
提效 7 倍,Apache Spark 自适应查询优化在网易的深度实践及改进
Performance Tuning
配置Spark SQL开启Adaptive Execution特性
How To Use Spark Adaptive Query Execution (AQE) in Kyuubi
【spark系列3】spark 3.0.1 AQE(Adaptive Query Exection)分析
玩转Spark Sql优化之3.0特性AQE(六)
As of Spark 3.0, there are three major features in AQE:
- coalescing post-shuffle partitions,
- converting sort-merge join to broadcast join,
- skew join optimization.
AQE 设计思路
不同于传统以整个执行计划为粒度进行调度的方式,AQE 会把执行计划基于 shuffle 划分成若干个子计划,每个子计划用一个新的叶子节点包裹起来,从而使得执行计划的调度粒度细化到 stage 级别 (stage 也是基于 shuffle 划分)。这样拆解后,AQE 就可以在某个子执行计划完成后获取到其 shuffle 的统计数据,并基于这些统计数据再对下一个子计划动态优化。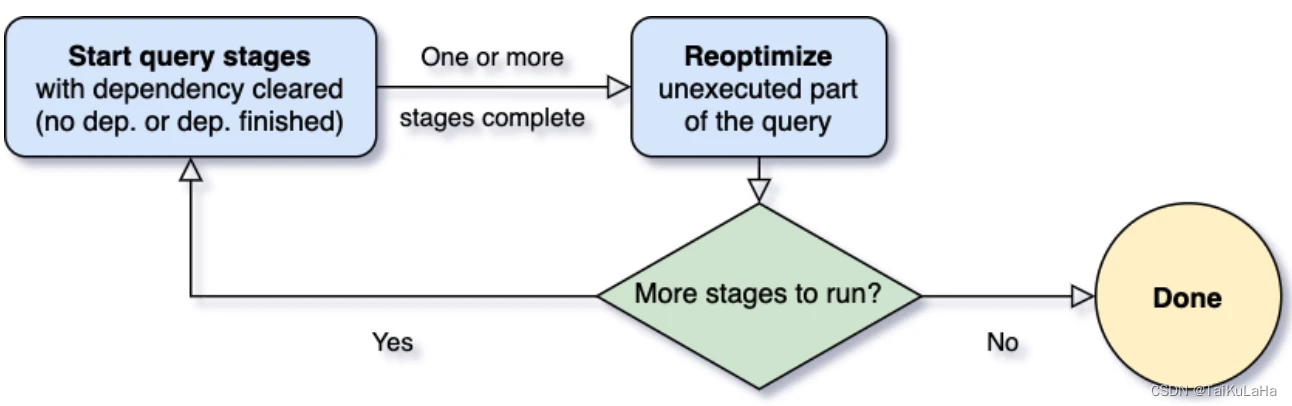
coalescing post-shuffle partitions
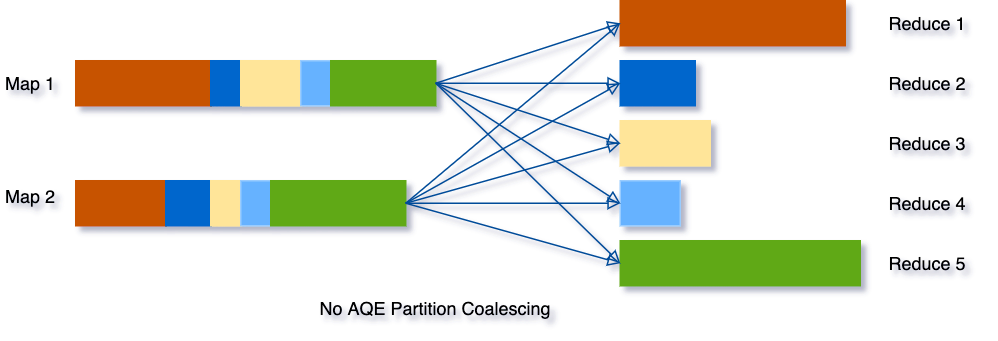
先明确一个简单的概念 map 负责写 shuffle 数据,reduce 负责读取 shuffle 数据。而 shuffle reader 可以理解为在 reduce 里负责拉 shuffle 数据的工具。标准的 shuffle reader 会根据预设定的分区数量 (也就是我们经常改的 spark.sql.shuffle.partitions),在每个 reduce 内拉取分配给它的 shuffle 数据。而动态生成的 shuffle reader 会根据运行时的 shuffle 统计数据来决定 reduce 的数量。下面举两个例子,分区合并和 Join 动态优化。
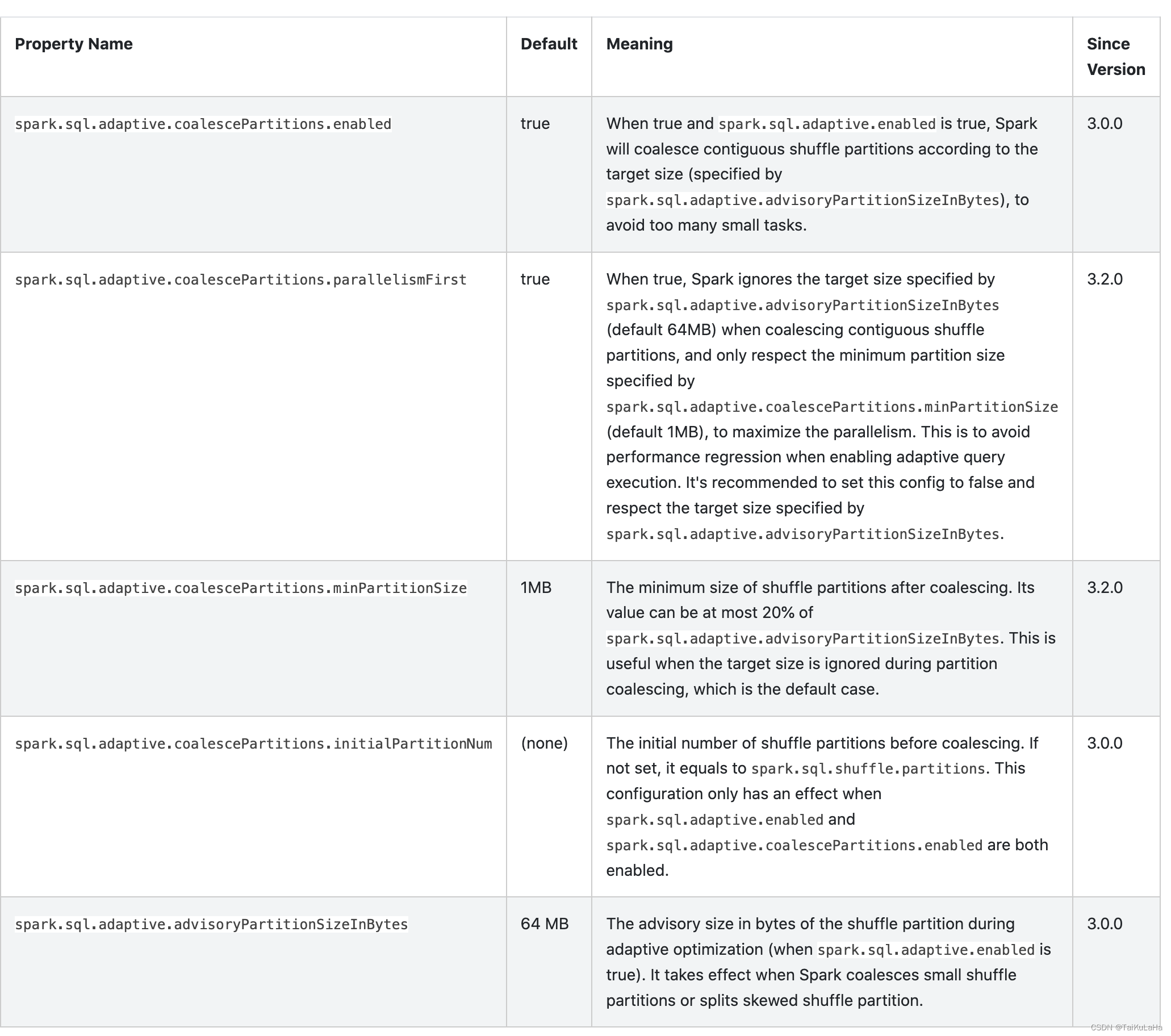
- 分区合并是一个通用的优化,其思路是将多个读取 shuffle 数据量少的 reduce 合并到 1 个 reduce。假如有一个极端情况,shuffle 的数据量只有几十 KB,但是分区数声明了几千,那么这个任务就会极大的浪费调度资源。在这个背景下,AQE 在跑完 map 后,会感知到这个情况,然后动态的合并 reduce 的数量,而在这个 case 下 reduce 的数量就会合并为 1。这样优化后可以极大的节省 reduce 数量,并提高 reduce 吞吐量。
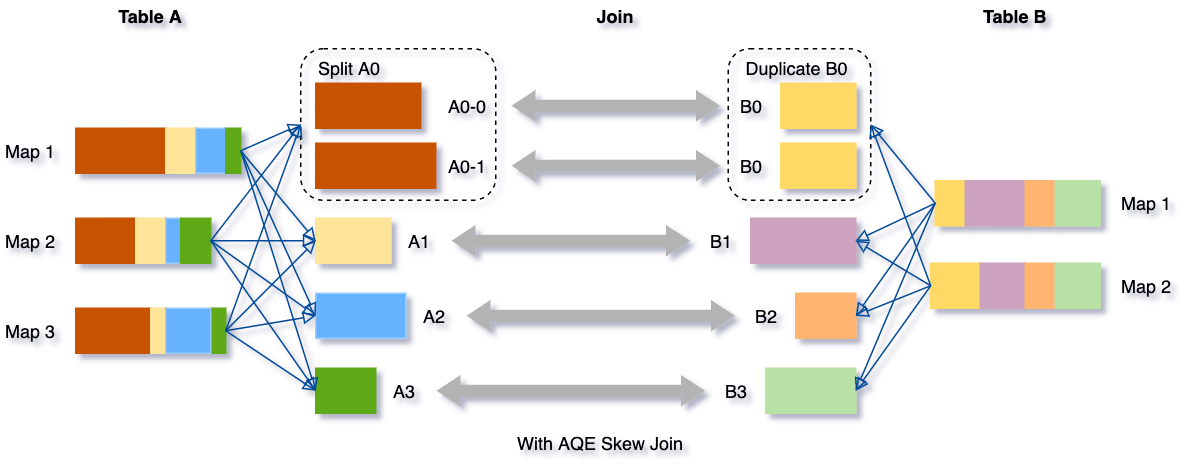
- Join 倾斜优化相对于分区合并,Join 倾斜优化则只专注于 Join 的场景。如果我们 Join 的某个 key 存在倾斜,那么对应到 Spark 中就会出现某个 reduce 的分区出现倾斜。在这个背景下,AQE 在跑完 map 后,会预统计每个 reduce 读取到的 shuffle 数据量,然后把数据量大的 reduce 分区做切割,也就是把原本由 1 个 reduce 读取的 shuffle 数据改为 n 个 reduce 读取。这样处理后就保证了每个 reduce 处理的数据量是一致的,从而解决数据倾斜问题。

converting sort-merge join to broadcast join
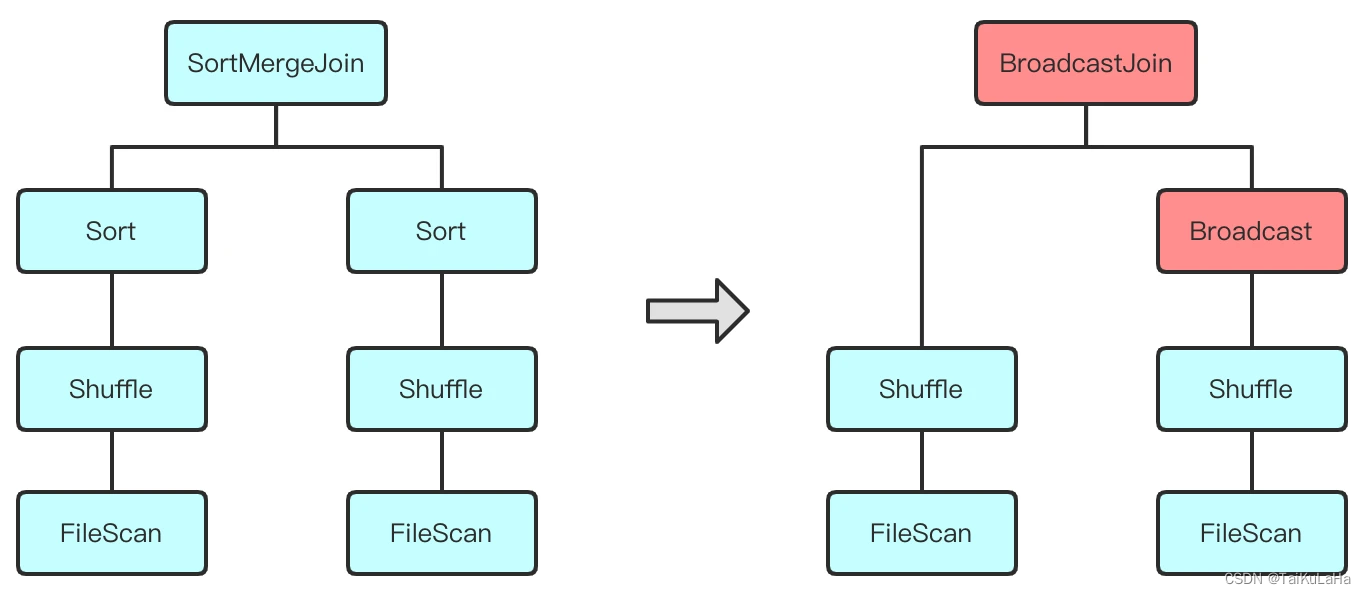
动态修改执行计划包括两个部分:对其逻辑计划重新优化,以及生成新的物理执行计划。我们知道一般的 SQL 执行流程是,逻辑执行计划 -> 物理执行计划,而 AQE 的执行逻辑是,子物理执行计划 -> 父逻辑执行计划 -> 父物理执行计划,这样的执行流程提供了更多优化的空间。比如在对 Join 算子选择执行方式的时候可能有原来的 Sort Merge Join 优化为 Broadcast Hash Join。执行计划层面看起来是这样:
skew join optimization
版权归原作者 TaiKuLaHa 所有, 如有侵权,请联系我们删除。