
目录
基于Filebeat+Kafka+ELK实现Nginx日志收集
1.规划好项目架构图

2.部署前端web集群
先准备3台Nginx服务器,用做后端服务器,(由于机器有限,也直接用这三台机器来部署ES集群),然后准备2台服务器做负载均衡器(Nginx实现负载均衡具体实现操作有机会在介绍),如果是简单学习测试,可以先使用3台Nginx服务器就可以,先告一段落。
3台Nginx服务器备注:
服务器IP地址安装软件elk-node1192.168.40.150elasticsearch、filebeat、logstash、kibana、nginxelk-node2192.168.40.137elasticsearch、filebeat、logstash、nginxelk-node3192.168.40.138elasticsearch、filebeat、logstash、nginx
安装nginx提供了一个脚本,可以直接运行这个脚本实现安装
#!/bin/bash
yum -y installwget zlib zlib-devel openssl openssl-devel pcre pcre-devel gcc gcc-c++ autoconf automake make#创建 nginx文件夹mkdir -p /nginx
cd /nginx
#解压 下载的nginx的源码包wget http://nginx.org/download/nginx-1.23.4.tar.gz
tar xf nginx-1.23.4.tar.gz
cd nginx-1.23.4
#生成编译前配置工作-->Makefile,指定存放nginx1文件路径,安装相应的模块
./configure --prefix=/usr/local/nginx1 --with-threads --with-http_ssl_module --with-http_stub_status_module --with-stream
#编译make#编译安装-->将编译好的二进制程序安装指定目录/usr/local/nginx1makeinstall
其它的软件安装过程都可以看我的博客 传送门
3.部署ES集群
集群介绍
这里介绍集群部署和一些简单的概念,更详细的内容可以查看我的这篇文章 ElasticSearch集群8.0版本搭建、故障转移
环境准备
服务器IP地址安装软件elk-node1192.168.40.150Elasticsearchelk-node2192.168.40.137Elasticsearchelk-node3192.168.40.138Elasticsearch
所有以下配置需要在配置文件中保持唯一,如果有重复的,则会报错
集群搭建
#启动3个虚拟机,分别在3台虚拟机上部署安装Elasticsearchmkdir -p /opt/elk
#将之前单机安装的elasearch分发到其它机器scp -r elsearch/ [email protected]:/opt/elk/
scp -r elsearch/ [email protected]:/opt/elk/
#node01的配置==>192.168.40.150
cluster.name: es-cluster
node.name: node01
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["192.168.40.137","192.168.40.138","192.168.40.150"]
cluster.initial_master_nodes: ["node01", "node02", "node03"]# 最小节点数
node.roles: [master,data]# 跨域专用
http.cors.enabled: true
http.cors.allow-origin: "*"#node02的配置:
cluster.name: es-cluster
node.name: node02
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["192.168.40.137","192.168.40.138","192.168.40.150"]
cluster.initial_master_nodes: ["node01", "node02", "node03"]# 最小节点数
node.roles: [master,data]#node03的配置:
cluster.name: es-cluster
node.name: node03
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["192.168.40.137","192.168.40.138","192.168.40.150"]
cluster.initial_master_nodes: ["node01", "node02", "node03"]# 最小节点数
node.roles: [master,data]#分别启动3个节点
./elasticsearch -d
查看集群
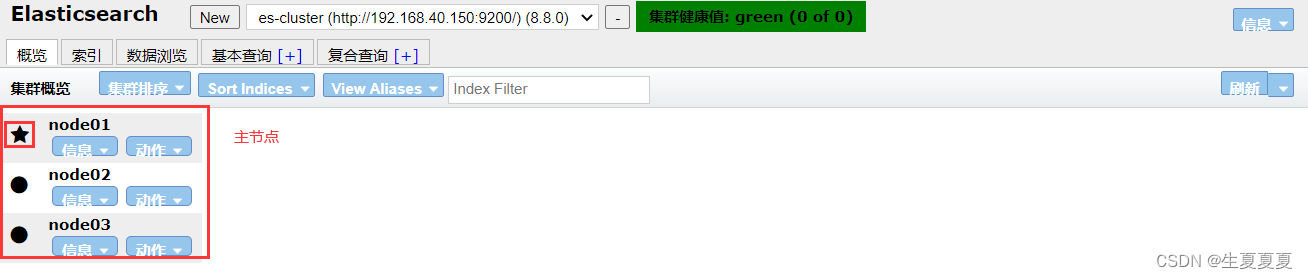
创建一个索引,其中加粗的为主分片,其余为副本分片
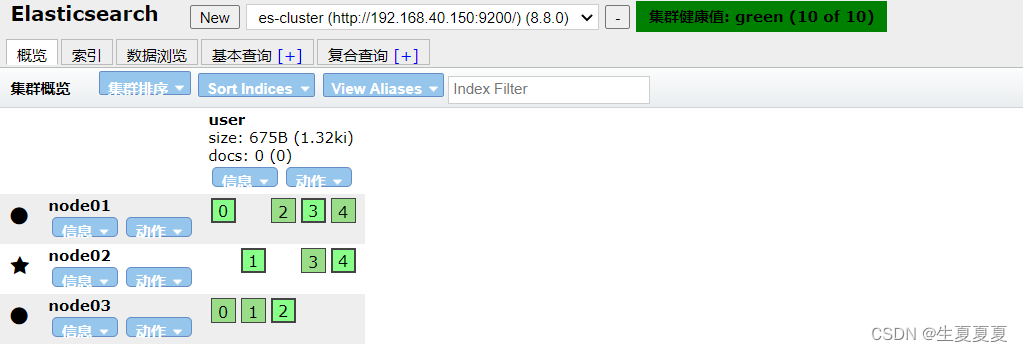
查询集群状态:/_cluster/health
响应如下:
分片和副本
为了将数据添加到Elasticsearch,我们需要索引(index)——一个存储关联数据的地方。实际上,索引只是一个用来指向一个或多个分片(shards)的“逻辑命名空间(logical namespace)”.
- 一个分片(shard)是一个最小级别“工作单元(worker unit)”,它只是保存了索引中所有数据的一部分。
- 我们需要知道是分片就是一个Lucene实例,并且它本身就是一个完整的搜索引擎。应用程序不会和它直接通 信。
- 分片可以是主分片(primary shard)或者是复制分片(replica shard)。
- 索引中的每个文档属于一个单独的主分片,所以主分片的数量决定了索引最多能存储多少数据。
- 复制分片只是主分片的一个副本,它可以防止硬件故障导致的数据丢失,同时可以提供读请求,比如搜索或者从别的shard取回文档。
- 当索引创建完成的时候,主分片的数量就固定了,但是复制分片的数量可以随时调整。
4.部署kafka集群
环境准备
服务器说明IP地址安装软件nginx-kafka1192.168.40.170Kafka、Zookeeper、javanginx-kafka2192.168.40.171Kafka、Zookeeper、javanginx-kafka3192.168.40.172Kafka、Zookeeper、java
静态IP配置
nginx-kafka1
进入/etc/sysconfig/network-scripts/目录下,vim ifcfg-ens33文件
BOOTPROTO="none"DEFROUTE="yes"NAME="ens33"DEVICE="ens33"ONBOOT="yes"IPADDR=192.168.40.170
PREFIX=24GATEWAY=192.168.40.2
DNS1=192.168.40.2
nginx-kafka2
BOOTPROTO="none"DEFROUTE="yes"NAME="ens33"DEVICE="ens33"ONBOOT="yes"IPADDR=192.168.40.171
PREFIX="24"GATEWAY=192.168.40.2
DNS1=192.168.40.2
nginx-kafka3
BOOTPROTO="none"DEFROUTE="yes"NAME="ens33"DEVICE="ens33"ONBOOT="yes"IPADDR=192.168.40.172
PREFIX=24GATEWAY=192.168.40.2
DNS1=192.168.40.2
重启网络服务
3台服务器都要重启网络服务,然后使用ping测试网络通信是否正常,如果可以相互ping通,则能通信
service network restart
域名解析设置
3台服务器都要设置域名解析
nginx-kafka1
root@nginx-kafaka1 ~]# cat /etc/hosts127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
#添加对应的域名解析192.168.40.170 nginx-kafka1
192.168.40.171 nginx-kafka2
192.168.40.172 nginx-kafka3
nginx-kafka2
root@nginx-kafaka2 ~]# cat /etc/hosts127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
#添加对应的域名解析192.168.40.170 nginx-kafka1
192.168.40.171 nginx-kafka2
192.168.40.172 nginx-kafka3
nginx-kafka3
root@nginx-kafaka3 ~]# cat /etc/hosts127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
#添加对应的域名解析192.168.40.170 nginx-kafka1
192.168.40.171 nginx-kafka2
192.168.40.172 nginx-kafka3
安装时间同步服务
安装
yum install chrony -y
设置启动
systemctl enable chronyd
ststemctl start chronyd
设置时区
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
关闭防火墙和selinux
防火墙关闭
systemctl enable chronyd
ststemctl start chronyd
selinux关闭
vim /etc/selinux/config
SELINUX=disabled
kafka集群依赖于zookeeper
Kafka集群依赖于Zookeeper主要是为了实现
分布式协调和管理
。Zookeeper是一个
分布式协调服务
,可以提供高可用的数据存储和访问服务。在Kafka集群中,Zookeeper主要用于以下几个方面:
Broker注册和发现:Kafka集群中的每个Broker都会在Zookeeper中注册自己的信息,包括Broker的ID、主机名和端口等。通过Zookeeper,客户端可以发现Kafka集群中的所有Broker,并且可以动态地感知Broker的变化。Topic和Partition管理:Kafka中的Topic和Partition信息也会存储在Zookeeper中。当有新的Topic或Partition被创建时,Kafka会将这些信息写入Zookeeper中,同时在Broker上创建对应的Topic和Partition。当Topic或Partition被删除时,Kafka也会从Zookeeper中删除对应的信息。Controller选举:在Kafka集群中,每个Partition都有一个Leader和多个Follower。Leader负责处理读写请求,Follower则负责同步Leader的数据。Kafka通过Zookeeper实现了Controller选举机制,当某个Broker宕机或不可用时,Zookeeper会重新选举一个新的Controller,负责管理集群中的Partition和Replica。因此,Zookeeper是Kafka集群中非常重要的组件,它可以提供高可用性、一致性和可靠性的服务,保证Kafka集群的正常运行。
不过kafka3.0以上版本zookeeper可以不再被需要,相关的集群元数据信息以 kafka 日志的形式存在
kafaka和zookeeper准备
kafaka下载: 传送门
zookeeper下载: 传送门
由于kafka和zookeeper都是用Java编写的,安装一下jdk,3台都要安装
yum install java -y
kafka配置
上传到三台机器的/opt目录下
nginx-kafka1已经上传,使用scp传送到其它服务器
[root@nginx-kafka1 opt]# ls
apache-zookeeper-3.8.1-bin.tar.gz kafka_2.13-3.5.0.tgz
[root@nginx-kafka1 opt]# scp apache-zookeeper-3.8.1-bin.tar.gz kafka_2.13-3.5.0.tgz [email protected]:/opt/ [root@nginx-kafka1 opt]# scp apache-zookeeper-3.8.1-bin.tar.gz kafka_2.13-3.5.0.tgz [email protected]:/opt/
解压
tar xf kafka_2.13-3.5.0.tgz
配置唯一的broker id
broker id 其实就是kafaka集群的一个节点,为了表示集群中不同的节点,将broker.id设置为一个整数值进行标识,建议按顺序设置,进入kafaka配置目录
[root@nginx-kafka1 config]# vim server.properties [root@nginx-kafka1 config]# pwd
/opt/kafka_2.13-3.5.0/config
broker.id=1
[root@nginx-kafka2 config]# vim server.properties [root@nginx-kafka2 config]# pwd
/opt/kafka_2.13-3.5.0/config
broker.id=2
[root@nginx-kafka3 config]# vim server.properties [root@nginx-kafka3 config]# pwd
/opt/kafka_2.13-3.5.0/config
修改监听的主机名和端口
在 ZooKeeper 集群中,配置
listeners
参数是为了让 ZooKeeper 能够与外部的客户端进行通信。
例如:
PLAINTEXT://nginx-kafka1:9092
是 Kafka 的监听地址,它告诉 ZooKeeper 监听来自该地址的客户端请求(这也就是为什么要设置域名解析)。这个地址包含了协议、主机名和端口号,其中
PLAINTEXT
是 Kafka 的一种传输协议,
nginx-kafka1
是 Kafka 的主机名,
9092
是 Kafka 的默认端口号。通过配置
listeners
参数,ZooKeeper 就可以与 Kafka 集群中的其他组件进行通信,比如消费者或生产者。
[root@nginx-kafka1 config]# vim server.propertieslisteners=PLAINTEXT://nginx-kafka1:9092
[root@nginx-kafka2 config]# vim server.properties listeners=PLAINTEXT://nginx-kafka2:9092
[root@nginx-kafka3 config]# vim server.properties listeners=PLAINTEXT://nginx-kafka3:9092
修改日志存放目录和默认的分区数量
vim server.properties
# 三台机器都配置
log.dirs=/data
num.partitions=3
配置zookeeper连接
vim server.properties
# 三台机器都配置
zookeeper.connect=192.168.40.170:2181,192.168.40.171:2181,192.168.40.172:2181
zookeeper配置
进入kafka配置目录
[root@nginx-kafka1 ~]# cd /opt/kafka_2.13-3.5.0/config/
修改配置文件,3台机器都要操作,其中
- server.1、server.2、server.3指的是服务器节点的 ID,这个 ID 必须是唯一的且在集群中必须按顺序递增
- 192.168.40.17*:3888:4888表示这个节点的主机名或 IP 地址和端口号。其中,“3888”是用于 follower 之间通信的端口号,“4888”是用于选举 leader 的端口号。这两个端口号都是 ZooKeeper 集群中的节点之间进行通信的重要端口号。
[root@nginx-kafka1 config]# vim zookeeper.properties [root@nginx-kafka1 config]# cat zookeeper.properties |grep -Ev "^$|^#"dataDir=/tmp/zookeeper
clientPort=2181maxClientCnxns=0
admin.enableServer=false
server.1=192.168.40.170:3888:4888
server.2=192.168.40.171:3888:4888
server.3=192.168.40.172:3888:4888
在刚才的配置文件中,可以看到存放数据的目录为
/tmp/zookeeper
,但该目录是不存在的,创建该目录
mkdir -p /tmp/zookeeper
然后创建一个
myid
的文件,进行Zookeeper id 宣告,宣告的id要和之前写入zoo.cfg文件内容的id对应,通过执行这个命令,为每一个 ZooKeeper 服务器节点分配 id。
nginx-kafka1
[root@nginx-kafka1 conf]# echo 1 >/tmp/zookeeper/myid
nginx-kafka2
[root@nginx-kafka2 conf]# echo 2 >/tmp/zookeeper/myid
nginx-kafka3
[root@nginx-kafka3 conf]# echo 3 >/tmp/zookeeper/myid
启动
先启动zookeeper,然后在启动kafka
修改一下PATH环境变量吧
PATH=/opt/apache-zookeeper-3.8.1-bin/bin:$PATH# 可以将其写入/root/.bashrc文件,然后刷新source /root/.bashrc
启动zookeeper服务端
[root@nginx-kafka1 apache-zookeeper-3.8.1-bin]# cd bin/[root@nginx-kafka1 bin]# ./zkServer.sh start
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /opt/apache-zookeeper-3.8.1-bin/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@nginx-kafka2 bin]# ./zkServer.sh start
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /opt/apache-zookeeper-3.8.1-bin/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@nginx-kafka3 bin]# ./zkServer.sh start
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /opt/apache-zookeeper-3.8.1-bin/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
查看状态
zkServer.sh status
如果看到有一个leader,两个follower则zookeeper启动成功
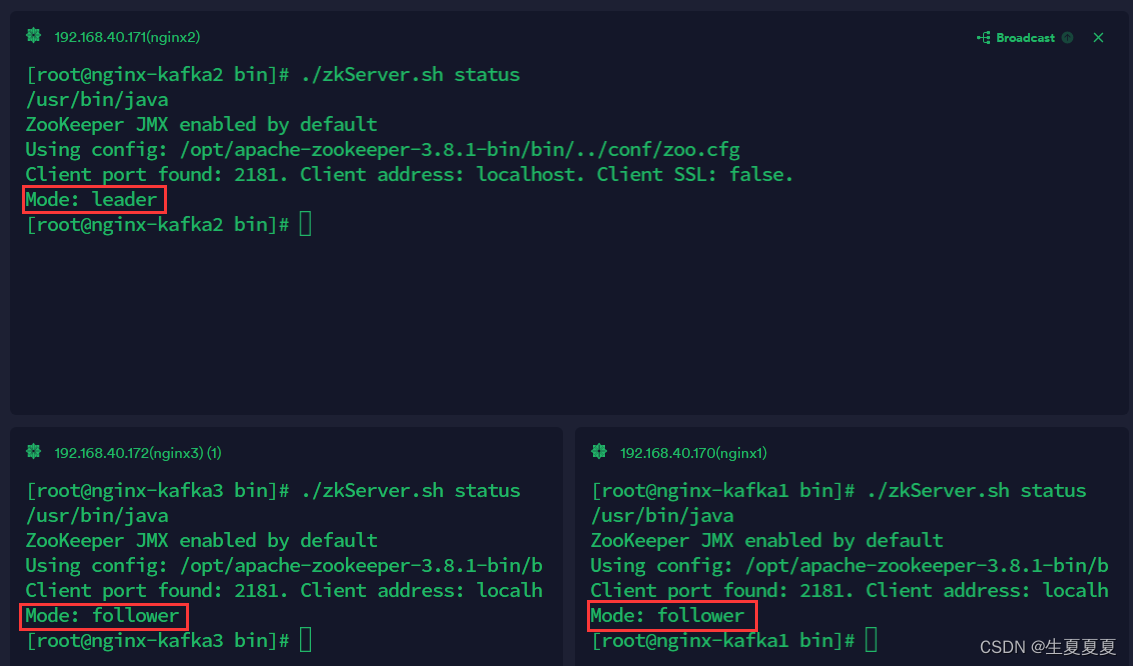
启动kafaka
[root@nginx-kafka1 kafka_2.13-3.5.0]# ./bin/kafka-server-start.sh -daemon ./config/server.properties
[root@nginx-kafka2 kafka_2.13-3.5.0]# ./bin/kafka-server-start.sh -daemon ./config/server.properties
[root@nginx-kafka3 kafka_2.13-3.5.0]# ./bin/kafka-server-start.sh -daemon ./config/server.properties
启动zookeeper客户端查看kafka是否启动成功
[root@nginx-kafka1 bin]# ./zkCli.sh
启动之后,执行如下命令
[zk: localhost:2181(CONNECTED)0]ls /brokers/ids
[1, 2, 3]
它会显示zookeeper中/brokers/ids节点下的子节点列表。该节点下有三个子节点,分别是1、2和3。在Kafka中,这些子节点表示Kafka集群中不同的broker节点。每个broker节点都有一个唯一的ID,这些ID就是/brokers/ids节点下的子节点。
测试
创建一个topic
bin/kafka-topics.sh --create --bootstrap-server 192.168.40.171:9092 --replication-factor 1 --partitions 1 --topic test
如果看到topics中有test这个主题的话,则成功
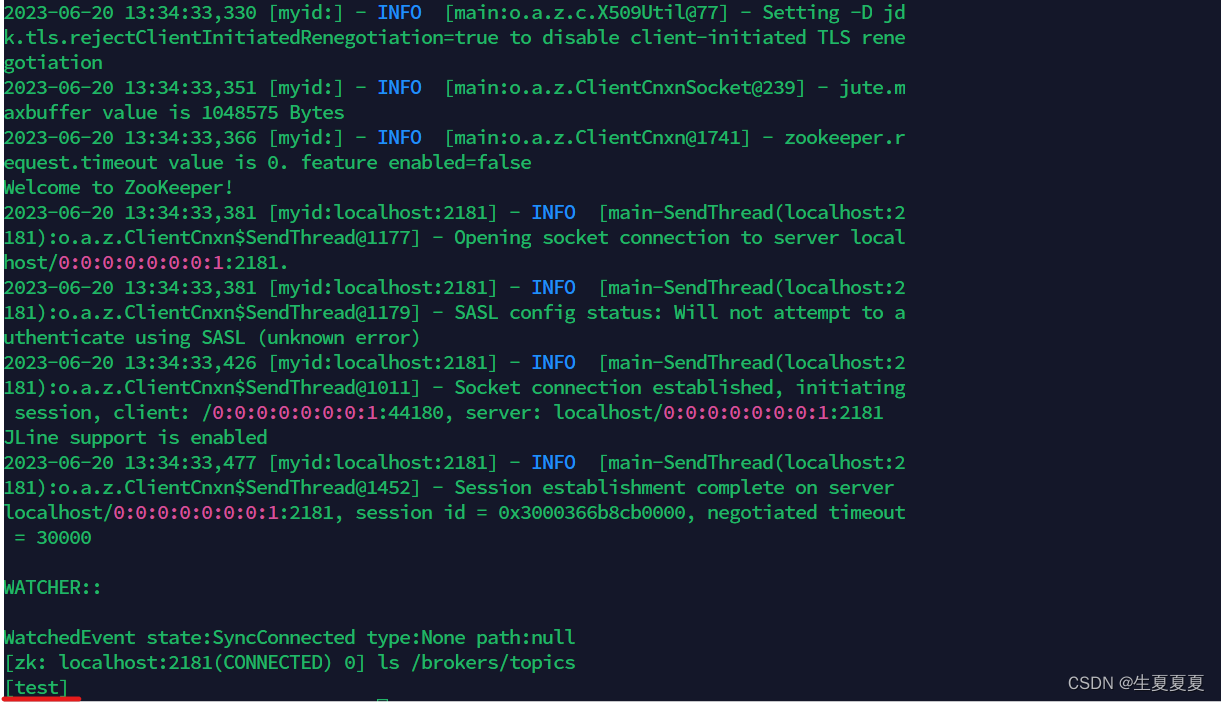
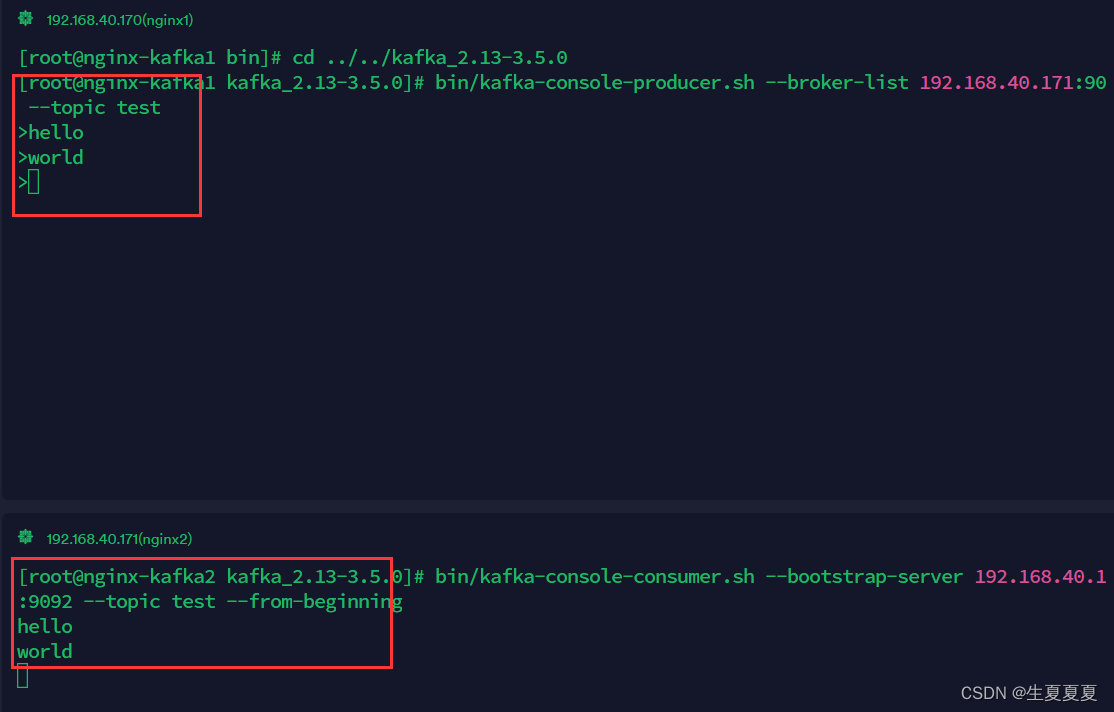
在test主题下创建生产者,往kafaka里写入数据
[root@nginx-kafka1 kafka_2.13-3.5.0]# bin/kafka-console-producer.sh --broker-list 192.168.40.171:9092 --topic test
从kafaka读取数据
[root@nginx-kafka2 kafka_2.13-3.5.0]# bin/kafka-console-consumer.sh --bootstrap-server 192.168.40.171:9092 --topic test --from-beginning
效果如下
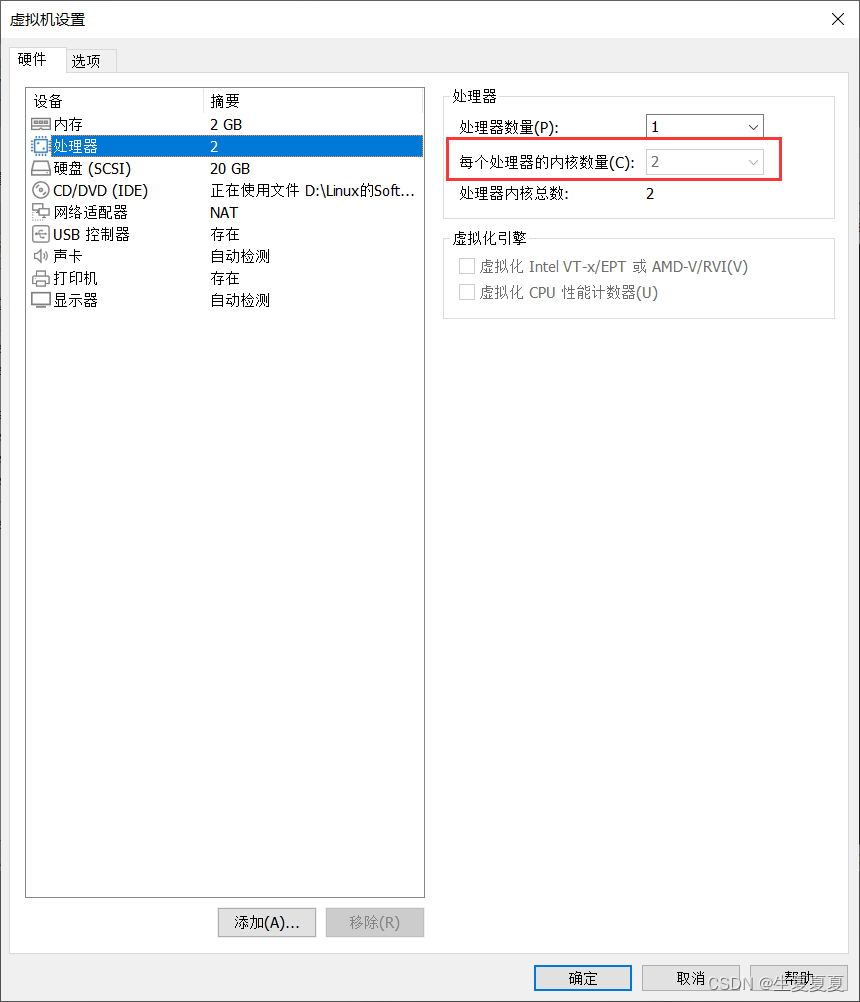
插一段:启动kafaka的时候有个提示
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
编辑虚拟机设置,将内核设置为2核,就不会报错了
5.使用filebeat获取nginx日志数据
filebeat进行日志收集测试kafka集群
filebeat的下载可以看我之前写的文章 Filebeat详细介绍,下载和启动,日志读取和模块设置等
配置
下载好之后,进入filebeat目录,将该目录下的filebeat.yml文件备份一遍
# 备份[root@nginx-kafka1 filebeat]# cp filebeat.yml filebeat.yml.bak# 清空原来的filebeat.yml文件[root@nginx-kafka1 filebeat]# >filebeat.yml# 编写filebeat.yml文件[root@nginx-kafka1 filebeat]# cat filebeat.yml
filebeat.inputs:
- type: log # 输入类型为日志类型
enabled: true
paths: # 存放日志的路径
- /var/log/nginx/shengxia/*.log
setup.template.settings:
index.number_of_shards: 3# 分片数量#------------------------------kafaka-------------------------# 将采集的日志输入的kafaka中
output.kafka:
hosts: ["192.168.40.170:9092","192.168.40.171:9092","192.168.40.172:9092"]#kafka集群所在的IP地址
topic: nginxlog # 主题
keep_alive: 10s
启动filebeat服务
[root@nginx-kafka1 filebeat]# nohup ./filebeat -e -c filebeat.yml &
测试
在kafka中创建名为nginxlog的主题
[root@nginx-kafka2 kafka_2.13-3.5.0]# bin/kafka-topics.sh --create --bootstrap-server 192.168.40.171:9092 --replication-factor 1 --partitions 1 --topic nginxlog
消费者查看是否采集到数据
[root@nginx-kafka2 kafka_2.13-3.5.0]# bin/kafka-console-consumer.sh --bootstrap-server 192.168.40.171:9092 --topic nginxlog --from-beginning
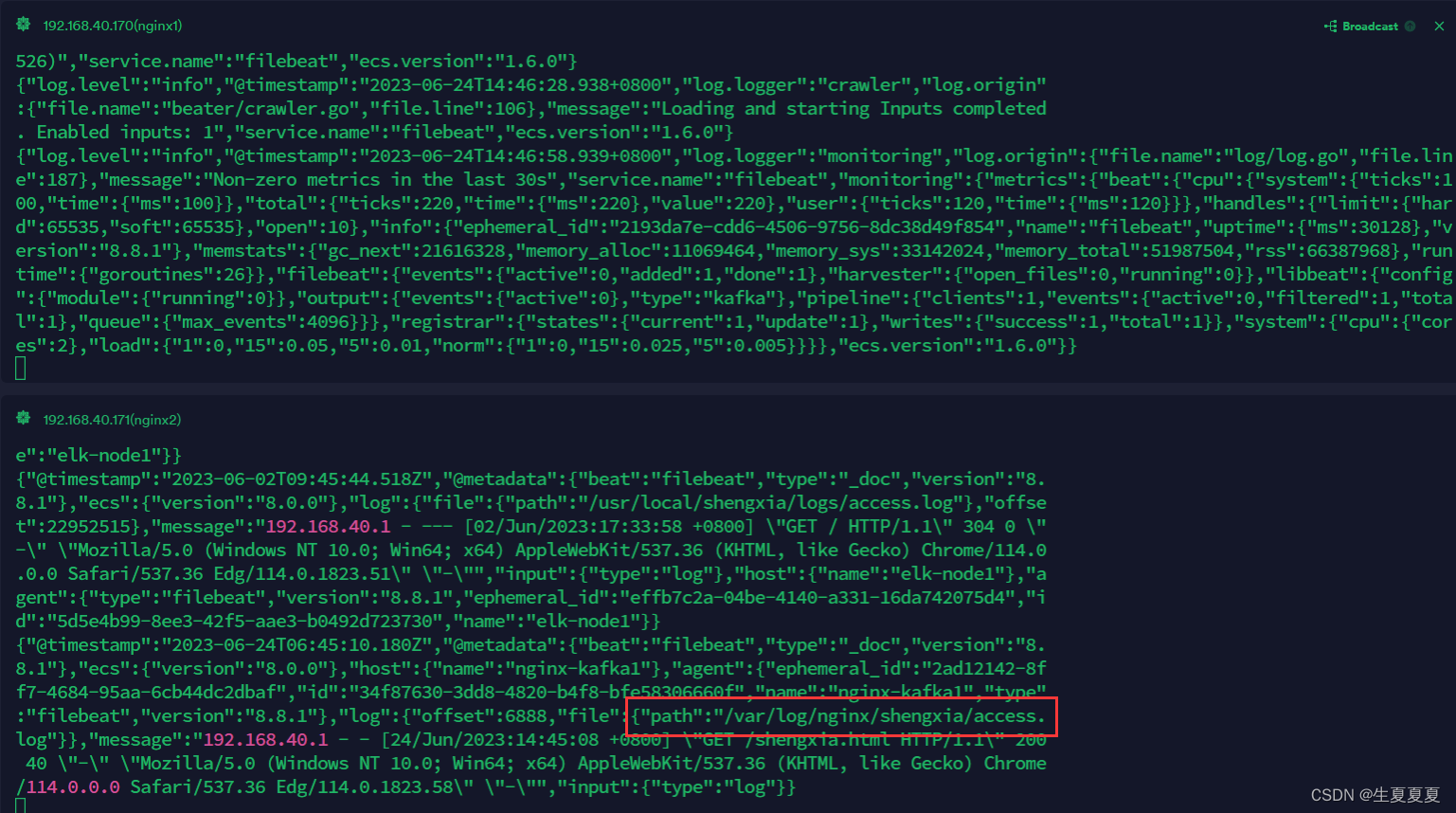
6.在ES集群中都部署filebeat,然后将收集的日志输出到ES集群和kafka集群查看
ES上的filebeat
filebeat.yml文件---->输出到ES集群
输出到ES集群的目的是为了测试ES集群是否能够顺利的获取filebeat采集的日志,如果觉得能成功,这一步可以不需要操作
filebeat.inputs:-type: log
enabled:truepaths:# 日志存放目录,根据自己存放日志目录修改- /usr/local/shengxia/logs/*.logsetup.template.settings:index.number_of_shards:3# 分片数量#将采集的日志收入elasticsearchoutput.elasticsearch:hosts:["192.168.40.150:9200","192.168.40.137:9200","192.168.40.138:9200"]
filebeat都放在后台运行
[root@elk-node1 filebeat]# nohup ./filebeat -e -c filebeat.yml &[1]112019[root@elk-node1 filebeat]# nohup: 忽略输入并把输出追加到"nohup.out
[root@elk-node2 filebeat]# nohup ./filebeat -e -c filebeat.yml &[1]112019[root@elk-node2 filebeat]# nohup: 忽略输入并把输出追加到"nohup.out
[root@elk-node3 filebeat]# nohup ./filebeat -e -c filebeat.yml &[1]112019[root@elk-node3 filebeat]# nohup: 忽略输入并把输出追加到"nohup.out
elasticsearch收集日志成功
elk-node1的日志收集
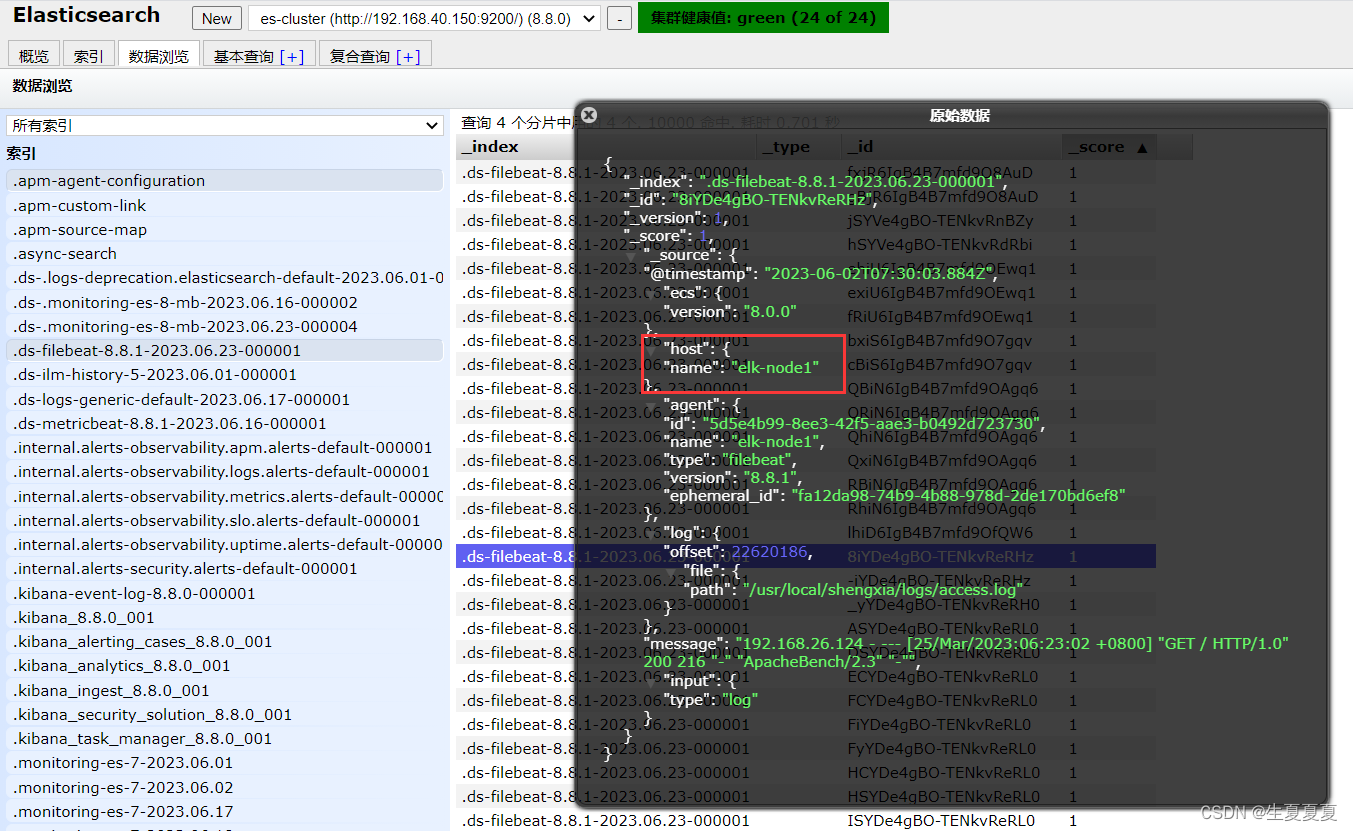
elk-node2的日志收集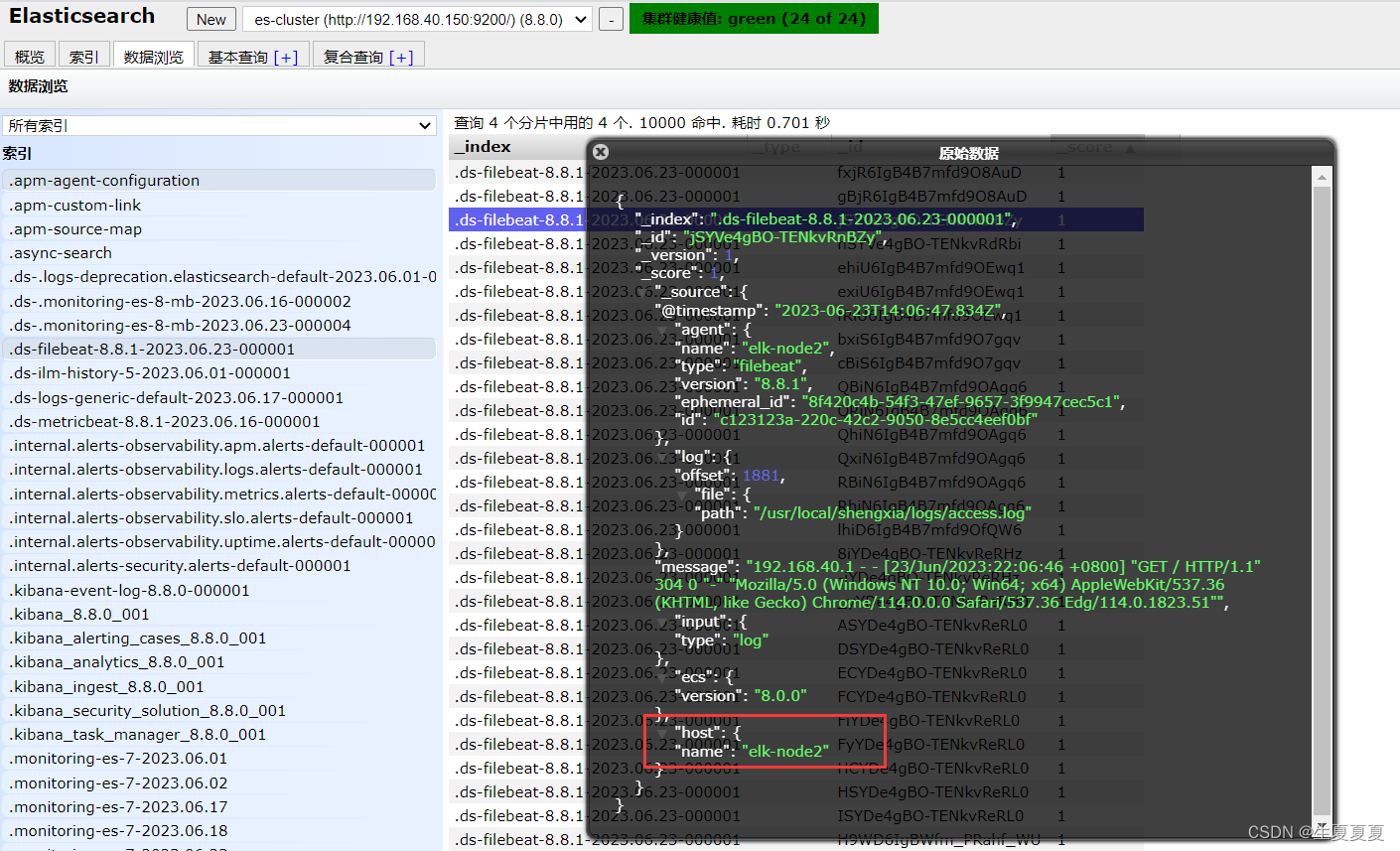
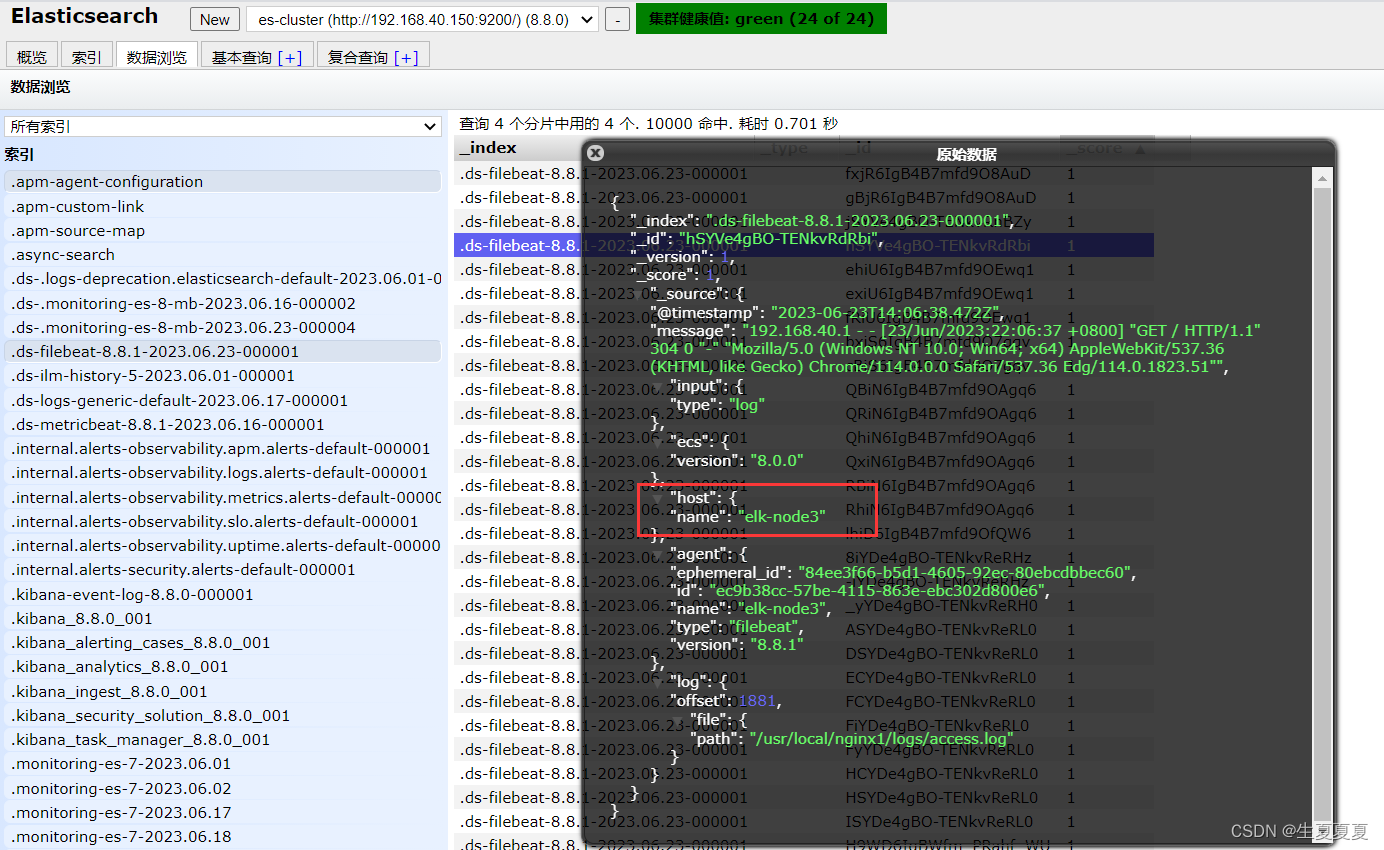
elk-node3的日志收集
filebeat.yml文件---->输出到kafka集群
3台服务器配置filebeat.yml文件,获取nginx日志数据
elk-node1
filebeat.inputs:-type: log
enabled:truepaths:# 日志存放目录- /usr/local/shengxia/logs/*.logsetup.template.settings:index.number_of_shards:3# 分片数量#------------------------------kafaka-------------------------## 将采集的日志输入的kafaka中output.kafka:hosts:["192.168.40.170:9092","192.168.40.171:9092","192.168.40.172:9092"]enabled:truetopic: nginxlog
keep_alive: 10s
elk-node2
filebeat.inputs:-type: log
enabled:truepaths:# 日志存放目录- /usr/local/shengxia/logs/*.logsetup.template.settings:index.number_of_shards:3# 分片数量#------------------------------kafaka-------------------------## 将采集的日志输入的kafaka中output.kafka:hosts:["192.168.40.170:9092","192.168.40.171:9092","192.168.40.172:9092"]enabled:truetopic: nginxlog
keep_alive: 10s
elk-node3
filebeat.inputs:-type: log
enabled:truepaths:# 日志存放目录- /usr/local/nginx1/logs/*.logsetup.template.settings:index.number_of_shards:3# 分片数量#------------------------------kafaka-------------------------## 将采集的日志输入的kafaka中output.kafka:hosts:["192.168.40.170:9092","192.168.40.171:9092","192.168.40.172:9092"]topic: nginxlog
keep_alive: 10s
同时,装有三台nginx服务器的机器要配置域名解析,原因如蓝色部分字体所示
192.168.40.170 nginx-kafka1
192.168.40.171 nginx-kafka2
192.168.40.172 nginx-kafka3
可能存在的问题:
filebeat抓取nginx日志传送到kafka没有接收,可能的原因是没有在安装filebeat所在的机器设置域名解析,因为配置kafka的server.properties中的listeners是通过域名配置的,所以需要设置域名解析。
启动kafka消费者
[root@nginx-kafaka2 kafka_2.13-3.5.0]# ./bin/kafka-console-consumer.sh --bootstrap-server 192.168.40.171:9092 --topic nginxlog --from-beginning
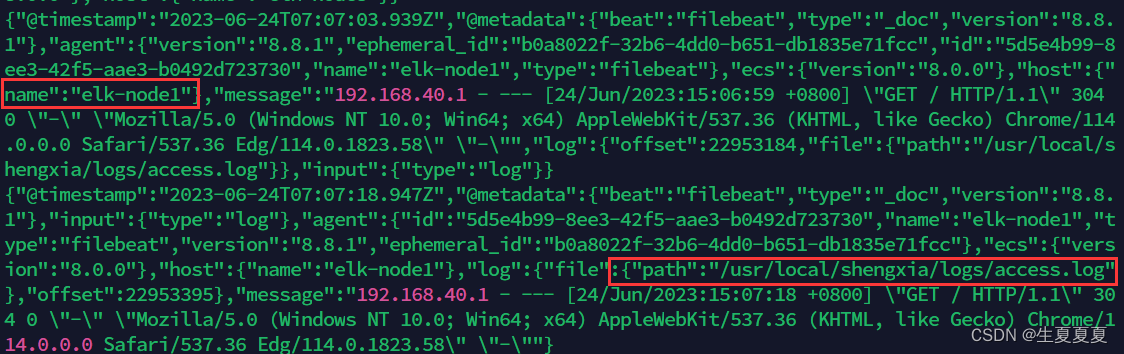
elk-node1的日志输入到kafka中
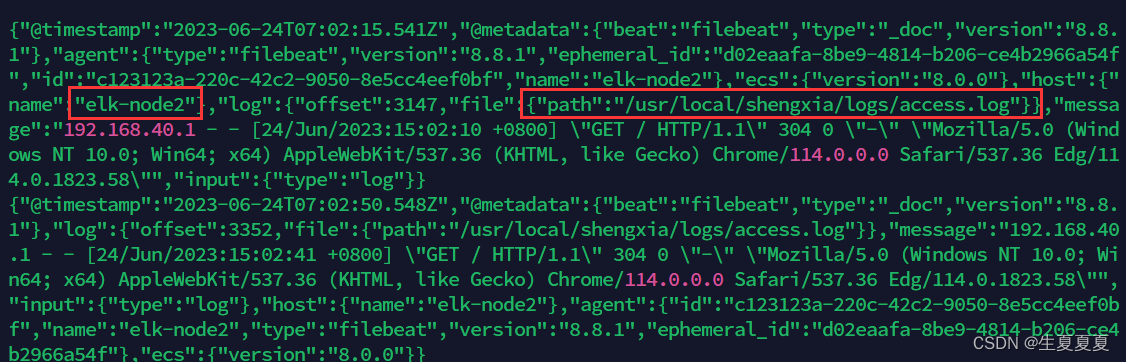
elk-node2的日志输入到kafka
elk-node3的日志输入到kafka中
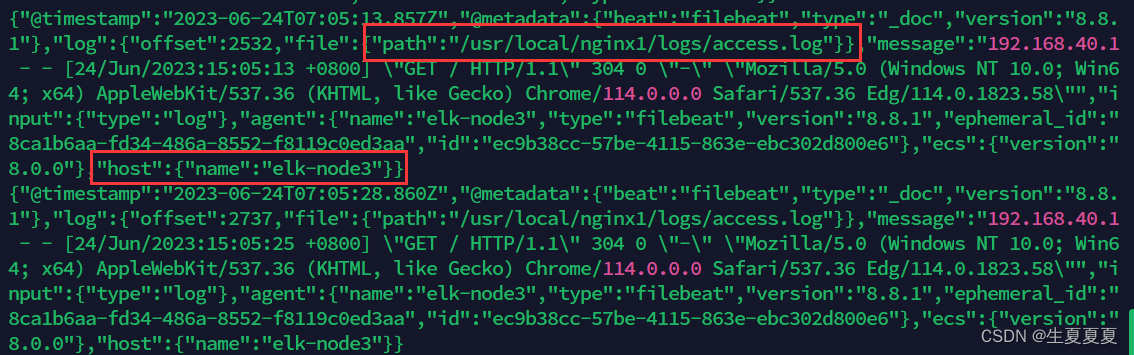
这三台nginx服务器的日志就都收集到kafka中,接下来使用logstash进行数据过滤
7.使用logstash进行数据过滤
先使用es这个用户启动es集群
[es@elk-node1 bin]$ pwd
/opt/elk/elsearch/bin
[es@elk-node1 bin]$ ./elasticsearch -d
[es@elk-node2 bin]$ pwd
/opt/elk/elsearch/bin
[es@elk-node2 bin]$ ./elasticsearch -d
[es@elk-node3 bin]$ pwd
/opt/elk/elsearch/bin
[es@elk-node3 bin]$ ./elasticsearch -d
logstash从kafka中获取数据到es,并将日志进行转化
[root@elk-node3 logstash]# pwd
/opt/elk/logstash
[root@elk-node3 logstash]# nohup ./bin/logstash -f nginx-logstash.conf &
nginx-logstash.conf文件
input {
kafka {
bootstrap_servers => "192.168.40.170:9092" # kafka服务器的IP地址
topics =>["nginxlog"]# 消费主题
auto_offset_reset => "latest"
codec => "json"
}}
filter {
grok {# 使用grok模式解析nginx字段
match =>{ "message" => "%{IPORHOST:clientip} %{USER:ident} %{USER:auth} \[%{HTTPDATE:timestamp}\] \"%{WORD:verb} %{URIPATHPARAM:request} HTTP/%{NUMBER:httpversion}\" %{NUMBER:response} %{NUMBER:bytes} \"%{DATA:referrer}\" \"%{DATA:agent}\"" }}
date {
match =>["timestamp","dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
}
mutate {
convert =>{
"response_code" => "integer"
"response_time" => "float"
}}}
output {
elasticsearch {
hosts =>["192.168.40.150:9200"]#elasticsearch服务器所在IP地址
index => "nginx-logs-%{+YYYY.MM.dd}" # 索引}}
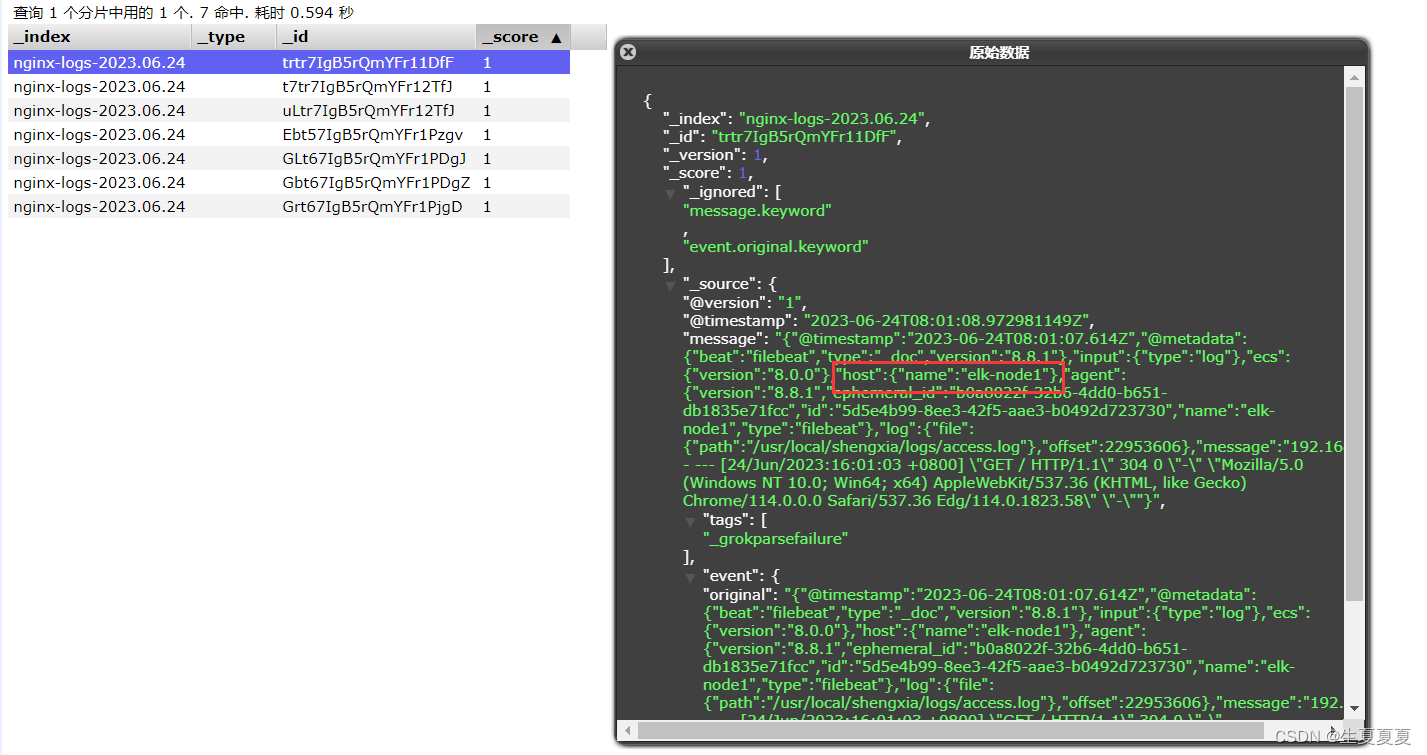
elk-node1的日志写入成功
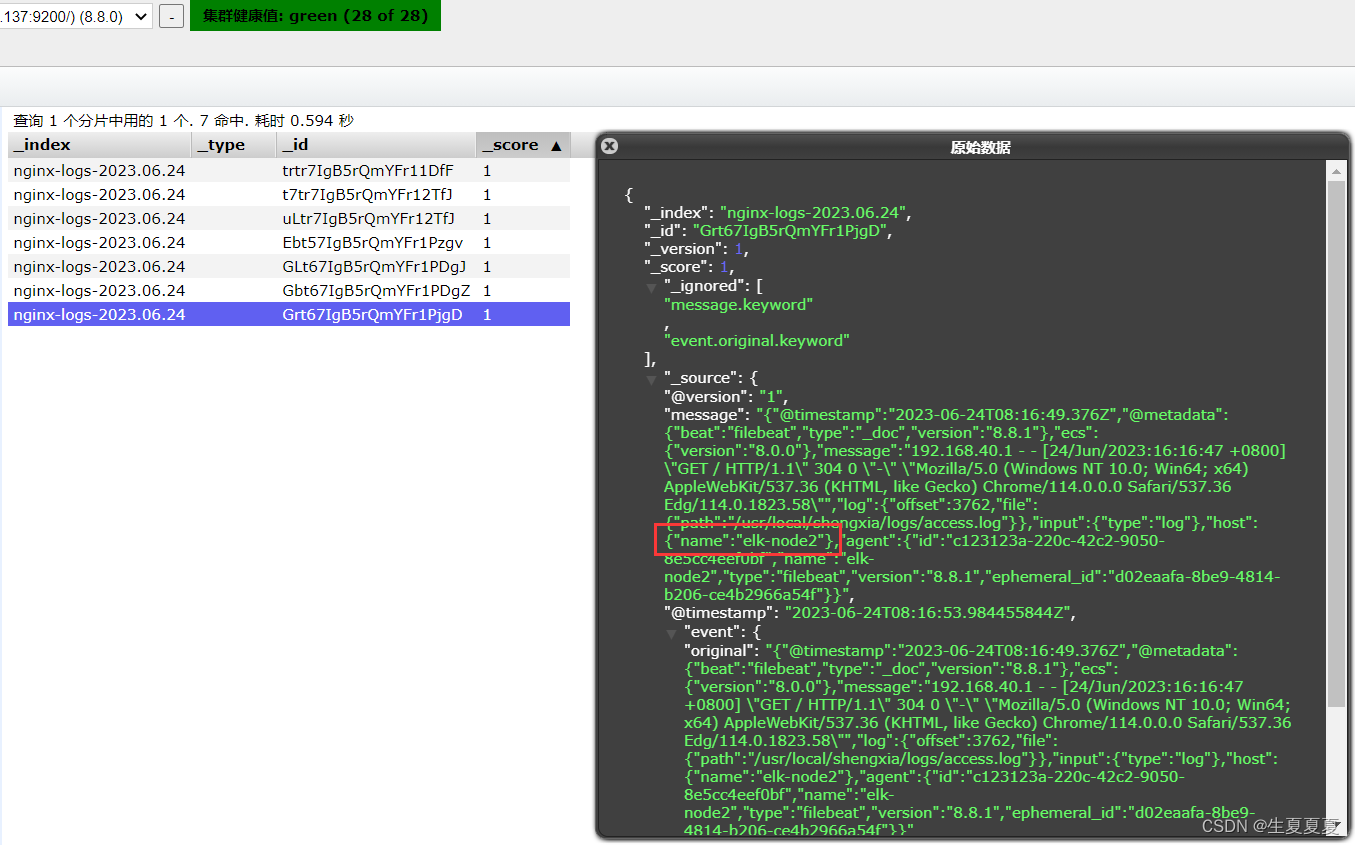
elk-node2的日志写入成功
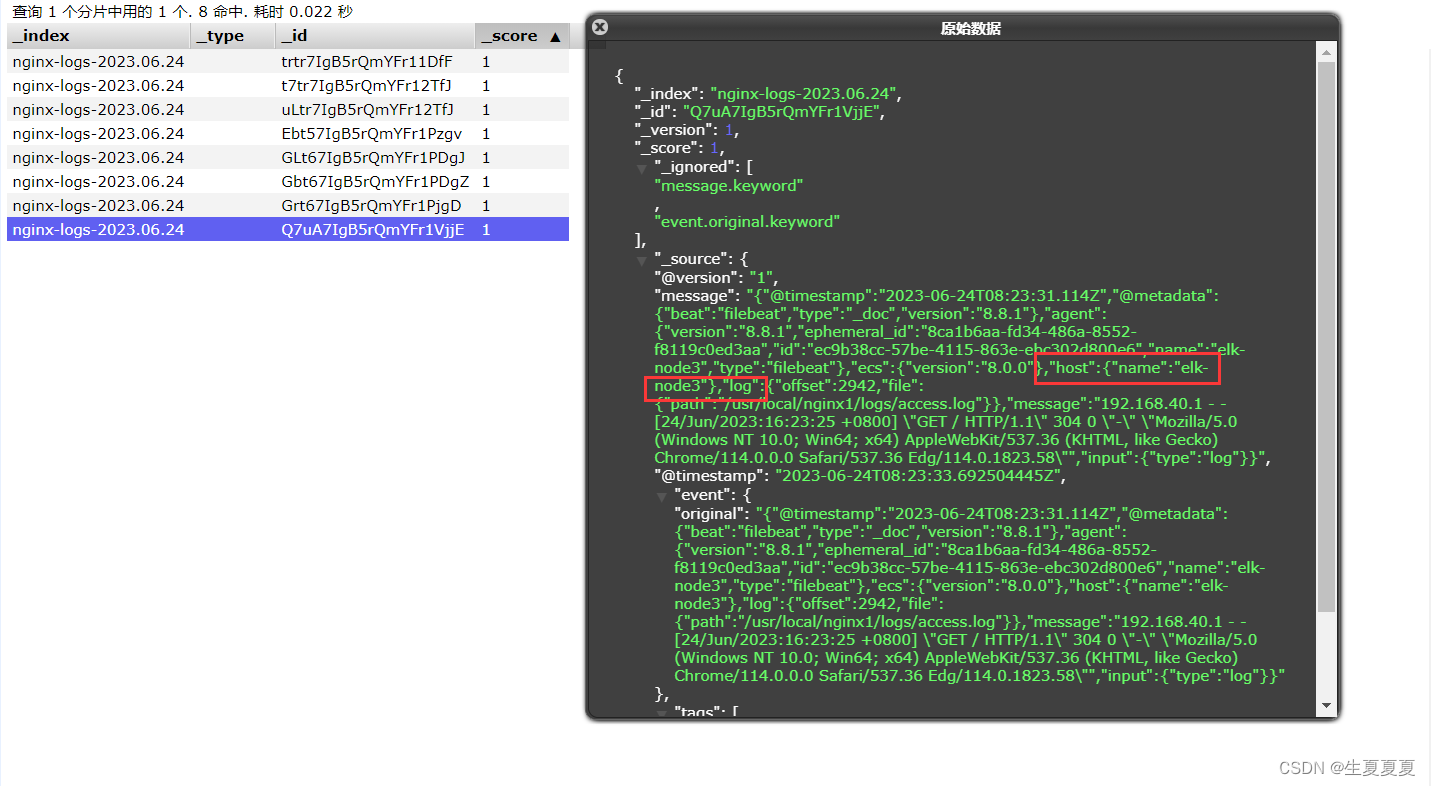
elk-node2的日志写入成功
8.使用kibana查看访问
启动kibana
[root@elk-node1 kibana-8.8]# nohup ./bin/kibana --allow-root &
创建索引
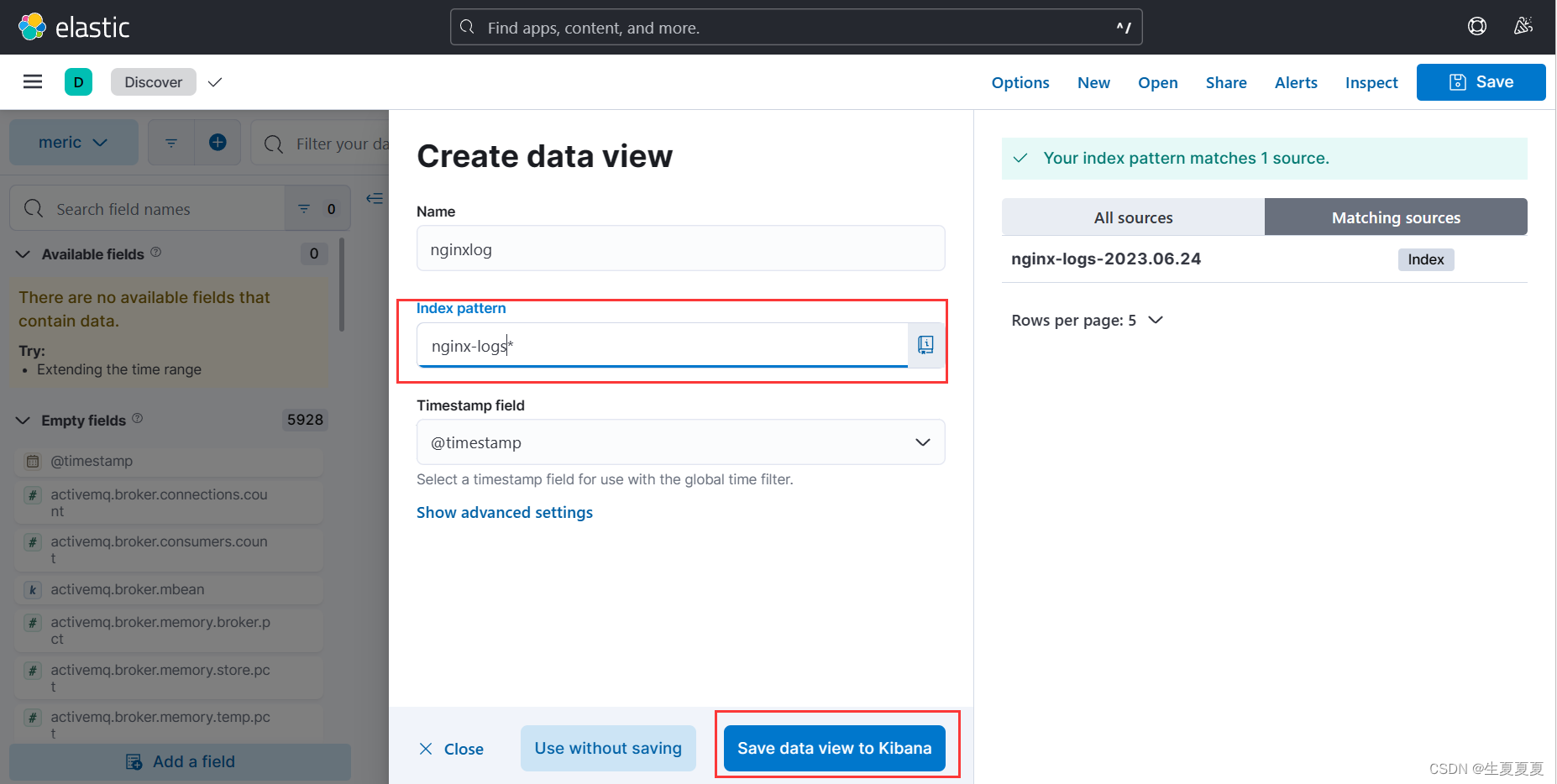
访问,发现显示的字段没有达到预期的要求
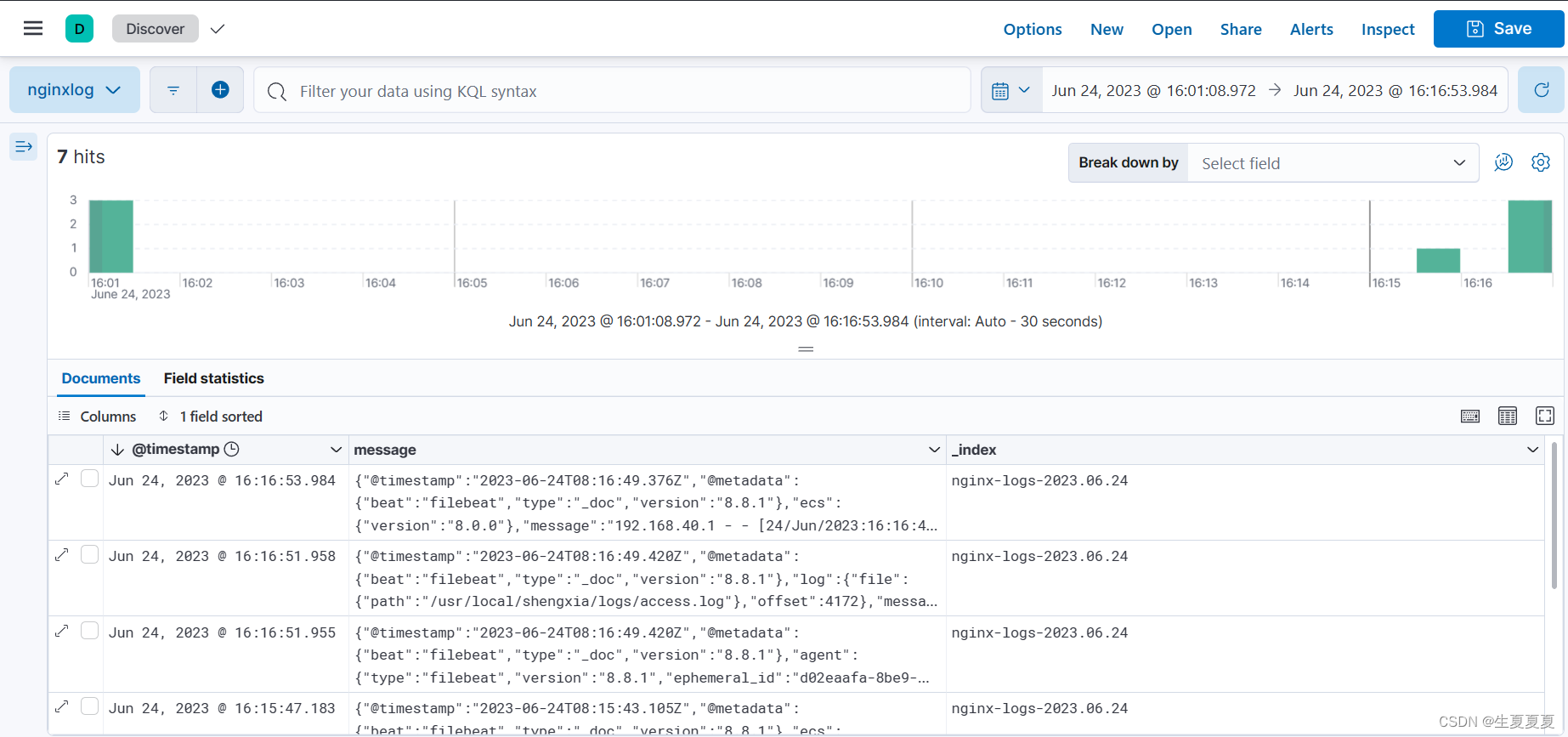
修改一下nginx.conf日志格式试一下(主要是grok解析nginx日志字段出现了点拆错,可以百度查找相关的解析格式,上面的grok是修正过后的,应该没啥问题)
可以查看到nginx日志的相关字段了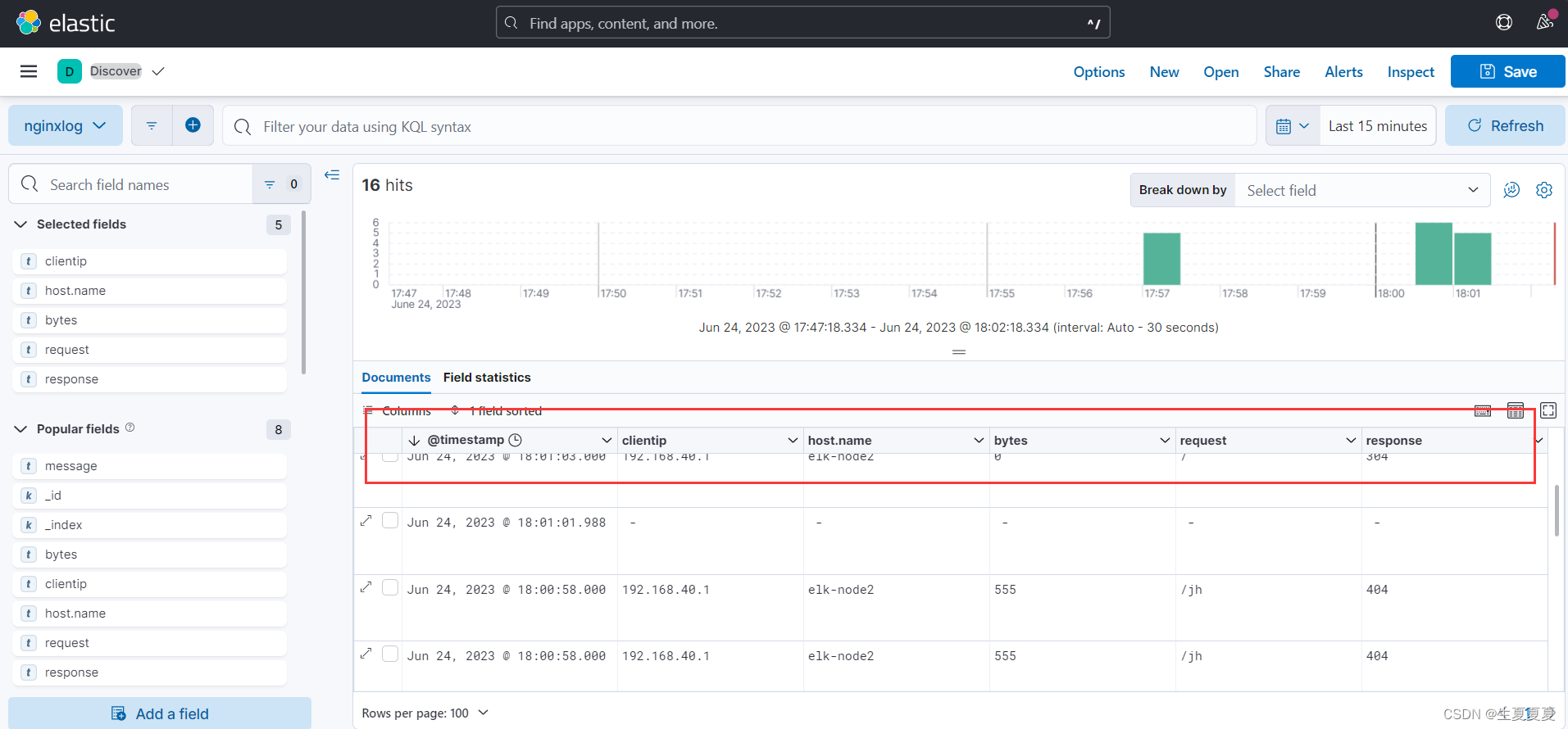
有结果后进行出图展示,可以自己设置相关的字段进行出图展示,我这里简单设置了一下
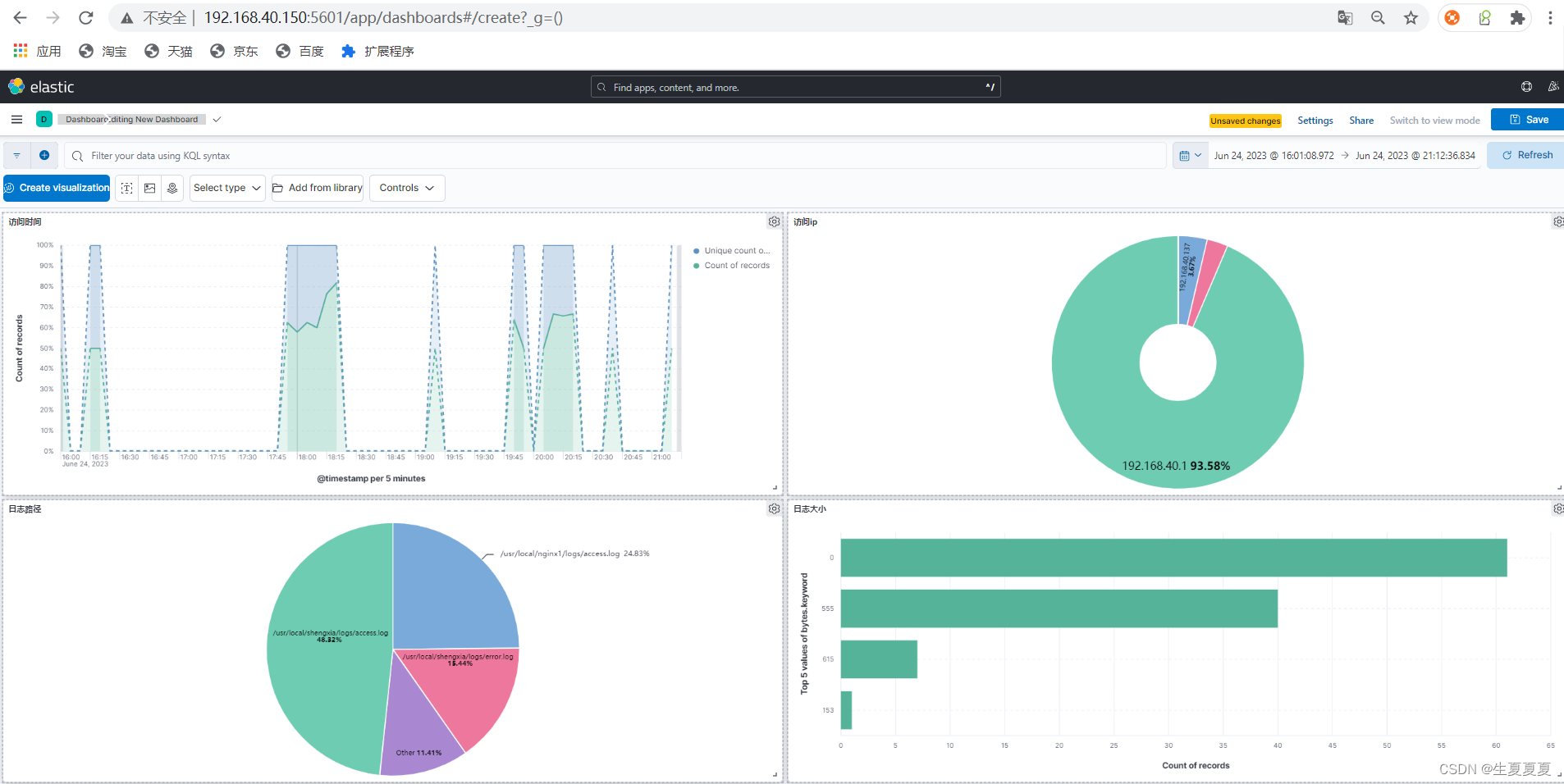
因为我也安装了grafana,也可以利用grafana进行出图展示,grafana安装的过程也可以看我之前的文章 Prometheus、Grafana、cAdvisor的介绍、安装和使用
选择Elasticsearch作为数据源,连接好ES集群所在的IP地址
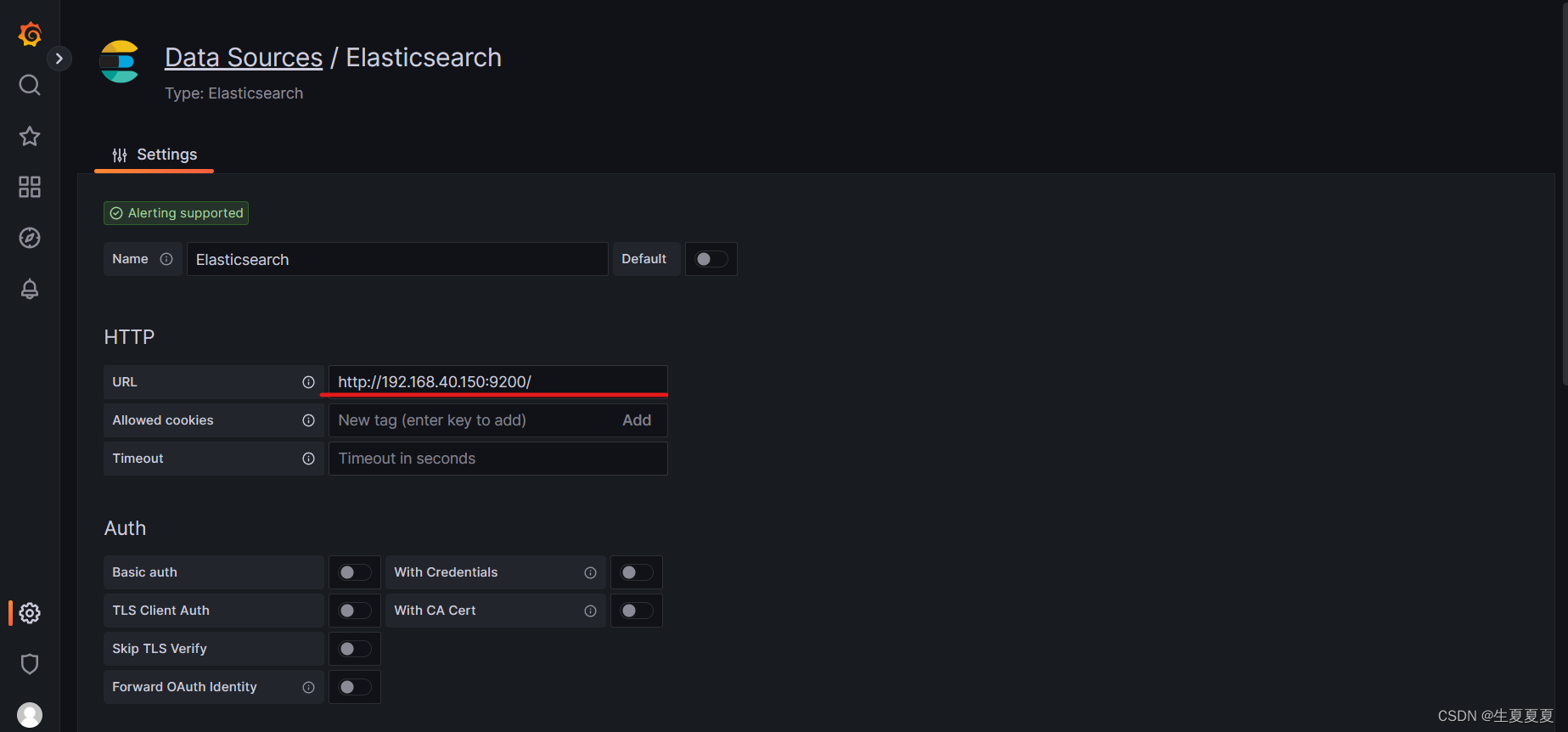
创建面板进行出图展示

设置告警规则,好像没啥用,可以忽略
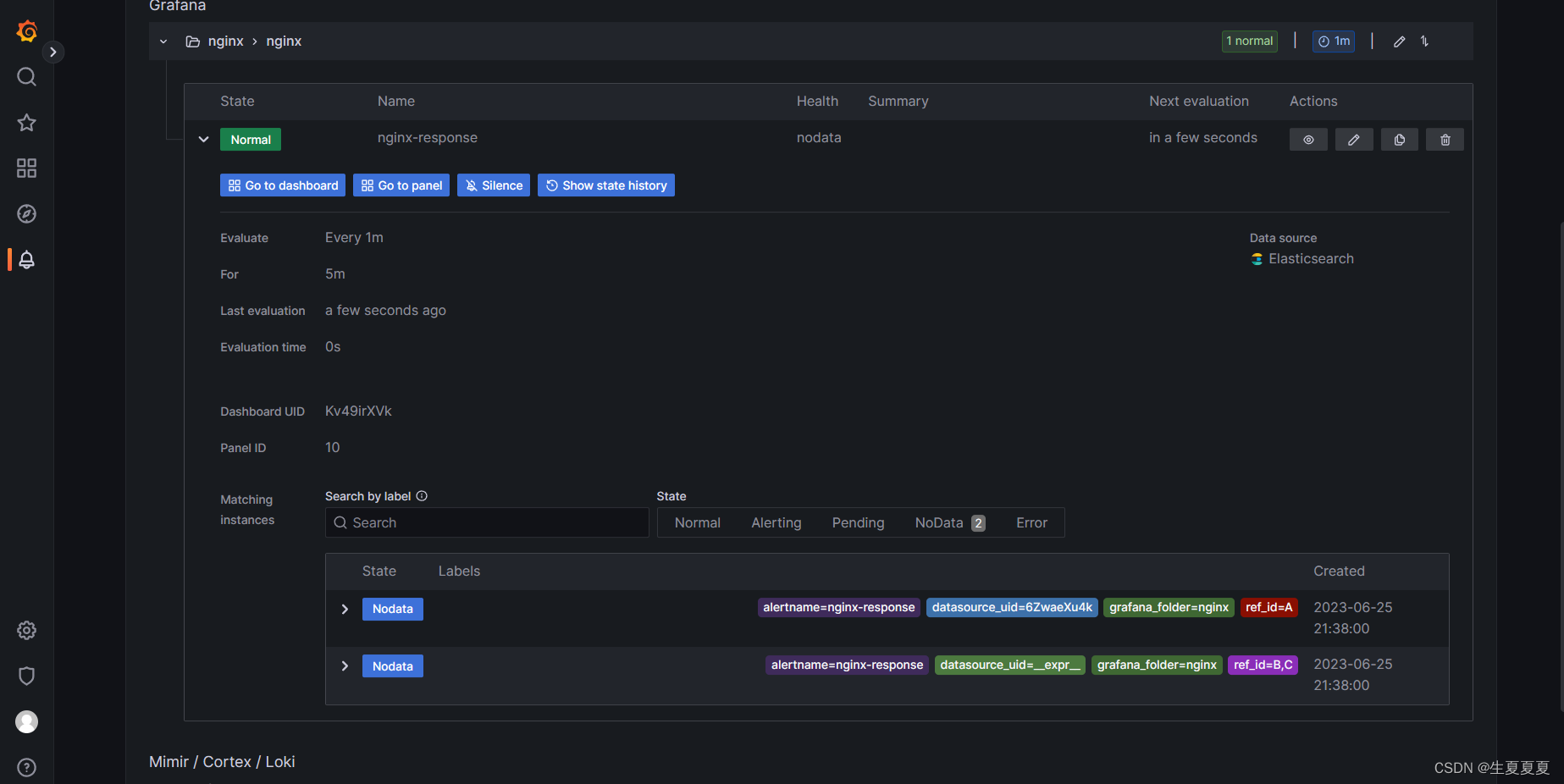
9.通过关键字段设置阈值,发送警告消息
尝试使用elasticalert实现qq邮箱告警
下载pyhton3的软件包
[root@elk-node1 elk]# yum -y install gcc gcc-c++ openssl-devel python3-devel
使用git下载elasticalert
[root@elk-node1 elasticalert]# yum install -y git && git clone https://github.com/Yelp/elastalert.git
如果git拉不下来,使用pip3安装
[root@elk-node1 elk]# pip3 install elastalert
如果存在如下错误
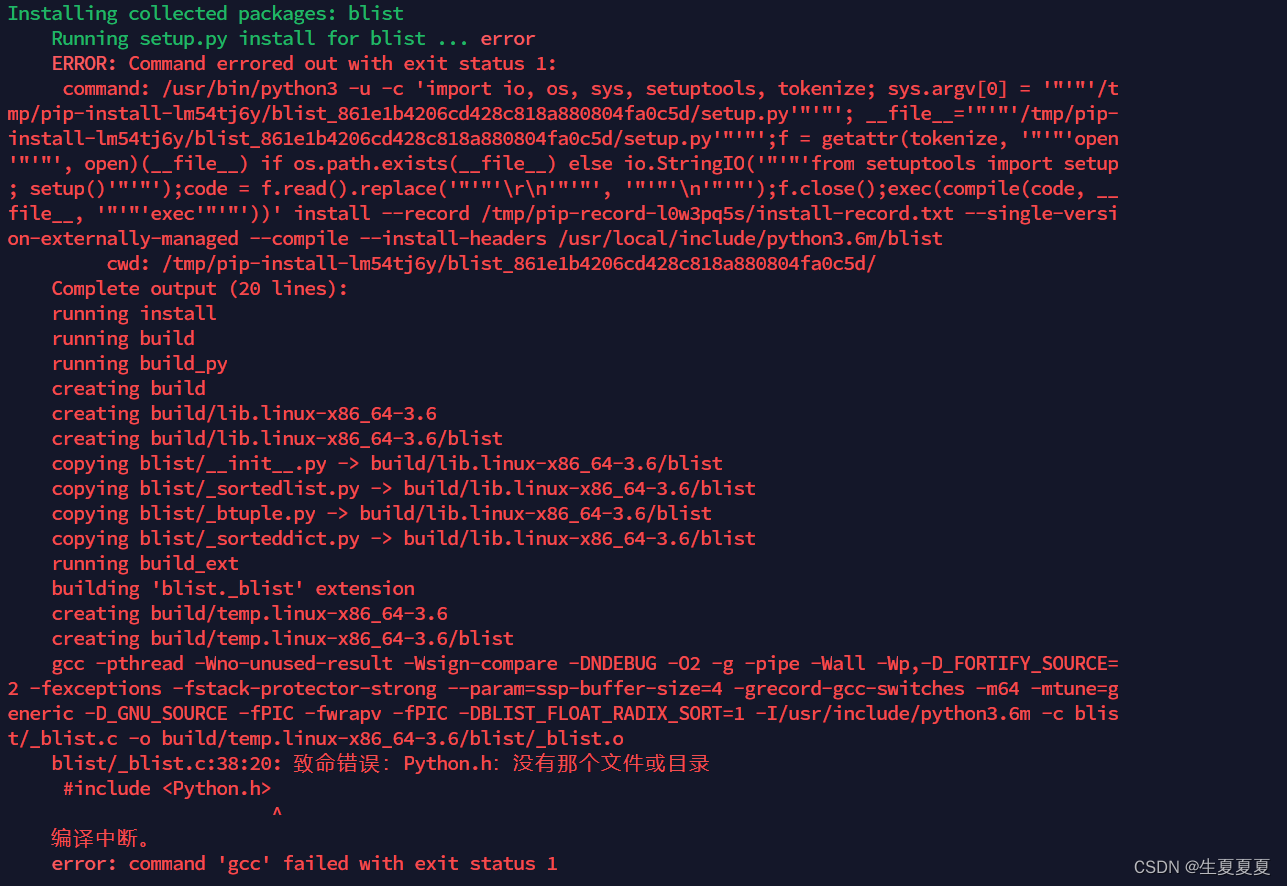
执行如下命令
[root@elk-node1 elk]# pip3 install blist
再次安装
[root@elk-node1 elk]# pip3 install elastalert
安装好后默认存放路径
[root@elk-node1 elk]# find / -name elastalert
/usr/local/bin/elastalert # 二进制文件
/usr/local/lib/python3.6/site-packages/elastalert # 安装目录
复制到elk目录下
[root@elk-node1 elk]# cp -r /usr/local/lib/python3.6/site-packages/elastalert .
踩坑,因为我的ES集群8.x版本以上的,与elastalert版本不兼容,所以…………………………失败了
尝试使用elasticalert2实现钉钉告警
安装相关依赖
yum -y groupinstall "Development tools"
yum install -y ncurses-devel gdbm-devel xz-devel sqlite-devel tk-devel uuid-devel readline-devel bzip2-devel libffi-devel
yum install -y openssl-devel openssl11 openssl11-devel
exportCFLAGS=$(pkg-config --cflags openssl11)exportLDFLAGS=$(pkg-config --libs openssl11)
下载并安装Python3.10.4,elastalert2需要最低Python3.10版本支持
[root@elk-node1 ~]# mkdir -p /opt/alert# 下载安装包[root@elk-node1 alert]# wget https://www.python.org/ftp/python/3.10.4/Python-3.10.4.tgz # 解压[root@elk-node1 alert]# tar zxvf Python-3.10.4.tgz[root@elk-node1 alert]# cd Python-3.10.4# 编译安装[root@elk-node1 Python-3.10.4]# ./configure --enable-optimizations && make altinstall
git克隆elasalert2
[root@elk-node1 alert]# git clone https://github.com/jertel/elastalert2.git
安装模块
[root@elk-node1 elastalert2]# pip install "setuptools>=11.3"[root@elk-node1 Python-3.10.4]# python3.10 setup.py install
安装钉钉插件
[root@elk-node1 alert]# wget https://github.com/xuyaoqiang/elastalert-dingtalk-plugin/archive/master.zip# 解压[root@elk-node1 alert]# unzip master.zip[root@elk-node1 alert]# mv elastalert-dingtalk-plugin-master dingtalk[root@elk-node1 alert]# cd dingtalk/[root@elk-node1 dingtalk]# cp -r elastalert_modules /opt/alert/elastalert2/[root@elk-node1 dingtalk]# cd /opt/alert/elastalert2/
修改配置文件
[root@elk-node1 elastalert2]# cd examples/[root@elk-node1 elastalert2]# cp config.yaml.example config.yaml
查看config.yaml文件
[root@elk-node1 examples]# cat config.yaml|grep -Ev "^#|^$"rules_folder: examples/rules # 规则文件所在的文件夹路径。run_every:# 规则执行的频率,每隔1分钟执行一次。minutes:1buffer_time:# 缓冲时间,在触发警报之前缓冲的时间,为15分钟。minutes:15es_host: 192.168.40.150 # Elasticsearch集群的IP地址,用于存储警报数据。es_port:9200# 端口writeback_index: elastalert_status # 用于保存警报状态的索引名称。alert_time_limit:# 警报的有效时间限制,2天内的警报将被处理。days:2
进入rules目录,新建规则文件
[root@elk-node1 examples]# cd rules/[root@elk-node1 rules]# cp example_frequency.yaml example_Warn.yaml
查看 example_Warn.yaml文件
[root@elk-node1 rules]# cat example_Warn.yaml | grep -Ev "^#|^$"name: Warn # 规则的名称。type: frequency # 规则类型为频率,表示要检测的事件是在一定时间范围内出现的次数。index: nginx-logs* # 要在哪个索引中搜索日志数据,这里是以"nginx-logs"开头的索引。num_events:5# 在指定的时间范围内,触发警报所需的事件数量,这里是在最近30分钟内出现了5次404错误。timeframe:minutes:30filter:# 过滤要检查的日志事件。这里使用了一个term(项)筛选器,表示只关注response.keyword字段等于"404"的事件。-term:response.keyword:"404"alert:# 定义触发警报时的操作。-"elastalert_modules.dingtalk_alert.DingTalkAlerter"# 钉钉机器人的Webhook地址,用于发送警报消息。dingtalk_webhook:"https://oapi.dingtalk.com/robot/send?access_token=填你自己的地址"dingtalk_msgtype: text # 钉钉消息的类型为文本。dingtalk_text:# 钉钉消息的内容,使用了'%{变量名}'来插入动态信息,这里不完善,有兴趣可以自己修改content:"Nginx 404 Alert: %{num_events} 404 errors occurred in the last %{timeframe}"
钉钉机器人设置
获取webhook的token
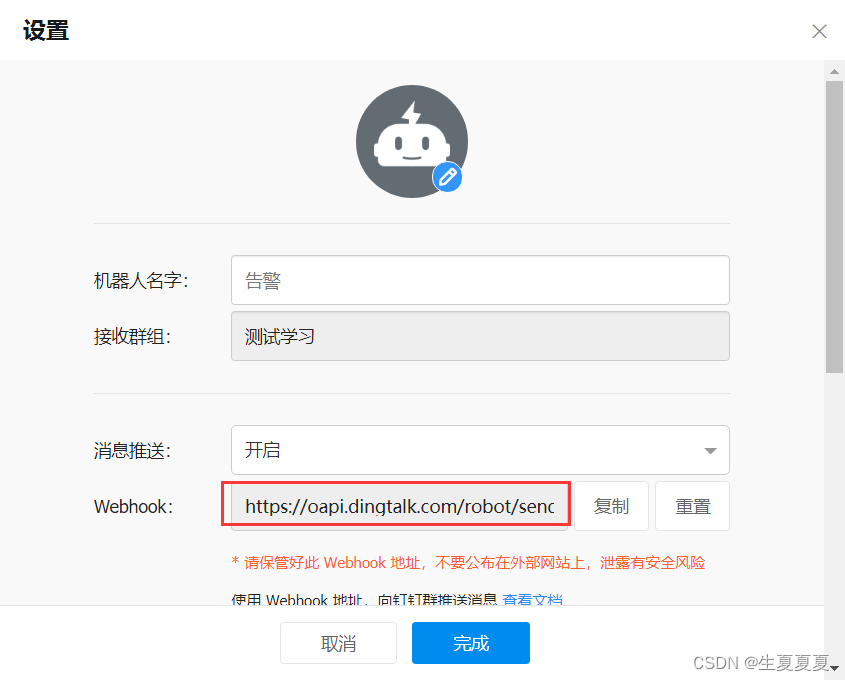
设置关键词
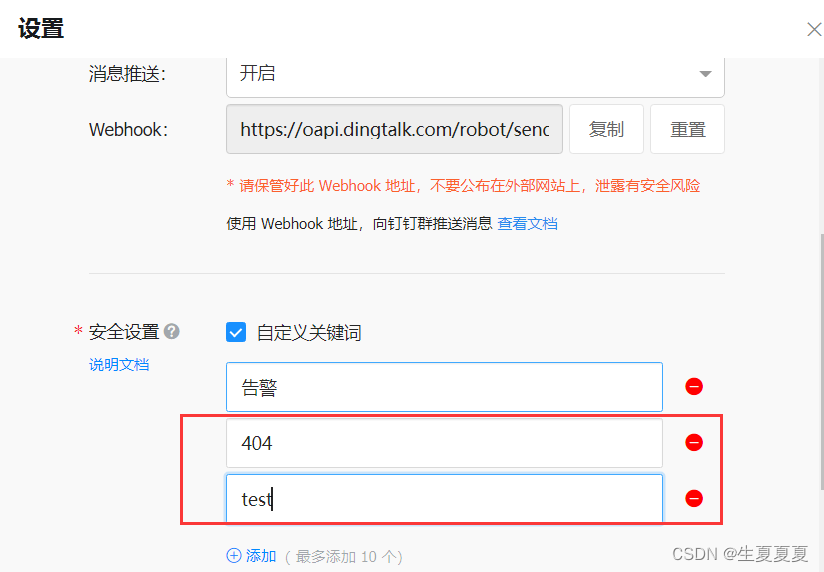
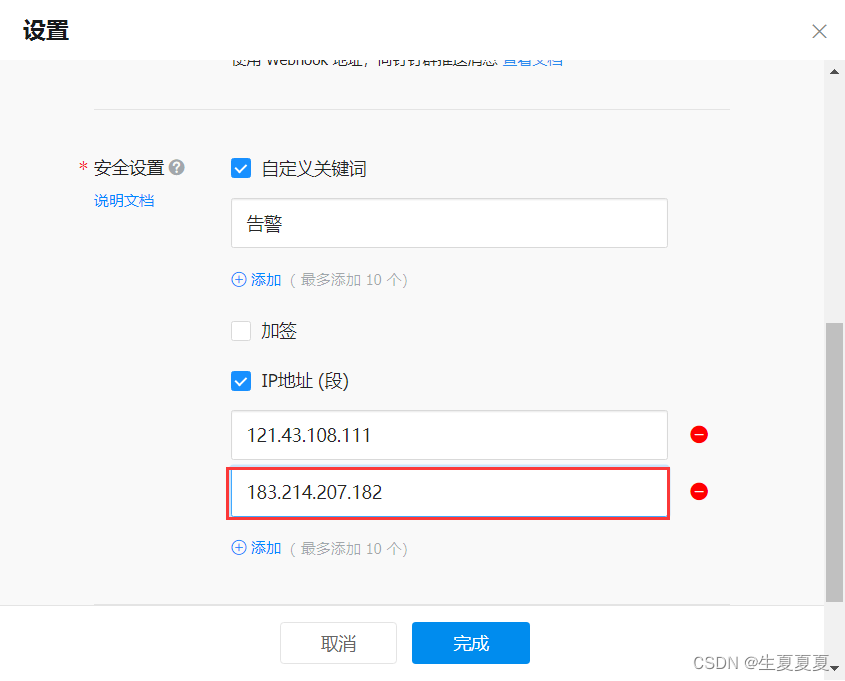
获取IP地址,注意,该IP地址不是虚拟机的IP地址,使用
curl ifconfig.me
可以获得
测试
curl -H 'Content-Type: application/json'\
-d '{"msgtype": "text", "text": {"content": "This is a test message"}}'\
-X POST https://oapi.dingtalk.com/robot/send?你自己的token
如果机器人显示消息,则可以正常工作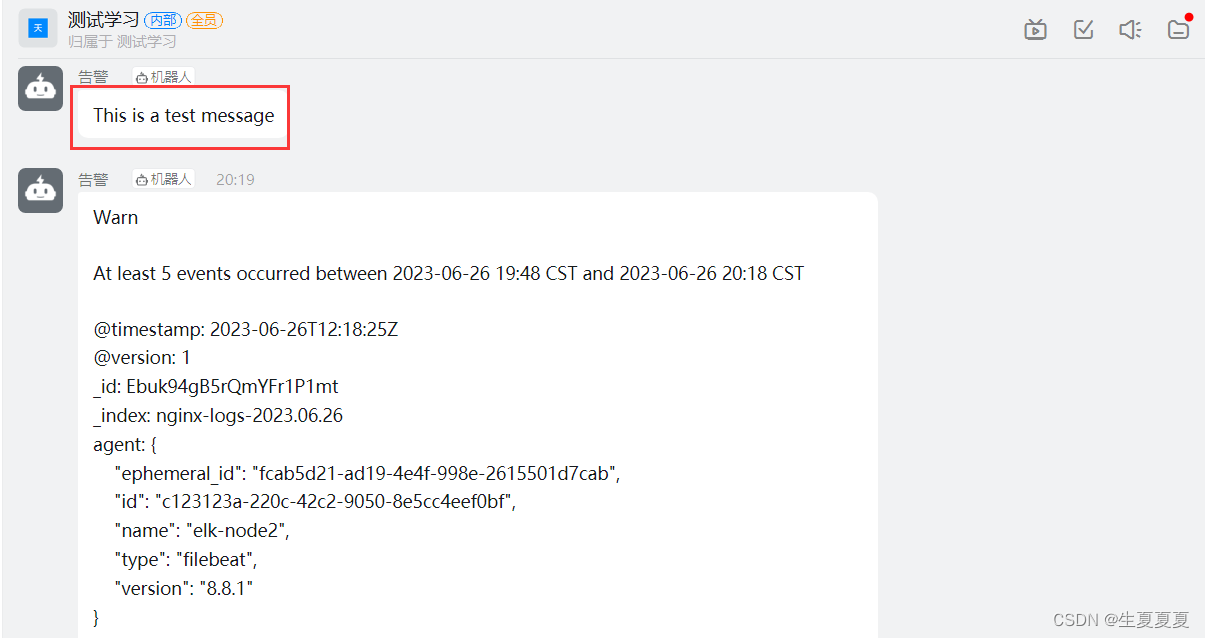
启动elastalert2
[root@elk-node1 elastalert2]# python3.10 -m elastalert.elastalert --verbose --config examples/config.yaml --rule examples/rules/example_Warn.yaml
报错
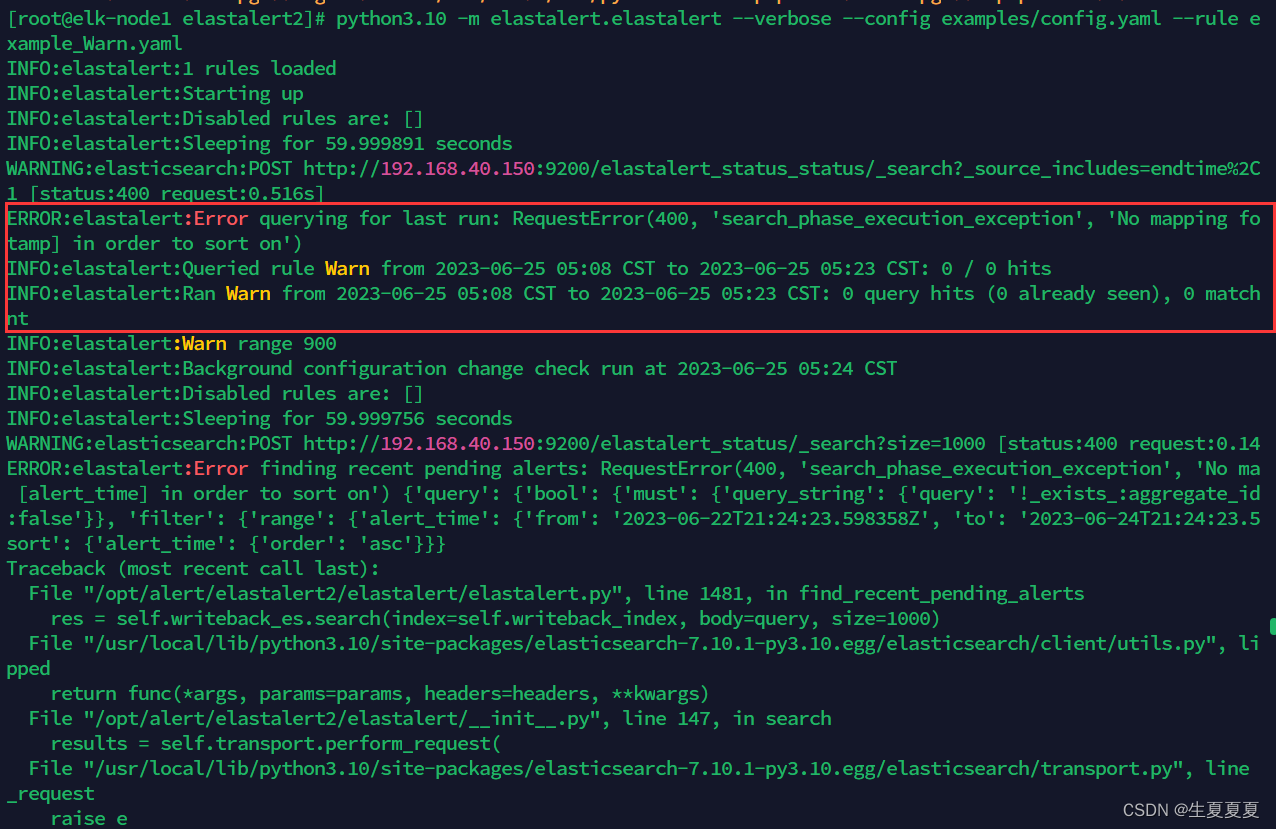
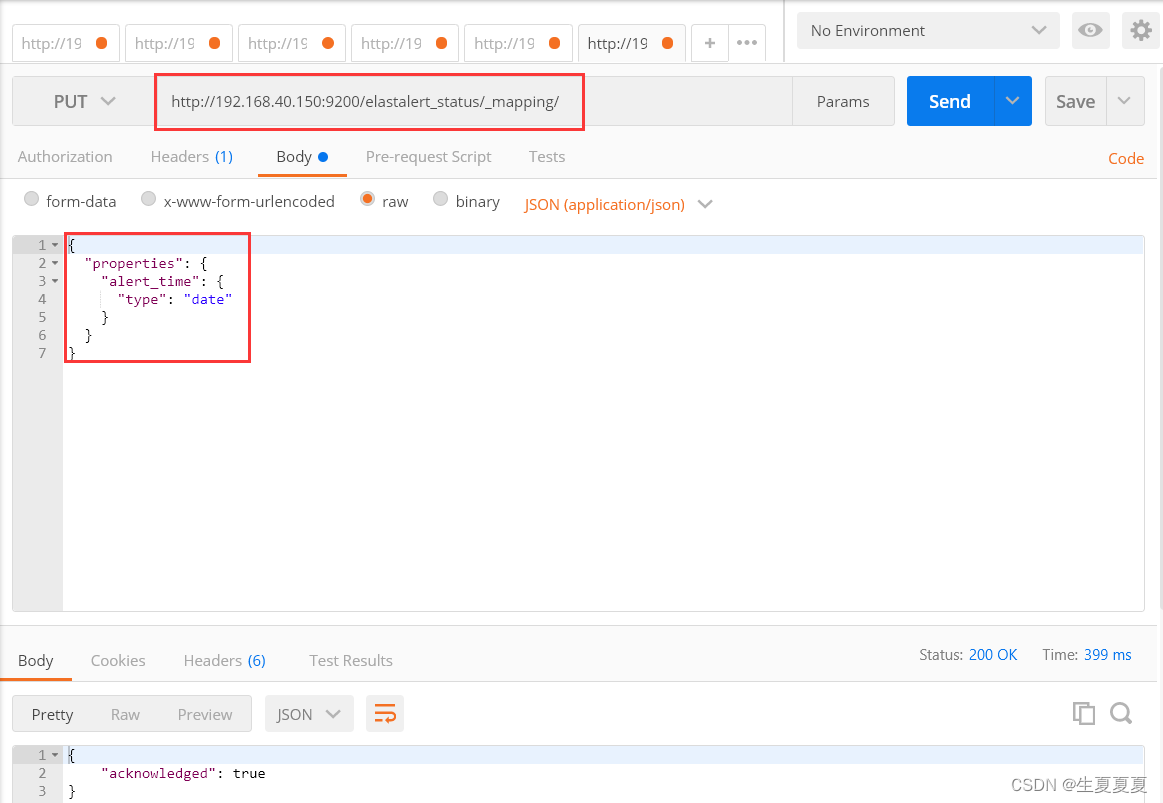
这段日志中信息是No mapping found for [@timestamp] in order to sort on,意思是Elasticsearch中找不到 @timestamp 字段的映射,因此不能按照 @timestamp 字段进行排序。这个问题的解决方法是在Elasticsearch中创建一个映射,将 @timestamp 字段定义为日期类型
{"properties":{"@timestamp":{"type":"date"}}}
放在后台运行
[root@elk-node1 elastalert2]# nohub python3.10 -m elastalert.elastalert --verbose --config examples/config.yaml --rule examples/rules/example_Warn.yaml &
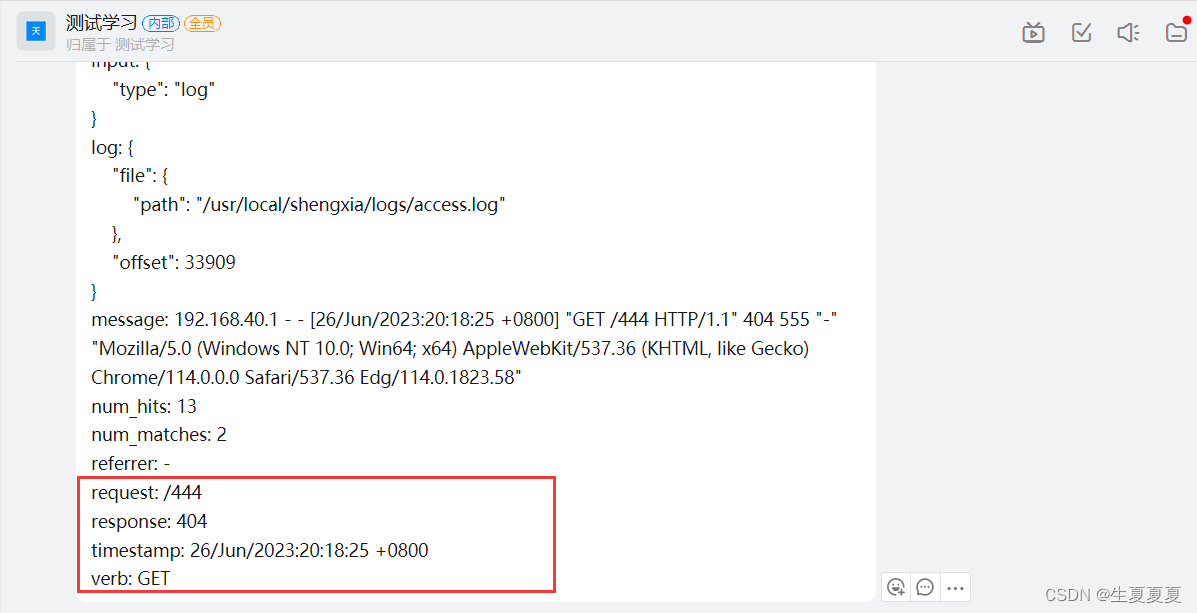
简单测试一下,钉钉可以接收警告消息
参考文章:传送门
版权归原作者 生夏夏夏 所有, 如有侵权,请联系我们删除。