
文章目录
原理
Hudi 通过索引机制提供高效的 upserts,具体是将给定的 hoodie key(record key(记录键) + partition path)与文件 id(文件组)建立唯一映射。这种映射关系,数据第一次写入文件后保持不变,
所以,一个 FileGroup 包含了一批 record 的所有版本记录。Index 用于区分消息是 INSERT 还是 UPDATE。
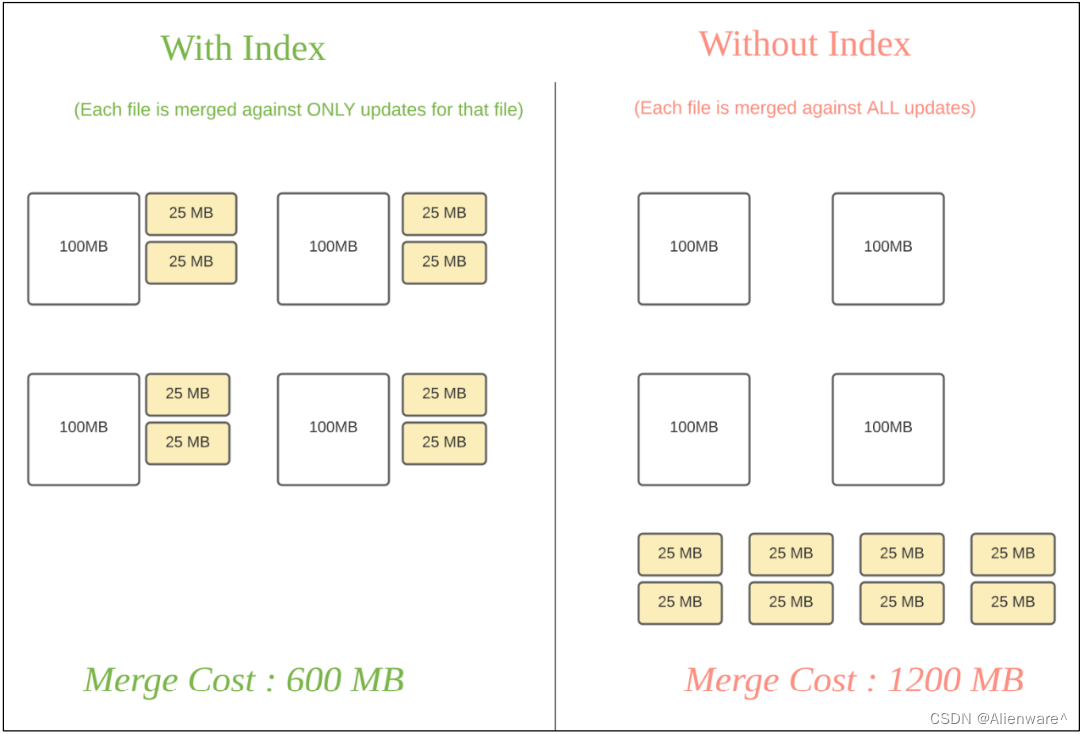
Hudi 为了消除不必要的读写,引入了索引的实现。在有了索引之后,更新的数据可以快速被定位到对应的 File Group。上图为例,白色是基本文件,黄色是更新数据,有了索引机制,可以做到:避免读取不需要的文件、避免更新不必要的文件、无需将更新数据与历史数据做分布式关联,只需要在 File Group 内做合并。
索引选项
索引选项原理优点缺点Bloom Index默认配置,使用布隆过滤器 来判断记录存在与否,也可 选使用record key的范围裁剪 需要的文件效率高,不依赖外部 系统,数据和索引保 持一致性因假阳性问题,还 需回溯原文件再查 找一遍Simple Index把 update/delete 操作的新数 据和老数据进行 join实现最简单,无需额 外的资源性能比较差HBase Index把 index 存放在 HBase 里面。 在插入 File Group 定位阶段 所 有 task 向 HBase 发 送 Batch Get 请求,获取 Record Key 的 Mapping 信息对于小批次的 keys, 查询效率高需要外部的系统, 增加了运维压力Flink State-based IndexHUDI 在 0.8.0 版本中实现 的 Flink witer,采用了 Flink的 state 作为底层的 index 存储,每个 records 在写入之前都会先计算目标 bucket ID。不 同 于 BloomFilter Index,避免了每次重复的文件 index 查找Flink是基于状态计算,如果索引数据特别大,进一步影响Flink的CK,另一部分会影响Flink资源的使用,可以进行状态调优
注意:Flink 只有一种 state based index(和 bucket_index),其他 index 是 Spark 可选配置。
全局索引与非全局索引
全局索引:全局索引在全表的所有分区范围下强制要求键的唯一性,也就是确保对给定的键有且只有一个对应的记录。全局索引提供了更强的保证,但是随着表增大,update/delete 操作损失的性能越高,因此更适用于小表。
非全局索引:默认的索引实现,只能保证数据在分区的唯一性。非全局索引依靠写入器为同一个记录的 update/delete 提供一致的分区路径,同时大幅提高了效率,更适用于大表。从 index 的维护成本和写入性能的角度考虑,维护一个 global index 的难度更大,对写入性能的影响也更大,所以需要 non-global index。
HBase 索引本质上是一个全局索引,bloom 和 simple index 都有全局选项:
- hoodie.index.type=GLOBAL_BLOOM
- hoodie.index.type=GLOBAL_SIMPLE
索引的选择策略
1)对事实表的延迟更新
许多公司会在 NoSQL 数据存储中存放大量的交易数据。例如共享出行的行程表、股票买卖记录的表、和电商的订单表。这些表通常一直在增长,且大部分的更新随机发生在较新的记录上,而对旧记录有着长尾分布型的更新。这通常是源于交易关闭或者数据更正的延迟性。换句话说,大部分更新会发生在最新的几个分区上而小部分会在旧的分区。
对于这样的作业模式,布隆索引就能表现地很好,因为查询索引可以靠设置得当的布隆过滤器来裁剪很多数据文件。另外,如果生成的键可以以某种顺序排列,参与比较的文件数会进一步通过范围裁剪而减少。Hudi 用所有文件的键域来构造区间树,这样能来高效地依据输入的更删记录的键域来排除不匹配的文件。
为了高效地把记录键和布隆过滤器进行比对,即尽量减少过滤器的读取和均衡执行器间的工作量,Hudi 缓存了输入记录并使用了自定义分区器和统计规律来解决数据的偏斜。有时,如果布隆过滤器的假阳性率过高,查询会增加数据的打乱操作。Hudi 支持动态布隆过滤器(设置 hoodie.bloom.index.filter.type=DYNAMIC_V0)。它可以根据文件里存放的记录数量来调整大小从而达到设定的假阳性率。
2)对事件表的去重
事件流无处不在。从 Apache Kafka 或其他类似的消息总线发出的事件数通常是事实表大小的 10-100 倍。事件通常把时间(到达时间、处理时间)作为首类处理对象,比如物联网的事件流、点击流数据、广告曝光数等等。由于这些大部分都是仅追加的数据,插入和更新只存在于最新的几个分区中。由于重复事件可能发生在整个数据管道的任一节点,在存放到数据湖前去重是一个常见的需求。
总的来说,低消耗去重是一个非常有挑战的工作。虽然可以用一个键值存储来实现去重(即 HBase 索引),但索引存储的消耗会随着事件数增长而线性增长以至于变得不可行。事实上,有范围裁剪功能的布隆索引是最佳的解决方案。我们可以利用作为首类处理对象的时间来构造由事件时间戳和事件 id(event_ts+event_id)组成的键,这样插入的记录就有了单调增长的键。这会在最新的几个分区里大幅提高裁剪文件的效益。
3)对维度表的随机更删
正如之前提到的,如果范围比较不能裁剪许多文件的话,那么布隆索引并不能带来很好
的效益。在这样一个随机写入的作业场景下,更新操作通常会触及表里大多数文件从而导致布隆过滤器依据输入的更新对所有文件标明阳性。最终会导致,即使采用了范围比较,也还是检查了所有文件。使用简单索引对此场景更合适,因为它不采用提前的裁剪操作,而是直接和所有文件的所需字段连接。如果额外的运维成本可以接受的话,也可以采用 HBase 索引,其对这些表能提供更加优越的查询效率。
当使用全局索引时,也可以考虑通过设置 hoodie.bloom.index.update.partition.path=true 或
hoodie.simple.index.update.partition.path=true 来处理 的情况;例如对于以所在城市分区的用户表,会有用户迁至另一座城市的情况。这些表也非常适合采用 Merge-On-Read 表型。
版权归原作者 Alienware^ 所有, 如有侵权,请联系我们删除。