
一、将HDFS副本数设置为3
1、什么是HDFS副本数?
HDFS 数据副本概念:HDFS数据副本存放策略,副本的存放是HDFS可靠性和高性能的关键。优化的副本存放策略是HDFS区分于其他大部分分布式文件系统的重要特性。这种特性需要做大量的调优,并需要经验的积累。
2.将副本数设置为3
将HDFS副本数设置为3,我们需要修改虚拟机主机上的Hadoop配置文件。
首先先把虚拟机路径切换到Hadoop文件的配置路径,使用命令:cd $HADOOP_HOME/etc/hadoop,修改hdfs-site.xml文件,把副本数量设置为3。
具体如下图:
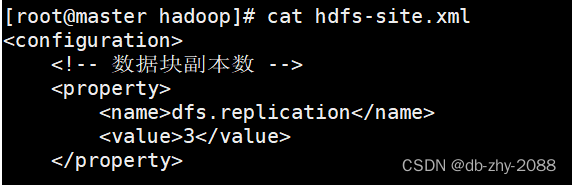
这里我已经修改过来,使用的是查看命令,修改命令为:**vi hdfs-site.xml,**接着输入i进入编式。到这里我们的副本数就设置完成了。
二、基于MapReduce框架开发wordcount程序
1、什么是MapReduce框架?
MapReduce是一种分布式计算模型,用于大规模数据集****(如TB级)的并行运算。核心思想是分而治之,即先分后总。主要用来处理离线数据。
基于MapReduce框架开发的程序称之为MapReduce程序。MapReduce程序由两个阶段组成: map和r****educe,用户(即程序员)只需实现map()和reduce()两个函数,即可开发出分布式计算程序。
2、 启动idea,新建一个maven项目
3、将HDFS相关的jar包引入到项目中
将HDFS相关的jar包引入到项目中,目的是调用HDFS提供的相关的类、方法。

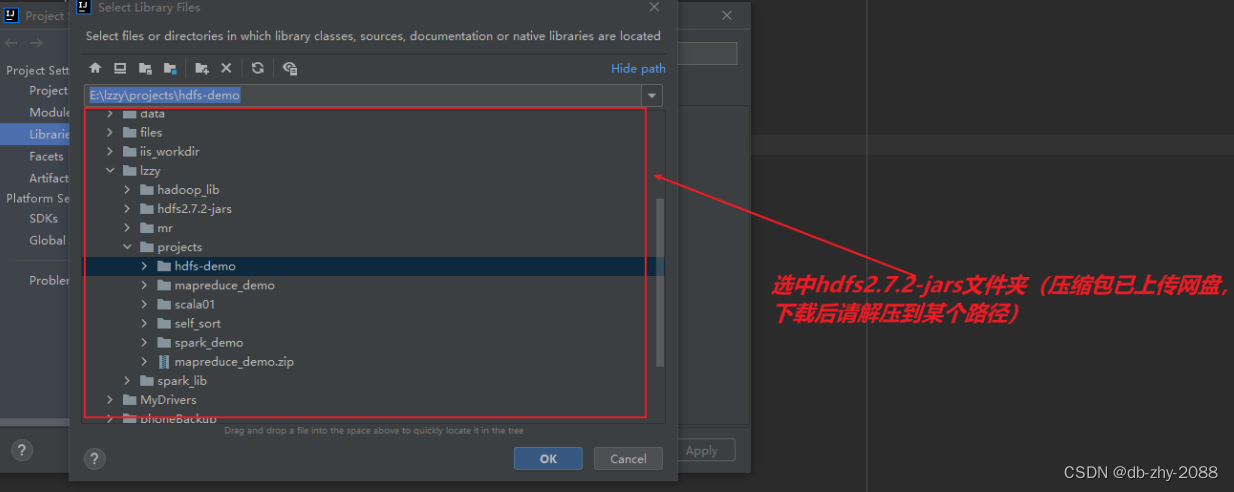
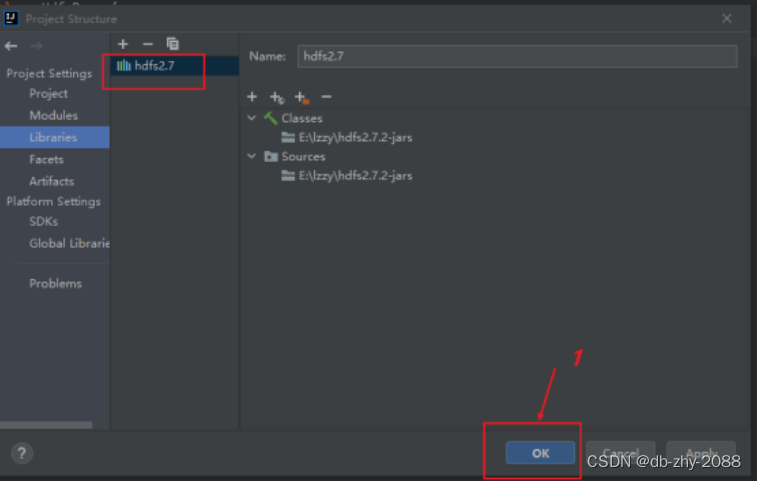

前面操作完后在这里会到这个目录,说明hdfs相关包已经引进来的,后续写代码引用相关类时,编译就不会报错。
4、代码开发
在这里,我以统计单词数量为例。结合map阶段、shuffle阶段、reduce阶段来看代码。业务逻辑都在map方法和reduce方法里。代码写完后,要搭建本地调试环境(即本地部署Hadoop)才能运行
package com.ligl;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class MrWordCount {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf,"word count");
job.setJarByClass(MrWordCount.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
//设置Map的输出的key的类型
job.setMapOutputKeyClass(Text.class);
//设置Map的输出的value的类型
job.setMapOutputValueClass(IntWritable.class);
//输出Reduce的输出的key的类型
job.setOutputKeyClass(Text.class);
//输出Reduce的输出的value的类型
job.setOutputValueClass(IntWritable.class);
job.setNumReduceTasks(2);
//设置要处理的文件的路径
FileInputFormat.addInputPath(job,new Path(args[0]));
//设置输出路径
FileOutputFormat.setOutputPath(job,new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
/**
* Mapper<Object, Text , Text, IntWritable>
* 第一类型参数Object:Mapper输入的key的数据类型
* 第二类型参数Text:Mapper输入的value的数据类型
* 第三类型参数Text:Mapper输入的key的数据类型
* 第四类型参数IntWritable:Mapper输入的value的数据类型
*/
public static class MyMapper extends Mapper<Object, Text , Text, IntWritable> {
@Override
protected void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
//value参数就是要处理的文件的一行行字符串
String[] words = value.toString().split("");
//将数据(单词->1)输出到下一阶段 shuffle
for(String w : words){
context.write(new Text(w),new IntWritable(1));
}
}
}
public static class MyReducer extends Reducer<Text ,IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum =0;
for (IntWritable v : values){
sum += v.get();
}
context.write(key,new IntWritable(sum));
}
}
}
在这里要注意传参,不然结果会报错,选择Edit Configurations...,传入参数hello.txt zu


运行结果如下,可以看到- Job job_local147052454_0001 completed successfully表明已经运行成功,同时也生成了zu文件夹:

5、本地环境搭建
解压hadoop-2.7.1-win(windows配置环境变量HADOOP_HOME,PATH添加:%HADOOP_HOME%\bin、%HADOOP_HOME%\lib,然后重启idea

三、打包项目
首先File -> project structure ...打开如下对话框
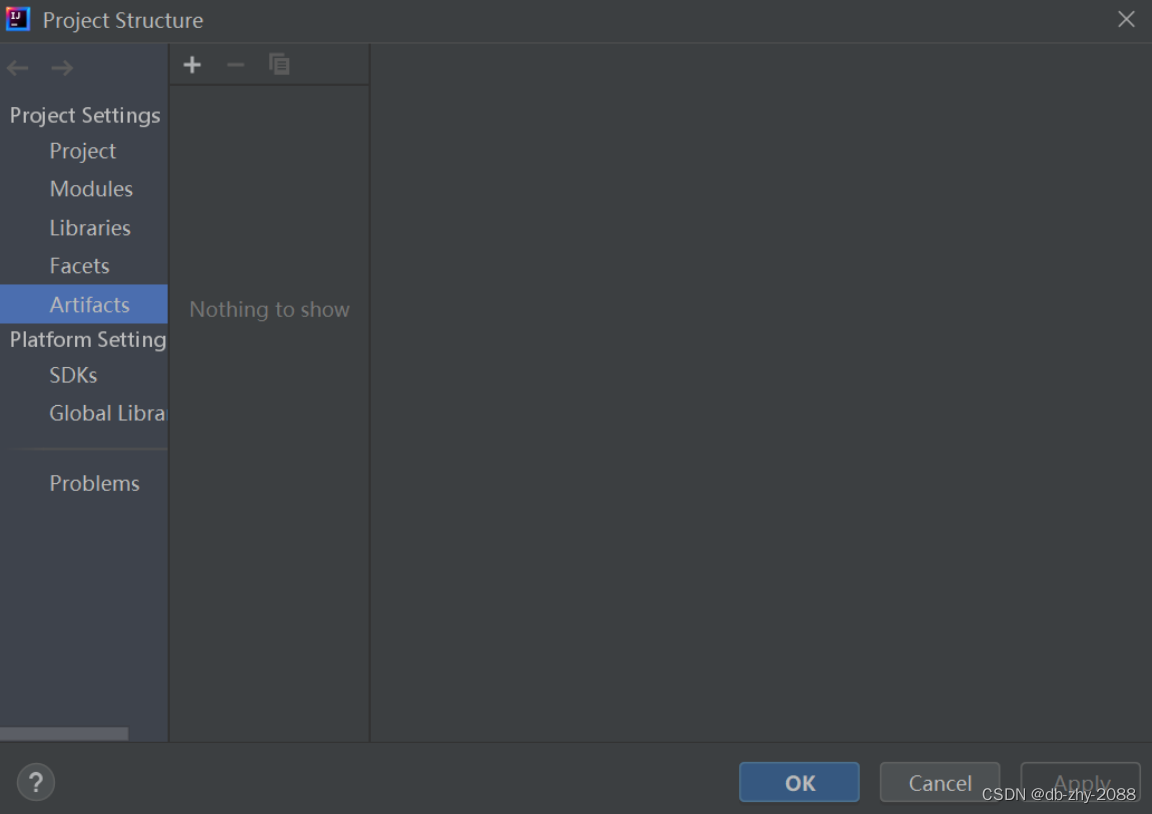
创建artifacts,如下图所示
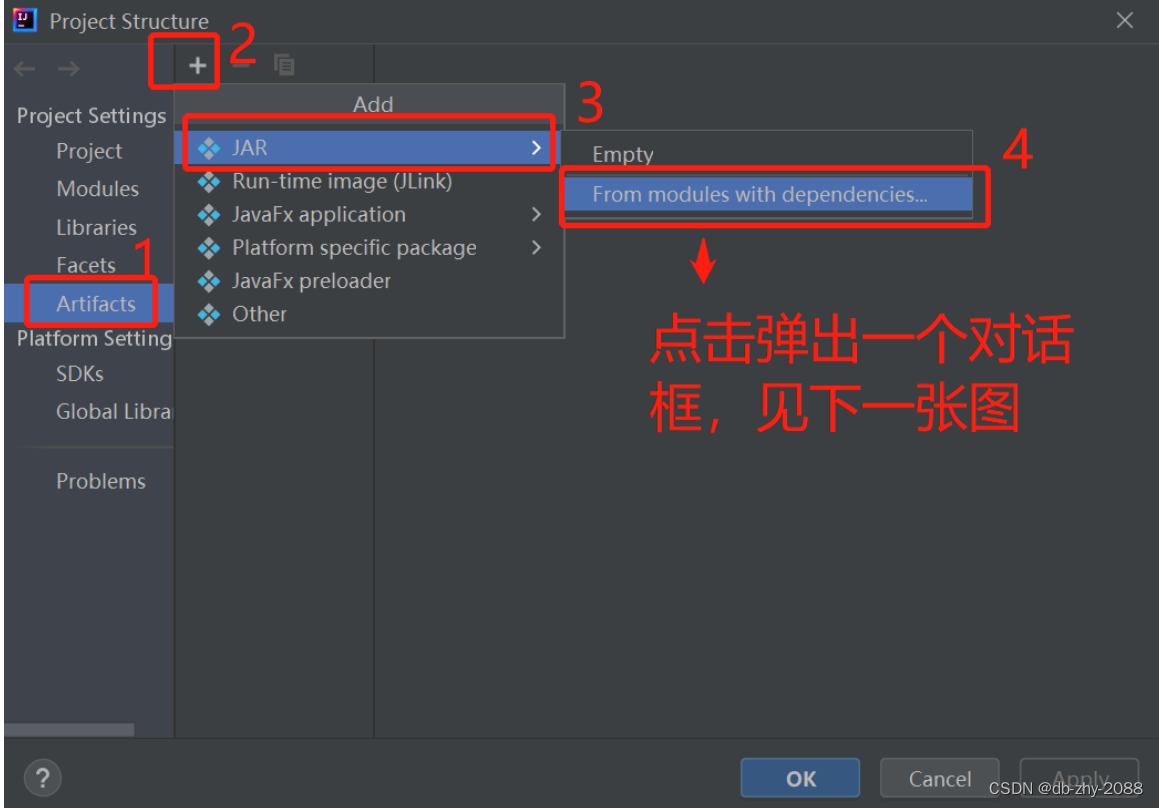
选择需要的main类以及manifest存放路径然后点击OK。
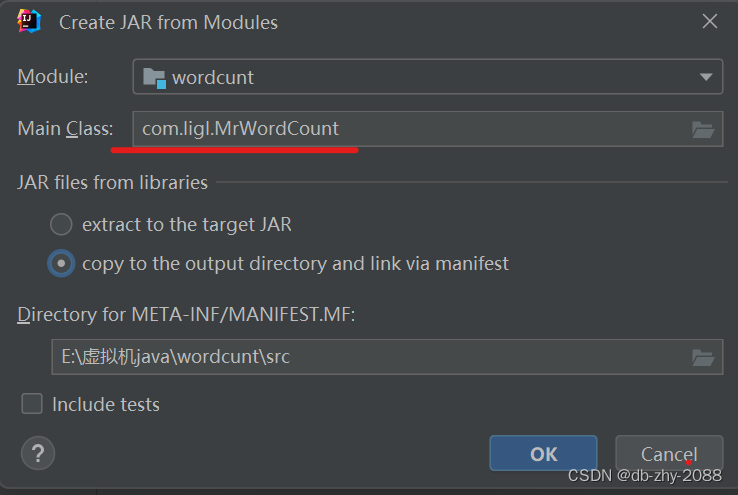
新建一个lib文件夹


把hdfs依赖添加到lib文件夹,点击OK。
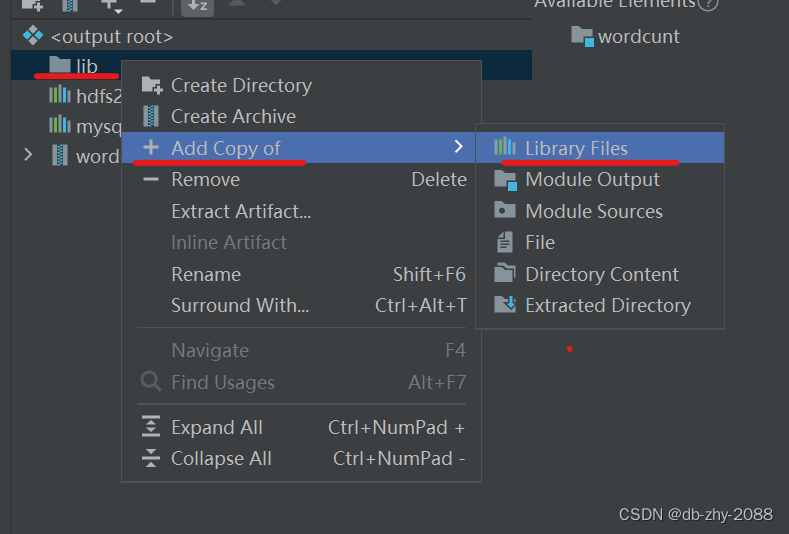
 接下来减去外层的hdfs依赖
接下来减去外层的hdfs依赖
在每一行的前面上都加上lib/,点击OK。
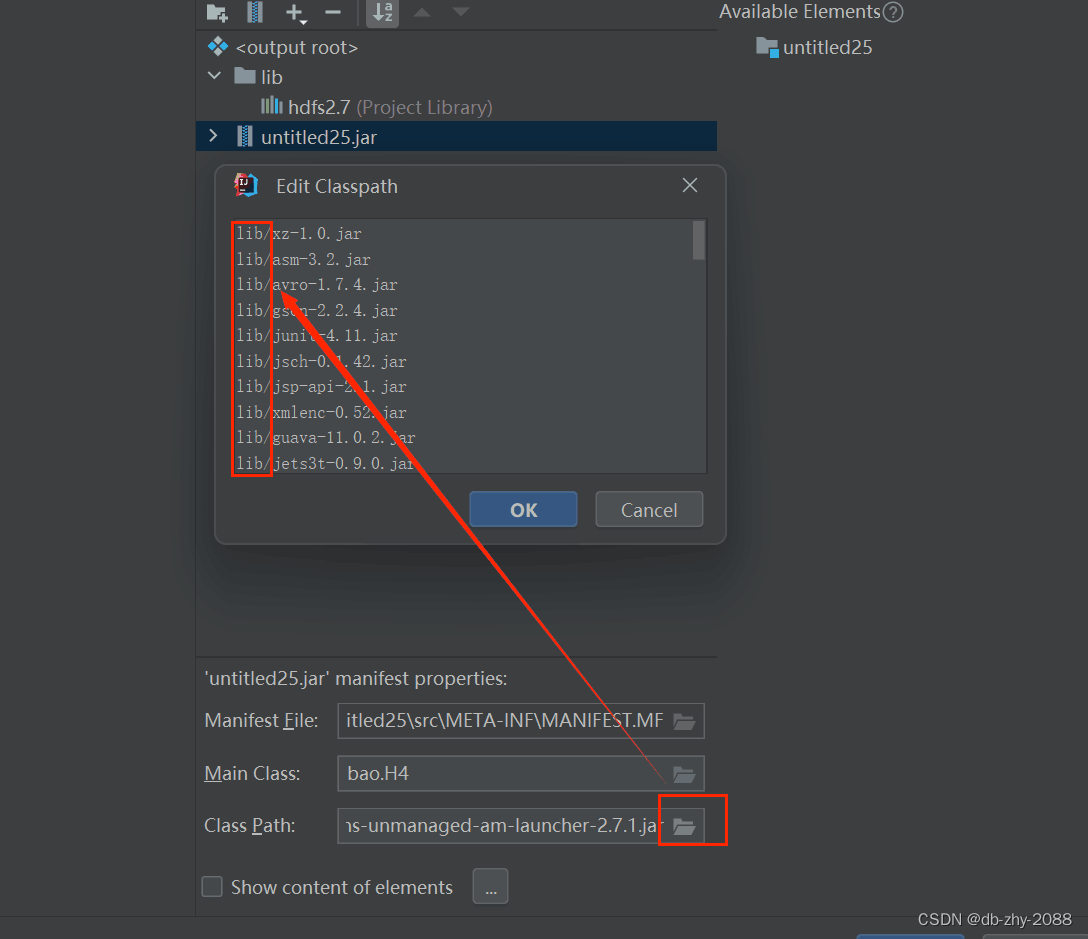 执行构建命令:build -> build artifacts...,出现下图弹框
执行构建命令:build -> build artifacts...,出现下图弹框

查看构建好的jar包:在项目的out文件夹下

四、在ssh运行MapReduce提供的wordcount例子
把jar包上传到虚拟机,然后运行。
- worcount这个程序的作用:统计输入的文件中每个单词数量。
- 将一个hello.txt上传到hdfs: hdfs dfs -put hello.txt /hello.txt
- cd HADOOP_HOME路径/share/hadoop/mapreduce
- 运行wordcount例子:hadoop jar hadoop-mapreduce-examples-2.7.1.jar wordcount /hello.txt /wc
- 查看结果:(1)hdfs dfs -ls /wc (2) hdfs dfs -cat /wc/part-r-00000

查看结果: 
五、总结
在这个过程中,遇到了不少难点,比如本地的代码运行不出来,要注意看有没有传入参数以及需要配置环境变量。在虚拟机中,需要先启动hadoop集群才可以运行jar包。
版权归原作者 db-zhy-2088 所有, 如有侵权,请联系我们删除。