
seaborn.relplot(*, x=None, y=None, hue=None, size=None, style=None, data=None, row=None,
col=None, col_wrap=None, row_order=None, col_order=None, palette=None, hue_order=None,
hue_norm=None, sizes=None, size_order=None, size_norm=None, markers=None, dashes=None,
style_order=None, legend='auto', kind='scatter', height=5, aspect=1, facet_kws=None,
units=None, **kwargs)
官网说明:seaborn.relplot — seaborn 0.11.2 documentation
函数用于两个变量之间的关系以及子集的语义映射。种类参数选择要使用的基本轴级别函数:
散点图()(默认为kind=“scatter”)
lineplot()(带kind=“line”)
额外的关键字参数被传递给底层函数,因此您应该参考每个参数的文档,以查看特定于种类的选项。
参数:
** x, y **vectors or keys in
data
指定x轴和y轴上位置的变量
** hue **vector or key in
data
将生成具有不同颜色的元素的分组变量。可以是按类别的(categorical),也可以是数字的,不过在后一种情况下,颜色映射的行为会有所不同。
** size **vector or key in
data
将生成不同大小元素的分组变量。可以是按类别的(categorical),也可以是数字的,在后一种情况下,大小映射的行为会有所不同。
** style **vector or key in
data
将生成具有不同样式的元素的分组变量。可以具有数字数据类型,但将始终被视为按类别的(categorical)。
** data** pandas.DataFrame, numpy.ndarray, mapping, or sequence
输入数据结构。要么是可以分配给命名变量的向量的长形式集合,要么是将进行内部整形的宽形式数据集。
** row, col **vectors or keys in
data
定义要在不同面上绘制的子集的变量。
** col_wrap **int
以该宽度“包裹”列变量,使列面跨越多行。与行方面不兼容。
** row_order, col_order **lists of strings
按顺序组织网格中的行和/或列,否则将从数据对象推断顺序。
** palette **string, list, dict, or matplotlib.colors.Colormap
映射色调时选择要使用的颜色的方法。字符串值传递给color_palete()。List或dict值表示按类别的映射,而colormap对象表示数字映射。
** hue_order **vector of strings
指定色调语义分类级别的处理和打印顺序。
** hue_norm **tuple or matplotlib.colors.Normalize
以数据单位设置归一化范围的一对值,或将从数据单位映射到[0,1]区间的对象。用法意味着数字映射。
** sizes **list, dict, or tuple
确定使用大小时如何选择大小的对象。它始终可以是大小值列表或大小变量到大小的dict映射级别。当大小为数字时,它也可以是一个元组,指定要使用的最小和最大大小,以便在此范围内规范化其他值。
** size_order **list
指定大小变量级别的出现顺序,否则将根据数据确定。大小变量为数字时不相关。
** size_norm **tuple or Normalize object
当尺寸变量为数字时,以数据单位进行归一化,以缩放打印对象。
** style_order **list
指定样式变量级别的外观顺序,否则将根据数据确定。当样式变量为数字时不相关。
** dashes **boolean, list, or dictionary
用于确定如何为样式变量的不同级别绘制线。设置为True将使用默认的破折号代码,或者可以将破折号代码列表或样式变量的字典映射级别传递给破折号代码。设置为False将对所有子集使用实线。破折号在matplotlib中指定:一个(段、间隙)长度的元组,或一个用于绘制实线的空字符串。
** markers **boolean, list, or dictionary
确定如何为样式变量的不同级别绘制标记。设置为True将使用默认标记,或者可以将标记列表或将样式变量的字典映射级别传递给标记。设置为False将绘制无标记线。标记在matplotlib中指定。
** legend **“auto”, “brief”, “full”, or False
如何绘制图例。如果“简短”,数字色调和大小变量将用均匀分布的值样本表示。如果“已满”,每组将在图例中获得一个条目。如果为“自动”,则根据级别数在简短表示或完整表示之间进行选择。如果为False,则不添加图例数据,也不绘制图例。
** kind **string
Kind of plot to draw(这是一种要绘制的图), corresponding to a seaborn relational plot. Options are {
scatter
and
line
}.
** height **scalar
每个面的高度(英寸)
** aspect **scalar
每个面的纵横比,因此纵横比*高度(
aspect*height
)表示每个面的宽度
** facet_kws **dict
要传递到FacetGrid的其他关键字参数的字典.
** units **vector or key in
data
识别采样单位的分组变量。使用时,将为每个单元绘制一条具有适当语义的单独线,但不会添加图例条目。当不需要精确身份时,用于显示实验重复的分布。
** kwargs **key, value pairings
其他关键字参数传递给底层plotting函数。
**Returns**
FacetGrid
一种对象,用于管理一个或多个子图,该子图对应于条件数据子集,具有用于批量设置轴属性的方便方法.
绘图举例:
数据集:fmri
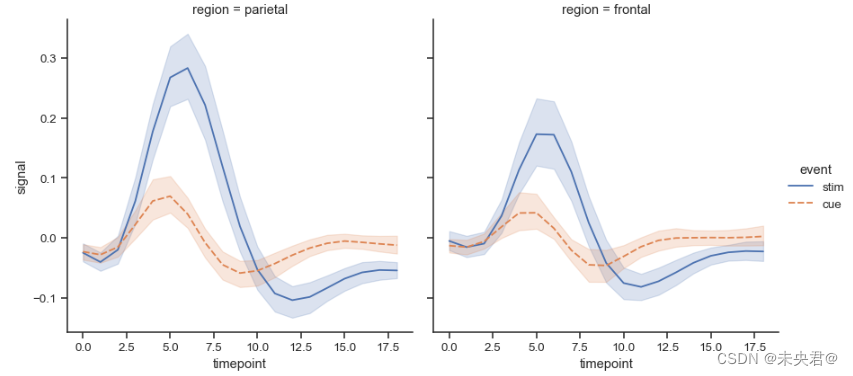
sns.relplot(
data=fmri, x="timepoint", y="signal", col="region",
hue="event", style="event", kind="line",)
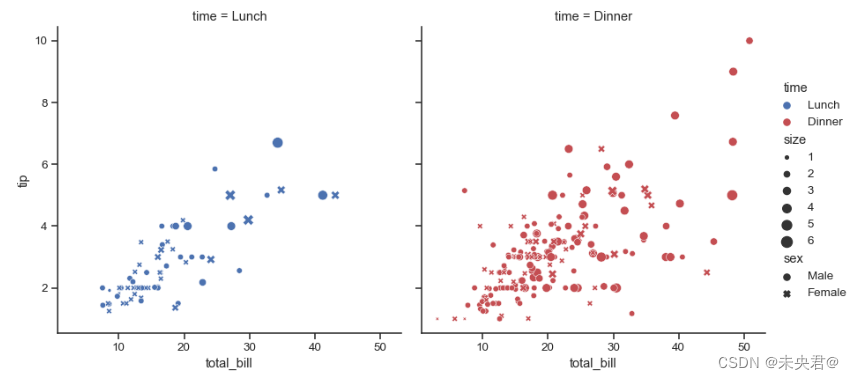
sns.relplot(
data=tips, x="total_bill", y="tip", col="time",
hue="time", size="size", style="sex",
palette=["b", "r"], sizes=(10, 100)
)
版权归原作者 未央君@ 所有, 如有侵权,请联系我们删除。