
摘要:本文整理自快手数据架构工程师张芒,阿里云工程师刘大龙,在 Flink Forward Asia 2022 生产实践专场的分享。本篇内容主要分为四个部分:
- Flink 流批一体引擎
- Flink Batch 生产实践
- 核心优化解读
- 未来规划
点击查看原文视频 & 演讲PPT
一、Flink 流批一体引擎
1.1 Lambda 架构

首先,介绍一下我们选择 Flink 作为流批一体引擎的思考。如上图所示,是现在生产应用最广的 Lambda 架构,相信大家已经很熟悉了,大概率也都在使用。Lambda 架构的优势非常明显:
- 灵活。实时链路和离线链路完全独立,按实际需求开发,互不影响;
- 容易落地。实时和离线链路都有成熟的解决方案;

当然缺点也很明显,实时计算和离线计算两条链路,存储不能复用,所以资源冗余严重。
然后,两种计算引擎,离线计算一般使用 Spark,实时计算使用 Flink,那么就要学习和维护两套代码,成本较高。
一般实时和离线又是两个团队开发和维护的,那么实现细节和口径难以统一,所以经常会有结果对不上的情况。因此,业务同学也非常希望实现流批的统一。
1.2 引擎统一

我们把流批一体分为两个方面,一个是引擎的统一,另一个是存储的统一。这里主要介绍,引擎的统一。
如果流批引擎统一了,那么用户只需要学习一种引擎,并且开发的代码也可以大量复用。这样极大的降低了开发运维的成本,由于计算逻辑相同,数据质量也就得到了保证。除此之外,快手离线作业切换引擎是非常便捷的。因此我们引擎统一的上线节奏和上线质量很容易把控。
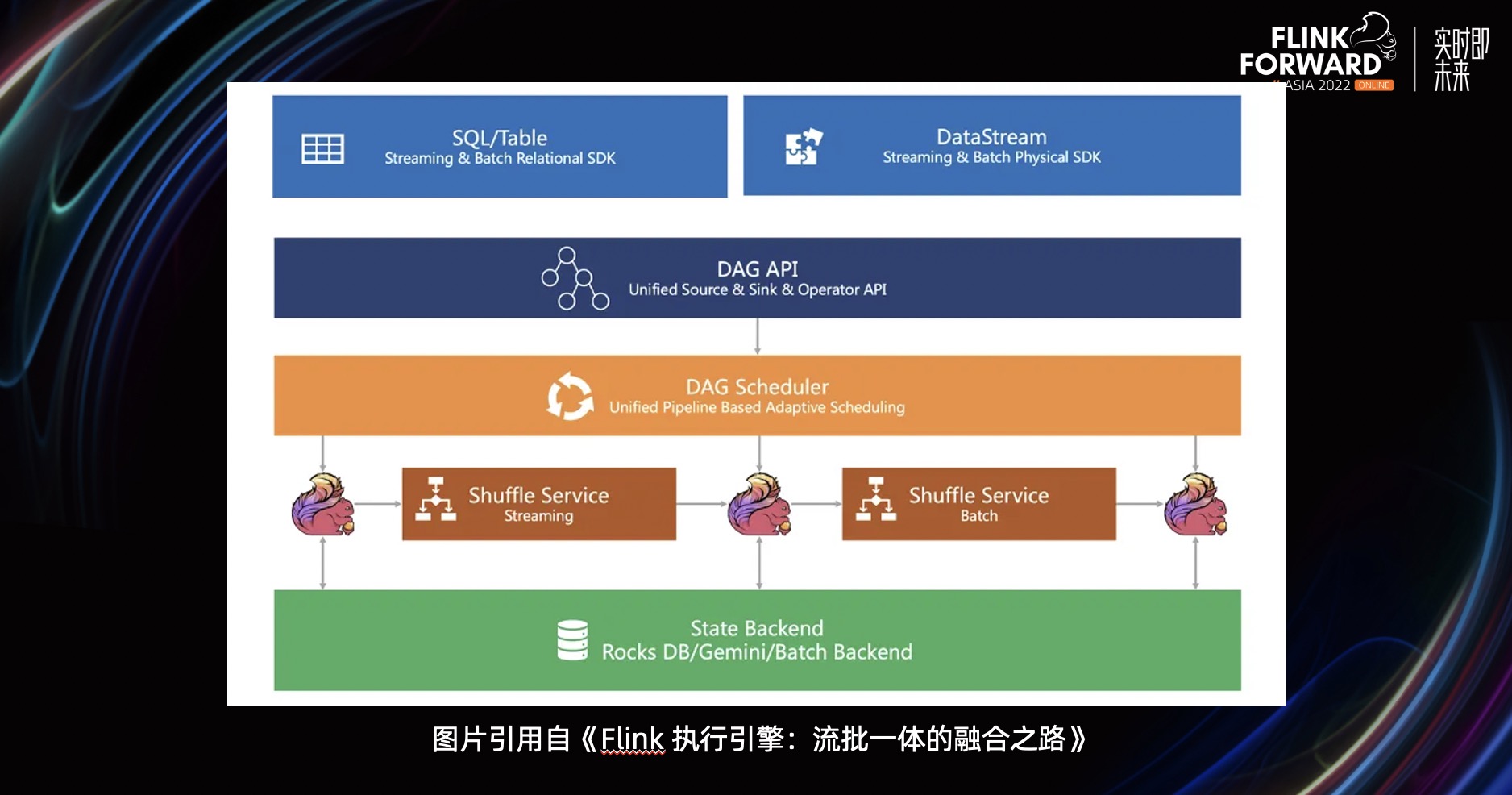
那么使用哪个引擎来作为流批统一的引擎呢?我们对比了主流的大数据引擎之后,选择了 Flink 作为流批统一的引擎。
因为 Flink 作为流计算领域的标杆,在架构设计上已经考虑到了流批融合,同时拥有活跃的社区。并且经过多个版本迭代之后,Batch 已经具备一定可用性了,我们之前在生产上也有过一些业务落地。
二、Flink Batch 生产实践

接下来,重点介绍一下 Flink Batch 生产应用的情况。目前,我们线上稳定运行了 3000+的 Flink Batch 作业,主要是平滑迁移的 Batch SQL。
与此同时,我们为用户提供多种入口选择。其中,Batch SQL 入口,面向传统的离线生产开发使用 Hive 方言,也是我本次分享的重点。
调度平台的 Flink Batch 入口,主要方便熟悉 Flink 的用户直接使用 Flink 方言或 API 开发 Batch 作业,并提供完整的离线调度支持。其他入口是业务方根据自己需要,基于我们平台搭建的业务系统。

如何在生产环境使用好基于 Hive 方言的 Flink Batch 呢?需要解决这几个方面的问题。
- 明确上线流程和标准。首先要筛选出合适的作业,然后验证数据质量、时效性、资源等各项指标,之后才能上线。
- 解决和 Hive SQL 的语法兼容问题,接入离线生产的各个系统,比如权限中心,元数据中心等。
- 保证生产环境的稳定运行,离线环境比实时环境复杂很多,会遇到一些实时场景不存在的问题。
- 解决和原离线引擎的性能差距;比如后面大龙老师会介绍的动态分区消除 Sort 算子优化。
这几个方面都解决之后,基本就可以推广应用了。

接下来,简单介绍一下快手的离线生产体系。在应用层,一般都是各种开发平台,或者是一些业务系统。在服务层,快手是使用 HiveServer 作为 Batch SQL 的统一入口,统一使用 Hive 方言。
BeaconServer 可以做 SQL 的改写,引擎的路由策略,还有 HBO 优化等。下面引擎层可以自由的切换,所以我们将 Flink 接入离线生产,只需要适配 HiveServer,然后在 BeaconServer 中,加入 Flink 引擎路由规则即可。
我们目前使用 SQL-Client 的方式接入 HiveServer,未来可能会扩展 SQL Gateway 的支持。

解决完如何接入离线体系的问题之后,我们需要明确作业上线的流程。
- 第一步,筛选出符合要求的 Batch SQL,比如,刚开始我们选择低优先级的简单数据处理作业。
- 第二步,使用 Flink 对 SQL 进行解析和校验,确定 Flink 是否支持。
- 第三步,对 Flink 可以运行的 SQL,进行改写,把插入表改成测试库中的表,然后提交运行。
- 第四步,对比影子作业和线上作业的结果是否一致,以及资源使用情况。
- 第五步,把前四步都成功的作业切换到 Flink 引擎上来,并且还要继续观察数据质量。
利用第三步提到的双跑能力,只是影子作业使用原来的离线引擎,线上作业使用 Flink,然后对比结果,确保没有预料之外的问题发生。这一步非常重要,能够帮我们及时发现没考虑到的 case。因为线上环境非常复杂,前期上线需要多观察。
目前,这个流程已经做到了自动化。我们的人力主要集中在解决发现的异常 case;
下面会介绍,这个流程的几个关键点,给大家一个参考。

刚开始使用 Flink 校验 SQL 的过程中,发现很多常用的语法都不支持,感觉不太正常。分析后发现,是因为打开方式不对,导致没有真正的用上 Flink HiveParser,通过查看这块的代码逻辑,发现问题所在。在 Flink 里,要真正使用 HiveParser,需要满足两个条件。
- 使用 Hive 方言。
- 当前 Catalog 必须是 HiveCatalog,否则会回滚到 FlinkParser。
除此之外,需要确保 HiveModule 是最高优先级。这样 Flink 和 Hive 同名的 Function 才会用 Hive 的实现。
如上图所示,按照右边这种方式实现之后,SQL 校验通过率提高了很多。但仍有很多 Batch 语法不支持,比如 Add Remote JAR 和 insert 目录等等。

在 SQL 改写方面,一般有两种情况。
- 用户作业里没有目标表的建表语句。我们会使用 CREATE TABLE LIKE 语句,先创建出测试库的目标表。然后,把原始 SQL 修改为写入测试库。
- 用户作业里带有目标表的建表语句。我们会直接个建表语句,改成创建到测试库。然后,把原始 SQL 修改为写入测试表。
在执行影子作业时,可以使用一个小权限的账号。这个账号只有写测试库的权限,避免 SQL 改写失败把数据写入到线上库。
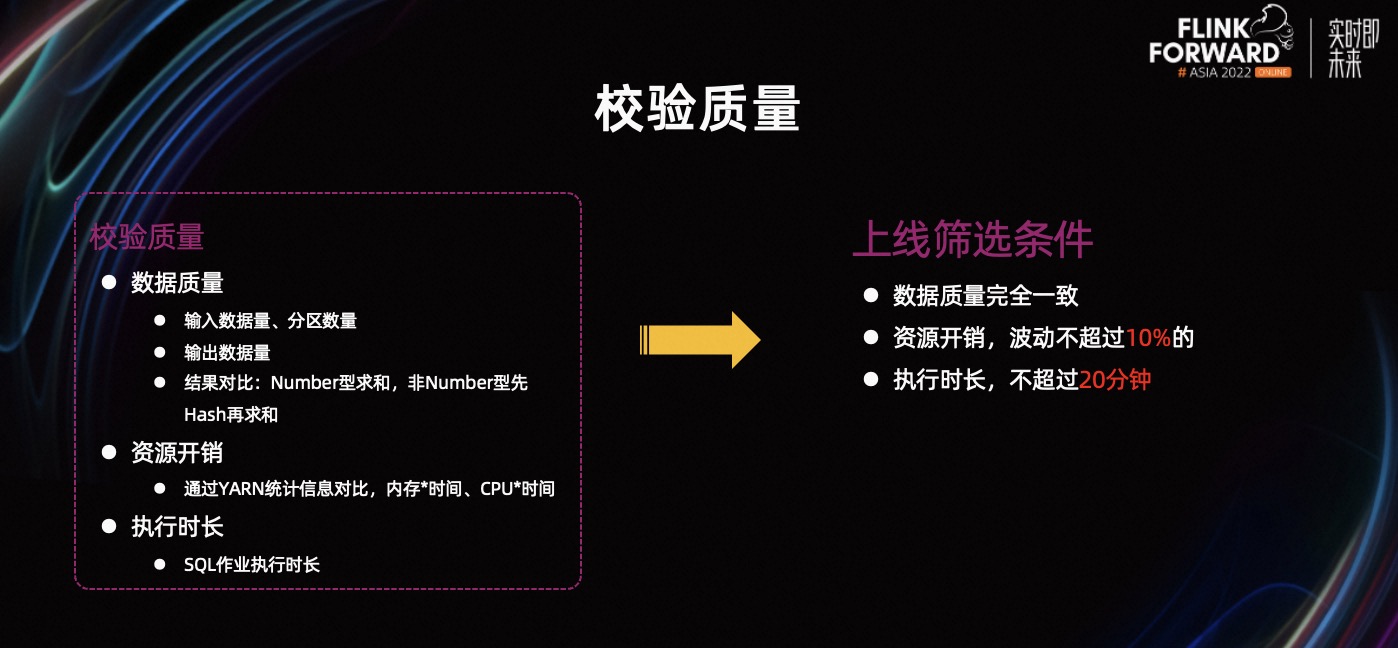
在质量校验方面,我们的策略如下。首先,根据 HiveServer 记录的作业输入信息,比对输入的数据量和分区数据是否一致。然后,根据作业的统计信息,比对写出的数据量是否一致。最后,比对写出的数据结果是否一致。
我们比对的方式是,把结果数据按列求和,如何所有列的结果都一致,则证明数据质量没问题。在按列求和时,如果是 Number 类型的列,直接求和;如果是非 Number 类型列,先取 Hashcode,然后再求和。
当结果对比一致后,我们会对比资源开销。这里统一使用 YARN 的统计口径,按照每个 Container 使用的资源*Container 运行的时间,最后加和算出资源总量。
上线作业的标准是,数据质量没有问题,并且资源使用增长量,不超过原引擎的 10%,执行时长不超过原引擎 20 分钟。介绍完 Flink Batch 作业上线流程之后,我们看一下接入离线生产还需要做哪些工作?

如上图所示,列出了我们做的一些修改。原来 Flink 的配置由 Flink、Hadoop、Hive 三部分组成,配置管理起来比较复杂也不够清晰。
因为我们通过 HiveServer 接入,HiveServer 在启动 Flink 时,会把 Hive Session 里的配置,都传给 Flink。这里包括用户手动 set 的配置和 Hadoop 相关配置。所以,我们把 Flink 的配置改为两部分,一部分是 Flink 自己的配置,一部分是 Hadoop 和 Hive 的配置。
SQL-Client 会默认会开启单词补全功能,即输入单词的一部分,然后使用 Tab 键来补全单词,这个功能在交互模式下是没问题的。但在使用文件传入 SQL 时,如果 SQL 内容中,刚好有这种情况,就会导致 SQL 发生变化,出现字段找不到的异常。所以从文件输入 SQL 时,需要关闭补全功能。
作业进度汇报,是对用户体验非常重要的功能。不然作业提交后,用户无法像 Hive/Spark 那样看到进度信息,HiveServer 也不知道作业运行是否正常,可能会出现作业一直卡主的情况。所以我们做了进度汇报功能,如果长时间没有汇报进度,HiveServer 就会主动杀掉作业。
最后,监控看板真很有必要。在分析问题时,可以辅助定位,不然只能盲猜。另外,在接入离线生产方面,还有一些和平台产品适配的工作。
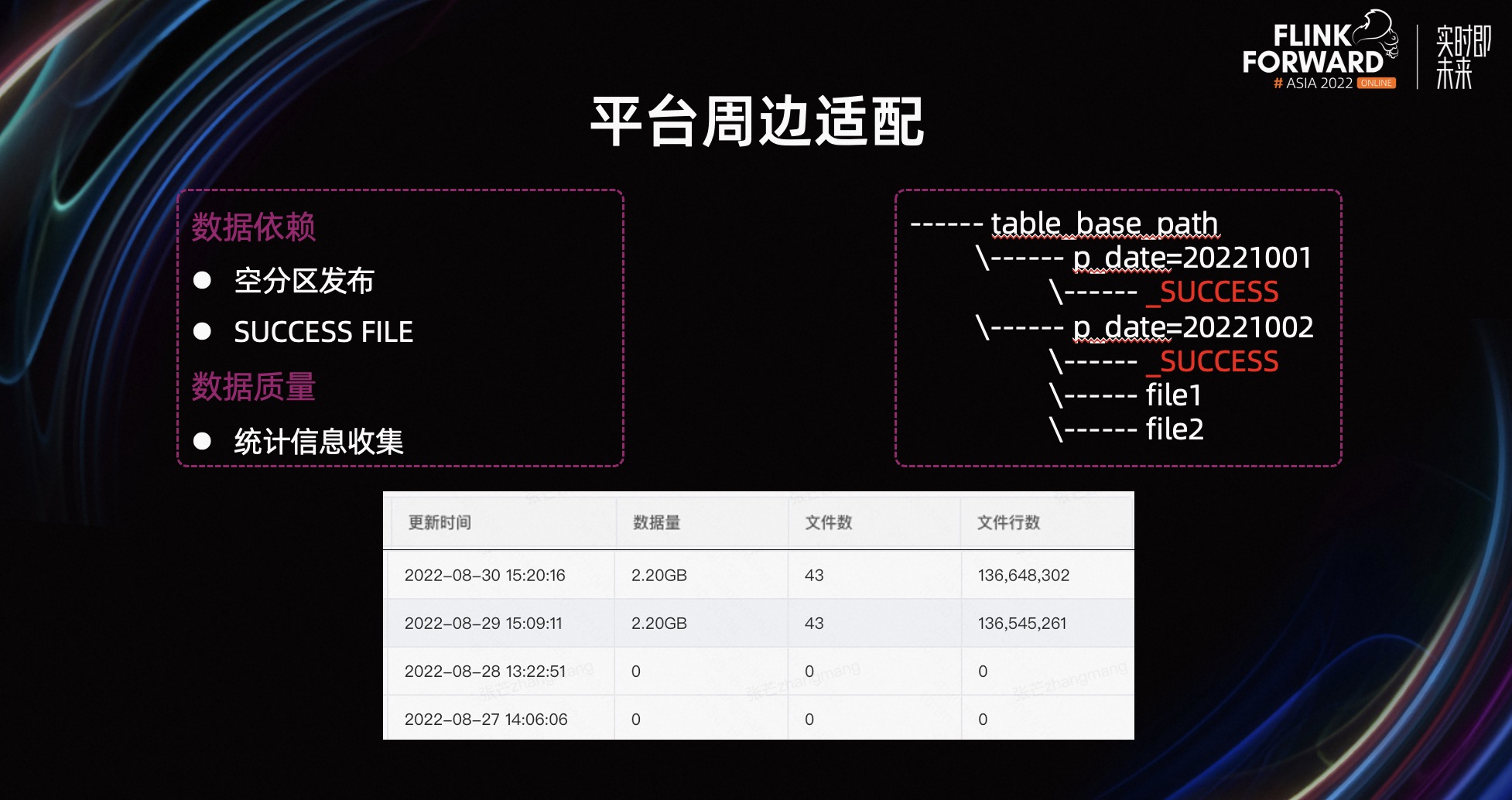
比如,空分区发布和 SUCCESS FILE 功能,快手的离线调度平台目前支持 3 种依赖方式。
- 任务依赖。当上游任务成功之后,才会拉起下游任务。
- 分区依赖。探测分区元数据是否生成,生成之后就拉起下游任务。
- SUCCESS FILE 依赖。根据文件是否存在,决定是否拉起下游任务。
Flink 根据 Sink 写出文件目录,来判断需要发布哪些分区,动态分区情况下没有问题。如果是静态分区写入的任务,同时没有数据生成,Flink 就不会发布分区,这样就可能会导致下游不被拉起。除此之外,如果没有写出 SUCCESS FILE 的话,也会有类似的问题。
在收集统计信息方面,Flink Batch 原来没有统计信息收集,当生成分区后,元数据中心显示数据为 0。用户看到之后,以为作业没有执行成功,就会重跑作业。如果用户配置了数据质量校验,没有统计信息,也会导致校验不通过。
介绍完接入相关内容,我们来看一下在线上运行之后遇到的问题。
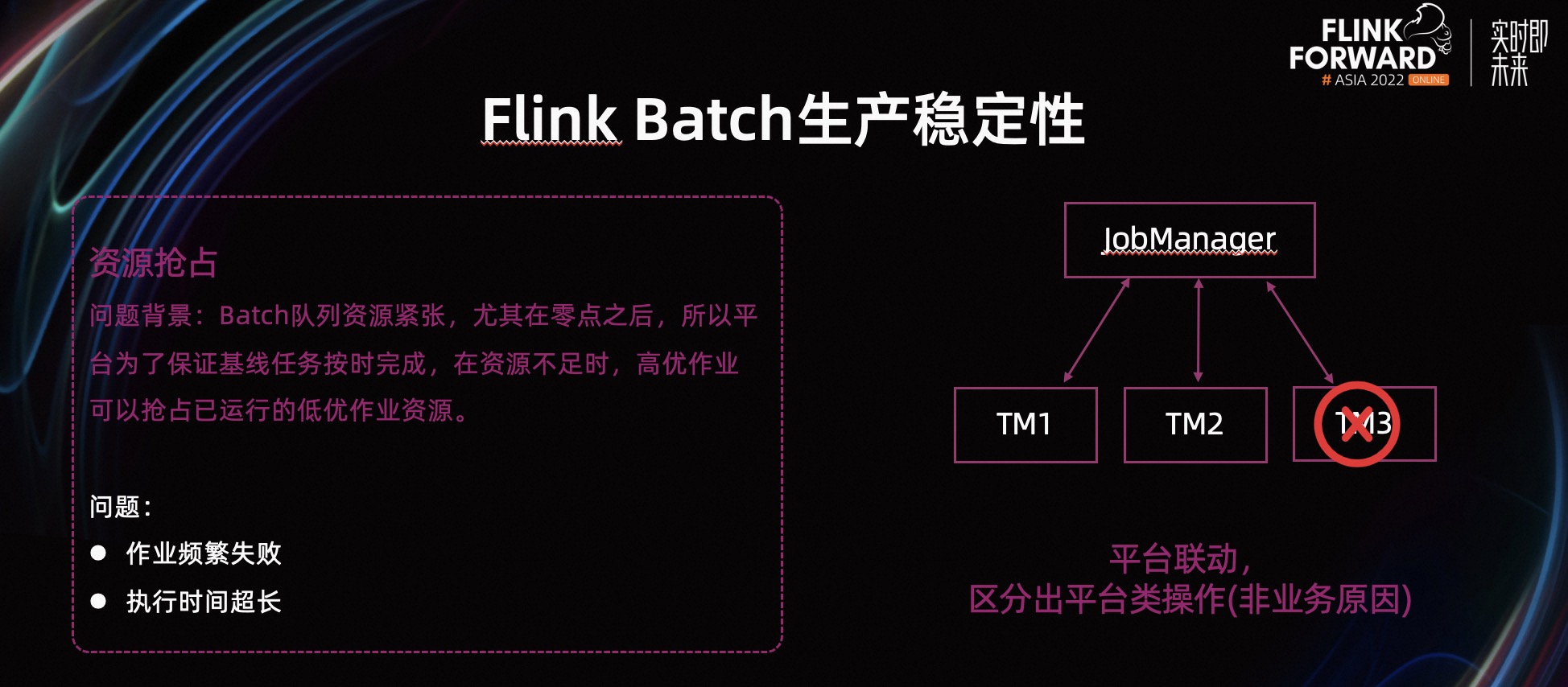
我们知道,离线生产一般是 T+1。由于 0 点之后开始处理前一天的数据,所以 0 点之后,会调度起大批的作业,离线资源就会很紧张。这个时候启动的基线作业,可能就拿不到资源。为了保证基线作业按时完成,YARN 会 Kill 掉一些低优作业的 Container,把资源分给基线任务。
Flink 一般会在一段时间内,当 Task 失败总次数达到阈值,作业失败。离线引擎一般是同一个 Task 失败几次,作业才会失败,并且离线引擎不会将平台原因导致的失败计算在内。
Flink Batch 上线之初,就遇到了资源抢占问题。作业会出现运行一段时间就失败,触发调度平台的失败重试,重试几次才会成功。有的作业可能不会失败,但因为 Task 被删除,需要重算数据,所以执行时间被拉长。
要想解决这个问题,又不能简单的把 Task 失败阈值上调。如果遇到业务逻辑导致的 Task 失败,调大失败阈值,会导致异常没有被及时发现,严重的会造成事故。
因此,我们参考离线引擎的做法,在 Task Fail 时拿到具体的失败原因。如果是资源抢占或者机器下线之类的平台原因,不计入失败次数。这样就解决了 Flink 作业频繁失败重试的问题。如果用户觉得运行时间过长,就需要考虑调整作业优先级。

解决了资源抢占问题后,离线集群慢节点问题是另一个稳定性隐患。CPU 利用率过高和 IO 繁忙在离线集群非常常见,个别 Task 长尾会导致整个作业执行时间超长。
解决这个问题的方法很简单,参考离线计算的推测执行即可。在发现 Task 执行时间,超过同 Task 的平均执行时间一段时间后。调度器在其他节点拉起一个镜像 Task,然后哪个 Task 先执行完,就用哪个 Task 的数据。
这个特性是快手和社区共建完成的,这里要特别注意的是,Flink 里数据分片是动态分配的,和 Hive、Spark 的静态机制不同。所以 Source 的推测执行实现复杂度会高很多,并且还要考虑到资源抢占等异常 case。

随着聚合类作业的上线,我们发现一些简单的聚合计算任务执行时间非常不稳定,有时很快,有时异常的慢。仔细分析之后发现,Flink 默认使用 TaskManager 来做 Shuffle,如果 Shuffle 数据没有被下游完全消费,那么 TaskManager 就不能释放。这样就会带来两个问题:
- 资源浪费。空闲的 TaskManager 不能释放。
- 如果这时候遇到资源抢占,或者机器下线,TaskManager 被 Kill 了,那么 Shuffle 数据就没了,需要重算这部分数据,这样就导致作业执行时间被拉长。
为了解决这个问题,需要把 Shuffle Service 独立出 TaskManager。有两种实现思路。
- 类似 Hive 或 Spark,使用基于 Yarn NodeManager 的 Shuffle Service。但 Flink 还没有相关实现,需要我们自行开发。
- 使用 Remote Shuffle Service。Flink 有开源实现,快手也有自研的 Remote Shuffle Service。
经过调研之后,我们选择了快手自研的 Remote Shuffle Service。因为快手的 Remote Shuffle Service 支持 Push-Based Shuffle。Shuffle Service 会将相同 Shuffle Partition 的数据合并,Task 只需从一个地方就可以读取到全部的 Shuffle 数据,社区的 Remote Shuffle Service 未来也会支持这个功能。
其次,快手的 Remote Shuffle Service 具有端到端数据一致性的校验,对数据质量有很好的保障。
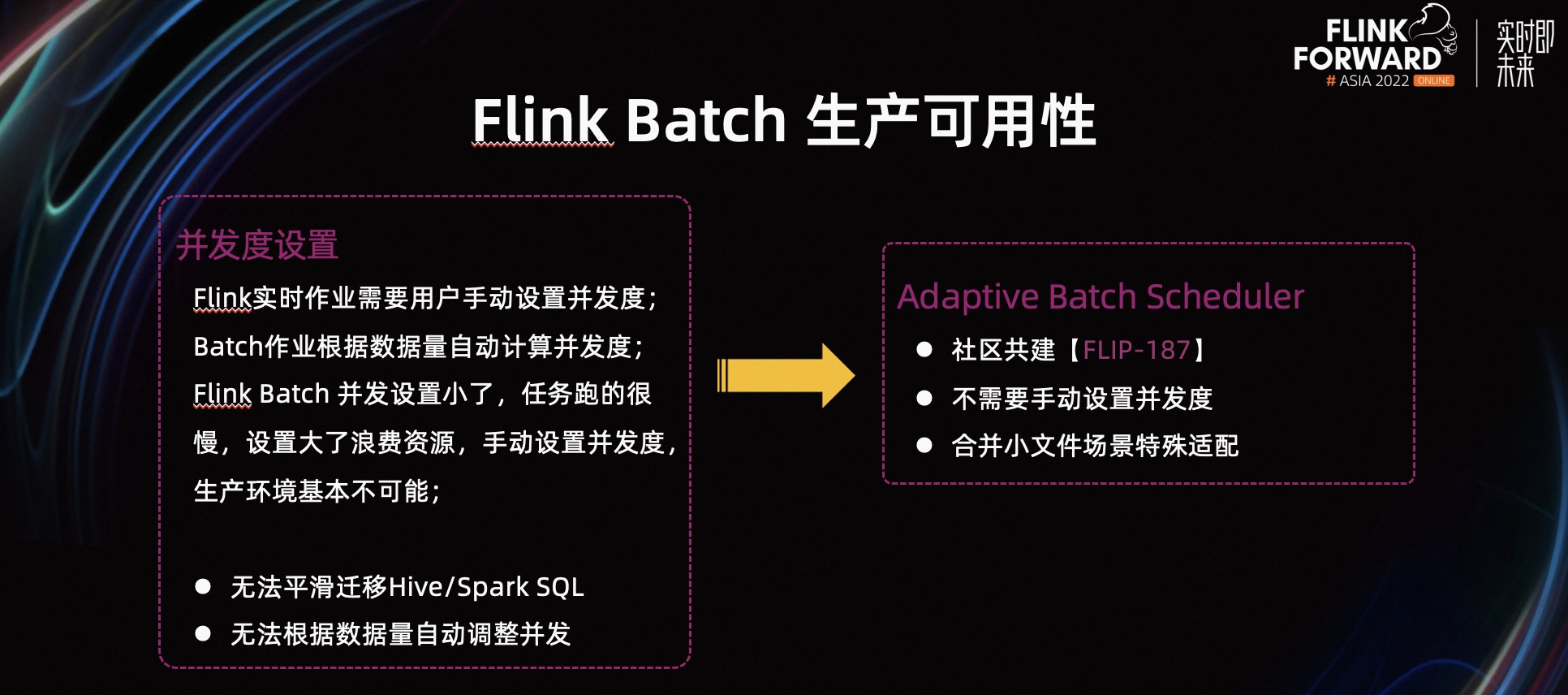
随着迁移作业量的增长,面临一个很棘手的问题,设置的默认并发度对大部分作业来说都不是最优的。
在实时计算场景,作业并发度都是用户自己设置的。但对离线计算来说,用户不需要设置并发度,引擎会根据数据量自动计算出对应的并发度。对我们来说,手动设置并发度是不现实的。由于数据量每天都在变化,不能每天都用同样的并发。
如果需要手动设置并发度,就无法实现平滑迁移 Hive/Spark 作业的目标。这个问题是我们和社区共建解决的,Adaptive Scheduler 根据数据量自动预估合适的并发度,这样我们就无需修改用户作业,实现平滑迁移。
除此之外,合并小文件的并发度 Adaptive Scheduler 暂时不能准确预估,我们通过 Hack 的方式临时解决,后续社区也会针对这种特殊 case 扩展 API 支持。

目前,我们正在逐步上量聚合类的 Batch 作业,遇到了两个比较复杂的问题,正在和社区一起解决。
- Hive UDAF 的支持。目前,Flink 只支持 Partial1 和 Final 模式的 Hive UDAF,像 Rank 类函数暂时不能支持。
- Hash Agg 的支持。目前,使用 Hive UDAF 的作业都会使用 Sort Agg,相较 Hash Agg 性能差异还是很明显的。
为了方便平滑迁移聚合类作业,Hash Agg 和完整 Hive UDAF 的支持都非常必要。
三、核心优化解读

Flink Batch 在快手落地上线的过程中遇到了诸多问题,包括语法兼容、Hive Connector、稳定性等多个方面。针对这些问题,快手和社区一起合作,共同解决这些问题,成功推进了 Flink Batch 的上线。接下来,给大家介绍一下社区从能用、好用、稳定可用等多个方面做的优化改进工作。
由于 Flink 是标准的 ANSI SQL,Hive SQL 与 ANSI SQL 语法差异较多。为了让 Hive SQL 平迁到 Flink SQL 引擎上,快手选择了使用 Hive Dialect。这样的话,绝大部分的作业都可以迁移,不需要用户修改 SQL。虽然在 Flink 1.16 版本之前,社区在 Hive Dialect 兼容上,已经做了很多工作。但离完全兼容 Hive SQL,仍有差距。快手选定了一批准备迁移的作业后,通过解析验证,发现诸多不支持的语法。
在快手给出 input 后,社区第一优先级做出了支持。如上图所示,我们列出了比较重要且很常用的一些语法,比如 CTAS、ADD JAR、USING JAR、宏命令、Transform 等。
UDF 在 Hive SQL 会经常使用的,用户一般会先在作业中 Add 一个远程的 UDF JAR,然后注册并使用。在 Flink 中,当前不支持 Add JAR,导致很多作业都无法迁移。除此之外,算法同学不喜欢写 Java UDF,他们一般用 python 写脚本,然后通过 transform 来处理数据。通过补全 Hive Dialect 语法,解决了迁移过程中的第一个 block。成功保证了现有的 Hive SQL,能跑在 Flink 引擎上。
社区在 Flink 1.16 版本做了大量工作,补全 Hive 语法。目前,通过 qtest 测试下来,整体兼容度能达到 95%,基本能保证用户现有的 Query 都能迁到 Flink 上来。Flink-25592&Flink-26360,这两个 umbrella issue 在追踪 Flink Batch 相关的工作。由于 CTAS&USING JAR 这两个功能,涉及到 PUBLIC API 的改动,在社区有对应的 FLIP 设计文档,因此接下来我会详细介绍一下这块的设计。

如上图所示,先介绍一下 FLIP-214 Create Function using JAR 功能。由于这个功能涉及到 SQL 模块的 ClassLoader 的改动。因此,有必要给大家介绍一下设计思路,避免大家踩一些 ClassLoader 的坑。
写 SQL 的人都知道,由于业务逻辑五花八门,计算引擎内置的函数往往不能满足需求。在此种情况下,需要用户手写 UDF 满足需求,尤其是 Java 技术栈的大数据引擎。我们会把 UDF 打到 JAR 包里,然后上传到某个远程的 HDFS 地址上,在使用的时候先 Add JAR 或者直接基于 JAR 包创建 UDF。
考虑到该场景以及快手的业务需求,社区在 1.16 支持了 USING JAR 功能。整体的语法部分如 PPT 中红色部分标出的字体,相比于之前,多了 USING JAR 的关键字,并且允许指定 JAR 包的地址,该地址可以是远程的,也可以是 Local 的。目前我们仅 Java&Scala 语言支持该语法。
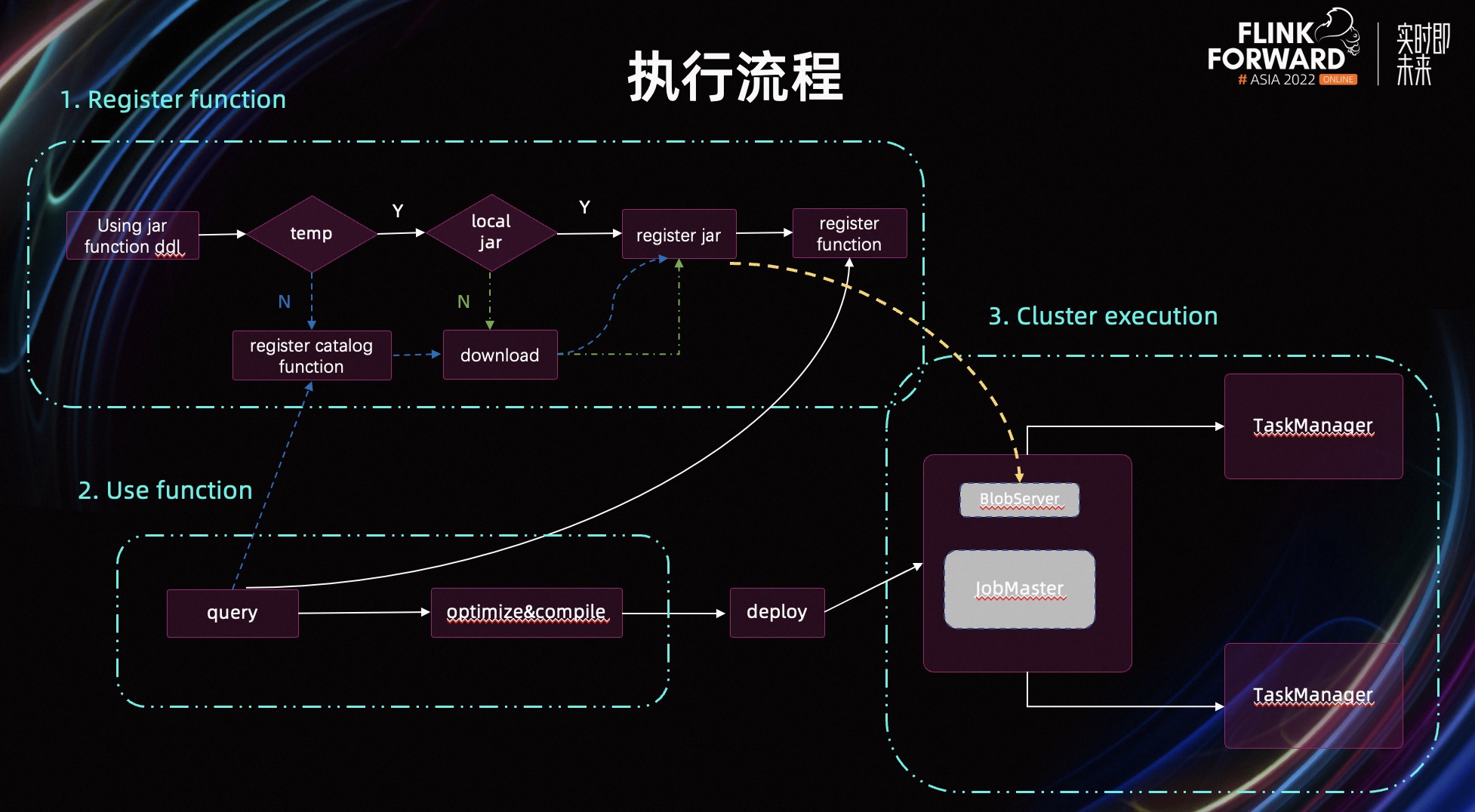
接下来,我来详细介绍一下如何使用 USING JAR 这个功能,以及其执行机制。首先,注册 UDF,在注册 UDF 的过程中,我们会解析 UDF 的 DDL,先判断函数是否是 temporary。如果不是,则直接注册到 Catalog 中,不做任何其他额外的工作。如果是 temporary,我们会接着判断 JAR 包的地址,是本地文件,还是远程的 HDFS、OSS 地址。
如果是 Local JAR,则会校验 JAR 包是否合法,如果 JAR 包合法,会把 JAR 包地址添加到 ResourceManager 中,同时也添加到 MutableURLClassLoader 中。
这里需要额外的说明一下,为了解决 Flink Table 模块中经常出现的 Connector&Catalog 相关的 ClassLoader 问题。1.16 版本社区在 Table 模块引入了一个 MutableURLClassLoader,每个 TableEnvironment 持有一个该 ClassLoader,允许动态的添加 JAR 包到 ClassLoader 中,这就解决了动态加载 JAR 包的问题。
接下来会把该 JAR 包注册到 FunctionCatalog 中管理。如果 JAR 包是远程的地址,会多一步下载的动作,这个动作由 ResourceManager 来完成,把 JAR 包下载到本地的临时目录,同时加载到 MutableURLClassLoader 中。
第二步是使用 UDF,如果在作业的 Query 中使用了 UDF,在 Query 解析优化的过程中,会先判断该 Function 是 temporary 的还是持久化的。如果是后者,会从 Catalog 中拿出其 JAR 地址信息,先把 JAR 包下载到本地,并加载到 ClassLoader 中,接着进行 Query 的优化,并生成 JobGraph。
生成 JobGraph 之后,第三步则是要把作业部署到集群上运行。我们在 Query 优化的时候需要 JAR 包,同时在集群上运行的时候也需要这些 JAR 包,否则作业运行时就会出现 ClassNotFoundException。那我们是怎么做的呢?
这里我们利用了 Flink 的 BlobServer,在往集群上提交作业时,我们会先把 ResourceManager 中维护的所有的本地 JAR 包,上传到 Flink JobManager 的 BlobServer 中,也就是图中黄色虚线标出的部分;在作业执行时,由 TM 负责从 BlobServer 中拉取这些 JAR 包。

接下来,我们介绍另一个比较常用的功能 CTAS。这个语法在所有大数据计算引擎中都支持,相比 CREATE TABLE 语法,其不同的地方在于文本中红色标出的字体。
该语法的作用是,由引擎基于 SELECT Query 自动推断出目标表的 Schema,并由 Catalog 负责创建;其等效于先创建目标表,再写一个 insert into...select query,其最大的好处是在 Query 比较复杂的时候,避免了用户手写目标表的 DDL,简化了用户的工作量,这个功能在生产环境中是非常有用的。
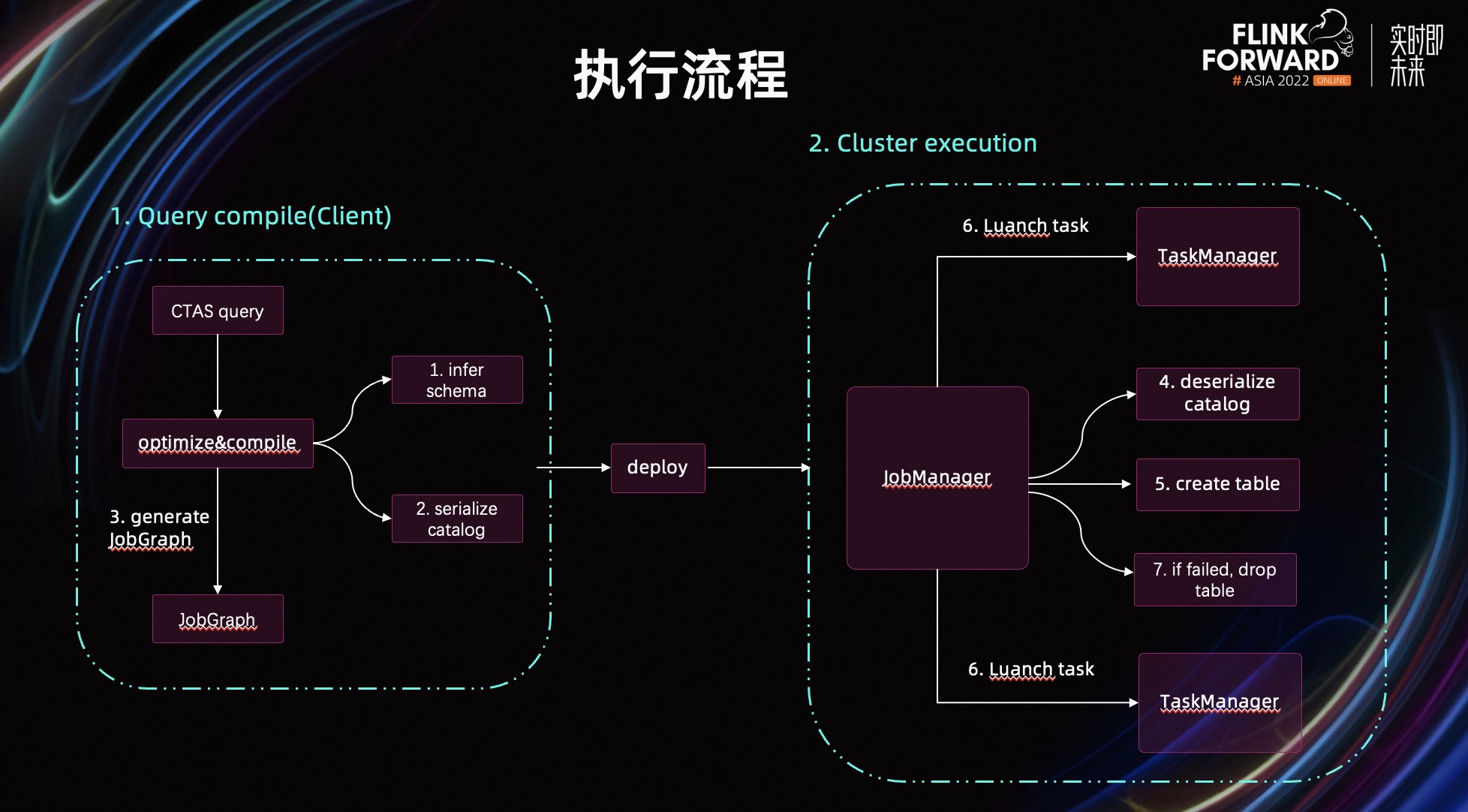
接下来,介绍一下 CTAS 整体的执行流程。首先,用户写了一个 CTAS Query,在客户端编译优化的过程中,我们会先基于 Query 推导出目标表的 Schema。然后,把对应的 Catalog 序列化。序列化的目的是,为了在 JobManager 上能反序列化,执行建表的动作。同时,我们生成一个钩子对象,由这个钩子在 JobManager 负责调用 Catalog 创建目标表。
第二步就是作业的执行。在作业开始调度前,我们首先在 JobManager 上把钩子对象及 Catalog 对象反序列化回来。接着,由钩子调用 Catalog 先创建目标表。然后,调度作业。
假设作业最终成功执行,则没有额外的动作。如果作业执行失败,或者被手动取消,出于原则性的考虑,我们会通过钩子调用 Catalog 把创建的目标表给 Drop 掉,保证最终没有对外部系统产生副作用。
考虑到 Flink 是一个流批一体的计算引擎,CTAS 语法在流批两种场景都能使用。但一般在流场景下,作业失败时,我们不会手动删除表,而是靠外部系统的更新能力,保证数据的最终一致性。
因此,我们引入了一个原子性相关的 option 由用户来决定是否需要保证数据的原子性。社区在 Flink 1.16 版本只完成了 CTAS 的一个基本功能,还没有支持原子性,这个会在 1.17 完成,更多细节大家可以去看 FLIP-218 的设计文档。

在快手 Flink Batch 实践过程中,我们发现 Hive Connector 诸多方面的问题。比如 Split 计算加速,统计信息收集、小文件合并等等。如上图所示,列出了在使用过程中,相对比较重要的一些功能。
通过这些优化,我们丰富了 Hive Connector 的能力,使其在 Batch 场景下更加好用。接下来,我会详细介绍动态分区写入优化和小文件合并。

不同于静态分区的写入,总是需要用户指定分区列的值。动态分区允许用户在写入数据的时候,不指定分区列的值。
比如,有这样一个分区表:用户可以使用如下的 SQL 语句向该分区表写入数据。
在该 SQL 语句中,用户没有指定分区列的值,这就是一个典型的动态分区写入的例子。
在 Flink 中,对应生成的 plan 是什么呢?如右边执行计划图所示,这里会有四个节点。其中,值得注意的是灰色的 Sort 节点。Flink 在动态分区写入时,会把数据按照动态分区列先做一个排序,然后再一个一个分区的写入数据。
这样带来了一些好处,但也导致作业的执行时间变的更长。因此,针对该现状和快手的业务场景,我们引入了一个选项,在写入动态分区时,允许用户手动关闭 Sort 节点,避免额外的排序,加快下游数据的产出速度。

小文件问题在生产环境中也是一个很常见的问题。在写入 Hive 表的时候,为了保证写入的速度,作业的并发设置较大。虽然加快了写入速度,但也引入了小文件问题。
小文件会增加 HDFS NameNode 压力和 RPC 压力,对下游的读取任务不友好。除此之外,在动态分区写入时,某个并发可能会同时写很多动态分区,导致大量的小文件。基于上述问题,我们在 Hive Batch 写入,支持了自适应合并小文件。
上图是 Batch 模式下,Hive Sink 支持小文件合并的拓扑。我们看到图中有四个节点,分别是 Writer、CompactorCoordinator、Rewriter 和 PartitionCommitter。这里的核心是 CompactorCoordinator 和 Rewriter。
CompactorCoordinator 是单并发节点,上游的 Writer 写完文件后,把文件路径信息告诉 CompactorCoordinator。CompactorCoordinator 拿到上游的所有文件后,判断哪些文件是小文件,需要合并成的目标文件大小,从而决定把哪些小文件合并成一个目标大文件。
然后把这些信息告诉给 Rewriter,由 Rewriter 来完成合并的工作,最后由 PartitionCommitter 提交分区信息。自适应合并小文件带来的收益是减少文件数量,降低 HDFS 的压力;提高用户作业的数据读取效率;加快执行速度。

接下来,讲一讲在使用 UDAF 过程中遇到的性能方面的问题。首先,我先来介绍一下 Sort-Agg 和 Hash-Agg 这两个概念。一般在聚合计算场景,有两种策略,分别是 Sort-Agg 和 Hash-Agg。
Sort-Agg 是在聚合计算之前,根据 group by key,对数据进行全局排序。排序之后,遍历所有数据,遇到相同 key 的数据,就做累加操作。如果遇到不同 key 的数据,意味着上一个 group 的所有数据已经计算完,可以直接往下游发送结果。然后,接着计算新 key 对应的 group 的聚合值。
Hash-Agg 则是指,在内存中构建一个 Hash 表,key 是 group by 的 key,value 是每个 group 的聚合值,一直往上累加。当所有数据遍历完,则最终结果才可输出。一般来说 Hash-Agg 在内存中完成,比较高效,而 Sort-Agg 需要一步外部排序,因此性能相对而言会差。
当前在 Flink 中存在两种聚合计算函数接口,分别是 ImperativeAggregateFunction 和 DeclarativeAggregateFunction。上图左边列举了这两种接口的对应的 UDAF 实现的优缺点。
Hive UDAF 当前只能走 Sort-Agg 策略,整体性能比较差。针对这个问题,经过调研之后,我们决定基于 DeclarativeAggregateFunction 接口,在 Flink 里重新实现 Hive 的一些常用的 UDAF。这里的难点是要做到与 Hive 的行为保持一致。重新实现之后,绝大部分的 Query 都可以使用 Hash-Agg,整体上达到了与内置函数一样的性能。

接下来,讲一下另一个比较重要的功能自适应调度器。写过 Flink 流作业的用户都知道,Flink 作业在上线前都需要设置并发度。对流作业而言,这是一个大家默认接受的事情。但对于批作业而言,情况就复杂很多。
首先,批作业数量很多,动辄成百上千,乃至数万,用户不可能 case by case 的调并发,费时费力。
其次,数据量每日都有可能变化,难以预估。因此,同一个并发度设置对同一个作业,不一定一直适用。无法保证作业的运行时间一直在一个稳定的时间基线范围内,对生产的影响会比较大。
最后,SQL 作业,除了 Source 和 Sink 外,只能配置全局统一的并行度,没法进行细粒度并行度设置,也会遇到资源浪费和额外开销的问题。
为了解决这些问题,社区为 Flink 引入了自适应批处理调度器。通过它框架会根据计算节点需要处理的数据量,自动推导节点的并行度。
这样的并行度配置比较通用,可以适用于大部分作业,无需为每个作业单独配置。自动设置的并行度,能够适配每天不同的数据量。同时,由于在运行时可以采集,各个节点实际需要处理的数据量,所以能够进行细粒度的并行度设置。它的流程大致如下:
- 当上游逻辑节点的所有执行节点都结束时,我们会采集其产出的数据量大小。
- 当下游逻辑节点消费的数据量确定后,我们可以通过并行度推导策略组件,为节点计算出合适的并行度。
- 在逻辑节点并行度确定后,我们会把它的执行节点,加入执行拓扑中,并尝试进行调度和部署。

和传统 Flink 作业执行不一样的地方在于,以往的作业执行拓扑是,在作业提交时就已经构建,是静态的。而自适应批处理调度的作业,执行拓扑是动态生成的。在动态执行拓扑下,一个下游节点可以消费多个 sub-partition,使得上游节点的执行过程,和下游节点的并行度解耦。
自适应批处理调度加上 Hive Source 的并发推导能力,解决了并发度设置的问题。在快手侧拿到的效果主要体现在两个方面:
- 有了这个功能,无需用户为每个作业单独配置并行度,使得 Flink Batch 更易用,支持细粒度的并行度设置,避免了资源浪费。
- 根据数据量,自动调整算子的并发,保证作业了在生产环境中稳定运行,保障了产出基线,作业可以平滑的迁移过来并上线。
接下来,介绍一下社区和快手合作在生产稳定性方面,做的一个比较重要的功能推测执行。在生产环境中,热点机器一般都是无法避免的,集群混部、密集回刷数据,都可能导致一台机器的负载变高、IO 繁忙,使得上面运行的 Flink 作业异常缓慢。一些偶发的机器异常,也会导致同样的问题。
这些缓慢的任务会影响整个作业的执行时间,使得作业的产出基线无法得到保障。而推测执行,是一种已经得到普遍的认可、用来解决这类问题的方法。因此社区在 Flink 1.16 版本中引入了这套机制。
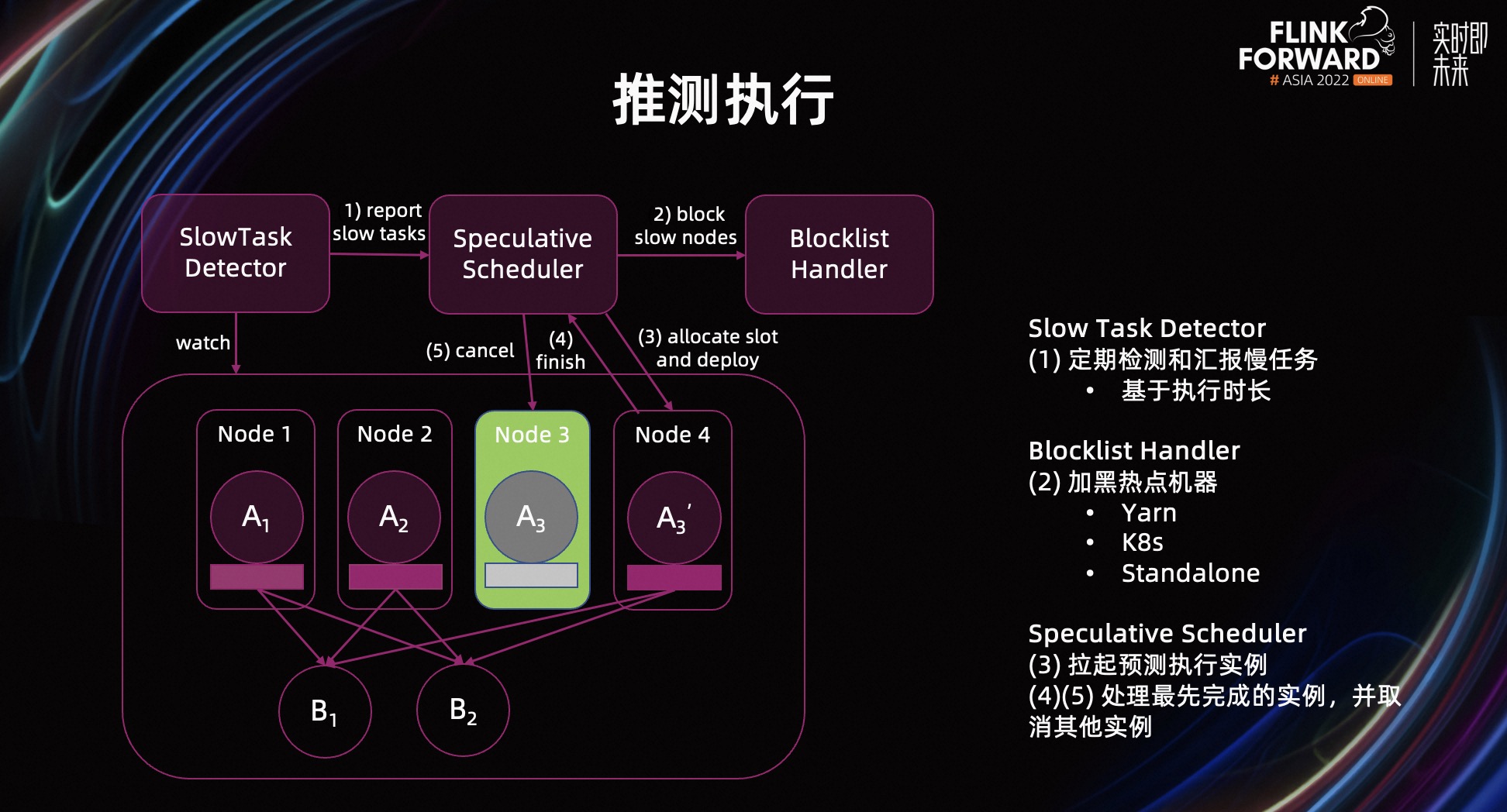
开启推测执行后,当框架发现批作业中出现某个 SubTask,明显比其他 SubTask 执行缓慢时,会为其拉起新的执行实例。我们把它叫做影子 Task,部署在正常的机器节点上,而原本的慢任务实例会被保留继续执行。
这些影子任务和对应的原始任务,具有相同的输入和产出。其中,最先完成的任务会被认可,产出的数据可以用来被下游节点消费;其他对应的实例会被取消,产出的数据会被清除。
推测执行的具体流程如图所示,当 SlowTaskDetector 发现存在慢任务时,会通知给推测执行调度器。调度器会把慢任务所在机器识别为热点机器,将其加入黑名单中。然后,如果慢任务的运行中的执行实例数尚未达到上限,调度器就会为其创建新的执行实例,并进行部署。当任意执行实例成功结束后,调度器会取消该实例对应执行节点的其他所有执行实例。

前面我们介绍了框架层面实现的通用的推测执行流程,但是对于 Source 和 Sink,推测执行会有一些特殊之处。对于 Source 节点来说,我们要保证同一个 Source 并发的不同执行实例,总是要读取相同的数据。这样才能保证结果的正确性。这里有几个特殊情况需要考虑。
- 对于 FLIP-27 新 Source,Source 端 Split 是动态分配的,我们需要保证影子 Task 和原来的慢 Task 处理的是相同的 Split。
- 原来的慢 Task 已经处理的一部分 Split,影子任务处理的速度比较快,能把前面的 Split 追上来。这时影子任务会请求分配更多的 Split,这个过程也需要原来慢任务处理的也是相同的 Split,这里可能是个相互赛马的过程;最终谁先执行完成,用谁的数据。
- 由于资源抢占、机器异常等原因,可能会出现影子任务或者慢任务挂掉的情况。如果只挂了一个 Task 可以先不用管;如果两个 Task 都挂了,推测执行调度器判断识别出来后,需要把已经处理的 Split 信息还回来,接着调度新的任务,来处理这些 Split。
大体上来说,就是在框架层加入了一个缓存,来记录各个 Source 并发已经获取到的数据分片,以及其下的所有执行实例已经处理到的分片信息。
对于 Sink 端,由于只是负责写数据,情况则简单很多,只需要保证影子任务和慢任务,最终那个先执行完,就提交那个的数据,同时清理掉另外一个无效 Sink 的数据,避免数据重复。
通过推测执行功能,保证了 Batch 任务执行的稳定,产出时间相对稳定可控,保障了 Flink Batch 在快手生产使用过程中的整体稳定性,为进一步的 Batch 落地打下了良好基础。
以上就是从能用、好用、生产稳定可用等三个方面,介绍了社区和快手合作在 Batch 方面做的一些核心优化改进工作。这些工作保证了 Flink Batch 在快手的上线,并在生产环境中稳定运行。随着快手在 Batch 的进一步推进,未来还会有诸多方面的工作要做。
四、未来规划

如上图所示,我们会在 Flink Batch 方向持续投入。监控指标展示以及 History Server 的可用性需要尽快补全,方便问题的定位和分析,用户就可以自助解决一些简单问题。除此之外,当聚合场景下的相关问题解决后,我们就可以大量迁移聚合类的作业。解决 Join 场景的问题后,将开始迁移复杂 Join 场景作业;
在流批一体存储的探索方面,待引擎能力建设后,开始建设统一的存储服务,给流作业和批作业提供统一的读写 API,解决冗余存储带来的成本问题。
点击查看原文视频 & 演讲PPT
版权归原作者 Apache Flink 所有, 如有侵权,请联系我们删除。