
Spark概述
1. Spark是什么
Spark 基于内存式计算的分布式的统一化的数据分析引擎
2. Spark 模块
Spark 框架模块包含:Spark Core、Spark SQL、Spark Streaming、Spark GraphX、 Spark MLlib,而后四项的能力都是建立在核心引擎之上。
3.Spark 四大特点
Spark使用Scala语言进行实现,它是一种面向对象、函数式编程语言,能够像操作本地集合一样轻松的操作分布式数据集。Spark具有运行速度快、易用性好、通用性强和随处运行等特点。
运行速度快:Spark支持内存计算
Spark处理数据与MapReduce处理数据相比,有如下3个不同点:
MapReduce Spark
计算流程结构 Map和Reduce的结果都必须进入磁盘 支持DAG,一个程序中可以有多个Map、Reduce过程,多个Map之间的操作可以直接在内存中完成
中间结果存储 磁盘 不经过Shuffle的中间处理结果数据直接存储在内存中
Task运行方式 进程(Process):MapTask、ReduceTask 线程(Thread):所有Task都以线
4.Spark 运行模式
Spark 框架编写的应用程序可以运行在本地模式(Local Mode)、集群模式(Cluster Mode)和云服务(Cloud),方便开发测试和生产部署。
集群模式:
1.Hadoop YARN集群模式(生产环境使用):运行在 yarn 集群之上,由yarn负责资源管理,Spark负责任务调度和计算,好处:计算资源按需伸缩,集群利用率高,共享底层存储,避免数据跨集群迁移。
2.Spark Standalone集群模式(开发测试及生成环境使用):类似Hadoop YARN架构,典型 的Mater/Slaves模式,使用Zookeeper搭建高可用,避免Master是有单点故障的。
3.Apache Mesos集群模式(国内使用较少):运行在mesos资源管理器框架之上,由mesos 负责r任务调度和计算
5.Spark中的宽窄依赖
- 依赖关系
RDD会不断进行转换处理,得到新的RDD,每个RDD之间就产生了依赖关系。
例如:A调用转换算子产生了B,那么我们称A为父RDD,称B为子RDD
2.宽窄依赖
窄依赖 (Narrow Dependencies):父RDD的一个分区的数据只给了子RDD的一个分区【不用调用分区器】
宽依赖 (Wide/Shuffle Dependencies):父RDD的一个分区的数据给了子RDD的多个分区【需要调用Shuffle的分区器来实现】
设计对RDD的宽窄依赖标记的好处
1.提高数据容错的性能,避免分区数据丢失时,需要重新构建整个RDD
场景:如果子RDD的某个分区的数据丢失
不标记:不清楚父RDD与子RDD数据之间的关系,必须重新构建整个父RDD所有数据
标记了:父RDD一个分区只对应子RDD的一个分区,按照对应关系恢复父RDD的对应分区即可
2.提高数据转换的性能,将连续窄依赖操作使用同一个Task都放在内存中直接转换
场景:如果RDD需要多个map、flatMap、filter、reduceByKey、sortByKey等算子的转换操作
不标记:每个转换不知道会不会经过Shuffle,都使用不同的Task来完成,每个Task的结果要保存到磁盘
标记了:多个连续窄依赖算子放在一个Stage中,共用一套Task在内存中完成所有转换,性能更快
Scala部署安装步骤
1.在网页上运行Scala
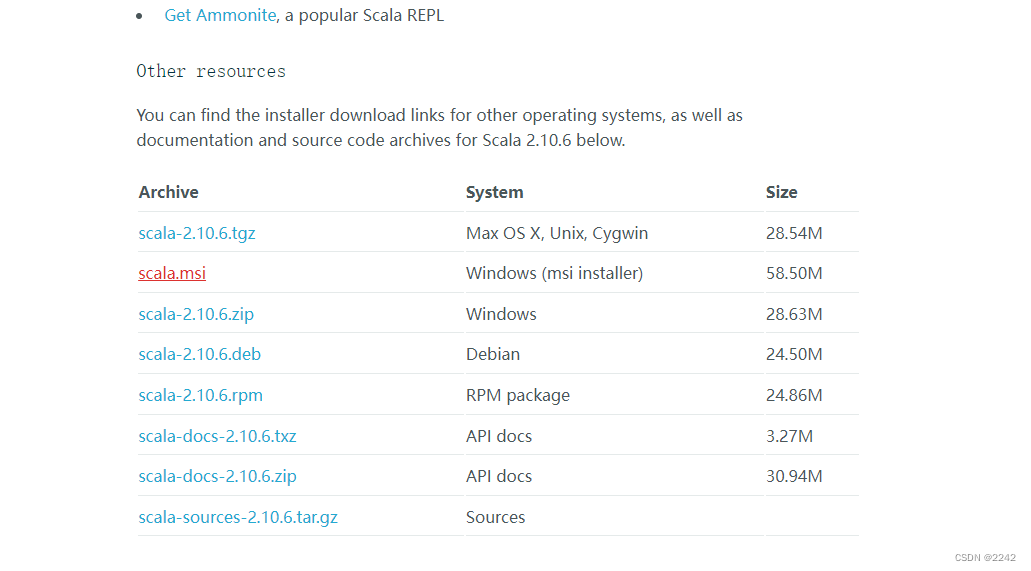
下载地址:https://www.scala-lang.org/download/all.html 进入官网后选择Scala 2.10.6版本

2.下载Scala.msi版本
3.解压文件
tar -zxvf scala-2.10.6.tgz
4.安装好之后点一直点next
5.配置环境变量 依次点击“计算机”--“属性”--“高级系统设置”--“环境变量” 选择,选择“path"变量 添加如下路径

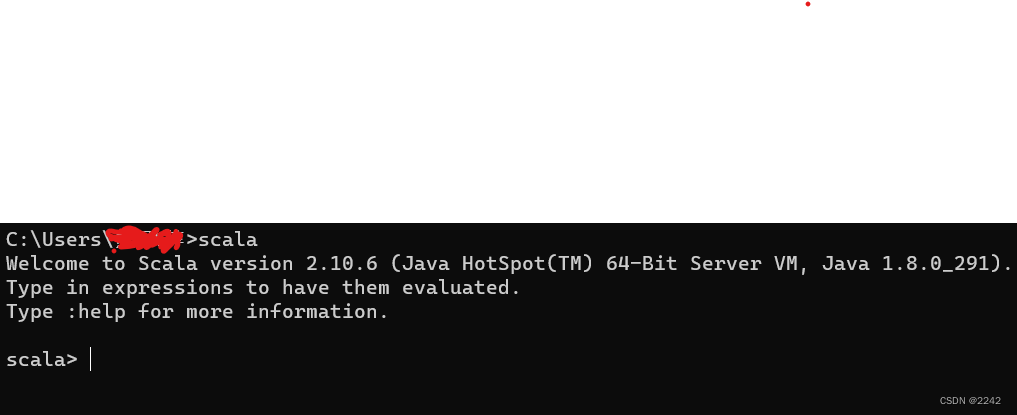
6.验证打开cmd命令行,输入scala
版权归原作者 2242 所有, 如有侵权,请联系我们删除。