
前言
小编目前大一,刚开始着手学习SSM,小编会把每个框架都整理成知识点发布出来。如果你也同时在学习SSM的话,不妨看看我做的这个笔记。我认为同为初学者,我把我对知识点的理解以这种代码加观点的方式分享出来不仅加深了我的理解,或许在某个时候对你也有所帮助,同时也欢迎大家在评论区分享你们的观点,另外如果这一篇笔记中有对Spring的知识点不够准确和深入的还请海涵。 知不可乎骤得,托遗响于悲风。
核心容器
Spring Framework系统架构
Spring Framework系统架构图讲究上层依赖下层
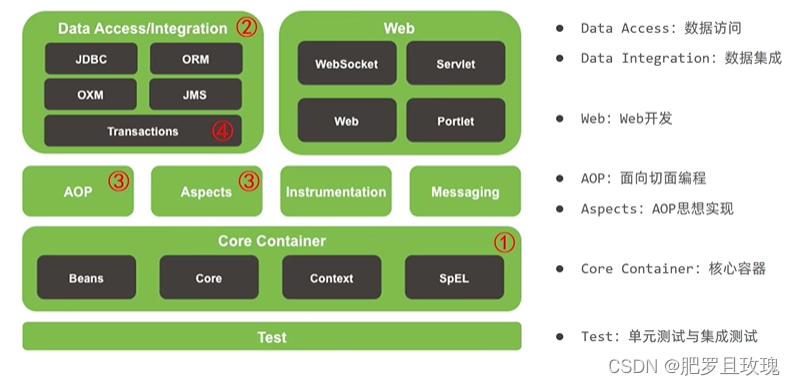
知识引入
核心概念
**IOC控制反转**:使用对象时,由主动new产生对象转换为由外部提供对象,此过程中对象创建控制权由程序转移到外部,此思想为控制反转。
Spring提供了一个容器,称为IOC容器,用来充当IOC思想中的"外部"
IOC容器负责对象的创建,初始化等一系列工作,被创建或被管理的对象在IOC容器中统称为Bean。
**DI依赖注入**:在容器中建立bean与bean之间的依赖关系的整个过程,称为依赖注入。
目标:充分解耦
1.使用IOC容器管理bean(IOC)
2.在IOC容器内将有依赖关系的bean进行关系绑定(DI)
最终效果:使用对象时不仅可以直接从IOC容器中获取,并且获取到的bean已经绑定了所有的依赖关系。
IOC入门案例
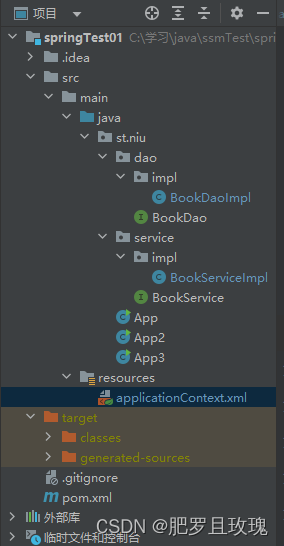
首先看一下项目结构,业务层实现类和业务层接口,数据层实现类和数据层接口。由于是非Spring环境的,App文件是主函数。
1.导入Spring的坐标
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>5.2.10.RELEASE</version>
</dependency>
2.在resource文件夹下创建spring的配置文件:applicationContext.xml

3.配置bean:用一对bean标签配置,id属性声明bean的名字,class属性声明要管理的对象类型(实现类)
<bean id="bookDao" class="st.niu.dao.impl.BookDaoImpl"/>
<bean id="bookService" class="st.niu.service.impl.BookServiceImpl"/>
4.获取IOC容器,参数写上面配置的配置文件名,表明加载配置文件。
ApplicationContext atc = new ClassPathXmlApplicationContext("applicationContext.xml");
5.获取bean,直接调用方法getbean,参数写上面配置bean的id属性
BookDao bookDao = (BookDao) atc.getBean("bookDao");
bookDao.save();
DI入门案例
基于上面IOC入门案例继续实现,达到充分解耦的目的
6.删除业务层使用new的方式创建dao对象
private BookDao bookDao;
7.提供依赖对象对应的set方法(这里是依赖注入中的setter注入,后面会详细讲解,这里可以理解为给ioc容器提供一个获取当前bean对象的入口方法就行了)
public void setBookDao(BookDao bookDao) {
this.bookDao = bookDao;
}
8.配置service与dao的关系,property标签表示配置当前bean的属性,name属性配置的是service层中对象的名字,ref属性配置的是参照的那个bean的id属性,在这个案例中就是bookDao那个bean中id属性,见下面代码,助于区分name和ref。
<bean id="bookDao" class="st.niu.dao.impl.BookDaoImpl"/>
<bean id="bookService" class="st.niu.service.impl.BookServiceImpl">
<property name="bookDao" ref="bookDao"/>
</bean>
· 补张图,更有助于理解name和ref分别指代什么

bean的配置
bean基础配置
见上两个案例那样配置id和class属性
bean的别名配置
给bean起别名,在name属性中可以声明别名,多个别名之间用空格隔开。别名也可用于getbean方法中的参数
<bean id="bookService" name="service service2 bookEbi" class="st.niu.service.impl.BookServiceImpl">
<property name="bookDao" ref="bookDao"/>
</bean>
值得注意的是,别名可以用于ref中,例如这里给bookDao起个别名叫dao,bookService中的ref属性可以配置为dao。
<bean id="bookDao" name="dao" class="st.niu.dao.impl.BookDaoImpl"/>
<bean id="bookService" name="service service2 bookEbi" class="st.niu.service.impl.BookServiceImpl">
<property name="bookDao" ref="dao"/>
</bean>
bean的作用范围配置
在bean配置中添加scope属性,其中singleton(默认值)表面当前bean是单例的,prototype是非单例的。可以分别打印多个bean对象的地址进行实验,这里就不作演示了。
<bean id="bookDao" name="dao" class="st.niu.dao.impl.BookDaoImpl" scope="prototype"/>
为什么bean默认为单例?
Spring反复造bean对象,会造成很大浪费,Spring仅仅只是进行bean管理,下次还要使用在容器中进行获取就行了。
适合交给Spring容器进行管理的bean:那种造一次就行了,可以反复使用的那些对象
例如:表现层对象,业务层对象,数据层对象,工具对象
不适合交给容器进行管理的bean:封装的实体类对象,每次封装的数据都不一样。
bean的实例化
构造方法
Spring是通过无参构造方法实例化Bean对象的,而且是通过反射实现的,所以无论构造方法是private还是public都可以被Spring使用。可以在构造方法中打印语句,进行验证.
public BookDaoImpl() {
System.out.println("bookDaoImpl constructor ....");
}
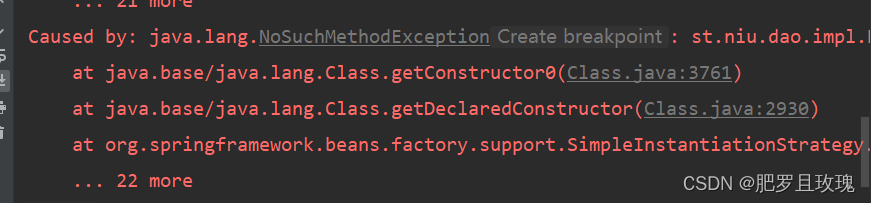
**补充知识**:点关于查看Spring的报错信息,拉到最底下,然后从下往上找**Caused by**,逐个解决。
静态工厂
这个知识点仅作了解就好了,看一遍有个印象就行
由于是工厂造对象,我们重新来看一下项目结构,OrderDao数据层实现类和数据层实现接口。
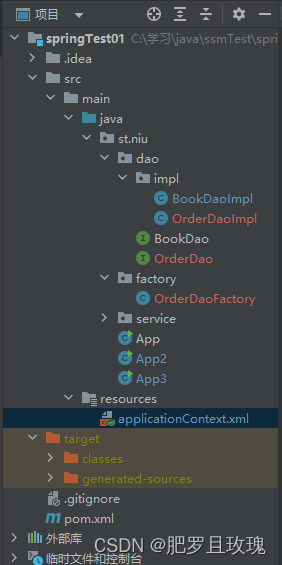
factory中OrderDaoFactory是工厂实例类,里面就是静态实例数据层对象
public class OrderDaoFactory {
public static OrderDao getOrderDao(){
return new OrderDaoImpl();
}
}
我们再来看看bean的配置文件,这里class写factory对象,因为是通过工厂去创建dao对象,所以我们先要配置工厂bean,factory-method属性指明工厂类中哪个方法是造对象的
<!-- 使用静态工厂实例化bean-->
<bean id="orderDao" class="st.niu.factory.OrderDaoFactory" factory-method="getOrderDao"/>
最后用Spring方式去运行一下:
ApplicationContext acc = new ClassPathXmlApplicationContext("applicationContext.xml");
OrderDao orderDao = (OrderDao) acc.getBean("orderDao");
orderDao.save();
这种方式了解就行。
实例工厂
这个知识点也仅作了解就好了,看一遍有个印象就行。
我们首先看一下目录结构,这次创建的是UserDao对象,实例工厂与上面静态工厂不同就在于,这里的造对象方法不是静态的了。
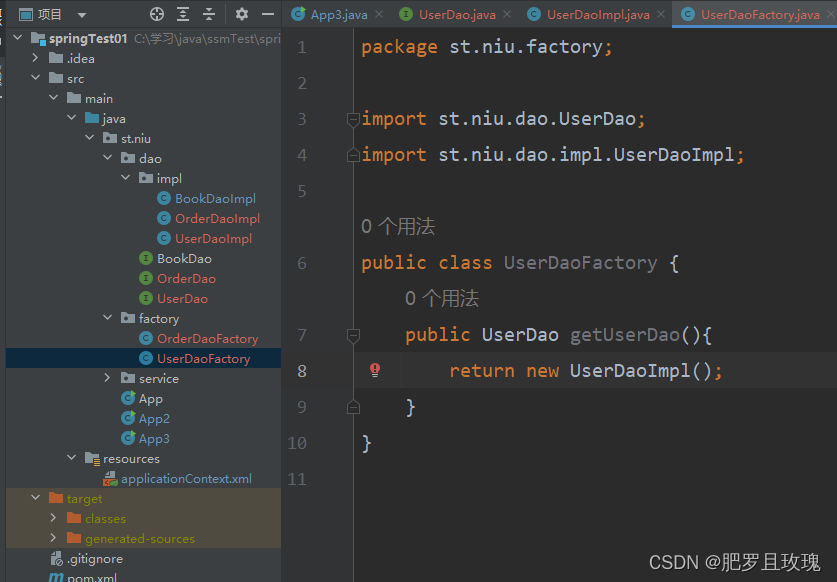
我们再来看一下bean配置,由于不是静态造对象了,所以我们应该先有工厂的bean对象,然后才能造我们userDao的对象,factory-bean属性表明当前bean由哪个工厂bean造出来的,填写工厂bean的id,factory-method属性指明工厂bean中哪个方法是造该bean对象的。
<!-- 使用实例工厂实例化bean-->
<bean id="userFactory" class="st.niu.factory.UserDaoFactory"/>
<bean id="userDao" factory-method="getUserDao" factory-bean="userFactory"/>
最后同样用Spring方式去运行一下:
ApplicationContext acc=new ClassPathXmlApplicationContext("applicationContext.xml");
UserDao userDao = (UserDao) acc.getBean("userDao");
userDao.save();
当前存在的问题,1.工厂bean对象配置的没有什么实际用处,单纯就是因为要造userDao对象而配置的,2.还有就是工厂bean中方法名不固定,每次需要配置。

FactoryBean
**务必要掌握!!!最后学整合时有用处**
这种方式就是为了解决了上面实例化工厂的两个问题,是怎么实现的呢?首先我们创建一个factorybean类去继承FactoryBean接口,泛型写当前工厂类要创建的bean对象,然后重写该接口的三个方法。看下面代码和注释,更有助于理解。
public class UserDaoFactoryBean implements FactoryBean<UserDao> {
//代替原始实例工厂中创建对象的方法,实现了固定方法名
@Override
public UserDao getObject() throws Exception {
return new UserDaoImpl();
}
//告诉它你要创建的这个对象是什么类型的,实现了不用单独配置工厂bean
@Override
public Class<?> getObjectType() {
return UserDao.class;
}
//决定你创建的这个bean(就是泛型)是否是单例的,true单例,false非单例
@Override
public boolean isSingleton() {
return true
}
}
创建完FactoryBean类后,我们再来看看这种方式下是怎么配置bean的呢?明显比实例化工厂简单,只要声明当前bean的id属性,和当前bean是通过哪个factoryBean实例化出来的。
<bean id="userDao" class="st.niu.factory.UserDaoFactoryBean"/>
最后main函数中的代码根本不用改。
ApplicationContext acc=new ClassPathXmlApplicationContext("applicationContext.xml");
UserDao userDao = (UserDao) acc.getBean("userDao");
userDao.save();
总结
以上就是实例化bean的四种方式,其中构造方法很常用,而静态工厂和实例工厂仅作了解就行,FactoryBean在后面会很实用,目前我们就用构造方法实例化bean就行了,又因为默认会提供无参构造方法,所以可以什么都不写,哈哈,有没有感觉白学了,其实不白学,至少你知道了四种实例化bean的方式。
bean的生命周期
生命周期:从创建到消亡的完整过程
bean生命周期:bean从创建到销毁的整体过程
bean生命周期控制:在bean创建后到销毁前做一些事情。
配置实现bean生命周期控制
这里我们在dao上来实现,以区别开后面接口的方式
关于bean生命周期控制主要就两个阶段,一个是bean初始化创建以后,另一个是bean消亡前,因此我们来定义这两个方法
//表示bean初始化后对应的操作
public void init(){
System.out.println("init...");
}
//表示bean销毁前对应的操作
public void destroy(){
System.out.println("destroy...");
}
然后我们在配置文件中进行配置,init-method属性声明bean初始化后执行的方法,destroy-method属性声明bean消亡前执行的方法
<bean id="bookDao" class="st.niu.dao.impl.BookDaoImpl" init-method="init" destroy-method="destroy"/>
接着我们在main方法中运行一下,就会发现destroy方法并没有执行,这是为什么呢?
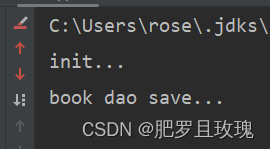
因为我们的程序目前是运行在jvm虚拟机当中,虚拟机退出时,还没有来得及给bean销毁的这样一个机会。怎么解决呢?
** 一个解决方案:**在jvm退出前,我们自己手动把ioc容器关闭了,调用容器的close()方法,但是ApplicationContext并没有这个方法,所以我们想用close方法就不能用ApplicationContext这个接口的对象,我们可以直接用ClassPathXmlApplicationContext实现类的对象,见下面代码,这时我们就可以调用close方法。再运行程序,init方法和destroy方法就都会执行了
// ApplicationContext ctx = new ClassPathXmlApplicationContext("applicationContext.xml");
ClassPathXmlApplicationContext ctx = new ClassPathXmlApplicationContext("applicationContext.xml");
BookDao bookDao = (BookDao) ctx.getBean("bookDao");
bookDao.save();
ctx.close();
再运行程序,init方法和destroy方法就都会执行了。

**另一个解决方案**:设置关闭勾子方法,简单来说就是给容器加个标记,提醒虚拟机在关闭前,先关闭容器再关闭虚拟机。只需要在代码里加上一句注册关闭勾子的代码就行了,放哪里都行。
// ApplicationContext ctx = new ClassPathXmlApplicationContext("applicationContext.xml");
ClassPathXmlApplicationContext ctx = new ClassPathXmlApplicationContext("applicationContext.xml");
//注册关闭勾子
ctx.registerShutdownHook();
BookDao bookDao = (BookDao) ctx.getBean("bookDao");
bookDao.save();
//ctx.close();
**区别**:close方法比较暴力,只能放在代码末尾,如果在getbean方法之前调用,容器都关闭了,也就自然无法从容器中获取bean对象了。建议使用第二种,但是做web应用时,程序是伴随tomcat服务器存在的,所以这两个都没必要写,仅作了解。
上面我们讲的都是通过bean配置的方式来实现生命周期的控制,下面我们来看看通过Spring提供的特有方式是怎么做的?
接口方式实现bean生命周期控制
这里我们在service上来实现,以区别开前面的方式
我们可以直接在需要控制的bean的实现类上实现InitializingBean, DisposableBean这两个接口,再重写里面的方法,见下面代码,更好理解。
//表示bean初始化对应的操作
//该方法执行在该对象属性设置(set方法)完以后
@Override
public void afterPropertiesSet() throws Exception {
System.out.println("service init ...");
}
//表示bean销毁前对应的操作
@Override
public void destroy() throws Exception {
System.out.println("service destroy ...");
}
依赖注入方式
setter注入
setter注入因为注入对象不同又分为两种,一种是注入引用类型,另一种是注入简单类型,我们分别来讲解。
引用类型
就像我们前面的DI入门案例一样,分两步。
第一步是在bean中定义引用类型并提供可访问的set方法。
private BookDao bookDao;
public void setBookDao(BookDao bookDao) {
this.bookDao = bookDao;
}
第二步就是在配置文件中使用property标签,ref属性注入引用类型对象。
<bean id="bookDao" class="st.niu.dao.impl.BookDaoImpl"/>
<bean id="bookService" class="st.niu.service.impl.BookServiceImpl">
<property name="bookDao" ref="bookDao"/>
</bean>
** 补充**:如果要注入多个bean呢?这相信对于聪明的你来说肯定易如反掌,我们只需要定义多个引用类型,然后提供其对应的set方法,再加几对property标签就行了,但是不要忘了把要注入的对象也定义成bean哦。就像下面这样。
private BookDao bookDao;
private UserDao userDao;
public void setBookDao(BookDao bookDao) {
this.bookDao = bookDao;
}
public void setUserDao(UserDao userDao) {
this.userDao = userDao;
}
<bean id="bookDao" class="st.niu.dao.impl.BookDaoImpl"/>
<bean id="userDao" class="st.niu.dao.impl.UserDaoImpl"/>
<bean id="bookService" class="st.niu.service.impl.BookServiceImpl">
<property name="bookDao" ref="bookDao"/>
<property name="userDao" ref="userDao"/>
</bean>
简单类型
简单类型的注入和引用类型的注入百分之就是都是一样的,就一个区别就是property配置的时候引用类型是用ref属性,而简单类型是用value属性。
定义简单类型,并提供对应的set方法。注意一下现在是在bookdao的实现类下注入,所以下面的bean配置也是bookdao。
private int id;
private String name;
public void setId(int id) {
this.id = id;
}
public void setName(String name) {
this.name = name;
}
在配置文件中使用property标签,value属性注入简单类型的值。关于类型转换Spring内部会自动转换。
<bean id="bookDao" class="st.niu.dao.impl.BookDaoImpl">
<property name="id" value="1"/>
<property name="name" value="zhangsan"/>
</bean>
构造器注入
通样构造器注入因为注入对象不同也分为两种,一种是注入引用类型,另一种是注入简单类型,我们分别来讲解。
引用类型
第一步和setter注入一样,我们只要定义要注入的对象,然后提供构造方法,将要注入的对象通过构造方法就行赋值就好了,简单,直接上代码。
private BookDao bookDao;
public BookServiceImpl(BookDao bookDao) {
this.bookDao = bookDao;
}
第二步就是配置bean呗,但是配置这方面就和setter注入不太一样了,构造注入就不使用property标签了,而是使用constructor-arg 标签,这个标签也是像配置property标签一样,声明name和ref两个属性,**但是注意!!!**之前在property标签里声明的name属性指的是实现类中定义的对象名,但是constructor-arg标签中name属性指的是构造方法中形参的名字。
<bean id="booDao" class="st.niu.dao.impl.BookDaoImpl"/>
<bean id="bookService" class="st.niu.service.impl.BookServiceImpl">
//这里的name属性指构造方法中形参的名字
<constructor-arg name="bookDao" ref="booDao"/>
</bean>
** 补充**:注入多个bean呢?我相信你肯定会说,这还不简单?不就是定义多个对象,生成构造方法,然后在配置中多配置几对constructor-arg标签呗,没错就是这样,同时聪明的你肯定不会忘记每个要注入的对象都要定义成bean,那我也就直接放代码了。
private BookDao bookDao;
private UserDao userDao;
public BookServiceImpl(BookDao bookDao, UserDao userDao) {
this.bookDao = bookDao;
this.userDao = userDao;
}
<bean id="bookDao" class="st.niu.dao.impl.BookDaoImpl"/>
<bean id="userDao" class="st.niu.dao.impl.UserDaoImpl"/>
<bean id="bookService" class="st.niu.service.impl.BookServiceImpl">
<constructor-arg name="bookDao" ref="bookDao"/>
<constructor-arg name="userDao" ref="userDao"/>
</bean>
简单类型
相信你现在已经会了引用类型的注入了,那简单类型相信你也可以猜出来了吧,和setter注入一样,第一步基本没变,我就直接放演示代码了
private int id;
private String name;
public BookDaoImpl(int id, String name) {
this.id = id;
this.name = name;
}
第二步配置,和setter注入一样,ref属性改成value属性就行了,直接上代码了啊。
<bean id="bookDao" class="st.niu.dao.impl.BookDaoImpl">
<constructor-arg name="id" value="1"/>
<constructor-arg name="name" value="zhangsan"/>
</bean>
**问题**:大家还记得constructor-arg标签name属性是不是指代构造方法的形参的名字,这也就造成我们当前代码是一个紧耦合的状态,这可不是我们想要的,接下来我们来讲一下解决方法,这里做了解就好了,因为后面都是用注解开发进行依赖注入的。
第一种方法:不用name属性去匹配,而是type属性去匹配参数类型,可以解决形参名耦合度高的问题,但是当出现两个参数类型一样,也就没得玩了,不知道哪个参数注入哪个了
<!-- 解决形参名耦合度高的问题,但是当出现两个类型一样的参数,也就没得玩了-->
<bean id="bookDao" class="st.niu.dao.impl.BookDaoImpl">
<constructor-arg type="int" value="1"/>
<constructor-arg type="java.lang.String" value="zhangsan"/>
</bean>
第二种方法:用参数的位置,也就是用index属性去指明位置,0表示第一个参数,1表示第二个参数,以此类推。
<bean id="bookDao" class="st.niu.dao.impl.BookDaoImpl">
<constructor-arg index="0" value="1"/>
<constructor-arg index="1" value="zhangsan"/>
</bean>
以上作为了解即可,以后并不会使用。
**依赖注入方式选择**
** **建议使用setter注入,第三方技术(别人写的bean)根据情况选择。
** **小编偷个懒,贴张图你们自己看吧,感觉以后基本上都是注解注入,这里了解即可。

自动装配
IOC容器根据bean所依赖的资源在容器中自动查找并注入到bean中的过程称为自动装配
自动装配的方式:
按类型(常用)
set方法仍然要提供,但配置文件就有所不同了,原来property标签就不需要了,给bean标签添加属性**autowire**,值分别有byType,byName,constructor,default,no。分别指代的是按类型,按名称,按构造方法,默认,不使用。**注意:**要装配的bean也要定义好(此处的bookDao)
<bean id="bookDao" class="st.niu.dao.impl.BookDaoImpl"/>
<bean id="bookService" class="st.niu.service.impl.BookServiceImpl" autowire="byType"/>
按名称
set方法也要提供,按名称就是把autowire属性改成byName就行了。但是实现类中定义的变量名要与对应的bean定义的id属性一致。
<bean id="bookDao" class="st.niu.dao.impl.BookDaoImpl"/>
<bean id="bookService" class="st.niu.service.impl.BookServiceImpl" autowire="byName"/>
依赖自动装配注意事项
贴个图,大家自己看一下吧,后面都是用注解开发,这方面了解即可。

扩展(集合注入)
这里也是了解一下,看个眼熟,这个东西以后一个项目里面写的非常少,大家看我代码演示一遍即可。
首先我们来介绍一下项目结构,只有一个数据层,也只配置了数据层的一个bean,数据层实现类就是定义五个不同集合,然后提供set方法,save方法就是打印集合,数据层实现类代码如下:
public class BookDaoImpl implements BookDao {
private int[] array;
private List<String> list;
private Set<String> set;
private Map<String, String> map;
private Properties properties;
public void setArray(int[] array) {
this.array = array;
}
public void setList(List<String> list) {
this.list = list;
}
public void setSet(Set<String> set) {
this.set = set;
}
public void setMap(Map<String, String> map) {
this.map = map;
}
public void setProperties(Properties properties) {
this.properties = properties;
}
@Override
public void save() {
System.out.println("book dao save...");
System.out.println("遍历数组" + Arrays.toString(array));
System.out.println("遍历List" + list);
System.out.println("遍历Set" + set);
System.out.println("遍历Map" + map);
System.out.println("遍历Properties" + properties);
}
}
接下来我们步入正题,我们来看一下怎么实现集合注入呢?同样我们提供set方法,所以在配置文件中我们也是用**setter注入**,看到setter注入我猜你第一反应是不是想到要用**property标签**啊,对的,没错,我们就是要用property标签,其中**name属性还是指的是实现类定义的变量名**,这里由于是集合,也就不用ref属性和value属性了,而是在property标签中定义**集合标签**,集合标签中再用**value标签**去给集合注入值,从而实现集合注入。
这里要注意三点,第一:要注入多少个集合,也就要多少个property标签。第二:对于map集合使用**entry实体类标签**来注入,key属性写键,value属性写值。第三:properties集合的标签有所不同,见下面代码,还有就是key属性写键,值写在一对标签中间,和map有所不同。
<bean id="bookDao" class="st.niu.dao.impl.BookDaoImpl">
<property name="array">
<array>
<value>100</value>
<value>200</value>
<value>300</value>
</array>
</property>
<property name="list">
<list>
<value>"zhangsan"</value>
<value>"lisi"</value>
<value>"wangwu"</value>
<!-- 如果泛型是引用类型,就这样写-->
<ref bean = "bean的Id"/>
</list>
</property>
<property name="set">
<set>
<value>"zhangsan"</value>
<value>"lisi"</value>
<value>"wangwu"</value>
<!-- set会自动去重-->
<value>"wangwu"</value>
</set>
</property>
<property name="map">
<map>
<!-- map用entry实体类标签注入-->
<entry key="country" value="China"/>
<entry key="province" value="hunan"/>
<entry key="city" value="huaihua"/>
</map>
</property>
<property name="properties">
<!-- propertie集合标签有所不同-->
<props>
<prop key="country">china</prop>
<prop key="province">hunan</prop>
<prop key="city">huaihua</prop>
</props>
</property>
</bean>
集合注入完毕后我们回到main方法中运行来看一下结果。
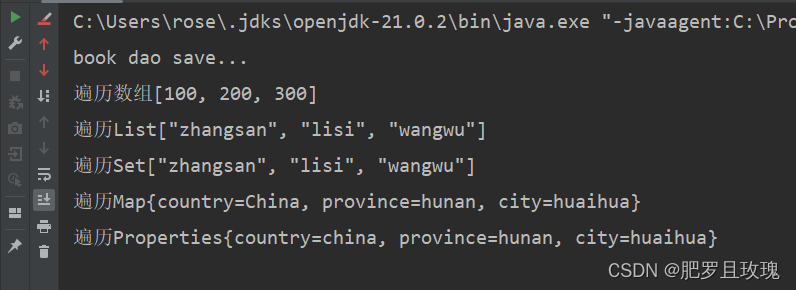
这一块知识了解即可
管理第三方的Bean
** **前面无论是简单类型,引用类型还是集合,我们讲的都是管理我们自己的bean,这里我们来讲解一下如何管理第三方的bean。我们就用两个案例来讲解数据源对象的管理。
Druid的管理
我们首先来讲如何管理德鲁伊连接池(druid),因为这个东西大家并不陌生。
首先我们应该在pom.xml文件中加入druid的坐标。
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.6</version>
</dependency>
接着我们就要在配置文件中去管理**DruidDataSource对象**。但是我们是采用构造器注入还是setter注入呢?我们可以查看DruidDataSource的方法,最后我们发现它没有提供合适的构造方法,但是提供了合适的set方法所以我们就用**setter注入**,老生常谈的property标签走起,这时我们要注入几个对象呢?别的不清楚,但是最基本的那四个:数据库驱动,数据库连接的url,用户名,密码,这四个我们可以直接写上去吧,那我就直接上代码了。
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/test"/>
<property name="username" value="root"/>
<property name="password" value="123456"/>
</bean>
** **配完上面这四个也就差不多了毕竟我们只是演示配置第三方bean,接下来我们去main方法中调用getbean方法看看能不能获取到呢?
ApplicationContext acc=new ClassPathXmlApplicationContext("applicationContext.xml");
DataSource dataSource = (DataSource) acc.getBean("dataSource");
System.out.println(dataSource);
看运行结果是成功获取到了的。

以上就是配置德鲁伊连接池,大家可能发现流程和我们前面的配置差不多,我想说确实是这样,只不过就是第三方bean的包名+类名我们并不熟悉。
c3p0的管理
经过druid的配置,大家大致熟悉了第三方bean的配置流程,接下来我们来做一个c3p0(同样是连接池对象)的配置。因为相信这个东西对于很多人来说是陌生的,我们在配置它时就会发现配置第三方bean的一些问题
首先第一步还是引入c3p0的坐标。
<dependency>
<groupId>c3p0</groupId>
<artifactId>c3p0</artifactId>
<version>0.9.1.2</version>
</dependency>
第二步同样配置bean,在c3p0中class属性是ComboPooledDataSource与Druid有所不同,我们同样发现它没有提供合适的构造方法,但是提供了合适的set方法所以我们就用setter注入,这时property中的name属性值与druid也有所不同,见下面代码。
<bean id= "c3p0dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="driverClass" value="com.mysql.jdbc.Driver"/>
<property name="jdbcUrl" value="jdbc:mysql://localhost:3306/test"/>
<property name="user" value="root"/>
<property name="password" value="123456"/>
</bean>
但是值得注意的是c3p0连接池还需需要导入mysql驱动类的坐标,就是可以理解为c3p0依赖于mysql的驱动,所以我们还要导入mysql驱动类的坐标。
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<version>8.3.0</version>
</dependency>
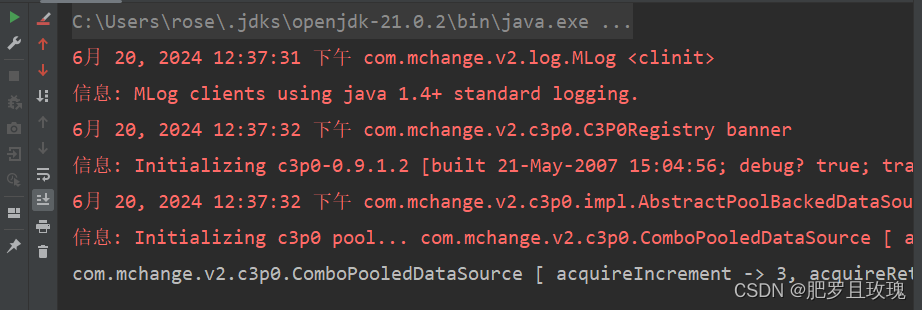
最后去main方法中调用getBean方法看看能不能获取到,代码和上面一样,只不过就是这里getBean方法的参数是我们配置的c3p0bean的id。
ApplicationContext acc = new ClassPathXmlApplicationContext("applicationContext.xml");
DataSource dataSource = (DataSource) acc.getBean("c3p0dataSource");
System.out.println(dataSource);
运行结果也是没有问题的,代表我们第三方配置bean成功了。
加载properties文件
对于上面我们管理第三方bean的步骤相信大家已经熟悉了,接下来我们来看看上面的程序存在什么问题?我们把数据库驱动,url,用户名,密码这些都以值的形式配置在了value属性中,这导致我们程序还是高耦合,换在以前我们都是写在properties文件当中的,然后在外面加载properties文件,那Spring环境要怎么实现的呢?接下来我们就来学习这方面的知识。
对于Spring加载properties文件有些特殊,首先我们要开启一个新的命名空间,这个命名空间就叫context,在配置文件中找到beans标签,把后面的配置,它一开始是这样的
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
">
然后我们把第一个xmlns属性和第三个schemalLoaction属性的两个值都复制一下,然后把beans的地方都改成context就行了,或者你也可以直接照着我的配置格式使用,配置格式如下:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd
">
接着我们配置一下我们的命名空间,使用context命名空间中的property-placeholder标签指定要加载的properties文件(jdbc.properties文件我已经事先准备好了,相信你也知道这里面的四样配置是什么了吧),其中property-placeholder标签是表示占位符标签,什么占位符呢?就是代表我们properties文件中的值占位符。
如果要加载多个properties文件,只要用逗号隔开,在后面继续写就行了,但是推荐用**classpath*:*.properties**这样的格式去加载所有配置文件
<context:property-placeholder location="jdbc.properties"/>
<!-- 加载所有类路径下的所有配置文件-->
<context:property-placeholder location="classpath*:*.properties"/>
接着我们把原来bean配置中的值全部换成${ }占位符就行了,也就是使用属性占位符${ }读取properties文件中的属性。
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource">
<property name="driverClassName" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
</bean>
这样我们就完成了Spring读取properties文件的操作了。
容器扩展
获取容器
这里我们主要讲一些关于容器扩展的知识,首先我们来讲一下获取容器。
前面我们一直都是加载类路径下的配置文件来获取容器
//1.加载类路径下的配置文件
ApplicationContext acc = new ClassPathXmlApplicationContext("applicationContext.xml");
但Spring还提供了我们可以从文件系统下用绝对路径的方式加载配置文件
//2.文件系统下加载配置文件
ApplicationContext acc = new FileSystemXmlApplicationContext("配置文件的绝对路径")
接下来我们来讲一下获取bean的方式。
获取bean
前面我们都是使用getBean然后参数写bean的id属性来获取bean。
BookDao bookDao = (BookDao) acc.getBean("bookDao");
同时我们发现每次强转都特别麻烦,Spring也提供了另一个不用强转的,但是不仅要提供bean的id属性还要提供bean的类型。
BookDao bookDao = acc.getBean("bookDao", BookDao.class);
但是这和强转没两样,在前面我们知道Spring提供了按类型自动装配,同样这里也可以按类型自动获取bean,但是前提是bean对象必须是单例的。
BookDao bookDao = acc.getBean(BookDao.class);
容器类层次结构
这里了解即可,小编本来想给大家演示一下BeanFactory接口的,但是小编这里new不了XmlBeanFactory实现类了,一方面说明确实是老的过时了,贴个图,大家自己看一下吧。

总结
总结正方面小编没什么好补充的,老师总结的就很到位,小编就把老师的图贴出来,大家回顾一下。
容器相关

bean相关

依赖注入

注解开发
Spring的一大亮点就在于它的纯注解开发模式基本上已经完善了,这很大程度上增加了开发的速度,减少了开发的难度,下面我们就来学习一下Spring注解开发的相关知识。
注解开发定义bean
首先我们来看一下注解开发是怎样定义bean的,之前我们都是在配置文件中用bean标签去定义bean的,但是现在我们用的是注解开发,我们不用像以前那样了。
**第一步**:我们直接在bean定义那个class类上加上**@Component("bookDao")注解**,括号里写bean的名称,也就是之前我们定义的id属性。
@Component("bookDao")
public class BookDaoImpl implements BookDao {
@Override
public void save() {
System.out.println("book dao save ... ");
}
}
但是只写这一个注解并不够,**第二步**:我们还要让Spring容器去加载它,也就是我们要用到context命名空间中的**component-scan标签去扫描**,base-packpage属性指定你要扫描的包名。
<context:component-scan base-package="st.niu.dao.impl"/>
以上两步就是我们使用注解开发去定义bean。
但是还有两点**值得注意:**
第一:base-packpage属性我们可以直接写组织名,这样扫描的范围更大了,像我们在给service层的实现类配置bean时,这个扫描也可以扫描到。
第二:每个实现类我们都用@Component注解,好像有时候分的不是太清楚,所以Spring给我们提供了@Component的三个衍生注解:
//用于定义业务层的bean
@Service("bookService")
//用于定义控制层的bean
@Controller
//用于定义数据层的bean
@Repository("bookDao")
纯注解开发模式
上面我们说了Spring已经提供了纯注解开发,但是在刚刚的程序中,我们还是在配置文件中使用了标签,现在我们来看看怎么实现纯注解开发,来达到一点配置文件都不用写呢?
我们可以不用配置文件,取而代之的是去定义一个配置类,我们就暂且叫他SpringConfig,这个类就可以替代我们的配置文件,首先我们需要在类上加上**@Configuration 注解来表明当前类是一个配置类**,同时这个注解也就相当于之前我们applicationContext.xml中的以下这些配置
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd
">
</beans>
这时我们配置文件当中还有一对component-scan标签表示Spring扫描,同样我们可以在SpringConfig类上加上**@ComponentScan("st.niu")注解**代替扫描标签,括号里写要扫描的包名,至此我们的application Context.xml配置文件已经完全可以删掉了,而我们的SpringConfig配置类当中只有这么一点内容
@Configuration
@ComponentScan("st.niu")
public class SpringConfig {
}
值得注意一点的是,@ComponentScan注解要扫描多个的话,需要用数组的形式
@ComponentScan({"st.niu.dao","st.niu.service"})
最后一步就是原来我们获取Spring容器是采用加载配置文件的方式,但是现在我们是纯注解开发,配置文件都没有了,也就不能用以前那种方式了,所以这里我们是读取配置类的方式,同时创建的实现类也变成了AnnotationConfigApplicationContext
//加载配置类初始化容器
ApplicationContext acc =new AnnotationConfigApplicationContext(SpringConfig.class);
BookDao bookDao = (BookDao) acc.getBean("bookDao");
bookDao.save();
注解开发bean的管理
bean作用范围
这块也就是之前我们说的bean的单例与非单例那个事情,由于是注解开发,我相信你也已经想到了就是把之前写的那个scope属性换成@Scope标签加在定义的bean的类上呗,确实是这样的,你说的没错
@Scope("prototype")
bean生命周期
这块也就是之前我们说的init和destroy方法,有印象吧,既然是纯注解开发,也肯定不能像以前那样实现接口或者标签里定义属性啦,我们来看看纯注解开发怎么实现呢?
我们只要在定义方法时在方法上面加上注解就行了,初始化的方法就加**@PostConstruct**,销毁的方法就加**@PreDestroy**,表明当前方法是当前bean的生命周期方法。
@PostConstruct
public void init(){
System.out.println("book dao init ... ");
}
@PreDestroy
public void destroy(){
System.out.println("book dao destroy ...");
}
如果打出来没有这两个注解的提示,那就引入下面这项依赖
<dependency>
<groupId>javax.annotation</groupId>
<artifactId>javax.annotation-api</artifactId>
<version>1.3.2</version>
</dependency>
注解开发依赖注入
由于Spring注解开发讲究的就是快速,所以对于构造器注入和setter注入也就没什么好讲的,我们直接讲自动装配,回顾我们前面了解的注解开发模式,我相信你会想之前我们都是在bean标签中定义autowire属性来指定自动装配,那自动装配是不是也是加入个@autowire注解就可以了,我想说,是这样的大差不差,我们只要在我们要注入的对象上面加**@Autowired注解**就可以实现自动装配了
@Autowired
private BookDao bookDao;
这里我们都不用提供set方法,因为**@Autowired**底层是通过**反射里的暴力反射**直接给他注入值。还有就是底层是按类型装配的,如果想按名称装配就给多个相同类型的bean起名,然后变量定义就用你想用的那个bean的名,但是**不建议这样使用**,如果想要按名称装配就再加上**@Qualifier注解**,括号里去指定想注入的bean的名称。
@Autowired
@Qualifier("bookDao")
private BookDao bookDao;
注意@Qualifier注解依赖于@Autowired注解,所以@Autowired注解不可以省略。
上面我们讲完了引用类型的注入,现在我们来看一下简单类型的注入。同样,非常简单,和前面大差不差,前面我们用value属性,这里我们用**@Value("zhangsan")**,括号里写要注入的值
@Value("zhangsan")
private String name;
这时我们会发现我们把值在这里写死了,我们就会想到之前我们可以读取外部properties文件,那纯注解开发可不可以实现读取外部properties文件呢?当然可以,我们只要在SpringConfig配置类上面加上**@PropertySource("jdbc.properties")**注解,括号里写配置文件名
@PropertySource("jdbc.properties")
这里同样如果要加载多个文件就像@ComponentScan一样,用数组的形式。
** 但是注意:这里不可以使用号通配符*
** **注解开发管理第三方bean
管理第三方bean
由于我们要管理的是第三方的bean我们就要在配置文件中去声明,现在当然是在配置类中声明,但是我们要注意的是我们不能在SpringConfig中声明,我们应该重新创建一个独立的配置类去管理我们要导入的第三方bean。
怎么做呢?首先我们要创建一个新的配置类,然后提供一个方法,方法的返回值就写第三方bean,方法名尽量就叫我们要给bean起的名,接着在里面给第三方bean设置属性,最后返回就行了。然后我们要在这个方法上添加**@Bean注解**,表明当前方法返回值是一个bean。
public class JdbcConfig {
//3.添加@Bean,表示当前方法的返回值是一个bean
@Bean
//1.定义一个方法获得要管理的对象
public DataSource dataSource() {
DruidDataSource ds = new DruidDataSource();
//设置属性
ds.setDriverClassName("com.mysql.jdbc.Driver");
ds.setUrl("jdbc:mysql://localhost:3306/test");
ds.setUsername("root");
ds.setPassword("123456");
return ds;
}
}
我们已经把第三方bean给定义好了,但是在我们SpringConfig配置类中还不知道有这个配置类呢,我相信你可能会想是不是可以在 @ComponentScan注解上加上配置类让它扫描呢?我想说可以,但是不推荐,我们可以在SpringConfig类中用**@Import(JdbcConfig.class)注解**去表示导入哪个配置类,括号里写配置类的class文件,同样如果要写多个的话,用数组的形式
@Configuration
@ComponentScan("st.niu")
@Import(JdbcConfig.class)
@PropertySource("jdbc.properties")
public class SpringConfig {
}
这里补充一下:一般@ComponentScan注解用于扫描我们自己的bean,而@Import用于导入第三方bean。
为第三方bean注入资源
简单类型
非常简单,直接在成员变量位置上定义我们要注入的类型,然后上面加上@Value注解声明注入的值,然后下面设置属性时就用声明的变量就可以了
public class JdbcConfig {
@Value("com.mysql.jdbc.Driver")
private String driver;
@Value("jdbc:mysql://localhost:3306/test")
private String url;
@Value("root")
private String userName;
@Value("123456")
private String password;
@Bean
public DataSource dataSource() {
DruidDataSource ds = new DruidDataSource();
ds.setDriverClassName(driver);
ds.setUrl(url);
ds.setUsername(userName);
ds.setPassword(password);
return ds;
}
}
引用类型
注入引用类型,我们就把要注入的资源写在我们提供的**定义第三方bean的方法形参**上就可以了。 这里Spring是用的自动装配,Spring会去容器中找需要的Bean,所以需要的Bean也要先定义好。
@Bean
//假设第三方bean需要依赖BookDao这个bean那就这样写
public DataSource dataSource(BookDao bookDao) {
System.out.println(bookDao);
DruidDataSource ds = new DruidDataSource();
ds.setDriverClassName(driver);
ds.setUrl(url);
ds.setUsername(userName);
ds.setPassword(password);
return ds;
}
总结
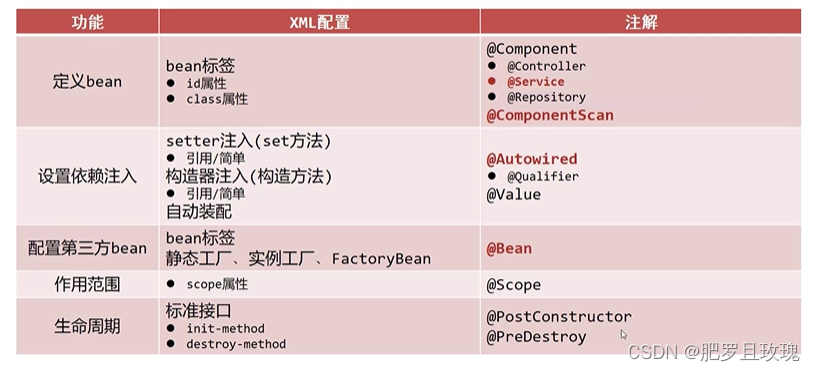
贴张图大家自己看一下XML配置与注解配置的比对吧
Spring整合案例
在之前讲XML配置的时候我们已经讲了Spring与DruidDataSource和c3p0的整合,现在我们学习玩注解开发之后,我们再来完成几个Spring与其它的整合。
Spring整合Mybatis
首先我们要整合Mybatis,那对应的依赖我们要导入吧,除了mybatis,mysql的依赖以外,我们还要导入两个依赖,一个是Spring操作jdbc的依赖,另一个是mybatis与Spring整合的依赖。
<!-- Spring操作JDBC的坐标-->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>5.2.10.RELEASE</version>
</dependency>
<!-- mybatis与Spring整合的坐标-->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
<version>3.0.3</version>
</dependency>
我们要整合Mybatis,我们又知道Mybatis原始操作中核心是SqlSessionFactory对象,所以我们的**核心目标**就是管理SqlSessionFactory这个Bean。
因此我们也就像之前那样,首先创建一个MybatisConfig配置类,里面提供返回SqlSessionFactory的对象,但是如果我们这样写,要set很多SqlSessionFactory的属性,所以Spring整合Mybatis的依赖给我们提供了**SqlSessionFacoryBean**简化了开发。其中因为SqlSessionFactoryBean需要配置一些数据库基本信息,然后我们之前在管理第三方bean,JdbcConfig类那里已经配置DataSource,这里就可以直接拿来用,其中第二个Bean----MapperScannerConfigurer是关于映射方面的读取,有关扫描可以实现自动代理,给我们自动生成dao的实现类。
public class MybatisConfig {
@Bean
public SqlSessionFactoryBean sqlSessionFactory(DataSource dataSource) {
SqlSessionFactoryBean ssfb = new SqlSessionFactoryBean();
ssfb.setTypeAliasesPackage("st.niu.domain");
ssfb.setDataSource(dataSource);
return ssfb;
}
@Bean
public MapperScannerConfigurer mapperScannerConfigurer(){
MapperScannerConfigurer msc=new MapperScannerConfigurer();
msc.setBasePackage("st.niu.dao");
return msc;
}
}
这一套Spring整合Mybatis都是固定格式,下次可以直接拿来用,换个参数就行了,但是以后会有更简单的方式。
Spring整合JUnit
同样的流程,我们先导两个坐标,一个是junit的坐标,一个是Spring整合Junit的坐标
<!-- junit坐标-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<!-- Spring整合Junit坐标-->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
<version>6.1.8</version>
</dependency>
接下来我们在Test文件夹下创建一个测试类,但是由于是Spring整合Junit所以我们还要交代一下运行器和Spring的运行环境,在测试类上定义**@RunWith(SpringJUnit4ClassRunner.class)** 注解设定类运行器和**@ContextConfiguration(classes = SpringConfig.class)**交代Spring的环境。然后写个测试方法就行了。
//设定类运行器
@RunWith(SpringJUnit4ClassRunner.class)
//交代Spring的环境
@ContextConfiguration(classes = SpringConfig.class)
public class AccountServiceTest {
@Autowired
private BookService bookService;
@Test
public void testbookService(){
bookService.save();
}
}
AOP
AOP面向切面编程,是一种编程范式,指导开发者如何组织程序结构。
作用:在不惊动**原始方法**的基础上为其进行**功能增强**。
Spring理念:无入侵式/无侵入式。
核心概念
连接点:所有的原始方法。
切入点:匹配连接点的式子,决定哪个连接点需要进行功能增强。
注意:连接点包含切入点,连接点范围大,切入点范围小。
通知:进行功能增强的方法。
切面:通知与切入点对应的关系。
通知类:通知所在的方法的类。
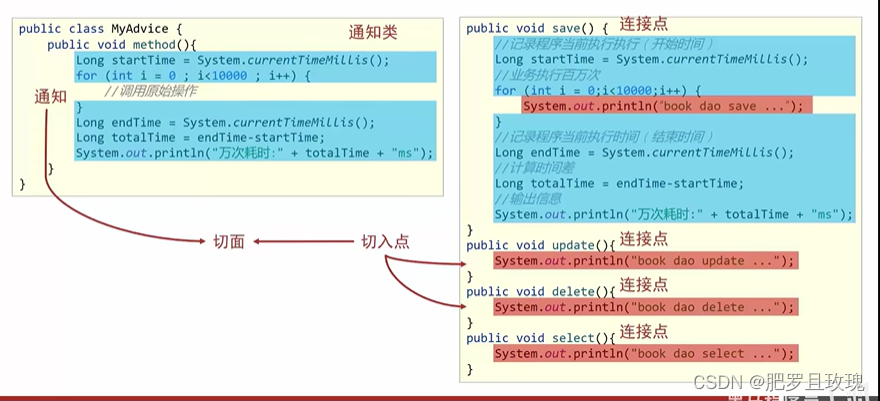

AOP入门案例
案例要求:在接口执行前输出当前系统时间。这里我们用注解开发来实现。
首先我们先分析一下思路:1.导入坐标(aop,aspect)2.制作连接点方法(原始操作,Dao接口与实现类)3.制作共性功能(通知类与通知)4.定义切入点 5.绑定切入点与通知关系
第一步:导入aop和aspect的坐标,但是这里值得注意的是我们之前导入了SpringContext的坐标,而aop与SpringContext有依赖关系,所以我们仅仅只需要导入aspect的坐标就行了
<!-- aspect坐标-->
<dependency>
<groupId>org.aspectj</groupId>
<artifactId>aspectjweaver</artifactId>
<version>1.9.4</version>
</dependency>
第二步:这个就是写一个接口和实现类,里面写两个方法进行比对就好了,这里大家看一眼就行了啊,和我们IOC入门案例没两样,为了区分,save方法实现了功能增强,update方法没有实现功能增强。另外注解开发不要忘了加上**@Repository注解**
@Repository
public class BookDaoImpl implements BookDao {
@Override
public void save() {
System.out.println(System.currentTimeMillis());
System.out.println("book dao save ...");
}
@Override
public void update() {
System.out.println("book dao update ...");
}
}
第三步:制作共性功能,前面我们知道这个东西叫通知,但是通知是在通知类当中的,所以我们先要创建一个通知类,就叫MyAdvice吧,然后再定义一个方法制作共性功能,就叫method吧。
public class MyAdvice {
public void method(){
System.out.println(System.currentTimeMillis());
}
}
第四步:定义切入点,这个比较复杂,首先我们要写一个私有的方法,方法名任意,这里我们叫pt,同时需要方法体但是不需要有实现,也就是定义一个空壳方法,接着又因为我们是注解开发,所以这时我们就在这个方法上加上**@Pointcut注解**,表明当前这个方法是定义的一个切入点,同时注解里加上这句话"execution(void st.niu.dao.BookDao.update())",其中execution是一个关键字,表示该切入点绑定的是括号里的这个方法,这个格式我们后面会详细讲,这里毕竟是入门程序,大家看得懂就行。
public class MyAdvice {
@Pointcut("execution(void st.niu.dao.BookDao.update())")
private void pt(){}
public void method(){
System.out.println(System.currentTimeMillis());
}
}
第五步:绑定切入点与通知关系,我们想在原始方法执行前执行通知,所以我们在method上面加上@Before("pt()")注解,括号里写的是绑定的哪个切入点。
@Before("pt()")
public void method(){
System.out.println(System.currentTimeMillis());
}
但是目前我们写的这个类还不归Spring容器管理,所以我们要在类上加上**@Component注解**,将该通知类放入IOC容器,同时变成Spring能控制得bean,同时我们再加上**@Aspect**注解告诉Spring将我们当前这个bean当作AOP作处理。最后我们这个程序还不知道我们当前是拿注解开发的AOP,所以我们还需要在SpringConfig配置类上加上**@EnableAspectJAutoProxy注解。**
//SpringConfig配置类当中
@Configuration
@ComponentScan("st.niu")
@EnableAspectJAutoProxy
public class SpringConfig {
}
//MyAdvice通知类
@Aspect
@Component
public class MyAdvice {
@Pointcut("execution(void st.niu.dao.BookDao.update())")
private void pt(){}
@Before("pt()")
public void method(){
System.out.println(System.currentTimeMillis());
}
}
以上就是我们AOP的入门案例,接下来我们就要详细学习AOP了。
AOP工作流程
1.Spring容器启动
2.读取所有切面配置中的切入点,如果切入点只定义不使用就不会读取
3.初始化bean,判定bean对应的类中的方法是否匹配到任意切入点
如果匹配失败,创建对象
如果匹配成功,创建(原始对象)目标对象的代理对象
4.获取bean执行方法
获取bean,调用方法并执行,完成操作
获取的bean是代理对象时,根据代理对象的运行模式运行原始方法与增强的内容,完成操作。
注意:如果想看到是否是代理对象,我们要打印对象的类型(getClass),不要直接打印对象,因为AOP中对代理对象底层重写了toString方法。
SpringAOP本质:代理模式
AOP切入点表达式
我们在入门案例中写的"void st.niu.dao.BookDao.update())"就是切入点表达式,也就是对我们要进行增强的方法的描述方式就是切入点表达式。
描述方式又分为描述接口和描述实现类,入门案例我们就是描述接口,同样我们也可以描述实现类"void st.niu.dao.impl.BookDaoImpl.update()"。那这个切入点表达式有没有一个标准形式呢?下面就让我们来看一下。
切入点表达式标准格式:动作关键字(访问修饰符 返回值 包名.类/接口名.方法名(参数)异常名)
@Pointcut("execution(void st.niu.dao.BookDao.update())")
动作关键字:描述切入点的行为动作,例如execution表示执行到指定切入点
访问修饰符:public ,private等,可以省略
返回值:void
包名:st.niu.dao
类/接口名: BookDao
方法名:update
参数:空
异常名:方法定义中抛出指定异常,可以省略。
同时切入点表达式支持通配符快速描述
*****:单个独立的任意符号,可以独立出现,也可以作为前缀或者后缀的匹配符出现。
@Pointcut("execution(public * st.niu.*.BookDao.update*(*))")
上面这个式子匹配的是**返回值任意**,st.niu包下的**任意一级包**的BookDao接口中,**任意以update开头**的方法中**有任意一个参数**的方法。
**..**:多个连续的任意符号,可以独立出现,常用于简化包名与参数的书写。
@Pointcut("execution(public void st..BookService.update(..))")
上面这个式子匹配的是返回值为void,st包下的**任意级包**的BookService接口中,名为update的方法中**有任意个参数**的方法。
+:专用于匹配子类类型
@Pointcut("execution(* *..*Service+.*(..))")
上面这个式子匹配的是**返回值任意**,任意包下以**Service结尾的类或接口的子类**的**任意方法**,**任意参数**(通俗讲也就是业务层的所有方法)。
**注意**:下面这个式子非常疯狂,代表匹配工程下的所有方法。
@Pointcut("execution(* *..*(..))")
下面贴张图大家看一下切入点表达式的书写技巧 
AOP通知类型
AOP通知描述了抽取的共性功能,根据共性功能抽取的位置不同,最终运行代码时要将其加入到合理的位置
AOP通知共分为五种类型
前置通知,后置通知,环绕通知(重点),返回后通知(了解),抛出异常后通知(了解)
前置通知
表示在目标方法执行前执行
@Before("pt()")
public void before(){
System.out.println("before advice ...");
}
后置通知
表示在目标方法执行后执行
@After("pt()")
public void after(){
System.out.println("after advice ...");
}
环绕通知(重点)
表示环绕目标方法执行,可以理解为与整个目标方法有关。环绕通知**必须要加上参数ProceedingJoinPoint**,表示原始方法运行对象,然后手动调用proceed()方法表示调用原始方法,否则原始方法根本不会执行。另外proceed()方法会强制抛异常,目的是防止原始方法抛出异常。
@Around("pt()")
public void around(ProceedingJoinPoint pjp) throws Throwable {
System.out.println("around before advice ...");
pjp.proceed();
System.out.println("around after advice ...");
}
另外如果原始方法运行完有参数,我们要用一个Object对象去接受,然后返回回去,所以我们的通知方法返回值也要定义成Object。另外如果原始方法是void类型,我们也可以接受到,只不过值是null
@Around("pt2()")
public Object aroundSelect(ProceedingJoinPoint pjp) throws Throwable {
System.out.println("around before advice ...");
Object result = pjp.proceed();
System.out.println("around after advice ...");
return result;
}
**补充 **
** 前面我们说过ProceedingJoinPoint是表示原始方法运行对象,那我们能不能拿到当前运行的对象的信息呢?这个对象提供了对应的方法getSignature()我们可以拿到一次执行的签名信息,可以理解为通过这个方法可以拿到封装这一次执行过程**的对象。通过这个签名信息,我们就可以拿到原始方法执行的信息了,比如方法名,类名等等。
@Around("pt()")
public Object around(ProceedingJoinPoint pjp) throws Throwable {
Object result = pjp.proceed();
//拿到当前这次执行的签名信息
Signature signature = pjp.getSignature();
//拿到方法名
String name = signature.getName();
//拿到方法的类名
Class declaringType = signature.getDeclaringType();
return result;
}
返回后通知
原始方法结束后运行,但是和后置通知不同的是,返回后通知只有**当原始方法正常结束**才会运行,而后置通知不管原始方法是否正常结束都会运行。
@AfterReturning("pt()")
public void afterReturning() {
System.out.println("afterReturning advice ...");
}
抛出异常后通知
只有当原始方法抛出异常才会运行
@AfterThrowing("pt()")
public void afterThrowing() {
System.out.println("afterThrowing advice ...");
}
AOP通知获取数据
这里我们来讲一下怎样从AOP通知中获取我们的数据,获取数据也分为三种,获取参数,获取返回值,获取异常。
** 获取参数 **
所有通知类型都可以拿到。
我们知道对于环绕通知我们可以通过**ProceedJointPoint参数**拿到原始方法对象,那其它四种通知呢?其实也差不多,只不过是参数有所不同,其它四种通知是通过**JoinPoint参数**获取到原始方法对象。我们先来看其它四种通知获取参数的方式,这里只讲前置通知了,因为另外三种获取方式一模一样,只要**声明JoinPoint参数**然后调用**getArgs()方法**就可以获取参数了。
** 注意**:如果有多个参数JoinPoint和ProceedJointPoint必须是形参里的第一个。
@Before("pt()")
public void before(JoinPoint jp) {
//拿到参数数组
Object[] args = jp.getArgs();
System.out.println(Arrays.toString(args));
System.out.println("before advice ...");
}
同样环绕通知获取参数也是调用一样的方法
@Around("pt()")
public Object around(ProceedingJoinPoint pjp) throws Throwable {
Object result = pjp.proceed();
Object[] args = pjp.getArgs();
System.out.println(Arrays.toString(args));
return result;
}
**补充:**但是我相信有人之前就想过,如果原始方法有参数,但是方法proceed()却没有传参,这是为什么呢?其实这里你不传参,它底层默认也会调用getArgs()得到参数然后传给proceed() 方法,但是我们也可以先把参数获取出来,对参数进行修改,然后再手动传给proceed()方法,这就适合某些需要对用户的数据进行特殊处理的时候使用。
获取返回值(了解)
只有返回后通知和环绕通知可以拿到
环绕通知我们之前已经演示过了,就是用一个参数去接受proceed()方法的返值。
这里我们来看一下返回后通知怎么拿返回值,分两步,第一步:我们要在注解后面**设置returning属性**,来声明返回值的变量名,第二步:在方法的形参上设置一个同名的Object对象,表示把方法的返回值装到这个变量里。
@AfterReturning(value = "pt()", returning = "ret")
public void afterReturning(Object ret) {
System.out.println("afterReturning advice ..." + ret);
}
** 获取异常(了解)**
只有抛出异常后通知和环绕通知可以拿到。
环绕通知要获取异常就让proceed()方法不要抛异常,用try catch捕捉就拿到了。
抛出异常后通知怎么拿到异常呢?其实和上面差不多,**多设置一个throwing属性和Throwable形参就行了**。上面返回后通知获取返回值和这个了解就行。
@AfterThrowing(value = "pt()",throwing = "t")
public void afterThrowing(Throwable t) {
System.out.println("afterThrowing advice ..."+t);
}
总结
总结这一块我偷个懒,就贴几张图,大家自己看一下吧。




Spring事务
Spring事务简介
事务的概念这一块相信大家都是知道的,我这里就简单说一下就行了。
事务是一组操作的集合,它是一个不可分割的工作单位。
事务作用:在数据层保障一系列的数据库操作同成功同失败。
Spring事务作用:在**数据层或业务层**保障一系列的数据库操作同成功同失败。
可见Spring事务区别在于可以在业务层也开启事务。
如何实现Spring开启事务呢?
第一步:在我们要加事务的方法上加**@Transactional注解,**但是建议一般不要加在实现类方法上,加在接口方法上。但是该注解同样可以写在类或者接口上,表示这一整个类或接口都开启事务。
@Transactional
public void update();
第二步:需要到我们在配置类中配置一个**事务管理器PlatformTransactionManager**,配置第三方bean相信大家都还有印象吧,这里我们要配置的是一个jdbc事务的实现类,因为我们是演示jdbc的事务,因此我们这里配置的是一个DataSource事务管理器,所以我们要设置DataSource,那怎么给第三方bean注入依赖,不就是添加在形参上嘛,相信你也没有忘。
@Bean
public PlatformTransactionManager transactionManager(DataSource dataSource) {
DataSourceTransactionManager transactionManager = new DataSourceTransactionManager();
transactionManager.setDataSource(dataSource);
return transactionManager;
}
第三步:在SpringConfig配置类中告诉Spring我们现在用注解式事务驱动了,所以我们需要在配置类上加上**@EnableTransactionManagement注解。**
@EnableTransactionManagement
以上就是开启Spring事务的基本步骤。
Spring事务角色
Spring之所以实现业务层也可以开启事务就是因为一般业务层会调用数据层,而每个数据层的方法也都要开启事务,那不如直接在业务层开启事务来进行事务的统一管理。
事务管理员:发起事务方,在Spring中通常指代业务层开启事务的方法。
事务协调员:加入事务方,在Spring中通常指代数据层方法,也可以是业务层方法。
Spring事务属性
我们在开启事务时我们同时可以给当前事务设置属性,在@Transactional注解里声明属性值就行了,属性值有如下这些
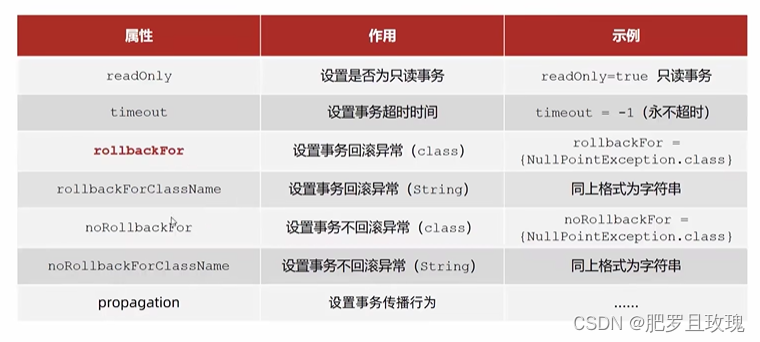
我们这里着重讲一下rollbackFor属性,在这个属性中我们可以**设置让事务回滚的异常**,就是声明遇到哪些异常才回滚 。
@Transactional(rollbackFor = {IOException.class})
下面我们有一个问题,当我们如果想在业务层去实现无论是否成功都要记录日志时,我们会发现我们把当前这个记录日志如果像上面一样书写就会被事务统一管理,这样rollback回滚的时候我们也就无法实现记录日志,这是当前存在的问题,接下来我们要介绍一个新的知识叫做事务传播行为。
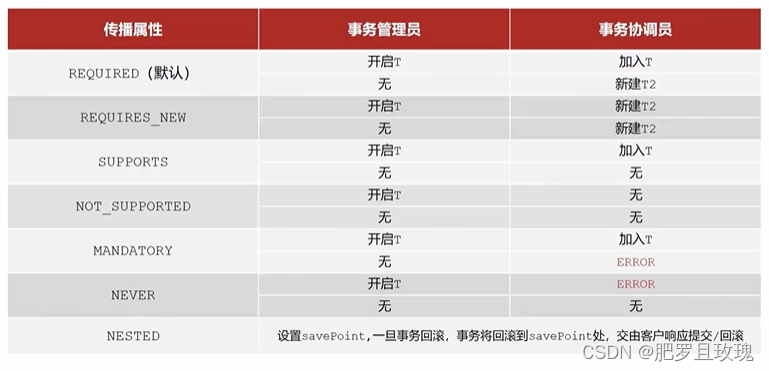
事务传播行为:事务协调员对事务管理员所携带事务的处理态度。一般来说也就是业务层对于数据层的事务决定是否统一管理,在上面的问题当中,我们就不希望记录日志的事务被统一管理,我们只要在记录日志的事务注解上声明**propagation属性值**,其中**REQUIRES_NEW**表示让事务管理员对于当前这个事务不要统一管理,另外开启一个新事物。
@Transactional(propagation = Propagation.REQUIRES_NEW)
下面这些传播行为就是其它传播属性值,REQUIRES_NEW掌握,其它作为了解,
结语
以上就是Spring的大致知识点了,小编这一篇笔记下来,下面显示有三万来个字,怎么说呢,确实不容易吧,但是小编自身收获也挺多,对Spring有了进一步的理解,如果这一台套知识梳理对你有所帮助,可以三连支持一下。 以上知识点与贴图均由小编自己学习黑马程序员的SSM教学视频总结而来。【黑马程序员SSM框架教程_Spring+SpringMVC+Maven高级+SpringBoot+MyBatisPlus企业实用开发技术】https://www.bilibili.com/video/BV1Fi4y1S7ix?p=43&vd_source=f9c02b14d6c8f102a730f58d382df8b
本文转载自: https://blog.csdn.net/2301_80339238/article/details/139799649
版权归原作者 肥罗且玫瑰 所有, 如有侵权,请联系我们删除。
版权归原作者 肥罗且玫瑰 所有, 如有侵权,请联系我们删除。