
一、前言
Hadoop2.7.7官方文档地址:https://hadoop.apache.org/docs/r2.7.7/index.html
如下图,本文将以离线批处理大数据为例,演示简单的Hadoop流程,不作过多理论概念介绍。
具体内容具体可分为:
1、文件导入Hdfs;
2、MapReduce作业;
3、Hive建模;
4、Sqoop数据抽取。
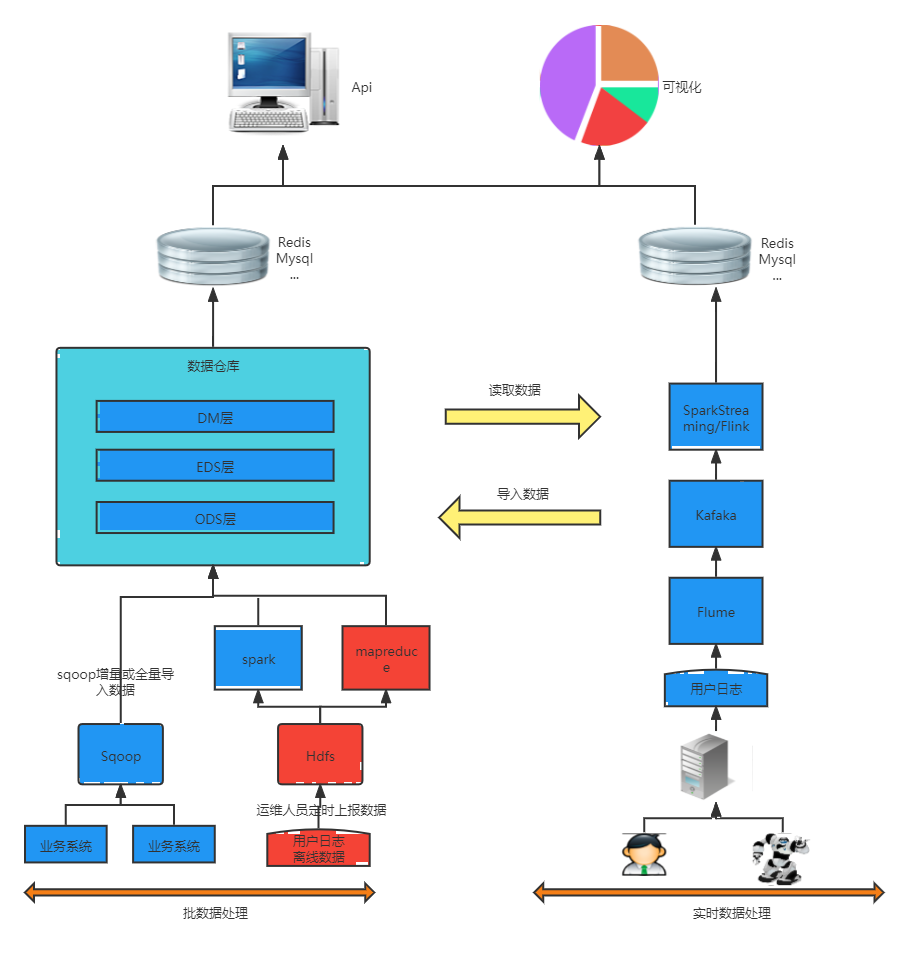
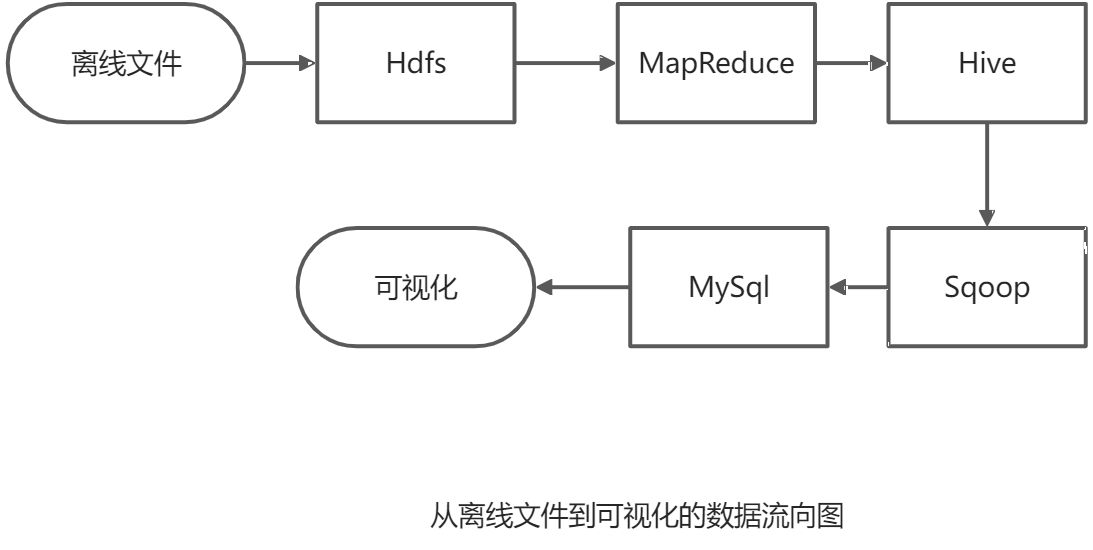
具体的流程如下图,下文的实践文档也是基于此流程顺序做示例:
二、准备工作
1、开发环境搭建(基于windows环境)
对于开发人员来说,无论是使用java或是scala开发Hadoop项目,1.1-1.4是必须要看的,具体的安装步骤,自行百度即可。
JDK包括了JRE(java运行时环境),开发人员本地开发环境安装JDK,部署JAVA程序的服务器可以只安装JRE。
Maven用于管理Java程序依赖的jar包,类似nuget管理依赖原件。此外,还用来作为项目的构建工具。
Eclipse、Idea,Java开发工具。Idea更为流行。
windows下的hadoop开发环境搭建,非必要。
1.1 java运行环境(JRE): windows10上的JDK安装及环境变量配置
1.2 Maven安装与配置(相当于Nuget)
1.3 java开发工具:IDEA或Eclipse安装
https://blog.csdn.net/weixin_44505194/article/details/104452880
https://blog.csdn.net/Youngist/article/details/106975302
1.4 java开发工具:IDEA配置maven、Eclipse配置Maven
1.5 Windows下Hadoop开发环境搭建windows+wsl/wsl2+docker+hadoop
https://www.jianshu.com/p/72aada169e92
https://blog.csdn.net/qq_32679139/article/details/104777295
不推荐,太消耗内存,环境搭好跑起来16G内存直接干到90%+,实际上还是基于linux来搭建伪分布式Hadoop
1.6 Windows下Hadoop开发环境搭建windows+Vmware+docker+hadoop
同上,不推荐。
1.7 Windows直接安装Hadoop
https://blog.csdn.net/qinlan1994/article/details/90413243
实际搭建相较Linux来说,更便捷,资源消耗少,开发人员调试比较方便。
1.8 XShell、XFtp安装
https://www.netsarang.com/en/free-for-home-school/
https://blog.csdn.net/love20165104027/article/details/84196543
2、相关知识准备
1.1 Linux常见命令
1.2 Hadoop相关概念
二、实践文档
1、HDFS篇
1.1 通过Web UI方式
http://Hdfs的nameNode所在机器的IP:50070/explorer.html#/
这种方式只能用于查看及下载文件。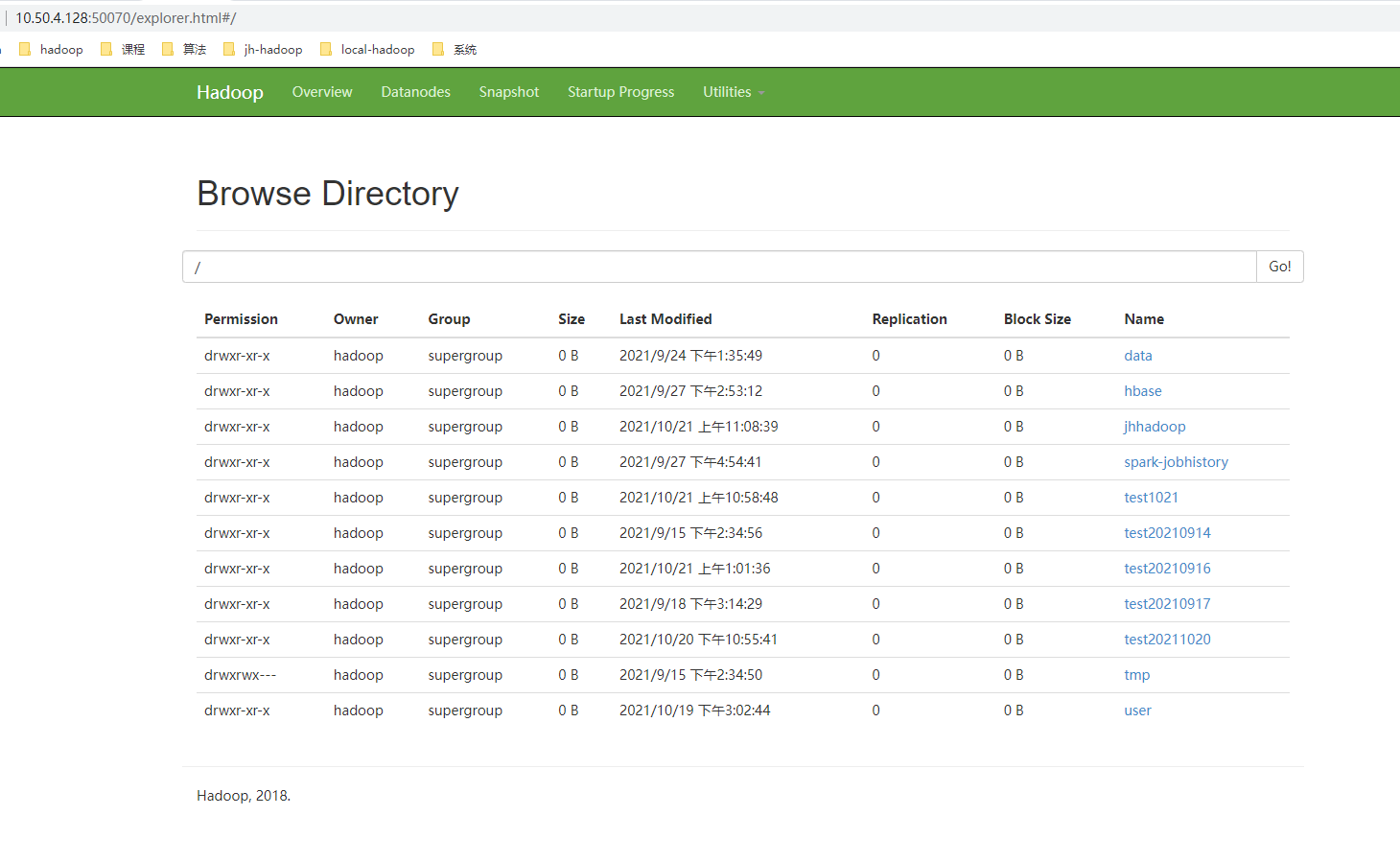
1.2 通过Hadoop的Shell命令操作Hdfs
与Hadoop所安装的机器通过XShell建立连接,到hadoop的安装路径的bin目录下,也就是$HADOOP_HOME/bin下可以看到hadoop和hdfs的脚本。分别输入命令 hadoop hdfs ,可以发现两个命令下都有文件系统相关选项。如下,我们可以使用hadoop fs,也可以使用hdfs dfs,但是在高版本的推荐hadoop fs命令
适用范围hadoop fs可以用于其他文件系统,不止是hdfs文件系统内,也就是说该命令的使用范围更广hadoop dfs只用于hdfs文件系统,实际运行还是hdfs dfshdfs dfs只用于hdfs文件系统
1.2.1 Hadoop fs 相关常用操作
在xhsell或者其他链接工具上输入hadoop fs 即可出现提示。如果对linux下文件相关操作命令熟悉的话,会发现相似度很高。
具体介绍参见官方文档:http://hadoop.apache.org/docs/r2.7.7/hadoop-project-dist/hadoop-common/FileSystemShell.html
1.2.2 上传本地文件至Hdfs
首先我们将测试文件(Data.csv)上传至hadoop所在的Linux上,如下图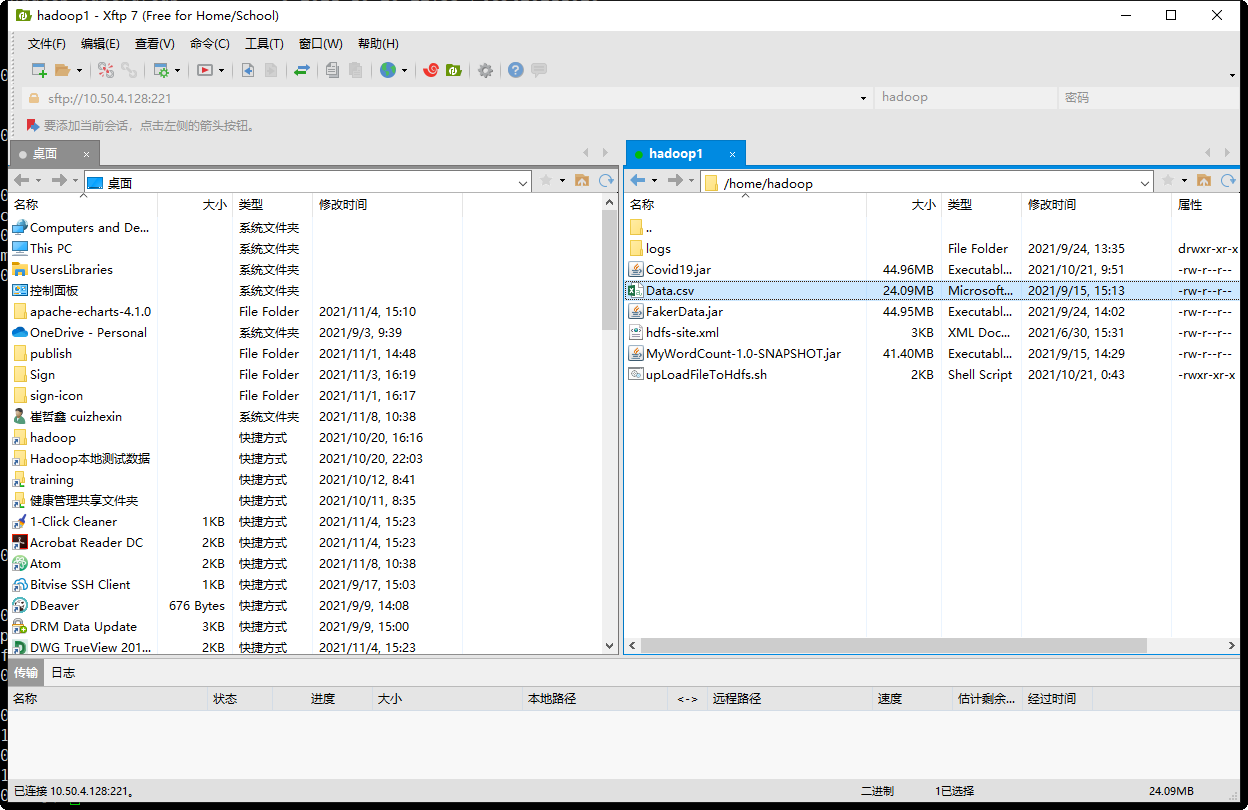
其次,通过 hadoop fs -copyFromLocal <源文件名称> <目标路径>
#--创建目录[hadoop@hadoop01 ~]$ hadoop fs -mkdir /test_hdfs_20211108
#--把本地文件上传到hdfs中[hadoop@hadoop01 ~]$ hadoop fs -copyFromLocal Data.csv /test_hdfs_20211108
#--查看文件最后1kb,使用cat命令也可以[hadoop@hadoop01 ~]$ hadoop fs -tail-f /test_hdfs_20211108/Data.csv
至此,最简单的一个文件上传至Hdfs已经完成,但是在真实的生产环境中,往往面对的是每时每刻都会生成的日志文件,将日志文件上传到Hdfs的工作一般都是运维人员来做。
1.2.3 编写Shell脚本,配合linux定时任务实现自动上传
不断生成的日志文件一般都是在夜间,凌晨进行Hdfs的上传,不可能运维人员守着服务器进行这个操作。且日志所在的路径,日志的命名都是有迹可循。所以可以通过Shell脚本,配合linux 定时任务来制定脚本的执行时机。这也是在很多企业的生产环境实际在用的一种方式。
那么如何编写SHell脚本,首先要明确,我们需要这个脚本做什么。核心要解决的问题:1、找到按规律生成的日志文件所在位置。2、将待上传的日志文件上传到指定目录,或追加到指定文件。
具体脚本如下。在面对不同的业务需求时,脚本的大体流程不变。
#!/bin/bash# 1、配置java环境exportJAVA_HOME=/opt/moudle/jdk
exportJRE_HOME=${JAVA_HOME}/jre
exportCLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
exportPATH=${JAVA_HOME}/bin:$PATH# 2、配置hadoop环境exportHADOOP_HOME=/opt/software/hadoop
exportPATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH# 1、先将需要上传的文件移动到待上传目录# 2、在讲文件移动到待上传目录时,将文件按照一定的格式重名名# /export/software/hadoop.log1 /export/data/click_log/click_log_{date}#日志文件存放的目录log_src_dir=/home/hadoop/logs/log/
#待上传文件存放的目录log_toupload_dir=/home/hadoop/logs/toupload/
#日志文件上传到hdfs的根路径hdfs_root_dir=/data/clickLog/
#打印环境变量信息echo"envs: hadoop_home: $HADOOP_HOME"#读取日志文件的目录,判断是否有需要上传的文件echo"log_src_dir:"$log_src_dirls$log_src_dir|whileread fileName;doif[["$fileName"== access.log.* ]];then# if [ "access.log" = "$fileName" ];thendate=$(date +%Y_%m_%d_%H_%M_%S)#将文件移动到待上传目录并重命名#打印信息echo"moving $log_src_dir$fileName to $log_toupload_dir"toupload_click_log_$fileName"$date"mv$log_src_dir$fileName$log_toupload_dir"toupload_click_log_$fileName"$date#将待上传的文件path写入一个列表文件willDoing#linux中>表示覆盖原文件内容(文件的日期也会自动更新),>>表示追加内容(会另起一行,文件的日期也会自动更新)。echo$log_toupload_dir"toupload_click_log_$fileName"$date>>$log_toupload_dir"willDoing."$date# fi是if的关闭标签fidone#找到列表文件willDoing#ls grep <args> 与参数匹配的过滤文件名#ls grep -v <args> 与参数不匹配的过滤文件名#下面的命令就是在待上传目录下,寻找文件名带有will的,且不含有 _COPY_ _DONE_的ls$log_toupload_dir|grep will |grep-v"_COPY_"|grep-v"_DONE_"|whileread line;do#打印信息echo"toupload is in file:"$line#将待上传文件列表willDoing改名为willDoing_COPY_mv$log_toupload_dir$line$log_toupload_dir$line"_COPY_"#读列表文件willDoing_COPY_的内容(一个一个的待上传文件名) ,此处的line 就是列表中的一个待上传文件的pathcat$log_toupload_dir$line"_COPY_"|whileread line;do#打印信息echo"puting...$line to hdfs path.....$hdfs_root_dir"#hdfs上传的核心语句,这里可以根据实际需要来选择appendToFile或copyFromLoacl等
hadoop fs -put$line$hdfs_root_dirdonemv$log_toupload_dir$line"_COPY_"$log_toupload_dir$line"_DONE_"done
至于配合linux crontab来执行定时任务,由于虚拟机的docker中并未安装crontab,这里不作演示。
1.3 通过Java API 加载文件至Hdfs
通过JavaApi的方式调用Hadoop提供的相关Api,首先就是要将Hadoop的相关jar包依赖进当前项目,与net项目添加Nuget依赖类似,在Java中,可以使用将离线jar添加到项目,也可以通过maven添加依赖。这里只介绍maven添加依赖。
如何创建Maven的java项目,代码实现逻辑很简单,不作赘述。相关代码已上传git。将代码运行起来之后,如下图swagger实例,可以基于hadoop提供的api实现的几个例子。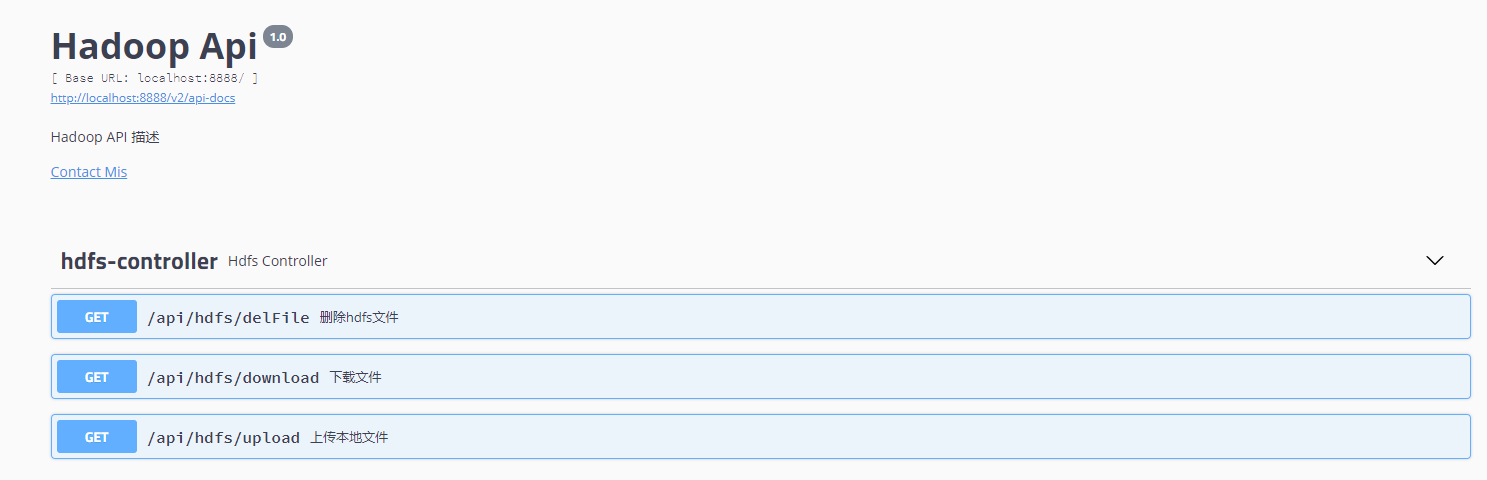
2、MapReduce篇
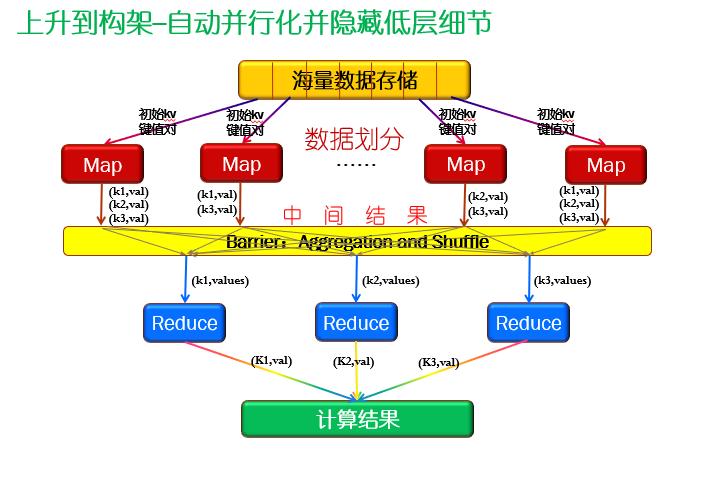
前面将离线文件上传至Hdfs之后,我们就需要使用MapReduce对离线文件中的数据进行一定程度的处理,比如一些过滤,清洗,分组、排序,求和,等等。下图为简单的map、reduce流程图。MapReduce在实际生产过程中有很多的应用,可以读取关系型数据库的数据、Hdfs的数据存储,可以输出到Hdfs中,Hive、甚至是关系型数据库中。
2.1 通过Java Api方式
跑mapreduce任务一般是将Java程序在本地打成jar,提交到hadoop集群上去跑任务,但如果出现错误往往很难定位错误,所以远程debug是开发中不可或缺的技能。通常大家都是在本地通过java写好mapreduce任务,希望能在window环境下运行。
2.1.1 本地无需Hadoop环境调试
这种方式最为简单,无需在windows配置任何Hadoop相关配置,只需要将Hadoop提供的相关jar通过maven依赖至项目中。
下面以一个简单需求为例演示:
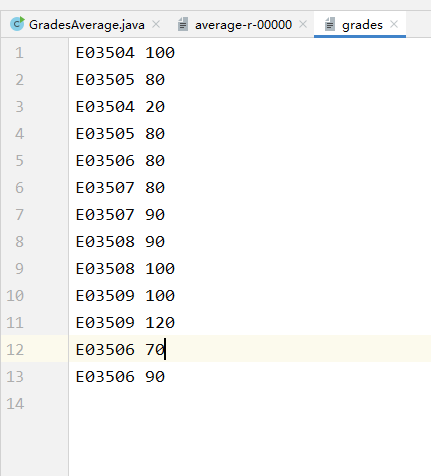
以上为某个文件,第一列与第二列中间通过空格隔开,第一列表示工号,第二列表示考试分数。需求是,得到每个工号的平均分。也就是如下的数据。
E03504 60.0
E03505 80.0
E03506 80.0
E03507 85.0
E03508 95.0
E03509 110.0
如果需求要求输出的文件中还要包含每个工号出现的次数,分数总和,如下
E03504 2 120 60.0
E03505 2 160 80.0
…
再如果需求要每个工号分别生成再不同的文件中
文件1:
E03504 2 120 60.0
文件2:
E03505 2 160 80.0
…
这几个需求实际上也就包含了我们在实际的业务场景下经常需要做的分组、求和、统计。下面是具体Job代码
packagegradesAverage;importorg.apache.hadoop.conf.Configuration;importorg.apache.hadoop.fs.FileSystem;importorg.apache.hadoop.fs.Path;importorg.apache.hadoop.io.FloatWritable;importorg.apache.hadoop.io.IntWritable;importorg.apache.hadoop.io.NullWritable;importorg.apache.hadoop.io.Text;importorg.apache.hadoop.mapreduce.*;importorg.apache.hadoop.mapreduce.lib.input.FileInputFormat;importorg.apache.hadoop.mapreduce.lib.output.FileOutputFormat;importorg.apache.hadoop.mapreduce.lib.output.TextOutputFormat;importjava.io.IOException;importjava.util.HashMap;importjava.util.Map;publicclassGradesAverage{/**
* MapReduce的核心思想就是分而治之
* Mapper 负责分
*/publicstaticclassTokenizerMapperextendsMapper<Object,Text,Text,IntWritable>{// Text 对应 string// IntWritable 对应 int// 在map方法外创建,避免重复创建privateText student =newText();privateIntWritable grade =newIntWritable();/**
* MapReduce的核心思想就是分而治之
* Mapper 负责分
*
* @param key 当前行行首从文件开始处计算的偏移量,而不是当前行的内容。
* @param value 当前行的内容,如 E03504 100
* @param context 记录map执行的上下文,是map和reduce执行各个函数之间的桥梁,可以理解为session
*/publicvoidmap(Object key,Text value,Context context)throwsIOException,InterruptedException{System.out.println("key is:"+ key +",value is: "+ value.toString());String[] list_strs = value.toString().split(" ");// 因为每行只有一个学号和对应成绩,不需要考虑切分多个词// list_strs = ['E03504','100']
student.set(list_strs[0]);
grade.set(Integer.parseInt(list_strs[1]));// 输出到上下文中
context.write(student, grade);}}/**
* Reducer 负责合
*/publicstaticclassGradesAverageReducerextendsReducer<Text,IntWritable,Text,FloatWritable>{privateFloatWritable gradesSum =newFloatWritable();/**
* reduce 计算
* mapreduce中,map阶段处理的数据如何传递给reduce阶段,是mapreduce框架中最关键的一个流程,这个流程就叫shuffle
* shuffle: 洗牌、发牌(核心机制:数据分区、排序、缓存),具体来说就是将maptask输出的处理结果数据,
* 分发给reducetask,并在分发的过程中,对数据按key进行了分区和排序
*
* @param key 这里的key是我们在map中写到context中的student
* @param values student对应的所有grades的集合
* @param context 上下文
*/publicvoidreduce(Text key,Iterable<IntWritable> values,Context context)throwsIOException,InterruptedException{int sum =0;int grades =0;for(IntWritable val : values){// 相同key出现的总次数
sum +=1;// key对应所有分数的综合
grades += val.get();// 这里可以通过这些数据进行一些简单的求和、求词频等计算}System.out.println("Reduce----student is:"+ key.toString()+",grades is:"+ grades +",sum is:"+ sum);
gradesSum.set((float) grades / sum);
context.write(key, gradesSum);//Text key1 = new Text();//key1.set(key.toString()+" "+sum+" "+grades+" "+gradesSum);//context.write(key1, null);}}/*
* 对mapper的结果进行分区,让多个reducer分别对多个partition文件并行处理。既然是分区,那么最重要的就是确定分区的逻辑,
* 也就是业务需求下,该根据什么条件进行分区,比如这里根据工号,或者根据分数范围分区,这些都是逻辑部分,
* 逻辑的最终目的是输出分区数量。但是这个分区数量要与reduceTask的数量一致。
* 例如:假设自定义分区数为6,reduceTask数量为6则
* job.setNumReduceTasks(1);会正常运行,只不过会产生一个输出文件
* job.setNumReduceTasks(3);会报错 java.io.IOException: Illegal partition for E03507
* job.setNumReduceTasks(7);大于5,程序会正常运行,会产生空文件
*
*/privatestaticclassMyPartitionerextendsPartitioner<Text,IntWritable>{privatestaticint index =-1;privateMap<String,Integer> map =newHashMap<String,Integer>();/*
* return:返回值为该行数据存储在第几个分区
* numPartitions: reduce执行的个数
*/@OverridepublicintgetPartition(Text key,IntWritable intWritable,int i){String currenKey = key.toString();// 判断key是否存在if(map.containsKey(currenKey)){return map.get(currenKey);}else{
map.put(currenKey,++index);return index;}}}// 重新定义最终输出的文件名称publicstaticclassMyOutPutFormatextendsTextOutputFormat<Text,IntWritable>{protectedstaticvoidsetOutputName(JobContext job,String name){
job.getConfiguration().set(BASE_OUTPUT_NAME, name);}}publicstaticvoidmain(String[] args)throwsIOException,ClassNotFoundException,InterruptedException{// 1.设置HDFS配置信息Configuration conf =newConfiguration();// 2.设置MapReduce作业配置信息String jobName ="GradesAverage";// 定义作业名称Job job =Job.getInstance(conf, jobName);
job.setJarByClass(GradesAverage.class);// 指定作业类//job.setJar("export\\GradesAverage.jar"); // 指定本地jar包
job.setMapperClass(TokenizerMapper.class);
job.setReducerClass(GradesAverageReducer.class);
job.setPartitionerClass(MyPartitioner.class);
job.setNumReduceTasks(6);
job.setOutputFormatClass(MyOutPutFormat.class);//输出key-value的类型
job.setOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputValueClass(FloatWritable.class);// 3.设置作业输入和输出路径//Path inPath =newPath("D:\\java_project\\nh_hadoop\\MRDemo\\input\\grades");Path outPath =newPath("D:\\java_project\\nh_hadoop\\MRDemo\\output\\grades\\");if(args.length ==2){
inPath =newPath(args[0]);
outPath =newPath(args[1]);}MyOutPutFormat.setOutputName(job,"average");FileInputFormat.addInputPath(job, inPath);FileOutputFormat.setOutputPath(job, outPath);// 如果输出目录已存在则删除FileSystem fs =FileSystem.get(conf);if(fs.exists(outPath)){
fs.delete(outPath,true);}// 4.运行作业System.out.println("Job: "+ jobName +" is running...");boolean completion = job.waitForCompletion(true);if(completion){System.out.println("统计 success!");System.exit(0);}else{System.out.println("统计 failed!");System.exit(1);}}}
输出结果如图,在本地文件夹中: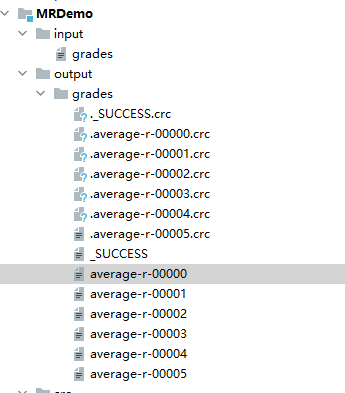
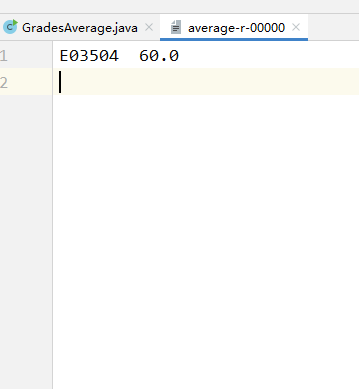
2.1.2 本地远程方式调试MapReduce
如使用这种方式,只需要在上一种方式的基础上,做一些修改
1、指定Hdfs地址。
2、本地伪装用户为Hadoop的超级用户
3、将Hadoop安装目录下的core_site.xml、mapper_site.xml、yarn_site.xml、hdfs_site.xml拷贝至当前项目的resources目录下
// 1.设置HDFS配置信息Configuration conf =newConfiguration();System.setProperty("HADOOP_USER_NAME","hadoop");String namenode_ip ="10.50.4.128";String hdfs ="hdfs://"+ namenode_ip +":9010";
conf.set("fs.defaultFS", hdfs);
conf.set("hadoop.job.user","hadoop");
conf.set("dfs.client.use.datanode.hostname","true");
conf.set("mapreduce.app-submission.cross-platform","true");
但是需要注意的是,在yarn_site.xml中,需要指定resourcemanager的地址,但是由于咱们公司hadoop这个地址是在docker中部署,没有将hadoop03、04机器的ip映射出来,所以本地调试时,就会报错
<property><!-- 指定RM的名字 --><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value></property><property><!-- 分别指定RM的地址 --><name>yarn.resourcemanager.hostname.rm1</name><value>hadoop03</value></property><property><name>yarn.resourcemanager.hostname.rm2</name><value>hadoop04</value></property>
这种方式的输出结果如下图,通过hdfs web ui浏览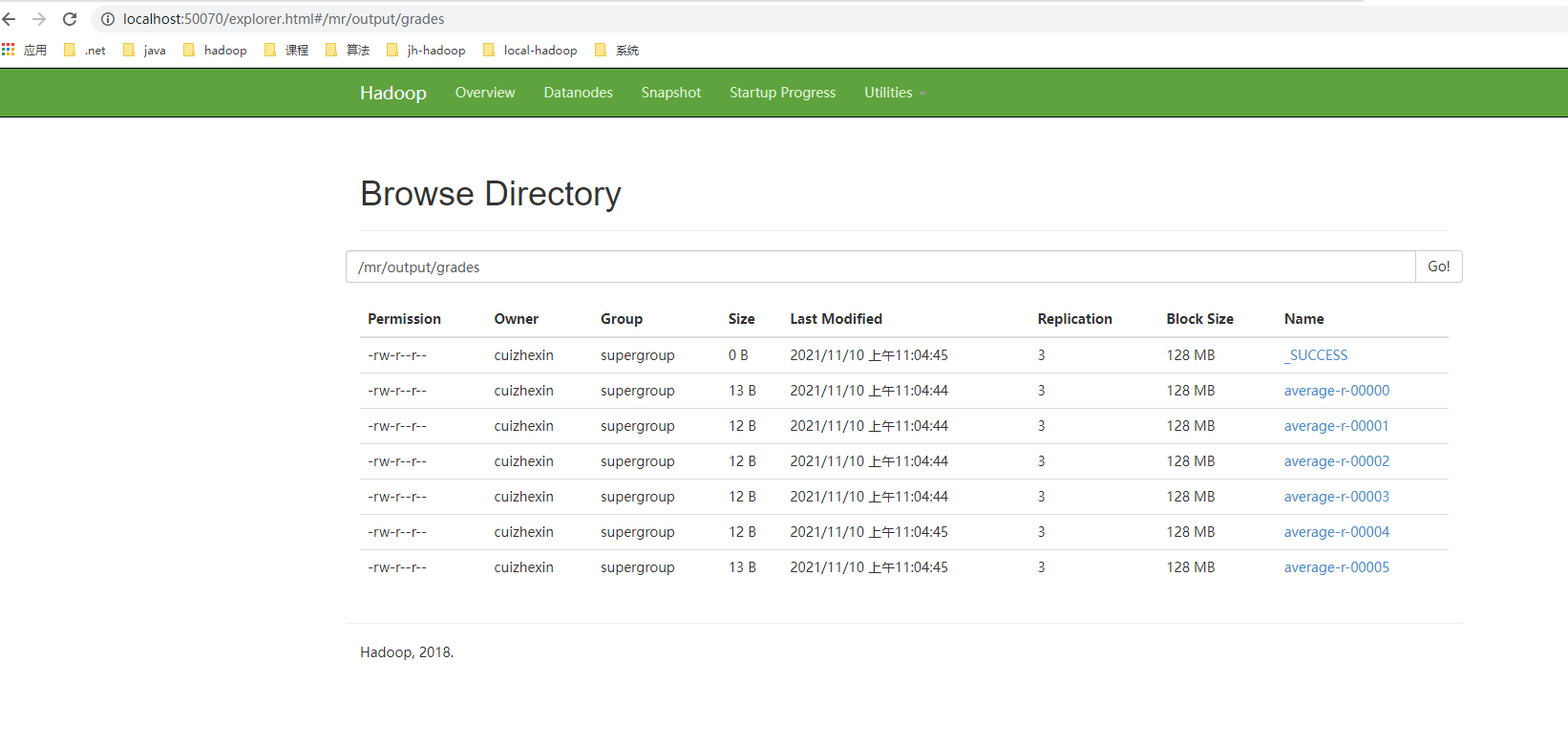
2.1.3 命令行执行Jar包方式
这种方式,在第一种方式的基础上,无需做其他修改。
1、将当前项目打成jar,然后上传至hadoop所在的linux机器
2、通过命令行执行 hadoop jar GradesJob.jar
hadoop jar GradesJob.jar
3、成功日志如下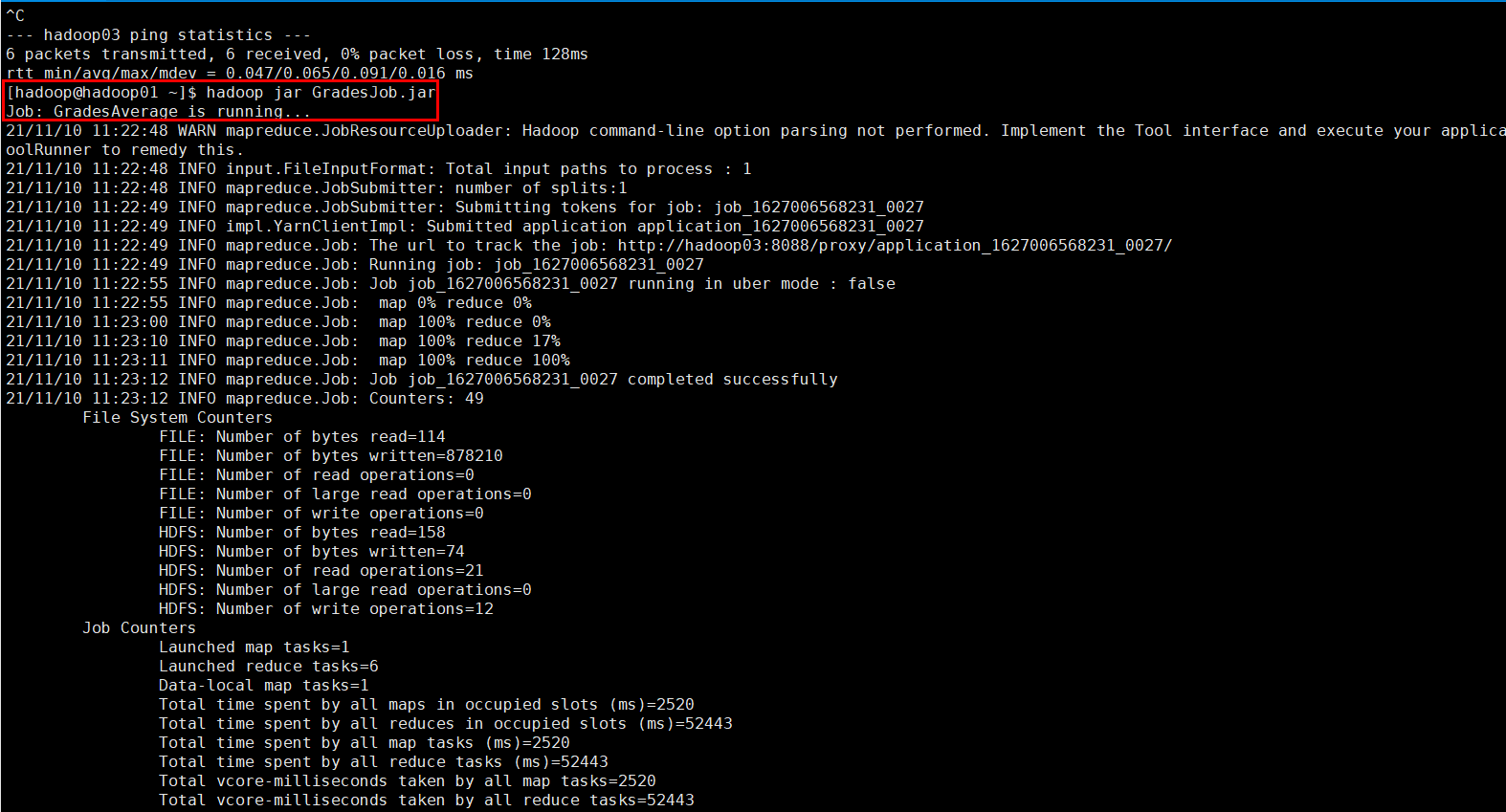
4、通过webui查看文件
2.1.4 Shell脚本定时执行MapReduce作业
下面是Shell伪代码,具体代码自行实现。需要注意的时如果通过这种方式,在作业的jarClass的main函数需要有返回值,或者是通过判断mr作业的日志来判断作业是否成功执行。
1、 判断mapreduce作业所需要的数据来源是否存在,这个一般是通过Hdfs的shell脚本在成功将文件上传至hdfs后,记录到某个中间文件中。当前shell通过读取这个中间文件来判断是否需要继续执行mr作业。
2、hadoop jar **.jar <参数1><参数2> 参数1、2对应了jar中main函数的string[] args,用于传递当前作业所需的输入文件、输出文件路径。
3、读取mr作业执行的返回结果,将其记录在某个记录mr的执行结果的中间文件中。用于Hive的Shell来进行判断
4、根据需要清空之前hdfs shell生成的中间文件
3、Hive篇
通过MapReduce作业,我们可以将符合我们业务需求的数据清洗过滤出来。我们通过Hive将清洗之后的文件加载到Hive中,再通过Sql进行一些复杂的关联计算等。将文件加载到HIve时,涉及到Hive建模问题,Hive的建模与传统的数据库设计理念不同,但其实如果不考虑数据仓库的情况下,与其他数据库设计无二,在这里不作赘述。
3.1 使用Hive自带的命令行接口执行Hive SQL、设置参数等功能
首先通过Xshell连接HIVE所在的虚拟机。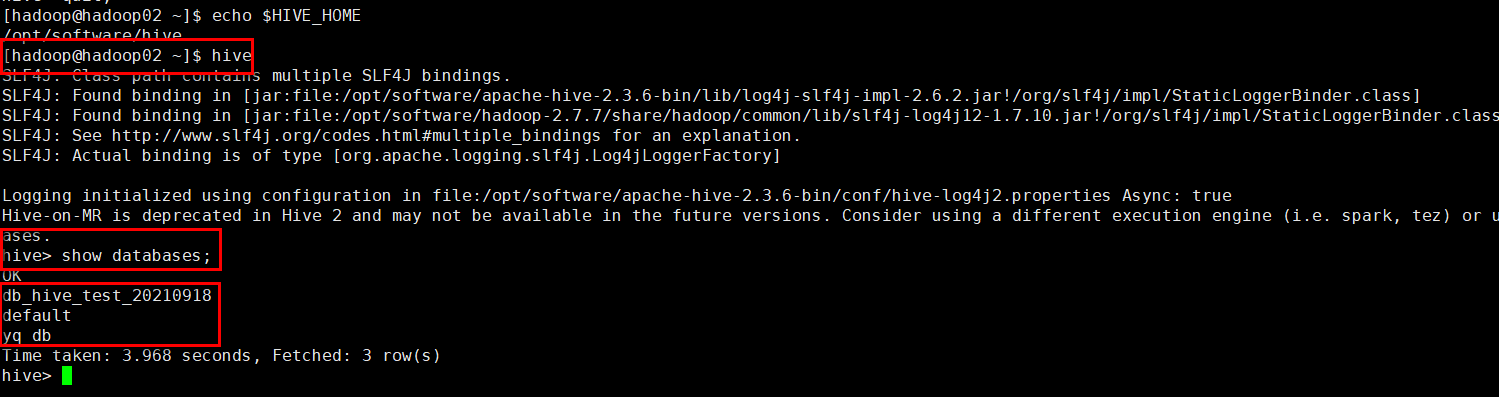
3.1.1、数据库基本操作
--展示所有数据库
show databases;
--切换数据库
use database_name;
/*创建数据库
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];
*/
create database test;
/*
删除数据库
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
*/
drop database database_name;
3.1.2、数据库表的基本操作
hive>createdatabase test;
OK
Time taken: 0.17 seconds
hive>use test;
OK
Time taken: 0.013 seconds
hive>createtable grades(student string,average float);
OK
Time taken: 0.433 seconds
hive>showtables;
OK
grades
Time taken: 0.023 seconds, Fetched: 1row(s)
hive>desc grades;
OK
student string
average floatTime taken: 0.067 seconds, Fetched: 2row(s)
hive># 创建表createtable covid_1021 ( provinceName string , pZipCode string, pConfirmedCount int, pSuspectedCount int, pCuredCount int, pDeadCount int, updateTime string )row format delimited fieldsterminatedby',';
hive># 加载数据到表中loaddata inpath '/jhhadoop/testmr/part-r-00000'intotable covid_1021;
hive>selectcount(*)from covid_1021;
执行查询如下图,一个简单的count函数,花费了9秒多,这也是HIVE的特点之一,对查询速度要求不高,所以也就注定了Hive不适合做实时查询。而是将查询结果通过Sqoop或Kettle等抽取到传统型数据库中,再通过代码封装成服务API提供接口。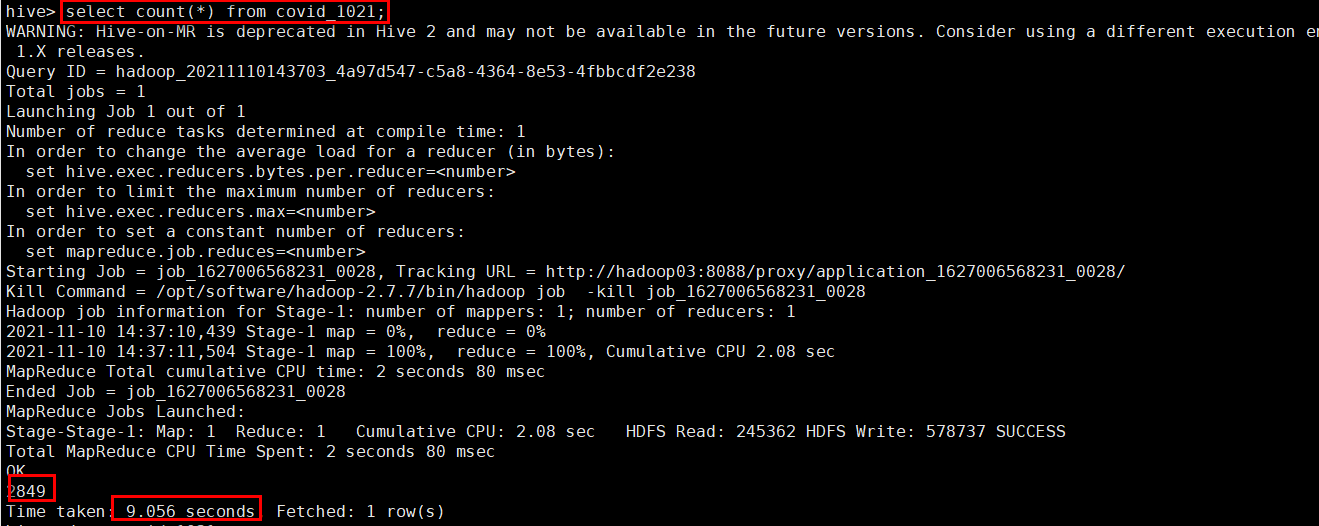
3.2 通过客户端界面工具连接
环境:windows10+hadoop+hive,为什么没有使用公司的测试环境,是因为hive的10000、10002端口没有映射出来。想要通过jdbc或者客户端工具连接,首先要启动hiveserver2,这里不做赘述。
DBeaver或DataGrip等数据库连接工具都支持Hive的连接。这里演示如何使用DBeaver连接Hive。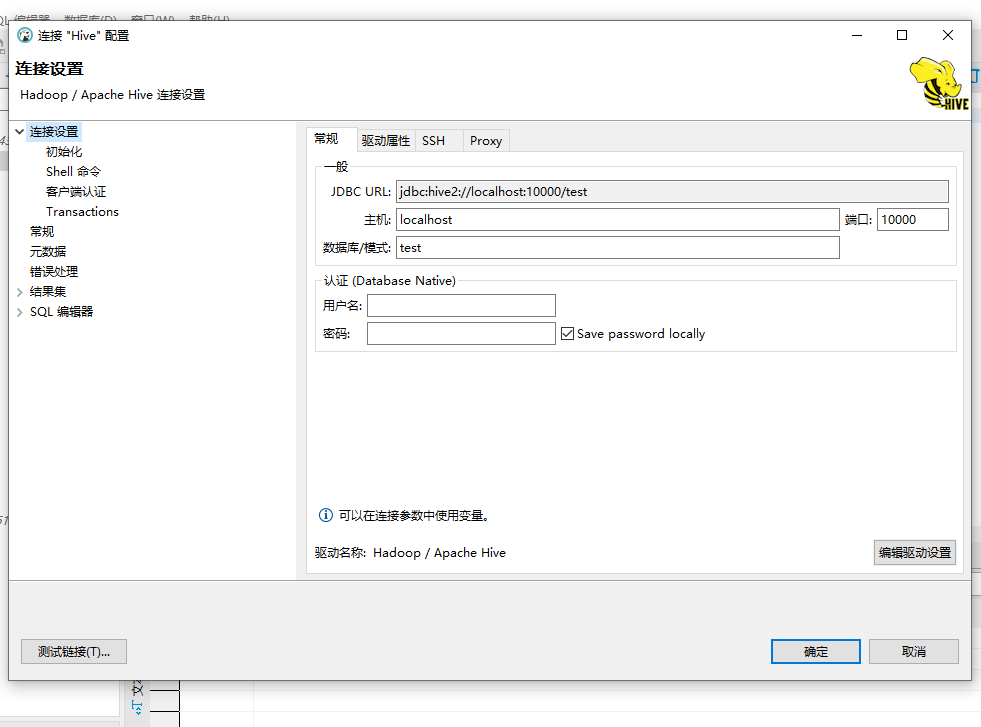
如上图所示,与一般的数据库连接无二。但是需要注意的是,hive默认是不需要用户名及密码的,如果在真实的开发过程中,你需要自定义hive的用户名密码,这是通过hive-site.xml中配置,指定你要校验用户名密码的jar包,不做赘述。还有一点是,在windows环境下去链接,带的默认用户名是当前机器的名称,是不能成功连接的的,需要在hadoop的core-site.xml里面进行配置,我当前的用户名为崔哲鑫,那就需要加上下面的这两个注释。
<property><name>hadoop.proxyuser.cuizhexin.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.cuizhexin.groups</name><value>*</value></property>
2、配置数据库连接驱动,这里建议使用hive自带的连接驱动hive-jdbc-2.3.2-standalone.jar ,位置在hive安装目录>jdbc下。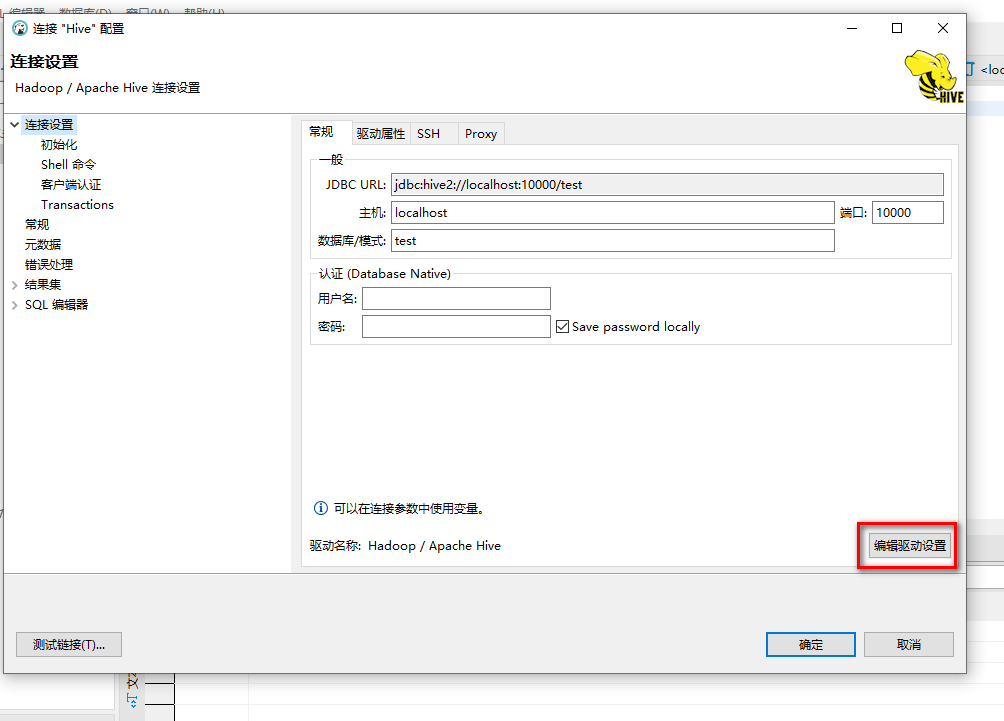

最后测试连接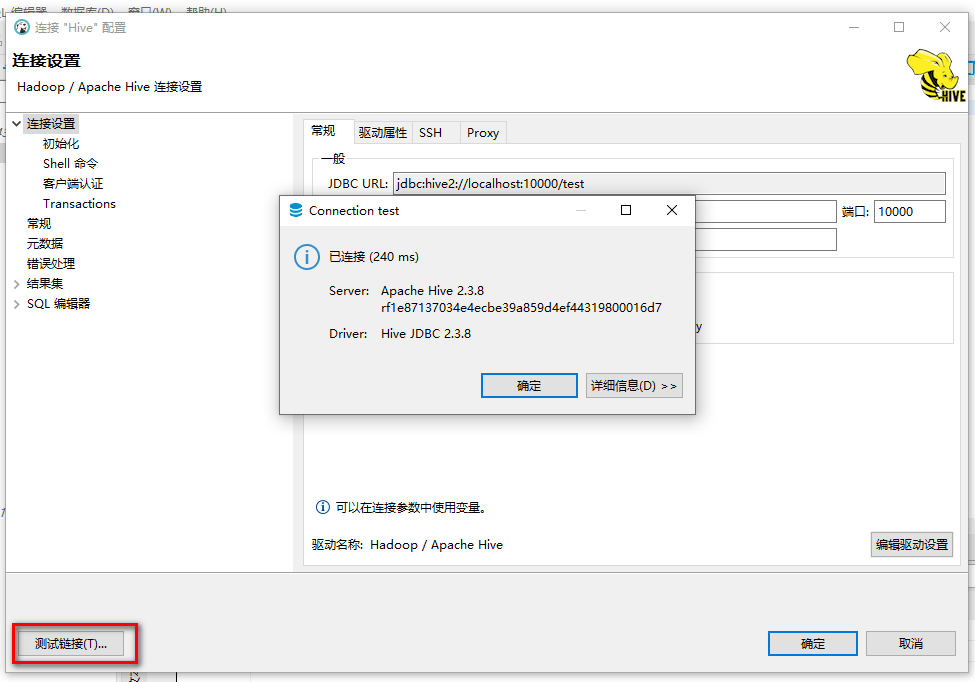
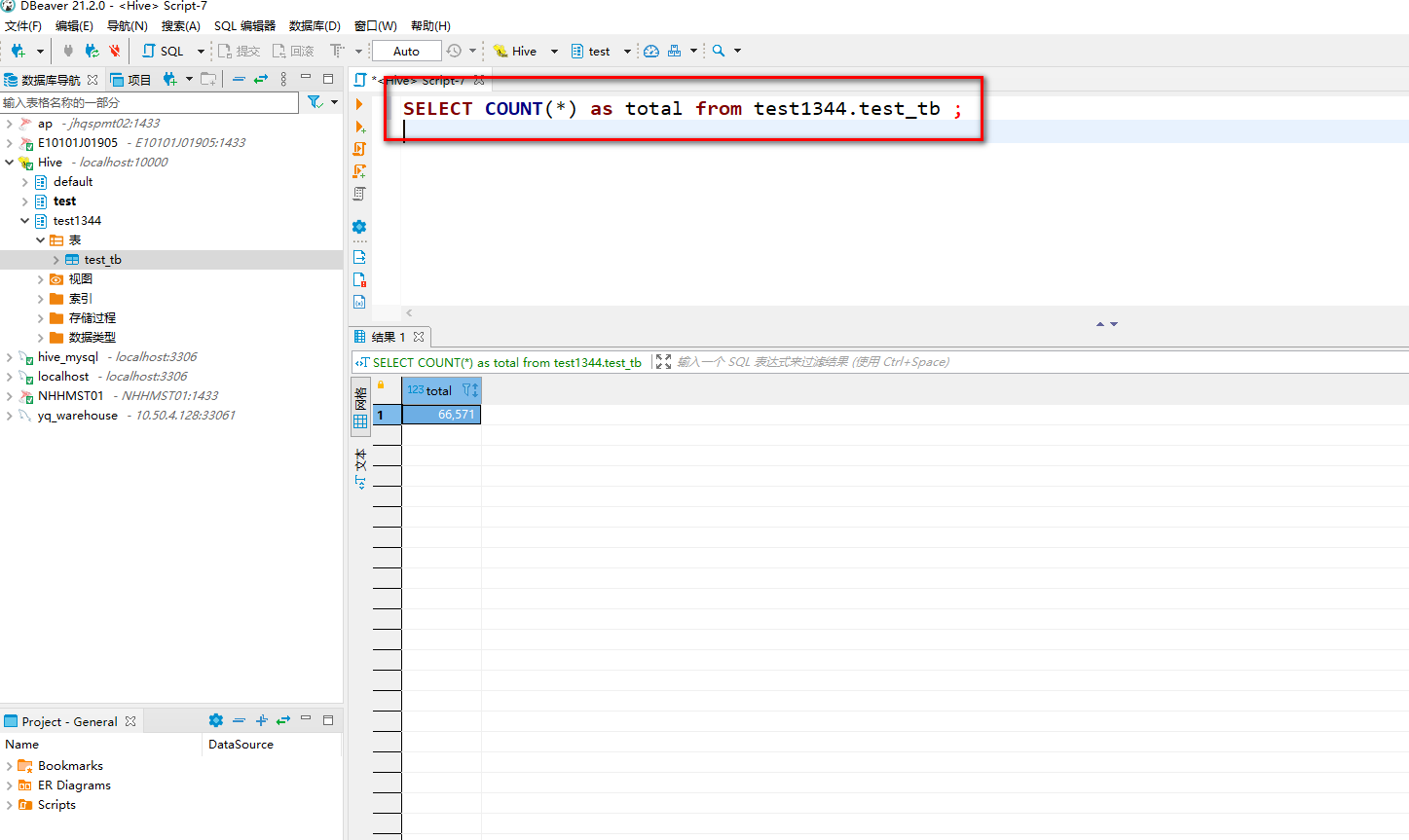
在hive的webUI http://ip:10002/上就可以看到我们执行的这些sql语句了
最后顺便看一下hive支持的数据类型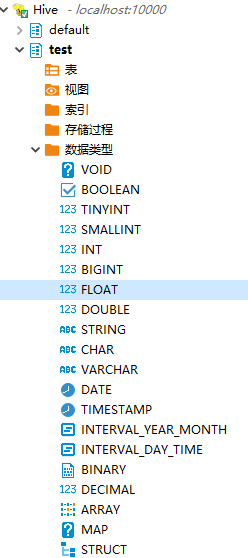
3.3 JavaApi通过Jdbc连接Hive
其实通过Java Api来去执行hive,在真实生产过程中,并不常用,因为Hive的sql执行时间估计不了,一般都很长,这其实是很影响体验的。这里就不做介绍了。
4、Sqoop篇
Sqoop目前有两个大版本,以Sqoop1为例。Sqoop1的使用更多的还是通过CLI命令行窗口来进行数据的导入导出。当然也可以通过Java APi来操作,但是是通过程序抱着命令来执行。
1、通过查看指定的数据库的databases来测试连接
sqoop list-databases -connect jdbc:mysql://10.50.4.128:33061/ -username hive -password hive
如下图,则连接成功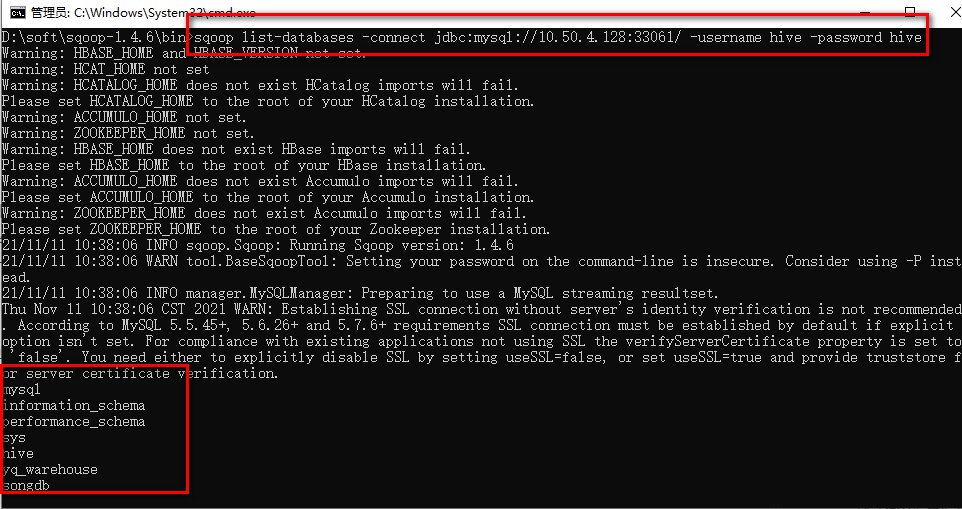
2、将数据库的表导入至Hive中(全量)
在Sqoop的导入中,可以使用where 或–query 'select语句’用于过滤数据
sqoop import--connect jdbc:mysql://10.50.4.128:33061/songdb --username hive --password hive --table song --hive-import
执行日志:通过日志可以分析出来几个核心的步骤:
1、26行可以看出 Writing jar file: \tmp\sqoop-cuizhexin\compile\1f8b1af217ae80907a5b1220db9310a1\song.jar,实际上Sqoop是把我们的命令首先达成一个jar包
2、43行,提交song.jar到mapreduce,然后执行Mapreduce作业
3、153行,在HIve中创建与导入表相同结构的表
4、264行,LOAD DATA INPATH ‘hdfs://localhost:9000/user/cuizhexin/song’ INTO TABLE
song
从hdfs中加载数据到hive 的song表中,这里也就可以知道上面的mapreduce实际上做的是将数据从mysql中读出,写入hdfs中。
D:\soft\sqoop-1.4.6\bin>sqoop import--connect jdbc:mysql://10.50.4.128:33061/songdb --username hive --password hive --table song --hive-import
Warning: HBASE_HOME and HBASE_VERSION not set.
Warning: HCAT_HOME not set
Warning: HCATALOG_HOME does not exist HCatalog imports will fail.
Please set HCATALOG_HOME to the root of your HCatalog installation.
Warning: ACCUMULO_HOME not set.
Warning: ZOOKEEPER_HOME not set.
Warning: HBASE_HOME does not exist HBase imports will fail.
Please set HBASE_HOME to the root of your HBase installation.
Warning: ACCUMULO_HOME does not exist Accumulo imports will fail.
Please set ACCUMULO_HOME to the root of your Accumulo installation.
Warning: ZOOKEEPER_HOME does not exist Accumulo imports will fail.
Please set ZOOKEEPER_HOME to the root of your Zookeeper installation.
21/11/11 10:43:03 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
21/11/11 10:43:03 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
21/11/11 10:43:03 INFO tool.BaseSqoopTool: Using Hive-specific delimiters for output. You can override
21/11/11 10:43:03 INFO tool.BaseSqoopTool: delimiters with --fields-terminated-by, etc.
21/11/11 10:43:03 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
21/11/11 10:43:03 INFO tool.CodeGenTool: Beginning code generation
Thu Nov 1110:43:03 CST 2021 WARN: Establishing SSL connection without server's identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or setuseSSL=true and provide truststore for server certificate verification.
21/11/11 10:43:03 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `song` AS t LIMIT 121/11/11 10:43:03 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `song` AS t LIMIT 121/11/11 10:43:03 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is D:\soft\hadoop-2.7.7
注: \tmp\sqoop-cuizhexin\compile\1f8b1af217ae80907a5b1220db9310a1\song.java使用或覆盖了已过时的 API。
注: 有关详细信息, 请使用 -Xlint:deprecation 重新编译。
21/11/11 10:43:05 INFO orm.CompilationManager: Writing jar file: \tmp\sqoop-cuizhexin\compile\1f8b1af217ae80907a5b1220db9310a1\song.jar
21/11/11 10:43:05 WARN manager.MySQLManager: It looks like you are importing from mysql.
21/11/11 10:43:05 WARN manager.MySQLManager: This transfer can be faster! Use the --direct21/11/11 10:43:05 WARN manager.MySQLManager: option to exercise a MySQL-specific fast path.
21/11/11 10:43:05 INFO manager.MySQLManager: Setting zero DATETIME behavior to convertToNull (mysql)21/11/11 10:43:05 INFO mapreduce.ImportJobBase: Beginning import of song
21/11/11 10:43:05 INFO Configuration.deprecation: mapred.job.tracker is deprecated. Instead, use mapreduce.jobtracker.address
21/11/11 10:43:05 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
21/11/11 10:43:05 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
21/11/11 10:43:05 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
Thu Nov 1110:43:06 CST 2021 WARN: Establishing SSL connection without server's identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or setuseSSL=true and provide truststore for server certificate verification.
21/11/11 10:43:06 INFO db.DBInputFormat: Using read commited transaction isolation
21/11/11 10:43:06 INFO db.DataDrivenDBInputFormat: BoundingValsQuery: SELECT MIN(`source_id`), MAX(`source_id`) FROM `song`21/11/11 10:43:06 WARN db.TextSplitter: Generating splits for a textual index column.
21/11/11 10:43:06 WARN db.TextSplitter: If your database sorts in a case-insensitive order, this may result in a partial import or duplicate records.
21/11/11 10:43:06 WARN db.TextSplitter: You are strongly encouraged to choose an integral split column.
21/11/11 10:43:06 INFO mapreduce.JobSubmitter: number of splits:5
21/11/11 10:43:06 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1636592599511_0002
21/11/11 10:43:06 INFO impl.YarnClientImpl: Submitted application application_1636592599511_0002
21/11/11 10:43:06 INFO mapreduce.Job: The url to track the job: http://E10101J01905:8088/proxy/application_1636592599511_0002/
21/11/11 10:43:06 INFO mapreduce.Job: Running job: job_1636592599511_0002
21/11/11 10:43:13 INFO mapreduce.Job: Job job_1636592599511_0002 running in uber mode :false21/11/11 10:43:13 INFO mapreduce.Job: map 0% reduce 0%
21/11/11 10:43:20 INFO mapreduce.Job: map 40% reduce 0%
21/11/11 10:43:21 INFO mapreduce.Job: map 60% reduce 0%
21/11/11 10:43:22 INFO mapreduce.Job: map 80% reduce 0%
21/11/11 10:43:23 INFO mapreduce.Job: map 100% reduce 0%
21/11/11 10:43:23 INFO mapreduce.Job: Job job_1636592599511_0002 completed successfully
21/11/11 10:43:23 INFO mapreduce.Job: Counters: 30
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=644075
FILE: Number of readoperations=0
FILE: Number of large readoperations=0
FILE: Number of writeoperations=0
HDFS: Number of bytes read=716
HDFS: Number of bytes written=42726933
HDFS: Number of readoperations=20
HDFS: Number of large readoperations=0
HDFS: Number of writeoperations=10
Job Counters
Launched map tasks=5
Other local map tasks=5
Total time spent by all maps in occupied slots (ms)=19130
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=19130
Total vcore-milliseconds taken by all map tasks=19130
Total megabyte-milliseconds taken by all map tasks=19589120
Map-Reduce Framework
Map input records=177315
Map output records=177315
Input splitbytes=716
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=233
CPU time spent (ms)=9572
Physical memory (bytes)snapshot=1055612928
Virtual memory (bytes)snapshot=1559941120
Total committed heap usage (bytes)=748158976
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=4272693321/11/11 10:43:23 INFO mapreduce.ImportJobBase: Transferred 40.7476 MB in18.2398 seconds (2.234 MB/sec)21/11/11 10:43:23 INFO mapreduce.ImportJobBase: Retrieved 177315 records.
Thu Nov 1110:43:23 CST 2021 WARN: Establishing SSL connection without server's identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or setuseSSL=true and provide truststore for server certificate verification.
21/11/11 10:43:23 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `song` AS t LIMIT 121/11/11 10:43:23 INFO hive.HiveImport: Loading uploaded data into Hive
21/11/11 10:43:25 INFO hive.HiveImport: SLF4J: Class path contains multiple SLF4J bindings.
21/11/11 10:43:25 INFO hive.HiveImport: SLF4J: Found binding in[jar:file:/D:/soft/hadoop-2.7.7/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]21/11/11 10:43:25 INFO hive.HiveImport: SLF4J: Found binding in[jar:file:/D:/soft/apache-hive-2.3.8-bin/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]21/11/11 10:43:25 INFO hive.HiveImport: SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.21/11/11 10:43:25 INFO hive.HiveImport: SLF4J: Actual binding is of type[org.slf4j.impl.Log4jLoggerFactory]21/11/11 10:43:25 INFO hive.HiveImport: 21/11/11 10:43:25 INFO conf.HiveConf: Found configuration file file:/D:/soft/apache-hive-2.3.8-bin/conf/hive-site.xml
21/11/11 10:43:25 INFO hive.HiveImport: 21/11/11 10:43:25 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.compress does not exist
21/11/11 10:43:25 INFO hive.HiveImport: 21/11/11 10:43:25 WARN conf.HiveConf: HiveConf of name hive.exec.orc.zerocopy does not exist
21/11/11 10:43:25 INFO hive.HiveImport: 21/11/11 10:43:25 WARN conf.HiveConf: HiveConf of name hive.orc.cache.stripe.details.size does not exist
21/11/11 10:43:25 INFO hive.HiveImport: 21/11/11 10:43:25 WARN conf.HiveConf: HiveConf of name hive.hwi.war.file does not exist
21/11/11 10:43:25 INFO hive.HiveImport: 21/11/11 10:43:25 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.row.index.stride does not exist
21/11/11 10:43:25 INFO hive.HiveImport: 21/11/11 10:43:25 WARN conf.HiveConf: HiveConf of name hive.outerjoin.supports.filters does not exist
21/11/11 10:43:25 INFO hive.HiveImport: 21/11/11 10:43:25 WARN conf.HiveConf: HiveConf of name hive.exec.orc.compression.strategy does not exist
21/11/11 10:43:25 INFO hive.HiveImport: 21/11/11 10:43:25 WARN conf.HiveConf: HiveConf of name hive.exec.orc.dictionary.key.size.threshold does not exist
21/11/11 10:43:25 INFO hive.HiveImport: 21/11/11 10:43:25 WARN conf.HiveConf: HiveConf of name hive.orc.row.index.stride.dictionary.check does not exist
21/11/11 10:43:25 INFO hive.HiveImport: 21/11/11 10:43:25 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.block.padding does not exist
21/11/11 10:43:25 INFO hive.HiveImport: 21/11/11 10:43:25 WARN conf.HiveConf: HiveConf of name hive.exec.orc.block.padding.tolerance does not exist
21/11/11 10:43:25 INFO hive.HiveImport: 21/11/11 10:43:25 WARN conf.HiveConf: HiveConf of name hive.hwi.listen.host does not exist
21/11/11 10:43:25 INFO hive.HiveImport: 21/11/11 10:43:25 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.stripe.size does not exist
21/11/11 10:43:25 INFO hive.HiveImport: 21/11/11 10:43:25 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.block.size does not exist
21/11/11 10:43:25 INFO hive.HiveImport: 21/11/11 10:43:25 WARN conf.HiveConf: HiveConf of name hive.exec.orc.memory.pool does not exist
21/11/11 10:43:25 INFO hive.HiveImport: 21/11/11 10:43:25 WARN conf.HiveConf: HiveConf of name hive.exec.orc.skip.corrupt.data does not exist
21/11/11 10:43:25 INFO hive.HiveImport: 21/11/11 10:43:25 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.buffer.size does not exist
21/11/11 10:43:25 INFO hive.HiveImport: 21/11/11 10:43:25 WARN conf.HiveConf: HiveConf of name hive.support.sql11.reserved.keywords does not exist
21/11/11 10:43:25 INFO hive.HiveImport: 21/11/11 10:43:25 WARN conf.HiveConf: HiveConf of name hive.exec.orc.encoding.strategy does not exist
21/11/11 10:43:25 INFO hive.HiveImport: 21/11/11 10:43:25 WARN conf.HiveConf: HiveConf of name hive.hwi.listen.port does not exist
21/11/11 10:43:26 INFO hive.HiveImport: 2021-11-11 10:43:26,606 main WARN Unable to instantiate org.fusesource.jansi.WindowsAnsiOutputStream
21/11/11 10:43:26 INFO hive.HiveImport: 2021-11-11 10:43:26,606 main WARN Unable to instantiate org.fusesource.jansi.WindowsAnsiOutputStream
21/11/11 10:43:26 INFO hive.HiveImport: 21/11/11 10:43:26 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.compress does not exist
21/11/11 10:43:26 INFO hive.HiveImport: 21/11/11 10:43:26 WARN conf.HiveConf: HiveConf of name hive.exec.orc.zerocopy does not exist
21/11/11 10:43:26 INFO hive.HiveImport: 21/11/11 10:43:26 WARN conf.HiveConf: HiveConf of name hive.orc.cache.stripe.details.size does not exist
21/11/11 10:43:26 INFO hive.HiveImport: 21/11/11 10:43:26 WARN conf.HiveConf: HiveConf of name hive.hwi.war.file does not exist
21/11/11 10:43:26 INFO hive.HiveImport: 21/11/11 10:43:26 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.row.index.stride does not exist
21/11/11 10:43:26 INFO hive.HiveImport: 21/11/11 10:43:26 WARN conf.HiveConf: HiveConf of name hive.outerjoin.supports.filters does not exist
21/11/11 10:43:26 INFO hive.HiveImport: 21/11/11 10:43:26 WARN conf.HiveConf: HiveConf of name hive.exec.orc.compression.strategy does not exist
21/11/11 10:43:26 INFO hive.HiveImport: 21/11/11 10:43:26 WARN conf.HiveConf: HiveConf of name hive.exec.orc.dictionary.key.size.threshold does not exist
21/11/11 10:43:26 INFO hive.HiveImport: 21/11/11 10:43:26 WARN conf.HiveConf: HiveConf of name hive.orc.row.index.stride.dictionary.check does not exist
21/11/11 10:43:26 INFO hive.HiveImport: 21/11/11 10:43:26 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.block.padding does not exist
21/11/11 10:43:26 INFO hive.HiveImport: 21/11/11 10:43:26 WARN conf.HiveConf: HiveConf of name hive.exec.orc.block.padding.tolerance does not exist
21/11/11 10:43:26 INFO hive.HiveImport: 21/11/11 10:43:26 WARN conf.HiveConf: HiveConf of name hive.hwi.listen.host does not exist
21/11/11 10:43:26 INFO hive.HiveImport: 21/11/11 10:43:26 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.stripe.size does not exist
21/11/11 10:43:26 INFO hive.HiveImport: 21/11/11 10:43:26 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.block.size does not exist
21/11/11 10:43:26 INFO hive.HiveImport: 21/11/11 10:43:26 WARN conf.HiveConf: HiveConf of name hive.exec.orc.memory.pool does not exist
21/11/11 10:43:26 INFO hive.HiveImport: 21/11/11 10:43:26 WARN conf.HiveConf: HiveConf of name hive.exec.orc.skip.corrupt.data does not exist
21/11/11 10:43:26 INFO hive.HiveImport: 21/11/11 10:43:26 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.buffer.size does not exist
21/11/11 10:43:26 INFO hive.HiveImport: 21/11/11 10:43:26 WARN conf.HiveConf: HiveConf of name hive.support.sql11.reserved.keywords does not exist
21/11/11 10:43:26 INFO hive.HiveImport: 21/11/11 10:43:26 WARN conf.HiveConf: HiveConf of name hive.exec.orc.encoding.strategy does not exist
21/11/11 10:43:26 INFO hive.HiveImport: 21/11/11 10:43:26 WARN conf.HiveConf: HiveConf of name hive.hwi.listen.port does not exist
21/11/11 10:43:26 INFO hive.HiveImport:
21/11/11 10:43:26 INFO hive.HiveImport: Logging initialized using configuration in file:/D:/soft/apache-hive-2.3.8-bin/conf/hive-log4j2.properties Async: true21/11/11 10:43:26 INFO hive.HiveImport: 21/11/11 10:43:26 INFO SessionState:
21/11/11 10:43:26 INFO hive.HiveImport: Logging initialized using configuration in file:/D:/soft/apache-hive-2.3.8-bin/conf/hive-log4j2.properties Async: true21/11/11 10:43:27 INFO hive.HiveImport: 21/11/11 10:43:27 INFO session.SessionState: Created HDFS directory: /tmp/hive/cuizhexin/ffc5d0eb-d0e4-4994-9035-e5936402fc54
21/11/11 10:43:27 INFO hive.HiveImport: 21/11/11 10:43:27 INFO session.SessionState: Created local directory: D:/soft/apache-hive-2.3.8-bin/my_hive/scratch_dir/ffc5d0eb-d0e4-4994-9035-e5936402fc54
21/11/11 10:43:27 INFO hive.HiveImport: 21/11/11 10:43:27 INFO session.SessionState: Created HDFS directory: /tmp/hive/cuizhexin/ffc5d0eb-d0e4-4994-9035-e5936402fc54/_tmp_space.db
21/11/11 10:43:27 INFO hive.HiveImport: 21/11/11 10:43:27 INFO conf.HiveConf: Using the default value passed infor log id: ffc5d0eb-d0e4-4994-9035-e5936402fc54
21/11/11 10:43:27 INFO hive.HiveImport: 21/11/11 10:43:27 INFO session.SessionState: Updating thread name to ffc5d0eb-d0e4-4994-9035-e5936402fc54 main
21/11/11 10:43:27 INFO hive.HiveImport: 21/11/11 10:43:27 INFO conf.HiveConf: Using the default value passed infor log id: ffc5d0eb-d0e4-4994-9035-e5936402fc54
21/11/11 10:43:27 INFO hive.HiveImport: 21/11/11 10:43:27 INFO ql.Driver: Compiling command(queryId=cuizhexin_20211111104327_c1f42ddd-855c-4748-8d63-6828838eac38): CREATE TABLE IF NOT EXISTS `song`(`acc_track_vol` INT, `accompany_quality` INT, `accompany_track` INT, `accompany_version` INT, `album` STRING, `audio_format` INT, `authorized_company` STRING, `bpm` INT, `composer` STRING, `duration` INT, `height` INT, `Image_quality` INT, `language` STRING, `lyric_feature` INT, `lyricist` STRING, `name` STRING, `original_singer` STRING, `original_sound_quality` INT, `original_track` INT, `original_track_vol` INT, `other_name` STRING, `pinyin` STRING, `pinyin_first` STRING, `post_time` STRING, `product` STRING, `publish_to` STRING, `singer_info` STRING, `singing_type` INT, `song_version` INT, `source` INT, `source_id` STRING, `star_level` INT, `status` INT, `subtitles_type` INT, `video_feature` INT, `video_format` STRING, `video_make` INT, `video_quality` INT, `video_resolution` INT, `width` INT) COMMENT 'Imported by sqoop on 2021/11/11 10:43:23' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\001'LINES TERMINATED BY '\012' STORED AS TEXTFILE
21/11/11 10:43:28 INFO hive.HiveImport: 21/11/11 10:43:28 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.compress does not exist
21/11/11 10:43:28 INFO hive.HiveImport: 21/11/11 10:43:28 WARN conf.HiveConf: HiveConf of name hive.exec.orc.zerocopy does not exist
21/11/11 10:43:28 INFO hive.HiveImport: 21/11/11 10:43:28 WARN conf.HiveConf: HiveConf of name hive.orc.cache.stripe.details.size does not exist
21/11/11 10:43:28 INFO hive.HiveImport: 21/11/11 10:43:28 WARN conf.HiveConf: HiveConf of name hive.hwi.war.file does not exist
21/11/11 10:43:28 INFO hive.HiveImport: 21/11/11 10:43:28 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.row.index.stride does not exist
21/11/11 10:43:28 INFO hive.HiveImport: 21/11/11 10:43:28 WARN conf.HiveConf: HiveConf of name hive.outerjoin.supports.filters does not exist
21/11/11 10:43:28 INFO hive.HiveImport: 21/11/11 10:43:28 WARN conf.HiveConf: HiveConf of name hive.exec.orc.compression.strategy does not exist
21/11/11 10:43:28 INFO hive.HiveImport: 21/11/11 10:43:28 WARN conf.HiveConf: HiveConf of name hive.exec.orc.dictionary.key.size.threshold does not exist
21/11/11 10:43:28 INFO hive.HiveImport: 21/11/11 10:43:28 WARN conf.HiveConf: HiveConf of name hive.orc.row.index.stride.dictionary.check does not exist
21/11/11 10:43:28 INFO hive.HiveImport: 21/11/11 10:43:28 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.block.padding does not exist
21/11/11 10:43:28 INFO hive.HiveImport: 21/11/11 10:43:28 WARN conf.HiveConf: HiveConf of name hive.exec.orc.block.padding.tolerance does not exist
21/11/11 10:43:28 INFO hive.HiveImport: 21/11/11 10:43:28 WARN conf.HiveConf: HiveConf of name hive.hwi.listen.host does not exist
21/11/11 10:43:28 INFO hive.HiveImport: 21/11/11 10:43:28 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.stripe.size does not exist
21/11/11 10:43:28 INFO hive.HiveImport: 21/11/11 10:43:28 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.block.size does not exist
21/11/11 10:43:28 INFO hive.HiveImport: 21/11/11 10:43:28 WARN conf.HiveConf: HiveConf of name hive.exec.orc.memory.pool does not exist
21/11/11 10:43:28 INFO hive.HiveImport: 21/11/11 10:43:28 WARN conf.HiveConf: HiveConf of name hive.exec.orc.skip.corrupt.data does not exist
21/11/11 10:43:28 INFO hive.HiveImport: 21/11/11 10:43:28 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.buffer.size does not exist
21/11/11 10:43:28 INFO hive.HiveImport: 21/11/11 10:43:28 WARN conf.HiveConf: HiveConf of name hive.support.sql11.reserved.keywords does not exist
21/11/11 10:43:28 INFO hive.HiveImport: 21/11/11 10:43:28 WARN conf.HiveConf: HiveConf of name hive.exec.orc.encoding.strategy does not exist
21/11/11 10:43:28 INFO hive.HiveImport: 21/11/11 10:43:28 WARN conf.HiveConf: HiveConf of name hive.hwi.listen.port does not exist
21/11/11 10:43:28 INFO hive.HiveImport: 21/11/11 10:43:28 INFO metastore.HiveMetaStore: 0: Opening raw store with implementation class:org.apache.hadoop.hive.metastore.ObjectStore
21/11/11 10:43:28 INFO hive.HiveImport: 21/11/11 10:43:28 INFO metastore.ObjectStore: ObjectStore, initialize called
21/11/11 10:43:28 INFO hive.HiveImport: 21/11/11 10:43:28 INFO DataNucleus.Persistence: Property hive.metastore.integral.jdo.pushdown unknown - will be ignored
21/11/11 10:43:28 INFO hive.HiveImport: 21/11/11 10:43:28 INFO DataNucleus.Persistence: Property datanucleus.cache.level2 unknown - will be ignored
21/11/11 10:43:29 INFO hive.HiveImport: 21/11/11 10:43:29 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.compress does not exist
21/11/11 10:43:29 INFO hive.HiveImport: 21/11/11 10:43:29 WARN conf.HiveConf: HiveConf of name hive.exec.orc.zerocopy does not exist
21/11/11 10:43:29 INFO hive.HiveImport: 21/11/11 10:43:29 WARN conf.HiveConf: HiveConf of name hive.orc.cache.stripe.details.size does not exist
21/11/11 10:43:29 INFO hive.HiveImport: 21/11/11 10:43:29 WARN conf.HiveConf: HiveConf of name hive.hwi.war.file does not exist
21/11/11 10:43:29 INFO hive.HiveImport: 21/11/11 10:43:29 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.row.index.stride does not exist
21/11/11 10:43:29 INFO hive.HiveImport: 21/11/11 10:43:29 WARN conf.HiveConf: HiveConf of name hive.outerjoin.supports.filters does not exist
21/11/11 10:43:29 INFO hive.HiveImport: 21/11/11 10:43:29 WARN conf.HiveConf: HiveConf of name hive.exec.orc.compression.strategy does not exist
21/11/11 10:43:29 INFO hive.HiveImport: 21/11/11 10:43:29 WARN conf.HiveConf: HiveConf of name hive.exec.orc.dictionary.key.size.threshold does not exist
21/11/11 10:43:29 INFO hive.HiveImport: 21/11/11 10:43:29 WARN conf.HiveConf: HiveConf of name hive.orc.row.index.stride.dictionary.check does not exist
21/11/11 10:43:29 INFO hive.HiveImport: 21/11/11 10:43:29 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.block.padding does not exist
21/11/11 10:43:29 INFO hive.HiveImport: 21/11/11 10:43:29 WARN conf.HiveConf: HiveConf of name hive.exec.orc.block.padding.tolerance does not exist
21/11/11 10:43:29 INFO hive.HiveImport: 21/11/11 10:43:29 WARN conf.HiveConf: HiveConf of name hive.hwi.listen.host does not exist
21/11/11 10:43:29 INFO hive.HiveImport: 21/11/11 10:43:29 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.stripe.size does not exist
21/11/11 10:43:29 INFO hive.HiveImport: 21/11/11 10:43:29 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.block.size does not exist
21/11/11 10:43:29 INFO hive.HiveImport: 21/11/11 10:43:29 WARN conf.HiveConf: HiveConf of name hive.exec.orc.memory.pool does not exist
21/11/11 10:43:29 INFO hive.HiveImport: 21/11/11 10:43:29 WARN conf.HiveConf: HiveConf of name hive.exec.orc.skip.corrupt.data does not exist
21/11/11 10:43:29 INFO hive.HiveImport: 21/11/11 10:43:29 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.buffer.size does not exist
21/11/11 10:43:29 INFO hive.HiveImport: 21/11/11 10:43:29 WARN conf.HiveConf: HiveConf of name hive.support.sql11.reserved.keywords does not exist
21/11/11 10:43:29 INFO hive.HiveImport: 21/11/11 10:43:29 WARN conf.HiveConf: HiveConf of name hive.exec.orc.encoding.strategy does not exist
21/11/11 10:43:29 INFO hive.HiveImport: 21/11/11 10:43:29 WARN conf.HiveConf: HiveConf of name hive.hwi.listen.port does not exist
21/11/11 10:43:29 INFO hive.HiveImport: 21/11/11 10:43:29 INFO metastore.ObjectStore: Setting MetaStore object pin classes with hive.metastore.cache.pinobjtypes="Table,StorageDescriptor,SerDeInfo,Partition,Database,Type,FieldSchema,Order"21/11/11 10:43:32 INFO hive.HiveImport: 21/11/11 10:43:32 INFO metastore.MetaStoreDirectSql: Using direct SQL, underlying DB is MYSQL
21/11/11 10:43:32 INFO hive.HiveImport: 21/11/11 10:43:32 INFO metastore.ObjectStore: Initialized ObjectStore
21/11/11 10:43:32 INFO hive.HiveImport: 21/11/11 10:43:32 INFO metastore.HiveMetaStore: Added admin role in metastore
21/11/11 10:43:32 INFO hive.HiveImport: 21/11/11 10:43:32 INFO metastore.HiveMetaStore: Added public role in metastore
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 INFO metastore.HiveMetaStore: No user is added in admin role, since config is empty
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 INFO metastore.HiveMetaStore: 0: get_all_functions
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 INFO HiveMetaStore.audit: ugi=cuizhexin ip=unknown-ip-addr cmd=get_all_functions
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 INFO parse.CalcitePlanner: Starting Semantic Analysis
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 INFO parse.CalcitePlanner: Creating table default.song position=2721/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 INFO metastore.HiveMetaStore: 0: get_table :db=default tbl=song
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 INFO HiveMetaStore.audit: ugi=cuizhexin ip=unknown-ip-addr cmd=get_table :db=default tbl=song
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 INFO ql.Driver: Semantic Analysis Completed
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 INFO ql.Driver: Returning Hive schema: Schema(fieldSchemas:null, properties:null)21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 INFO ql.Driver: Completed compiling command(queryId=cuizhexin_20211111104327_c1f42ddd-855c-4748-8d63-6828838eac38); Time taken: 6.486 seconds
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 INFO ql.Driver: Concurrency mode is disabled, not creating a lock manager
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 INFO ql.Driver: Executing command(queryId=cuizhexin_20211111104327_c1f42ddd-855c-4748-8d63-6828838eac38): CREATE TABLE IF NOT EXISTS `song`(`acc_track_vol` INT, `accompany_quality` INT, `accompany_track` INT, `accompany_version` INT, `album` STRING, `audio_format` INT, `authorized_company` STRING, `bpm` INT, `composer` STRING, `duration` INT, `height` INT, `Image_quality` INT, `language` STRING, `lyric_feature` INT, `lyricist` STRING, `name` STRING, `original_singer` STRING, `original_sound_quality` INT, `original_track` INT, `original_track_vol` INT, `other_name` STRING, `pinyin` STRING, `pinyin_first` STRING, `post_time` STRING, `product` STRING, `publish_to` STRING, `singer_info` STRING, `singing_type` INT, `song_version` INT, `source` INT, `source_id` STRING, `star_level` INT, `status` INT, `subtitles_type` INT, `video_feature` INT, `video_format` STRING, `video_make` INT, `video_quality` INT, `video_resolution` INT, `width` INT) COMMENT 'Imported by sqoop on 2021/11/11 10:43:23' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\001'LINES TERMINATED BY '\012' STORED AS TEXTFILE
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 INFO sqlstd.SQLStdHiveAccessController: Created SQLStdHiveAccessController for session context : HiveAuthzSessionContext [sessionString=ffc5d0eb-d0e4-4994-9035-e5936402fc54, clientType=HIVECLI]21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 WARN session.SessionState: METASTORE_FILTER_HOOK will be ignored, since hive.security.authorization.manager is set to instance of HiveAuthorizerFactory.
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 INFO hive.metastore: Mestastore configuration hive.metastore.filter.hook changed from org.apache.hadoop.hive.metastore.DefaultMetaStoreFilterHookImpl to org.apache.hadoop.hive.ql.security.authorization.plugin.AuthorizationMetaStoreFilterHook
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 INFO metastore.HiveMetaStore: 0: Cleaning up thread local RawStore...
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 INFO HiveMetaStore.audit: ugi=cuizhexin ip=unknown-ip-addr cmd=Cleaning up thread local RawStore...
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 INFO metastore.HiveMetaStore: 0: Done cleaning up thread local RawStore
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 INFO HiveMetaStore.audit: ugi=cuizhexin ip=unknown-ip-addr cmd=Done cleaning up thread local RawStore
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 INFO ql.Driver: Completed executing command(queryId=cuizhexin_20211111104327_c1f42ddd-855c-4748-8d63-6828838eac38); Time taken: 0.015 seconds
21/11/11 10:43:33 INFO hive.HiveImport: OK
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 INFO ql.Driver: OK
21/11/11 10:43:33 INFO hive.HiveImport: Time taken: 6.658 seconds
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 INFO CliDriver: Time taken: 6.658 seconds
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 INFO conf.HiveConf: Using the default value passed infor log id: ffc5d0eb-d0e4-4994-9035-e5936402fc54
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 INFO session.SessionState: Resetting thread name to main
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 INFO conf.HiveConf: Using the default value passed infor log id: ffc5d0eb-d0e4-4994-9035-e5936402fc54
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 INFO session.SessionState: Updating thread name to ffc5d0eb-d0e4-4994-9035-e5936402fc54 main
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 INFO ql.Driver: Compiling command(queryId=cuizhexin_20211111104333_07d0c2db-a7f4-4aac-baae-0049d31c54b6):
21/11/11 10:43:33 INFO hive.HiveImport: LOAD DATA INPATH 'hdfs://localhost:9000/user/cuizhexin/song' INTO TABLE `song`21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.compress does not exist
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 WARN conf.HiveConf: HiveConf of name hive.orc.cache.stripe.details.size does not exist
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 WARN conf.HiveConf: HiveConf of name hive.hwi.war.file does not exist
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.row.index.stride does not exist
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 WARN conf.HiveConf: HiveConf of name hive.outerjoin.supports.filters does not exist
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 WARN conf.HiveConf: HiveConf of name hive.exec.orc.compression.strategy does not exist
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 WARN conf.HiveConf: HiveConf of name hive.exec.orc.dictionary.key.size.threshold does not exist
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 WARN conf.HiveConf: HiveConf of name hive.orc.row.index.stride.dictionary.check does not exist
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 WARN conf.HiveConf: HiveConf of name hive.hwi.listen.host does not exist
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 WARN conf.HiveConf: HiveConf of name hive.support.sql11.reserved.keywords does not exist
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 WARN conf.HiveConf: HiveConf of name hive.hwi.listen.port does not exist
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 WARN conf.HiveConf: HiveConf of name hive.exec.orc.zerocopy does not exist
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.block.padding does not exist
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 WARN conf.HiveConf: HiveConf of name hive.exec.orc.block.padding.tolerance does not exist
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.stripe.size does not exist
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.block.size does not exist
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 WARN conf.HiveConf: HiveConf of name hive.exec.orc.memory.pool does not exist
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 WARN conf.HiveConf: HiveConf of name hive.exec.orc.skip.corrupt.data does not exist
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.buffer.size does not exist
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 WARN conf.HiveConf: HiveConf of name hive.exec.orc.encoding.strategy does not exist
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 INFO metastore.HiveMetaStore: 0: Opening raw store with implementation class:org.apache.hadoop.hive.metastore.ObjectStore
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 INFO metastore.ObjectStore: ObjectStore, initialize called
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 INFO metastore.MetaStoreDirectSql: Using direct SQL, underlying DB is MYSQL
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 INFO metastore.ObjectStore: Initialized ObjectStore
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 INFO metastore.HiveMetaStore: 0: get_table :db=default tbl=song
21/11/11 10:43:33 INFO hive.HiveImport: 21/11/11 10:43:33 INFO HiveMetaStore.audit: ugi=cuizhexin ip=unknown-ip-addr cmd=get_table :db=default tbl=song
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO ql.Driver: Semantic Analysis Completed
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO ql.Driver: Returning Hive schema: Schema(fieldSchemas:null, properties:null)21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO ql.Driver: Completed compiling command(queryId=cuizhexin_20211111104333_07d0c2db-a7f4-4aac-baae-0049d31c54b6); Time taken: 0.25 seconds
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO ql.Driver: Concurrency mode is disabled, not creating a lock manager
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO ql.Driver: Executing command(queryId=cuizhexin_20211111104333_07d0c2db-a7f4-4aac-baae-0049d31c54b6):
21/11/11 10:43:34 INFO hive.HiveImport: LOAD DATA INPATH 'hdfs://localhost:9000/user/cuizhexin/song' INTO TABLE `song`21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO ql.Driver: Starting task [Stage-0:MOVE]in serial mode
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO metastore.HiveMetaStore: 0: Cleaning up thread local RawStore...
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO HiveMetaStore.audit: ugi=cuizhexin ip=unknown-ip-addr cmd=Cleaning up thread local RawStore...
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO metastore.HiveMetaStore: 0: Done cleaning up thread local RawStore
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO HiveMetaStore.audit: ugi=cuizhexin ip=unknown-ip-addr cmd=Done cleaning up thread local RawStore
21/11/11 10:43:34 INFO hive.HiveImport: Loading data to table default.song
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO exec.Task: Loading data to table default.song from hdfs://localhost:9000/user/cuizhexin/song
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO metastore.HiveMetaStore: 0: get_table :db=default tbl=song
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO HiveMetaStore.audit: ugi=cuizhexin ip=unknown-ip-addr cmd=get_table :db=default tbl=song
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.compress does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.orc.cache.stripe.details.size does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.hwi.war.file does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.row.index.stride does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.outerjoin.supports.filters does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.compression.strategy does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.dictionary.key.size.threshold does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.orc.row.index.stride.dictionary.check does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.internal.ss.authz.settings.applied.marker does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.hwi.listen.host does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.support.sql11.reserved.keywords does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.hwi.listen.port does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.zerocopy does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.block.padding does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.block.padding.tolerance does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.stripe.size does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.block.size does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.memory.pool does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.skip.corrupt.data does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.buffer.size does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.encoding.strategy does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO metastore.HiveMetaStore: 0: Opening raw store with implementation class:org.apache.hadoop.hive.metastore.ObjectStore
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO metastore.ObjectStore: ObjectStore, initialize called
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO metastore.MetaStoreDirectSql: Using direct SQL, underlying DB is MYSQL
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO metastore.ObjectStore: Initialized ObjectStore
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO metastore.HiveMetaStore: 0: get_table :db=default tbl=song
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO HiveMetaStore.audit: ugi=cuizhexin ip=unknown-ip-addr cmd=get_table :db=default tbl=song
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 ERROR hdfs.KeyProviderCache: Could not find uri with key [dfs.encryption.key.provider.uri] to create a keyProvider !!21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO metastore.HiveMetaStore: 0: alter_table: db=default tbl=song newtbl=song
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO HiveMetaStore.audit: ugi=cuizhexin ip=unknown-ip-addr cmd=alter_table: db=default tbl=song newtbl=song
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO ql.Driver: Starting task [Stage-1:STATS]in serial mode
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO exec.StatsTask: Executing stats task
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO metastore.HiveMetaStore: 0: Cleaning up thread local RawStore...
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO HiveMetaStore.audit: ugi=cuizhexin ip=unknown-ip-addr cmd=Cleaning up thread local RawStore...
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO metastore.HiveMetaStore: 0: Done cleaning up thread local RawStore
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO HiveMetaStore.audit: ugi=cuizhexin ip=unknown-ip-addr cmd=Done cleaning up thread local RawStore
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO metastore.HiveMetaStore: 0: get_table :db=default tbl=song
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO HiveMetaStore.audit: ugi=cuizhexin ip=unknown-ip-addr cmd=get_table :db=default tbl=song
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.compress does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.orc.cache.stripe.details.size does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.hwi.war.file does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.row.index.stride does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.outerjoin.supports.filters does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.compression.strategy does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.dictionary.key.size.threshold does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.orc.row.index.stride.dictionary.check does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.internal.ss.authz.settings.applied.marker does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.hwi.listen.host does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.support.sql11.reserved.keywords does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.hwi.listen.port does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.zerocopy does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.block.padding does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.block.padding.tolerance does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.stripe.size does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.block.size does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.memory.pool does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.skip.corrupt.data does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.buffer.size does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.encoding.strategy does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO metastore.HiveMetaStore: 0: Opening raw store with implementation class:org.apache.hadoop.hive.metastore.ObjectStore
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO metastore.ObjectStore: ObjectStore, initialize called
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO metastore.MetaStoreDirectSql: Using direct SQL, underlying DB is MYSQL
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO metastore.ObjectStore: Initialized ObjectStore
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO metastore.HiveMetaStore: 0: get_table :db=default tbl=song
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO HiveMetaStore.audit: ugi=cuizhexin ip=unknown-ip-addr cmd=get_table :db=default tbl=song
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO metastore.HiveMetaStore: 0: Cleaning up thread local RawStore...
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO HiveMetaStore.audit: ugi=cuizhexin ip=unknown-ip-addr cmd=Cleaning up thread local RawStore...
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO metastore.HiveMetaStore: 0: Done cleaning up thread local RawStore
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO HiveMetaStore.audit: ugi=cuizhexin ip=unknown-ip-addr cmd=Done cleaning up thread local RawStore
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO metastore.HiveMetaStore: 0: alter_table: db=default tbl=song newtbl=song
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO HiveMetaStore.audit: ugi=cuizhexin ip=unknown-ip-addr cmd=alter_table: db=default tbl=song newtbl=song
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.compress does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.orc.cache.stripe.details.size does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.hwi.war.file does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.row.index.stride does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.outerjoin.supports.filters does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.compression.strategy does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.dictionary.key.size.threshold does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.orc.row.index.stride.dictionary.check does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.internal.ss.authz.settings.applied.marker does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.hwi.listen.host does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.support.sql11.reserved.keywords does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.hwi.listen.port does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.zerocopy does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.block.padding does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.block.padding.tolerance does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.stripe.size does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.block.size does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.memory.pool does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.skip.corrupt.data does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.default.buffer.size does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 WARN conf.HiveConf: HiveConf of name hive.exec.orc.encoding.strategy does not exist
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO metastore.HiveMetaStore: 0: Opening raw store with implementation class:org.apache.hadoop.hive.metastore.ObjectStore
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO metastore.ObjectStore: ObjectStore, initialize called
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO metastore.MetaStoreDirectSql: Using direct SQL, underlying DB is MYSQL
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO metastore.ObjectStore: Initialized ObjectStore
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO hive.log: Updating table stats fast for song
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO hive.log: Updated size of table song to 8545386621/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO exec.StatsTask: Table default.song stats: [numFiles=10, numRows=0, totalSize=85453866, rawDataSize=0]21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO ql.Driver: Completed executing command(queryId=cuizhexin_20211111104333_07d0c2db-a7f4-4aac-baae-0049d31c54b6); Time taken: 0.522 seconds
21/11/11 10:43:34 INFO hive.HiveImport: OK
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO ql.Driver: OK
21/11/11 10:43:34 INFO hive.HiveImport: Time taken: 0.772 seconds
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO CliDriver: Time taken: 0.772 seconds
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO conf.HiveConf: Using the default value passed infor log id: ffc5d0eb-d0e4-4994-9035-e5936402fc54
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO session.SessionState: Resetting thread name to main
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO conf.HiveConf: Using the default value passed infor log id: ffc5d0eb-d0e4-4994-9035-e5936402fc54
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO session.SessionState: Deleted directory: /tmp/hive/cuizhexin/ffc5d0eb-d0e4-4994-9035-e5936402fc54 on fs with scheme hdfs
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO session.SessionState: Deleted directory: D:/soft/apache-hive-2.3.8-bin/my_hive/scratch_dir/ffc5d0eb-d0e4-4994-9035-e5936402fc54 on fs with scheme file21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO metastore.HiveMetaStore: 0: Cleaning up thread local RawStore...
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO HiveMetaStore.audit: ugi=cuizhexin ip=unknown-ip-addr cmd=Cleaning up thread local RawStore...
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO metastore.HiveMetaStore: 0: Done cleaning up thread local RawStore
21/11/11 10:43:34 INFO hive.HiveImport: 21/11/11 10:43:34 INFO HiveMetaStore.audit: ugi=cuizhexin ip=unknown-ip-addr cmd=Done cleaning up thread local RawStore
21/11/11 10:43:35 INFO hive.HiveImport: Hive import complete.
21/11/11 10:43:35 INFO hive.HiveImport: Export directory is contains the _SUCCESS file only, removing the directory.
2、将Hive的数据导出至Mysql
这个操作首先需要在MySql的相关库中建立对应的表
需要注意的参数就是–export-dir 是hive的表在hdfs中对应的路径。
sqoop export--connect jdbc:mysql://10.50.4.128:33061/songdb --username hive --password hive --table uuid_table --export-dir /uuid1.txt
日志如下:
D:\soft\sqoop-1.4.6\bin>sqoop export--connect jdbc:mysql://10.50.4.128:33061/songdb --username hive --password hive --table uuid_table --export-dir /uuid1.txt
Warning: HBASE_HOME and HBASE_VERSION not set.
Warning: HCAT_HOME not set
Warning: HCATALOG_HOME does not exist HCatalog imports will fail.
Please set HCATALOG_HOME to the root of your HCatalog installation.
Warning: ACCUMULO_HOME not set.
Warning: ZOOKEEPER_HOME not set.
Warning: HBASE_HOME does not exist HBase imports will fail.
Please set HBASE_HOME to the root of your HBase installation.
Warning: ACCUMULO_HOME does not exist Accumulo imports will fail.
Please set ACCUMULO_HOME to the root of your Accumulo installation.
Warning: ZOOKEEPER_HOME does not exist Accumulo imports will fail.
Please set ZOOKEEPER_HOME to the root of your Zookeeper installation.
21/11/11 11:11:13 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
21/11/11 11:11:13 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
21/11/11 11:11:13 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
21/11/11 11:11:13 INFO tool.CodeGenTool: Beginning code generation
Thu Nov 1111:11:13 CST 2021 WARN: Establishing SSL connection without server's identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by default if explicit option isn't set. For compliance with existing applications not using SSL the verifyServerCertificate property is set to 'false'. You need either to explicitly disable SSL by setting useSSL=false, or setuseSSL=true and provide truststore for server certificate verification.
21/11/11 11:11:13 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `uuid_table` AS t LIMIT 121/11/11 11:11:13 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `uuid_table` AS t LIMIT 121/11/11 11:11:13 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is D:\soft\hadoop-2.7.7
注: \tmp\sqoop-cuizhexin\compile\31a9bfa48b7ee5d51050cf963c21dd10\uuid_table.java使用或覆盖了已过时的 API。
注: 有关详细信息, 请使用 -Xlint:deprecation 重新编译。
21/11/11 11:11:15 INFO orm.CompilationManager: Writing jar file: \tmp\sqoop-cuizhexin\compile\31a9bfa48b7ee5d51050cf963c21dd10\uuid_table.jar
21/11/11 11:11:15 INFO mapreduce.ExportJobBase: Beginning export of uuid_table
21/11/11 11:11:15 INFO Configuration.deprecation: mapred.job.tracker is deprecated. Instead, use mapreduce.jobtracker.address
21/11/11 11:11:15 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
21/11/11 11:11:15 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
21/11/11 11:11:15 INFO Configuration.deprecation: mapred.map.tasks.speculative.execution is deprecated. Instead, use mapreduce.map.speculative
21/11/11 11:11:15 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
21/11/11 11:11:15 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
21/11/11 11:11:16 INFO input.FileInputFormat: Total input paths to process :121/11/11 11:11:16 INFO input.FileInputFormat: Total input paths to process :121/11/11 11:11:16 INFO mapreduce.JobSubmitter: number of splits:4
21/11/11 11:11:16 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1636592599511_0004
21/11/11 11:11:16 INFO impl.YarnClientImpl: Submitted application application_1636592599511_0004
21/11/11 11:11:16 INFO mapreduce.Job: The url to track the job: http://E10101J01905:8088/proxy/application_1636592599511_0004/
21/11/11 11:11:16 INFO mapreduce.Job: Running job: job_1636592599511_0004
21/11/11 11:11:24 INFO mapreduce.Job: Job job_1636592599511_0004 running in uber mode :false21/11/11 11:11:24 INFO mapreduce.Job: map 0% reduce 0%
21/11/11 11:11:30 INFO mapreduce.Job: map 25% reduce 0%
21/11/11 11:11:31 INFO mapreduce.Job: map 50% reduce 0%
21/11/11 11:11:32 INFO mapreduce.Job: map 75% reduce 0%
21/11/11 11:11:33 INFO mapreduce.Job: map 100% reduce 0%
21/11/11 11:11:33 INFO mapreduce.Job: Job job_1636592599511_0004 completed successfully
21/11/11 11:11:33 INFO mapreduce.Job: Counters: 30
File System Counters
FILE: Number of bytes read=0
FILE: Number of bytes written=511776
FILE: Number of readoperations=0
FILE: Number of large readoperations=0
FILE: Number of writeoperations=0
HDFS: Number of bytes read=2546628
HDFS: Number of bytes written=0
HDFS: Number of readoperations=19
HDFS: Number of large readoperations=0
HDFS: Number of writeoperations=0
Job Counters
Launched map tasks=4
Rack-local map tasks=4
Total time spent by all maps in occupied slots (ms)=13441
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=13441
Total vcore-milliseconds taken by all map tasks=13441
Total megabyte-milliseconds taken by all map tasks=13763584
Map-Reduce Framework
Map input records=66571
Map output records=66571
Input splitbytes=496
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=126
CPU time spent (ms)=6101
Physical memory (bytes)snapshot=832360448
Virtual memory (bytes)snapshot=1240788992
Total committed heap usage (bytes)=594542592
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=021/11/11 11:11:33 INFO mapreduce.ExportJobBase: Transferred 2.4287 MB in17.8752 seconds (139.128 KB/sec)21/11/11 11:11:33 INFO mapreduce.ExportJobBase: Exported 66571 records.
版权归原作者 大大大大泡泡糖 所有, 如有侵权,请联系我们删除。