
Python的web自动化学习(一)Selenium库的工作原理
首发2023-07-31 11:01·云中随心而记
后续会根据持续学习来更新,大家一起学习
引言:
Selenium是一个流行的自动化测试工具,用于模拟和控制浏览器行为,常用于Web应用程序的功能测试和验收测试。Selenium支持多种编程语言,包括Python、Java、C#等,并提供了一组API,用于操作浏览器的各种行为。
Selenium库的工作原理主要包括以下几个关键组件: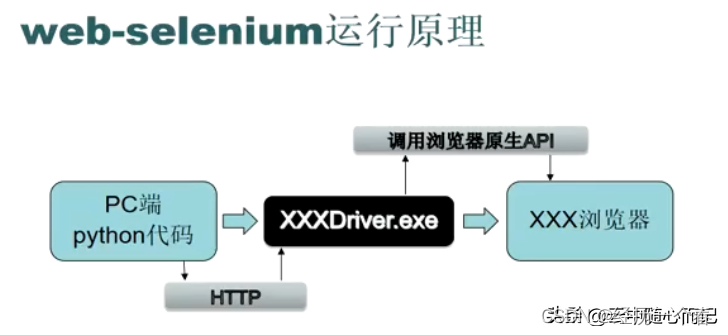
我们以谷歌浏览器为例来一起进行学习:
WebDriver:
WebDriver是Selenium的核心组件,它提供了与各种浏览器的交互能力。通过WebDriver,Selenium可以自动化启动浏览器、打开URL、填写表单、点击按钮、获取元素属性等等操作。
浏览器驱动:
Selenium需要与浏览器进行交互,所以需要安装相应的浏览器驱动。不同的浏览器需要对应不同的浏览器驱动,比如Chrome需要ChromeDriver,Firefox需要GeckoDriver。驱动程序将接收来自Selenium的指令,并在浏览器中执行相应的操作
下面介绍两个常用的驱动下载地址:
Chrome浏览器驱动下载地址:
http://chromedriver.storage.googleapis.com/index.htm
Firefox(火狐)浏览器驱动:
https://github.com/mozilla/geckodriver/releases/
定位元素:
Selenium可以通过各种方式来定位Web页面上的元素,比如ID、名称、类名、链接文本等等。通过定位元素,Selenium可以准确地找到需要操作的页面元素。
前面文章有介绍过元素定位 可参考:
https://www.toutiao.com/article/7260753838771290661/
执行操作:
一旦定位到Web元素,Selenium可以执行多种操作,如点击、输入文本、获取元素属性等。这些操作可以模拟用户在浏览器中的行为。以下是实例说明
点击操作:
Chrome浏览器:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://example.com")
button = driver.find_element_by_xpath("//button[@id='myButton']")
button.click()
Firefox浏览器:
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("https://example.com")
button = driver.find_element_by_xpath("//button[@id='myButton']")
button.click()
输入文本操作:
Chrome浏览器:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://example.com")
input_box = driver.find_element_by_xpath("//input[@id='myInput']")
input_box.send_keys("Hello World")
Firefox浏览器:
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("https://example.com")
input_box = driver.find_element_by_xpath("//input[@id='myInput']")
input_box.send_keys("Hello World")
获取元素属性:
Chrome浏览器:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://example.com")
element = driver.find_element_by_xpath("//div[@class='myDiv']")
text = element.text
Firefox浏览器:
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("https://example.com")
element = driver.find_element_by_xpath("//div[@class='myDiv']")
text = element.text
断言和验证:在自动化测试中,验证页面上的特定行为和结果非常重要。Selenium提供了丰富的断言和验证方法,以确保应用程序的正确性。
页面标题断言:
Chrome浏览器:
from selenium import webdriver
importassert
driver = webdriver.Chrome()
driver.get("https://example.com")
title = driver.title
assert"Example"in title
Firefox浏览器:
from selenium import webdriver
importassert
driver = webdriver.Firefox()
driver.get("https://example.com")
title = driver.title
assert"Example"in title
页面文本断言:
Chrome浏览器:
from selenium import webdriver
importassert
driver = webdriver.Chrome()
driver.get("https://example.com")
element = driver.find_element_by_xpath("//div[@class='myDiv']")
text = element.text
assert"Hello world"in text
Firefox浏览器:
from selenium import webdriver
importassert
driver = webdriver.Firefox()
driver.get("https://example.com")
element = driver.find_element_by_xpath("//div[@class='myDiv']")
text = element.text
assert"Hello world"in text
这些示例演示了在不同的浏览器中执行断言操作。无论使用哪种浏览器驱动,您可以使用相同的断言方法来验证页面标题、文本等内容。只需根据所使用的浏览器类型选择适当的驱动程序,然后使用相同的断言语句来进行验证。
版权归原作者 经历一个春 所有, 如有侵权,请联系我们删除。