
✅作者简介:大家好,我是Philosophy7?让我们一起共同进步吧!🏆 📃个人主页:Philosophy7的csdn博客
🔥系列专栏:
👑哲学语录: 承认自己的无知,乃是开启智慧的大门
💖如果觉得博主的文章还不错的话,请点赞👍+收藏⭐️+留言📝支持一下博>主哦🤞


文章目录
一、HBase的介绍
HBase是一种构建在HDFS之上的分布式、面向列的存储系统。隶属于Apache基金组织的一个子项目,Apache HBase是基于Google BigTable开源实现的。也就意味着,HBase支持海量数据的存储,而且还是一种NoSQL的一种数据库。
RDBMS(Relational DataBase Management System)关系型数据库它的优点在于:
- 丰富的数据类型
- 丰富的功能
- 事务的支持
- 随机读操作
缺点:
- 不支持海量数据的存储
- 结构单一、不易扩展
- 读写性能较差
NoSQL:非关系型数据库
优点:
- 稀疏性,容易节省存储空间
- 键值对的方式存储
- 海量数据的维护和处理非常轻松,成本低。
- 速度快,效率高。 NoSQL 可以使用硬盘或者随机存储器作为载体,而关系型数据库只能使用硬盘。
缺点:
- 非关系型数据库暂时不提供 SQL 支持,学习和使用成本较高。
- 非关系数据库没有事务处理,无法保证数据的完整性和安全性。适合处理海量数据,但是不一定安全。
- 功能不如关系型数据库丰富
1、面向行和面向列存储的对比
行存储数据
idnameagesex1jack20男2tom29男
列存储数据
id123namejacktomroseage231926
这两种存储的数据都是从上到下,从左到右排列的。
项目行存储列存储优点写入效率高,提供数据完整性保证读取过程有冗余,适合数据定长的大数据计算缺点数据读取有冗余,影响计算速度缺乏数据完整性保证,写入效率低改进优化的存储格式,保证在内存中快速删除冗余数据多线程并行读写操作应用场景商业领域、互联网互联网
数据模型
逻辑上,HBase 的数据模型同关系型数据库很类似,数据存储在一张表中,有行有列。但从 HBase 的底层物理存储结构(K-V)来看,HBase 更像是一个
multi-dimensional map
多维映射
- NameSpace:命名空间 - 命名空间,类似于关系型数据库的 DatabBase 概念,每个命名空间下有多个表。HBase 有两个自带的命名空间,分别是 hbase 和 default,hbase 中存放的是 HBase 内置的表, default 表是用户默认使用的命名空间。
- Region - 类似于关系型数据库的表概念。不同的是,HBase 定义表时只需要声明列族即可,不需 要声明具体的列。
- Row : 行 - HBase 表中的每行数据都由一个 RowKey 和多个 Column(列)组成,数据是按照 RowKey 的字典顺序存储的,并且查询数据时只能根据 RowKey 进行检索,所以 RowKey 的设计十分重 要。
- Column:列 - HBase 中的每个列都由 Column Family(列族)和 Column Qualifier(列限定符)进行限 定,例如 info:name,info:age。建表时,只需指明列族,而列限定符无需预先定义。
- TimeStamp:时间戳 - 用于标识数据的不同版本(version),每条数据写入时,如果不指定时间戳,系统会 自动为其加上该字段,其值为写入 HBase 的时间。
- Cell : 单元格 - 由{rowkey, column Family:column Qualifier, time Stamp} 唯一确定的单元。cell 中的数 据是没有类型的,全部是字节码形式存贮。
2、逻辑模型
HBase是一种类似BigTable的分布式数据库,是一个稀疏的、长期存储的(存储在硬盘上)、多维度的、排序的映射表,表的索引是行键、列关键字和时间戳,HBase中的数据都是字符串。类似于一种Json格式的字符串
行键时间戳列族info列族info21001Timestampinfo1:name=“zhangsan”info2:name=“lisi”1002xxxxxxxxxinfo1:age=“23”info2:age=“29”
3、物理模型
在物理存储方面,仍然是按照列来存储数据的。
行键时间戳列单元格(Value)1001t1info1:namezhangsan1001t2info1:age261002t1info1:namelisi1002t2info1:age29
注意:在逻辑模型中有些列是空白的,这样的列实际不会被存储,当请求这些空白的单元格时会返回一个Null值。如果在查询的时候不提供时间戳,那么会返回距离现在最近的时间戳的版本数据,数据的存储按照时间戳来排序。
4、特点
非关系型数据库从严格意义上来说并不是数据库,而是一种数据结构化存储方法的集合。HBase作为一个NoSQL数据库,仅支持单行事务,通过不断增加集群中的节点数据量来增加计算能力,具有以下特点:
- 容量巨大 - HBase在纵向和横向上支持大数据量存储,一个表中可以有百亿行、百亿列
- 面向列 - HBase是面向列存储和权限控制,列能够独立检索。
- 稀疏性 - HBase是基于列存储的,不允许存储为空的列,因此是稀疏的,可以节省存储空间,增加存储量
- 数据多版本 - 每个单元格中可以有多个版本,默认情况下版本号是数据插入时的时间戳(1970年计算的秒单位)
- 可扩展性 - HBase的数据存文件储于HDFS上,由于HDFS具有动态增加节点的特性,所以HBase也能够实现集群的扩展。
- 高性能: - WAL(Write Ahead Log,预写日志)机制保证了数据写入时因集群故障而导致数据丢失;HBase位于HDFS上,HDFS也有数据备份功能;同时HBase引入Zookeeper避免Master单点故障。
- 数据类型单一: - Hbase中的数据都是字符串,没有其他类型
5、系统架构
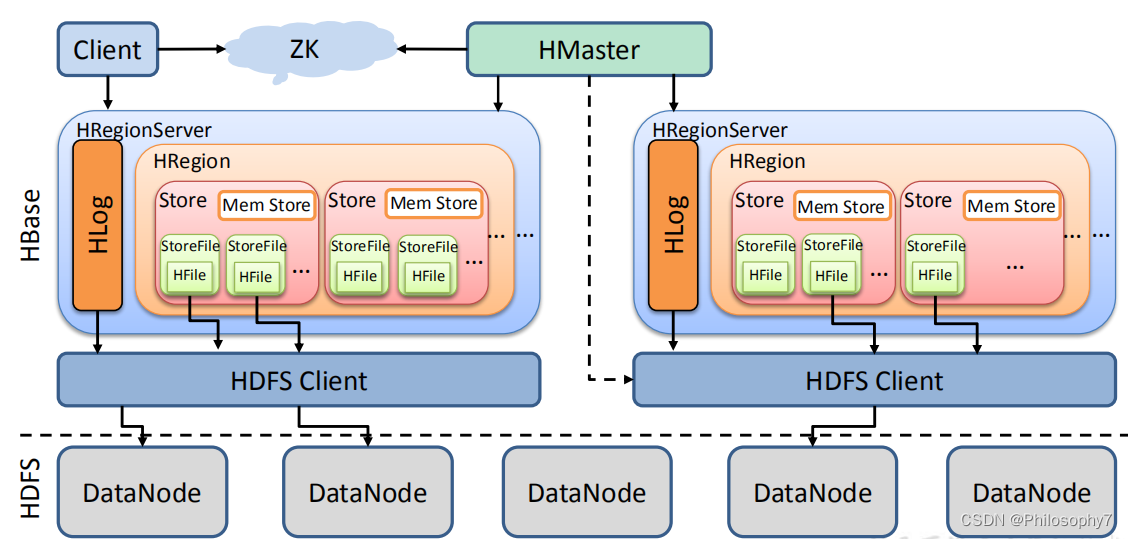
HBase属于以主从架构,隶属于Hadoop生态系统,由以下组件组成:Client、Zookeeper、HMaster、HRegionServer和HResion。
- Client:- 包含访问HBase的接口,使用RPC机制(远程调用)与HMaster和HResionServer进行通信
- Zookeeper:- Hbase引入Zookeeper的主要原因就是为了防止单点故障。并起到一个协同服务。
- HMaster- HBase中主要服务器,负责集群状态的管理维护。- 管理用户对表的增删改查也就是DDL- 为HRegionServer分配Region- 处理元数据的更新请求
- HRegionServer- HRegionServer是集群当中具体对外提供服务的进程,主要负责维护Region的启动和管理,处理用户读写请求(DML操作)。- 一个HRegionServer包含多个Region
- HRegion- 相对于关系型数据库中的表概念,HBase按照行键会进行表的切割操作,每个Region都记录了行键的起始和结尾。- HRegion负责和Client进行通信,实现数据的读写。
HMaster启动步骤:
- 首先从Zookeeper当中获取唯一代表HMaster的锁
- 扫描Zookeeper上所有的server的目录,获得当前的HRegionServer的列表
- 和扫描到的所有HRegionServer进行通信,获得当前已经分配的HRegion和HregionServer的关系
- 扫描元数据表和Region的集合,计算当前未分配的HRegion,将他们放入到待分配列表中
二、环境搭建
在进入环境搭建的环节,我们首先认识一下HBase的运行环境:
- 独立式 - 默认情况下使用的就是独立式的HBase。也就意味着HBase不会使用HDFS,而是使用本地的文件系统。
- 分布式 - 分布式可以分为伪分布式和完全分布式。伪分布式模式的 HBase 就是在单个主机上运行的完全分布式模式。而对于完全分布式需要配置相关的文件。例如:``hbase.cluster.distributed
属性设置为true`
1、解压tar包
tar -zxvf hbase-1.3.1-bin.tar.gz -C /usr/local/
重命名hbase
mv hbase-1.3.1/ hbase
2、HBase配置文件
hbase-site.xml
<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>hbase.zookeeper.quorum</name><value>master,slave1,slave2</value><description>The directory shared by RegionServers.
</description></property><property><name>hbase.rootdir</name><value>hdfs://master:8020/hbase</value><description>The directory shared by RegionServers.
</description></property><property><name>hbase.cluster.distributed</name><value>true</value><description>The mode the cluster will be in. Possible values are
false: standalone and pseudo-distributed setups with managed ZooKeeper
true: fully-distributed with unmanaged ZooKeeper Quorum (see hbase-env.sh)
</description></property><property><name>hbase.zookeeper.property.dataDir</name><value>/usr/local/zookeeper-3.4.5/zkData</value><description>Property from ZooKeeper config zoo.cfg.
The directory where the snapshot is stored.
</description></property></configuration>
hbase-env.sh
hbase-env.sh 文件中的以下行显示了如何设置
JAVA_HOME
环境变量(HBase 需要的)并将堆设置为 4 GB(而不是默认值 1 GB)。如果您复制并粘贴此示例,请务必调整
JAVA_HOME
以适合您的环境。

# The java implementation to use. Java 1.7+ required.exportJAVA_HOME=/usr/local/jdk1.8.0_321
# Extra Java CLASSPATH elements. Optional.# export HBASE_CLASSPATH=# The maximum amount of heap to use. Default is left to JVM default. 默认是1G 设置为4GexportHBASE_HEAPSIZE=4G
regionservers
在此文件中列出将运行 RegionServers 的节点,
如果要配置本机名称,请将localhost注释掉
#localhost
master
slave1
slave2
3、使用scp发送给其他集群
scp -r /usr/local/hbase/ slave1:/usr/local/
scp -r /usr/local/hbase/ slave2:/usr/local/
4、启动HBase
启动Hadoop集群
cd $HADOOP_HOME
sbin/start-dfs.sh
sbin/start-yarn.sh
启动Zookeeper
#配置环境变量 直接启动 集群都要启动
zkServer.sh start
启动Hbase
bin/start-hbase.sh #启动
bin/stop-hbase.sh #关闭

启动成功后,
http://master:16010
访问HBase管理Web界面。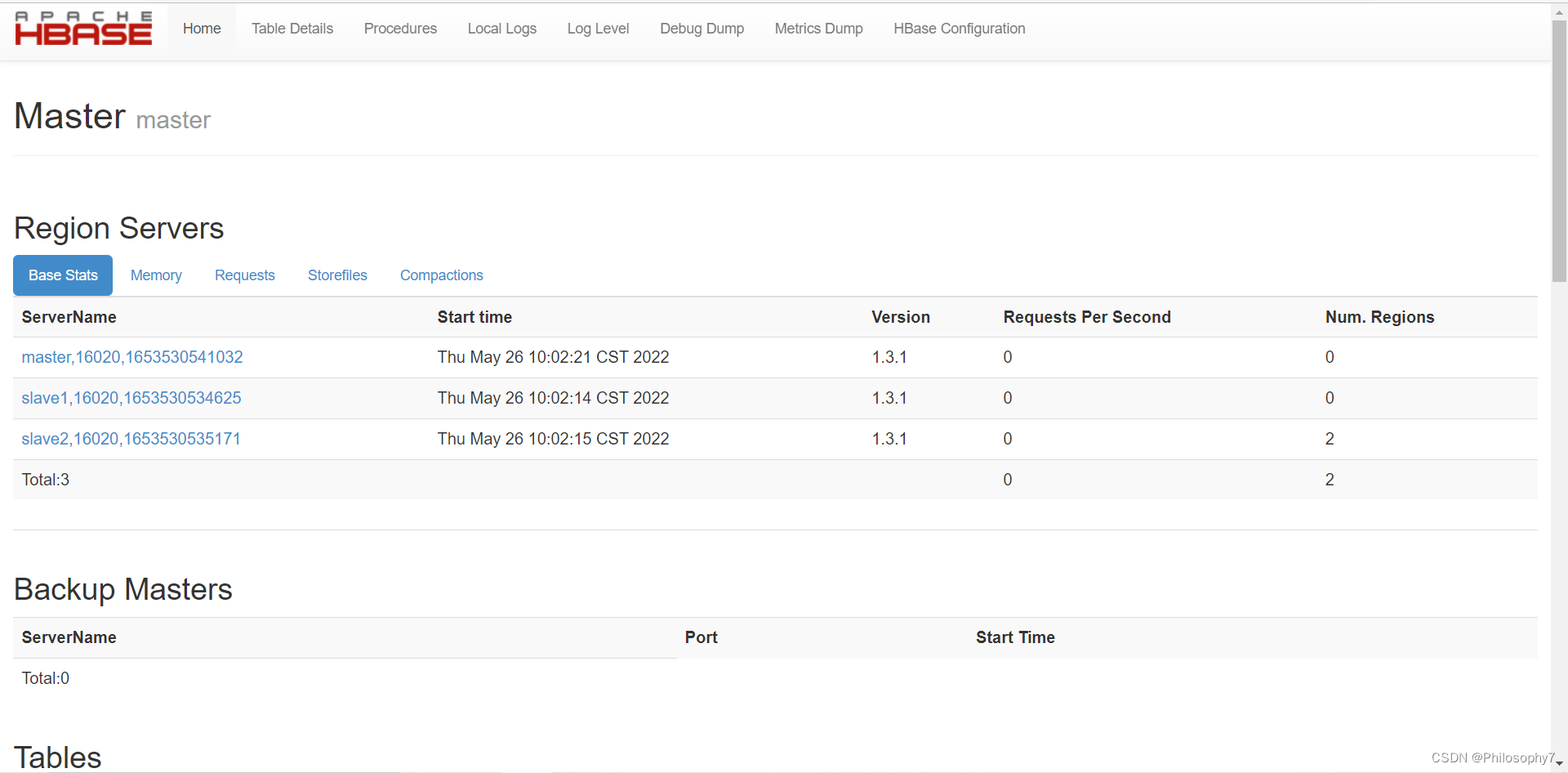
交互式界面
bin/hbase shell
#这里有一个恶心的点就是 光标停留在哪就删除哪 如果需要往前删除需要按住Ctrl键
基本操作
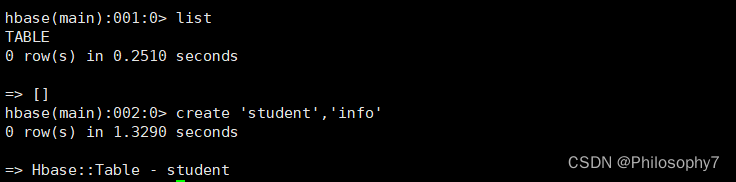
创建表
#可以使用help帮助命令查看
create 'student','info'# 后面的info是列族 可以声明多个列族
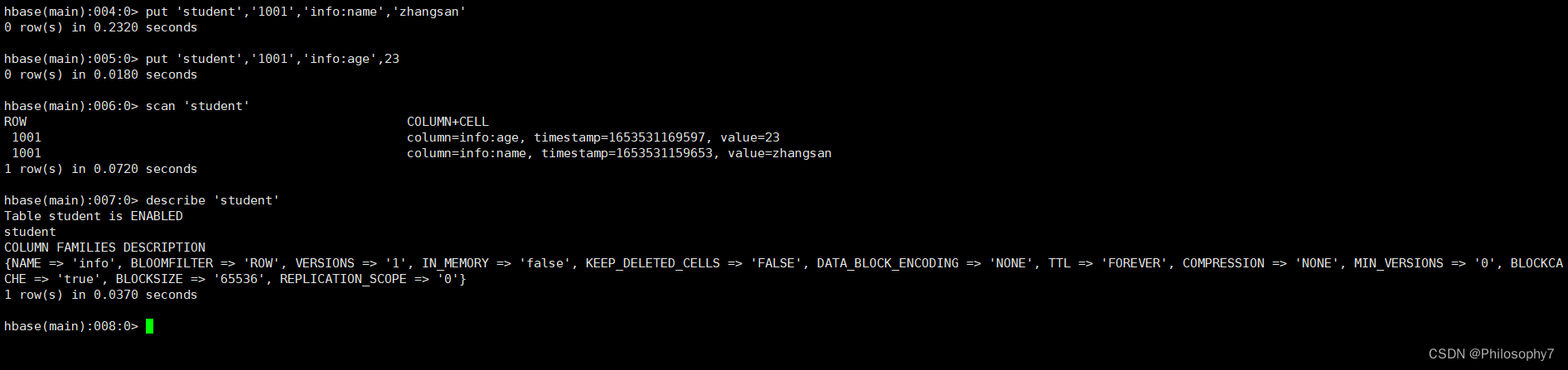
#插入数据
put 'student','1001','info:name','zhangsan'
put 'student','1001','info:age',29
#扫描全表查看数据
scan 'student'#查看表详细信息
describe 'student'
版权归原作者 Philosophy7 所有, 如有侵权,请联系我们删除。