
写在前面
基于前面对Flink基础的学习,本章在对基础知识点的了解基础上,开始尝试使用Flink进行更进一步的应用。本周在工作中,同事遇到了使用Flink中两阶段提交的机制,因此,在应用篇中对两阶段提交进实现端到端的Exactly Once进行介绍。2PC本质上就是一种分布式一致性算法,其目的是为了保证分布式系统中事务一致性。当然,本帖子只作为学习用,实际应用场景会更加复杂,关于实践过程中的问题欢迎留言交流。
1、两阶段提交
两阶段提交(Two-phase Commit,简称2PC)是在分布式系统架构的中,为了保证事务一致性的一种分布式一致性算法。在分布式系统中,每个节点虽然可以知晓自己的操作时成功或者失败,却无法知道其他节点的操作的成功或失败。当一个事务跨越多个节点时,为了保持事务的ACID特性,需要引入一个作为协调者的组件来统一掌控所有节点(称作参与者)的操作结果并最终指示这些节点是否要把操作结果进行真正的提交(比如将更新后的数据写入磁盘等等)。因此,二阶段提交的算法思路可以概括为: 参与者将操作成败通知协调者,再由协调者根据所有参与者的反馈情报决定各参与者是否要提交操作还是中止操作。
注:这里的一致性就是ACID中的Consistency,AID都是为了实现C。
1.1、实现前提
2PC算法的成立基于以下假设:
- 该分布式系统中,存在一个节点作为协调者(Coordinator),其他节点作为参与者(Participants)。且节点之间可以进行网络通信。
- 所有节点都采用预写式日志,且日志被写入后即被保持在可靠的存储设备上,即使节点损坏不会导致日志数据的消失。
- 所有节点不会永久性损坏,即使损坏后仍然可以恢复。
1.2、基本算法
2PC的整个过程分为2个阶段,准备阶段和提交阶段。
1. 准备阶段
1、事务询问:协调者向所有参与者发送事务内容,询问是否可以执行事务的提交操作,并等待各参与者的响应。
2、执行事务:各参与者执行事务操作,准备好事务资源,记录undo、redo信息。
3、反馈询问结果:如果参与者成功执行了事务操作,那么返回给协调者
yes(表示当前事务可以提交),否者返回给协调者no(表示当前事务不能执行)
。
2. 提交阶段
在准备阶段,由于参与者可以返回yes/no,则在提交阶段也会出现两种可能,即全局提交事务、全局回滚事务。
全局提交事务:当准备阶段所有参与者都返回yes的响应后,协调者就爱那个发起全局提交事务请求。
1、发送提交请求:由协调者向所有参与者发送global_commit请求,要求提交当前事务。
2、事务提交:当参与者收到global_commit请求后,则执行事务提交操作,并释放整个分布式事务期间占用的事务资源。
3、反馈提交结果:参与执行完事务提交后,向协调者返回ack消息。
4、完成事务提交:
协调者收到所有参与者反馈的ack消息后,给客户端返回结果,完成本次事务
。
注:从这里可以看出,客户端只和协调者进行交互。
全局回滚事务:当准备阶段有一个参与者都返回no的响应后,实际场景中,协调者还会怎加等待响应时间,如果超时后,则协调者将发起全局回滚事务请求,中断事务。
1、发送回滚请求:由协调者向所有参与者发送global_rollback请求,要求中断当前事务
2、事务回滚:当参与者收到global_rollback请求后,会利用准备阶段记录的undo信息来进行回滚,并释放整个分布式事务期间占用的事务资源。
3、反馈回滚结果:参与在执行完事务提交后,向协调者返回ack消息。
4、中断事务:协调者收到所有参与者反馈的ack消息后,给客户端返回结果,完成中断事务。
协调者 参与者
QUERY TO COMMIT
-------------------------------->
VOTE YES/NO prepare*/abort*
<-------------------------------
commit*/abort* COMMIT/ROLLBACK
-------------------------------->
ACKNOWLEDGMENT commit*/abort*
<--------------------------------
end
"*" 所标记的操作意味着此类操作必须记录在稳固存储上.
1.3、存在问题
2PC协议明显的优点就是:原理简单、容易实现。但是它的缺点更加明显:
1、同步阻塞:每个参与者都需要等待协调者的消息,才能继续下一阶段。当协调者在发送第二阶段的消息之前宕机,那么所有参与者将一直锁定准备阶段的事务资源,事务推进不下去了,造成事务阻塞。只有等到协调者恢复,事务才能继续进行。
2、单点问题/脑裂:协调者在2PC中,太过重要,当协调者宕机,整个集群将不可用。脑裂是指因为网络原因,出现多个协调者。
3、太过保守:任何一个节点故障,都会导致整个事务协调失败,换句话说没有完善的容错机制。
2、Kafka的Exactly One
Kafka 0.11.0.0 版本开始引入了幂等性与事务这两个特性,以此来实现 EOS ( exactly once
semantics ,精确一次处理语义)。
在消息队列中,存在at most once、at least once、exactly once三种语义,根据【FLP不可能定理】,exactly once由于涉及到发送端和生产端的各种机制的限制,绝对的exactly once级别是几乎不可能存在的。但是通过减少重复消费+at least once,可以近似逼近 exactly once。
那 Kafka 中的 Exactly Once 又是解决的什么问题呢?它解决的是,在流计算中,用 Kafka 作为数据源,并且将计算结果保存到 Kafka 这种场景下,数据从 Kafka 的某个主题中消费,在计算集群中计算,再把计算结果保存在 Kafka 的其他主题中。这样的过程中,保证每条消息都被恰好计算一次,确保计算结果正确。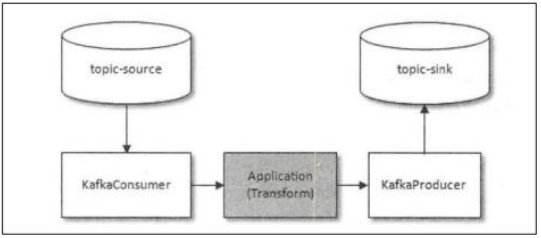
2.1、Kafka的幂等性
幂等性是数学中一个概念,对于一个函数,使用相同的参数,执行多次,获取的结果是一致的。如果业务不满足幂等性,在消息被重复消费的时候,可能会导致数据的不一致,从而导致业务数据错乱。
幂等性:保证生产者的exactly once
,这里的幂等性只保证生产消息的Exactly Once,和幂等写入不是一个概念。
生产者在进行发送失败后的重试时(retries),有可能会重复写入消息,而使用 Kafka 幂等性功能之
后就可以避免这种情况。
具体过程如下:
1、每一个 producer 在初始化时会生成一个 producer_id,并为每个目标分区维护一个“消息序列号”;
2、producer 每发送一条消息,会将<producer_id,分区>对应的“序列号”加 1
3、broker 端会为每一对{producer_id,分区}维护一个序列号,对于每收到的一条消息,会判断服
务端的 SN_OLD 和接收到的消息中的 SN_NEW 进行对比:
- 如果 SN_OLD + 1 == SN_NEW,正常;
如果 SN_NEW<SN_OLD+1,说明是重复写入的数据,直接丢弃- 如果 SN_NEW>SN_OLD+1,说明中间有数据尚未写入,或者是发生了乱序,或者是数据丢失,将抛出严重异常:OutOfOrderSequenceException
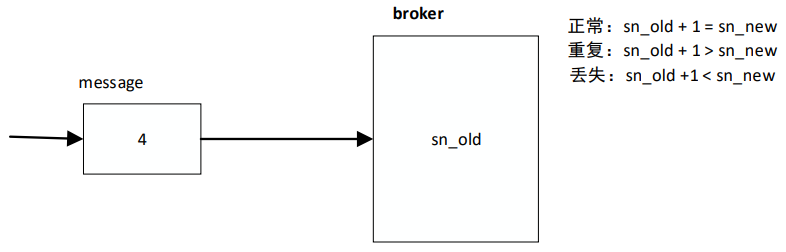 举例: producer.send(“aa”) 消息 aa 就会拥有了一个唯一的序列号 如果这条消息发送失败,producer 内部自动重试(retry),此时序号不变; producer.send(“bb”) 消息 bb 拥有一个新的序列号。
举例: producer.send(“aa”) 消息 aa 就会拥有了一个唯一的序列号 如果这条消息发送失败,producer 内部自动重试(retry),此时序号不变; producer.send(“bb”) 消息 bb 拥有一个新的序列号。
注意:
1、kafka 只保证 producer 单个会话中的单个分区幂等;因为,一个消息不会发送到多个分区里面,分区之间不用考虑幂等性;
2、`上述方式也可以理解为kafka在生产端的exactly once
2.2、Kafka的事务
回到前面的使用exactly once,我们往往需要实现,从“读取 source 数据,至业务处理,至处理结果写入 kafka”的整个流程,具备原子性:要么全部流程成功,要么全部失败!
(也就是说,处理且输出结果成功,才会提交消费者端偏移量;如果处理或者输出结果失败,
则消费偏移量也不会提交)
保证消费者的exactly once
事务的实现大致上是一个两阶段提交过程,一是增加 Transaction ID,二是增加事务控制消息,三是增加一个 Transaction Coordinator 组件。
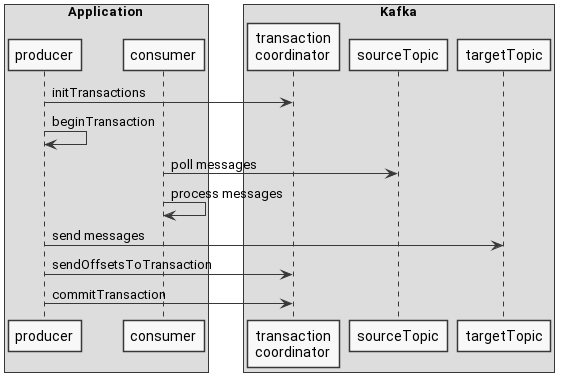
整个过程大致如下图:
- producer 寻找事务协调器:producer 向任意 broker 发送 FindCoordinatorRequest,得到 Coordinator 的地址;
- producer 向 Coordinator 发送 InitPidRequest,得到 PID,从而可以完成下属操作 - 将 transaction ID 与 PID 绑定,允许重启后仍能得到同样的 PID,从而做到跨 Session 的 Exactly Once 保证;- 递增 PID 对应的 Epoch,避免前一代卡死掉的 Producer 继续搞事情;- 继续或回滚该 Producer 未完成的事务;
- 开始事务:Producer 调用 beginTransaction 方法表示开启新事务,这里并没有对 Coordinator 的请求,只是将 Producer 标记为 IN_TRANSACTION 状态;
- Consume-Transform-Produce 循环,消费者拉取消息并处理消息,然后通过send message写入下一个topic
- 提交偏移量给事务协调器:除了将新生成的消息添加到事务中之外,我们还必须处理消耗的偏移量,因为这些偏移量应该与事务同时提交。
- 提交事务:表示完成了消费。
总的来说:
- 幂等 + At Least Once == Exactly Once:PID 与 Sequence 号允许 Kafka 的 Producer 实现 Exactly Once 语义。
- Kafka 事务只保证 Kafka 系统内部读写操作的原子性;
- 利用提交点位是向 __commit_offset 这个内部 Topic 写入的性质, 可以将 Consume-Transform-Produce 循环视为原子批量写入。
- 消费侧通过事务控制消息即 Commit/Abort Marker 来决定消费事务消息还是忽略事务消息,开启 Read Committed 后,Consumer 最多读取到 LSO(Last Stable Offset)位置的消息,LSO < HW < LEO。
3、Flink的Exactly Once
3.1、Exactly-once Semantics Within an Apache Flink Application
Flink 集群本身是如何保证 Exactly Once 语义的?
Flink 集群本身也是一个分布式系统,它首先需要保证数据在 Flink 集群内部只被计算一次,只有在这个基础上,才谈得到端到端的 Exactly Once。
Flink 通过 CheckPoint 机制来定期保存计算任务的快照,这个快照中主要包含两个重要的数据:
- 整个计算任务的状态。这个状态主要是计算任务中,每个子任务在计算过程中需要保存的临时状态数据。
- 数据源的位置信息。这个信息记录了在数据源的这个流中已经计算了哪些数据。如果数据源是 Kafka 的主题,这个位置信息就是 Kafka 主题中的消费位置。
有了 CheckPoint,当计算任务失败重启的时候,可以从最近的一个 CheckPoint 恢复计算任务。具体的做法是,每个子任务先从 CheckPoint 中读取并恢复自己的状态,然后整个计算任务从 CheckPoint 中记录的数据源位置开始消费数据,只要这个恢复位置和 CheckPoint 中每个子任务的状态是完全对应的,或者说,每个子任务的状态恰好是:“刚刚处理完恢复位置之前的那条数据,还没有开始处理恢复位置对应的这条数据”,这个时刻保存的状态,就可以做到严丝合缝地恢复计算任务,每一条数据既不会丢失也不会重复。
3.2、End-to-end Exactly Once Applications with Apache Flink
在 Flink 1.4 之前,只在 Flink 内部保证精确处理一次语义,对于第三方数据源没有保证。但是 Flink 应用程序与各种各样的 Sink 一起运行,开发人员需要能够实现 end2end 的精确一次语义。要提供端到端的精确一次语义,这些外部系统必须提供提交和回滚与 Flink Checkpoint 相协调的方法。
核心要点:
数据从source、process、sink的整个流程中,要么每个环节都处理,要么都失败回滚到未处理的状态(类似于事务的原子性)。Flink 在目前的各类分布式计算引擎中,对 EOS 的支持是最完善的;
- source端的EOS保证: Flink 的很多 source 算子都能为 EOS 提供保障,如kafkaSource:- 能够记录偏移量,说明消费的位置- 能够重放数据- 将偏移量记录在State中,与下游其他算子的state一起,由Checkpoint机制实现“状态数据的”快照统一
- 算子状态的EOS语义保证: 基于分布式快照算法:(Chandy-Lamport),flink 实现了整个数据流中各算子的状态数据快照统一。即:一次 checkpoint 后所持久化的各算子的状态数据,确保是经过了相同数据的影响; 这样一来,就能确保:- 一条(或一批)数据要么是经过了完整正确处理;- 如果这条(批)数据在中间任何过程失败,则重启恢复后,所有算子的 state 数据都能回到这条数据从未处理过时的状态
- sink端的EOS保证: 从的 source 端和内部 state 的容错机制来看,一批数据如果在 sink 端写出过程中失败(可能 已经有一部分数据进入目标存储系统),则重启后重放这批数据时有可能造成目标存储系统中出现数 据重复,从而破坏 EOS; 对此,flink 中也设计了相应机制来确保 EOS:- 采用幂等写入方式,目标存储系统支持幂等写入,且数据中有合适的 key(主键)- 采用两阶段提交(2PC,two phase)事务写入方式,外部系统不但要支持事务,同时也要能支持根据事务 id 去恢复之前的事务,参考接口:
TwoPhaseCommitSinkFunction- 采用预写日志 2PC 提交方式,本质上和2PC一样,只是这个时候不将数据提前写到目标存储系统,参考接口:GenericWriteAheadSink
2PC过程说明如下:
第一阶段:预提交阶段
1、开启事务---->正常输出数据---->Barrier到达---->4、预提交事务(存储本质对外事务号,以及事务状态,pending)---->3、做local Checkpoint----->3、向JobManager上报---->等待notify通知
第二阶段:事务提交阶段
notify到达---->5、提交事务(向外部系统commit,如果成功,则修改事务状态:finished)
注:如果第一阶段成功后,系统突然出问题,那么二阶段无法提交,如果间隔时间短还行,时间长了,则二阶段即时提交了事务,外部存储系统还是无法恢复数据。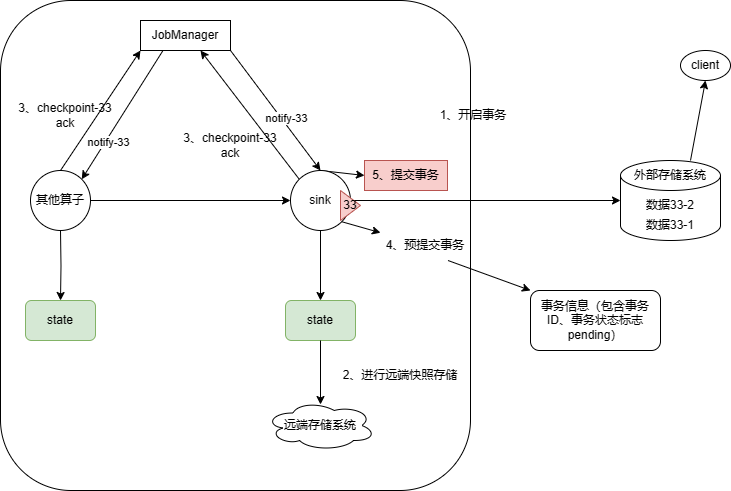
3.3、Implementing the Two-Phase Commit Operator in Flink
在使用两步提交算子时,我们可以继承
TwoPhaseCommitSinkFunction
这个虚拟类。
- 开始事物(beginTransaction)- 创建一个临时文件夹,来写把数据写入到这个文件夹里面。
- 预提交(preCommit)- 将内存中缓存的数据写入文件并关闭。
- 正式提交(commit)- 将之前写完的临时文件放入目标目录下。这代表着最终的数据会有一些延迟。
- 丢弃(abort)- 丢弃临时文件。
通过一个简单例子来解释一下这个虚拟类。这个两步提交的类有四个状态。
1、从kafka读数据(里面有Operator-state状态)
KafkaSource<String> sourceOperator =KafkaSource.<String>builder().setBootstrapServers("192.168.247.129:9092").setTopics("eos").setGroupId("eos01").setValueOnlyDeserializer(newSimpleStringSchema()).setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"false")//flink容错并不依赖__consumer_offsets的记录.setProperty("commit.offsets.on.checkpoint","false").setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.LATEST)).build();DataStreamSource<String> stream1 = env
.fromSource(sourceOperator,WatermarkStrategy.noWatermarks(),"kfkSource");
2、处理过程中用到了带状态的map算子,(里面用到了keyed-state状态)
逻辑:输入一个字符串,变大写拼接此前字符串,输出
SingleOutputStreamOperator<String> stream2 = stream1.keyBy(s ->"group1").map(newRichMapFunction<String,String>(){privateValueState<String> valueState;@Overridepublicvoidopen(Configuration parameters)throwsException{
valueState =getRuntimeContext().getState(newValueStateDescriptor<String>("preStr",String.class));}@OverridepublicStringmap(String element)throwsException{// 从状态中取出上一条字符串String preStr = valueState.value();if(preStr ==null) preStr ="";// 更新状态
valueState.update(element);//埋点异常int random =RandomUtils.nextInt(1,4);System.out.println(element+"-------"+random+"-------"+("x".equals(element)&& random %2==0));if("x".equals(element)&& random %2==0){System.out.println("产生异常......");thrownewException("产生异常......");}return preStr +":"+ element.toUpperCase();}});
3、用Exactly-Once的MySQL-sink算子输出数据(并附带主键的幂等性 )
publicclassMySqlTwoPhaseCommitSinkextendsTwoPhaseCommitSinkFunction<String,Connection,Void>{privateString curValue;publicMySqlTwoPhaseCommitSink(TypeSerializer<Connection> transactionSerializer,TypeSerializer<Void> contextSerializer){super(transactionSerializer, contextSerializer);}@Overrideprotectedvoidinvoke(Connection connection,String value,Context context)throwsException{System.err.println("start invoke......."+value);
curValue = value;String sql ="insert into t_eos value(?)";PreparedStatement ps = connection.prepareStatement(sql);
ps.setString(1, value);//执行insert语句
ps.execute();}@OverrideprotectedConnectionbeginTransaction()throwsException{String url ="jdbc:mysql://localhost:3306/flinktest?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&useSSL=false&autoReconnect=true";Connection connection =DBConnectUtil.getConnection(url,"root","123456");System.err.println("start beginTransaction......."+curValue);return connection;}@OverrideprotectedvoidpreCommit(Connection connection)throwsException{System.err.println("start preCommit......."+curValue);}/**
* 如果invoke执行正常则提交事物
* @param connection
*/@Overrideprotectedvoidcommit(Connection connection){System.err.println("start commit......."+curValue);DBConnectUtil.commit(connection);}@OverrideprotectedvoidrecoverAndCommit(Connection connection){System.err.println("start recoverAndCommit......."+curValue);}@OverrideprotectedvoidrecoverAndAbort(Connection connection){System.err.println("start abort recoverAndAbort......."+curValue);}/**
* 如果invoke执行异常则回滚事物,下一次的checkpoint操作也不会执行
* @param connection
*/@Overrideprotectedvoidabort(Connection connection){System.err.println("start abort rollback......."+curValue);DBConnectUtil.rollback(connection);}}
stream2.addSink(newMySqlTwoPhaseCommitSink(newKryoSerializer<>(Connection.class,newExecutionConfig()),VoidSerializer.INSTANCE));
测试结果分析:
1、kafka产生消息,flink4后面的x,产生异常
2、task重启,重启后,重启日志为flink4执行后的Checkpoint,x再次被flink算子处理,flink4:X插入记录;
注:这里的x产生异常后,Checkpoint只能从flink4重启,因为map算子下游无法正常返回notify给JobManager。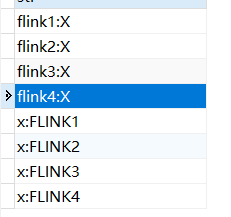
参考链接:
- https://ofcoder.com/2020/07/05/theory/%E5%88%86%E5%B8%83%E5%BC%8F%E4%B8%80%E8%87%B4%E6%80%A7%E5%8D%8F%E8%AE%AE%20-%202PC,%203PC/
- https://flaneur2020.github.io/2020/03/30/kafka02-transaction/
- https://zh.wikipedia.org/wiki/%E4%BA%8C%E9%98%B6%E6%AE%B5%E6%8F%90%E4%BA%A4
- https://chrzaszcz.dev/2019/12/kafka-transactions/
- https://blog.csdn.net/weixin_54542328/article/details/135149508
- https://vendanner.github.io/2021/03/12/%E8%AF%91-An-Overview-of-End-to-End-Exactly-Once-Processing-in-Apache-Flink-(with-Apache-Kafka,-too!)/
- https://www.bing.com/images/blob?bcid=r8wGOJAHq3cGbzlM.wmJozosDpfG…3M
- https://flink.apache.org/2018/02/28/an-overview-of-end-to-end-exactly-once-processing-in-apache-flink-with-apache-kafka-too/
版权归原作者 星星点灯1996 所有, 如有侵权,请联系我们删除。