
🐱作者:一只大喵咪1201
🐱专栏:《网络》
🔥格言:你只管努力,剩下的交给时间!

现在是传输层,在应用层中的报文(报头 + 有效载荷)就不能被叫做报文了,而是叫做数据段(报头 + 有效载荷),传输层的有效载荷就是应用层的完整报文。
目录
🏺再谈端口号
- 端口号(port):标识了一个主机上进行通信的不同的应用程序。

如上图所示,FTP,SSH,SMTP,HTTP,FTP等类型的服务器,其实就是在一台机器上运行着的不同进程,这些是他们的名字。
每一个进程都有一个端口号,如上图中的,TCP21,TCP22等等,TCP后面的数字就是端口号,当数据从网络中传输到应用层后,根据端口号将数据交给对应的进程。
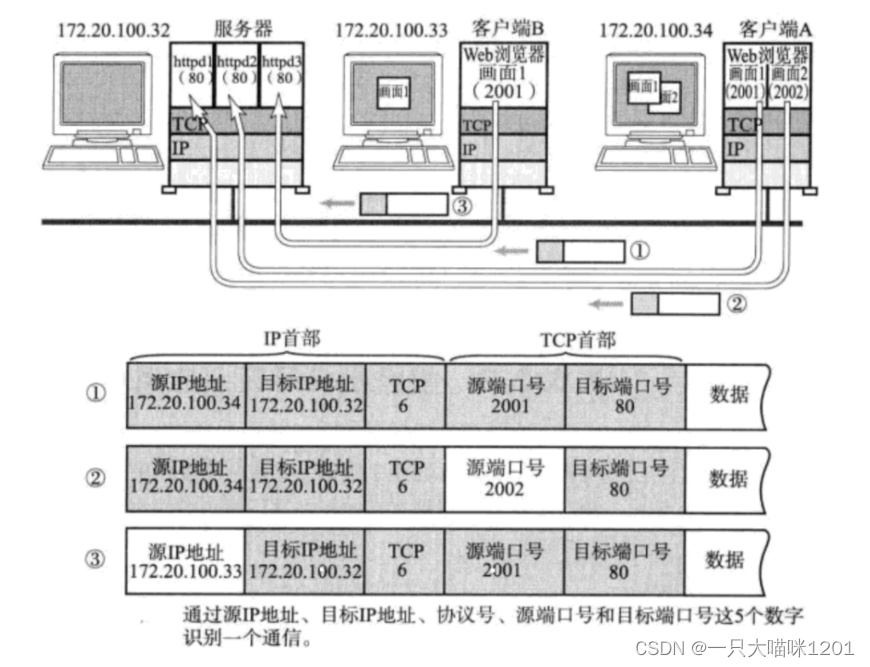
- 在TCP/IP协议中, 用 “源IP”, “源端口号”, “目的IP”, “目的端口号”, “协议号” 这样一个五元组来标识一个通信。
如上图网络通信中的数据1和2,是客户端A的两个浏览器页面(两个进程)向服务器发送的数据,所以TCP/IP协议中,源IP地址都是客户端A的IP地址,目标IP地址都是服务器的IP地址,源端口号分别是2001和2002,表示两个页面的两个进程,目标端口号也都是服务端的HTTP进程,端口号是80。
数据3是客户端B的一个浏览器页面(一个进程)向服务器发送的数据,源IP地址就是客户端B的IP地址,目标IP是服务端的IP地址,源端口号是这个页面进程的端口号,目标端口号是服务器HTTP进程的端口号80。
- 协议号:这些通信协议的编号,通过指定的协议号可以指定使用哪个协议。
IP地址在后面本喵讲解网络层中的IP协议时再详谈。
🥝端口号划分
在前面编写套接字代码的时候,本喵代码中指定的端口号是一个
uint16_t
类型的数据,是一个16位的无符号整数,它的范围是
0~65535
,也就意味着端口号的范围是
0~65535
。
知名端口号:
- 端口号为
0~1023的是知名端口号,如HTTP,FTP,SSH等这些广为使用的应用层协议,他们的端口都是固定的。
应用层协议本质上就是进程,协议规定是通过进程的执行来体现的,所以
应用层协议 = 进程 = 端口号
,他们可以看成是等价的。
就好比,110对应的是报警电话,120对应的是急救电话,119是火警电话…。
同样的:
- ssh服务, 使用22端口
- ftp服务, 使用21端口
- telnet服务, 使用23端口
- http服务, 使用80端口
- https服务, 使用443
- …
0~1023
这些端口号都有对应的协议,不能随便更改,就像报警电话不会随便更改一样。
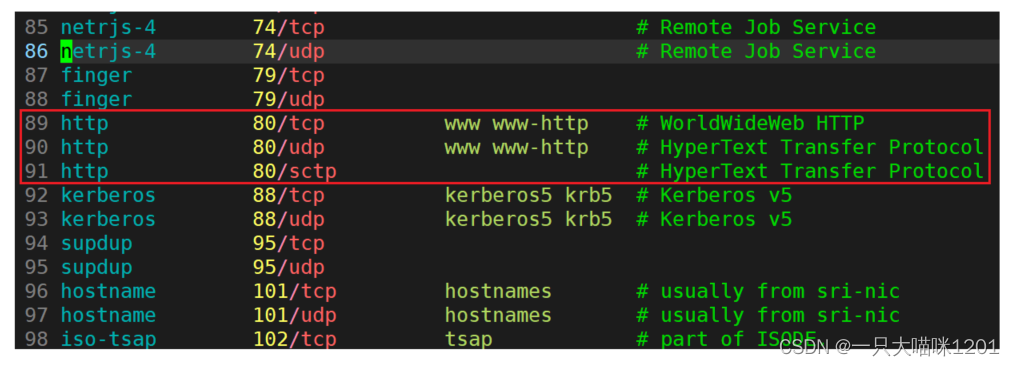
在文件
/etc/services
中存设定了具体端口号对应的服务协议,如上图红色框中所示,http的端口号是80。
我们自己写程序的时候,如果使用到端口号,要避开
0~1023
这些知名端口号。
操作系统动态分配的端口号:
1024~65535这些端口号可以由我们指定去绑定某个进程,也可以让操作系统从这些端口号中为某个进程随机分配一个。
在前面写套接字代码的时候,本喵服务器上的进程经常都是绑定的端口号是8080,需要使用
bind
系统调用去绑定。
客户端的套接字中,虽然也需要为进程绑定端口号,但是本喵并没有显式绑定(调用
bind
绑定),而是在调用
send
时,让操作系统自己从
1024~65535
中随机指定一个端口号绑定。
端口号与进程之间的关系:
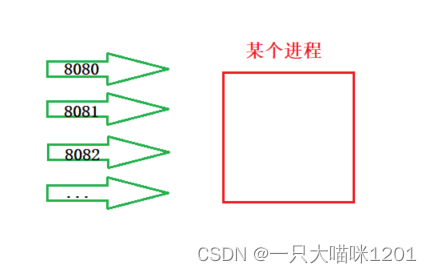
如上图所示,从端口号到进程必须是唯一的,也就是说根据一个端口号只能找到一个进程。
并且一个进程可以有多个端口号,如上图所示的8080,80801…,这些端口号都表示一个进程。
- 但是一个端口号不能绑定多个进程。
netstat:
netstat
指令前面本喵用过好几次,就是用来查看当前机器上网络状态的。
- 语法
netstat [选项]- 功能:查看网络状态
- 常用选项:
- n 拒绝显示别名,能显示数字的全部转化成数字
- l 仅列出有在 Listen (监听) 的服務状态
- p 显示建立相关链接的程序名
- t (tcp)仅显示tcp相关选项
- u (udp)仅显示udp相关选项
- a (all)显示所有选项,默认不显示LISTEN相关
这里本喵就不演示了,大家自行组合使用即可。
还有一个指令
pidof [进程名]
使用起来非常的方便,可以直接得到进程名对应的
pid
值,不用再使用
ps ajx
来查了。
🏺UDP
🥝协议格式
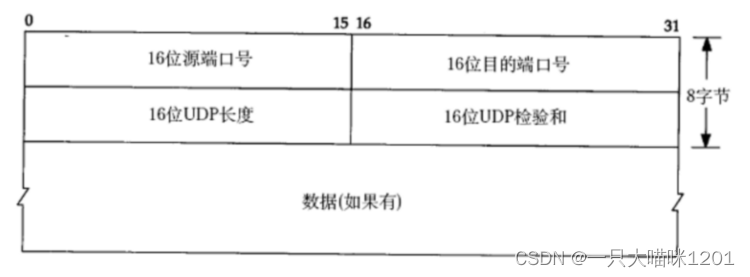
如上图所示就是UDP协议的格式,前八个字节属于协议报头部分,之后的才是有效载荷。
UDP协议其实就是前八个字节,也就是两个
int
类型的数据,其中第一个
int
类型数据的前16位
0~15
存放的是源端口号,后16位
16~31
是目的端口号,第二个
int
类型数据的前16位
0~15
存放的是UDP长度,后16位
16~31
存放的是UDP校验和。
UDP协议是传输层协议,是由操作系统维护的,而Linux操作系统又是由C语言写的,所以UDP协议报头的结构化数据伪代码是:
structudp_hdr{unsignedint src_port:16;//16位源端口号unsignedint dest_port:16;//16位目的端口号unsignedint length:16;//16位UDP长度unsignedint check:16;//16位UDP校验和};
UDP协议报头本质上就是一个结构体,如上面代码所示,使用位段将两个
unsigned int
类型的数据分成四部分。
- 16位源端口号:表示发送端(客户端)的端口号。
- 16位目的端口号:表示接收端(服务端)的端口号。
- 16位UDP长度:整个UDP数据段(报文)的长度,包括报头和有效载荷,UDP数据段最大就是216 = 64KB。
- 16位校验和:由操作系统进行校验,如果发送方和接收方的校验和不一致,说明出错,就会丢弃整个UDP数据段。
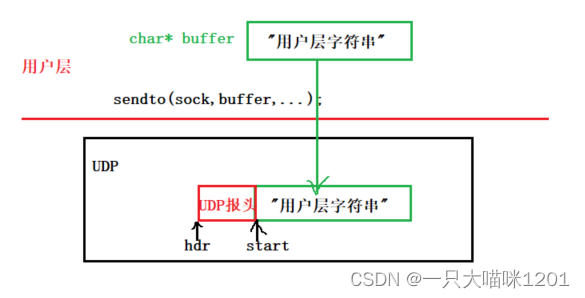
如上图,将用户层的数据(字符串)使用
sendto
发送到UDP套接字中时,其本质上就是将用户层
buffer
中的字符串复制到UDP套接字的内核缓冲区中。
- hdr指针指向内核缓冲区最起始位置(UDP报头),start指针指向内核中有效载荷的起始位置。
上面过程的伪代码:
char* hdr =malloc(XXX);//操作系统创建内核缓冲区char* start = hdr +sizeof(structudr_hdr);//指向有效载荷strcpy(start,buffer,len);//将用户缓冲区中数据复制到内核缓冲区有效载荷处。(structudp_hdr*)hdr->src_port = xxx;//赋值源端口(structudp_hdr*)hdr->dest_port = xxx;//赋值源端口(structudp_hdr*)hdr->length = xxx;//赋值源端口(structudp_hdr*)hdr->check = xxx;//赋值源端口
操作系统会在内核中使用
malloc
创建一个内核缓冲区,这个缓冲区最大是64KB,前8个字节属于UDP的报头,也就是
struct udp_hdr
类型对象,再偏移报头字节数(
sizeof(udp_hdr)
),用
start
指向有效载荷存储的起始位置。
再将内核缓冲区中的字符串使用
strcpy
复制到内核中存放有效载荷的位置,再将内核缓冲区强转成
struct udp_hdr
类型,将报头的4部分填充,最后将整个缓冲区的数据发送到对端。
🥝解包和分用
UDP的解包和分用比较简单,对端收到UDP数据段以后,直接将有效载荷拿到,并且放入到接收缓冲区中,只需要从整个数据段的头部偏移
sizeof(struct udp_hdr)
个字节即可拿到有效载荷。
分用时,将绑定的端口号作为
key
值,在操作系统维护的网络通信进程哈希表中查找到对应的进程,将有效载荷交给进程即可。
🥝特点
- 无连接:只需要指定目的IP和目的端口就可以直接进行传输,不需要建立连接。
- 不可靠:没有确认机制,没有重传机制,如果因为网络故障该数据段无法发到对方,UDP协议层也不会给应用层返回任何错误信息。
- 面向数据报:不能够灵活控制读写数据的次数和数量。
UDP发送数据的方式就像寄信一样,只管发出去,至于对方能不能收到完全不关心。
面向数据报:
应用层交给UDP多长的报文,UDP原样发送,既不拆分,也不合并。
- UDP发送数据段时,是一次性将内核缓冲区中的数据全部发送出去。
- 接收端会一次性接收发送端发送的所有数据,不能分多次接收。
就像快递,你发快递只能一个一个发,不能先发半个,然后再发半个,收快递也是,不能先收半个,然后再收半个,只能一个个完整的快递进行收发。
UDP缓冲区:
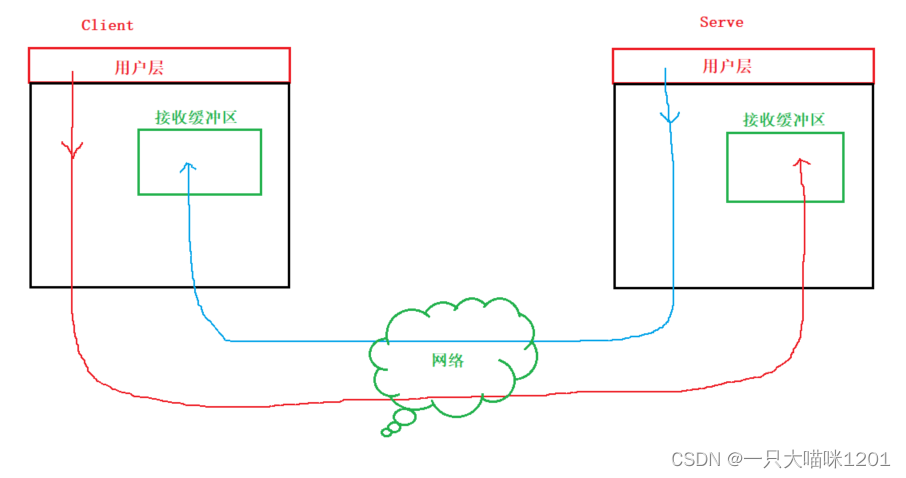
如上图所示,UDP协议没有真正意义上的发送缓冲区,当客户端的用户层将数据使用
sendto
发送的时候,操作系统将数据拷贝到上面伪代码中的那个数组中,然后将整个数组的数据全部发送。
但是UDP协议存在接收缓冲区,服务端的操作系统将客户端发送来的数据存放在接收缓冲区中,如上图绿色框所示,当接收缓冲区满了,或者在适当的时候,操作系统会将数据再交给用户层。
- 因为没有发送缓冲区,所以UDP协议发送数据时,用户层一调用
sendto数据就被发送出去了,没有停留。
根据上图,虽然没有发送缓冲区,但是双方都有接收缓冲区,客户端发送数据,服务端接收数据的同时,并不妨碍服务端也发送数据,客户端接收数据。
- 这样的双方同时发送并且接收数据的模式叫做全双工。
注意事项:
前面本喵说过,UDP数据段最长不能超过64KB,所以如果传输的数据超过了64KB,就需要在应用层手动的分包,将数据分成多个64KB大小的数据包,然后多次发送,并且在接收端手动拼装。
常见的基于UDP的应用层协议:
- NFS: 网络文件系统
- TFTP: 简单文件传输协议
- DHCP: 动态主机配置协议
- BOOTP: 启动协议(用于无盘设备启动)
- DNS: 域名解析协议
这些协议在传输层都是使用的UDP协议。当然也包括我们自己写UDP程序时自定义的应用层协议。
🏺TCP
- TCP全称为 “传输控制协议(Transmission Control Protocol”).。
- 人如其名, 要对数据的传输进行一个详细的控制。
🥝协议格式
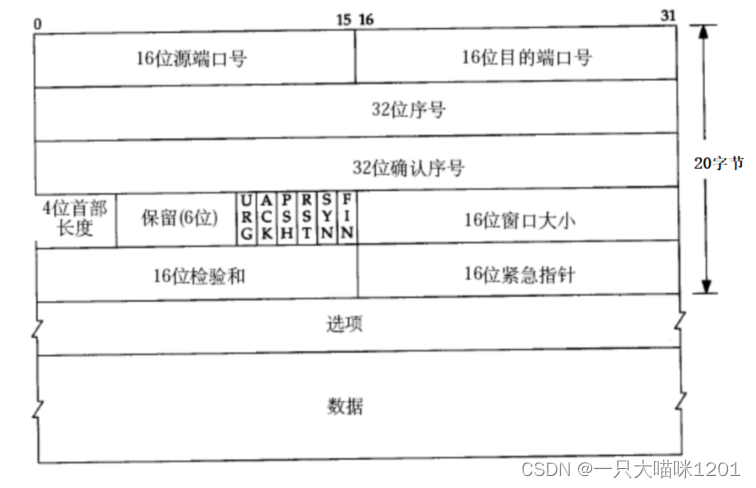
如上图所示,TCP协议报头的长度固定20个字节,不包括选项和有效载荷,本喵也不会讲解选项部分,有兴趣的小伙伴可以自行了解。
TCP协议报头同样也是一个结构化数据,和UDP一样,只是结构体中的成员变量大小和类型不同而已。
- 16位源端口号:发送方进程的端口号。
- 16位目的端口号:接收方进程的端口号。
- 32位序号/32位确认号: 后面详细讲。
- 4位TCP报头长度: 表示该TCP头部有多少个32位bit(有多少个4字节),也就是一个
unsigned int类型,所以TCP头部长度是TCPval * 4 。最大头部长度是15 * 4 = 60字节。
- TCP中的4位首部长度包含报头和选项,报头部分固定20字节。
- 头部长度 - 20 = 选项长度。
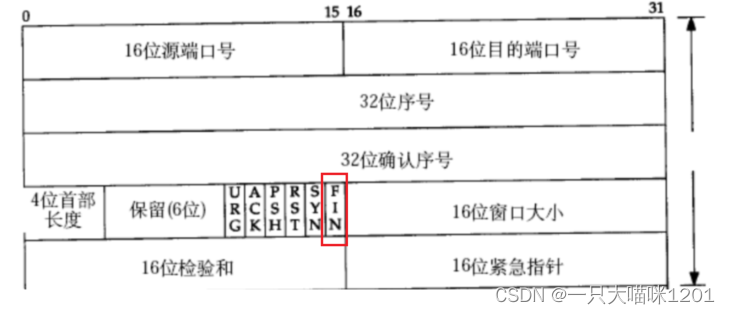
- 6位标志位:标识UDP数据段的类型。
- URG:紧急指针是否有效。
- ACK:确认号是否有效。
- PSH:提示接收端应用程序立即从TCP缓冲区把数据拿走。
- RST:对端要求重新建立连接,所以把携带RST标识的数据段称为复位报文段。
- SYN:请求建立连接,所以把携带SYN标识的数据段称为同步报文段。
- FIN:通知对端,本段关闭了,称携带FIN标识的为结束报文段。
- 16位窗口大小:表示滑动窗口的大小,后面详细讲解。
- 16位校验和:发送端填充CRC校验. 接收端校验不通过, 则认为数据有问题,此处的检验和不仅包含TCP首部,也包含TCP数据部分。
- 16位紧急指针:标识哪部分数据是紧急数据(带外数据)。
这些报头中的内容,本质上也是一个结构体的成员变量,伪代码:
structtcp_hdr{uint32_t src_port:16;uint32_t dest_port:16;uint32_t seq;uint32_t ack_seq;uint32_t header_length:4;......};
🥝解包和分用
缓冲区:
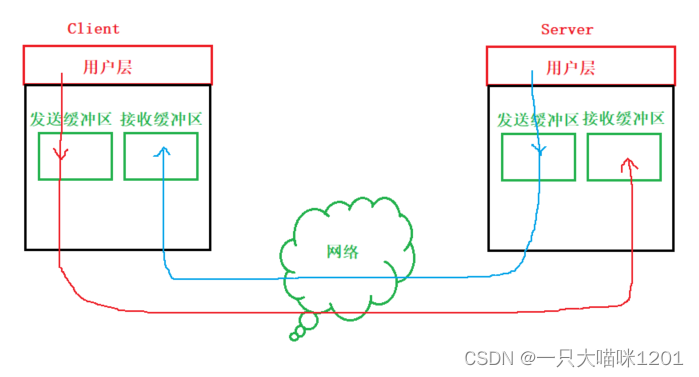
如上图所示,TCP协议中,通信双方都既有发送缓冲区,又有接收缓冲区,用户层在
send
数据之后,操作系统会自动拼接TCP报头形成数据段,然后放入到发送缓冲区中。
对端收到数据段后先放入接收缓冲区中,等待用户层读取数据,通信双方既可以发送数据,也可以接收数据,而且互不影响,同样是全双工的方式。
- 至于什么时候将数据段从发送缓冲区发出去,什么时候将数据从接收缓冲区交给应用层。
- 一次从缓冲区发送多少个字节的数据,一次又接受多少数据。
- 这些全部由操作系统自行控制,也就是由TCP协议自行决定。
所以说,TCP是传输控制协议,它完全有自主决定权,而且是面向字节流的,发送数据接收数据以字节为单位,在发送接收过程中,完全不考虑是不是一个完整的数据段。
- TCP不像UDP那样,一次必须发送或者接收一个完整的数据段,而是以字节为单位的,发送或接收一个完整的数据段,需要很多个字节。
- 这些流动的字节像河流一样,所以说TCP是面向字节流的。
在对端收到TCP数据段以后,根据数据段中的TCP首部长度,得到整个报头长度,偏移
sizeof(struct tcp_hdr)
后,得到有效载荷的首地址,直到下一个TCP数据段的起始全部都是有效载荷,将这部有效载荷提取到接收缓冲区中就完成了解包。
那么又是怎么完成分用的呢?也就是说该如何找到曾经
bind
端口号的特定进程呢?
网络协议和协议栈:
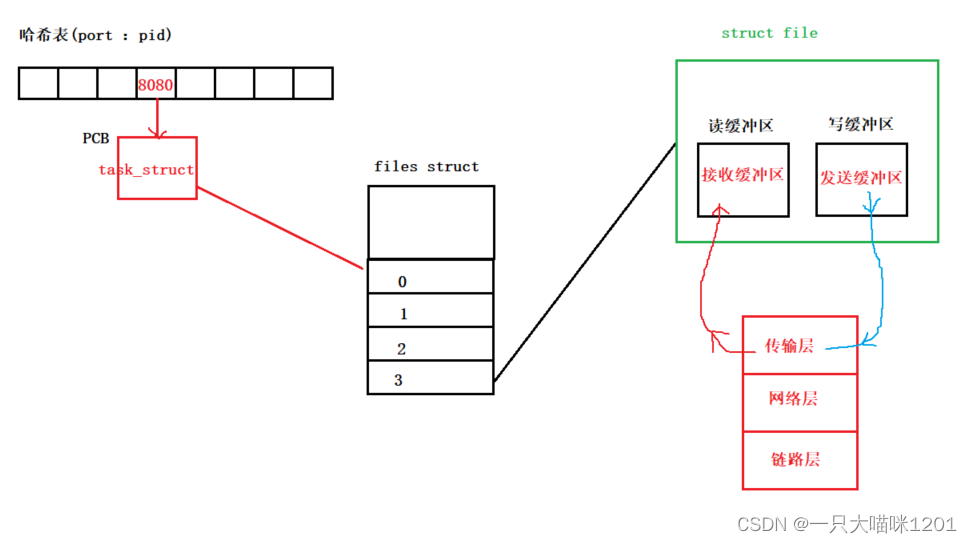
如上图所示,应用层协议本质上就是一个一个的进程,每一个进程都有
pid
,网络协议还有一个
port
,操作系统将网络通信进程的PCB用一个哈希表来维护。
- 以【port :pid】键值对的形式存放在哈希表中,其中
port是key值,pid是value。
在操作系统完成数据段的解包以后,会从这个哈希表中,根据TCP协议中的
目的port
查找对应
pid
值的PCB,这个PCB维护的文件描述符表中有一个
fd
指向的是一个套接字,如上图所示的3。
- 套接字本质上也是一个文件,所以也存在一个
struct file结构体,该结构体中的读写缓冲区其实就是TCP协议的接收和发送缓冲区。
然后将TCP层解包后的有效载荷放入找到的
struct file
的接收缓冲区中,如上图带箭头红色线条所示。此时就完成了分用,应用层像读取文件内容一样从
fd = 3
的文件中读取有效载荷(报文)即可。
发送的过程只是反过来而已,本喵不再详细讲解。
🥝可靠性
确认应答(ACK)机制
- TCP将每个字节的数据都进行了编号,即为序列号。
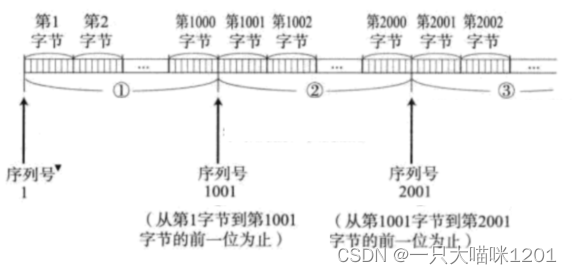
TCP数据段
char* udp[N]
本质上就是一个
char*
类型的数组,每个元素大小是一字节,TCP数据段就放在这个数组中,包括报头,选项以及有效载荷,所以数据段中的每个数据都有一个编号,就是数组的下标。
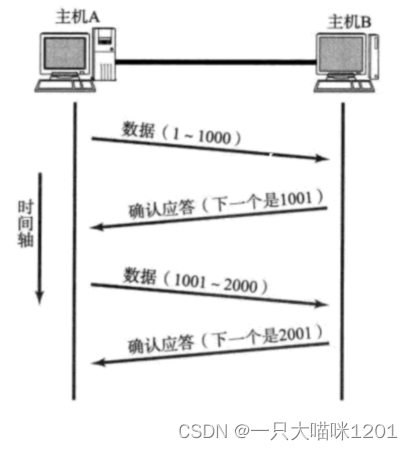
如上图所示,主机A和主机B使用TCP协议进行通信,主机A发送数据(1~1000),主机B收到后回复一个应答信号(AKC),其值是1001。
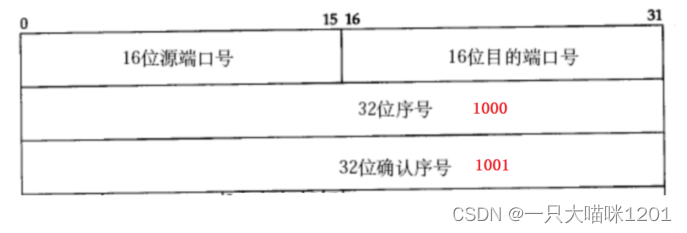
上面通信过程中,发送的数据编号范围是1~1000,所以主机A在发送数据的时候,将数字1000填入到报头中的32位序号中。
主机B在收到数据段以后,将1001作为确认序号填入到报头中的32位确认序号中,然后发送给主机A,此时发送的数据段中没有有效载荷,只有报头。
- 确认应答信号中只有TCP报头部分,没有有效载荷。
- 确认序号中的1001,表示主机B已经收到编号1001之前的所有数据。
- 主机A接收到确认应答后,下次发送数据就从编号位1001处开始。
主机A收到确认应答信号后,就可以保证刚刚发送的数据主机B收到了,并且下次发送从确认序号处开始发送即可。
ACK标志位:
那么主机A在收到主机B的应答信号后,如何确定这就是一个确认应答信号呢?它有没有可能是一个正常的数据段,但是并没有有效载荷呢?
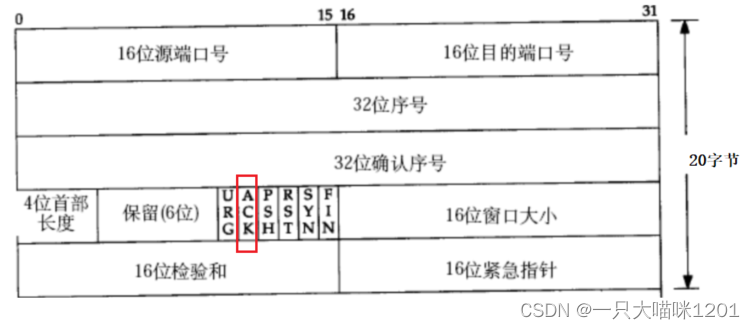
如上图所示,主机B在给主机A发送应答信号之前,除了会填充32位的确认序号外,还会将6个标志位的
AKC
置一。
当主机A收到确认应答信号后,发现
ACK
的状态是1,就知道这是一个确认应答信号,而不是一个普通的数据段,然后再区查看确认序号中的值,来判断刚刚发送的数据主机B是否完全收到了。
跟前前面主机A和主机B的通信示意图可以看到,在主机B给主机A发送了确认应答信号后,主机A没有任何表示,但是此时主机B就不知道它发送的应答信号主机A到底有没有收到。
- 确认应答机制只保证历史数据的可靠性,最新数据(确认应答)无法保证可靠性。
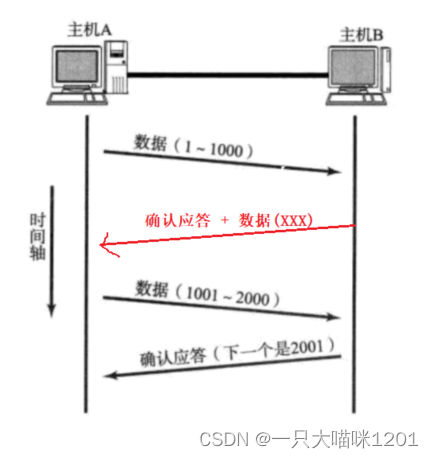
当主机A给主机B发送数据后,主机B收到了,并且也有数据给主机A发送,就可以将数据和确认应答信号作为一个数据段发送给主机A,如上图所示。
此时除了要将报头中的确认序号,ACK标志位填充外,还要将有效载荷拼接数据段中。
当主机A收到数据段以后,除了发现它是一个应答信号,确定对方收到了字节刚刚发送的数据,又发现它同样有有效载荷,此时的有效载荷就是主机B发送过了的数据。
为什么要有两组序号呢?一个是32位序号,一个是32位确认序号,只用一个不行吗?
答案是为了实现全双工,像上面本喵讲解的一样,主机B给主机A发送的数据段中不仅起确认应答作用,还有数据,如果此时只有一个组序号,主机A接收到数据段后就不能知道这个序号是确认序号还是数据的编号。
使用两组序号就将确认应答和数据的序号分离开了,互不影响,通信双方可以实现全双工通信。
超时重传机制
丢包:
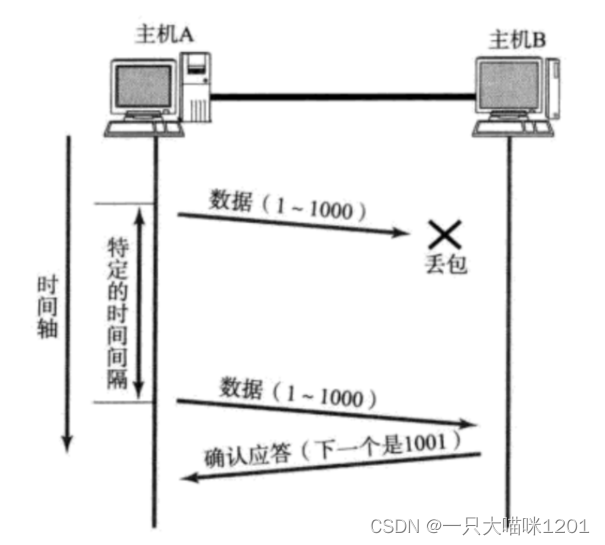
如上图所示,如果主机A给主机B发送数据之后,由于网络拥堵等原因,发生了丢包,导致数据无法到底主机B,所以主机B也不会给主机A一个应答信号。
- 如果主机A在一个特定时间间隔内没有收到B发来的确认应答,就会进行重发,这就是超时重传机制。
还有一种情况:丢应答
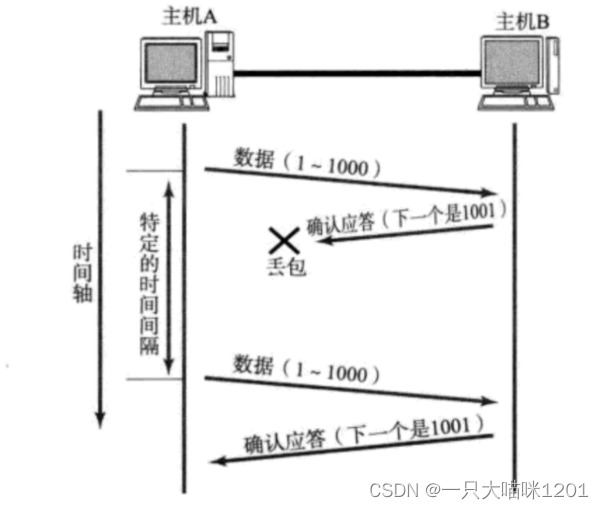
如上图所示,主机A未收到B发来的确认应答, 也可能是因为ACK丢失了,主机B其实是收到了数据的,但是此时主机A认为主机B没有收到,所以就会触发超时重传机制,主机A会再次重新发送刚刚数据。
因此主机B会收到很多重复数据,所以TCP协议需要能够识别出哪些包是重复的包,并且把重复的丢弃掉。
- 利用前面提到的序列号,就可以很容易做到去重的效果,这一切都是操作系统在做。
超时重传的中的超时又是如何确定呢?多长时间算是超时呢?
最理想的情况下,找到一个最小的时间,保证 “确认应答一定能在这个时间内返回”,但是这个时间的长短,随着网络环境的不同是有差异的。
如果超时时间设的太长,会影响整体的重传效率,如果超时时间设的太短, 有可能会频繁发送重复的包。
- TCP为了保证无论在任何环境下都能比较高性能的通信,因此会动态计算这个最大超时时间。
Linux中(BSD Unix和Windows也是如此),超时以500ms为一个单位进行控制,每次判定超时重发的超时时间都是500ms的整数倍。
如果重发一次之后,仍然得不到应答, 等待 2 * 500ms 后再进行重传,如果仍然得不到应答,等待 4 * 500ms 再进行重传。
以此类推,以指数形式递增,累计到一定的重传次数,TCP认为网络或者对端主机出现异常,强制关闭连接。
连接管理机制
这就是传说中的“三次握手,四次挥手”。
三次握手: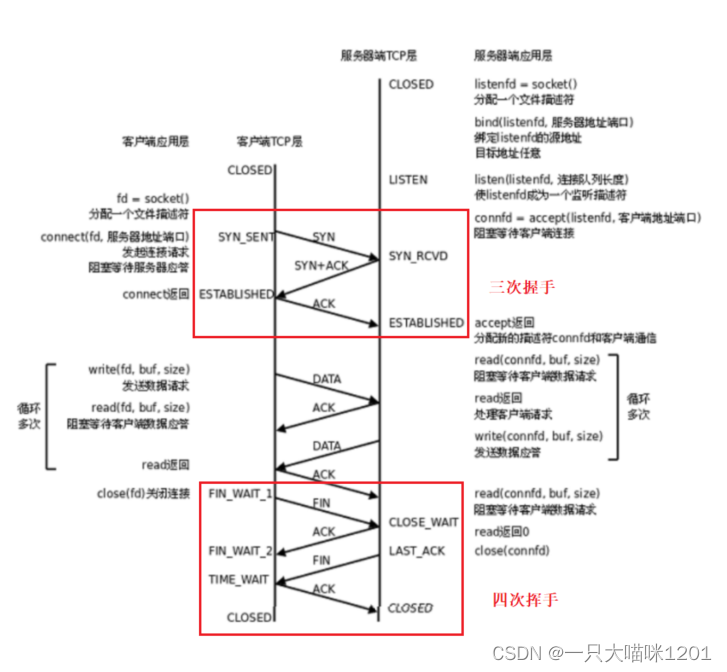
如上图所示就是使用TCP协议通信的整个流程。客户端使用
socket
创建套接字,服务端使用
socket
创建套接字,
bind
了端口号,并且
listen
了套接字,设置为监听状态。
- 第一次挥手:客户端给服务端发送数据段,没有数据,只有是将报头中的
SYN标志位置一,然后将只有报头的数据段发送给服务端,表示请求建立连接。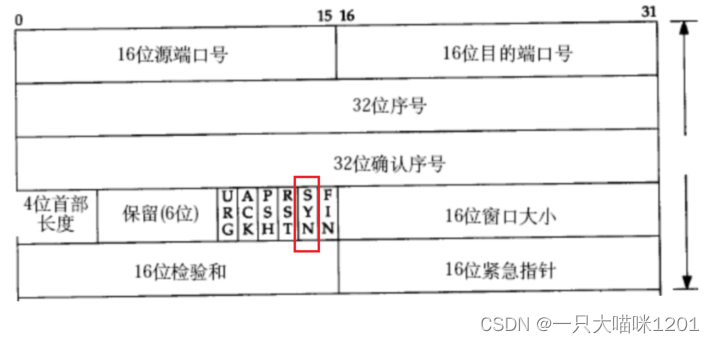 如上图所示,报头中六个标志位中的
如上图所示,报头中六个标志位中的SYN被置一,表示发起连接请求。所以当服务端收到客户端这个请求报文后,就知道三次挥手开始了。 - 第二次挥手:服务端在收到客户端的连接请求后,返回应答信号和连接请求,表示同意并且建立连接。
此时的数据段中同样没有数据,只有报头,并且六个标志位中的
ACK
和
SYN
被置一,其中
ACK
是作为客户端发起连接请求的确认应答信号,
SYN
是服务端向客户端发起的连接请求。
- 第三次握手:客户端收到服务器端的数据段后,将套接字的状态设为
ESTABLISHED,正式建立连接,并且再给服务端一个ACK信号。
在客户端收到服务器的数据段后,根据
ACK
标志位知道了服务器收到了自己的连接请求,再根据
SYN
标志位知道了服务器向自己也发起了连接请求,那么自己就可以正式建立连接了,然后再给服务端一个应答信号,让服务端也建立连接。
服务端收到这个最后应答信号后,便知道客户端已经建立好连接了,自己也将套接字设置为
ESTABLISHED
状态,表示连接建立。
- 当客户端使用了
connect系统调用后,三次挥手就被发起了。- 当服务端使用了
accept系统调用后,三次挥手的请求就被接收到了,并且开始进行后续动作。- 三次挥手的过程完全由操作系统来维护。
此时服务端和客户端双方的套接字都是
ESTABLISHED
状态,双方正式连接连接。
- 根据三次挥手示意图中可以看到,双方建立连接的过程中,客户端比服务端先建立连接。
- 双方建立连接存在一个时间差,申请者先建立。
为什么就必须得是三次握手?一次握手行不行,两次呢?四次呢?
假设现在一次握手就可以建立连接:
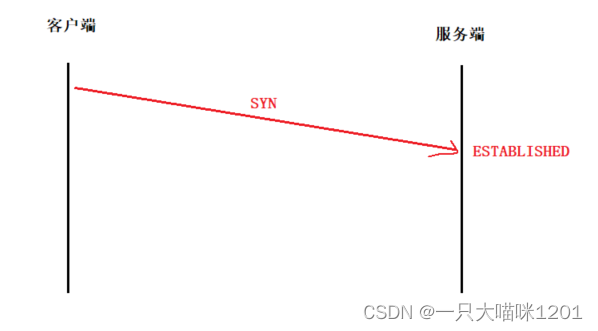
如上图所示,当客户端发出带有
SYN
标志位的数据端后,服务端收到后便建立连接,将套接字设置为
ESTABLISHED
状态。
如果此时客户端发送了连接请求,并且自己没有建立连接,自己的系统中并没有建立用来连接套接字,那么服务端就相当于维护着一个完全没有用处的套接字,白白占用系统资源。
如果此时的客户端是一个不法份子,他就可以频繁的向服务端发起三握手手请求,并且自己不建立连接,只让服务端建立连接,那么服务端的系统资源很快就被占用完,服务端也就奔溃了。
- 这种现象被叫做SYN洪水。
再假设现在两次握手建立连接:
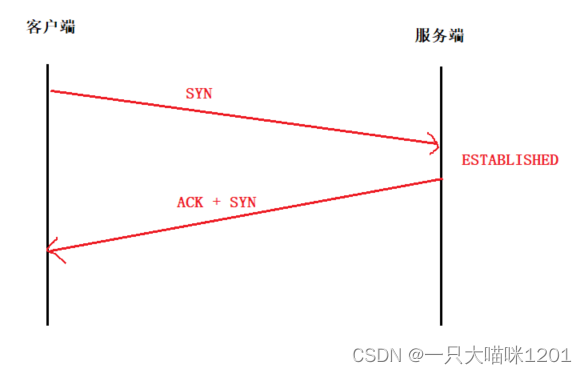
如上图所示,客户端向服务端发起三次握手请求,服务端收到后建立了连接,并且给客户端发送了
ACK
应答信号和
SYN
连接请求,让客户端也建立连接。
但是客户端在收到服务端的数据端后选择了忽略,并不建立连接。
如果客户端同样频繁发起三次握手请求,并且忽略服务端返回的数据端,那么同样会发送SYN洪水。
三次握手:
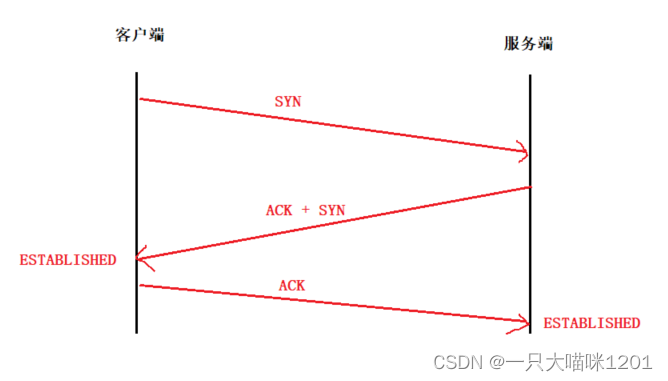
当客户端发起三次握手请求后,服务端收到以后并没有第一时间建立连接,而是给客户端确认应答,并且也向客户端发起连接请求。
客户端在收到服务端的数据段后,需要先建立连接,然后再向服务端发送确认应答,表示自己已经建立好了连接。
服务端在收到应答信号后,知道客户端已经建立了连接,自己再建立连接。
- 三次握手能够保证,服务端在连接连接的时候,客户端已经建立好了连接。
所以如果是单一的客户端发起
SYN洪水
,那么客户端需要和服务端付出同等的代价,都需要建立连接。一般情况下,服务端的配置比客户端会高,所以客户端耗不过服务端自己就先奔溃了。
如果有多台客户端向同一台服务端发起SYN洪水攻击,那么服务端也是扛不住的,但是这种安全问题就不是TCP协议该管的事情,TCP仅能做的事情就是让自己的机制没有漏洞。
- 三次握手可以有效防止单一客户端向服务端发起攻击。
在三次握手的过程中,客户端证明了自己有发送和接收数据的能力,服务端也证明了自己有发送和接收数据的能力。
- 三次握手可以用最小的成本验证客户端和服务端之间的全双工通信信道是通畅的。
这一点,一次握手和两次握手都无法验证。
至于四次握手,五次握手等等更多次的握手根本就没有必要去用,因为三次握手能解决问题就没有必要用更多次的握手。
- 三次握手不一定非得成功,最担心的其实是最后一个
ACK丢失,但是有配套的解决方案,就是超时重传机制。- 三次握手最重要的是建立了连接结构体,这些结构体同样被操作系统采用先描述再组织的方式管理了起来。
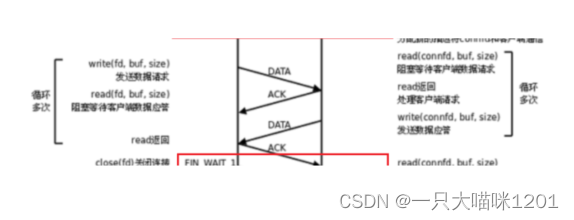
四次挥手:

当客户端使用
close
系统调用后,就向服务端发起了四次挥手请求,四次挥手的作用是断开连接。
- 第一次挥手:客户端向服务端发送数据段,同样没有数据,只是将
FIN标志位置一,表示要断开连接。 - 第二次挥手:服务端收到客户端断开连接的请求后,将自己的套接字设置为
CLOSE_WAIT状态,然后给客户端发送确认应答信号。
客户端收到服务端的确认应答信号后,知道了服务端已经收到了自己四次挥手断开连接的请求,然后开始等待服务器的
FIN
信号。
- 第三次挥手:服务器的套接字处于
CLOSE_WAIT状态时,同样要向客户端发送断开连接的请求,所以向客户端发送带有FIN信号的数据段。
通信是双方的事,不能客户端说断开连接就断开连接,只有双方都发起过断开连接的请求
FIN
,连接才能断开。
- 第四次挥手:客户端收到服务端发来的
FIN数据后,知道了服务端也要断开连接,此时将自己的套接字设置为TIME_WAIT状态,然后给服务端发送确认应答。
客户端收到服务端发来的断开连接请求后,并没有第一时间断开,而是先将状态设置为
TIME_CLOSE
状态,等待一段时间后再断开连接。
服务端收到客户端的第四次挥手应答信号后,知道了客户端已经收到了自己断开连接的请求,所以就将自己的套接字关闭了。
- 发起四次挥手的一方,最后的状态是
TIME_WAIT。- 被动断开连接的一方,两次挥手完成后会进入
CLOSE_WAIT状态。
- TCP协议中,通信双方的地方是对等的,发起四次挥手以及三次握手有可能是任何一方。
在三次握手和四次挥手之间,就是双方在进行通信,采用的是确认应答机制,如上图所示。
理解TIME_WAIT状态
为什么客户端在发起四次挥手请求到完成后并没有第一时间断开连接而是等待一段时间呢?
- 保证最后一个ACK尽可能的被对方收到,如果对应没有收到会触发超时重传机制,此时未完全关闭的套接字还可以重写发送ACK信号。
- 双方在断开连接的时候,网络中还有滞留的报文,要保证滞留报文进行撤销(教材中的理由)。
从
TIME_WAIT
到
CLOSED
之间维持的时间是多久呢?
- MSL:通信数据段从一方到另一方花费的最长时间称为MSL。
这个维持的时间是 2 * MSL,这段时间能够保证服务端触发一次超时重传,并且客户端做出一次应答,正好是两次传送数据的时间。
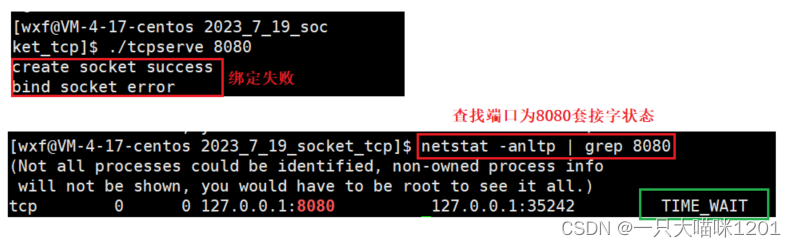
如上图,在写前面写套接字代码的时候,服务端绑定了一个端口后,进行网络通信,然后使用
ctrl + c
将服务端服务进程结束。
然后再运行,也就是重启服务端,绑定相同的端口,但是此时就会出现
bind error
错误,无法绑定,服务器也就重启失败。
- 服务端进程结束,服务端主动断开连接,它会有一段时间处于
TIME_WAIT状态,套接字没有完全关闭。- 再次运行时无法绑定还没有关闭的套接字。
在绑定失败后,查看失败端口号
8080
的网络状态,可以看到,该套接字的状态是
TIME_CLOSE
状态,这个状态一般会维持4分钟,也就是两个
MSL
时间。
这样其实也存在很大危害,如果在618当天,淘宝服务器突然奔溃了,需要立刻重启,但是需要等待两个
MSL
时间(大概4分钟),在这段时间内,已经和服务器建立连接的客户端就会因为超时而断开连接,那么造成的损失是不可估量的。
解决方法:
使用系统调用
setsockopt()
设置socket描述符的选项
SO_REUSEADDR
为1,此时就可以立刻重新绑定之前的端口号了。
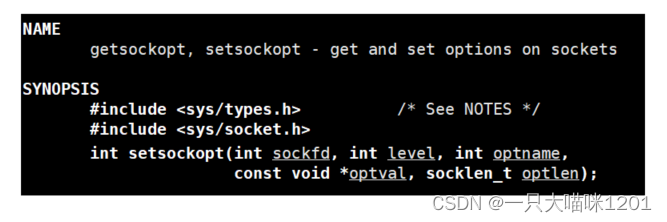

如上图红色框中代码所示,在
bind
套接字之前,使用
setsockopt
将
SO_REUSEADDR
设置为1。
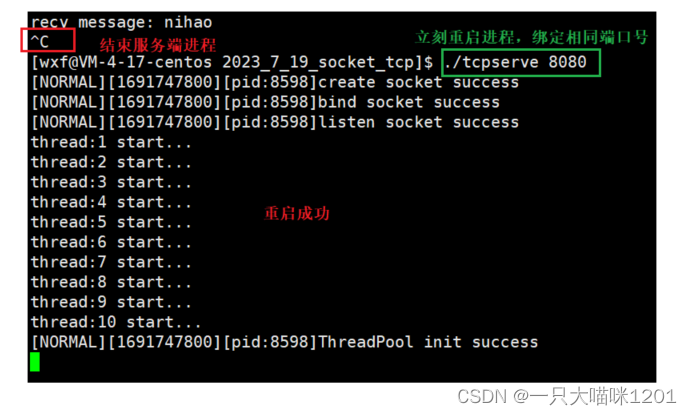
如上图所示,使用
ctrl + c
结束服务端进程后,可以立刻重新启动,并且绑定之前的端口号
8080
。
但是这样就有可能导致数据丢失等问题,所以还要结合具体情况来使用。
理解CLOSE_WAIT状态

如上图代码所示,在前面写的使用TCP协议的HTTP应用程序中,服务端不执行
close
,也就是说,即使客户端断开连接,服务端也不会关闭套接字。
- 在TCP协议中,对应着客户端发起四次挥手请求,服务端给确认应答信号。
- 但是服务没有发出
FIN信号,没有请求断开连接,也就是从第三次和第四次挥手没有了。
根据上面通信流程示意图,此时服务端的套接字就会维持在
CLOSE_WAIT
状态。
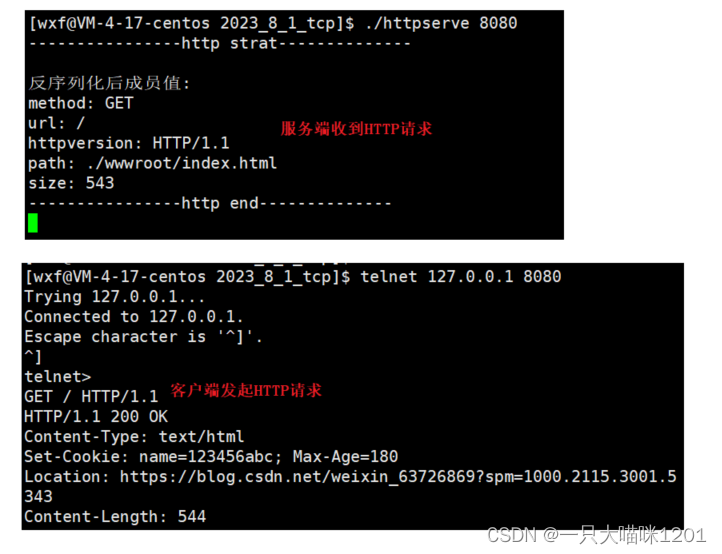
如上图所示,运行服务端进程后,客户端发起HTTP请求,服务端收到了客户端的请求报文。

此时查看当前机器上
httpserver
套接字的状态,可以看到,一个是监听状态
LISTEN
,一个是建立连接状态
ESTABLISHED
,连接状态的套接字是用来进行通信的。
- 此时将客户端的套接字关闭,也就是退出。

此时再次查看服务器套接字状态,可以看到,用来进行通信的套接字状态未
CLOSE_WAIT
。
根据上面现象我们知道,当一段发起四次挥手断开连接后,另一端必须也要发起
FIN
断开连接请求,也就是调用
close
系统调用,否则无法断开连接,就会存在
CLOSE_WAIT
状态的套接字,占用系统资源。
🏺总结
这篇文章介绍了UDP的全部内容,比较简单,还有TCP的部分内容,其他维护可靠性的机制再下篇文章中本喵再详细介绍。
版权归原作者 一只大喵咪1201 所有, 如有侵权,请联系我们删除。