
在之前的文章中,我们学习了如何在spark中使用RDD方法的map,sortby,collect。想了解的朋友可以查看这篇文章。同时,希望我的文章能帮助到你,如果觉得我的文章写的不错,请留下你宝贵的点赞,谢谢。
Spark-Scala语言实战(7)-CSDN博客文章浏览阅读802次,点赞22次,收藏8次。今天开始的文章,我会带给大家如何在spark的中使用我们的RDD方法,今天学习RDD方法中的map,sortby,collect三种方法。希望我的文章能帮助到大家,也欢迎大家来我的文章下交流讨论,共同进步。https://blog.csdn.net/qq_49513817/article/details/137143284?今天的文章,我会继续带着大家如何在spark的中使用我们的RDD方法,今天学习RDD方法中的flatMap,take,union三种方法。
一、知识回顾
昨天我们学习了RDD的三种方法,分别是map,sortby,collect。
其中map的作用是转换操作
它会转化成一个新的RDD
其次就是sortby,它可以对我们RDD中的元素进行排序

当然,升序降序都是我们可以通过参数自行设置的
最后就是我们的collect,它的作用是将数据转化成数组
现在复习完毕,开始今天的学习吧
二、RDD方法
1.flatMap
- flatMap()方法将函数参数应用于RDD之中的每一个元素,将返回的迭代器(如数组、列表等)中的所有元素构成新的RDD。
- 使用flatMap()方法时先进行map(映射)再进行flat(扁平化)操作,数据会先经过跟map一样的操作,为每一条输入返回一个迭代器(可迭代的数据类型),然后将所得到的不同级别的迭代器中的元素全部当成同级别的元素,返回一个元素级别全部相同的RDD。
- 这个转换操作通常用来切分单词。
例:
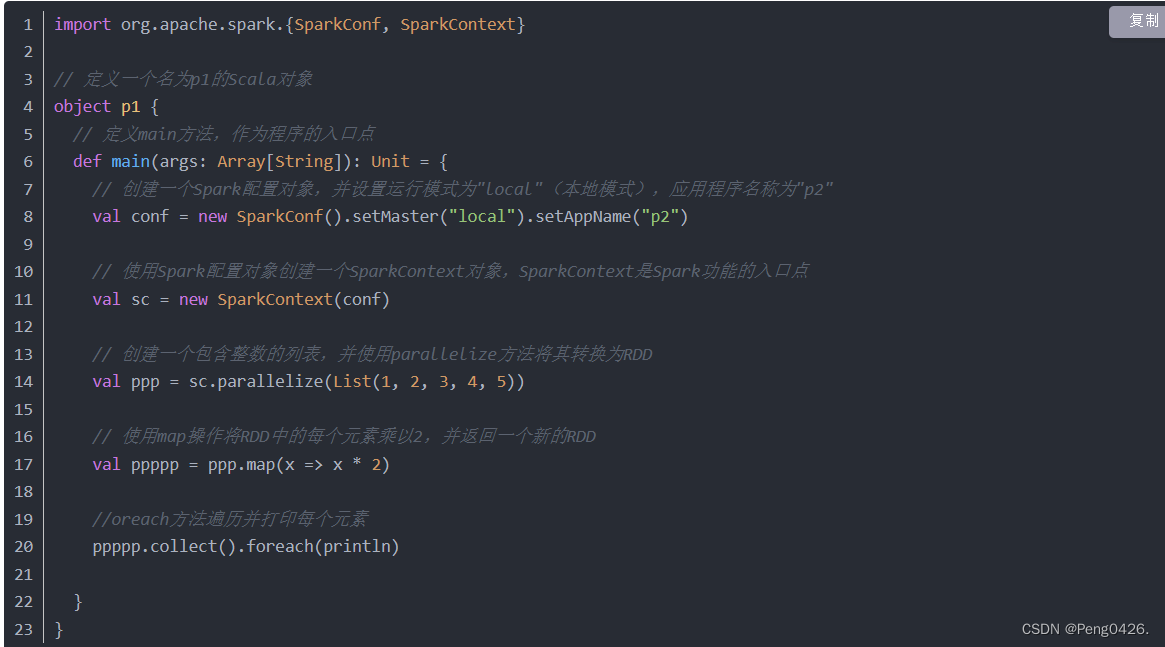
import org.apache.spark.{SparkConf, SparkContext}
object p1 {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setMaster("local").setAppName("p2")
val sc=new SparkContext(conf)
// 创建一个包含字符串的列表,并将其转换为RDD
val ppp = List("1,2,3", "4,5,6", "7,8,9")
val rdd = sc.parallelize(ppp)
// 定义一个函数来拆分字符串并返回数字列表
def ppppp(s: String): List[Int] = {
s.split(",").map(_.toInt).toList
}
val pppp = rdd.flatMap(ppppp)
val pppppp = pppp.collect()
pppppp.foreach(println)
}
}
可以看到,我们的代码预期效果就是用flatMap方法将列表中三个字符串给拆分,那么运行看看效果吧
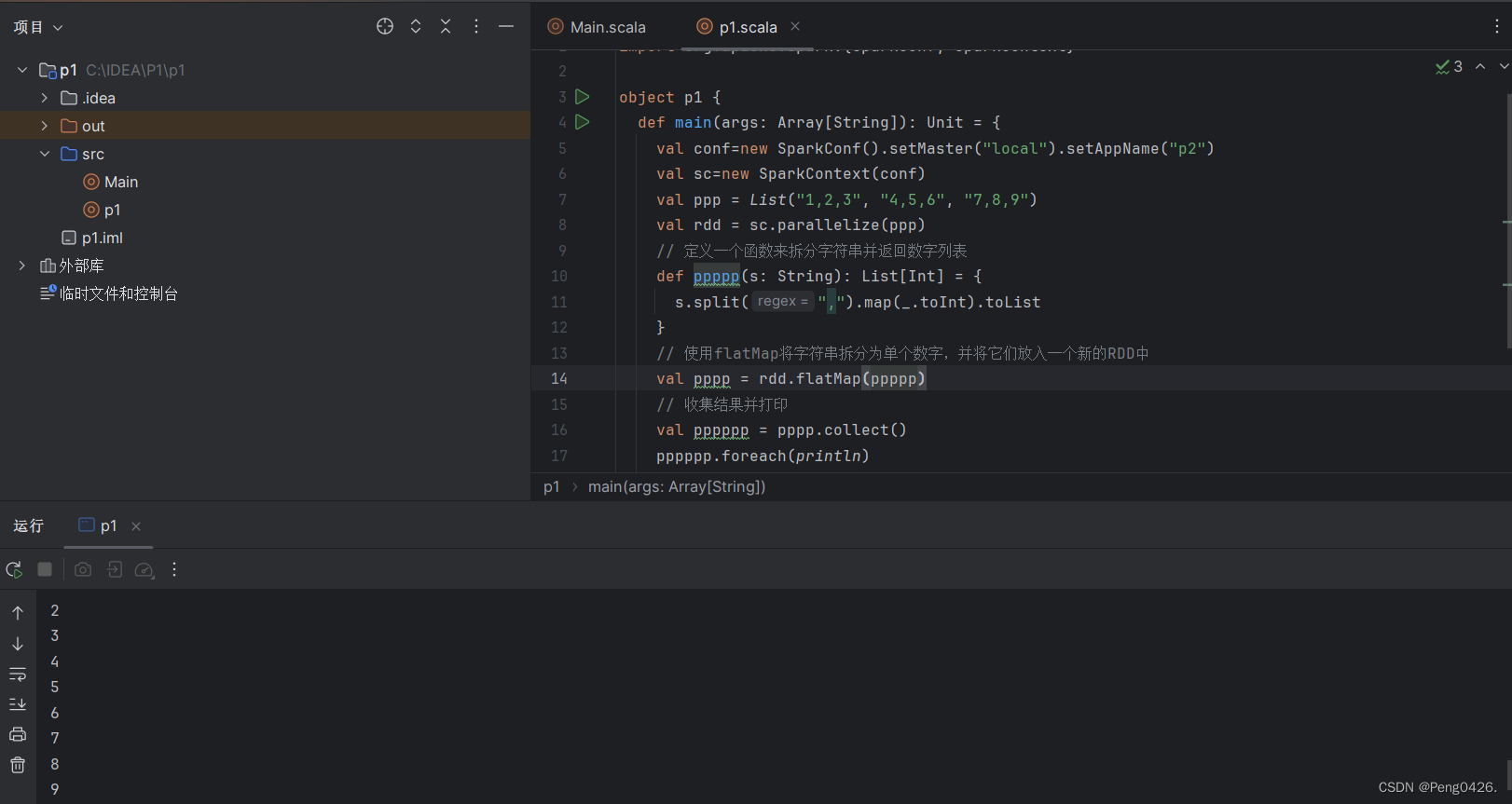
可以看到输出结果,成功拆分
2.take
- take(N)方法用于获取RDD的前N个元素,返回数据为数组。
- take()与collect()方法的原理相似,collect()方法用于获取全部数据,take()方法获取指定个数的数据。
例:
import org.apache.spark.{SparkConf, SparkContext}
objectp1{
defmain(args: Array[String]): Unit = {
val conf=newSparkConf().setMaster("local").setAppName("p2")
val sc=newSparkContext(conf)
// 创建一个包含一些数字的RDDval p = sc.parallelize(Seq(1, 2, 3, 4, 5, 6, 7, 8, 9, 10))
// 使用take操作取出前3个元素val pp = p.take(3)
// 打印取出的元素
pp.foreach(println)
}
}
看我们的代码,可以知道我们要用take方法取出我们前三个元素,那么就应该是元素 1,2,3,那么现在运行代码看下是否输出这些值。
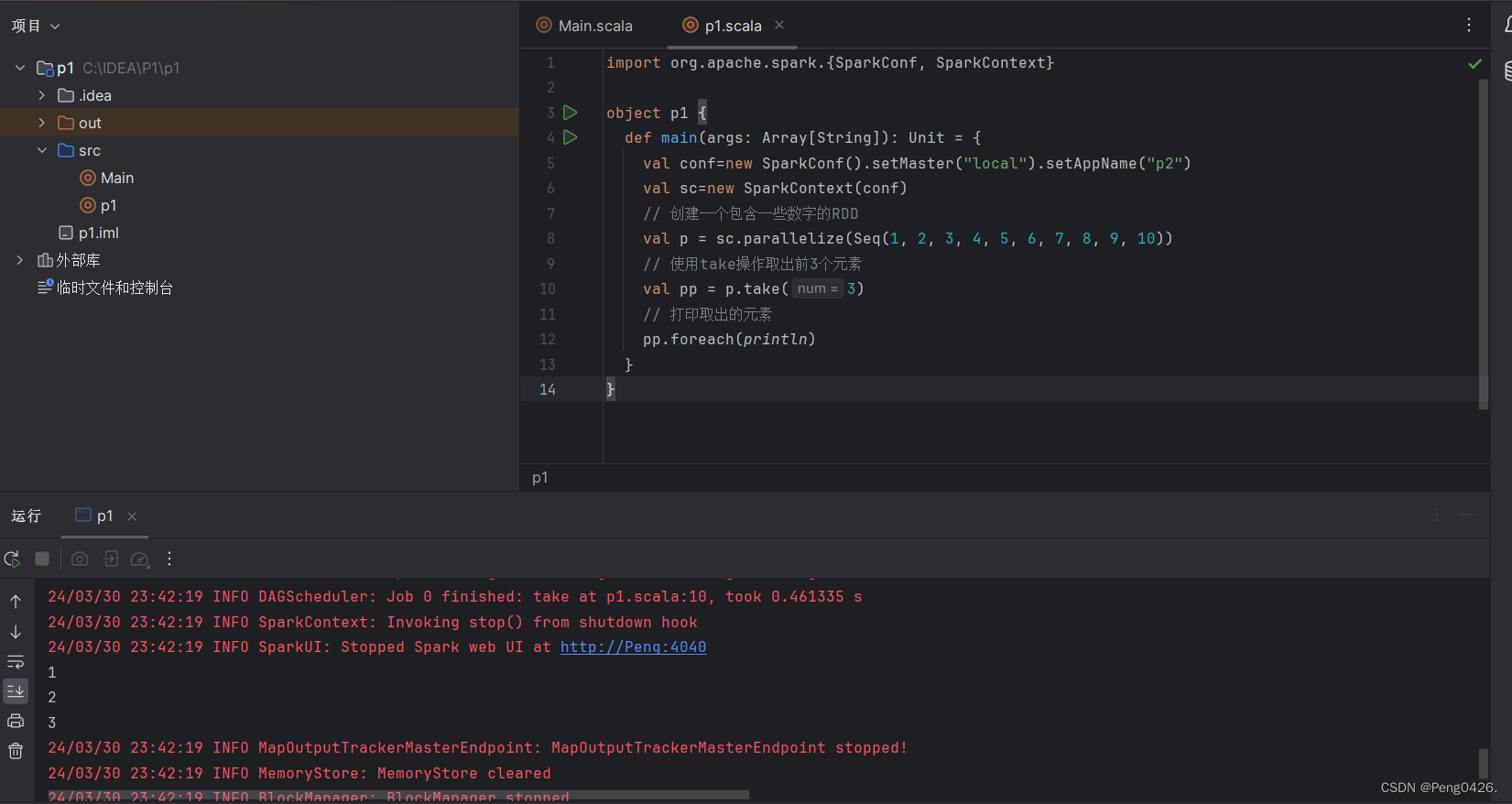 可以看到成功输出1,2,3,代码正确,快去尝试吧~
可以看到成功输出1,2,3,代码正确,快去尝试吧~
3.union
- union()方法是一种转换操作,用于将两个RDD合并成一个,不进行去重操作,而且两个RDD中每个元素中的值的个数、数据类型需要保持一致。
- 使用union()方法合并两个RDD。
例:
import org.apache.spark.{SparkConf, SparkContext}
objectp1{
defmain(args: Array[String]): Unit = {
val conf=newSparkConf().setMaster("local").setAppName("p2")
val sc=newSparkContext(conf)
// 创建第一个RDDval p1 = sc.parallelize(Seq(1, 2, 3))
// 创建第二个RDDval p2 = sc.parallelize(Seq(4, 5, 6))
// 使用union操作合并两个RDDval ppp = p1.union(p2)
// 收集结果并打印val ppppp = ppp.collect()
ppppp.foreach(println)
}
}
可以看到代码预期效果是使用union方法将p1与p2合并,那么ppppp输出的应该是123456,那么来运行试试吧

可以看到成功输出123456。
注意,union合并需要两个数据类型相同,否则会报错
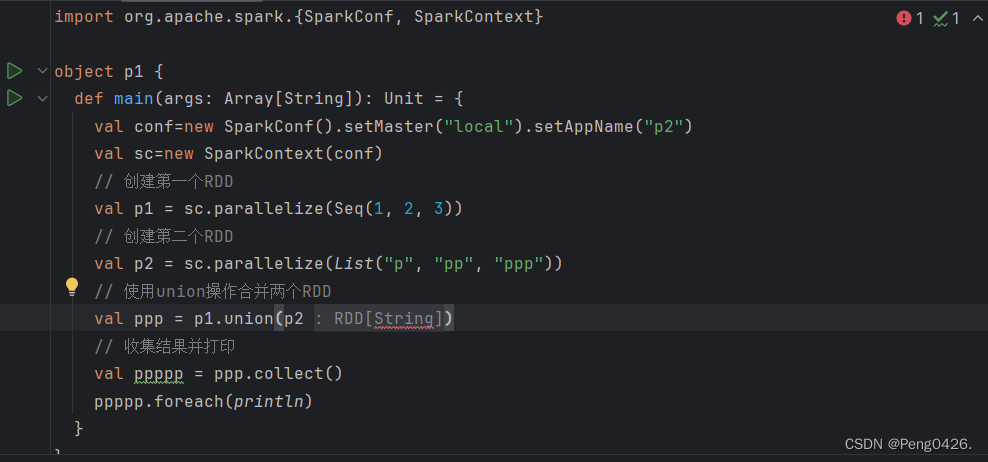
一个字母,一个数字,是肯定不行的
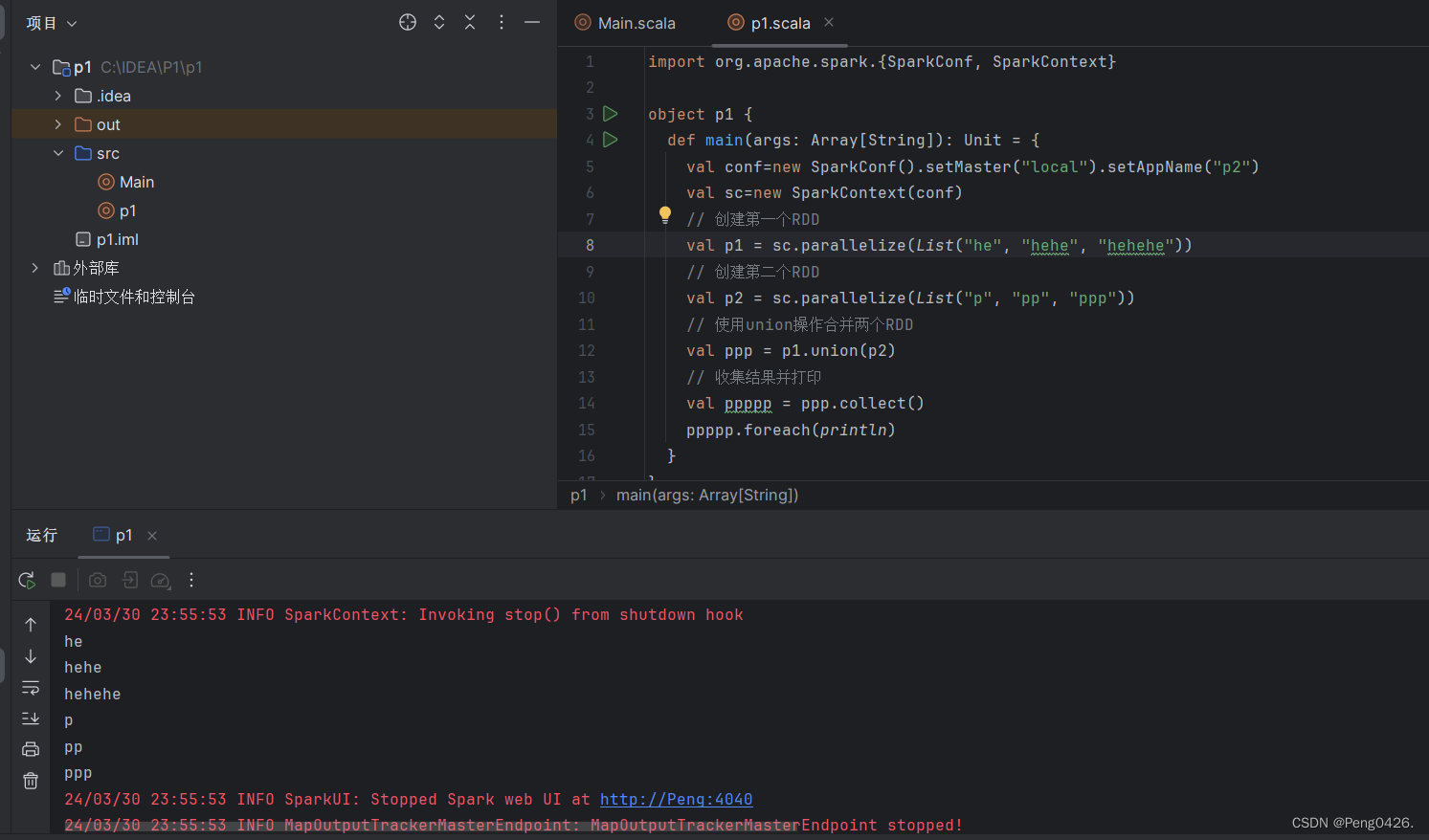
如果这样全是字母,就可以,快去动手试试吧~
拓展- 方法参数设置
1.方法参数
方法参数描述与效果
map
func
(函数)对RDD中的每个元素应用函数
func
,返回一个新的RDD。每个元素都会根据
func
定义的规则进行转换。
sortBy
keyfunc
(函数,可选),
ascending
(布尔值,可选,默认为True),
numPartitions
(整数,可选)根据
keyfunc
指定的键对RDD中的元素进行排序,返回一个新的RDD。
ascending
决定排序方向,
numPartitions
决定输出RDD的分区数。未指定
keyfunc
时,默认按照元素本身排序。
collect
无将RDD中的所有元素收集到驱动程序中,并返回列表。这对于获取RDD的全部内容并在驱动程序中处理非常有用,但请注意,对于大RDD可能会导致性能问题。
flatMap
func
(函数)对RDD中的每个元素应用函数
func
,并将返回的所有元素“压平”成一个新的RDD。这常用于将嵌套结构的数据扁平化。
take
num
(整数)从RDD的开头返回前
num
个元素。这可以用于获取RDD的部分数据,而不必处理整个RDD。
union
other
(另一个RDD)返回两个RDD的并集。这不会删除重复的元素,因此如果两个RDD中有相同的元素,它们都会在结果RDD中出现。
2.
sortBy
参数设置
参数描述效果
keyfunc
(函数,可选)指定用于排序的键的函数。如果未指定
keyfunc
,
sortBy
将默认按照RDD中的元素本身进行排序。如果指定了
keyfunc
,则
sortBy
将按照
keyfunc
处理后的结果对RDD中的元素进行排序。例如,如果RDD的元素是元组,你可以通过
keyfunc
来指定按照元组的某个字段进行排序。
ascending
(布尔值,可选,默认为True)指定排序方向。如果
ascending
为True,则按照升序排序;如果为False,则按照降序排序。这允许你根据需要选择正序或倒序排列RDD中的元素。
numPartitions
(整数,可选)指定输出RDD的分区数。这个参数决定了排序后RDD的分区数。如果未指定,则排序后的RDD的分区数通常与原始RDD的分区数相同。分区数的设置会影响排序操作的并行度和性能,因此在实际应用中需要根据集群资源和任务需求进行合理设置。
版权归原作者 Peng0426. 所有, 如有侵权,请联系我们删除。