
1、使用distinct去重
distinct用来查询不重复记录的条数,用
count(distinct id)
来返回不重复字段的条数。用法注意:
- distinct【查询字段】,必须放在要查询字段的开头,即放在第一个参数;
- 只能在SELECT 语句中使用,不能在 INSERT, DELETE, UPDATE 中使用;
- DISTINCT 表示对
后面的所有参数的拼接取不重复的记录,即查出的参数拼接每行记录都是唯一的 - 不能与all同时使用,默认情况下,查询时返回的就是所有的结果。
distinct支持单列、多列的去重方式。
- 作用于单列- 单列去重的方式简明易懂,即相同值只保留1个。
selectdistinct name from A //对A表的name去重然后显示 - 作用于多列- 多列的去重则是根据指定的去重的列信息来进行,即只有所有指定的列信息都相同,才会被认为是重复的信息。- 注意,distinct作用于多列的时候只在开头加上即可,并不用每个字段都加上。distinct必须在开头,在中间是不可以的,会报错,`select id,distinct name from A //错误
selectdistinct id,name from A //对A表的id和name去重然后显示 - 配合count使用
selectcount(distinct name)from A //对A表的不同的name进行计数 - 按顺序去重时,
order by 的列必须出现在 distinct 中- 出错代码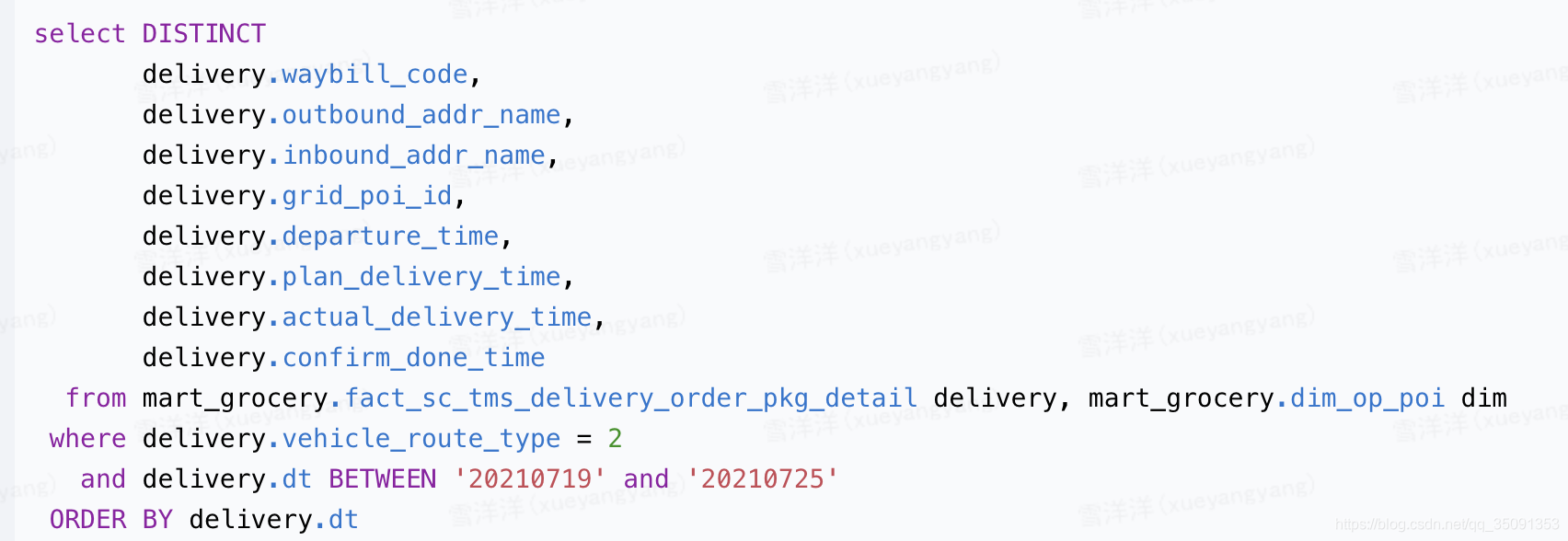 - 改正后的代码
- 改正后的代码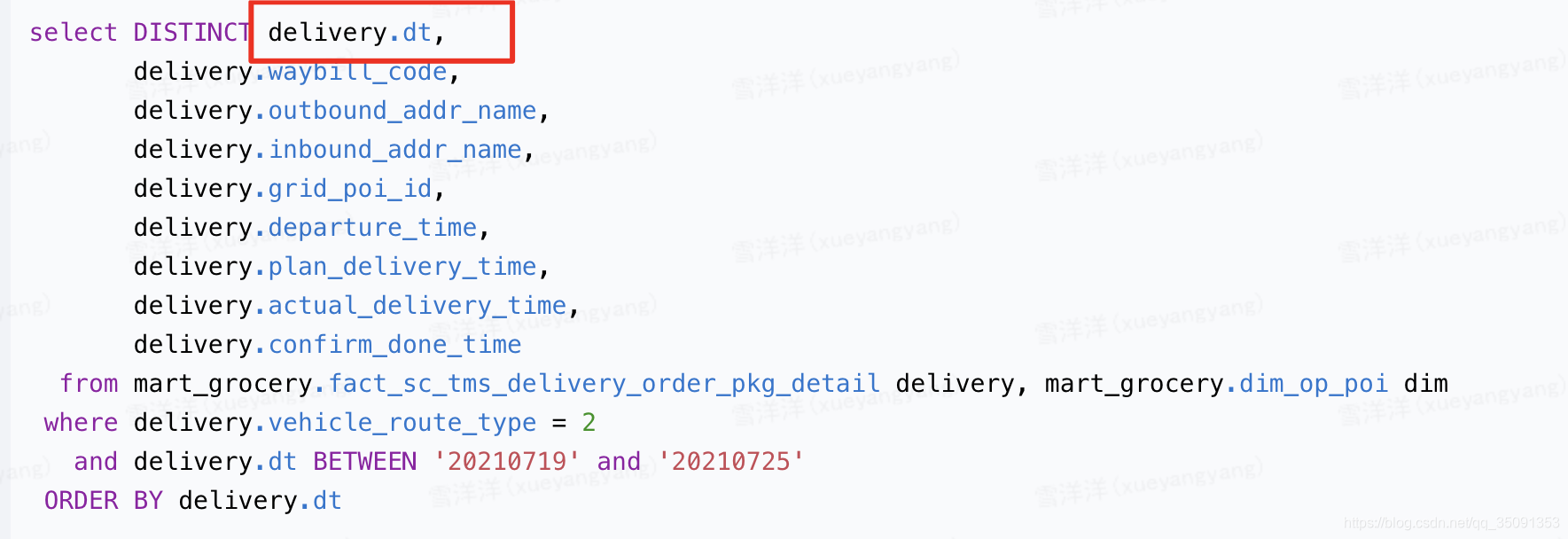 - 讨论:若不使用Distinct关键字,则order by后面的字段不一定要放在seletc中
- 讨论:若不使用Distinct关键字,则order by后面的字段不一定要放在seletc中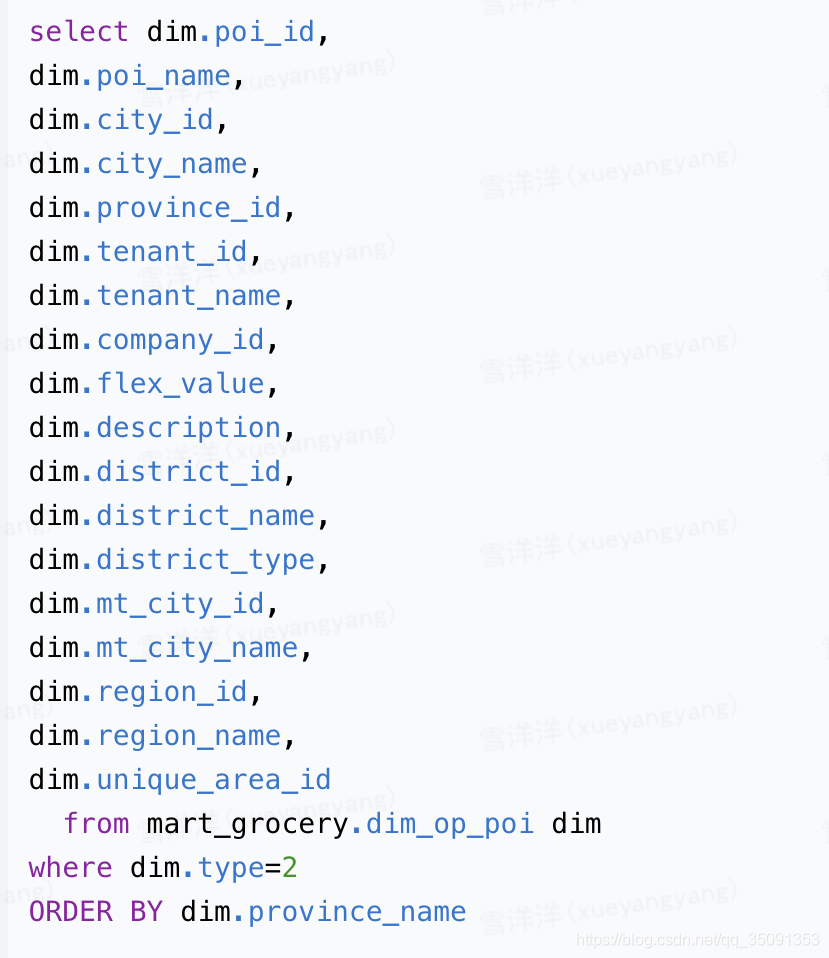
MySQL中使用去重distinct方法的示例详解
【Hive】数据去重
2、使用group by
GROUP BY 语句根据一个或多个列对结果集进行分组。在分组的列上我们可以使用 COUNT, SUM, AVG,等函数,形式为
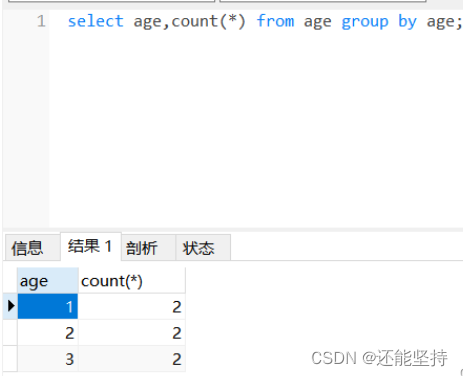
select 重复的字段名 from 表名 group by 重复的字段名;
- group by 对age查询结果进行了分组,自动将重复的项归结为一组。
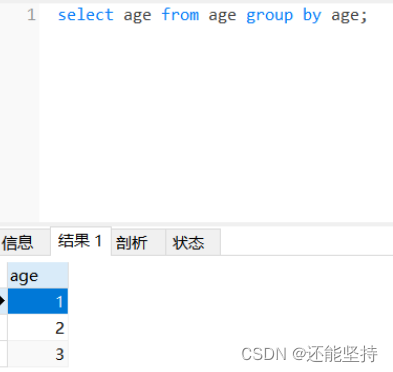
- 还可以使用count函数,统计重复的数据有多少个
3、使用ROW_NUMBER() OVER 或 GROUP BY 和 COLLECT_SET/COLLECT_LIST
说到要去重,自然会想到 DISTINCT,但是在 Hive SQL 里,它有两个问题:
- DISTINCT 会以 SELECT 出的全部列作为 key 进行去重。也就是说,只要有一列的数据不同,DISTINCT 就认为是不同数据而保留。
- DISTINCT 会将全部数据打到一个 reducer 上执行,造成严重的数据倾斜,耗时巨大。
2.1 ROW_NUMBER() OVER
DISTINCT 的两个问题,用 ROW_NUMBER() OVER 可解。比如,如果我们要按 key1 和 key2 两列为 key 去重,就会写出这样的代码:
WITH temp_table AS(SELECT
key1,
key2,[columns]...,
ROW_NUMBER()OVER(PARTITIONBY key1, key2
ORDERBYcolumnASC)AS rn
FROMtable)SELECT
key1,
key2,[columns]...FROM
temp_table
WHERE
rn =1;
这样,
Hive 会按 key1 和 key2 为 key,将数据打到不同的 mapper 上,然后对 key1 和 key2 都相同的一组数据,按 column 升序排列,并最终在每组中保留排列后的第一条数据。借此就完成了按 key1 和 key2 两列为 key 的去重任务
。注意 PARTITION BY 在此起到的作用:
- 一是按 key1 和 key2 打散数据,解决上述问题 (2);
- 二是与 ORDER BY 和 rn = 1 的条件结合,按 key1 和 key2 对数据进行分组去重,解决上述问题 (1)。
但显然,这样做十分不优雅(not-elegant),并且不难想见其效率比较低。
row_number() OVER (PARTITION BY
COL1ORDER BY
COL2) as num 表示根据
COL1分组,在分组内部根据
COL2排序,此函数计算的值num就表示每组内部排序后的顺序编号(组内连续的唯一的)
2.2 GROUP BY 和 COLLECT_SET/COLLECT_LIST
ROW_NUMBER() OVER 解法的一个核心是利用 PARTITION BY 对数据按 key 分组,同样的功能用 GROUP BY 也可以实现。但是,GROUP BY 需要与聚合函数搭配使用。我们需要考虑,什么样的聚合函数能实现或者间接实现这样的功能呢?不难想到有 COLLECT_SET 和 COLLECT_LIST。
SELECT
key1,
key2,[COLLECT_LIST(column)[1]AScolumn]...FROM
temp_table
GROUPBY
key1, key2
对于 key1 和 key2 以外的列,我们用 COLLECT_LIST 将他们收集起来,然后输出第一个收集进来的结果
。这里使用 COLLECT_LIST 而非 COLLECT_SET 的原因在于 SET 内是无序的,因此你无法保证输出的 columns 都来自同一条数据。若对于此没有要求或限制,则可以使用 COLLECT_SET,它会更节省资源。
相比前一种办法,由于省略了排序和(可能的)落盘动作,所以效率会高不少。但是因为(可能)不落盘,所以 COLLECT_LIST 中的数据都会缓存在内存当中。如果重复数量特别大,这种方法可能会触发 OOM。此时应考虑将数据进一步打散,然后再合并;或者干脆换用前一种办法。
删除 Hive SQL 查询结果中的重复内容
数据库之MySQL查询去重数据
版权归原作者 还能坚持 所有, 如有侵权,请联系我们删除。