
文章目录
hive cli 导出
通过
hive cli
查询导出。
示例: 将 Hive 中
dwd.dim_machine
表导出到本地
/opt/software/test.csv
文件中,添加表头。
hive -e"set hive.cli.print.header=true;select * from dwd.dim_machine;"|tr"\t"","> /opt/software/test.csv
hive -e:以带表头的方式查询。tr:将"\t"替换成逗号","
结果:
通过 spark-shell 导出
前提:需要配置好与 hive 的连接。
示例: 将 Hive 中
dwd.dim_machine
表导出到本地
/opt/software/test2.csv
文件中。
示例: 在 spark-shell 中导出。
spark.sql("select * from dwd.dim_machine").write.csv("file:///opt/software/result")
注意: spark 导出的是一个目录,我们需要拿到目录下的 csv 文件。
进入
result
目录,会看到如下文件:
后缀为
csv
的就是我们的结果文件。
按题目要求设置文件路径与名称:
mv part-00000-e72da482-533b-486c-a8b2-d37c6abe8eb4-c000.csv ../test2.csv
结果:
insert 导出
直接在 Hive 界面中进行操作。
示例: 将 Hive 中
dwd.dim_machine
表导出到本地
/opt/software/test3.csv
文件中。
insert overwrite local directory '/opt/software/test'row format delimited fieldsterminatedby','select*from dwd.dim_machine;
结果: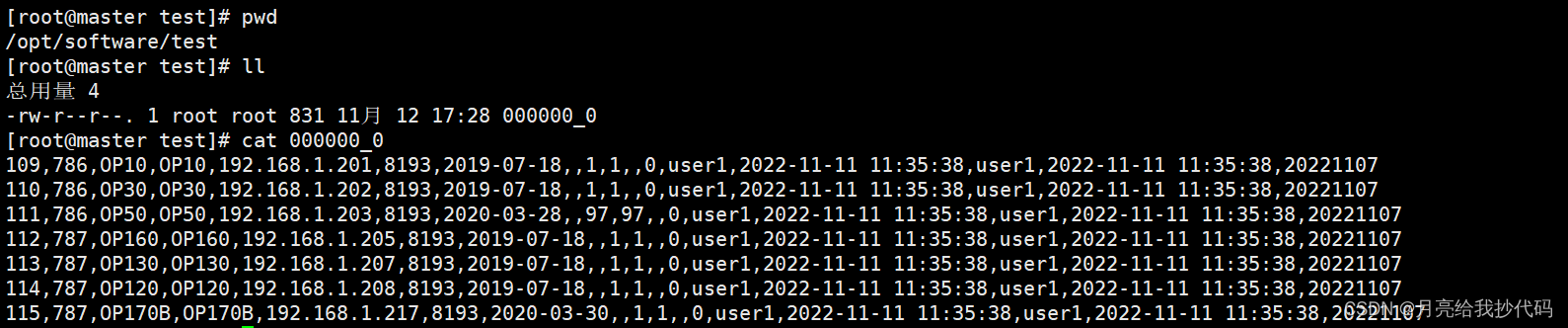
最后,按题目要求改成指定路径与名称就可以啦,这里就不操作了。
本文转载自: https://blog.csdn.net/weixin_46389691/article/details/127822372
版权归原作者 月亮给我抄代码 所有, 如有侵权,请联系我们删除。
版权归原作者 月亮给我抄代码 所有, 如有侵权,请联系我们删除。