
文章目录
前言
本文主要是使用 Java 语言中 spring-kafka 依赖 对 Kafka 进行使用。
使用以下依赖对 Kafka 进行操作:
<!-- https://mvnrepository.com/artifact/org.springframework.kafka/spring-kafka --><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId><version>2.8.11</version></dependency>
需要更改版本的话,可以前往:Maven 仓库
创建项目,先创建一个简单的 Maven 项目,删除无用的包、类之后,使用其作为一个父级项目。
以下内容如果在项目启动时报这个错:
org.yaml.snakeyaml.error.YAMLException: java.nio.charset.MalformedInputException: Input length = 1
把注释删除就可以了。
写法一:发送的消息对象是字符串
1 创建项目
随后创建SpringBoot模块。选择 Kafka 组件
随后调整该项目的POM依赖为:
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency></dependencies><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.8.1</version><configuration><source>11</source><target>11</target><encoding>UTF-8</encoding></configuration></plugin><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build>
注意这一步同时需要将Java版本、Maven版本都调整好。我这里目前使用的是Java11。
2 项目结构
我们先看
spring-kafka-demo
模块的内容
3 application.yml 配置文件
主要指定集群信息、生产者信息、消费者信息。尤其重要的是序列化方式。
server:# 优雅停机shutdown: graceful
spring:kafka:# kafka集群信息,多个用逗号间隔bootstrap-servers: localhost:9092# 生产者producer:# 重试次数,设置大于0的值,则客户端会将发送失败的记录重新发送retries:3#批量处理大小,16Kbatch-size:16384#缓冲存储大,32Mbuffer-memory:33554432acks:1# 指定消息key和消息体的编码方式:字符串序列化key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# 消费者consumer:# 消费者组group-id: TestGroup
# 是否自动提交enable-auto-commit:false# 消费偏移配置# none:如果没有为消费者找到先前的offset的值,即没有自动维护偏移量,也没有手动维护偏移量,则抛出异常# earliest:在各分区下有提交的offset时:从offset处开始消费;在各分区下无提交的offset时:从头开始消费# latest:在各分区下有提交的offset时:从offset处开始消费;在各分区下无提交的offset时:从最新的数据开始消费auto-offset-reset: latest
# 指定消息key和消息体的解码方式:字符串反序列化key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 监听listener:# record:当每一条记录被消费者监听器(ListenerConsumer)处理之后提交# batch:当每一批poll()的数据被ListenerConsumer处理之后提交# time:当每一批poll()的数据被ListenerConsumer处理之后,距离上次提交时间大于TIME时提交# count:当每一批poll()的数据被ListenerConsumer处理之后,被处理record数量大于等于COUNT时提交# count_time:TIME或COUNT中有一个条件满足时提交# manual:当每一批poll()的数据被ListenerConsumer处理之后, 手动调用Acknowledgment.acknowledge()后提交# manual_immediate:手动调用Acknowledgment.acknowledge()后立即提交,一般推荐使用这种ack-mode: manual_immediate
4 生产者 KafkaProducerComponent
packageorg.feng.kafka.sender;importlombok.extern.slf4j.Slf4j;importorg.springframework.kafka.core.KafkaTemplate;importorg.springframework.kafka.support.SendResult;importorg.springframework.lang.NonNull;importorg.springframework.stereotype.Component;importorg.springframework.util.concurrent.ListenableFutureCallback;importjavax.annotation.Resource;/**
* Kafka消息生产者组件
*
* @version v1.0
* @author: fengjinsong
* @date: 2023年03月16日 23时26分
*/@Slf4j@ComponentpublicclassKafkaProducerComponent{@ResourceprivateKafkaTemplate<String,String> kafkaTemplate;/**
* 预先在 Kafka 中创建好的 topic
*/publicstaticfinalString TOPIC ="testTopic";publicvoidsend(String topic,String data){
kafkaTemplate.send(topic, data)// 回调.addCallback(newListenableFutureCallback<>(){@OverridepublicvoidonFailure(@NonNullThrowable throwable){
log.error("主题[{}]发送消息[{}]失败", topic, data, throwable);}@OverridepublicvoidonSuccess(SendResult<String,String> result){
log.info("主题[{}]发送消息[{}]成功", topic, data);}});}}
5 消费者 KafkaConsumerComponent
packageorg.feng.kafka.receiver;importlombok.extern.slf4j.Slf4j;importorg.feng.kafka.sender.KafkaProducerComponent;importorg.springframework.kafka.annotation.KafkaListener;importorg.springframework.stereotype.Component;/**
* 监听消息:消费端
*
* @version v1.0
* @author: fengjinsong
* @date: 2023年03月17日 19时54分
*/@Slf4j@ComponentpublicclassKafkaConsumerComponent{@KafkaListener(topics =KafkaProducerComponent.TOPIC)publicvoidconsumerTestTopic(String data){
log.info("消费者监听到数据:{}", data);}}
6 控制器(GET请求发送消息)
packageorg.feng.kafka.controller;importlombok.extern.slf4j.Slf4j;importorg.feng.kafka.sender.KafkaProducerComponent;importorg.springframework.web.bind.annotation.GetMapping;importorg.springframework.web.bind.annotation.PathVariable;importorg.springframework.web.bind.annotation.RestController;importjavax.annotation.Resource;/**
* 发送消息控制器
*
* @version v1.0
* @author: fengjinsong
* @date: 2023年03月17日 19时56分
*/@Slf4j@RestControllerpublicclassSendMessageController{@ResourceprivateKafkaProducerComponent kafkaProducerComponent;@GetMapping("/send/{data}")publicStringsend(@PathVariable("data")String data){
log.info("即将把数据【{}】发送到消息队列", data);
kafkaProducerComponent.send(KafkaProducerComponent.TOPIC, data);return"send ok";}}
7 启动类
packageorg.feng.kafka;importorg.springframework.boot.SpringApplication;importorg.springframework.boot.autoconfigure.SpringBootApplication;@SpringBootApplicationpublicclassSpringKafkaDemoApplication{publicstaticvoidmain(String[] args){SpringApplication.run(SpringKafkaDemoApplication.class, args);}}
8 测试效果
我这边已经启动了 Kafka ,随后在本地再启动本项目,待项目启动后,使用 GET 请求给 Kafka 中扔消息。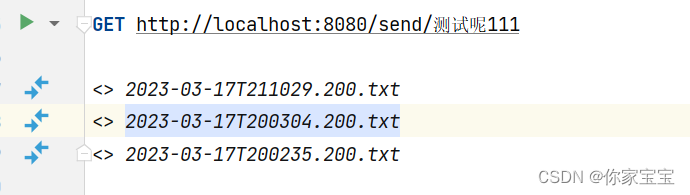
使用以上的链接触发。
可以依次观察到日志记录:
即将把数据【测试呢111】发送到消息队列
消费者监听到数据:测试呢111
主题[testTopic]发送消息[测试呢111]成功
写法二:发送复杂消息对象
其实就是自定义一个对象,直接扔到消息队列里。然后再使用监听器监听到,并作出处理。
核心改变的地方是消息Value 的序列化方式、反序列化方式,更改为:
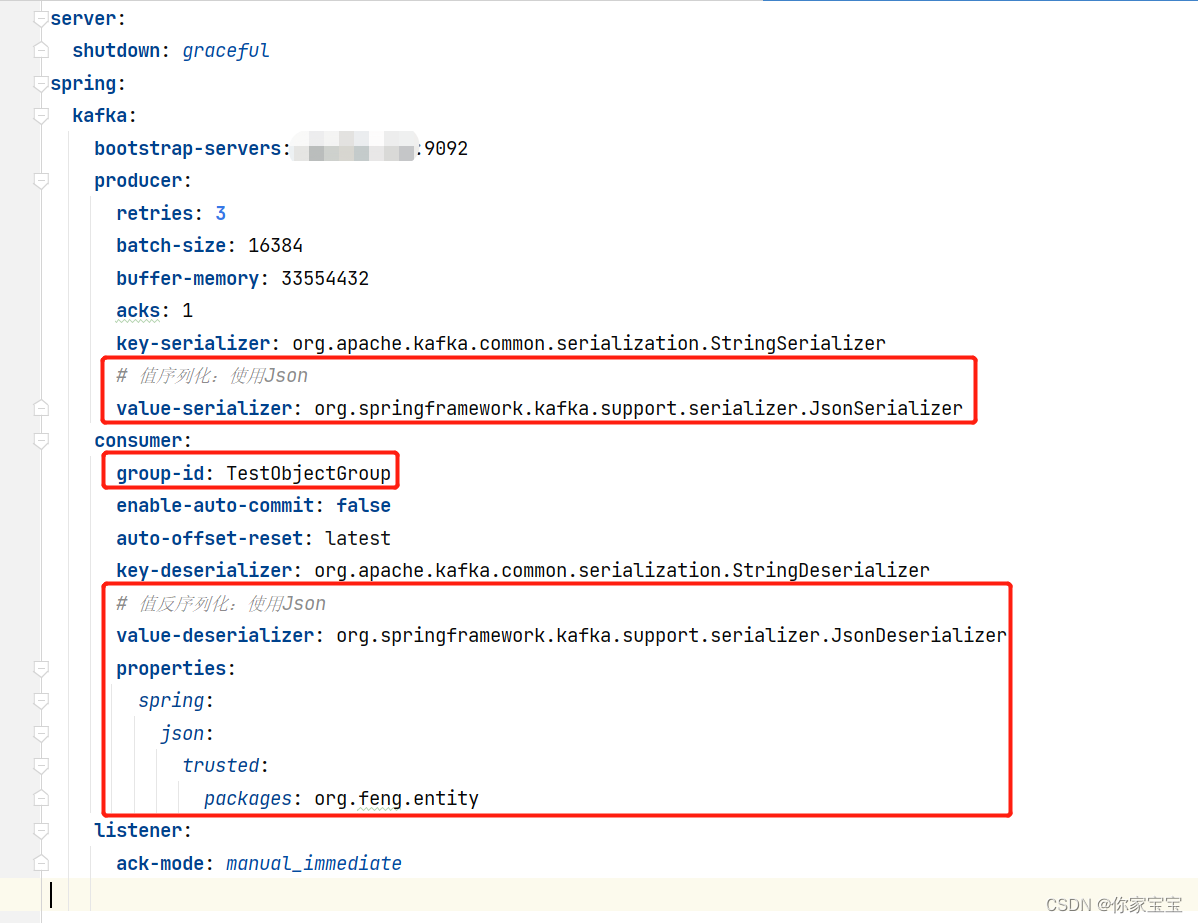
修改了 group-id、值的序列化、反序列化,以及增加了属性“信任的包”。
你想把哪个类的对象放消息队列,就得在这个包下进行定义这个类。
1 创建项目
项目的版本和写法一保持一致。
包括 POM 文件也是一致的。
2 项目结构
3 application.yml 配置文件
PS:这里将注释几乎全部去掉了
server:shutdown: graceful
spring:kafka:bootstrap-servers: localhost:9092producer:retries:3batch-size:16384buffer-memory:33554432acks:1key-serializer: org.apache.kafka.common.serialization.StringSerializer
# 值序列化:使用Jsonvalue-serializer: org.springframework.kafka.support.serializer.JsonSerializer
consumer:group-id: TestObjectGroup
enable-auto-commit:falseauto-offset-reset: latest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 值反序列化:使用Jsonvalue-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
# 信任的包properties:spring:json:trusted:packages: org.feng.entity
listener:ack-mode: manual_immediate
4 信任的包中定义的实体类
4.1 kafka 消息接口规则定义
packageorg.feng.entity;/**
* kafka 消息
*
* @version v1.0
* @author: fengjinsong
* @date: 2023年03月17日 20时16分
*/publicinterfaceKafkaMessage{}
4.2 测试实体定义
实体实现了
KafkaMessage
规则。
并定义了简单的属性值。
packageorg.feng.entity;importlombok.Data;importjava.time.LocalDateTime;importjava.util.Locale;importjava.util.UUID;/**
* 测试kafka消息对象
*
* @version v1.0
* @author: fengjinsong
* @date: 2023年03月17日 20时18分
*/@DatapublicclassTestKafkaMessageimplementsKafkaMessage{privateLocalDateTime time =LocalDateTime.now();privateString message;privateString business ="test";privateString messageId = UUID.randomUUID().toString().toLowerCase(Locale.ROOT).replaceAll("-","");}
5 生产者 KafkaObjectSerializerProducerComponent
packageorg.feng.producer;importlombok.NonNull;importlombok.extern.slf4j.Slf4j;importorg.feng.entity.KafkaMessage;importorg.springframework.kafka.core.KafkaTemplate;importorg.springframework.kafka.support.SendResult;importorg.springframework.stereotype.Component;importorg.springframework.util.concurrent.ListenableFutureCallback;importjavax.annotation.Resource;/**
* 生产者
*
* @version v1.0
* @author: fengjinsong
* @date: 2023年03月17日 20时21分
*/@Slf4j@ComponentpublicclassKafkaObjectSerializerProducerComponent{/**
* 预先在 Kafka 中创建好的 topic
*/publicstaticfinalString TOPIC ="testObjectTopic";@ResourceprivateKafkaTemplate<String,?superKafkaMessage> kafkaTemplate;publicvoidsendTest(String topic,KafkaMessage kafkaMessage){
kafkaTemplate.send(topic, kafkaMessage)// 回调.addCallback(newListenableFutureCallback<SendResult<String,?superKafkaMessage>>(){@OverridepublicvoidonFailure(@NonNullThrowable throwable){
log.error("主题[{}]发送消息[{}]失败", topic, kafkaMessage, throwable);}@OverridepublicvoidonSuccess(SendResult<String,?superKafkaMessage> result){
log.info("主题[{}]发送消息[{}]成功,发送结果:{}", topic, kafkaMessage, result);}});}}
6 消费者 KafkaObjectSerializerConsumerComponent
packageorg.feng.consumer;importlombok.extern.slf4j.Slf4j;importorg.feng.entity.TestKafkaMessage;importorg.feng.producer.KafkaObjectSerializerProducerComponent;importorg.springframework.kafka.annotation.KafkaListener;importorg.springframework.stereotype.Component;/**
* 消费者
*
* @version v1.0
* @author: fengjinsong
* @date: 2023年03月17日 20时30分
*/@Component@Slf4jpublicclassKafkaObjectSerializerConsumerComponent{@KafkaListener(topics =KafkaObjectSerializerProducerComponent.TOPIC)publicvoidconsumerTestTopic(TestKafkaMessage data){
log.info("消费者监听到数据:{}", data);}}
7 控制器(GET请求发送消息)
重点在于,消息内容是自定义的
TestKafkaMessage
实例。
packageorg.feng.controller;importlombok.extern.slf4j.Slf4j;importorg.feng.entity.TestKafkaMessage;importorg.feng.producer.KafkaObjectSerializerProducerComponent;importorg.springframework.web.bind.annotation.GetMapping;importorg.springframework.web.bind.annotation.RequestBody;importorg.springframework.web.bind.annotation.RestController;importjavax.annotation.Resource;/**
* 发送消息控制器
*
* @version v1.0
* @author: fengjinsong
* @date: 2023年03月17日 19时56分
*/@Slf4j@RestControllerpublicclassSendMessageController{@ResourceprivateKafkaObjectSerializerProducerComponent kafkaObjectSerializerProducerComponent;@GetMapping("/send")publicStringsend(@RequestBodyTestKafkaMessage data){
log.info("即将把数据【{}】发送到消息队列", data);
kafkaObjectSerializerProducerComponent.sendTest(KafkaObjectSerializerProducerComponent.TOPIC, data);return"send ok";}}
8 启动类
和写法一基本一致(除了类名不同)
9 测试效果
我这边已经启动了 Kafka ,随后在本地再启动本项目,待项目启动后,使用 GET 请求给 Kafka 中扔消息。
使用以上的链接触发。
可以依次观察到日志记录:
即将把数据【TestKafkaMessage(time=2023-03-17T21:29:21.564849900, message=消息内容就是我了, business=test, messageId=aa12c2e29bed431090918d971477de16)】发送到消息队列
消费者监听到数据:TestKafkaMessage(time=2023-03-17T21:29:21.564849900, message=消息内容就是我了, business=test, messageId=aa12c2e29bed431090918d971477de16)
主题[testObjectTopic]发送消息[TestKafkaMessage(time=2023-03-17T21:29:21.564849900, message=消息内容就是我了, business=test, messageId=aa12c2e29bed431090918d971477de16)]成功,发送结果:SendResult [producerRecord=ProducerRecord(topic=testObjectTopic, partition=null, headers=RecordHeaders(headers = [RecordHeader(key = __TypeId__, value = [111, 114, 103, 46, 102, 101, 110, 103, 46, 101, 110, 116, 105, 116, 121, 46, 84, 101, 115, 116, 75, 97, 102, 107, 97, 77, 101, 115, 115, 97, 103, 101])], isReadOnly = true), key=null, value=TestKafkaMessage(time=2023-03-17T21:29:21.564849900, message=消息内容就是我了, business=test, messageId=aa12c2e29bed431090918d971477de16), timestamp=null), recordMetadata=testObjectTopic-0@1]
附录
1 减少日志输出
默认情况下,Kafka的日志很多都会打印出来,但是又与我们业务本身无关。需要屏蔽一下。
这里做了简单的处理,使用 logback 设置了日志级别。
logback 文件内容如下:
<?xml version="1.0" encoding="UTF-8" ?><configurationdebug="false"><!-- 配置控制台输出 --><appendername="STDOUT"class="ch.qos.logback.core.ConsoleAppender"><encoderclass="ch.qos.logback.classic.encoder.PatternLayoutEncoder"><!-- 格式化输出: %d表示日期, %thread表示线程名, %-5level: 级别从左显示5个字符宽度 %msg:日志消息, %n是换行符 --><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS}[%thread] %-5level %logger{50} - %msg%n</pattern></encoder></appender><!-- 日志输出级别 --><rootlevel="INFO"><appender-refref="STDOUT"/></root><!-- 定制化某些包的日志输出级别 --><loggername="org.apache.kafka"level="warn"additivity="false"/><loggername="org.springframework"level="info"><appender-refref="STDOUT"/></logger></configuration>
效果如下:
发现日志确实少了很多。这样也方便我们后续开发。
2 手动提交偏移量
细心的朋友们可能已经发现了,以上的实例中,在项目重新启动时,会自动消费几条数据,这主要是因为我们设置了“不自动提交偏移量”,但是程序中又没有去手动提交。
现在我们来处理这个问题,首先是对原先的配置进行微调:
server:shutdown: graceful
spring:kafka:bootstrap-servers: localhost:9092producer:retries:3batch-size:16384buffer-memory:33554432acks:1key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
consumer:group-id: TestObjectGroup
# 依然使用非自动提交enable-auto-commit:false# 修改读取的偏移量的方式auto-offset-reset: earliest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
properties:spring:json:trusted:packages: org.feng.entity
listener:ack-mode: manual
# 设置并发量concurrency:3
以上修改了读取偏移量的方式为:在各分区下有提交的offset时,从offset处开始消费;在各分区下无提交的offset时:从头开始消费
然后调整监听者的配置
ack-mode: manual
,当每一批
poll()
的数据被消费端处理之后, 手动调用
Acknowledgment.acknowledge()
后提交。
监听器的写法上也做一下调整:
packageorg.feng.consumer;importlombok.extern.slf4j.Slf4j;importorg.apache.kafka.clients.consumer.ConsumerRecord;importorg.feng.entity.TestKafkaMessage;importorg.feng.producer.KafkaObjectSerializerProducerComponent;importorg.springframework.kafka.annotation.KafkaListener;importorg.springframework.kafka.support.Acknowledgment;importorg.springframework.stereotype.Component;/**
* 消费者
*
* @version v1.0
* @author: fengjinsong
* @date: 2023年03月17日 20时30分
*/@Component@Slf4jpublicclassKafkaObjectSerializerConsumerComponent{@KafkaListener(topics =KafkaObjectSerializerProducerComponent.TOPIC)publicvoidconsumeTestTopicAndCommit(ConsumerRecord<String,TestKafkaMessage>record,Acknowledgment ack){try{
log.info("消费者监听到数据:{}",record.value());// 手动提交
ack.acknowledge();}catch(Exception e){
log.info("消费失败,数据:{}",record.value(), e);}}}
监听器的主要调整在于方法入参、消费者处理消息后增加手动提交的操作。
版权归原作者 你家宝宝 所有, 如有侵权,请联系我们删除。