
实验名称
部署全分布模式HBase集群和实战HBase
实验性质
(必修、选修)
必修
实验类型(验证、设计、创新、综合)
综合
实验课时
2
实验日期
2023.11.07-2023.11.10
实验仪器设备以及实验软硬件要求
专业实验室(配有centos7.5系统的linux虚拟机三台)
实验目的
理解HBase数据模型。
理解HBase体系架构。
熟练掌握HBase集群的部署。
了解HBase Web UI的使用。
熟练掌握HBase Shell常用命令的使用。
了解HBase Java API,能编写简单的HBase程序。
实验内容(实验原理、运用的理论知识、算法、程序、步骤和方法)
****1.****HBase集群的部署原理:
Hadoop生态环境: HBase通常部署在Hadoop生态环境上,依赖HDFS(Hadoop Distributed File System)存储数据。
ZooKeeper: HBase集群通常依赖ZooKeeper进行协调和管理,确保集群中的各个节点之间的一致性和可用性。
Master-RegionServer架构: HBase集群包含一个或多个Master节点和多个RegionServer节点。Master负责集群管理和元数据操作,而RegionServer存储和处理实际的数据。
HBase根目录: HBase在HDFS上有一个根目录,用于存储表的元数据和实际数据。这个目录会分散在HDFS上的不同节点上,实现了数据的分布式存储。
2. HBase实战的实验原理:
创建和管理表: 使用HBase Shell或API创建表,定义列簇、列等结构,并观察表的分布情况。
数据写入和读取: 向HBase表中写入数据,并通过不同方式进行读取,观察数据的分布和读写性能。
HBase过滤器: 使用HBase过滤器来检索满足特定条件的数据,例如列值、时间戳等。
HBase Coprocessors: 实验使用HBase Coprocessors来进行数据处理,例如计数、聚合等,加强HBase的功能。
监控和性能调优: 使用HBase的监控工具(如HBase Web UI)来监测集群的状态,观察各节点的负载情况,进行性能调优。
故障模拟: 模拟节点故障,观察HBase的自动恢复机制,确保集群的可用性和容错性。
数据一致性: 观察HBase在数据写入和更新时的一致性保证,了解HBase的事务特性。
备份和恢复: 实验备份和恢复HBase表,确保在发生灾难性事件时能够迅速还原数据。
实验步骤:
1.规划全分布模式HBase集群。
采用的是HBase版本是1.4.10,3个节点的机器名分别为master、slave1、slave2,IP地址依次为192.168.18.100、192.168.18.101、192.168.18.102
2.部署全分布模式HBase****集群。
1). 初始软硬件环境准备
(1)准备3台机器,安装操作系统,编者使用CentOS Linux 7.5。
(2)对集群内每一台机器,配置静态IP、修改机器名、添加集群级别域名映射、关闭防火墙。
(3)对集群内每一台机器,安装和配置Java,要求Java 1.7或更高版本,编者使用Oracle JDK 8u191。
(4)安装和配置Linux集群中主节点到从节点的SSH免密登录
2). 获取HBase
HBase官方下载地址为https://hbase.apache.org/downloads.html,建议读者下载stable目录下的当前稳定版本。编者采用的HBase稳定版本是2019年6月10日发布的HBase 1.4.10,其安装包文件hbase-1.4.10-bin.tar.gz例如存放在master机器的/home/xuluhui/Downloads中。
3). 主节点上配置HBase
HBase所有配置文件位于$HBASE_HOME/conf下,具体的配置文件如前文图5-9所示。本实验中编者仅修改hbase-env.sh、hbase-site.xml、regionservers三个配置文件。
假设当前目录为“/opt/so/hbase-1.4.10”,切换到普通用户如root下,在主节点master上配置HBase的具体过程如下所示。
(1)编辑配置文件hbase-env.sh
hbase-env.sh用于设置Linux/Unix环境下运行HBase要用的环境变量,包括Java安装路径等,使用“vim conf/hbase-env.sh”对其进行如下修改。
设置JAVA_HOME,与master上之前安装的JDK位置、版本一致,将第27行的注释去掉,并修改为以下内容,修改后的效果如图所示。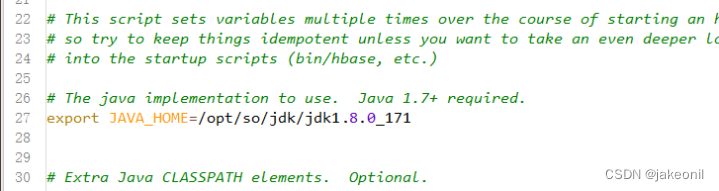
export JAVA_HOME=/usr/java/jdk1.8.0_191/
编辑配置文件hbase-env.sh中JAVA_HOME
将第46、47行的PermSize作为注释,因为JDK8中无需配置,修改后的效果如图所示。
编辑配置文件hbase-env.sh中PermSize
JDK8下若PermSize配置不作为注释或删掉,则启动HBase集群时会出现以下“warning”警告信息
设置HBASE_PID_DIR,修改进程号文件的保存位置,该参数默认为“/tmp”,将第120行修改为以下内容,如图所示。其中pids目录由HBase集群启动后自动创建。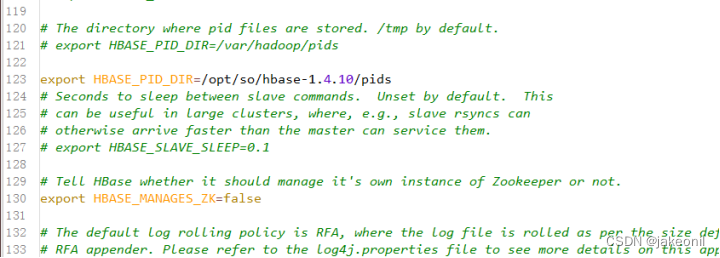
编辑配置文件hbase-env.sh中HBASE_PID_DIR
设置HBASE_MANAGES_ZK,将其值设置为false,即关闭HBase本身的ZooKeeper集群,将第128行修改为以下内容,如图所示。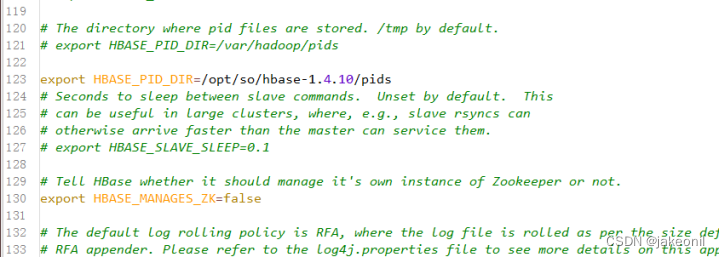
编辑配置文件hbase-env.sh中HBASE_MANAGES_ZK
(2)编辑配置文件hbase-site.xml
hbase-site.xml是HBase核心配置文件,包括HBase数据存放位置、ZooKeeper集群地址等配置项。在master机器上修改配置文件hbase-site.xml,具体内容如下所示。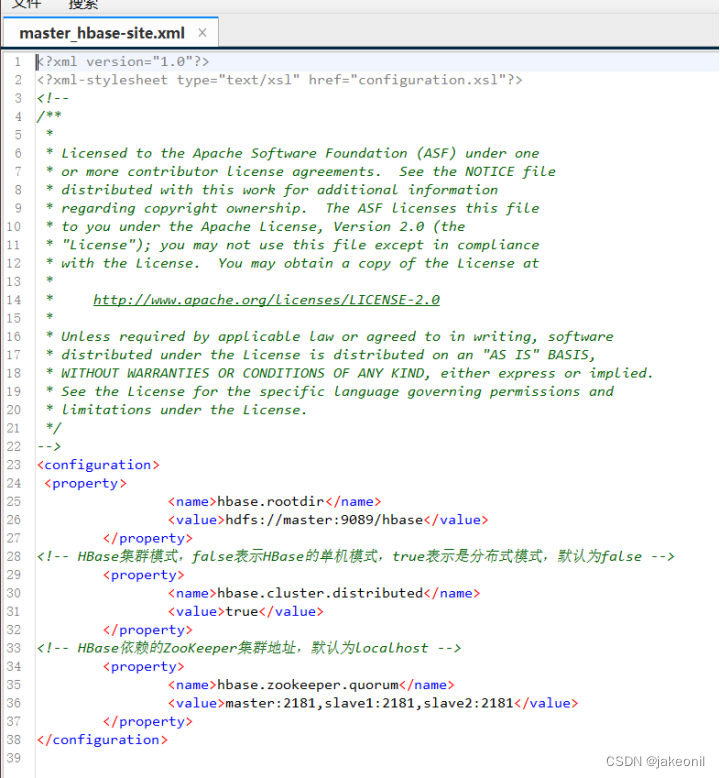
(3)编辑配置文件regionservers
Regionservers用于设置运行HRegionServer从进程的机器列表,每行1个主机名。在master机器上修改配置文件regionservers,该文件原来内容为“localhost”,修改为以下内容。
slave1
slave2
3.启动全分布模式HBase集群。
(1. 启动HDFS集群
在主节点上使用命令“start-dfs.sh”启动HDFS集群,使用的命令及运行效果如图5-23所示,从图5-23中可以看出,HDFS主进程NameNode成功启动,slave1和slave2上的从进程DataNode此处未展示,读者应保证HDFS所有主从进程都启动成功。
(2. 启动ZooKeeper集群
由于本实验中HBase并未自动管理ZooKeeper,所以用户需要手工启动ZooKeeper集群。在ZooKeeper集群的所有节点上使用命令“zkServer.sh start”启动ZooKeeper集群,编者为了方便,在节点master上使用ssh远程连接slave1、slave2,完成了各个节点ZooKeeper的启动工作
(3. 启动HBase集群
在主节点上启动HBase集群

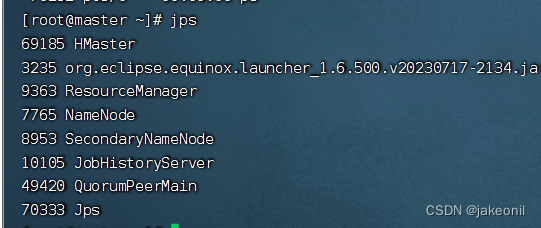
而在从节点上: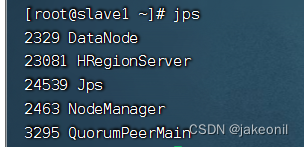
4.验证全分布模式HBase集群。
主节点上的webUI的界面是:
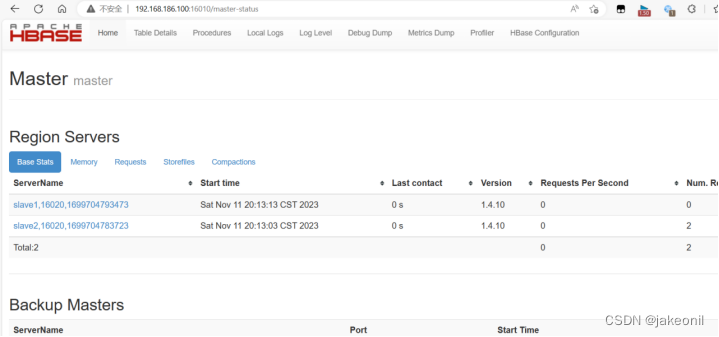
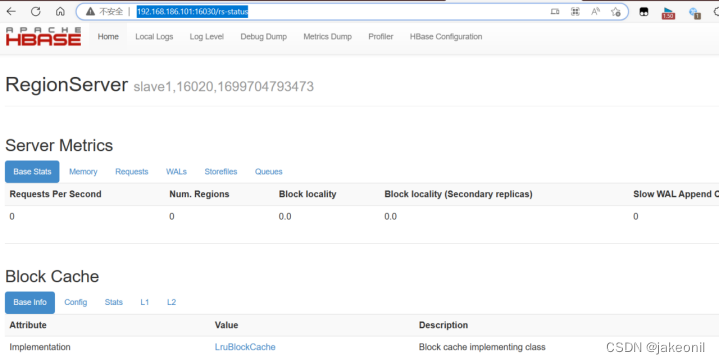
从节点的webUI的界面:
****5.**使用HBase Web **UI。
(1)使用hbase shell
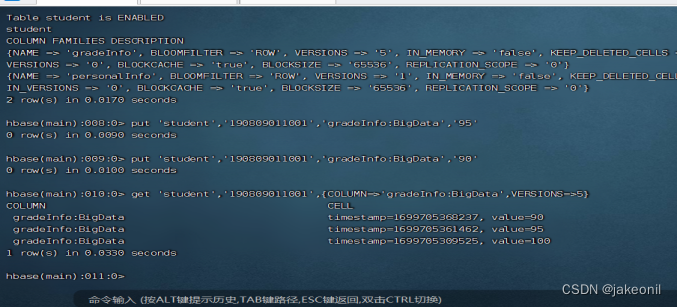
(2)打开HBase主节点的Web UI,可以看到已建立的student表,如图所示。
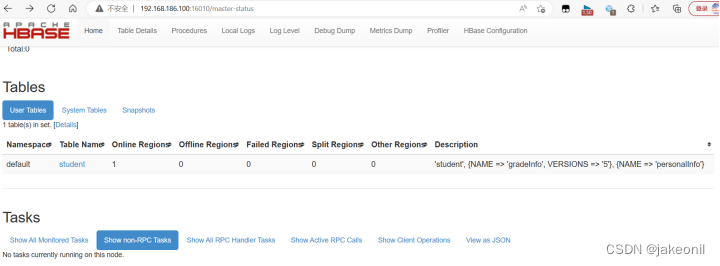
从HBase集群主节点的Web UI界面上查看student表
(3)使用命令“zkCli.sh -server master:2181,slave1:2181,slave2:2181”连接ZooKeeper客户端,从ZooKeeper的存储树中也可以查看到建立的student表,如图所示。
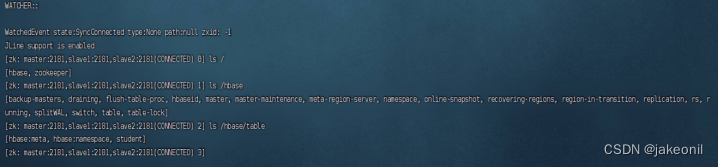
从ZooKeeper存储树中可查看到student表
(4)由于HBase底层存储采用HDFS,所以打开HDFS Web UI,也可以查看到建立的student表,如图所示。
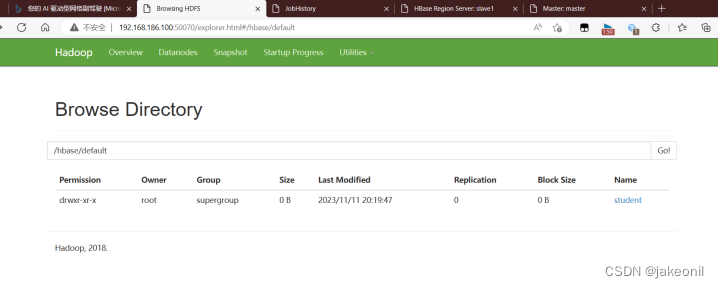
6****. ****关闭全分布模式HBase集群。
使用命令“stop-hbase.sh”
关闭HBase集群照本实验设置,关闭HBase集群后HBase主节点master上的主进程HMaster、HBase从节点slave1、slave2上的从进程HRegionServer消失,同时HBase主从节点上所有与HBase相关的ZooKeeper节点文件*.znode和进程号文件*.pid也依次消失。
实验结果与分析
1.集群启动: 通过Web UI、HBase Shell以及其他工具,确认HBase集群启动正常。
2.表的创建和管理: 通过HBase Shell和Web UI,查看已建立的表(例如,student表)。
3.数据写入和读取: 使用HBase Shell或API向表中写入数据,并通过不同方式进行读取,观察性能。
4.过滤器和Coprocessors: 使用过滤器检索数据,尝试使用Coprocessors进行数据处理,验证功能。
5.监控和性能调优: 使用HBase Web UI监测集群状态,观察各节点负载情况,进行性能调优。
6.故障模拟: 模拟节点故障,验证HBase的自动恢复机制,确保集群容错性。数据一致性: 观察数据写入和更新时的一致性,了解HBase的事务特性。
7.备份和恢复: 实验备份和恢复HBase表,确认在灾难性事件时能够迅速还原数据。
版权归原作者 jakeonil 所有, 如有侵权,请联系我们删除。