
什么是kafka
Kafka是一种高吞吐量的分布式发布订阅消息系统(消息引擎系统),它可以处理消费者在网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息
其实我们简单点理解就是系统A发送消息给kafka(消息引擎系统),系统B从kafka中读取A发送的消息。而kafka就是个中间商。
消息队列的好处
解耦合
耦合的状态表示当你实现某个功能的时候,是直接接入当前接口,而利用消息队列,可以将相应的消息发送到消息队列,这样的话,如果接口出了问题,将不会影响到当前的功能。
异步处理
异步处理替代了之前的同步处理,异步处理不需要让流程走完就返回结果,可以将消息发送到消息队列中,然后返回结果,剩下让其他业务处理接口从消息队列中拉取消费处理即可。
流量削峰高流量的时候,使用消息队列作为中间件可以将流量的高峰保存在消息队列中,从而防止了系统的高请求,减轻服务器的请求处理压力。
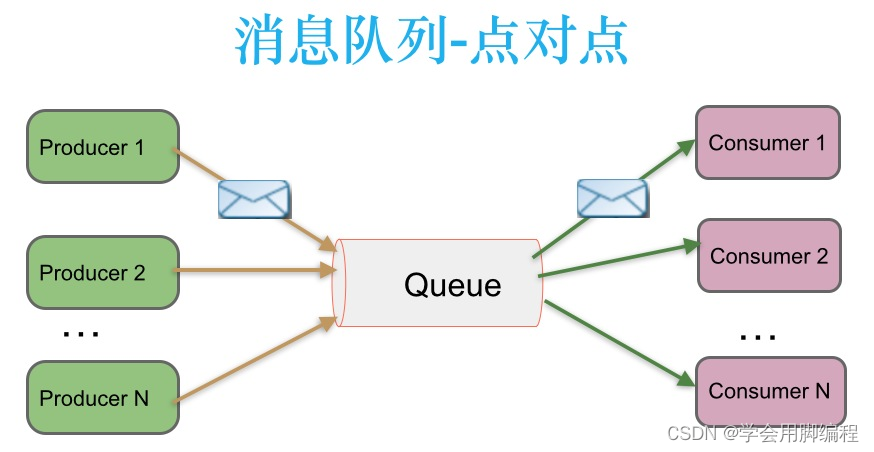
** 点对点消息传递模式**
在点对点消息系统中,消息持久化到一个队列中。此时,将有一个或多个消费者消费队列中的数据。但是一条消息只能被消费一次。当一个消费者消费了队列中的某条数据之后,该条数据则从消息队列中删除。该模式即使有多个消费者同时消费数据,也能保证数据处理的顺序。这种架构描述示意图如下:
发布-订阅消息传递模式
在发布-订阅消息系统中,消息被持久化到一个topic中。与点对点消息系统不同的是,消费者可以订阅一个或多个topic,消费者可以消费该topic中所有的数据,同一条数据可以被多个消费者消费,数据被消费后不会立马删除。在发布-订阅消息系统中,消息的生产者称为发布者,消费者称为订阅者。该模式的示例图如下:
生产者发送一条消息到queue,只有一个消费者能收到。
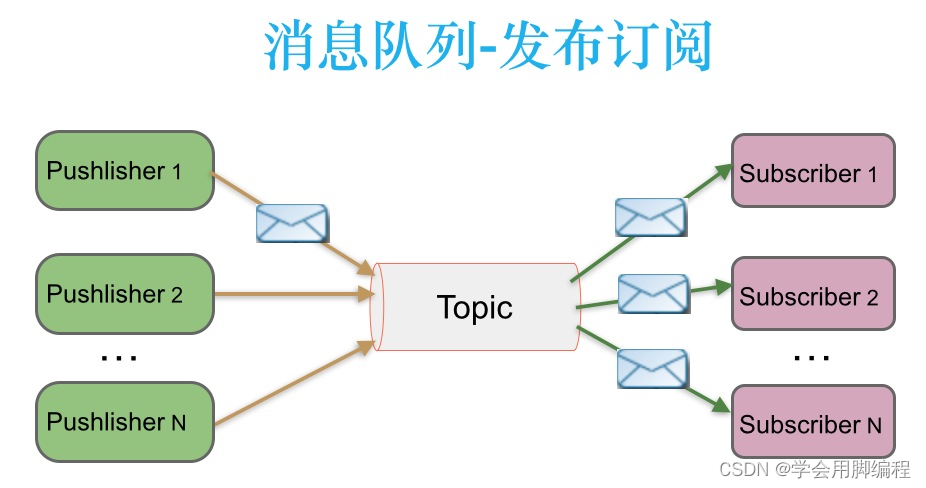
发布者发送到topic的消息,只有订阅了topic的订阅者才会收到消息。
三、Kafka中的术语解释概述
在深入理解Kafka之前,先介绍一下Kafka中的术语。下图展示了Kafka的相关术语以及之间的关系:

上图中一个topic配置了3个partition。Partition1有两个offset:0和1。Partition2有4个offset。Partition3有1个offset。副本的id和副本所在的机器的id恰好相同。
如果一个topic的副本数为3,那么Kafka将在集群中为每个partition创建3个相同的副本。集群中的每个broker存储一个或多个partition。多个producer和consumer可同时生产和消费数据。
broker
Kafka 集群包含一个或多个服务器,服务器节点称为broker。
broker存储topic的数据。如果某topic有N个partition,集群有N个broker,那么每个broker存储该topic的一个partition。
如果某topic有N个partition,集群有(N+M)个broker,那么其中有N个broker存储该topic的一个partition,剩下的M个broker不存储该topic的partition数据。
如果某topic有N个partition,集群中broker数目少于N个,那么一个broker存储该topic的一个或多个partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致Kafka集群数据不均衡。
Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
类似于数据库的表名
Partition
topic中的数据分割为一个或多个partition。每个topic至少有一个partition。每个partition中的数据使用多个segment文件存储。partition中的数据是有序的,不同partition间的数据丢失了数据的顺序。如果topic有多个partition,消费数据时就不能保证数据的顺序。在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1。
Producer
生产者即数据的发布者,该角色将消息发布到Kafka的topic中。broker接收到生产者发送的消息后,broker将该消息追加到当前用于追加数据的segment文件中。生产者发送的消息,存储到一个partition中,生产者也可以指定数据存储的partition。
Consumer
消费者可以从broker中读取数据。消费者可以消费多个topic中的数据。
Consumer Group
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
Leader
每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的partition。
Follower
Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与Leader保持数据同步。如果Leader失效,则从Follower中选举出一个新的Leader。当Follower与Leader挂掉、卡住或者同步太慢,leader会把这个follower从“in sync replicas”(ISR)列表中删除,重新创建一个Follower。
简单来说:
Producer:消息生产者,向Kafka中发布消息的角色。
Consumer:消息消费者,即从Kafka中拉取消息消费的客户端。
Consumer Group:消费者组,消费者组则是一组中存在多个消费者,消费者消费Broker中当前Topic的不同分区中的消息,消费者组之间互不影响,所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。某一个分区中的消息只能够一个消费者组中的一个消费者所消费
Broker:经纪人,一台Kafka服务器就是一个Broker,一个集群由多个Broker组成,一个Broker可以容纳多个Topic。
Topic:主题,可以理解为一个队列,生产者和消费者都是面向一个Topic
Partition:分区,为了实现扩展性,一个非常大的Topic可以分布到多个Broker上,一个Topic可以分为多个Partition,每个Partition是一个有序的队列(分区有序,不能保证全局有序)
Replica:副本Replication,为保证集群中某个节点发生故障,节点上的Partition数据不丢失,Kafka可以正常的工作,Kafka提供了副本机制,一个Topic的每个分区有若干个副本,一个Leader和多个Follower
Leader:每个分区多个副本的主角色,生产者发送数据的对象,以及消费者消费数据的对象都是Leader。
Follower:每个分区多个副本的从角色,实时的从Leader中同步数据,保持和Leader数据的同步,Leader发生故障的时候,某个Follower会成为新的Leader。
四、Kafka架构
拓扑结构图
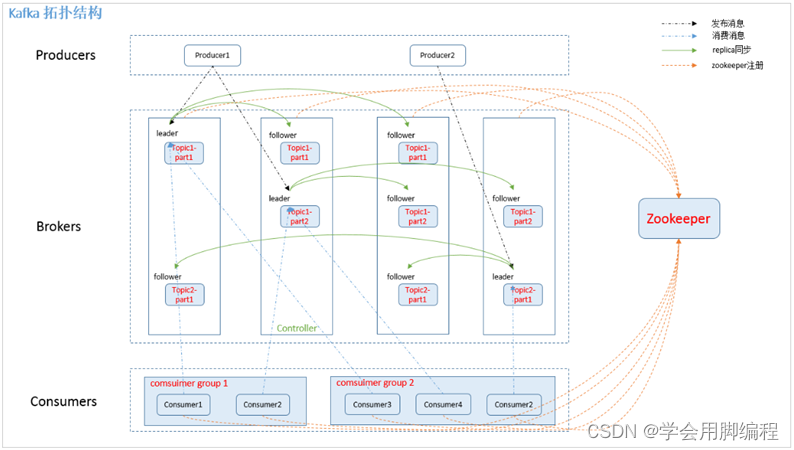
如上图所示,一个典型的Kafka集群中包含若干Producer(可以是web前端产生的Page View,或者是服务器日志,系统CPU、Memory等),若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高),若干Consumer Group,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。
版权归原作者 学会用脚编程 所有, 如有侵权,请联系我们删除。