
1:测试数据
CREATE TABLE student (
stu_no VARCHAR(40) NOT NULL,
name VARCHAR(100) NOT NULL
);
insert into student values('1','name1');
insert into student values('2','name2');
insert into student values('3','name1');
insert into student values('4','name2');
insert into student values('5','name1');
** 测试1:对name 字段进行过滤**
SELECT DISTINCT `name` FROM student;
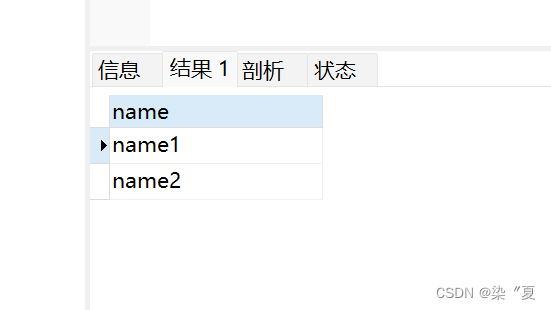
** 测试2:对所有的字段进行去重。**
SELECT DISTINCT * FROM student;
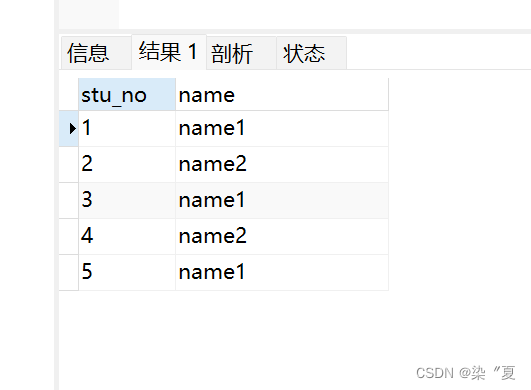
对比测试1和测试2 发现,
distinct 可以对单一字段进行去重,当对所有的字段去重时,只有不同数据的每个字段完全一样的数据被去掉,其他只有一个字段重复的数据并没有变化,因此得出结论:
distinct主要是针对全部字段去重,即去掉完全一样的数据。、
测试3:
select stu_no,name from student group by name;
select stu_no,name from student group by stu_no;

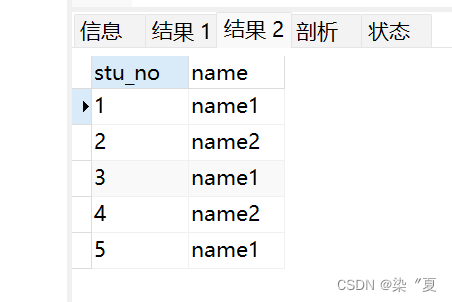
总结:
** 相同:distinct和group by都可以用来去重**
** 不同之处,distinct针对全部字段去重,而group by可以针对全部字段中的单一字段去重。**
两者执行方式不同,distinct主要是对数据两两进行比较,需要遍历整个表。group by分组类似先建立索引再查索引,当数据量较大时,group by速度要优于distinct。
本文转载自: https://blog.csdn.net/XikYu/article/details/130627494
版权归原作者 染〞夏 所有, 如有侵权,请联系我们删除。
版权归原作者 染〞夏 所有, 如有侵权,请联系我们删除。