
前言
本文隶属于专栏《大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和参考文献请见大数据技术体系
背景
数据湖非常有用和方便,让我们分析数据湖的需求和使用。
关于数据湖请参考我的博客——什么是数据湖?为什么需要数据湖?
Hadoop 系统和数据湖经常一起被提及。
数据加载到 Hadoop 分布式文件系统(HDFS),并在基于分布式处理架构的部署中存储在 Hadoop 集群的许多计算机节点上。
然而,数据湖越来越多地使用云对象存储服务而不是 Hadoop 构建。
一些 NoSQL 数据库也被用作数据湖的平台。
关于 NoSQL 请参考我的博客——NoSQL是什么?
包含结构化、非结构化和半结构化数据的大数据集经常存储在数据湖中。
大多数数据仓库建立在关系系统上不太适合这种情况(ROLAP)。
关于 ROLAP 请参考我的博客——OLAP有哪些实现方法?
关系系统通常只能存储结构化事务数据,因为它们需要固定的数据模式(Schema)。
数据湖不需要任何前期定义,并支持各种模式。
因此,他们现在可以以不同的形式管理各种数据类型。
使用 Hadoop 框架构建的数据湖还缺乏非常基本的功能,即 ACID 合规性。
Hive 试图通过提供更新功能来克服一些限制,但整个过程很混乱。
业内不同的公司针对上面的问题有着不同的解决方案,Databricks(Spark 背后的公司)就提出了一个独特的解决方案,即 Delta Lake。
Delta Lake 允许在现有数据湖上进行 ACID 事务。
它可以与许多大数据框架无缝集成,如 Spark、Presto、Athena、Redshift、Snowflake 等。
WHAT

Delta Lake 是一个开源项目,它可以运行在你现有的数据湖之上,可以在数据湖上构建湖仓一体架构,并且与 Apache Spark API 完全兼容。
关于湖仓一体请参考我的博客——湖仓一体(Lakehouse)是什么?
Delta Lake 提供 ACID 事务、可扩展的元数据处理,并在现有数据湖(如 S3、ADLS、GCS 和 HDFS)上统一流数据和批数据处理。
具体来说,Delta Lake 提供:
- Spark 上的 ACID 事务:串行化的隔离级别确保读者永远不会看到不一致的数据。
- 可扩展的元数据处理:利用 Spark 分布式处理能力轻松处理数十亿个文件的 PB 级别数据表的所有元数据。
- 流批统一:Delta Lake 中的表是批处理表也是流处理的 source 和 sink。流式数据摄取、批处理历史回填、交互式查询都可以做到开箱即用。
- Schema 实施:自动处理模式(Schema)变化,以防止在摄取期间插入不良记录。
- 时间旅行:数据版本控制可以实现回滚、完整的历史审计跟踪和可复制的机器学习实验。
- upsert/delete:支持合并、更新和删除操作,以启用复杂的场景,如更改数据捕获、缓慢更改维度(SCD)操作、流升级等。
我们用 Delta Lake 做什么?
大数据架构目前在开发、运行和维护方面具有挑战性。
在现代数据架构中,实时计算、数据湖和数据仓库通常至少以三种方式使用。
业务数据通过数据流网络传输,如 Apache Kafka 等,这些网络优先考虑更快的交付。
关于 Apache Kafka 请参考我的博客——Kafka 是什么?
数据随后在 Data Lake 中收集,Data Lake 用于大规模、廉价的存储,包括 Apache Hadoop 或 Amazon S3。
最重要的数据被上传到数据仓库,因为令人遗憾的是,数据湖无法在性能或质量方面单独支持高端业务应用程序。
这些存储成本明显高于数据湖,但经过相当大的性能、并发性和安全性。
批处理和流处理系统在 Lambda 架构中同时准备记录,这是一种常见的记录准备技术。
然后在调查期间将结果合并,以提供全面的回应。
由于处理最近生成的事件和旧事件的严格延迟要求,这种架构臭名昭著。
该架构的主要缺点是维护两个独立系统的开发和运营负担。
过去,曾尝试将批处理和流处理集成到一个系统中。
另一方面,公司在尝试中并不总是成功的。
绝大多数数据库的一个关键组成部分是 ACID。
然而,在 HDFS 或 S3 方面,提供与 ACID 数据库相同的可靠性是具有挑战性的。
Delta Lake 通过跟踪对记录目录的所有提交,在事务日志中实现 ACID事务。
Delta Lake 架构提供了串行化的隔离级别,以确保众多用户之间的数据一致性。
Parquet VS Delta Lake
Delta lake 底层数据的存储格式是 Parquet 数据格式的包装,但它在 Parquet 之上提供了一些额外的功能。
关于 parquet 请参考我的博客——Parquet是什么?
以下是差异:
ParquetDelta Lake列式数据存储ACID 事务存储层类型声明编码可扩展的元数据处理不支持数据版本支持数据版本适用于 Hadoop 生态系统中任何项目,不管哪种数据处理框架只适用于 Spark 处理框架,可以和 Presto,Athena 等集成
Delta Lake 的架构
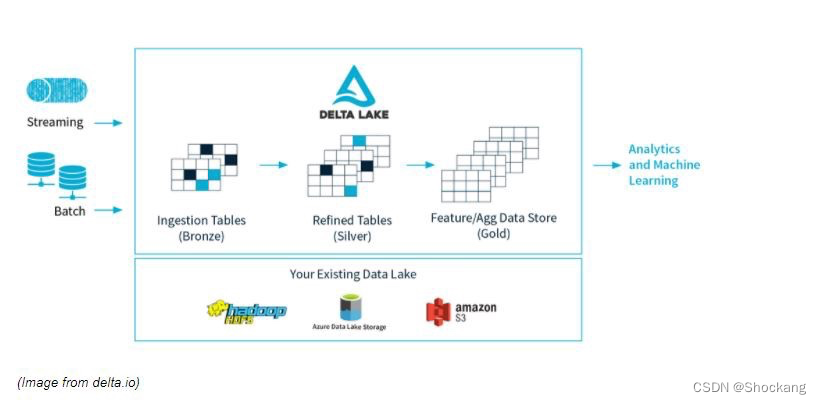
Delta Lake 的架构总体上被划分为3个区域。
在这里,Bronze 表是典型的数据湖,大量数据不断涌入。此时数据可能很脏(即数据质量很低),因为它来自不同的来源,其中一些来源不那么干净。
关于数据质量请参考我的博客——数据质量如何评测?
此后,数据不断流入 Silver 表,就像与数据湖相连的数据流源头一样,快速移动和不断流动。
当数据向下游流动时,它经过不同的函数、过滤器、查询的转换得以清理和过滤,随着数据流动而变得更加纯净。
当它到达下游的数据处理,即我们的 Gold 表时,它会接受一些最终的净化和严格的测试,以使其做好准备,因为消费者,即机器学习算法、数据分析等非常挑剔,不会容忍受污染的数据。
Delta Lake 是如何运作的?
为了了解 Delta Lake 的工作原理,需要了解事务日志的工作原理。
事务日志的运行线程是贯穿了众多的重要功能,包括 ACID 事务、可扩展元数据处理、时间旅行等。
每当用户执行任何修改后的命令时,Delta Lake 都会将其分解为一系列由一个或多个 action 组成的步骤。
action 是 Spark 中的概念,详情请参考我的博客——Spark Core核心概念一网打尽
这些 action 包括:
- 添加文件:它添加数据文件
- 删除文件:它删除数据文件
- 更新元数据:它更新表元数据。
- 设置事务:它记录了创建带有 ID 的微批处理的结构流作业
- 更改协议:通过将 Delta Lake 传输到最新的安全协议来提高安全性。
- 提交信息:它包含有关提交的信息。
版权归原作者 Shockang 所有, 如有侵权,请联系我们删除。