
**Spark概述 **[参考Spark大数据技术与应用(第二版)]
Spark是什么

Spark是一种基于内存的快速、通用、可拓展的大数据分析计算引擎。
Spark官网:http://spark.apache.org/
Spark的特点
1、快速
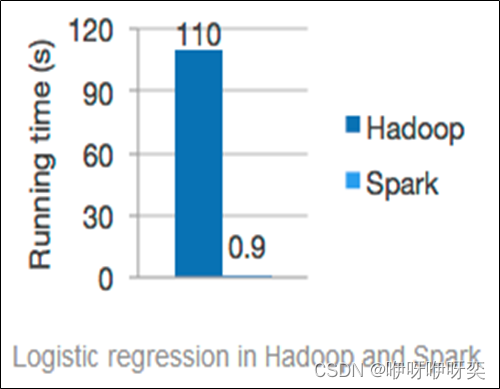
一般情况下,对于迭代次数较多的应用程序,Spark程序在内存中的运行速度是Hadoop MapReduce运行速度的100多倍,在磁盘上的运行速度是Hadoop MapReduce运行速度的10多倍。
2、易用
Spark支持使用Scala、Python、Java及R语言快速编写应用。同时Spark提供超过80个高阶算子,使得编写并行应用程序变得容易,并且可以在Scala、Python或R的交互模式下使用Spark。



3、通用
Spark可以与SQL、Streaming及复杂的分析良好结合。Spark还有一系列的高级工具,包括Spark SQL、MLlib(机器学习库)、GraphX(图计算)和Spark Streaming(流计算),并且支持在一个应用中同时使用这些组件。

4、随时运行
用户可以使用Spark的独立集群模式运行Spark,也可以在EC2(亚马逊弹性计算云)、Hadoop YARN或者Apache Mesos上运行Spark。并且可以从HDFS、Cassandra、HBase、Hive、Tachyon和任何分布式文件系统读取数据。

5、代码简洁
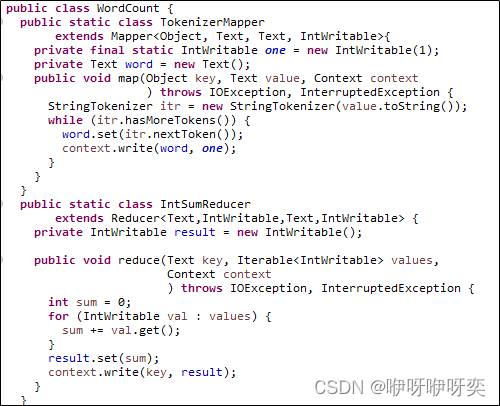
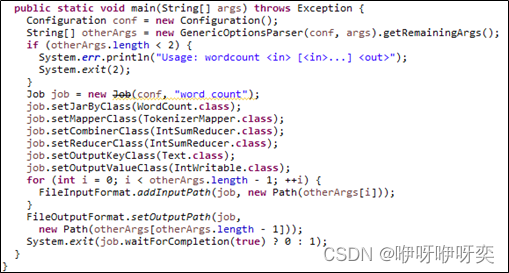
Spark支持使用Scala、Python等语言编写代码。Scala和Python的代码相对Java的代码而言比较简洁,因此,在Spark中一般都使用Scala或Python编写应用程序,这也比在MapReduce中编写应用程序简单方便。例如,MapReduce实现单词计数可能需要60多行代码,而Spark使用Scala语言实现只需要一行代码。
sc.textFile("/user/root/a.txt").flatMap(.split(" ")).map((,1)).reduceByKey(+).saveAsTextFile("/user/root/output")
以上是Spark的优点,难道Spark是完美无缺的吗?

Spark的缺点
1、功能单一
2、资源消耗
MapReduce PK Spark
1.通用性
Spark(实时)
一栈式,主要说的是,Spark不仅仅可以进行离线计算(SparkCore),同时还可以进行流式处理(SparkStreaming)、交互式计算(SparkShell,SparkSQL,StructStreaming,图计算(SparkGraphx),机器学习(SparkMLLib),也就是说我们可以在一个项目中,同时可以使用上述所有的框架,这是Spark相比较于其它框架最大的优势。可以使用多中语言进行编程。
MapReduce
MapReduce主要是擅长离线的计算,不擅长实时计算。
2.内存和磁盘的使用情况
Spark
Spark是基于RDD,主要使用内存进行储存计算的源数据及过程的数据,避免了写磁盘的IO操作,速度自然比较快。
MapReduce
MapReduce基于磁盘的计算,计算的过程中需要大量的溢写磁盘的操作,IO瓶颈比较明显,速度自然不好。
3.API
Spark
Spark编程过程中系统提供了大量的算子,transformation和action算子,功能之强大是MR无法比拟的,编程自由度比较高。
MapReduce
MapReduce的编程API只是提供了 map和reduce的操作,编程局限性比较大,什么操作都需要往规定好的模式上去套,死板。
4.系统自由度
Spark
Spark给用户提供了诸多的参数进行设置,适应不同场景的应用,比如sort,系统并没有强制进行sort,如果需要可以进行相应参数的设置,去掉自动排序的功能之后提高效率。
MapReduce
MapReduce的shuffle的过程中相当的复杂,虽然shuffle的过程是奇迹发生的地方,但是这里边做的事太多了,很多没有法子去掉,也就是说有可能对于场景无用的操作也做了,比如排序,本身其实我们有可能不需要sort,但是基于MR的特性,它必须依靠sort,这样白白浪费了性能。
5.系统容错性
Spark
Spark中有个血缘关系,在计算过程中如果出现问题造成数据丢失,系统不用重新计算,只需要根据血缘关系找到最近的中间过程数据进行计算,而且基于内存的中间数据存储增加了再次使用的读取的速度。
MapReduce
MapReduce的过程中的中间文件溢写磁盘,如计算过程中出现数据的丢失,只能重新来过.严重影响时效性。
MapReduce PK Spark简直完败,但是Hadoop能被Spark取代吗?
答案是:不能!!!Spark 并不能完全替代 Hadoop,Spark 主要用于替代Hadoop中的MapReduce 计算模型。存储依然可以使用 HDFS,但是中间结果可以存放在内存中,调度可以使用 Spark 内置的,也可以使用更成熟的调度系统 YARN 等。
结构化数据与非结构化数据
结构化数据:即行数据,存储在数据库里,可以用二维表结构来逻辑表达实现的数据。
ps:二维表结构,用通俗的话来说就是excel表格,即:有行有列的。
非结构化数据:不方便用数据库二维逻辑表来表现的数据,包括所有格式的办公文档、文本、图片、XML、HTML、各类报表、图像和音频/视频信息等等。
半结构化数据:就是介于完全结构化数据(如关系型数据库、面向对象数据库中的数据)和完全无结构的数据(如声音、图像文件等)之间的数据,HTML文档就属于半结构化数据。它一般是自描述的,数据的结构和内容混在一起,没有明显的区分。
spark搭建的三种模式
1、Standalone模式(独立、本地模式)
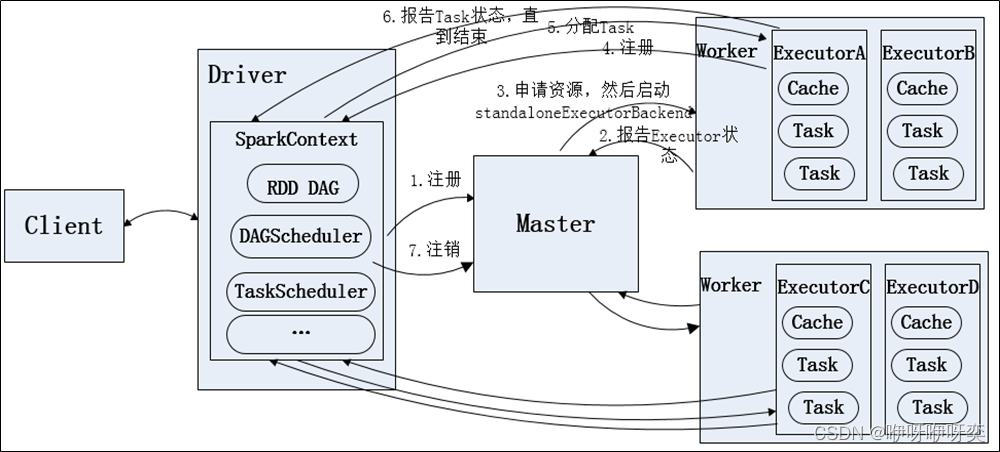
Standalone模式是Spark自带的资源管理器。
2、YARN模式
YARN模式根据Driver在集群中的位置又分为两种。
SparkonY****ARN
cluster模式:
driver运行在集群子节点上,适合用于生产,通信成本低,只能在日志中查看输出结果
yarn-client运行流程
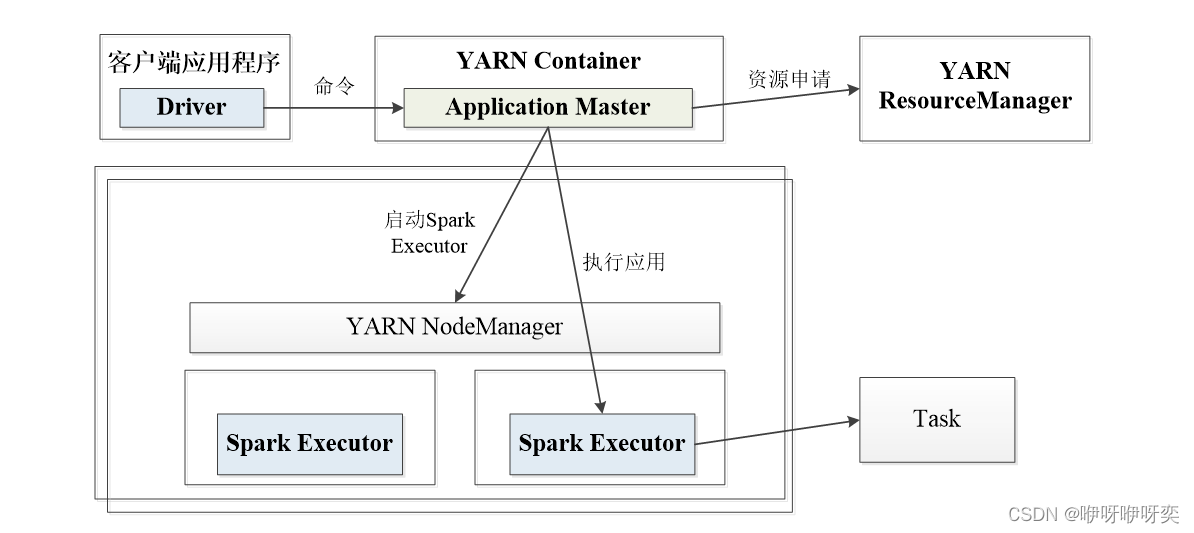
client模式:
dirver运行在提交任务的客户端上,通信成本高,可以直接查看输出结果
yarn-cluster运行流程

3、Mesos模式
官方推荐这种模式(当然,原因之一是血缘关系)。正是由于Spark开发之初就考虑到支持Mesos,因此,目前而言,Spark运行在Mesos上会比运行在YARN上更加灵活,更加自然。
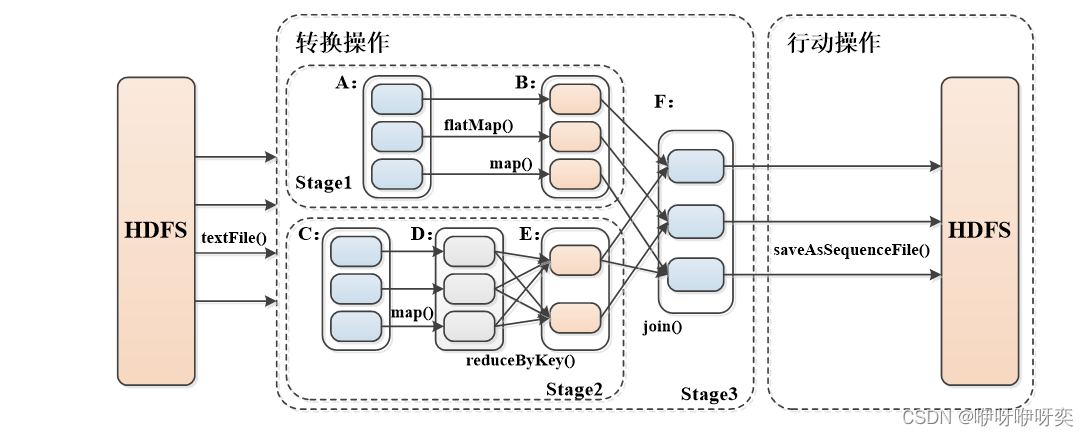
Spark RDD转换和操作示例
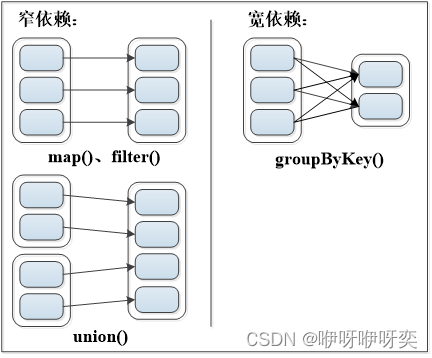
宽依赖与窄依赖
窄依赖:表现为一个父RDD的分区对应于一个子RDD的分区或者多个父RDD的分区对应于一个子RDD的分区。(独生子女关系)
宽依赖:表现为存在一个父RDD的一个分区对应一个子RDD的多个分区。(超生现象)
Q:Stage划分的依据是?
A:Stage划分基于数据依赖关系的,一般分为两类:宽依赖(Shuffle Dependency)与窄依赖(Narrow Dependency)。
Q:怎么定义一个Task?
A:Spark目前提供了两类Task,分别为ShuffleMapTask和ResultTask。一个stage可能包含一个或者多个task任务,task任务与partition、executor息息相关,即并行度。
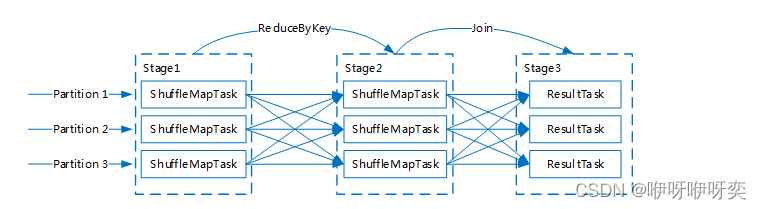
总结上图,一个Stage内只会存在同一种Task,Task数量与Stage的Partition数量保持一致(运行的Task数量可能会大于Partition数量)
版权归原作者 咿呀咿呀奕 所有, 如有侵权,请联系我们删除。