
一、背景
在Kafka的组成部分(Broker、Consumer、Producer)中,设计理念迥异,每个部分都有自己独特的思考。而把这些部分有机地组织起来,使其成为一个整体的便是「网络传输」。区别于其他消息队列的方式(RocketMQ处理网络部分直接使用成熟的组件Netty),Kafka则是直接对java的NIO进行了二次包装,从而实现了高效的传输
然而处理网络相关的工作是非常复杂的,本文我们只聚焦于网络传输的Producer端,而Producer端也只聚焦在消息发送的部分,使用场景带入的方式来分析一下消息发送的环节,Producer是如何将其扔给网络并发送出去的
二、概述

我们首先回想一下Producer消息发送的整体流程
- 客户端线程会不断地写入数据,当前线程并不会阻塞,而是马上返回。这个时候消息被Producer放在了缓存内,消息并没有真正发送出去
- Producer内部为每个Partition维护了一个RecordBatch的队列,先进先出的模式,统称为RecordAccumulator,数据第一步会先放在这个组件中。放在这个组件中的数据什么时候会真正发送出去呢?这里其实是“大巴车”逻辑(大巴车逻辑是指:1、如果某辆大巴车已经坐满人了,这个时候无条件立即发车。2、虽然本辆大巴车没有坐满人,但是车已经在原地等待了1个小时,即便是只有1位乘客,也要立即发车),以下2个条件满足其一即可:
- RecordBatch已满,无法写入新数据
- RecordBatch虽然还未满,但是已超时
- 为了给RecordAccumulator提速,又引申出了MemoryPool的概念,它主要的作用是一次性分配了一块内存池,避免每次RecordBatch新建时,临时开辟内存空间
- 为什么开辟内存空间会很慢呢? 单纯分配一个连续的内存空间不会有太多的耗时,这里主要是JDK为ByteBuffer的置0操作,byte[]数组开辟空间耗时也是同理。例如DirectByteBuffer.java的构造函数是这样实现的
unsafe.setMemory(base, size, (byte) 0); - 以上所有部分均不涉及网络相关操作,真正网络发送/接收的逻辑是放在了Sender.java线程中。Sender线程会不断地从RecordAccumulator中拉取满足条件的消息记录,从而与Broker建联并发送
以上是Producer发送消息的主流程,本文将会聚焦在Sender网络线程及其相关的逻辑
三、Java NIO
因为Kafka的网络实现是对Java NIO的二次封装,因此在真正开始分析之前,我们有必要先对NIO做个简单回顾
3.1、Server端
public void startServer() throws IOException {
// Selector选择器,NIO中的核心组件,也就是用它来监听所有的网络事件
selector = Selector.open();
// 打开服务端的ServerSocketChannel,只有服务端需要打开ServerSocket
server = ServerSocketChannel.open();
// 为服务端绑定端口,之后所有的client均连接次端口
server.bind(new InetSocketAddress(PORT));
// 这里配置为非阻塞
server.configureBlocking(false);
// 主要是将ServerSocketChannel与selector进行绑定
server.register(selector, SelectionKey.OP_ACCEPT);
SocketChannel client;
SelectionKey key;
Iterator keyIterator;
while (true) {
// 调用select()方法,如果有新的请求,则马上返回,否则最多阻塞100ms
int select = selector.select(100);
if (select == 0) {
continue;
}
// 将所有的事件拿出来,准备迭代
keyIterator = selector.selectedKeys().iterator();
while (keyIterator.hasNext()) {
key = keyIterator.next();
if (key.isAcceptable()) {
// 处理新进来的链接请求
operateConnectEvent(key);
}
if (key.isReadable()) {
// 处理读取事件的请求
operateReadEvent(key);
}
// 事件处理完后,将其移除
keyIterator.remove();
}
}
}
想必大家对上面的demo不会太陌生,这就是JDK给我们提供的server端启动端口监听的经典demo,这里需要注意的是:处理读写请求时,尽量开辟线程来异步处理,避免影响selector监听线程
3.2、Client端
public void startClient() throws IOException {
// 客户端打开自己的Selector
selector = Selector.open();
// 与Server端开始建联
socketChannel = SocketChannel.open(new InetSocketAddress(port));
// 设置非阻塞
socketChannel.configureBlocking(false);
// 注册读时间到selector上,这样通过selector就可以监听网络读取的事件了
SelectionKey selectionKey = socketChannel.register(selector, SelectionKey.OP_READ);
// attach方法并没有实质的含义,一般是将自己业务中的辅助类绑定在key上,方便后续的读取及处理
selectionKey.attach(null);
Iterator ikeys;
SelectionKey key;
SocketChannel client;
try {
while (flag) {
// 调用此方法一直阻塞,直到有channel可用
selector.select();
ikeys = selector.selectedKeys().iterator();
while (ikeys.hasNext()) {
key = ikeys.next();
if (key.isReadable()) {
// 处理读事件,一般开多线程处理
handleReadEvent();
}
ikeys.remove();
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
主要思想也是通过selector监听不同的事件,一旦获取到事件,便开线程异步处理,不阻塞selector,从而达到高效通信的目的
Server端+Client端不足百行的demo代码,会被Kafka如何包装呢?
四、Sender线程概述
我们在具体介绍Sender线程之前,首先对其有个全貌的认知,也就是先整体后细节。而本节就是一个整体认知,虽然很多细节不会展开,但是对网络线程的理解至关重要
4.1、单网络线程
Sender线程是在KafkaProducer对象初始化启动的,启动后便是一个无限循环的调用。run()方法如下
@Override
public void run() {
log.debug("Starting Kafka producer I/O thread.");
// main loop, runs until close is called
while (running) {
try {
runOnce();
} catch (Exception e) {
log.error("Uncaught error in kafka producer I/O thread: ", e);
}
}
.... // 此处是一些优雅关机的代码
}
由此我们可以得出结论
- Sender线程是一个单线程,一个KafkaProducer只会对应一个网络线程
- Sender伴随Producer的启动而启动,同时也伴随Producer的消亡而消亡
其实这也就解释了当我们启动一个Producer进行压测的时候,通常不能把带宽打满。因为网络线程所做的事儿,无非是将用户生产的数据从JVM中拷贝至网卡,而这个动作又是典型的cpu密集型,单个线程确实无法提高资源利用率
而相比较Broker而言,Broker提供了更为丰富的线程数量配置策略,比如网络线程数的配置num.network.threads及IO线程数的配置num.io.threads等,为什么Producer的网络线程要配置为单个呢?我个人认为主要是以下原因:
- Producer客户端的定位;虽然Producer与Broker都存在网络传输的功能,但是Producer终究只是一个客户端,通常客户端所在的机器配置是比不上Broker端的,因此单个网络线程足以满足绝大部分场景的需求
- 容易横向扩展;我们可以通过简单地启动多个Producer从而实现性能的提升,而这个操作是轻量的
- 开发的复杂性;即便是在单网络线程的case下,Producer需要处理数据收集、发送、接收、维护元数据等,复杂性已然不低,如果需要单KafkaProducer同时启动多个网络线程的话,势必带来较大的复杂性
4.2、Sender概览
由上节我们知道Sender线程一直在重复调用runOnce()方法,这个方法又做了什么操作呢?
void runOnce() {
if (transactionManager != null) {......}
long currentTimeMs = time.milliseconds();
// 拉取已经准备好的数据
long pollTimeout = sendProducerData(currentTimeMs);
// 执行网络数据发送
client.poll(pollTimeout, currentTimeMs);
}
简单概括就是两件事儿:
- 将RecordAccumulator中已经准备好的数据,进行字节粒度的协议编码,最终放入待发送区
- 真正执行NIO数据发送、接收响应
五、线程相关类
在NIO中很重要的2个概念是:Selector及SelectionKey,即一个是多路复用器,一个可以简单认为是Channel。Kafka分别对这个概念进行了包装,整体的类图如下:
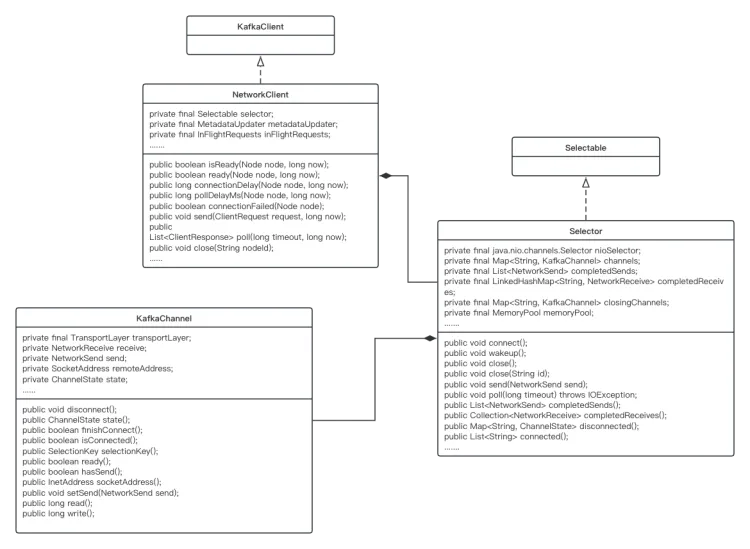
5.1、NetworkClient
顾名思义,这个类是为客户端而服务的,它是所有客户端访问网络的总入口,他只实现了一个接口KafkaClient,也是KafkaClient的唯一实现类。接口有如下方法:
- boolean isReady(Node node, long now);
- boolean ready(Node node, long now);
- long connectionDelay(Node node, long now);
- long pollDelayMs(Node node, long now);
- boolean connectionFailed(Node node);
- AuthenticationException authenticationException(Node node);
- void send(ClientRequest request, long now);
- List poll(long timeout, long now);
- void disconnect(String nodeId);
- void close(String nodeId);
- Node leastLoadedNode(long now);
- int inFlightRequestCount();
- boolean hasInFlightRequests();
- int inFlightRequestCount(String nodeId);
- boolean hasInFlightRequests(String nodeId);
- boolean hasReadyNodes(long now);
- void wakeup();
- ClientRequest newClientRequest(String nodeId, AbstractRequest.Builder requestBuilder,long createdTimeMs, boolean expectResponse);
- ClientRequest newClientRequest(String nodeId,AbstractRequest.Builder requestBuilder,long createdTimeMs,boolean expectResponse,int requestTimeoutMs,RequestCompletionHandler callback);
- void initiateClose();
- boolean active();
可以看到大部分都是与网络相关的,而里面比较重要且高频的方法不外乎以下两个,也是本文着重展开介绍的2个方法
- void send(ClientRequest request, long now);
- List poll(long timeout, long now);
字面含义,即一个发送、一个接受,然而这里封装的这2个方法却是更偏重业务语义
| void send(ClientRequest request, long now); | * 对消息进行协议编码
- 是将消息放入待发送区,但并不会真正出发网络请求 | | List poll(long timeout, long now); | 而poll方法中则包含了真正网络的发送与接收,也就是只有poll方法会调用Java NIO的相关api接口* 真正提交网络发送
- 处理发送成功的请求列表
- 处理接收到的response
- connection相关处理
- … |
后续的分析也主要围绕这两个入口方法展开
NetworkClient作为网络请求的入口类,很多关于底层网络的操作都是交由Selector来实现的,而NetworkClient则更多的将自己的职责放在了网络上层的建设上,诸如维护发送列表、inFlightRequests等业务控制上
List responses = new ArrayList<>();
handleCompletedSends(responses, updatedNow);
handleCompletedReceives(responses, updatedNow);
handleDisconnections(responses, updatedNow);
handleConnections();
handleInitiateApiVersionRequests(updatedNow);
handleTimedOutConnections(responses, updatedNow);
handleTimedOutRequests(responses, updatedNow);
completeResponses(responses);
5.2、Selector
注意,与nio包中Selector不同的是,这里的Selector的全路径是
org.apache.kafka.common.network.Selector
,我们看一下它的主要成员变量,也大致能猜到它在网络请求中发挥哪些功能
private final java.nio.channels.Selector nioSelector;
private final Map channels;
private final Set explicitlyMutedChannels;
private final List completedSends;
private final LinkedHashMap completedReceives;
private final Set immediatelyConnectedKeys;
private final Map closingChannels;
private Set keysWithBufferedRead;
private final Map disconnected;
private final List connected;
private final List failedSends;
private final ChannelBuilder channelBuilder;
.........
- 它持有nio的java.nio.channels.Selector引用,这样可以直接进行一些底层的网络操作,比如真正与broker建联
- 所有已建联的channel列表,这样通过nodeId可以快速找到对应的KafkaChannel
- 保存已完成发送的列表,当NetworkClient需要处理这些请求时,可以直接在这里获取到;注意这个list的实现类就是简单的ArrayList,因为网络线程是单线程,所以不存在并发冲突的问题
- 同样存储了接收请求列表LinkedHashMap,不再展开
- 以及存储正在关闭的channel、已经关闭的Channel等
- 。。。。。。
Selector相对比NetworkClient来说,它做了更贴合网络的操作,比如真正与broker建联、维护Channel列表、处理超时时,关闭Channel等等
值得一提的是,Selector对于SocketChannel的配置,我们看一下关于配置的方法
org.apache.kafka.common.network.Selector#configureSocketChannel
private void configureSocketChannel(SocketChannel socketChannel, int sendBufferSize, int receiveBufferSize)
throws IOException {
socketChannel.configureBlocking(false);
Socket socket = socketChannel.socket();
socket.setKeepAlive(true);
if (sendBufferSize != Selectable.USE_DEFAULT_BUFFER_SIZE)
socket.setSendBufferSize(sendBufferSize);
if (receiveBufferSize != Selectable.USE_DEFAULT_BUFFER_SIZE)
socket.setReceiveBufferSize(receiveBufferSize);
socket.setTcpNoDelay(true);
}
有这样几个配置项:
- socketChannel.configureBlocking(false); 配置为非阻塞
- socket.setKeepAlive(true); 保持连接
- socket.setSendBufferSize(sendBufferSize); 配置发送缓冲区,默认为128K
- socket.setReceiveBufferSize(receiveBufferSize); 配置接收缓冲区,默认32K
- socket.setTcpNoDelay(true); 非Delay
我们注意到,上面几个配置都比较好理解,包括发送的缓冲区比接收缓冲区大了不少,因为Producer是典型的发送多,接收少的场景;而TcpNoDelay属性为什么要设置为true呢? 设置为false不是能提高网络性能吗?
其实在TCP中有个Nagle算法,这个算法的目的是减少网络中小包的数量,通俗点来讲就是将诸多的小包整合为一个大包进行传输,这样做的好处是,提高网络利用率,使得整体发送速率更快;弊端是可能会增加某些包的延迟。那Kafka为什么要禁用这个算法呢?其实本质原因就是Kafka在Producer内部已经完成了消息攒批,这些待发送的包无非以下两种状态:
- 攒批充足,默认是16K,包足够大,不需要Nagle算法的干预
- 攒批不理想,待发送的数据可能很小;但是即便是数据很少,这些消息也在批次中停留了足够久的时间,这个时候唯一要做的就是尽快把数据发出去,不要再帮我为了优化TCP而增加延迟了,否则超过Producer等待的最大时长,Producer会将本次请求标记超时。其次这种攒批不理想的场景,通常是Producer发送量很小,数据在时间轴上很稀疏,即便是启用了Nagle算法,大概率也不能产生TCP变大包的预期
总结一句话就是Producer的聚批做的已经足够好了,Nagle算法的介入只会带来负优化
5.3、KafkaChannel
上文可知,Selector管理了所有的Channel,而KafkaChannel则是与某个broker连接的具体通道。Selector的各类网络请求也均交给KafkaChannel来执行。
需要说明的是,KafkaChannel其实是通道注册的时候attach在SelectionKey上的,也就是KafkaChannel与SelectionKey是1对1的关系。以下是KafkaChannel所对外暴露的方法
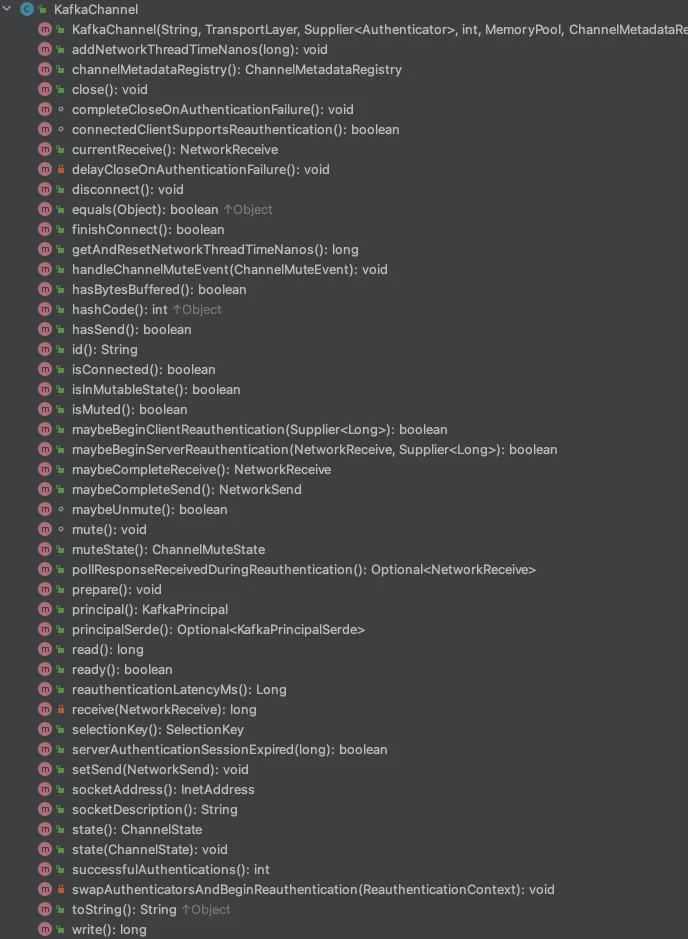
除了网络相关的操作外,KafkaChannel还有一个很重要的特性,就是缓存当天通道的即将要发送的数据,以及接收到的数据
- private NetworkSend send;
- private NetworkReceive receive;
当然放在这里的数据都是已经经过编解码完毕的数据
小结:3个类的总代码行数超过了3000行,是Producer发送消息的核心类,我们先对这3个类有个大致的概念,以及它们每个类主要实现的功能点,这样非常有益于对整体的认知。至于Kafka将网络操作的相关操作抽象为这3个类是否合理,就仁者见仁智者见智了,其实这3个类是nio及Kafka自身业务的混合体,它的核心就是为Kafka的客户端网络请求提供服务;笔者认为虽然这样的设计并没有把一些特性或者功能的界限画的很清楚,但是整体运行Kafka的网络功能还是游刃有余的
六、数据准备
单纯地将数据放入聚合器Accumulator还不算是数据准备完成,消息发送需要将其转换为面向字节的网络协议的格式,才是真正具备待发送的前提
6.1、消息编码
发送请求的编码在类org.apache.kafka.common.protocol.SendBuilder中:
private static Send buildSend(
Message header,
short headerVersion,
Message apiMessage,
short apiVersion
) {
ObjectSerializationCache serializationCache = new ObjectSerializationCache();
MessageSizeAccumulator messageSize = new MessageSizeAccumulator();
header.addSize(messageSize, serializationCache, headerVersion);
apiMessage.addSize(messageSize, serializationCache, apiVersion);
SendBuilder builder = new SendBuilder(messageSize.sizeExcludingZeroCopy() + 4);
builder.writeInt(messageSize.totalSize());
header.write(builder, serializationCache, headerVersion);
apiMessage.write(builder, serializationCache, apiVersion);
return builder.build();
}
编码分2部分,首先需要计算当前类型编码占用空间的总大小,然后将内容进行逐一填充;这里Kafka将各类消息定义了统一的接口 org.apache.kafka.common.protocol.Message,这样每种类型的消息都写好各自的编解码协议即可,类似于命令模式,对各类编解码进行了解耦,方便后续的扩展与维护。而Message接口的实现类居然有 357 个之多,可见其软件设计的复杂度
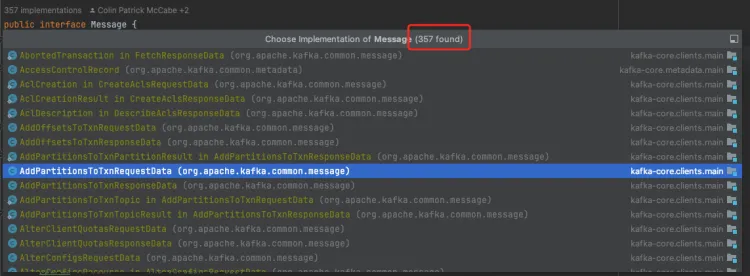
如此之多的实现类,我们无法穷举,因此以发送消息类型的Message为demo来阐述一下编码的格式;任何消息类型的网络编码格式均分为header与body两部分,发送消息类型的header与body分别为
org.apache.kafka.common.message.RequestHeaderDataorg.apache.kafka.common.message.ProduceRequestData
6.1.1、header编码
首先看header部分的编码

下面分别对上述字段进行简要说明
api key
协议的类型编码,即每种类型的协议编码均不同,例如消息发送-0,消息拉取-1,获取位点-2,获取metadata-3等等,2.8.2版本的kafka的协议类型已经到达了64种,具体可以查看枚举类
org.apache.kafka.common.message.ApiMessageTypeapi key version
根据调整会不断迭代升级,2.8.2版本已经升级到了9
correlation id
相关性id,客户端指定,从0开始累加,服务端返回时,也需要回应同样的编号,这样客户端就可以将一次request跟response联系起来。这里可以看到,相关性id的长度是4个字节,难道不怕越界吗?其实相关性id不需要保证唯一性,当达到了int最大值后,下一次从0继续即可
client id length
客户端id其实是一个字符串,比如“producer-1”,因为是可变内容,因此照例使用length+content的方式进行存储
client id content
同上,真正存储 client id 的内容
tagged field
标记位,一般情况下,这个属性通常是empty的,主要是为了提供RPC协议的灵活性,例如一些可有可无的字段,在没有这个字段时如何节省传输带宽;另外协议传输的扩展性也可以依赖这个字段,例如我们想在一次消息发送的时候,顺便将traceID也带上,等等
背景可以参考 KIP-482 https://cwiki.apache.org/confluence/display/KAFKA/KIP-482%3A+The+Kafka+Protocol+should+Support+Optional+Tagged+Fields
另外我们还留意到某些字段使用了varint,这个又是什么鬼呢?简单来说就是可变长度的int,还有varlong等类型。当我们想将一个字段设置为int型,而大多数的情况下,它可能只占用了很小的空间,例如0、1、2等,这个时候可变长度就派上了用场,本文不再对此展开,相关的论文读者可参考 westword加速http://code.google.com/apis/protocolbuffers/docs/encoding.html
Kafka中varint的实现:
public static void writeUnsignedVarint(int value, ByteBuffer buffer) {
while ((value & 0xffffff80) != 0L) {
byte b = (byte) ((value & 0x7f) | 0x80);
buffer.put(b);
value >>>= 7;
}
buffer.put((byte) value);
}
6.1.2、body编码
消息发送对应的body编码实现类是
org.apache.kafka.common.message.ProduceRequestData

虽然body真正的内容会比header多很多,但是其编码协议并不复杂,大部分字段上图均已说明。值得一提的是,Kafka协议为了压缩协议体积,可谓“无所不用其极”,还有很多很多细节层面的优化,也正是由于这些一点一滴的积累,成就了Kafka在消息队列中行业大佬的地位
6.2、TCP粘包/拆包
这里没有太多需要展开论述的,Kafka处理粘包/拆包的问题,采用的就是经典的length+content的方式;也就是首先写入4个字节的包长度,后面紧跟消息内容;而拆包时,先读取4个字节,继而完整读取后续的消息
6.3、零拷贝?
细心的读者可能会发现,在构造Send类的时候,也就是数据编码的时候
org.apache.kafka.common.protocol.SendBuilder#buildSend
,有这样的代码:
SendBuilder builder = new SendBuilder(messageSize.sizeExcludingZeroCopy() + 4);
builder.writeInt(messageSize.totalSize());
header.write(builder, serializationCache, headerVersion);
apiMessage.write(builder, serializationCache, apiVersion);
感觉像是所有的协议层均用堆内存的ByteBuffer来构建,但是消息体本身却让它走零拷贝。消息发送也可以零拷贝吗?消息本身不是已经进入到了JVM堆内存中了吗?零拷贝又是如何实现呢
而且我们在类
org.apache.kafka.common.message.ProduceRequestData.PartitionProduceData#addSize
中也发现了操作零拷贝的代码
\_size.addZeroCopyBytes(records.sizeInBytes())
,但是在真正写入消息记录的时候,却只是将消息记录放入了SendBuilder的成员变量中
org.apache.kafka.common.protocol.SendBuilder#buffers
。究竟是怎么回事儿呢?
原来这里闹了乌龙,SendBuilder也仅是复用了
org.apache.kafka.common.protocol.MessageSizeAccumulator
类的功能,而这个类除了给Producer使用外,还会给消息拉取、同broker内同步流量等使用,在消费的场景确实用到了零拷贝的能力,而Producer却是一定无法执行零拷贝的,因为消息体已经存在于了JVM堆中
6.4、放入待发送区
经过上述一大圈工作,Kafka将编码好的消息封装进入了
org.apache.kafka.common.network.ByteBufferSend
中,接下来就是放入网络待发送区了
其实放入待发送区就是将ByteBufferSend放入KafkaChannel的成员变量send中,
org.apache.kafka.common.network.KafkaChannel#setSend
public void setSend(NetworkSend send) {
if (this.send != null)
throw new IllegalStateException("Attempt to begin a send operation with prior send operation still in progress, connection id is " + id);
this.send = send;
this.transportLayer.addInterestOps(SelectionKey.OP_WRITE);
}
因为马上就要执行write操作了,因此开始监听channel的OP_WRITE写入事件
有个细节需要注意下,这里会判断
send != null
,这个网络send会有不等于null的时候吗?这里先卖个关子,后文会提及。
另外有同学说,“Producer有两个队列,一个攒批队列,一个网络待发送的队列”,我们通过读源码发现,这个说法肯定是有问题的,Sender网络线程只有一个,也不存在网络待发送队列,而是每个Channel在同一时刻只会发送一个Send
七、执行发送
7.1、发送流程
真正执行发送的逻辑反而变得简单,入口方法为
org.apache.kafka.clients.NetworkClient#poll
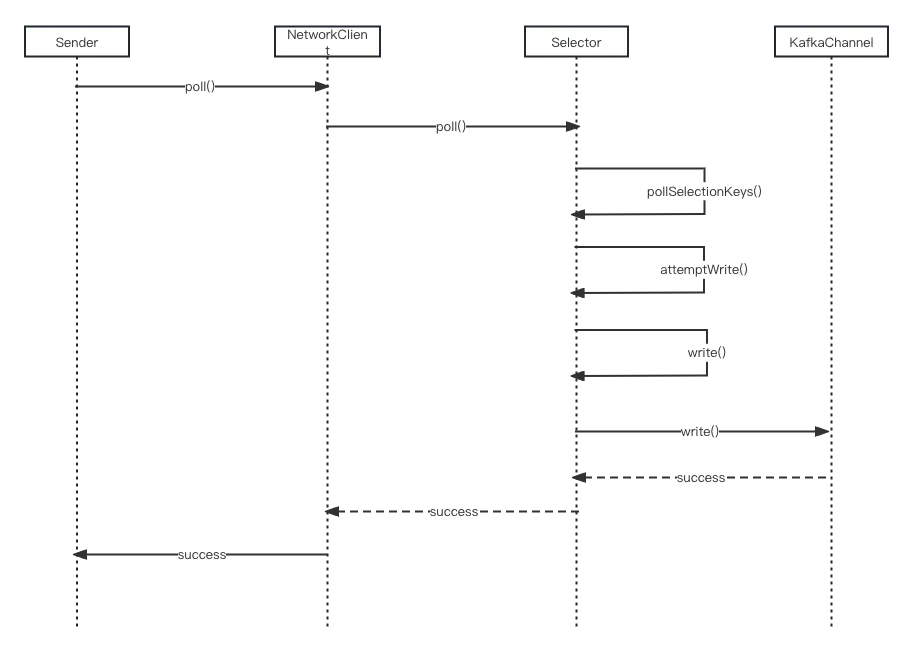
最终会调用至KafkaChannel的write()方法
public long write() throws IOException {
if (send == null)
return 0;
midWrite = true;
return send.writeTo(transportLayer);
}
这里简单提一下接口
org.apache.kafka.common.network.TransportLayer
,这个接口的实现类有2个:PlaintextTransportLayer、SslTransportLayer,也就是Kafka抽象了一个TransportLayer层,通过对TransportLayer层的切换来实现网络加解密的动作,这样把对SSL的操作放在了最底层,即便于维护,又不会对上层的代码产生影响,的确是高
继续往下追的话,我们在PlaintextTransportLayer发现了NIO的jdk调用
public int write(ByteBuffer[] srcs) throws IOException {
return socketChannel.write(srcs);
}
至此写入动作完结
7.2、只发送一次?
通常我们向网络或者文件发送ByteBuffer时,为了确保ByteBuffer中的内容全部发送完毕,会一直判断ByteBuffer的remaining()已经为空,才停止发送,这样能保证将ByteBuffer中的数据全部发送出去,如下:
while (byteBuffer.remaining() > 0) {
socketChannel.write(byteBuffer);
}
但在真正执行发送的代码中,我们注意到,调用网络请求发送的代码中,只触发了一次
public long writeTo(TransferableChannel channel) throws IOException {
long written = channel.write(buffers);
if (written < 0)
throw new EOFException("Wrote negative bytes to channel. This shouldn't happen.");
remaining -= written;
pending = channel.hasPendingWrites();
return written;
}
再结合6.4小节中,如果发现send属性不为空,则会抛出异常:
public void setSend(NetworkSend send) {
if (this.send != null)
throw new IllegalStateException("Attempt to begin a send operation with prior send operation still in progress, connection id is " + id);
this.send = send;
this.transportLayer.addInterestOps(SelectionKey.OP_WRITE);
}
抛出异常后,Producer就会把当前的Channel关闭。那我们能否得出这样一个结论:一旦某个Channel中的数据不能一次性发送完毕,Kafka就会抛出异常,然后关闭当前Channel ?
答案是否定的,因为在数据准备准备阶段,Kafka会判断,如果当前的Channel中有待发送数据,则不会从Accumulator中拉取该Channel的数据,而在发送阶段,会任然将未发送出去的数据再次执行发送
org.apache.kafka.clients.NetworkClient#isReady
的方法的相关调用如下
// org.apache.kafka.clients.NetworkClient#isReady
@Override
public boolean isReady(Node node, long now) {
return !metadataUpdater.isUpdateDue(now) && canSendRequest(node.idString(), now);
}
// org.apache.kafka.clients.NetworkClient#canSendRequest
private boolean canSendRequest(String node, long now) {
return connectionStates.isReady(node, now) && selector.isChannelReady(node) &&
inFlightRequests.canSendMore(node);
}
// org.apache.kafka.clients.InFlightRequests#canSendMore
public boolean canSendMore(String node) {
Deque queue = requests.get(node);
return queue == null || queue.isEmpty() ||
(queue.peekFirst().send.completed() && queue.size() < this.maxInFlightRequestsPerConnection);
}
// org.apache.kafka.common.network.ByteBufferSend#completed
public boolean completed() {
return remaining <= 0 && !pending;
}
Kafka为什么要这样设计,一次性将数据发送出去不好吗?一定要这样费尽周章的各种判断吗?
这里正印证了那句老话:细节之处见功力!通常情况下,当我们调用write()接口,向操作系统发送网络数据时,只要网络不太繁忙,一般都是能够一次性将数据发完的,OS也会尽量将数据全部发送出去。而如果一次没有将缓冲区的数据发送完毕,那很有可能印证出当前channel的网络压力非常大,如果采用不发送完毕不罢休的逻辑,那很有可能当前Sender线程要在这里“卡”很久,而Sender我们知道是单线程的,他是会向多个Broker也就是多个Channel发送数据的,我们不能因为一个Broker的网络阻塞,而影响了整个Producer的吞吐。当然未发送的数据也不是不管了,而是等到下一个周期再尝试发送,这样即便是某个Broker网络拥塞了,不会影响其他Broker的吞吐
Kafka在接受网络数据的时候,同样也是采用“只接受一次”的策略
八、处理响应
处理响应的过程与发送数据一样,入口均在
org.apache.kafka.clients.NetworkClient#poll
中,相比较发送而言,处理响应是一个相对轻量的操作,主要经历以下几个步骤:
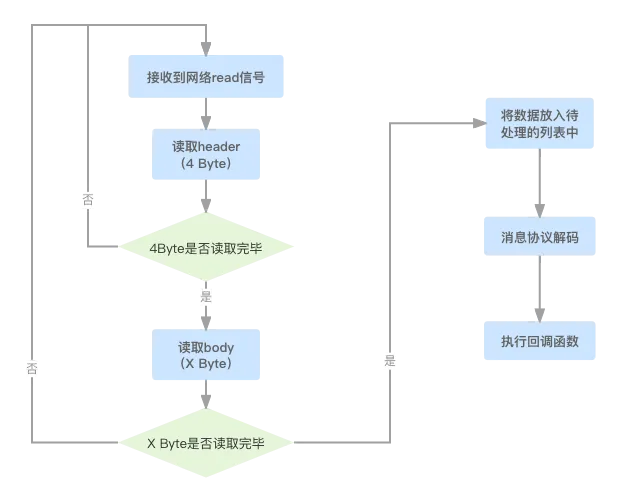
- 接收网络read信号1. 这个的触发代码就是JDK的select,
this.nioSelector.selectedKeys(),只要有read信号就会进来 - 读取4字节的header
- 有同学会说,4个字节,还有可能读不满吗?的确,因为虽然只读4个字节,但也是通过TCP打包进行传输,很有可能出现粘包的情况,只读取到1、2个字节。如果遇到读不满的情况,Producer会将已读取的数据暂时放入ByteBuffer缓存中,等待下一次的Sender线程的轮循,直到读取满4个字节
- 读取消息体X字节
- 消息体的读取跟header一致,只不过读取header的时候,明确知道是4个字节,而读取body的时候,是一个动态值,需要读取从header获取
- 将消息放入待处理列表
- 消息协议解码
- 这里正好是消息发送时的逆操作,进行协议解码。需要注意,消息解码分两步,一个是header解码,一个是body解码
- 主要注意的是,header解码的时候,会判断response的correlationId与request的是否一致,如果发现匹配不上,将会抛出异常
- 解码的入口方法为
org.apache.kafka.common.requests.AbstractResponse#parseResponse(org.apache.kafka.common.protocol.ApiKeys, java.nio.ByteBuffer, short)里面根据请求类型的不同,分别做了对应的处理,此处不再赘述 - 执行回调函数
- Producer的
org.apache.kafka.clients.NetworkClient#inFlightRequests成员变量存储了所有已经发送给Broker但是还未收到响应的请求列表,这个列表默认大小是5,即最多同时允许5个请求没有收到响应,且里面存储了回调函数org.apache.kafka.clients.NetworkClient.InFlightRequest#callback,方便收到响应后,触发后续的业务逻辑,比如归还MemoryPool等
九、总结
至此,一次网络的发送与接收便告一段落,不过需要指明的是,本文仅仅是阐述了消息发送时候,涉及网络相关部分的主流程,还有很多细节并没有展开,比如Selector是如何关闭Channel的、Channel遇到不预期异常后如何触发重连等。另外Producer还有很多请求类型,比如获取meta数据、心跳、sync api version等,不过这些连接类型虽然与消息发送不一样,但是网络流程均是相通的。网络策略是Kafka的基建,对网络部分有个整体的了解,有利于我们更快地学习、吸收Kafka
虽然 talk is cheap, show me the code,但我本人不喜欢在技术的文章中,黏贴大量的代码段,因为要读源码的话,读者直接在github上拉取对应版本代码阅读更方便。不过由于Kafka网络部分相对还是比较复杂的,也掺杂了很多业务处理的逻辑,本文还是黏贴了很多关键部分的代码以及出处的method,所幸代码篇幅都很短,希望不要给阅读带来不便
简单总结一下Producer网络部分的特点
- 异步;异步处理也是Producer的整体特点,Producer将网络线程与发送线程独立开来,也就为消息攒批提供了底层支持;同时接收到消息响应后,异步调用callback等,设计都非常合理
- 细节;我理解Kafka的高吞吐并不是某个设计带来的宏利,而是对于诸多细节完美处理而实现的。例如屏蔽Nagle算法、一次发送/接收、可变长度编码、使用队列缓存等等
- 原生JDK NIO;Kafka对NIO的接口进行了二次封装,不过封装的很轻量,基本上均是使用JDK的接口。此外使用header+body的方式解决了TCP粘包/拆包的问题
版权归原作者 egrad 所有, 如有侵权,请联系我们删除。