
文章目录
一、InceptorSQL概述
InceptorSQL是一个分布式SQL引擎,经常在一下这些场景中使用:1. 批处理; 2.统计分析;3. 图计算和图检索;4.交互式统计分析
Inceptor中表的种类有很多,他们的划分规则如下:
- 按 Inceptor的所有权 分类可分为:外部表(或简称为外表)和托管表(内表)。
- 按 表的存储格式 分类可分为:TEXT表、ORC表、CSV表和Holodesk表。
- 按表 是否分区 可分为:分区表和非分区表。
- 按表 是否分桶 可分为:分桶表和非分桶表。
- 托管表(内表) CREATE TABLE 默认创建托管表。Inceptor对托管表有所有权——用 DROP 删除托管表时,Inceptor会将表中数据全部删除。
- 外表 外表用 CREATE EXTERNAL TABLE 创建,外表中的数据可以保存在HDFS的一个指定路径上(和LOCATION <hdfs_path> 合用)。Inceptor对外表没有所有权。用DROP 删除外部表时,Inceptor删除表在metastore中的元数据而不删除表中数据,也就是说 DROP 仅仅解除Inceptor对外表操作的权利。
- Text表 文本格式的表,统计和查询性能都比较低,也不支持事务处理,所以通常用于将文本文件中的原始数据导入Inceptor中。针对不同的使用场景,用户可以将其中的数据放入ORC表或Holodesk表中。Inceptor提供两种方式将文本文件中的数据导入TEXT表中: (1)建外部TEXT表,让该表指向HDFS上的一个目录,Inceptor会将目录下文件中的数据都导入该表。(推荐) (2)建TEXT表(外表内表皆可)后将本地或者HDFS上的一个文件或者一个目录下的数据 LOAD 进该表。这种方式在安全模式下需要多重认证设置,极易出错,星环科技 不推荐 使用这个方式导数据。
- CSV表 CSV表的数据来源为CSV格式(Comma-Separated Values)的文件。文件以纯文本形式存储表格数据(数字和文本),CSV文件由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字符或字符串,最常见的是逗号或制表符。通常,所有记录都有完全相同的字段序列。和TEXT表相似,CSV表常用于向Inceptor中导入原始数据,然后针对不同场景,用户可以将其中的数据放入ORC表或Holodesk表中星环科技 不建议在任何计算场景中使用CSV表
- ORC表 ORC表即ORC格式的表。在Inceptor中,ORC表还分为ORC事务表和非事务表。a. ORC事务表支持事务处理和更多增删改语法(INSERT VALUES/UPDATE/DELETE/MERGE),所以如果您需要对表进行事务处理,应该选择使用ORC事务表。b. ORC非事务表则主要用来做统计分析。
- Holodesk表 Holodesk表存储在内存或者SSD中(可以根据您的需要设置),同时,星环科技为其提供了一系列优化工具,使得在Holodesk表上进行大批量复杂查询能达到极高的性能。所以,如果您的数据量特别大,查询非常复杂,您应该选择使用Holodesk表。
二、实验环境
基于星环云课堂TranswarpVD
三、实验准备
- 进入TDH-Client目录下 cd /transwarp/Desktop/TDH-Client
- 执行TDH Client的init.sh脚本,此操作只对当前Session有效 source ./init.sh
四、实验目的
• 掌握Inceptor SQL的基本使用。
• 了解Inceptor各类表的区别与应用场景。
五、实验步骤
5.1 使用Waterdrop连接Inceptor
- 打开Transwarp Manager查看集群中Inceptor主节点的Server Host查看结果为tdh-05(后面会用)

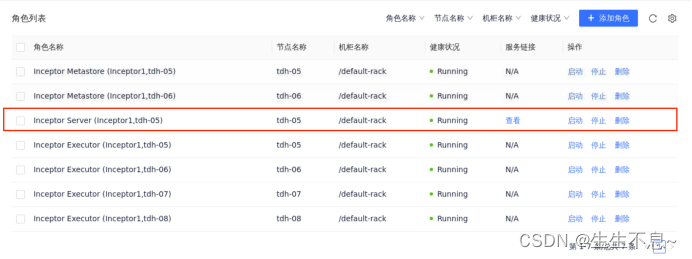
- 在桌面点击waterdrop,并建立与Inceptor的连接
3. 在弹出界面中填写如下信息,其中Server Host为Inceptor主节点地址,之前步骤中已经获取到,Port为10000,Auth Type选择为LDAP。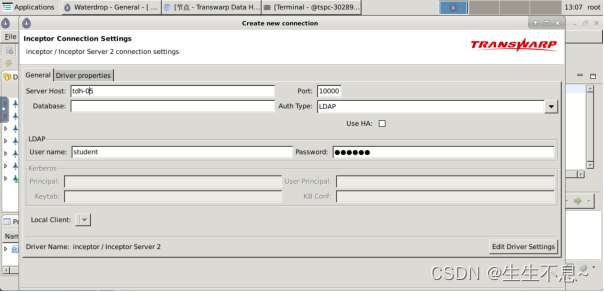
4. 进行连接测试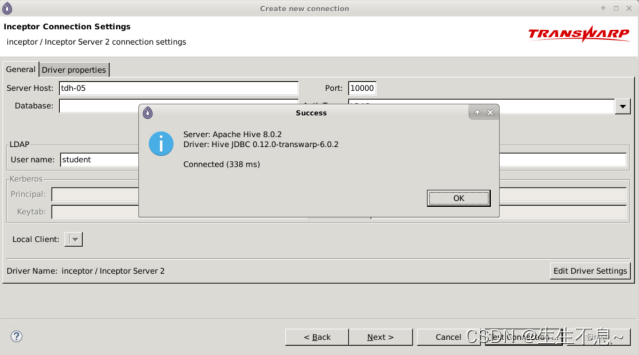
5. 点击Next完成连接操作。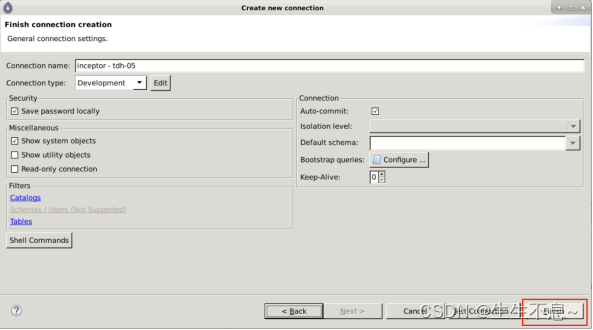
6. 建立与Inceptor的连接,并打开SQL编辑器,之后的SQL操作都在编辑器中完成,编写好SQL后,选中SQL内容,按快捷键Ctrl+回车执行。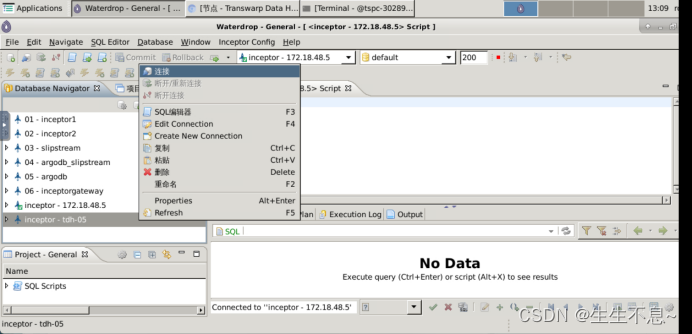

5.2、WordCount
(1)创建wordcount.txt文件,并上传HDFS
• 任务:将本地文件wordcount.txt上传至HDFS目录中。
• 步骤
Linux:
1.echo -e “Deer Bear River\nCar Car River\nDeer Car Bear” > /transwarp/Desktop/wordcount.txt
// 在本地创建wordcount.txt文件,并完成数据写入
2.hadoop fs -mkdir -p /training/{student_name}/inceptor_data/wordcount
// 在HDFS中创建作业输入目录
3.hadoop fs -put /transwarp/Desktop/wordcount.txt /training/{student_name}/inceptor_data/wordcount/
// 将wordcount.txt上传到作业输入目录
4. hadoop fs -chmod -R 777 /training/{student_name}/inceptor_data/wordcount/
(2)在Waterdrop中创建内表,并导入HDFS数据
• 任务:创建内表docs,并将HDFS中的数据导入。
• 步骤
SQL:
1、 create database {database_name};
// 创建数据库, 命名规范为db_账号名,
2、use {database_name};
// 进入数据库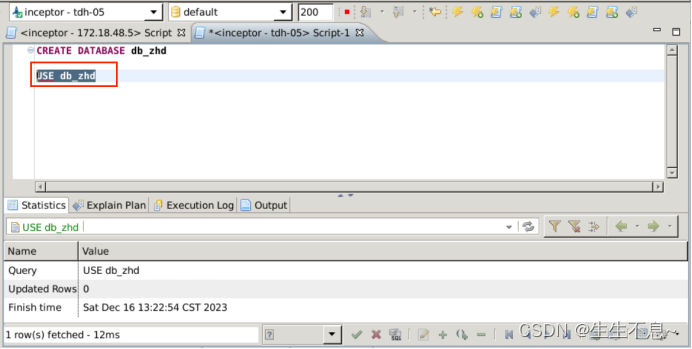
3、create table docs(line string);
// docs表创建
4.load data inpath ‘/training/{student_name}/inceptor_data/wordcount’ into table docs;
// 导入hdfs数据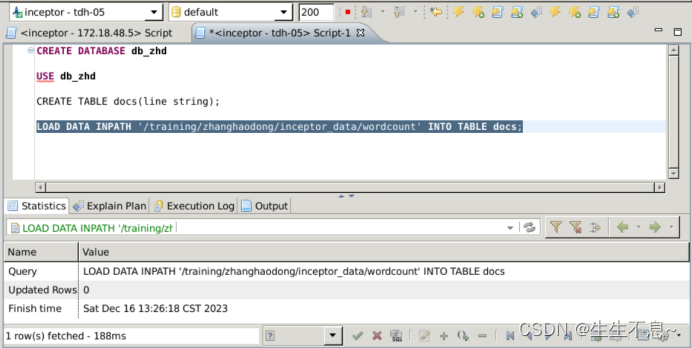
(3)创建结果表
• 任务:创建内表wc,保存词频统计结果。
• 步骤
SQL:
1、 create table wc(word string, totalword int);
// docs表创建
(4)计算wordcount
• 任务:对docs表完成词频统计,将结果保存到wc表中。
• 步骤
SQL:
1、from (select explode(split(line, ’ ')) as word from docs) w
insert into table wc
select word, count(1) as totalword
group by word
order by word;
// wordcount统计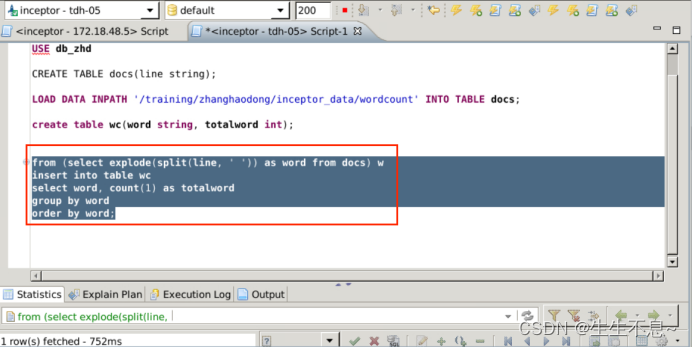
2、select * from wc;
// 查看分析结果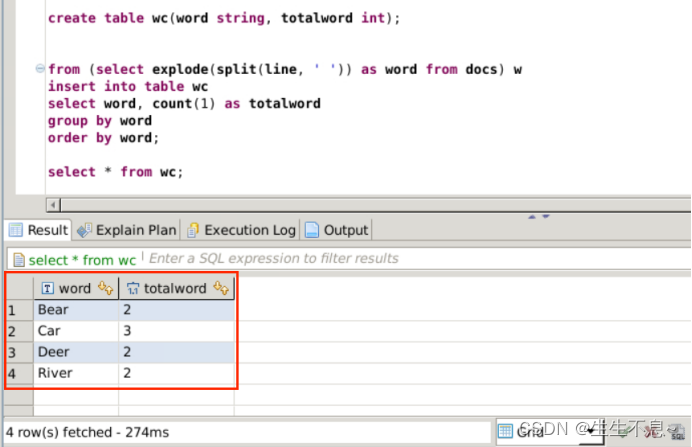
5.3、外部表与内部表
(1)创建外部表,查看数据格式
• 任务:为data.csv文件创建外部表,并查看数据内容。
• 步骤
SQL:
// 在Inceptor中创建外表,并查看数据
drop table if exists ext_table;
create external table ext_table(rowkey string, num int, country int, rd string) row format delimited fields terminated by ‘,’ location ‘/images/inceptor_data’;
select * from ext_table limit 10;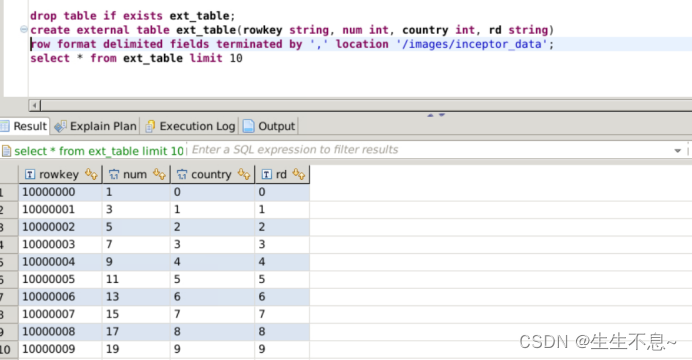
(2)创建内表,并接入外表数据
• 任务:创建ORC内表,并将外表数据导入。
• 步骤
SQL:
// 在Inceptor中创建内表
drop table if exists inner_table;
create table inner_table(rowkey string, num int, country int, rd int) stored as orc;
// 将外表数据导入到内表中. insert into inner_table select * from ext_table;
// 查看内表数据
select * from inner_table limit 10;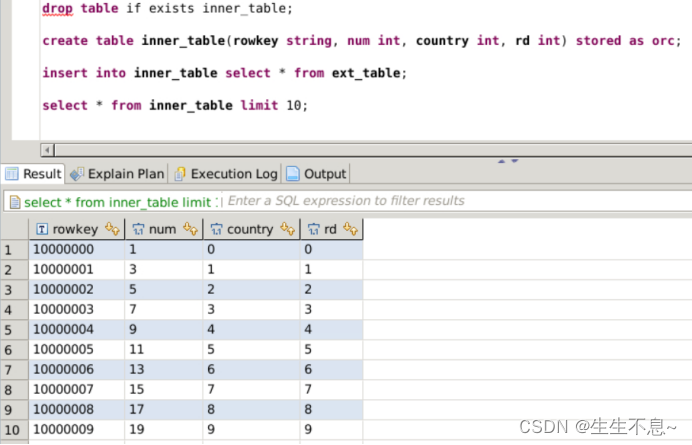
5.4、普通ORC表
• 任务:并创建普通ORC表,并验证ORC表的事务性。
• 步骤
SQL:
// 创建数据库和ORC表
drop table if exists orc_table;
create table orc_table(key int, value string) stored as orc;
// 向ORC表中插入数据,会报错(ORC表没有事务)
insert into orc_table values(1,‘test’);
5.5、创建ORC事务表
• 任务:创建ORC事务表,并进行事务操作。
• 步骤
SQL:
// 设置开启事务
set transaction.type=inceptor;
// 设置PLSQL编译器不检查语义
set plsql.compile.dml.check.semantic=false;
// 创建ORC事务表
drop table if exists atomicity_table;
create table atomicity_table(key int, value string) clustered by(key) into 8 buckets stored as orc tblproperties(‘transactional’=‘true’);
向ORC事务表中插入数据
insert into atomicity_table values(1,‘src1’);
insert into atomicity_table values(2,‘src2’);
// 查看数据是否写入成功
select * from atomicity_table;
// 更新ORC事务表数据
update atomicity_table set value = ‘src3’ where key = 1;
// 查看数据是否更新成功
select * from atomicity_table;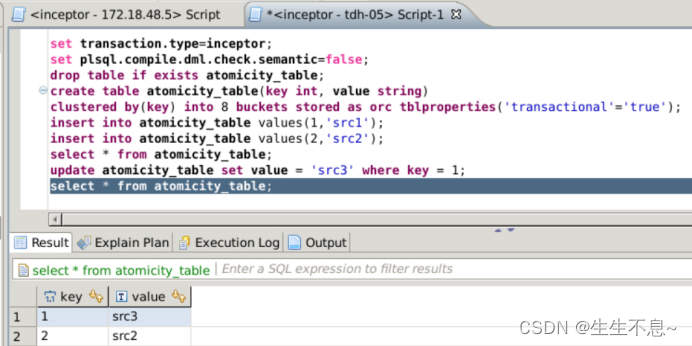
5.6、创建ORC分区表
• 任务:创建单值分区表user_acc_level,表包含字段为name,分区字段为acc_level。
• 步骤
SQL:
// 创建单值分区表,分区键=acc_level
CREATE TABLE user_acc_level (name STRING)
PARTITIONED BY (acc_level STRING);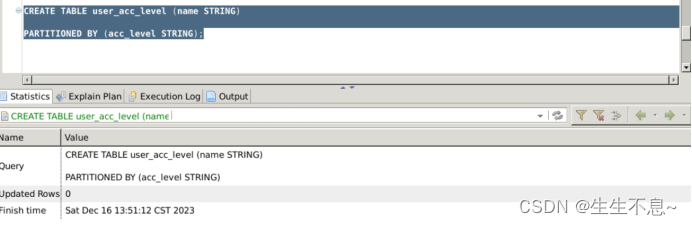
5.7、创建ORC分区分桶表
• 任务:创建范围分区分桶表,并存储为ORC格式。
• 步骤
SQL:
// 创建范围分区分桶表,分区键=sj,分桶键=mbbh
create table hq_ais_history_data_orc_bucket (
cbm string,
csx int,
cwjqd int,
dzdwzz int,
gjmc string,
hh string,
hs double,
hwlx int,
hx double,
hxzt int,
imobm string,
mbbh string,
mdd string,
txzt int,
xxlx int,
xxly int,
yjddsj string,
zdjss double,
zxl int,
lat double,
lon double,
mbsj int
)
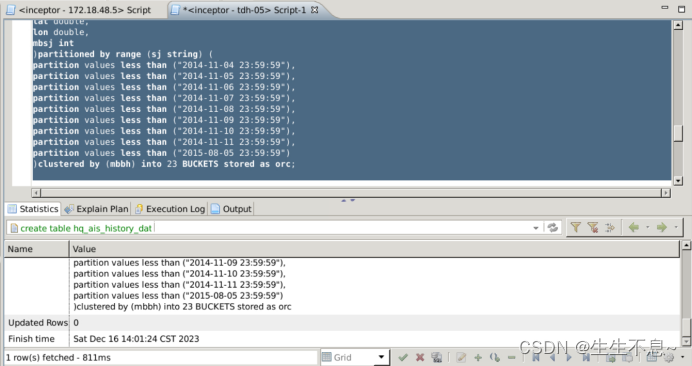
partitioned by range (sj string) (
partition values less than (“2014-11-04 23:59:59”),
partition values less than (“2014-11-05 23:59:59”),
partition values less than (“2014-11-06 23:59:59”),
partition values less than (“2014-11-07 23:59:59”),
partition values less than (“2014-11-08 23:59:59”),
partition values less than (“2014-11-09 23:59:59”),
partition values less than (“2014-11-10 23:59:59”),
partition values less than (“2014-11-11 23:59:59”),
partition values less than (“2015-08-05 23:59:59”)
)
clustered by (mbbh) into 23 buckets
stored as orc;
版权归原作者 生生不息~ 所有, 如有侵权,请联系我们删除。