
一、数据库系统基础
1.1概念
1.1.1 基础芝士
数据库 DB ,数据库管理系统 DBMS (mysql,oracle,sqlsever...), 结构化查询语言 SQL
DBMS——>SQL——>DB
1.1.2 SQL语言分类
1,DQL数据查询语言(select)
2, DML数据操作语言(对 **表** 数据 增 insert 删 delete 改 update)
3, DDL数据定义语言 (操作**表结构 **增 create 删 drop 改 alter)
4, TCL 事务控制语句 事务提交commit **事务回滚rollback**
5,DCL 数据控制语言(权限)
1.1.3数据独立性(物理独立性,逻辑独立性)
物理:用户应用程序与数据库中数据的物理存储是独立的
逻辑: 用户应用程序与数据库中数据的逻辑结构是独立的
1.2概念模型
1.2.1实体,属性,码(键),实体类型,实体集,联系
** 关系型数据库采用关系模型**
1.2.2 ER图和关系模型
** 一.画ER图**
1.矩形框——实体
2.椭圆 ——属性
3.菱形框——表示联系
** 二.联系:一对一,一对多,多对多**
eg1:
** 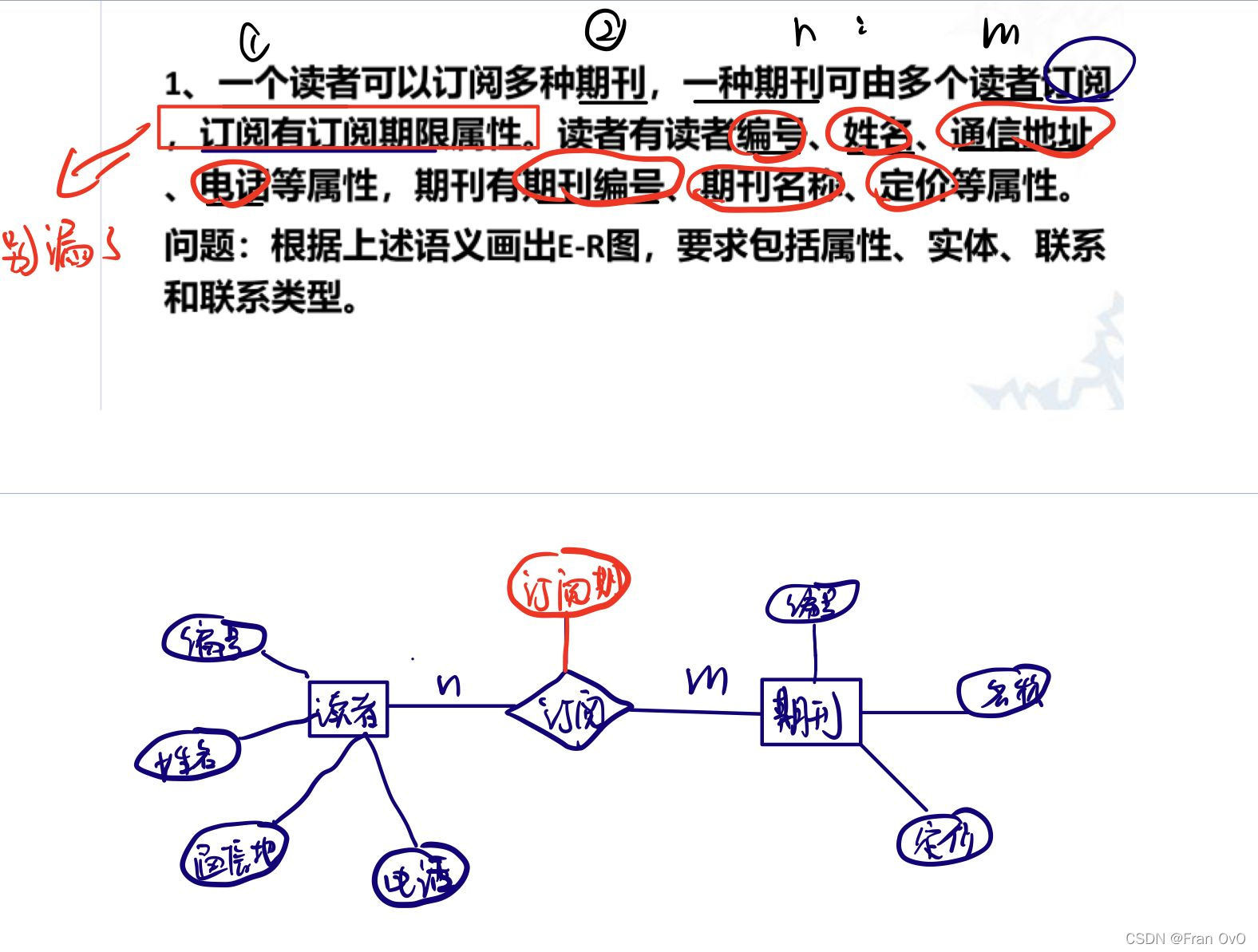 **
**
1.2.3.ER转逻辑结构模型
eg2:

步骤1:实体类型转换成关系模式:
系(系编号,系名,电话)
教师(教工号,姓名,性别,职称)
课程(课程号,课程名,学分)
步骤2:联系转化:
**(1) 1:1 **
** 在任一方加入主键**
系(系编号,系名,电话,教工号(系))
(2) 1:n
** 在n方加入1的主键 **
** **教师(教工号,姓名,性别,职称,系编号)
课程(课程号,课程名,学分,系编号)
(2) n:m
** **联系转化为关系模型——>m主键+n主键+自己属性
** *任教(教工号,课程号,教拆)*
所以m:n的关系会再产生一个关系:

1.3数据库系统的结构
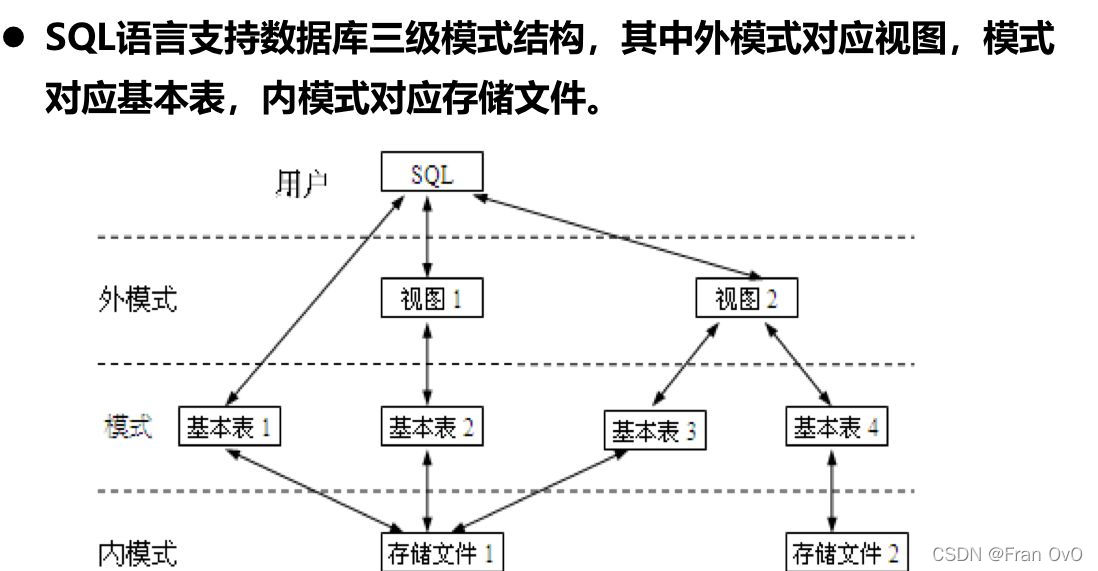
1.外模式:视图
2.模式:基本表
3.内模式:存储方式和数据的物理结构
二、关系数据库
1.基础芝士
1.1概念:
1, 候选码(key):若关系中的某一属性组的值能唯一标识一个元组(表中的一行),而其子集不能,则成为该属性组为候选码。
就像一张学生表student(id,name,age,sex,deptno),其中的id是可以唯一标识一个元组的,所以id是可以作为候选码的,既然id都可以做候选码了,那么id和name这两个属性的组合也可以标识一个元组,所以

** 一个或多个**
2,主码(primary key)
1.2关系的完整性
1,实体的完整性:属性A是基本关系的主属性,则A不能取空值(主键)
2,参照完整性:主和从(外键)
三,数据定义
1.数据类型
(就注意一下mysql的double在SQL sever是decimal)
2,建表--DDL
SQL sever
use mydb
--判断表存不存在
drop table if exists Department
--建表(部门,职级,员工)
create table Department--部门
(
--部门编号,主键,标识种子:自动增长identity(初始值,增长步长)
DepartmentId int primary key identity(1,1),
--部门名称
DepartmentName varchar(50) not null,
--部门描述
DepartmentRemark text
)
(mysql的auto_increment是表示种子是自增)
use mydb
drop table if exists Department;
create table Department
(
DepartmentId int primary key auto_increment,
DepartmentName varchar(50) not null,
DepartmentRemark text
);
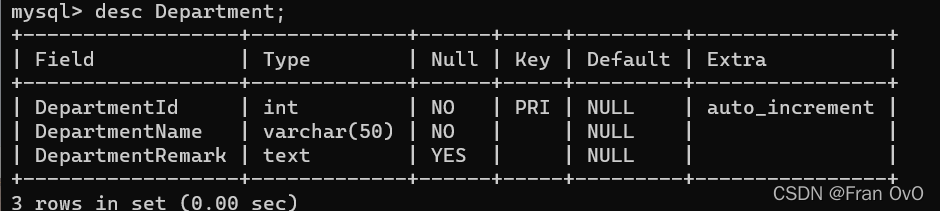
同样我们再建一张员工表PEOPLE和产品Product
--员工
--员工
create table PEOPLE
(
empno int not null identity,
empid int not null primary key,
ename varchar(10),
job varchar(9),
mgr int,
hiredate date default NULL,
sal decimal(7,2),
comm decimal(7,2),
deptno int foreign key references Department(DepartmentId)
)
--产品
create table Product
(
ID int identity(1,1) primary key not null,
prono varchar(50) unique not null,
typeid int foreign key references Department(DepartmentId),
price decimal(18,2) check (price between 100 and 180000) default(100.00) not null,
countpro int
)
3,修改表的结构--DDL
--(1)添加列
alter table Department add LOC varchar(50)
--(2)删除列
alter table Department drop column DepartmentRemark
--(3)修改列
alter table Department alter column DepartmentName varchar(30)
mysql改表好像是用modify,反正改表结构几乎不会出现OvO了解了解
mysql> alter table Department alter column loc varchar(20);
4,约束 constraint
主键约束(primary key),外键约束(foreign key),唯一约束(unique),check约束(check)mysql没有check约束,默认值约束(default)
确保数据的完整性 = 在创建表时给表中添加约束
完整性的分类:
- **实体完整性:**主键约束(primary key)唯一约束(unique)自动增长列(auto_increment,identity)
- **域完整性:**非空约束(not null)默认值约束(default)check约束
- **引用完整性:**外键约束(foreign key)
建表时:
create table Product
(
ID int identity(1,1) primary key not null,
prono varchar(50) unique not null,
typeid int foreign key references Department(DepartmentId),
price decimal(18,2) check (price between 100 and 180000) default(100.00) not null,
countpro int
)
建表后:
create table ProductT
(
ID int identity(1,1) not null,
prono varchar(50) not null,
typeid int ,
price decimal(18,2) not null,
)
--(4)添加约束,
--alter table 表名 add constraint 约束名 check()
--alter table 表名 add constraint 约束名 primary key(字段)
--alter table 表名 add constraint 约束名 unique(字段)
--alter table 表名 add constraint 约束名 default 默认值 for 字段
--alter table 表名 add constraint 约束名 foreign key(字段) references 表(字段)
-- 主表 从表
alter table ProductT add constraint CK_price check(price between 100 and 180000)
alter table ProductT add constraint PK_ID primary key(ID)
alter table ProductT add constraint UN_prono unique(prono)
alter table ProductT add constraint DF_price default 100.0 for price
alter table ProductT add constraint FK_typeid foreign key(typeid) references Department(DepartmentId)
5,插入,修改,删除数据--DML
--添加部门
insert into Department (DepartmentName, LOC ) values ( 'ACCOUNTING', 'NEW YORK');
insert into Department (DepartmentName, LOC ) values ('RESEARCH', 'DALLAS');
insert into Department (DepartmentName, LOC ) values ('SALES', 'CHICAGO');
insert into Department (DepartmentName, LOC ) values ('OPERATIONS', 'BOSTON');
--添加员工
insert into PEOPLE(empid ,ename, job, mgr, hiredate, sal, comm,deptno) values ( 7369, 'SMITH', 'CLERK', 7902, '1980-12-17', 800, NULL, 2);
insert into PEOPLE(empid ,ename, job, mgr, hiredate, sal, comm,deptno) values ( 7499, 'ALLEN', 'SALESMAN', 7698, '1981-02-20', 1600, 300, 3);
insert into PEOPLE(empid ,ename, job, mgr, hiredate, sal, comm,deptno) values ( 7521, 'WARD', 'SALESMAN', 7698, '1981-02-22', 1250, 500, 3);
insert into PEOPLE(empid , ename, job, mgr, hiredate, sal, comm,deptno) values( 7566, 'JONES', 'MANAGER', 7839, '1981-04-02', 2975, NULL, 2);
insert into PEOPLE(empid ,ename, job, mgr, hiredate, sal, comm,deptno) values( 7654, 'MARTIN', 'SALESMAN', 7698, '1981-09-28', 1250, 1400, 3);
insert into PEOPLE(empid ,ename, job, mgr, hiredate, sal, comm,deptno) values( 7698, 'BLAKE', 'MANAGER', 7839, '1981-05-01', 2850, NULL, 3);
insert into PEOPLE(empid ,ename, job, mgr, hiredate, sal, comm,deptno) values( 7782, 'CLARK', 'MANAGER', 7839, '1981-06-09', 2450, NULL, 1);
insert into PEOPLE(empid , ename, job, mgr, hiredate, sal, comm,deptno) values( 7788, 'SCOTT', 'ANALYST', 7566, '1987-04-19', 3000, NULL, 2);
insert into PEOPLE(empid , ename, job, mgr, hiredate, sal, comm,deptno) values( 7839, 'KING', 'PRESIDENT', NULL, '1981-11-17', 5000, NULL, 1);
insert into PEOPLE(empid ,ename, job, mgr, hiredate, sal, comm,deptno) values( 7844, 'TURNER', 'SALESMAN', 7698, '1981-09-08', 1500, 0, 3);
insert into PEOPLE(empid ,ename, job, mgr, hiredate, sal, comm,deptno) values( 7876, 'ADAMS', 'CLERK', 7788, '1987-05-23', 1100, NULL, 2);
insert into PEOPLE(empid ,ename, job, mgr, hiredate, sal, comm,deptno) values( 7900, 'JAMES', 'CLERK', 7698, '1981-12-03', 950, NULL, 3);
insert into PEOPLE(empid ,ename, job, mgr, hiredate, sal, comm,deptno) values( 7902, 'FORD', 'ANALYST', 7566, '1981-12-03', 3000, NULL, 2);
insert into PEOPLE(empid ,ename, job, mgr, hiredate, sal, comm,deptno) values ( 7934, 'MILLER', 'CLERK', 7782, '1982-01-23', 1300, NULL, 1);
--修改
update PEOPLE set sal = 1000.00,deptno =2 where empno=12
--部门3的加薪300
update PEOPLE set sal = sal+300 where deptno=3
--删除
delete from PEOPLE where empno=15
注意:delete from删除的只是15的数据,15标识并没有消失,呃,就是说再增加一条语句,他的empno员工编号不是15了,而是16

还有updata 和delete 要加where条件,不然会裂开的
当然,你还可以用truncate table__ 清空表的数据,还有用drop table__ 直接干死一张表
四,查询
1,简单查询
select 字段 as 新的名字 from 表
select 字段*(+,-,/,运算)2 from 表
select * from 表 --查询全部
select distinct(字段)--去除重复值的查询

2,条件查询
语法:select 字段1,字段2……from 表 where 条件
2.1常用运算符:……
注意:如果and 和or 同时出现有优先级的问题
eg.查询工资大于2500,并且部门编号为1或者2的员工
select * from PEOPLE where sal>2500 and (deptno=2 or deptno =1)
and的优先级高
2.2模糊查询
like 有四种匹配模式:
1,% 0个或者多个
--1,中间含有o
select * from PEOPLE where ename like'%o%'
--2,开头是S
select * from PEOPLE where ename like'S%'
--3,结尾是N
select * from PEOPLE where ename like'%N'
2,_匹配单个字符
--匹配长度一致
select * from PEOPLE where ename like'_____'
select * from PEOPLE where ename like'__R_'
3,[]范围匹配
--匹配[]里面有的
--5个字且第三是在a到p之间
select * from PEOPLE where ename like'__[a-p]__'
4,[^]不在这个范围
与上面那个相反
3,数据处理函数(单行处理函数)
一个输入一个输出
常见:
1,upper(列字符串):将字符串的内容全部大写
2,lower(列字符串):将字符串的内容全部小写
3,rand ():一百以内的随机数
4,流程控制
case
when……then……
when……then……
else……
end
select *,
case
when sal between 0 and 1000 then '低层'
when sal between 1000 and 3000 then '中层'
else '高层'
end as '员工等级'
from PEOPLE

当然,还可以
if
begin
……
end
else
begin
……
end
4,排序order by
指定排序:desc(降序),asc(升序)
select * from PEOPLE order by sal desc
select * from PEOPLE order by sal asc
--多字段排序,按工资升序,按部门编号降序
select * from PEOPLE order by sal asc,deptno desc

5,多行处理函数(聚合函数或分组函数)
count 计数 sum 求和 avg平均数 max最大值 min最小值
注意:分组函数要先分组才能使用
1,count(*)和count(字段)的区别
select count(*) from PEOPLE--统计表的总行数
select count(comm) from PEOPLE--该字段不为null的个数

6,分组查询 group by
1,执行顺序
像select......from ......group by ......
是先进行分组再查询,就是说先group by 再select
但是如果要进行分组还要条件的查询,他们的执行顺序就不太寻常
select ......from ......
where......
group by .....
order by......
这样的命令,执行顺序是:
from—>where—>group by—>select—>order by
条件是在分组前执
eg1:找出每个岗位的工资和
思路:按照工作岗位分组,然后对工资求和
select job,sum(sal)as'各单位工资和' from PEOPLE group by job
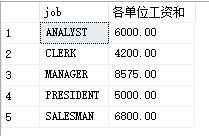
以上语句是先从PEOPLE中按job进行分组(ANALYST,CLERK......)再进行sum
然后再select
eg2:找出 每个部门deptno 不同 工作岗位job 的最高薪资
(不同部门的不同岗位)——>两个字段联合分组
思路:先对每个部门和工作进行分组,再取最大值
select job,deptno,max(sal)as'各部门各工种的最高薪资' from PEOPLE group by job,deptno
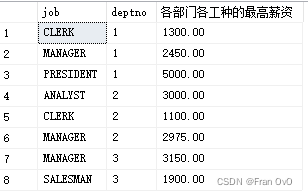
eg3:找出 1980-12-20之后入职 每个部门deptno 不同 工作岗位job 的最高薪资
先where出1980-12-12日之后数据
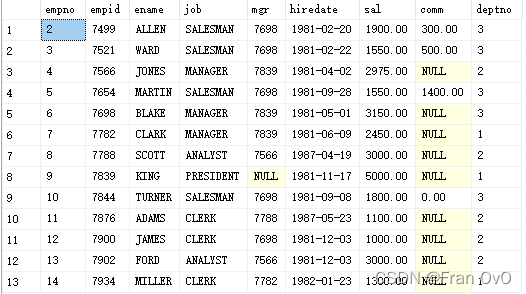
再对每个部门和工作进行分组,再取最大值
select job,deptno,max(sal)as'各部门各工种的最高薪资' from PEOPLE where hiredate>1980-12-20 group by job,deptno
2,HAVING关键字
如果想要找到每个部门的平均工资且平均工资大于2000的部门,我们可能会想到:
select deptno from PEOPLE where avg(sal)>2000 group by deptno;
但是avg是分组函数,在分组之后,where是再group by前,所以不能这样写
要是想在分组后加条件,就用having
select deptno,avg(sal)as'平均工资' from PEOPLE group by deptno having avg(sal)>2000
from—>where—>group by—>having——>select—>order by
之前说的count(*),在分组之后,表示的是分完组的表
select deptno,avg(sal)as'平均工资' from PEOPLE group by deptno having count(*)>=4
代表的是有查询四条以上的部门的平均工资
7,连接查询(多表查询)
分类:内连接{等值查询,非等值查询,自连接},外连接{左外连接,右外连接,完全外连接}
1,笛卡儿积现象
两个集合相乘的
两张表进行连接查询,没有任何条件限制的时候,最终查询结果条数是两张表条数的乘积
select ename ,DepartmentId from Department,PEOPLE
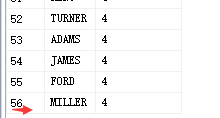
14*4=56条
避免笛卡儿积现象就加条件
select ename ,DepartmentName from Department d,PEOPLE e where d.DepartmentId=e.deptno

2,内连接
2.1等值连接
前面那句就是等值连接
select
e.ename ,d.DepartmentName
from
Department d,PEOPLE e
where
d.DepartmentId=e.deptno
这个语法是sql92的语法,为了增强表的运算能力,sql99语法便引入了join on
但是连接表不一定要用join

where虽然是92语法,但是where也可以实现表连接
select
e.ename ,d.DepartmentName
from
Department d
inner join --inner表示内连接,可以忽略不写
PEOPLE e
on
d.DepartmentId=e.deptno
目的就是让where可以去干其他事
2.2非等值连接
select
e.ename ,d.DepartmentName,e.sal
from
Department d
join --inner表示内连接,可以忽略不写
PEOPLE e
on
e.sal between 1000 and 1200
2.3自连接
就是自己和自己连接
eg:查询员工的上级领导,要求显示员工名和对应的领导名
select a.ename as'员工名',b.ename as'领导名'
from
PEOPLE a
join
PEOPLE b
on
a.mgr=b.empid
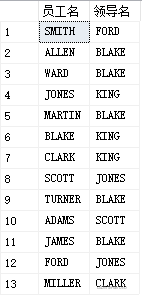
只有13行,因为king没有领导
3,外连接
1,右外连接(右边看成主表)
右表所有行right join on
select a.ename as'员工名',b.ename as'领导名'
from
PEOPLE a
right join
PEOPLE b
on
a.mgr=b.empid
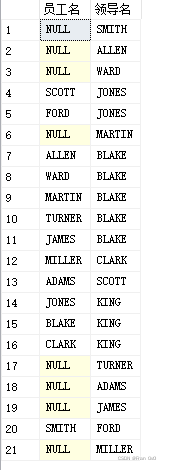
2,左外连接(左边看成主表)
左表所有行left join on
select a.ename as'员工名',b.ename as'领导名'
from
PEOPLE a
left join
PEOPLE b
on
a.mgr=b.empid
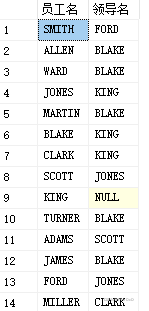
3,全外连接(两表不管是否符合关系,都要显示)
左右两表所有行 full join on
select a.ename as'员工名',b.ename as'领导名'
from
PEOPLE a
full join
PEOPLE b
on
a.mgr=b.empid
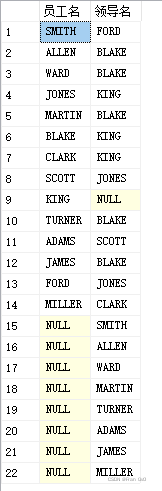
没有员工的领导就是最低层的员工,没有领导的员工就是最高层
8,嵌套查询(子查询)
select语句中嵌套select语句,被嵌套的select语句叫做子查询(子查询不能包含order by)
子查询可出现在三个位置
1,select后面
2,from后面
3,where后面
select...(select)
from...(select)
where(select)
1,select后面的子查询
eg:找出每个员工的部门名称,显示员工名,部门名:
select
ename,
(select d.DepartmentName from Department d where e.deptno=d.DepartmentId)
as dname
from PEOPLE e
可以看见是外部的PEOPLE e和子查询中的Department进行连接
2,from后面的子查询
from后面的子查询可以将子查询的结果看成一张表(相当于视图)
eg:找出每个岗位的平均工资的薪资等级
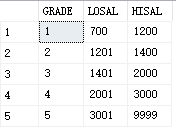
五个等级
登记表:
CREATE TABLE salgrade
(
GRADE INT,
LOSAL INT,
HISAL INT
);
INSERT INTO SALGRADE ( GRADE, LOSAL, HISAL ) VALUES (
1, 700, 1200);
INSERT INTO SALGRADE ( GRADE, LOSAL, HISAL ) VALUES (
2, 1201, 1400);
INSERT INTO SALGRADE ( GRADE, LOSAL, HISAL ) VALUES (
3, 1401, 2000);
INSERT INTO SALGRADE ( GRADE, LOSAL, HISAL ) VALUES (
4, 2001, 3000);
INSERT INTO SALGRADE ( GRADE, LOSAL, HISAL ) VALUES (
5, 3001, 9999);
第一步:找到每个岗位的平均工资
select job,avg(sal)as '平均工资'from PEOPLE group by job
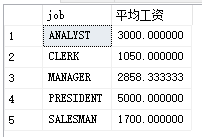
第二部:看成一张表进行,与登记表进行连接
select t.job,s.GRADE
from
(select job,avg(sal)as '平均工资'from PEOPLE group by job) t
join
SALGRADE s
on
t.平均工资 between s.LOSAL and s.HISAL
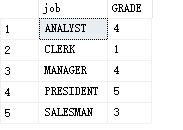
3,where 后面的子查询
回了一个集合,可以通过与这个集合的比较来确定另一个查询集合
eg:查找比平均工资高的员工
select ename from PEOPLE where sal>(select avg(sal)from PEOPLE)
1,in子查询(找一个范围)
in 和not in 只能返回一列数据
eg:查找不在New York上班的员工
--列出部门在new york的员工
--1,子查询
select ename from PEOPLE
where
deptno not in
(select DepartmentId from Department where loc='new york')
--2,连接查询
select e.ename from
PEOPLE e
join
Department d
on
e.deptno=d.DepartmentId
where d.loc!='new york'
2,比较子查询
all 所有
any 是否含有
eg:查找New York员工比所有CHICAGO员工工资都少的员工
思路:先用in子查询查出所有NEWYORK的员工,再用连接查询查CHICAGO员工工资(返回一列CHICAGO员工工资表),最后查找New York员工比所有CHICAGO员工工资都少的员工
--查找new york比所有CHICAGO员工工资都少的员工
select ename,sal from PEOPLE
where
deptno in (select DepartmentId from Department where loc='new york') and
sal < all(select e.sal from PEOPLE e join
Department d on e.deptno=d.DepartmentId where d.loc='CHICAGO')
--查找new york是否含有比CHICAGO员工工资少的员工
select ename,sal from PEOPLE
where
deptno in (select DepartmentId from Department where loc='new york') and
sal < any(select e.sal from PEOPLE e join
Department d on e.deptno=d.DepartmentId where d.loc='CHICAGO')
当然也可以直接连接,然后where
3,exists子查询
返回TRUE或者FALSE,如果子查询结果存在返回true,不存在就为false
eg:查询是否存在工资等级为5的员工
思路:父表的sal进入子查询,与salgrade 进行匹配,直到出现等级为5的返回true
--查询是否存在工资等级等于5的员工
select ename,sal from PEOPLE e where exists( --外部父表为e
select * from SALGRADE s where
(e.sal between s.LOSAL and s.HISAL)
and (s.GRADE=5)
)
可以看见exists的子查询是将父表的字段一个一个放入子查询进行查询
9,其他子句
1,into
查询的结果加入一张表中(表复制)
select 字段 into 新表 from 原表 where 条件
2,union——>并
连接表,多张表连接在一起
3,except和intersect
1,EXCEPT是指在第一个集合中存在,但是不存在于第二个集合中的数据。——补集
eg:查找工作为CLERK但工资水平小于2的员工
--查找工作为CLERK但工资水平小于2的
select ename,sal from PEOPLE where job='CLERK'
except
select e.ename,e.sal from PEOPLE e join salgrade s on e.sal between s.LOSAL and s.HISAL where s.GRADE>=2
2,INTERSECT是指在两个集合中都存在的数据。——>交集
eg:查找工作为CLERK且工资水平为2的员工
--查找工作为CLERK且工资水平为2的员工
select ename,sal from PEOPLE where job='CLERK'
intersect
select e.ename,e.sal from PEOPLE e join salgrade s on e.sal between s.LOSAL and s.HISAL where s.GRADE=2
eg:
4,with as
这东西就真像视图了,select出来的的结果看成一张表,可在之后查询直接使用
10,视图view
外模式,虚拟表,站在不同的角度看待数据
注意:视图的增删改查会导致原表数据被改动
作用:简化sql语言
创建视图
create view 视图名
as
select...
我们创建一张员工领导视图
create view People_view
as
select a.ename as '员工名',b.ename as '领导名'from
PEOPLE a
join
PEOPLE b
on a.mgr =b.empid;
drop view People_view
然后删除视图

可以从别的视图创建新的视图
11,游标
用来查询数据的指针
12,分页top
top表示查询前几行
这里可以用top查询前几行为页
--查询一页
select top 5 * from PEOPLE
--查询第二页(除了前五行以外)
select top 5 * from PEOPLE where empno not in(select top 5 empno from PEOPLE)
--查询前50%的数据
select top 50 percent * from PEOPLE
五,T-SQL
1,SQL语言分类
1,DQL数据查询语言(select)
2, DML数据操作语言(对 **表** 数据 增 insert 删 delete 改 update)
3, DDL数据定义语言 (操作**表结构 **增 create 删 drop 改 alter)
4, TCL 事务控制语句 事务提交commit **事务回滚rollback**
5,DCL 数据控制语言(权限)
2,数据类型的使用方法
3,变量
1,局部变量:以@开头
声明declare @变量 数据类型
**赋值 1,set ****@变量=**
** 2,select @变量= ——一般用于表查询出的数据赋给变量**
表达式返回多个值时,用SET将会出错,而SELECT将取最后一个值
declare @a decimal(20,2)
select @a= sal from PEOPLE
print @a

tip:mysql的如果没在begin ...end中是不能使用的,可以直接set @变量
2,全局变量:以@@开头,由系统进行定义和维护
4,运算符
5,流程控制
1,选择分支结构
if ...
begin
...
end
else
begin
...
end
--或者
case
when...then...
when...then...
when...then...
else
end
我们给员工排个等级
select 员工名,job,领导名,sal,
case
when sal between 800 and 1000 then '底层'
when sal between 100 and 3000 then '中层'
else '高层'
end 员工等级
from People_view;
2,循环语句
这和C一样
while 条件
begin
...
end
六,索引
提高查询效率
1,分类
索引按存储类型分类:聚集索引(clustered)和非聚集索引(nonclustered)
区别:聚集索引可以理解为按26字母的顺序排序的字典,找a开头的,就去a那一块里面找
非聚集索引可以理解为偏旁查找,以这个字的特征作为键值给出地址,例如‘傅,但,保’ 存储再以单人旁的那块地方,你找到 ’傅‘ 会给你个页面,就是'傅'的位置,同理'但'和'保'一样,但他们并不在傅的正上方或者正下方,这就是非聚集索
一个表中最多一个聚集索引,但可以有一个或者多个非聚集索引——>聚集索引就是主键
2,创建索引
create (unique)clustered(nonclustered)index 索引名 on 表(字段)
create unique nonclustered index empno_clustered on PEOPLE(empno)
也可以多字段进行复合索引

七,存储过程和触发器
1,存储过程
存储过程:一种为了完成特定功能的一个或者一组sql语句集合
1,1存储过程分类:
1,系统存储过程(名字都以sp_为前缀)
2,自定义存储过程:用户自己创建,可导入参数,也可以有返回值
1,2存储过程芝士:
与函数的区别:可以可以被外部程序调用,如java,c++
执行:exec/execute,(mysql用call) 存储过程名 参数1,参数2
1,3创建存储过程:
1,简单设计存储过程
create proc 存储过程名字
参数列表
as
begin
...
end
go
exec 存储过程名字 参数1,参数2--不要用括号
--查询是否存在工资等级等于5的员工
select ename,sal from PEOPLE e where exists( --外部父表为e
select * from SALGRADE s where
(e.sal between s.LOSAL and s.HISAL)
and (s.GRADE=5)
)
--创建以上的存储过程
create proc proc_Findsal
as
begin
select ename,sal from PEOPLE e where exists
( --外部父表为e
select * from SALGRADE s where
(e.sal between s.LOSAL and s.HISAL)
and (s.GRADE=5)
)
end
go
exec proc_Findsal
2,创建带参数的存储过程:
eg:创建一个添加产品的存储过程
select * from ProductT
drop proc proc_insert_pro
create proc proc_insert_pro
@prono varchar(50),@typeid int,@price decimal(18,2)
as
insert into ProductT(prono,typeid,price) values(@prono ,@typeid ,@price)
select * from ProductT
go
exec proc_insert_pro 'shirt',1,100.00
3,使用通配符参数的存储过程:
eg:查找领导名字中有'A'的员工
create proc proc_like
@name_like varchar(30)= '%a%'--参数默认值
as
select a.JOB,a.empid,a.SAL,a.ename as '员工名',b.ename as '领导名'from
PEOPLE a
join
PEOPLE b
on a.mgr =b.empid
where b.ename like @name_like
go
exec proc_like
exec proc_like '%c%'
参数默认值,这个和c和python函数的参数默认值一样,如果调用这个存储过程没引入参数,内部的参数以默认值调用

4,带有返回值的(只能返回整数,不能字符串。。。啥的)
create proc proc_return
@bool int =0,
@check varchar(4)='no'
as
if(@bool=1 and @check='yes')
begin
select top 50 percent * from PEOPLE
return 1
end
else if(@bool=0)
return -1
else
return -1
go
declare @a int,@b int
exec @a= proc_return 1,'yes'
exec @b= proc_return
print @a
print @b

5,使用OUTPUT游标参数——后面补
2,触发器
因为发生了什么事情,而自动发生什么事情,就像有人打了你一巴掌,你在那一瞬间又打了回去了

触发表是一种特殊的存储过程,不同的是他不用exec来调用,而是通过事件的触发自动执行
这个事件就是对表的操作:改结构DDL,改数据DML
2.1触发器的分类
DDL触发器,DML触发器
一般的DDL语句出现的可能都很小了,DDL触发器出现的可能就更小了
所以我们研究DML触发器
DML触发器的两种分类:
1,after触发器(事后触发器):就是别人打了你一巴掌之后你打了回来——>操作都成功后执行触发器
2,instead of 触发器(事前触发器):别人要打你一巴掌被你提前预判了而且你还提前打了一巴掌给他——>不执行原来的增删改,而是执行触发器
2.2触发器的两张虚拟表
inserted 插入表 delete 删除表
对表的操作inserted
deleted
insert存放插入数据无update存放更新数据存放更新数据delete无存放被删除的数据
所以触发器也是一个特殊的事务,可以进行事务回滚(rollback transaction)
2.3 after触发器
create trigger 触发器名
on 表名
after(for) 操作(insert,update,delete)
as
...T-SQL语句
go
1,after insert
eg添加员工信息如果员工部门编号在Department表里面查询不到,则自动添加新部门
--添加员工信息如果员工部门编号在Department表里面查询不到,则自动添加新部门
create trigger trigger_insert_new
on PEOPLE --因为是添加员工到员工表
for insert
as
if not exists(select* from Department where DepartmentId=(select deptno from inserted))
insert into Department(DepartmentName,loc) values('新部门','newloc')
go
--测试触发器
alter table PEOPLE drop constraint FK__PEOPLE__deptno__76619304--先把这个外键约束删了,不然加不进去
insert into PEOPLE(empid,ename,job,sal,deptno) values(9999,'fran','boss',99999.99,5)
delete from PEOPLE where ename='fran'
select * from Department
select * from PEOPLE
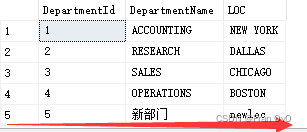

可以看见添加了两条数据
2,after update
eg1:修改部门之后,员工表的部门编号也同步更新
因为原本的部门表的deptno是标识列不能修改,所以我新建了一张部门表
CREATE TABLE DEPT
(
id int not null primary key identity,
DEPTNO int not null ,
DNAME VARCHAR(14) ,
LOC VARCHAR(13),
);
INSERT INTO DEPT ( DEPTNO, DNAME, LOC ) VALUES (
1, 'ACCOUNTING', 'NEW YORK');
INSERT INTO DEPT ( DEPTNO, DNAME, LOC ) VALUES (
2, 'RESEARCH', 'DALLAS');
INSERT INTO DEPT ( DEPTNO, DNAME, LOC ) VALUES (
3, 'SALES', 'CHICAGO');
INSERT INTO DEPT ( DEPTNO, DNAME, LOC ) VALUES (
4, 'OPERATIONS', 'BOSTON');
select * from dept
--修改部门之后,员工表的部门编号也同步更新
create trigger triggrr_update
on dept
for update
as
if update(DEPTNO)
update PEOPLE set deptno=(select deptno from inserted)--新编号
where deptno =(select deptno from deleted)--老编号
go
update DEPT set DEPTNO =2 where DEPTNO=1

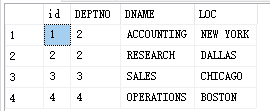
这里更新的新编号要从inserted表里面取,旧编号要从deleted表里面取
update()函数:测试字段是否update或者insert操作,有返回true,无则false
eg:如果修改部门的loc则取消修改操作
--如果修改部门的loc则取消修改操作
create trigger triggrr_update_rollback
on dept
for update
as
if update(loc)
begin
print '违背数据的一致性'
rollback transaction
end
go
update DEPT set loc ='loctemp' where loc='NEW YORK'
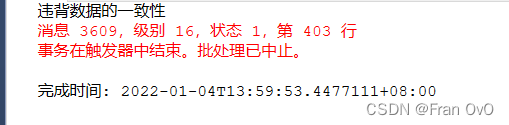
**3,after delete **
eg--删除一个部门之后,删掉部门里的员工
--删除一个部门之后,删掉部门里的员工
create trigger triggrr_delete
on dept
for delete
as
delete from PEOPLE where deptno =(select deptno from deleted)
go
delete from DEPT where DEPTNO=1
注意,delete不能用update()判断是否更改
2.4instead of 触发器
操作前触发
eg删除一个部门前判断是否部门有人,如果没人之间删除,如果有人则不删除
--删除一个部门前判断是否部门有人,如果没人之间删除,如果有人则不删除
alter trigger triggrr_delete_instead
on dept
instead of delete
as
if not exists(select * from PEOPLE where deptno=(select deptno from deleted))
begin
delete from Dept where deptno=(select deptno from deleted)
print '删除成功'
end
else
print '不能删除'
go
delete from DEPT where DEPTNO=4

结语:
写这个刚好复习一遍期末考,其实还要挺多没写的,也是刚好用几张表写了挺多知识点
呃。。。
大部分是SQL sever上写的,后面有时间一定加上mysql写的
版权归原作者 Fran OvO 所有, 如有侵权,请联系我们删除。