
🍁作者简介:🏅云计算领域优质创作者🏅新星计划第三季python赛道TOP1🏅 阿里云ACE认证高级工程师🏅
✒️个人主页:小鹏linux
💊个人社区:小鹏linux(个人社区)欢迎您的加入!
为大家推荐一款刷题神奇 点击链接访问牛客网
各大互联网大厂面试真题。基础题库到进阶题库等各类面试题应有尽有!
牛客网面经合集,满足大厂面试技术深度,快速构建Java核心知识体系大厂面试官亲授,备战面试与技能提升,主要考点+主流场景+内功提升+真题解析
1.容器技术
容器技术显然不是什么新概念,最早的容器技术可以追溯到 1979 年诞生的 chroot 技术 ,容器技术又称为容器虚拟化,这是虚拟化技术中的一种 ,目前虚拟化技术主要有硬件虚拟化、半虚拟化和操作系统虚拟化等 。本系列文章讲述的容器虚拟化属于操作系统虚拟化,其相较于其他主流虚拟化技术更为轻量。
1.1 虚拟化技术
虚拟化 (Virtualization) 就是通过虚拟化技术将一台实体计算机虚拟为多台逻辑计算机,虚拟后的每一台逻辑计算机都可以运行不同的操作系统,从逻辑上来看,每台逻辑计算机都是一个虚拟实体,它们的运行是相互不影响、相互隔离的,即每一个实例都是彼此独立的 ,虽然通过虚拟技术可以运行虚拟计算机 ,但是它们并不是在真实的基础上运行的 。因此虚拟化就是一种技术,通过虚拟化的技术在一个单核的 CPU 上虚拟出多核的 CPU 处理器,对于虚拟化而言,这些技术不单单只CPU 虚拟化,还有很多,比如:系统虚拟化、网络虚拟化、桌面虚拟化和应用虚拟化等,显而易见,虚拟化归根到底就是表示计算机资源的—种抽象方法 深入了解虚拟化后,可以知道虚拟化并非是简单的一种技术或者一个实体,它更是一系列虚拟技术的集合,如:硬件虚拟化技术、处理器虚拟化技术、指令虚拟化技术、软件虚拟化技术等。
其实虚拟化并不是一个新的技术概念,虚拟化技术在很早之前已经被计算机行业列为主流的竞争焦点之一 ,20 世纪 70 年代, IT 巨头 IBM 的虚拟概念是将一个 CPU 处理器虚拟成多个 CPU理器,这些逻辑的虚拟处理器可以同时处理执行任务,后来逐渐地每一个虚拟 CPU 都是彼此独立的并可以同时工作,也就是后来的system390 计算机 。近年来,虚拟化技术再次成为了 IT 领域研究的热点,随着 CPU 处理器处理能力的提高,四核、八核、十六核、甚至是三十二核 CPU 处理器相继出现,在这些硬件性能显著提高的基础上,虚拟化技术带来了诸多的好处,特别是 x86 (冯诺依曼结构)架构以及 am, (哈曼结构)架构;同时,虚拟化在嵌入式研究领域中也越来越受到重视。
虚拟化技术从早期发展到现在,可以实现虚拟化技术的方法已经数不胜数,虚拟化的类型也有很多 。不同的方法通过不同层次的抽象可以实现相同的虚拟化结果,根据不同的分类依据,虚拟化也有不同的分类种类,比如按照虚拟技术的虚拟对象分类,或者按照虚拟技术的抽象程度分类等。
1.1.1 虚拟化技术分类
虚拟化技术的分类与定义在不同领域有不同的理解 ,对于计算机领域, 虚拟化技术主要分为两大类,一类硬件虚拟化,另一类基于软件虚拟化 。硬件虚拟化并不多见,大都是半虚拟化与软件结合。硬件虚拟技术在所有的虚拟化分类中,它是最为复杂的技术之一,硬件虚拟技术就是在宿主物理真机上创建一个模拟硬件的程序,来仿真模拟所有操作系统运行环境中所有的硬件,在这个基础上运行我们的操作系统。
硬件虚拟化是依赖固件以及硬件共同协作开发的,固件开发人员可以利用目标硬件 VM 在仿真环境中验证实际的代码,而不需要等到硬件实际可用的时候详细研究 硬件虚拟化的每—条指令都必须在真实硬件的基础上来进行仿真模拟, 也就是说,所有的硬件都是通过软件仿真模拟的,也正因为如此,硬件虚拟化的运行效率是很低的,倘若我们对硬件的各方面限制都比较严格的话,甚至要求多级缓存的话,在硬件虚拟化技术上运行的系统速度、性能等各方面都较差。
1.1.2 容器技术在虚拟化技术中的位置
相比之下,应用较为广泛的则是基于软件的虚拟化技术 而软件虚拟化又可以分为应用虚拟化(例如 Wine)和平台虚拟化(例如虚拟机),而本篇博文中的容器技术属于操作系统虚拟化,操作系统虚拟化又属于平台虚拟化中的一种,如下图:
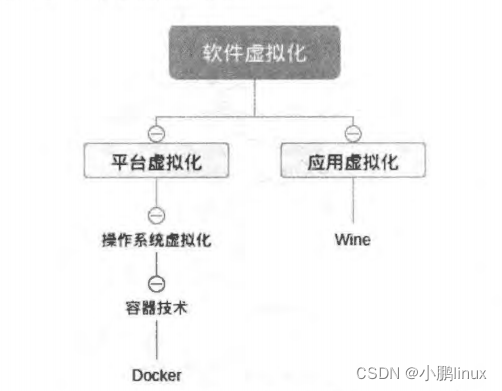
所谓容器,顾名思义就是用来放东西的器具 ,有意思的是在 Docker 刚引入国内的时候,曾有过一番讨论 Container 这个单词是翻译为"容器”合适,还是“集装箱“合适 。之所以有人建议翻译为“集装箱”,并不仅仅是因为 Docker 的图标是—条鲸鱼驮着几个集装箱的形象,而因为容器技术本身就是借鉴了工业运输上的经验发展而来的。
《经济学家》杂志是这样评价工业运输领域集装箱的 :“ 没有集装箱,就不可能有全球化 “在 1956年集装箱出现之前 ,货物运输缺乏标准,成本很高,特别是远洋运输,直到“集装箱”这个概念的出现,毫不起眼的集装箱降低了货物运输的成本,实现了货物运输的标准化,以此为基础逐步建立起全球范围内的船舶、港口、航线、 公路、中转站、桥梁、隧道、多式联运相配套的物流系统,世界经济形态因此而发生改变。同样的,软件行业的容器技术也是在尝试打造一套标准化的软件构建、分发流程,以降低运维成本 ,提高软件安全与运行稳定等。与工业运输的集装箱不同,容器技术要复杂很多,容器技术不仅仅要打造一个运输用的“集装箱”,还要保证软件在容器内能够运行,在操作系统上打造—个“独立的箱子" 这需要解决文件系统、网络、硬件等多方面的问题。经过长时间的发展,容器技术现已逐步成熟,并在 Docker 的诞生下迎来了它的繁荣时代 ,大家大可把容器理解为一个沙盒,每个容器独立 ,各个容器之间可以通过容器引擎相互通信。
1.2 容器技术于Docker
如果说工业上的集装箱是从一个箱子开始的,那么软件行业上的容器则是从文件系统隔离开始,说到容器技术,最早的容器技术大概是 chroot (1979 年)了,它最初是 UNlX 操作系统上的一个系统调用,用于将—个进程及其子进程的根目录改变到文件系统中的—个新位置,让这些进程只能访问该目录 。直到今天,主流的 Linux 上还有这个工具,我们可以打开—个终端,输入 hroot --help 查看一下这个古老的命令:
user@ops-admin : ~user@ops- admin :~$ chroot --help
用法: chroot 选项)新根[命令[参数]...]
或: chroot 选项
以指定的新根为运行指定命令时的根目录。
--user spec=用户:组 指定所用的用户及用户组(可使用“数字”或“名字")
--groups=组列表 指定可供选择的用户组列表,形如组1,组2,组3...
--help 显示此帮助信息并退出
--version 显示版本信息并退出
If no command is given, run ' ${SHELL} -i'(default: ' /bin/sh -i') .
请向 [email protected] 报告 chroot 的错误
GNU coreutils 的主页: <http://www.gnu.org/sofware/coreutils/>
GNU 软件一般性帮助: <http://www.gnu.org/gethelp/>
要获取完整文档,请运行 info coreutils 'chroot invocation'
chroot 这个命令主要是用来把用户的文件系统根目录切换到指定的目录下,实现简单的文件系统隔离 。可以说 chroot 的出现是为了提高安全性,但这种技术并不能防御来自其他方面的攻击,黑客依然可以逃离设定、访问宿主机上的其他文件。
1.2.1 容器技术的发展
在2000 年,由 R&D Associates 公司的 Derrick T. Woolworth为 FreeBSD 引入的 FreeBSD Jails成为了最早的容器技术之一,与 chroot 不同的是,它可以为文件系统、用户、网络等的隔离。增加了进程沙盒功能, 因此,它可以为每个 jail 指定 IP 地址、可以对软件的安装和配置进行定制,等等 。紧接着出现了 Linux VServer, 这是另外一种jail机制,它用于对计算机系统上的资源(如文件系统、 CPU 处理时间、网络地址和内存等 进行安全地划分。每个所划分的分区叫作一个安全上下文, 在其中的虚拟系统叫作虚拟私有服务器 。后来在 2004 和2005 年分别出现了 Soaris Containes和OpenVZ 技术,在可控性和便捷性上更胜一筹,如图:

时间来到 2006 年, Google 公开了 Process Containers 技术,用于对一组进程进行限制 、记账、隔离资源的使用 (CPU、内存 、磁盘 、网络等) 为了避免和 Linux 内核上下文中的"容器”一词混淆而改名为 Control Groups ,2007 年被合并到了 LinuX 6.24 内核中。
在前面的 Cgroups等技术出现以后,容器技术有了更快的发展,如下图简述了容器技术的发展史:
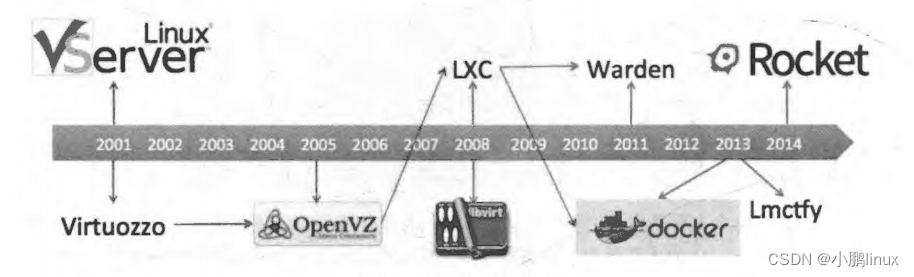
2008 年出现了 LXC (Linux Containers), 它是第—个最完善的 Linux 容器管理器的实现方案,是通过 Cgroups 和Linux 名字空间 namespace 实现的。 LXC 存在千 liblxc 库中,提供了各种编程语言APi实现。与其他容器技术不同的是, LXC 可以工作在普通的Linux 内核上,而不需要增加补丁。
LXC 的出现为后面一系列工具的出现奠定了基础, 2011 Cloud Foundry 发布了 Warden, 不像LXC, Warden 并不紧密耦合到 Linux 上,而是可以工作在任何可以提供隔离环境的操作系统上,它以后台守护进程的方式运行,为容器管理提供了 APl。
在2013 年, Goog 发布了 Lmctfy, 这是—个 Google 容器技术的开源版本,提供 Linux 应用容器。Google 启动这个项目的目的是旨在提供性能可保证的、高资源利用率的 、资源共享的、可超售的、接近零消耗的容器 。Lmctfy 首次发布千 2013 年10 月, 2015 年Google 决定贡献核心的 Lmctfy概念,并抽象成 Libcontainer,现在为 Kubernetes 所用的 cAdvisor工具就是从 Lmctfy 项目的成果开始发展的。Libcontainer 项目最初由 Docker 发起,现在已经被移交给了开放容器基金会。
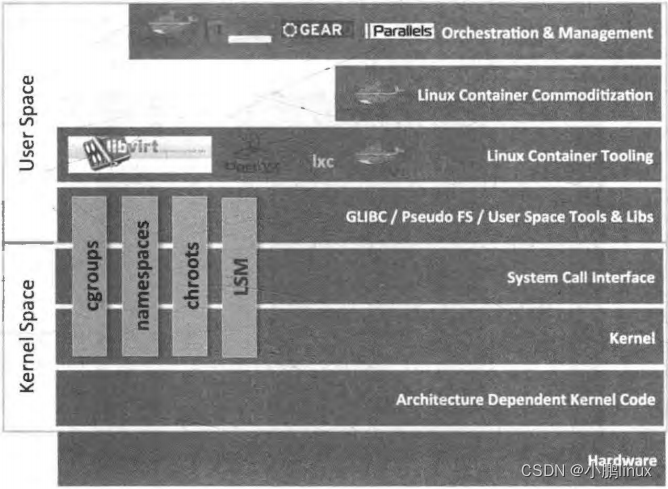
同年, dotCloud 发布了 Docker --到目前为止最流行和广泛使用的容器管理系统,即本博文的主角。在LXC 的基础上, Docker 进一步优化了容器的使用体验,使得容器更容易操作和被管理。Docker 提供了从构建、运行到管理、监控等一系列工具,引入了整个管理容器的生态系统,这包括高效、分层的容器镜像模型、全局和本地的容器注册库、清晰的 REST API、 命令行,等等。这是Docker 与其他容器平台最大的不同,在如下图中可以看到 Docker 跨越了多个层面,整合了一系列零散的工具,从而达到—系列便捷的操作,这是当时 Docker 从众多容器技术中脱颖而出的一个重要原因。
1.2.2 为什么使用容器
与传统软件行业的开发、运维相比,容器虚拟化可以更高效地构建应用,也更容易管理维护.举个简单的例子,常见的 LAMP 开发网站,按照传统的做法自然是各种安装,然后配置 再然后测试,发布,中间麻烦事—大堆,相信不少兄弟们都深有体会了一段时间,用户群体增加,服务器需要搬迁到更合适的机房,往往需要再执行 一次以前的部署步骤,还包括数据的导出导入,极大地花费了运维人员的时间。最可怕的是搬迁后因为一些不可预知的原因导致软件无法正常运行,只能一头扎进代码中找 Bug。
如果使用容器技术,运维只需要一个简单的命令即可部署一整套 LAMP 环境,并且无需复杂的配置与测试,即使搬迁也只是打包传输即可,即使在另—台机器上 ,软件也不会出现“水土不服” 的情况 。这无疑节省了运维人员的大量时间而对于开发来说,一处构建,到处运行大概是梦寐以求的事情,这也是很多跨平台语言的宣传标语之一,但是不管是怎样的跨平台语言在很多细节上都需要不少调整才能运行在另—个平台上。但容器技术则不—样,开发者可以使用熟悉的编程语言开发软件,之后用容器技术打包构建,便可以一键运行在所有支持该容器技术的平台上。容器技术具有更快的交付和部署速度,而且相较于其他虚拟化技术,容器技术更加轻量
1.3 容器技术原理
上面提到,容器的核心技术是 Cgroup Namespace, 在此基础 还有—些其他工具共同构成容器技术。从本质上来说容器是宿主机上的进程,容器技术通过 Namespace 实现资源隔离,通过 Cgroup实现资源控制,通过 rootfs 实现文件系统隔离 再加上容器引擎自身的特性来管理容器的生命周期。简单地说,本博文所说的 Docker 的早期其实就相当于 LXC 的管理引擎, LXC 是Cgroup 的管理工具, Cgroup 是Namespace 的用户空间管理接口 。Namespace 是Linux 内核在 task_struct 中对进程组管理的基础机制。
1.3.1 从Namespace 说起
想要实现资源隔离,第一个想到的就是chroot 命令,通过它可以实现文件系统隔离,这也是最早的容器技术。 但是在分布式的环境下,容器必须要有独立的 IP、 端口、路由等,自然就有了网络隔离。同时,也需要考虑进程通信隔离、权限隔离等,因此—个容器基本上需要做到6项基本隔离,也就是 Linux 内核中提供的 6种Nainespace 隔离,如下表所示:
Names pace
隔离内容
IPC
信号量、 消息队列和共享内存
Network
网络资源
Mount
文件系统挂载点
PID
进程 ID
UTS
主机名和域名
User
用户 ID 和组 ID
当然,完善的容器技术还需要处理很多工作 。
对Namespace 的操作,主要是通过 clone、setns 、unshare 这三个系统调用来完成的。
clone 可以用来创建新的 Namespace ,clone 有一个 flags 参数,这些 flags 参数以 CLONE_NEW*为格式,包括 CLONE_NEWNS、CLONE_NEWIPC、 CLONE_NEWUTS 、CLONE_NEWNET、CLONE_NEWPID 和CLONE_NEWUSER,传入这些参数后,由 创建出来的新进程就位于新的Namespace之中了。
因为 Mount Namespace 是第—个实现的Namespace,当初实现没有考虑到还有其他Namespace出现。因此用了 CLONE_NEWNS 的名字,而不是 CLONE_ EWMNT 之类的名字 其他 CLONE_NEW* 都可以看名字知用途。
那么如何为已有的进程创建新的 Namespace 呢?这就需要使用unshare,使用share调用的进程会被放进新的 Namespace 里面。
而setns是将进程放到已有的 Namespace中,docker exec 命令的实现原理就是setns
事实上,开发Namespace的主要目的之—就是实现轻量级的虚拟化服务。在同—个 Namespace下的进程可 彼此响应,而对外界进程隔离,这样在Namespace下,进程仿佛处于一个独立的系统环境中,以达到容器的目的。
查看当前进程的 Namespace
在了解Namespace API 之前,我们先来了解如何查看进程的Namespace,执行如下:
user@ops- admin : ~$ ls - 1 /proc/ $$/ns
total 0
lrwxrwxrwx 1 user user O Jul 11 17 : 55 cgroup -> cgroup : [ 4026531835)
lrwxrwxrwx 1 user user O Jul 11 17 : 55 ipc - > ipc : [ 4026531839]
lrwxrwxrwx 1 user user O Jul 11 17 : 55 mnt -> mnt [4026531840]
lrwxrwxrwx 1 user user O Jul 11 17 : 55 net -> net : [4026531973)
lrwxrwxrwx 1 user user O Jul 11 17 : 55 pid - > pid : [4026531836]
lrwxrwxrwx 1 user user O Jul 11 17 : 55 user -> user : [4026531837]
lrwxrwxrwx 1 user user O Jul 11 17 : 55 uts -> uts : [4026531838]
这里的$$是指当前进程的 ID 号。可以看到诸如 4026531835这样的数字,这表示当前进程指向的Namespace,当两个进程指向同一串数字时,表示它们处于同—个 Namespace下。
使用 clone 创建新的 Namespace
创建—个新的Namespace的方法是使用 clone() 系统调用,其会创建一个新的进程。为了说明创建的过程,给出 clone() 的原型如下:
int clone (int (*child_ func) (void *), void *child_stack,int flags, void*arg);
本质上,clone是一个通用的 fork() 版本, fork() 的功能由 flags 参数控制。总的来说,约有超20个不同的CLONE_* 标志控制 clone 提供不同的功能,包括父子进程是否共享如虚拟内存、打开的文件描述符、子进程等—些资源 如调用clone时设置了一个 CLONE_NEW*标志, 一个与之对应的新的命名空间将被创建。新的进程属于该命名空间。可以使用多个CLONE_NEW* 标志的组合。
使用 setns 关联一个已经存在的 Namespace
当一个 Namespace没有进程时还保持其打开,这么做是为了后续能添加进程到该Namespace中。
而添加这个功能就是使用 setns 系统调用来完成的,这使得调用的进程能够和 Namespace 关联, docker exec 就需要用到这个方法:
int setns(int fd , int nstype);
1.3.2 认识 Cgroup
Cgroup是 Linux 内核提供的一种可以限制、记录、隔离进程组所使用的物理资源 (如: CPU、内存、IO 等等)的机制。它最初由 Google 的工程师提出,后来被整合进 Linux 内核 ,Cgroup 也是 LXC 为实现虚拟化所使用的资源管理手段,因此可以说没有Cgrou 就没有 LXC。
目前, Cgroup 有一套进程分组框架,不同资源由不同的子系统控制 。一个子系统就是—个资源控制器,比如 CPU 子系统就是控制 CPU 时间分配的一个控制器。子系统必须附加 (attach) 到一个层级上才能起作用 ,一个子系统附加到某个层级以后,这个层级上的所有控制族群都受这个子系统的控制。
Cgroup 各个子系统的作用如下:
• Blkio : 为块设备设定输入/输出限制,比如物理设备 (磁盘、固态硬盘、 USB, 等等)
• Cpu: 提供对 CPU 的Cgroup 任务访问
• Cpuacct: 生成 Cgroup 中任务所使用的 CPU 报告
• Cpuset: 为Cgroup中的任务分配独立的 CPU(在多核系统和内存节点
• Devices: 允许或者拒绝 Cgroup 中的任务访问设备
• Freezer: 挂起或者恢复 Cgroup 中的任务
• Memory: 设定 Cgroup 中任务使用的内存限制,并自动生成由那些任务使用的内存资源报告
• Net_cls: 使用等级识别符 (classid) 标记网络数据包,可允许 Linux 流量控制程序 (tc)别从具体 Cgroup 中生成的数据包
• Net_prio : 设置进程的网络流量优先级
• Huge_tlb : 限制 HugeTLB 的使用
• Perf_ event: 允许 Perf 工具基于 Cgroup 分组做性能监测
这样说理解起来也很吃力 ,下面就通过命令来挂载 Cgroupfs:
root@ops-admin:~# mount -t cgroup -o cpuset cpuset /sys/fs/cgroup/cpuset
这个动作一般情况下已经在linux启动时候做了,查看 Cgroupfs:
root@ops-admin ~ # cpuset ls
cgroup.clone_children cpuset.memory_pressure_enabled
cgroup .procs cpuset.memory spread page
cgr.oup.sane_behavior cpuset.memory_spread_slab
cpuset.cpu_exclusive cpuset.mems
cpuset.cpus cpuset.sched_load balance
cpuset.effective_cpus cpuset.sched_relax_domain_level
cpuset.effective_mems docker
cpuset.mem exclusive notify_on_release
cpuset.mem_hardwall release_agent
cpuset.memory_migrate asks
cpuset.memory_pressure
在主流 linux发行版下,可以通过 /etc/cgconfig.conf 或者cgroup-bin的相关指令来配置 Cgroup:
mount {
cpuset = /sys/fs/cgroup/cpuset;
momory = /sys/fs/cgroup/momory;
}
group cnsworder/test {
perm {
task {
uid = root;
gid = root;
}
admin {
uid = root;
gid = root;
}
}
cpu {
cpu.shares = 1000;
}
}
然后通过命令行把一个进程移动到这个 Cgroup 中:
root@ops-admin:~ # moun -t group - o cpu cpu /sys/fs/cgroup/cpuset
root@ops-admin:~ # cgcreate - g cpu,momory : /cnsworder
root@ops-admin:~ # chown root:root /sys/fs/cgroup/cpuse /cnsworder/test/*
root@ops-admin:~ # chown root:root /sys/fs/cgroup/cpuse /cnsworder/test/task
root@ops-admin:~ # cgrun -g cpu,momory:/cnsworder/test bash
1.3.3 容器的创建
上面两节只是非常简单地了解了Namespace和Cgroup两个概念,实际上像各个Namespace的具体介绍与各个Cgroup子系统的介绍都没有深入讲解,但通过上面两节的学习,相信读者脑海中已经大致有了容器创建过程的雏形。
系统调用clone创建新进程,拥有自己的Namespace。
该进程拥有自己的pid、mount、user、net、ipc、uts namespace。
root@ops-adrnin:~ # pid =clone(fun , stack, flags, clone_arg) ;
如将 pid 写入 cgroup 子系统,就受到 cgroup 子系统的控制。
roo @ops-admin:~# echo$pid >/sys/fs/cgroup/cpu/tasks
root@ops-admin:~# echo$pid >/sys/fs/cgroup/cpuset/tasks
root@ops-admin:~# echo$pid >/sys/fs/cgroup/bikio/tasks
roo @ops-admin ~# echo$pid >/sys/fs/cgroup/memory/tasks
root@ops-admin:~# echo$pid >/sys/fs/cgroup/devices/tasks
roo @ops-admin:~# echo$pid >/sys/fs/cgroup/feezer/tasks
通过 pivot_root 系统调用,使进程进入一个新的 rootfs, 之后通过 exec 系统调用在新的Namespace、cgroup 、rootfs 中执行 "bin/bash"
fun() {
pivot_root("path_of_rootfs/", path);
exec("/bin/bash");
}
凡是通过上面操作成功的,都是在一个容器中运行了 "bin/bash"。
👑👑👑结束语👑👑👑

版权归原作者 小鹏linux 所有, 如有侵权,请联系我们删除。