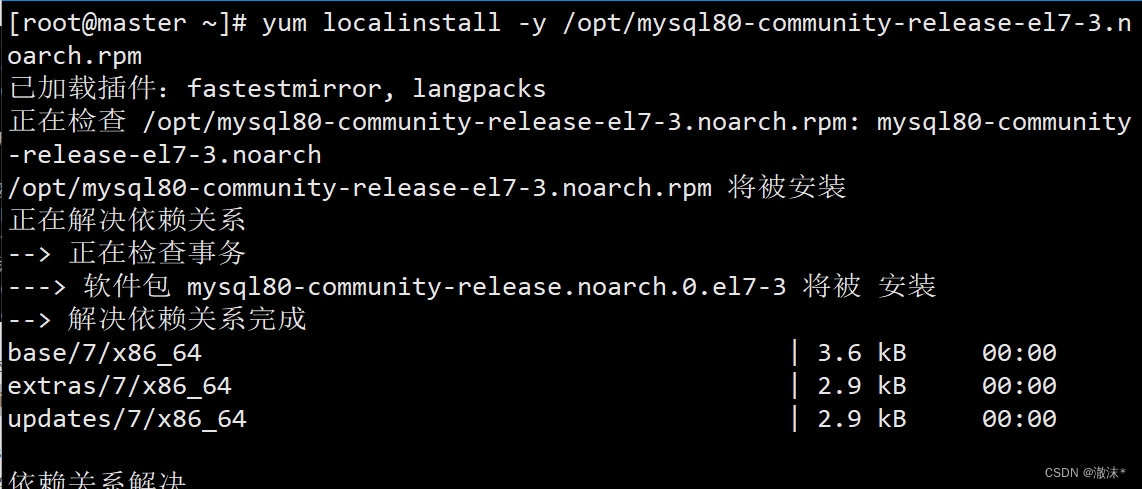
1.2 加载本地yum源
yum localinstall -y /opt/mysql80-community-release-el7-3.noarch.rpm
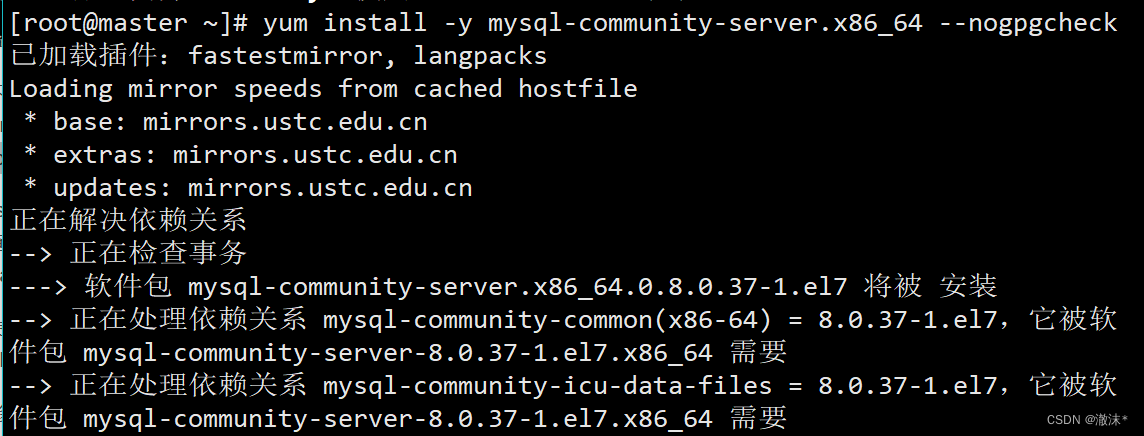
1.3 下载mysql服务
yum install -y mysql-community-server.x86_64 --nogpgcheck
service mysqld start 开启mysql服务

2.mysql 密码设置
2.1 查询mysql初始密码 注意:每个人密码不一样
cat /var/log/mysqld.log |grep password

2.2 使用初始密码登录
mysql -u root -p 初始密码
由于修改密码规则需经过密码重置,因此基于初始密码做简单修改,如在末尾增加一个a
alter user 'root'@'localhost' identified by '初始密码a';

2.3 修改8.0密码规则
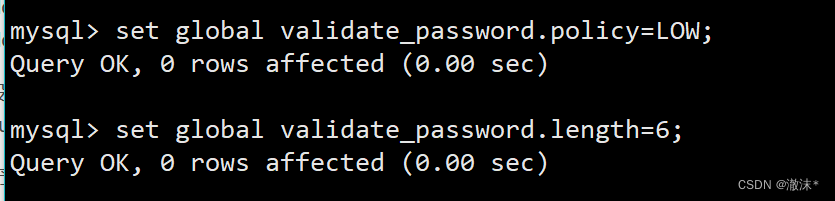
set global validate_password.policy=LOW;
set global validate_password.length=6;
2.4 设置自定义密码
alter user 'root'@'localhost' identified by '123456';

- 赋予外部连接权限
create user 'root'@'%' identified by '123456';
grant all privileges on . to 'root'@'%' with grant option;

刷新系统权限相关表
flush privileges;

退出登录
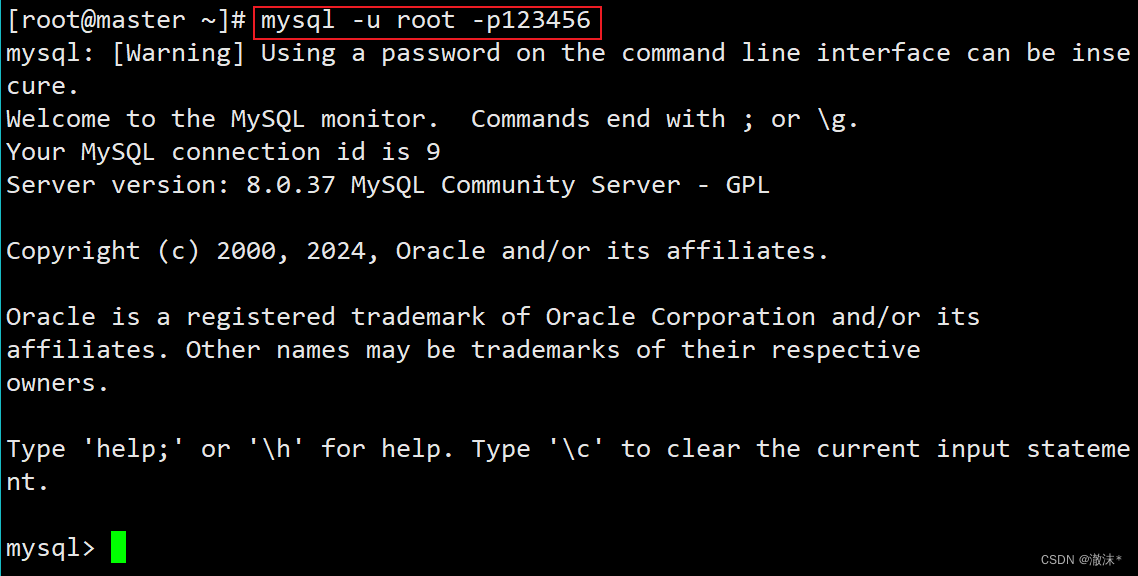
使用密码123456重新登录MySQL,可以看到登录成功
十、安装Hive
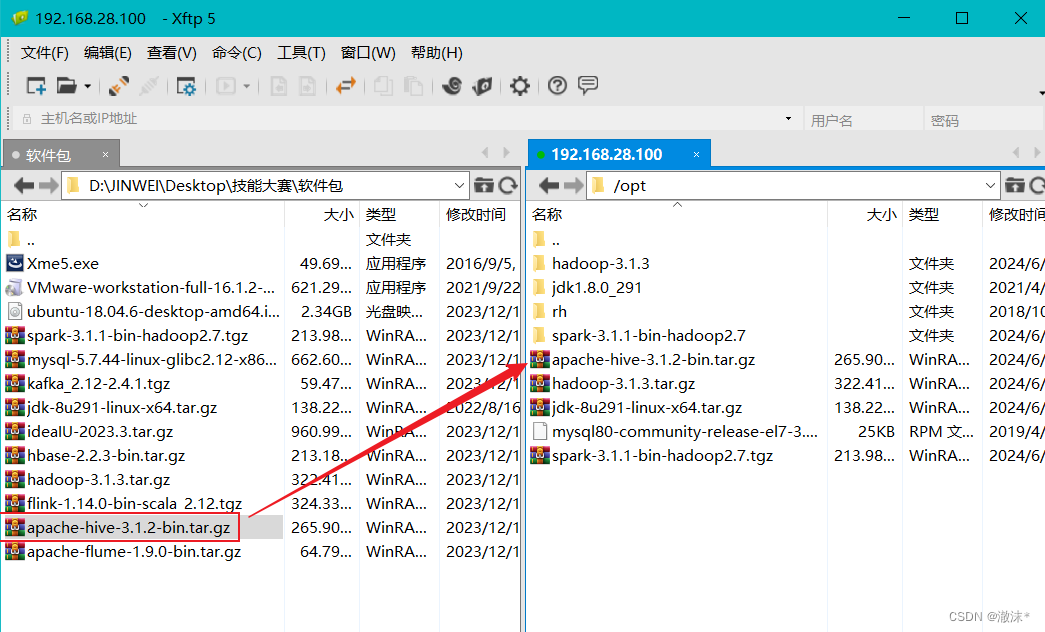
1.上传Hive安装包到/opt目录
2.解压Hive安装包
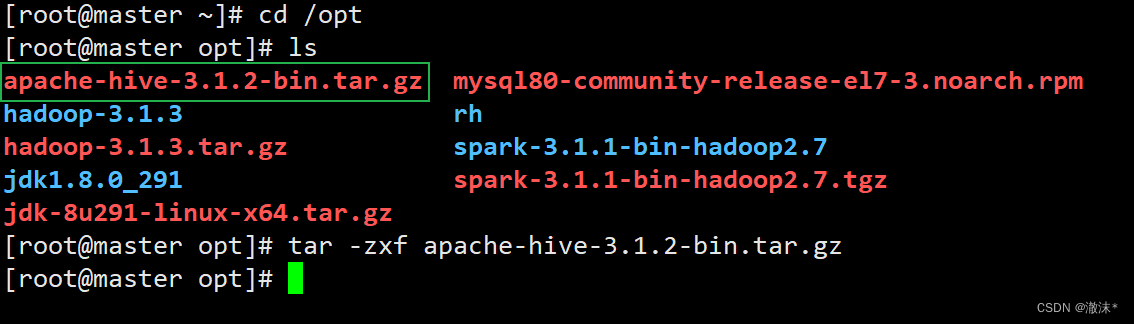
3.添加环境变量
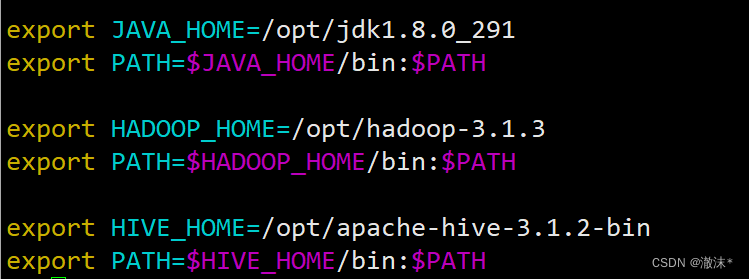
4.生效环境变量
source /etc/profile
5.解决日志Jar包冲突
Hive由日志slf4j配置,但是我们yarn也有,两者会冲突。将hive安装目录下的lib目录的日志文件名修改。
cd /usr/local/apache-hive-3.1.2-bin/lib
mv log4j-slf4j-impl-2.10.0.jar log4j-slf4j-impl-2.10.0.jar.bak

6.将MySQL的JDBC驱动拷贝到Hive的lib目录下,驱动文件下载地址:链接

将hive安装目录lib下的jline-2.12.jar同步到hadoop类库中,勿忘子节点同样需要同步
cp /opt/apache-hive-3.1.2-bin/lib/jline-2.12.jar /opt/hadoop-3.1.3/share/hadoop/yarn/lib/

删除hive安装目录lib下的guava-19.0.0.jar包,并将hadoop类库中的新版guava包同步过来
rm -rf /opt/apache-hive-3.1.2-bin/lib/guava-19.0.jar
cp /opt/hadoop-3.1.3/share/hadoop/common/lib/guava-27.0-jre.jar /opt/apache-hive-3.1.2-bin/lib/

7.配置hive-site.xml
进入hive安装目录下的conf目录:cd /opt/apache-hive-3.1.2-bin/conf/
在hive/conf目录下新建hive-site.xml文件:vim hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<!--你的Mysql数据库密码-->
<value>123456</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://127.0.0.1:3306/hive?createDatabaseIfNotExist=true&useUnicode=true&characterEncoding=UTF-8&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>datanucleus.readOnlyDatastore</name>
<value>false</value>
</property>
<property>
<name>datanucleus.fixedDatastore</name>
<value>false</value>
</property>
<property>
<name>datanucleus.autoCreateSchema</name>
<value>true</value>
</property>
<property>
<name>datanucleus.autoCreateTables</name>
<value>true</value>
</property>
<property>
<name>datanucleus.autoCreateColumns</name>
<value>true</value>
</property>
</configuration>
- 配置hive-env.sh
在顶部添加:
export HADOOP_HOME=/opt/hadoop-3.1.3
export HIVE_CONF_DIR=/opt/apache-hive-3.1.2-bin/conf
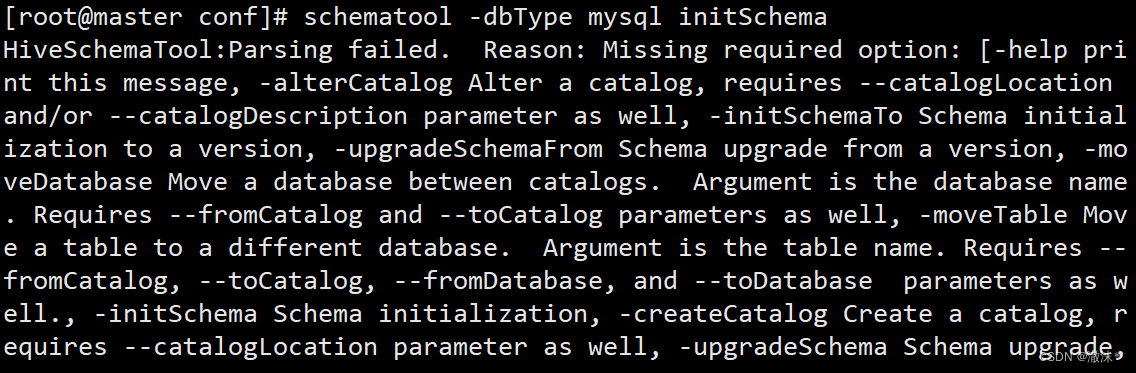
9.初始化Mysql服务器
在启动Hive之前,需要执行schematool -dbType mysql -initSchema
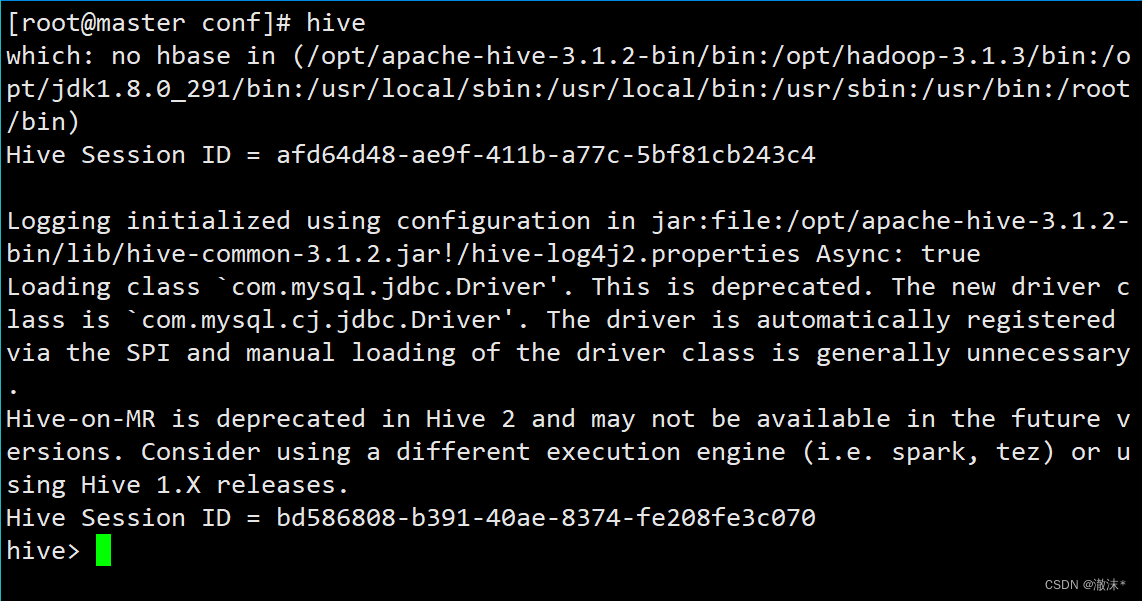
10.启动hive成功的界面(一定要先启动Hadoop集群):
使用hive命令启动
总结
到此,我们Hadoop安装和配置就到了尾声,Hadoop第一次安装配置的过程中可能会遇到各种困难,但是各位同学一定要坚持下去!!! 勇敢牛牛,不怕困难!
版权归原作者 澈沫* 所有, 如有侵权,请联系我们删除。