
一:索引
索引是一种特殊的文件,包含着对数据表里所有记录的引用指针。可以对表中的一列或多列创建索引,并指定索引的类型,各类索引有各自的数据结构实现。
1.1索引的意义
索引的意义:加快查找速度,但需要付出额外的空间代价,保存索引可能会拖慢增删改的速度,但是总体来说还是利大于弊的,因为在平时中,我们查询的频率会比增删改的效率高
索引是数据库中的一种数据结构,用于加速查询操作。它类似于书籍的目录,可以快速找到需要的数据行,而无需扫描整个表。索引可以根据一个或多个列创建,通过将这些列的值映射到对应的数据行位置,实现快速的数据检索。
1.2 索引的作用
索引的作用主要体现在以下几个方面:
- 提高查询效率:通过使用索引,数据库可以快速定位到匹配条件的数据行,从而加快查询速度。特别是在大型表中,索引的使用可以大幅提升查询效率。
- 加速排序和分组:当使用ORDER BY或GROUP BY语句进行排序或分组时,索引可以提供排序或分组的依据,加快排序和分组操作的速度。
- 实现唯一约束:索引可以强制保持列的唯一性,防止数据冗余或重复。
- 加速连接操作:当进行表连接操作时,通过创建适当的索引,可以减少连接操作所需的时间。
1.3 索引的使用场景
索引的使用场景与以下情况相关:
- 经常被查询的列:如果某个列经常被用于查询条件,那么为该列创建索引可以加速查询。
- 大型表:在大型表中,数据量庞大,扫描整个表会消耗大量时间,使用索引可以显著减少查询时间。
- 经常需要排序和分组的列:对于需要经常排序或分组的列,通过创建索引,可以提高排序和分组操作的效率。
- 外键关联的列:对于与其他表有外键关联的列,为其创建索引可以提高连接操作的速度。
1.4查看创建和删除索引
- 查看索引
showindexfrom 表名;
案例:查看学生表已有的索引
showindexfrom student;
- 创建索引
对于非主键、非唯一约束、非外键的字段,可以创建普通索引
createindex 索引名 on 表名(字段名);
案例:创建班级表中,name字段的索引
createindex idx_classes_name on classes(name);
- 删除索引
dropindex 索引名 on 表名;
案例:删除班级表中name字段的索引
dropindex idx_classes_name on classes;
1.5索引的案例
以下是一个用于演示索引使用的示例数据:
表结构如下:
CREATETABLE users (
id INTPRIMARYKEY,
name VARCHAR(50),
email VARCHAR(100),
age INT,
city VARCHAR(50));
现在,我们随机生成一些数据并插入表中:
INSERTINTO users (id, name, email, age, city)VALUES(1,'Alice','[email protected]',25,'New York'),(2,'Bob','[email protected]',30,'London'),(3,'Charlie','[email protected]',35,'Paris'),(4,'David','[email protected]',27,'Los Angeles'),(5,'Emily','[email protected]',32,'Tokyo'),(6,'Frank','[email protected]',29,'Berlin'),(7,'Grace','[email protected]',33,'Sydney'),(8,'Henry','[email protected]',28,'Toronto'),(9,'Isabella','[email protected]',31,'Moscow'),(10,'Jack','[email protected]',26,'Beijing');
接下来,我们将创建索引来优化查询操作。
- 创建一个联合索引,包含name和age字段:
CREATEINDEX idx_name_age ON users (name, age);
这个联合索引将使得按照name和age进行查询更加高效。
- 创建一个单列索引,包含city字段:
CREATEINDEX idx_city ON users (city);
这个单列索引将使得按照city进行查询更加高效。
现在,我们可以进行一些查询操作来演示索引的使用。
- 查找名字为"Alice"并且年龄为25的用户:
SELECT*FROM users WHERE name ='Alice'AND age =25;
这个查询将使用名为
idx_name_age
的联合索引来加速搜索。
- 查找年龄大于30的用户,并按照城市进行排序:
SELECT*FROM users WHERE age >30ORDERBY city;
这个查询将使用名为
idx_age
的单列索引来加速搜索,并使用索引排序来提高性能。
注意:我们在创建主键约束(PRIMARY KEY)、唯一约束(UNIQUE)、外键约束(FOREIGN KEY)时,会自动创建
对应列的索引。
二:事务
2.1事务的特性
在MySQL中,事务是一组数据库操作的单元,它们被视为一个不可分割的工作单元。事务具有以下四个特性,通常被称为ACID属性:
- 原子性(Atomicity):事务是原子操作的集合,表示事务中的所有操作要么全部成功执行,要么全部回滚。如果发生错误,所有已执行的操作都将被撤消,数据库将回到事务执行前的状态。
- 一致性(Consistency):事务开始前和结束后,数据库的完整性约束没有被破坏。换句话说,事务的执行不会破坏数据库的一致性。
- 隔离性(Isolation):并发执行的事务之间应该相互隔离,每个事务都感觉不到其他事务的存在。隔离性确保事务之间的操作互不干扰。
- 持久性(Durability):事务成功提交后,对数据库的修改将永久保存,即使系统发生故障也不会丢失。
事务的作用是保证数据库在并发操作时的一致性和完整性。当多个用户同时对数据库进行读写操作时,事务可以确保数据的正确性,并防止出现数据丢失或不一致的情况。
在MySQL中,可以使用以下语句来定义和使用事务:
- 开启事务:
START TRANSACTION; - 提交事务:
COMMIT;(全部成功) - 回滚事务:
ROLLBACK;(全部失败)
在事务中,可以执行多个SQL语句,包括插入、更新、删除以及查询等操作。可以使用以下语句来控制事务的行为:
- 设置保存点(Savepoint):
SAVEPOINT savepoint_name;,可以在需要的地方设置保存点,并在需要时回滚到保存点。 - 设置自动提交模式:
SET autocommit = 0;,禁用自动提交模式,使得在一个事务中的操作可以一次性提交。 - 设置事务隔离级别:
SET TRANSACTION ISOLATION LEVEL level;,可以设置事务的隔离级别,包括读未提交(Read Uncommitted)、读提交(Read Committed)、可重复读(Repeatable Read)和串行化(Serializable)。
2.2事务的案例
starttransaction;-- 阿里巴巴账户减少2000update accout set money=money-2000where name ='阿里巴巴';-- 四十大盗账户增加2000update accout set money=money+2000where name ='四十大盗';commit;
start transaction表示开启事务,commit表示提交事务,到这一步就相当于事务执行完了
事务的本质就是把多个sql语句打包成一个整体,这个整体要么全部执行成功,要都不成功,而不会出现一半成功一半失败的情况,如果在执行过程中,执行一半出错了,出错之后,会自动把数据还原成未执行前的状态,这个回复数据的操作叫做回滚,所以我们需要额外的部分来记录事务中的操作步骤(数据库有个专门用来记录事务的日志),正因如此,使用事务,执行sql的开销会更大,效率也就更低了
三:java的JDBC编程
JDBC,即Java Database Connectivity,java数据库连接。是一种用于执行SQL语句的Java API,它是Java中的数据库连接规范。这个API由 java.sql.,javax.sql. 包中的一些类和接口组成,它为Java开发人员操作数据库提供了一个标准的API,可以为多种关系数据库提供统一访问。
3.1数据库编程的必备条件
- 编程语言,如Java,C、C++、Python等
- 数据库,如Oracle,MySQL,SQL Server等
- 数据库驱动包:不同的数据库,对应不同的编程语言提供了不同的数据库驱动包,如:MySQL提供了Java的驱动包mysql-connector-java,需要基于Java操作MySQL即需要该驱动包。同样的,要基于Java操作Oracle数据库则需要Oracle的数据库驱动包ojdbc
3.2 JDBC的使用
3.2.1数据库驱动包的添加
首先准备数据库驱动包,并添加到项目的依赖中:在项目中创建文件夹lib,并将依赖包mysql-connector-java-5.1.47.jar复制到lib中。再配置该jar包到本项目的依赖中:右键点击项目Open Module Settings,在Modules中,点击项目,配置Dependencies,点击+,JARS or Directories,将该lib文件夹配置进依赖中,表示该文件夹下的jar包都引入作为依赖。
示图如下:
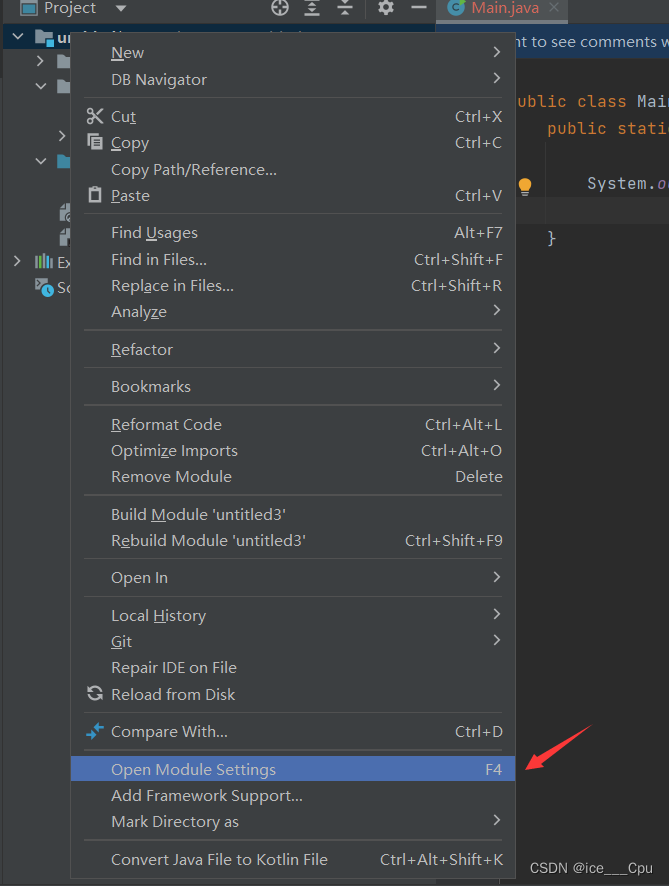
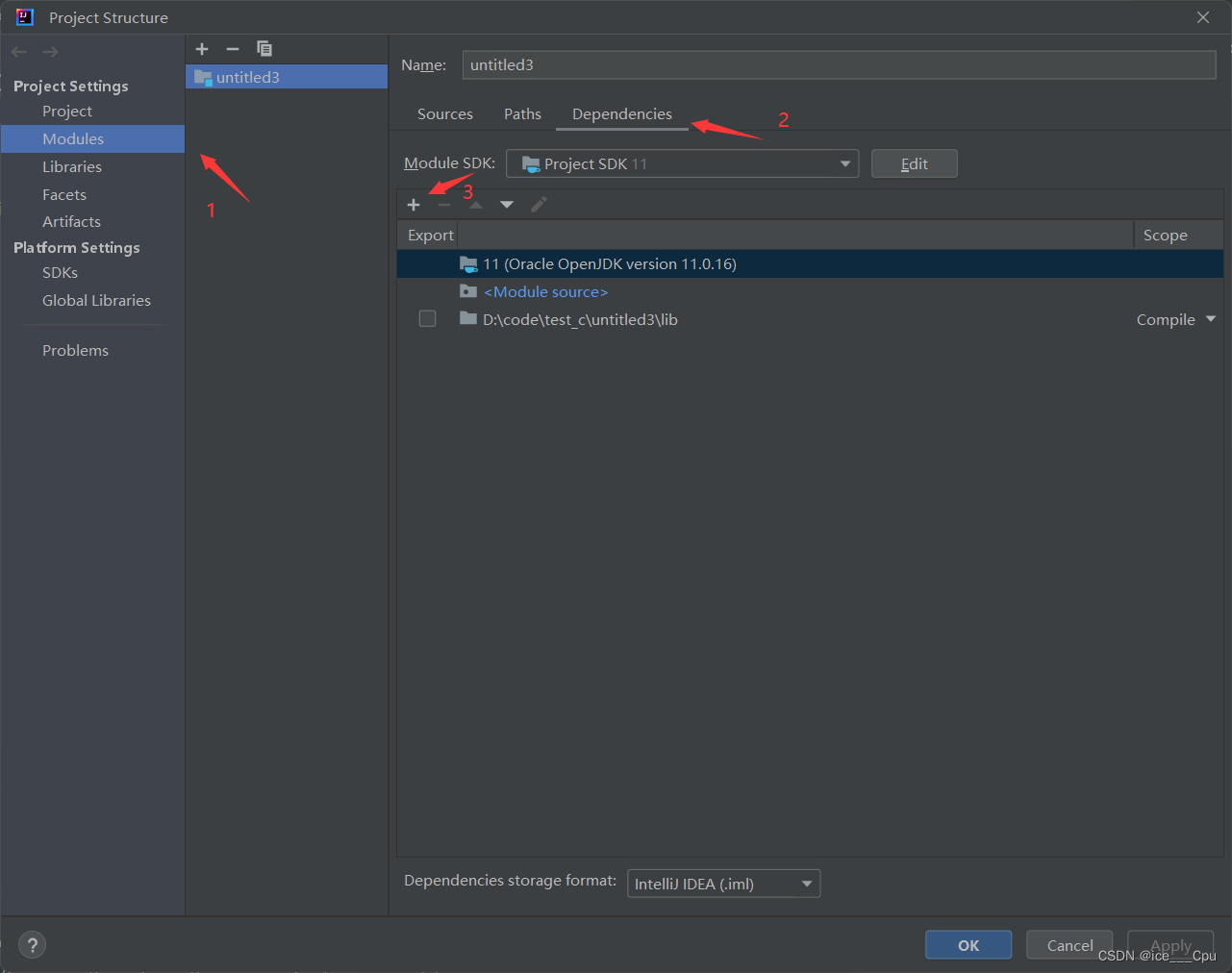
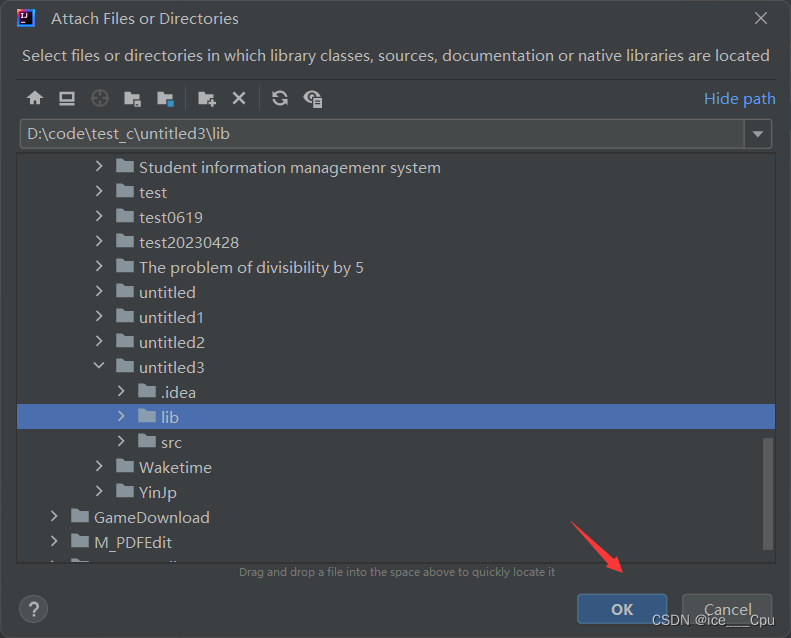
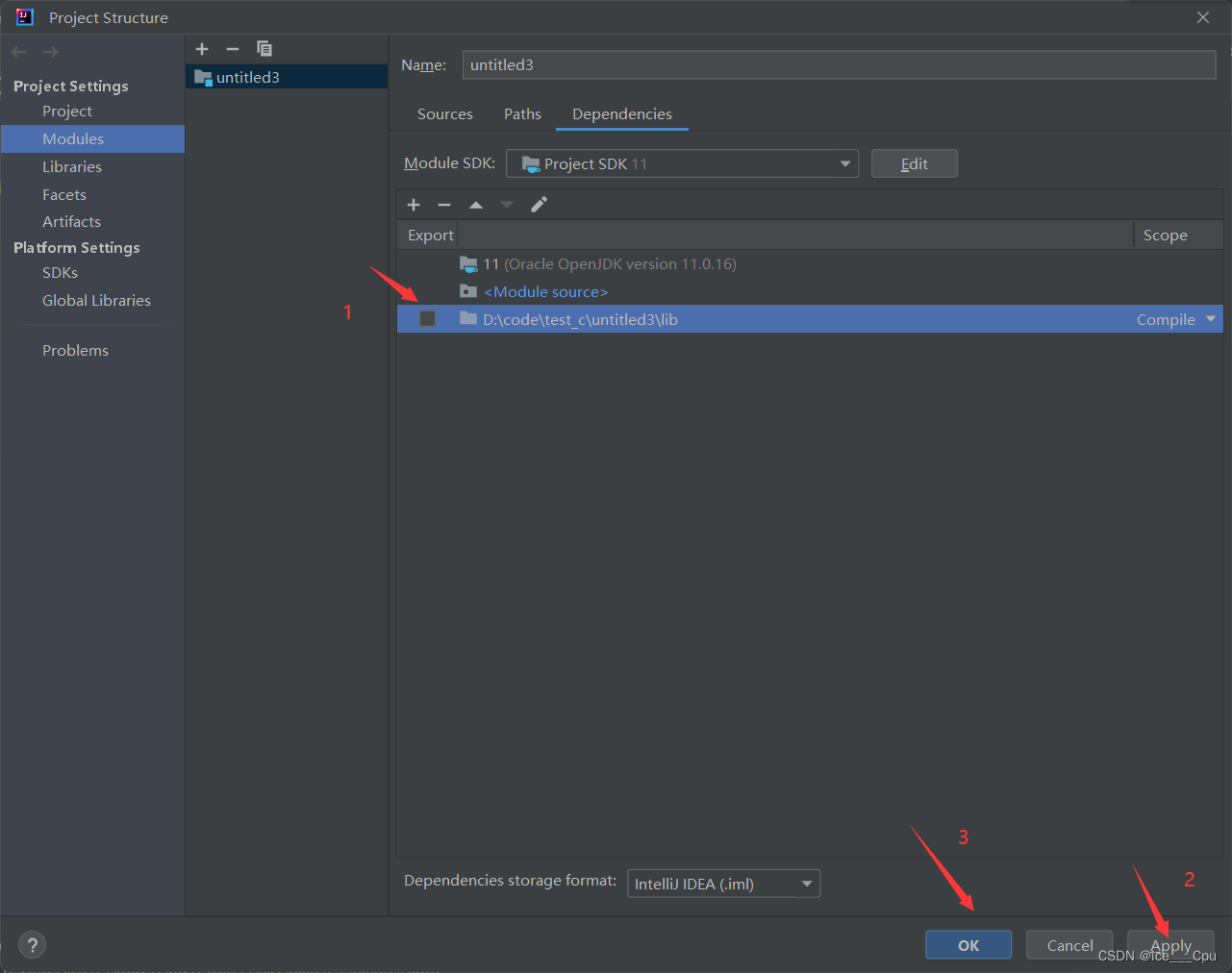
3.2.2 建立数据库连接
// 加载JDBC驱动程序。Class.forName("com.mysql.jdbc.Driver");// 创建数据库连接Connection connection =DriverManager.getConnection("jdbc:mysql://localhost:3306/test? user=root&password=root&useUnicode=true&characterEncoding=UTF-8");
在Java中,
Class.forName("com.mysql.jdbc.Driver")
是用于加载并注册 MySQL JDBC 驱动程序的代码。
具体来说,这段代码做了以下几个操作:
- 通过调用
Class.forName()方法,加载位于"com.mysql.jdbc.Driver"包中的类。 - 加载类的过程中,MySQL JDBC 驱动程序会自动注册到 DriverManager 中。
- DriverManager 将负责管理可用的数据库驱动程序。
- 注册驱动程序后,才可以使用 JDBC API 连接和操作 MySQL 数据库。
而第二行代码是使用JDBC连接到MySQL数据库的示例。
DriverManager是Java提供的用于管理数据库驱动程序的类。getConnection()是DriverManager类的方法,用于建立与数据库的连接。"jdbc:mysql://localhost:3306/test?user=root&password=root&useUnicode=true&characterEncoding=UTF-8"是连接URL的格式和参数。 -jdbc:mysql://:表示使用MySQL数据库驱动程序。-localhost:3306:数据库服务器的主机名(在本例中为本地主机)和端口号(本地主机默认为3306)。-test:数据库的名称。-user=root&password=root:登录数据库的用户名和密码。-useUnicode=true&characterEncoding=UTF-8:表示使用Unicode编码和UTF-8字符集进行字符处理。
综上所述,这行代码的作用是建立一个与MySQL数据库的连接,并使用给定的用户名、密码和其他参数进行身份验证和配置。所以要确保替换正确的主机名、端口号、数据库名称、用户名和密码以适应实际情况。
3.3.3创建操作命令
Statement statement = connection.createStatement();
这行代码的意思是创建一个
Statement
对象,用于执行SQL语句。
Statement
是Java JDBC中的一个接口,用于向数据库发送SQL语句并获取结果。通过
connection.createStatement()
方法可以在
connection
对象上创建一个
Statement
对象。
具体使用
Statement
对象的步骤如下:
- 首先,通过
connection对象创建一个Statement对象。这个对象负责与数据库进行通信。 - 然后,使用
Statement对象的executeQuery()方法来执行SQL查询语句,或使用executeUpdate()方法执行SQL更新语句。 - 如果是执行查询语句,可以使用
ResultSet对象来获取查询结果。
需要注意的是,使用
Statement
对象执行SQL语句存在SQL注入的安全风险,建议使用
PreparedStatement
来替代
Statement
,可以有效避免SQL注入问题。
3.3.4 执行sql语句
ResultSet resultSet= statement.executeQuery("select id, sn, name, qq_mail, classes_id from student");
这一行代码是在执行一条SQL查询语句并将其结果存储在一个
ResultSet
对象中。
让我们一步一步来解释这段代码的含义:
ResultSet resultSet: 这是一个变量声明,用于存储查询结果的对象。它是一个指向结果集的游标,通过它可以依次访问结果集中的每一行数据。statement.executeQuery("select id, sn, name, qq_mail, classes_id from student"): 这是一个Statement对象的方法调用,通过它执行了一条SQL查询语句。具体来说,这个查询语句从名为"student"的表中选择了"id"、“sn”、“name”、“qq_mail”、"classes_id"这五个字段,并将查询结果存储在ResultSet对象中。
这段代码的作用是执行一条查询语句来获取表中所有学生的"id"、“sn”、“name”、"qq_mail"和"classes_id"字段的数据,并将查询结果存储在
ResultSet
对象中供后续的处理和操作使用。
需要注意的是,这段代码仅仅是查询语句的执行,获取到的查询结果还需要进一步操作和处理才能得到最终的结果。
3.3.5处理结果集
while(resultSet.next()){int id = resultSet.getInt("id");String sn = resultSet.getString("sn");String name = resultSet.getString("name");int classesId = resultSet.getInt("classes_id");System.out.println(String.format("Student: id=%d, sn=%s, name=%s,
classesId=%s", id, sn, name, classesId));}
这段代码是一个循环,用于迭代结果集中的每一行数据。它使用
resultSet.next()
方法来移动结果集的光标到下一行数据,并返回一个布尔值,表示是否还有更多的数据可供迭代。
在每次迭代的循环体内,通过使用
resultSet.getInt()
和
resultSet.getString()
等方法,我们可以从结果集中获取指定列的数据。这些方法接受列名称或列索引作为参数,并返回相应的数据类型的值。
在这段代码中,我们通过
resultSet.getInt("id")
获取了"id"列的整数值,通过
resultSet.getString("sn")
获取了"sn"列的字符串值,通过
resultSet.getString("name")
获取了"name"列的字符串值,通过
resultSet.getInt("classes_id")
获取了"classes_id"列的整数值。
最后,使用
System.out.println()
方法将每一行数据输出到控制台,使用
String.format()
方法来格式化输出的字符串。
总结来说,这段代码的作用是循环遍历结果集中的每一行数据,然后提取每行的不同列的值,并将其打印输出到控制台。
3.3.6释放资源(关闭结果集,命令,连接)
//关闭结果集if(resultSet !=null){try{
resultSet.close();}catch(SQLException e){
e.printStackTrace();}}//关闭命令if(statement !=null){try{
statement.close();}catch(SQLException e){
e.printStackTrace();}}//关闭连接命令if(connection !=null){try{
connection.close();}catch(SQLException e){
e.printStackTrace();}}
这段代码的作用是关闭数据库连接中的相关资源,以释放系统资源并确保数据完整性。
首先,它检查
resultSet
对象是否为
null
,如果不是
null
则尝试关闭
resultSet
。
然后,它检查
statement
对象是否为
null
,如果不是
null
则尝试关闭
statement
。
最后,它检查
connection
对象是否为
null
,如果不是
null
则尝试关闭
connection
。
关闭这些资源是很重要的,因为它们与数据库有关,如果不及时关闭可能会导致资源泄漏和性能问题。在关闭资源之前,通常会将它们用于执行数据库操作或查询。关闭资源可以释放它们占用的内存,并允许其他操作使用这些资源。
在这段代码中,如果关闭过程中发生了
SQLException
异常,它会被捕获并使用
e.printStackTrace()
打印出异常的堆栈跟踪信息,以便进行调试和错误处理。异常处理是为了防止在资源关闭过程中出现问题导致程序中断。
3.3.7JDBC使用步骤总结
- 创建数据库连接Connection
- 创建操作命令Statement
- 使用操作命令来执行SQL
- 处理结果集ResultSet
- 释放资源
四:JDBC常用的接口和类
4.1 数据库连接Connection
Connection接口实现类由数据库提供,获取Connection对象通常有两种方式:
- 一种是通过DriverManager(驱动管理类)的静态方法获取:
// 加载JDBC驱动程序Class.forName("com.mysql.jdbc.Driver");// 创建数据库连接Connection connection =DriverManager.getConnection(url);
- 一种是通过DataSource(数据源)对象获取。实际应用中会使用DataSource对象。
DataSource ds =newMysqlDataSource();((MysqlDataSource) ds).setUrl("jdbc:mysql://localhost:3306/test");((MysqlDataSource) ds).setUser("root");((MysqlDataSource) ds).setPassword("root");Connection connection = ds.getConnection();
以上两种方式的区别是:
- DriverManager类来获取的Connection连接,是无法重复利用的,每次使用完以后释放资源时,通过connection.close()都是关闭物理连接。
- DataSource提供连接池的支持。连接池在初始化时将创建一定数量的数据库连接,这些连接是可以复用的,每次使用完数据库连接,释放资源调用connection.close()都是将Conncetion连接对象回收。
4.2Statement对象
Statement对象主要是将SQL语句发送到数据库中。JDBC API中主要提供了三种Statement对象

实际开发中最常用的是PreparedStatement对象,以下对其的总结: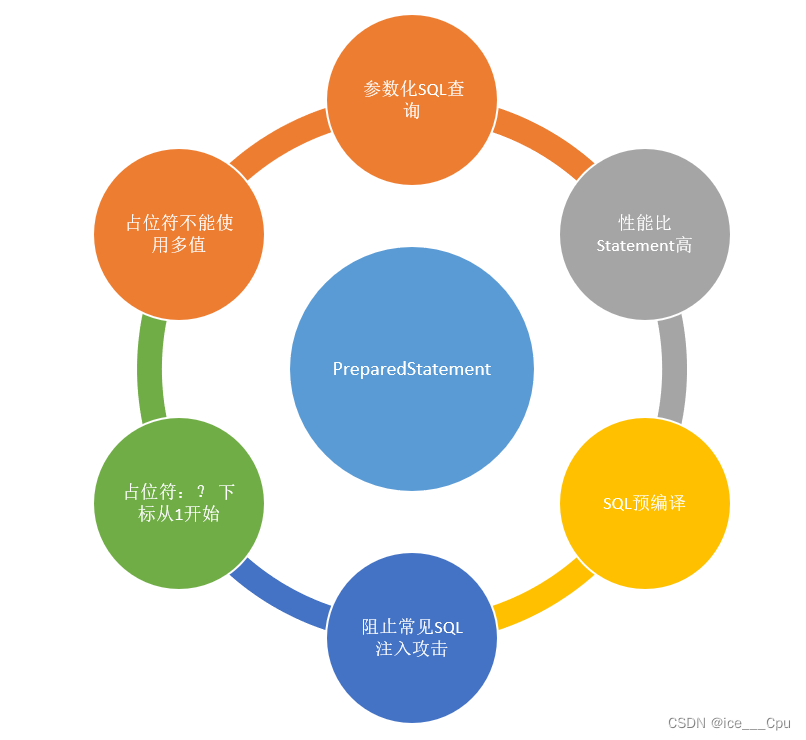
两种常用执行SQL的方法:
- executeQuery() 方法执行后返回单个结果集的,通常用于select语句
- executeUpdate()方法返回值是一个整数,指示受影响的行数,通常用于update、insert、delete语句
4.3ResultSet对象
ResultSet对象它被称为结果集,它代表符合SQL语句条件的所有行,并且它通过一套getXXX方法提供了对这些行中数据的访问。
ResultSet里的数据一行一行排列,每行有多个字段,并且有一个记录指针,指针所指的数据行叫做当前数据行,我们只能来操作当前的数据行。我们如果想要取得某一条记录,就要使用ResultSet的next()方法 ,如果我们想要得到ResultSet里的所有记录,就应该使用while循环。
版权归原作者 ice___Cpu 所有, 如有侵权,请联系我们删除。