
1、FlinkCDC是什么
1.1 CDC是什么
CDC是Chanage Data Capture(数据变更捕获)的简称。其核心原理就是监测并捕获数据库的变动(例如增删改),将这些变更按照发生顺序捕获,将捕获到的数据,写入数据库种如神策数据的核心kudu、doris、mysql、kakfa等。
1.2 CDC的实现方式
1.2.1 基于查询的CDC
- 离线调度查询作业,批处理。把一张表同步到其他系统,每次通过查询去获取表中最新的数据
- 无法保障数据一致性,查的过程中有可能数据已经发生了多次变更;
- 不保障实时性,基于离线调度存在天然的延迟。
1.2.2 基于日志的CDC
- 实时消费日志,流处理,例如 MySQL 的 binlog 日志完整记录了数据库中的变更,可以把 binlog 文件当作流的数据源;
- 保障数据一致性,因为 binlog 文件包含了所有历史变更明细;
- 保障实时性,因为类似 binlog 的日志文件是可以流式消费的,提供的是实时数据。
1.2.3 常见的开源的CDC方案比较

1.2.4 个人对于CDC领域的一些浅见
其实对于CDC领域在数仓行业中很常见,无论是离线数仓也好还是实时数仓也好,或者说是业务系统也好,例如京东就是使用CDC方案来同步优惠卷的。其实在很多的CDC的同步方案中,大部分公司其实选用的是第一种,查询同步方案,为什么这么做呢,很多人可能会问,实时同步不好吗,我想说的是实时的CDC太复杂,虽然一致性不高,但是其实运营或者其他人员并不需要这么高的实时性,可能某些领域需要,当然也有很多的表结构设计没有update_time字段,这样的话如果同步一张表,可能会有点麻烦,但是并非是不能同步,如果数据量不大的话,或者有其他自增键的话会很方便,但是如果没有的话就会很麻烦,也可以做,可以做整行的md5这里我就不一一赘述了,在进行查询cdc同步的一些情况。日志cdc呢,其实根本原理就是监控类似于mysql的binlog。可以让整个数据的增删改,进行捕获,从而可以达到两个数据的一致性,当然这个一致性并不是实时的,哪怕是mysql的主从都有可能延迟,更别提咱们监控binlog了,当然这种延迟几乎很少见,业务也不会发现,这种CDC虽然听上去很好,但是实现较为困难,限制比较大,例如下游的数据源要支持改,不像离线可以用拉链表来解决。但是这种方式真的很好,如果开发人员和架构设计人员以及数据设计人员的设计比较好,这种方式效果是最棒的,我司的mysql同步器就支持这两种方式,根据使用人员的喜好来进行选择。
2、Flink CDC的原理
2.1 1.x Flink CDC
Flink1.x的cdc依赖于Debezium组件,debezium为了保证数据的一致性,在全量读取时,会加锁。
此时呢会分为全局锁权限和无全局锁权限。
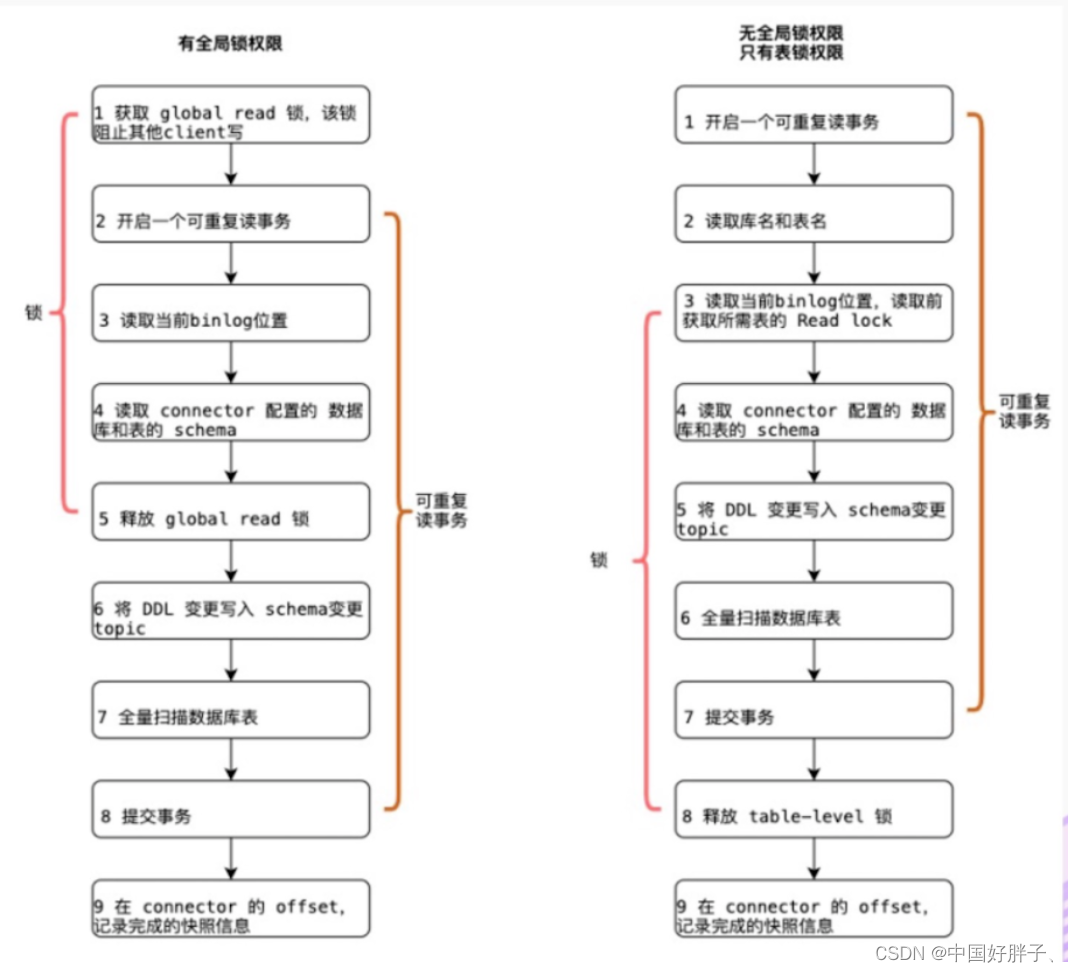 那么为什么debezium为什么要这么做呢,要加上全局锁呢,因为数据一致性问题,这就涉及到数据库的全局锁和表锁了,数据库的全局锁,以mysql为例,全局锁就是对整个数据库实例加锁。MySQL 提供了一个加全局读锁的方法,命令是Flush tables with read lock (FTWRL)。
那么为什么debezium为什么要这么做呢,要加上全局锁呢,因为数据一致性问题,这就涉及到数据库的全局锁和表锁了,数据库的全局锁,以mysql为例,全局锁就是对整个数据库实例加锁。MySQL 提供了一个加全局读锁的方法,命令是Flush tables with read lock (FTWRL)。
当你需要让整个库处于只读状态的时候,可以使用这个命令,之后其他线程的以下语句会被阻塞:数据更新语句(数据的增删改)、数据定义语句(包括建表、修改表结构等)和更新类事务的提交语句。一般全局锁的使用场景在数据库备份上,当然如果主库加锁的话,会导致一些问题。例如加锁后,这个数据库实例无法更新,业务基本就停止了。从库呢,也不能从binlog拉取数据,这就导致了主从延迟,假如有的业务使用的是从库的话就会出现问题。当然全局锁有问题,那么不加锁会导致什么问题呢,数据不一致问题:
比如手机卡,购买套餐信息
这里分为两张表 u_acount (用于余额表),u_pricing (资费套餐表)
步骤:
1. u_account 表中数据 用户A 余额:300
u_pricing 表中数据 用户A 套餐:空
2. 发起备份,备份过程中先备份u_account表,备份完了这个表,这个时候u_account 用户余额是300
3. 这个时候套用户购买了一个资费套餐100,餐购买完成,写入到u_print套餐表购买成功,备份期间的数据。
4. 备份完成
可以看到备份的结果是,u_account 表中的数据没有变, u_pricing 表中的数据 已近购买了资费套餐100.
哪这时候用这个备份文件来恢复数据的话,用户A 赚了100 ,用户是不是很舒服啊。但是你得想想公司利益啊。
也就是说,不加锁的话,备份系统备份的得到的库不是一个逻辑时间点,这个数据是逻辑不一致的。
当然mysql的备份工具,mysqldump可以在备份的时候支持更新,基于MVCC的机制。MVCC (Multiversion Concurrency Control),多版本并发控制。顾名思义,MVCC 是通过数据行的 多个版本 管理来实现数据库的 并发控制。这项技术使得在InnoDB的事务隔离级别下执行 一致性读操 作有了保证。换言之,就是为了查询一些正在被另一个事务更新的行,并且可以看到它们被更新之前的值,这样在做查询的时候就不用等待另一个事务释放锁。
不再深入解释mysql的核心机制了。
表锁是什么呢,顾名思义就是锁住了整张表。在加表锁的表上,无法进行DDL、DML操作。当然在mysql5.5以后,有一个表锁是MDL,MDL不需要显示的使用,在访问一个表的时候会被自动加上。MDL 的作用是,保证读写的正确性。你可以想象一下,如果一个查询正在遍历一个表中的数据,而执行期间另一个线程对这个表结构做变更,删了一列,那么查询线程拿到的结果跟表结构对不上,肯定是不行的。因此,在 MySQL 5.5 版本中引入了 MDL,当对一个表做增删改查操作的时候,加 MDL读锁;当要对表做结构变更操作的时候,加 MDL 写锁。
- 读锁之间不互斥,因此你可以有多个线程同时对一张表增删改查。
- 读写锁之间、写锁之间是互斥的,用来保证变更表结构操作的安全性。因此,如果有两个线程要同时给一个表加字段,其中一个要等另一个执行完才能开始执行。
MDL锁有一些问题,假如在多个读session中进行更改表结构操作的话,可能会卡死。
这个就是debezium在flink1.x中的应用。
2.2 2.x Flink CDC
Flink 2.x不仅引入了增量快照读取机制,还带来了一些其他功能的改进。以下是对Flink 2.x的主要功能的介绍:
增量快照读取:Flink 2.x引入了增量快照读取机制,这是一种全新的数据读取方式。该机制支持并发读取和以chunk为粒度进行checkpoint。在增量快照读取过程中,Flink首先根据表的主键将其划分为多个块(chunk),然后将这些块分配给多个读取器并行读取数据。这一机制极大地提高了数据读取的效率。
精确一次性处理:Flink 2.x引入了Exactly-Once语义,确保数据处理结果的精确一次性。MySQL CDC 连接器是Flink的Source连接器,可以利用Flink的checkpoint机制来确保精确一次性处理。
动态加表:Flink 2.x支持动态加表,通过使用savepoint来复用之前作业的状态,解决了动态加表的问题。
无主键表的处理:Flink 2.x对无主键表的读取和处理进行了优化。在无主键表中,Flink可以通过一些额外的字段来识别数据记录的唯一性,从而实现准确的数据读取和处理。
对于Flink 2.x的CDC方案呢,可以理解为全量读取时,在划分chunk块的时候,采用了查询读,他是将主键进行切分的。默认一个chunk8096条数据,知道这些就可以了。
2.x的 Flink cdc实现较为复杂,这里就不一一赘述了。
3、FlinkCDC的使用
3.1 导入依赖
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.75</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<!-- 可以将依赖打到jar包中 -->
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
3.2 代码实操
import com.ververica.cdc.connectors.mysql.MySqlSource;
import com.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.ververica.cdc.debezium.DebeziumSourceFunction;
import com.ververica.cdc.debezium.StringDebeziumDeserializationSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class FlinkCDC {
public static void main(String[] args) throws Exception {
//1.获取Flink执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//通过FlinkCDC构建SourceFunction
DebeziumSourceFunction<String> sourceFunction = MySqlSource.<String>builder()
.hostname("hadoop102")
.port(3306)
.username("root")
.password("123456")
.databaseList("cdc_test") //监控的数据库
.tableList("cdc_test.user_info") //监控的数据库下的表
.deserializer(new StringDebeziumDeserializationSchema())//反序列化
.startupOptions(StartupOptions.initial())
.build();
DataStreamSource<String> dataStreamSource = env.addSource(sourceFunction);
//3.数据打印
dataStreamSource.print();
//4.启动任务
env.execute("FlinkCDC");
}
}
4、Flink CDC输出数据解析
4.1 数据的数据结构
 flink cdc的输出结果大概可以分为 before、after、
flink cdc的输出结果大概可以分为 before、after、
before代表变更前数据,after代表变更后数据。
还有个op,这个op代表的是事务的操作:
r:读取历史
d:删除
c:创建
u:更新
版权归原作者 中国好胖子、 所有, 如有侵权,请联系我们删除。