
HDFS完全分布式集群搭建详细步骤:
一 步骤框架
前期准备工作(准备3台虚拟机)
----将默认主机名(hostname)修改为node01、node02、node03。 ----修改每台机器/etc/hosts文件配置环境工作
----分别修改Hadoop-env.sh和yarn-env.sh
----修改核心配置文件core-site.xml
----修改核心配置文件hdfs-site.xml
----修改核心配置文件yarn-site.xml
----修改核心配置文件mapred-site.xml
----修改配置文件slaves文件
注:这四个配置文件都存放在/opt/software/hadoop/hadoop-2.9.2这个路径下,我们需要在这个路径下去修改这些配置文件。Hadoop的安装版本是Hadoop-2.9.2
二 详细配置过程(傻瓜式配置过程)
1.检查当前环境
----网络配置
----主机名配置
----主机名映射
----防火墙与selinux的关闭
----ssh免密
----JDK的安装
注:具体详见下文
2.开始配置操作
----创建安装目录
cd /opt
mkdir software
cd software
mkdir hadoop
cd hadoop/
mkdir hdfs
cd hdfs/
mkdir data
mkdir name
mkdir tmp
----返回hadoop目录上传文件
cd /opt/software/hadoop/

----安装lrzsz插件
yum -y install lrzsz

----rz#上传hadoop-2.9.2.tar.gz(或者直接将压缩包拖拽进命令行)

----将上传的文件进行解压
tar -xvzf hadoop-2.9.2.tar.gz
----配置HADOOP HOME的环境变量
vi /etc/profile
----打开配置文件后将以下代码键入最底部
export HADOOP_HOME=/opt/software/hadoop/hadoop-2.9.2
export PATH=${PATH}:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
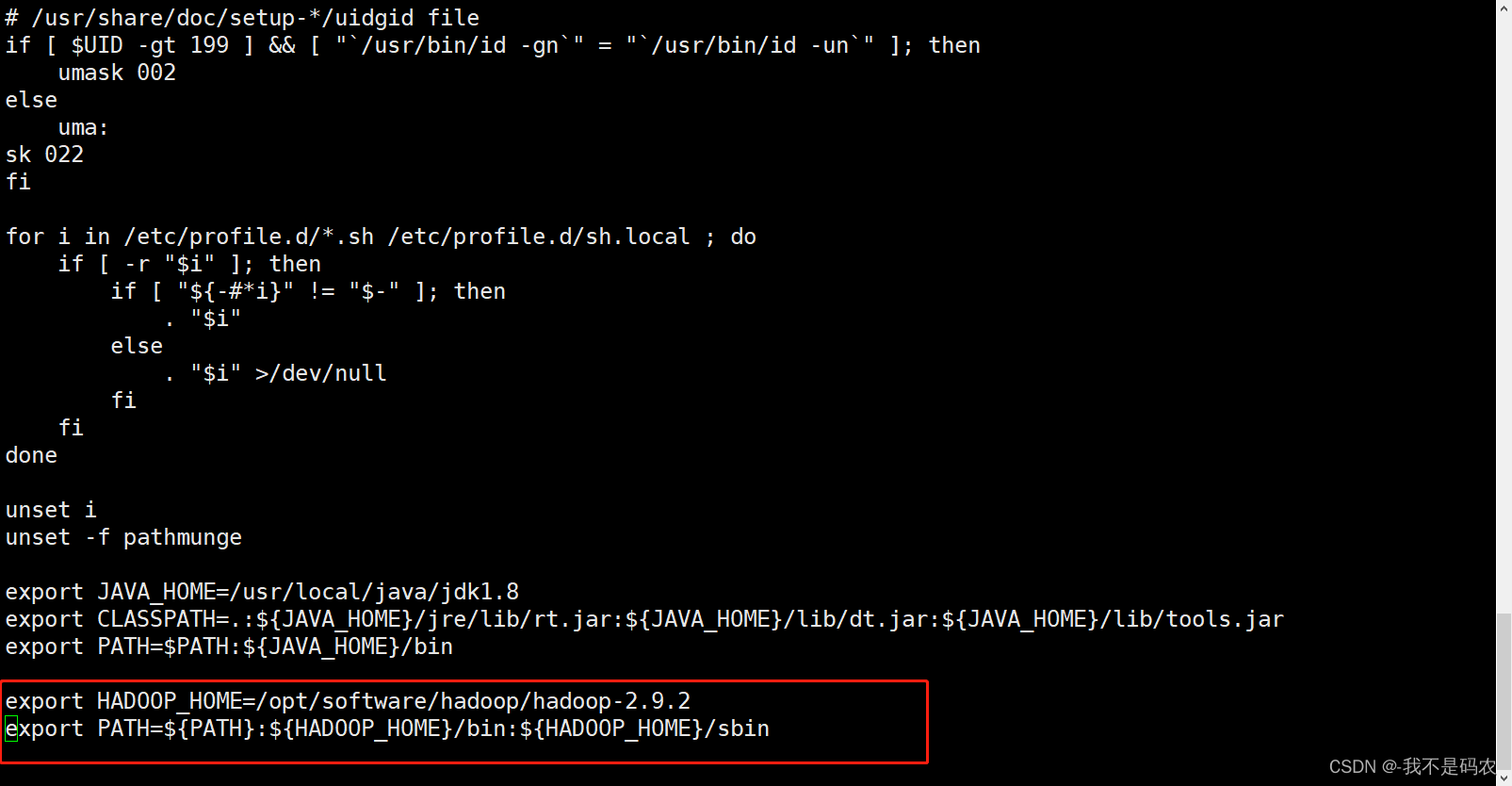
----刷新配置文件
source /etc/profile
----测试hadoop是否安装成功
hadoop version

----配置hadoop-env.sh(仅修改JAVA_HOME和HADOOP_CONF_DIR的值,其他配置不变)
----先cd进入Hadoop路径
cd /opt/software/hadoop/hadoop-2.9.2/etc/hadoop/
----进入hadoop-env.sh配置文件
vi hadoop-env.sh
----配置为:
export JAVA_HOME=/usr/local/java/jdk1.8
export HADOOP_CONF_DIR=/opt/software/hadoop/hadoop-2.9.2/etc/hadoop
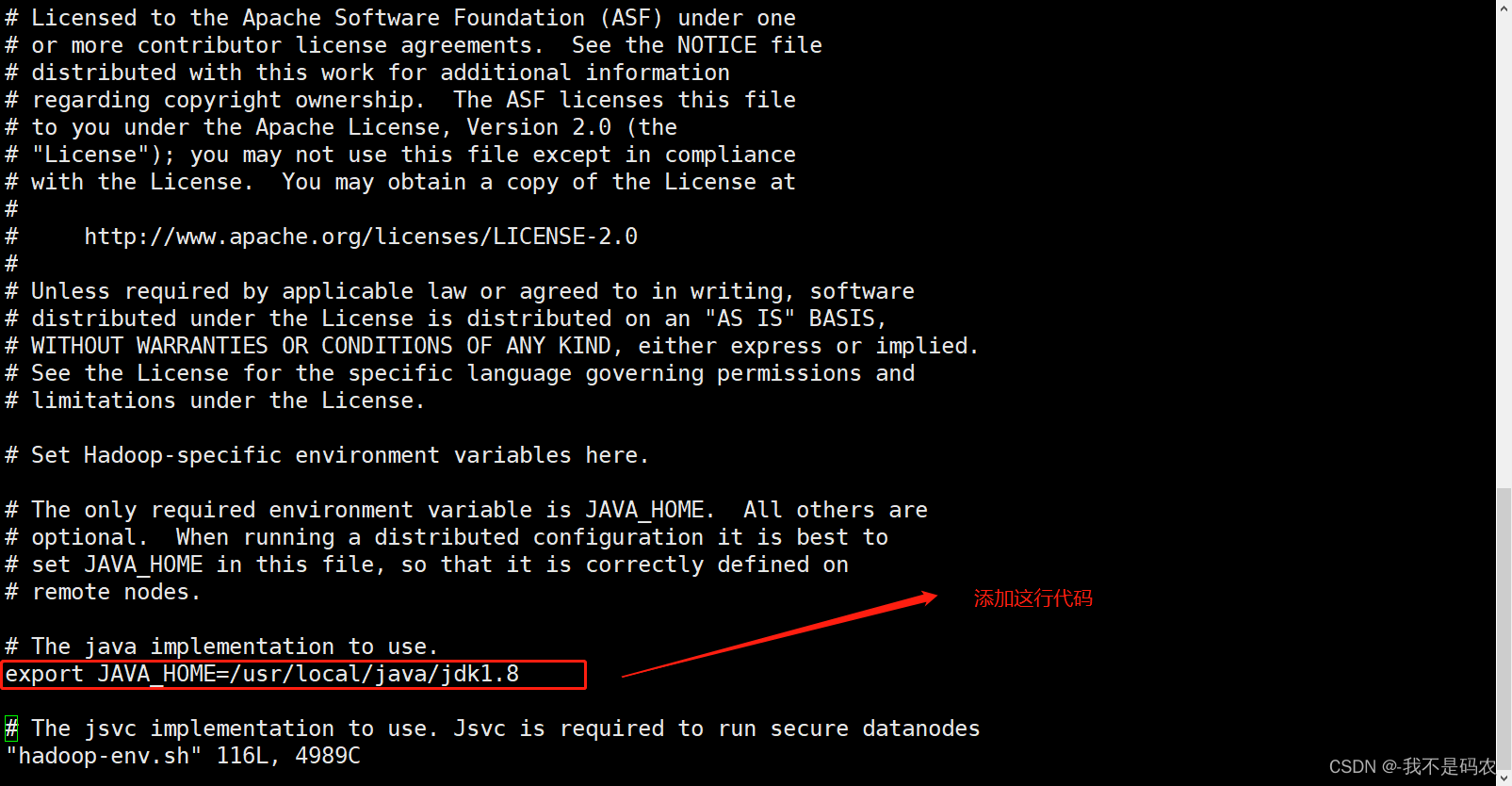

----配置yarn-env.sh
----进入yarn-env.sh配置文件
vi yarn-env.sh
----找到# export JAVAHOME=/home/y/libexec/jdk1.6.0/在该代码的下一行添加以下配置(注:此配置为新增值,无需修改其他配置)
export JAVA_HOME=/usr/local/java/jdk1.8
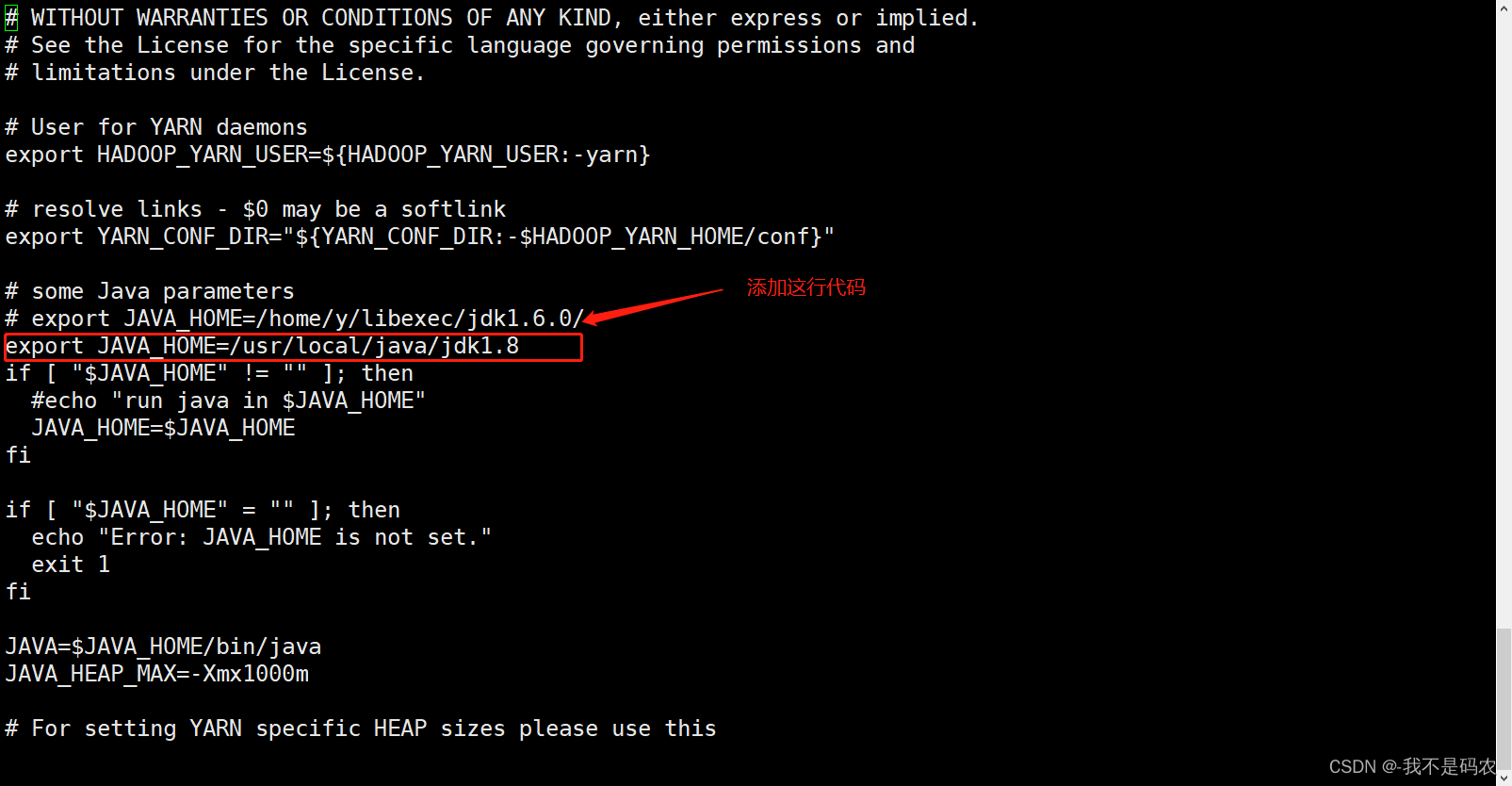
----配置core-site.xml
----进入core-site.xml配置文件
vi core-site.xml
----在文件底部的<configuration> </configuration>之间添加以下代码
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/software/hadoop/hdfs/tmp</value>
</property>
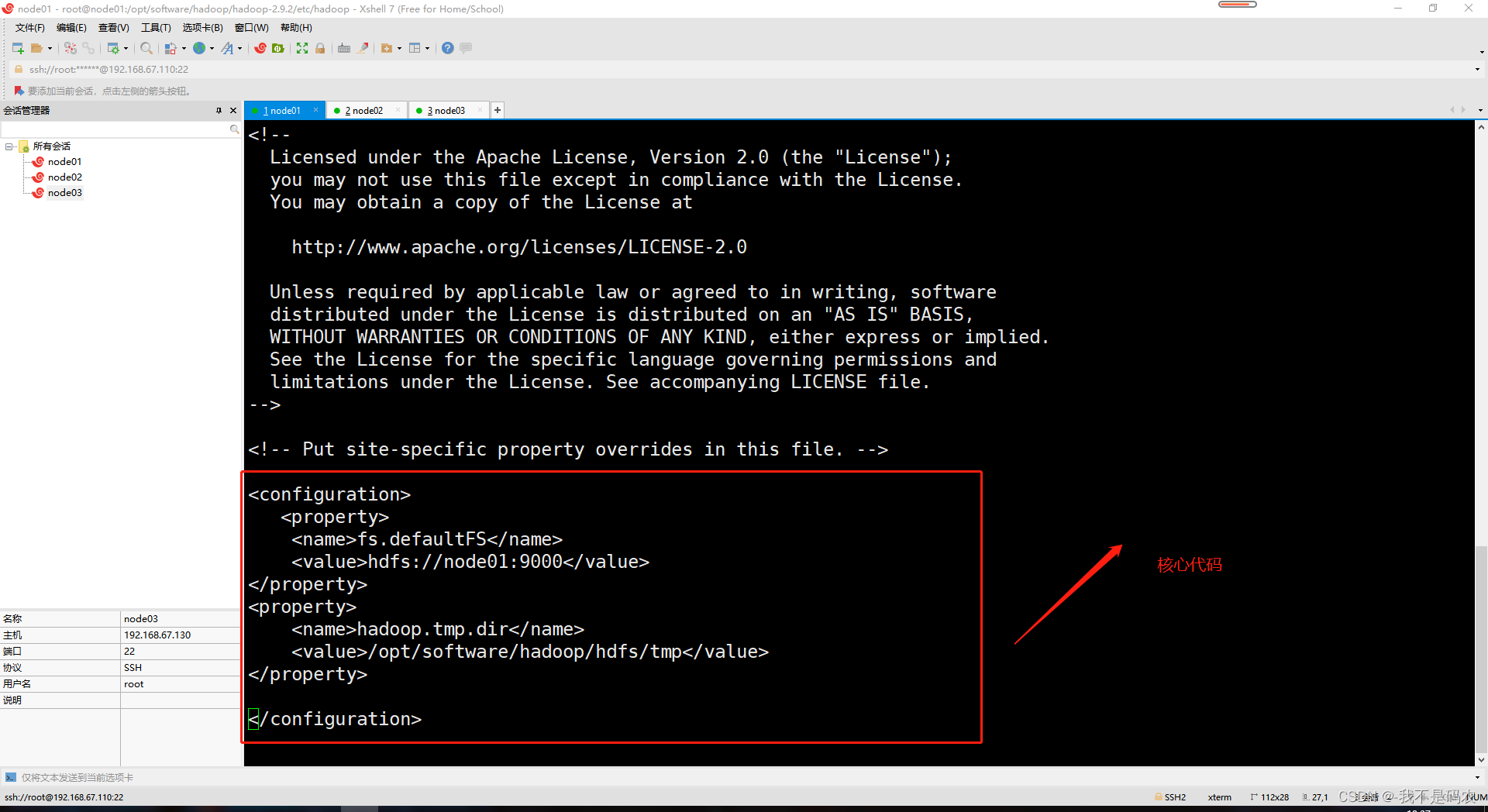
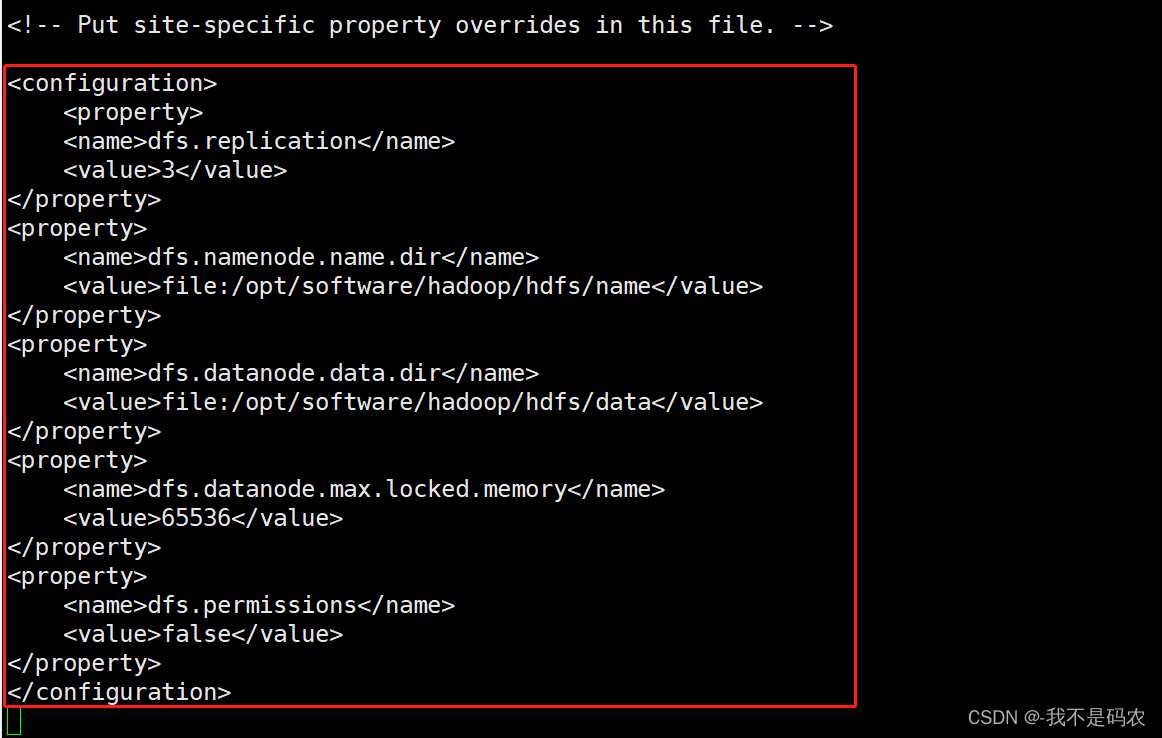
----配置hdfs-site.xml
----进入hdfs-site.xml配置文件
vi hdfs-site.xml
----在文件底部的<configuration> </configuration>之间添加以下代码
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/software/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/software/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.datanode.max.locked.memory</name>
<value>65536</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
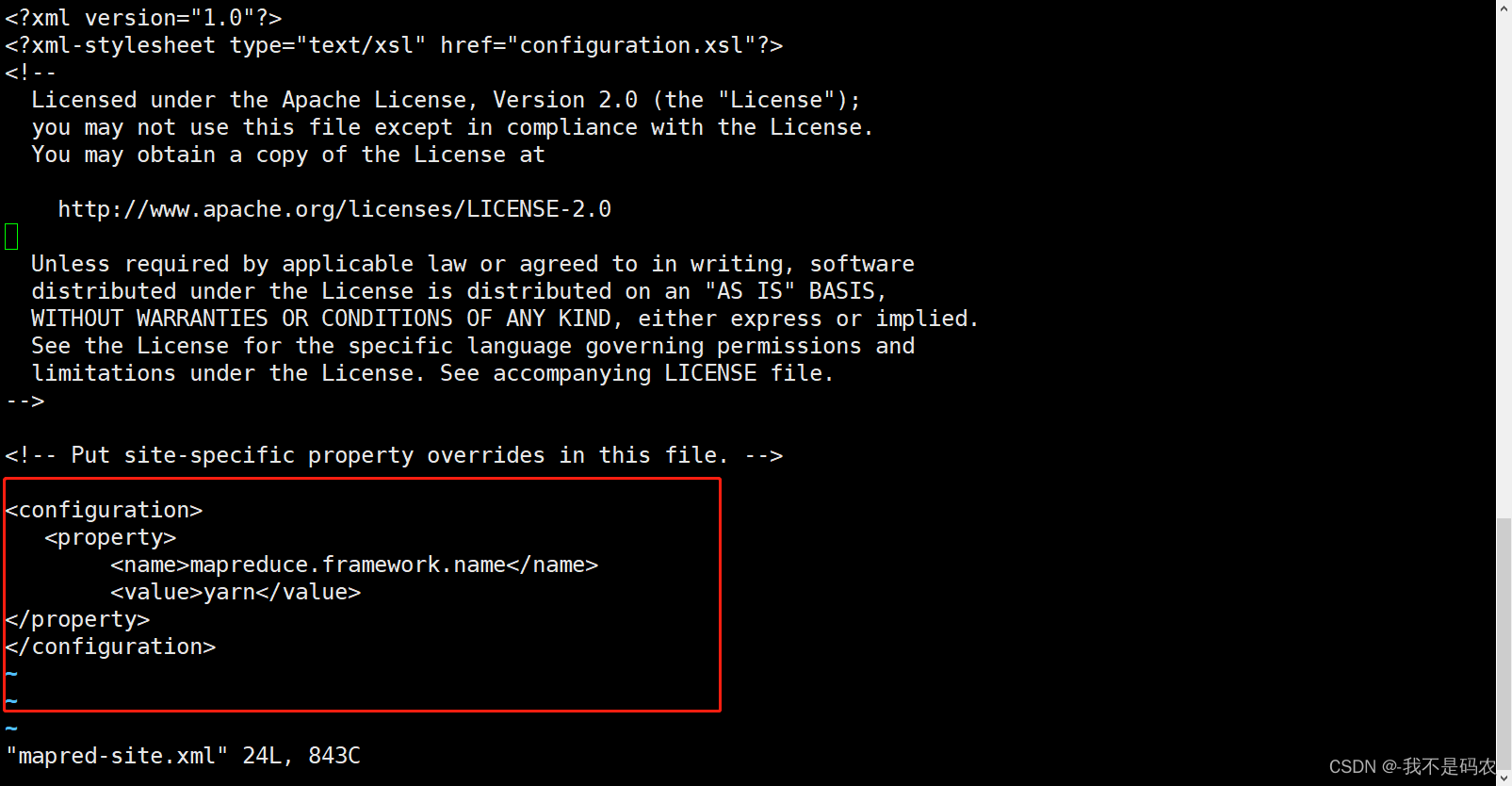
----配置mapred-site.xml
----将mapred-site.xml.template复制并重命名为mapred-site.xml文件进行配置
cp mapred-site.xml.template mapred-site.xml
----进入mapred-site.xmll配置文件
vi mapred-site.xml
----在文件底部的<configuration> </configuration>之间添加以下代码
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
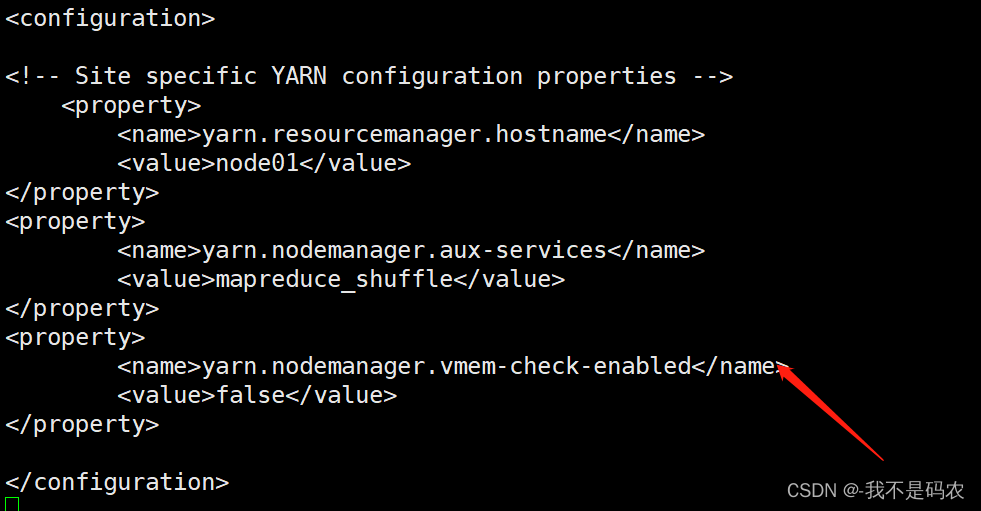
----配置yarn-site.xml
----进入yarn-site.xml配置文件
vi yarn-site.xml
----在文件底部的<configuration> </configuration>之间添加以下代码
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
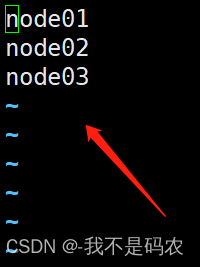
----配置三台主机名(原主机名为hostname)
vi slaves
----配置同步信息
----在node02和node03上执行以下命令
cd /opt/
mkdr software
----将node01上的配置文件分发同步到node02和node03上(使用scp命令进行同步)
cd /opt/software/
scp -r hadoop/ node02:$PWD
scp -r hadoop/ node03:$PWD


 显示这些表示分发成功了!
显示这些表示分发成功了!
----配置环境变量
----分别在node02和node03上执行以下命令
cd /opt/software/hadoop/hadoop-2.9.2/etc/hadoop/


vi /etc/profile
----在文件底部添加以下代码
export HADOOP_HOME=/opt/software/hadoop/hadoop-2.9.2
export PATH=${PATH}:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
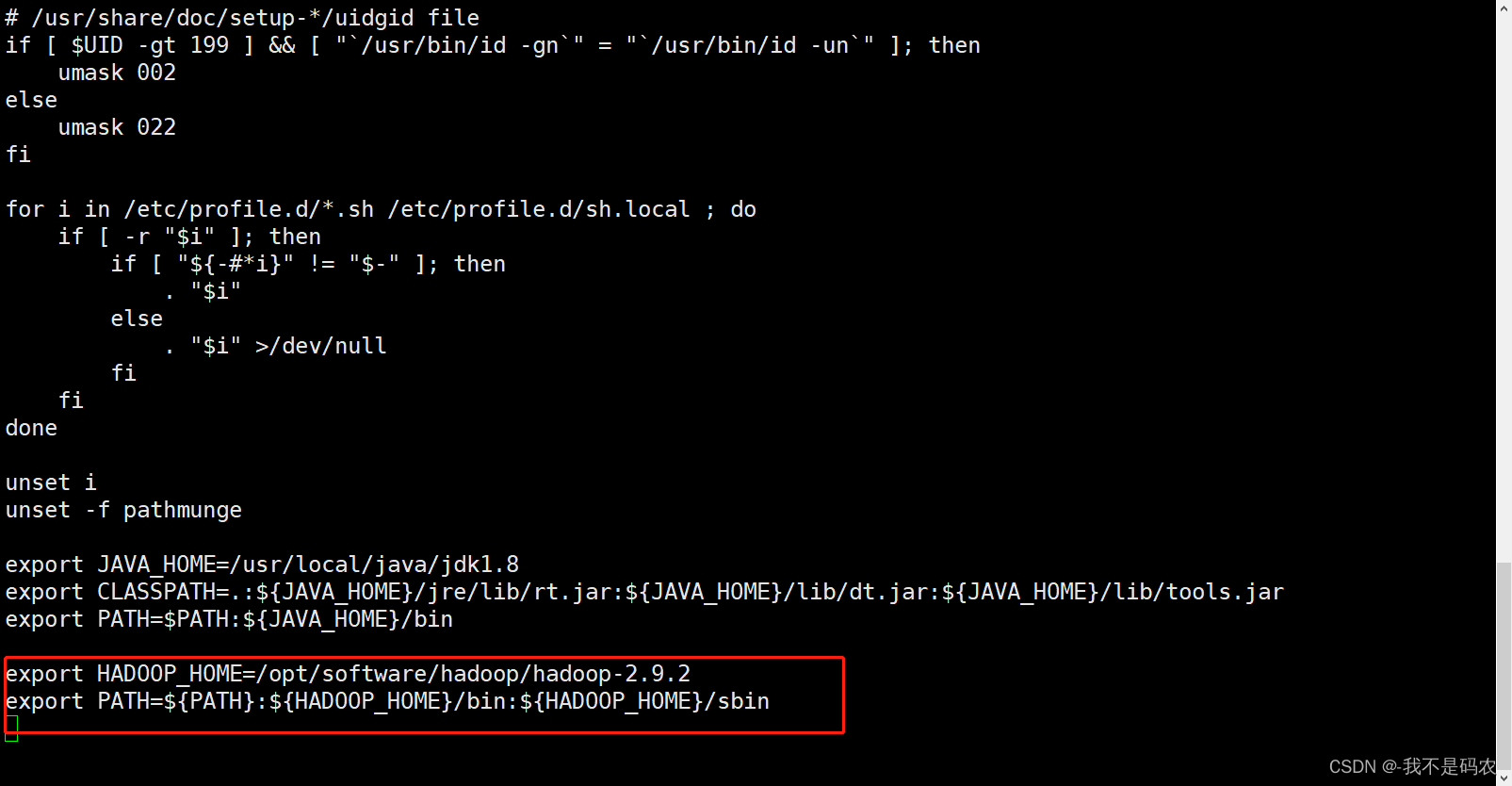
----配置完成后分别在node02和node03上刷新配置文件
source /etc/profile
三 集群的启动
1.格式化集群
----在node01上进行格式化
hdfs namenode -format

2.启动集群(仅在node01上启动)
start-dfs.sh
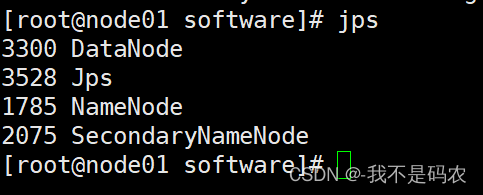
3.查看启动情况
----在node01,node02,node03上分别查看进程启动情况
jsp
----在浏览器上访问web管理台:
----http://192.168.67.110:50070/
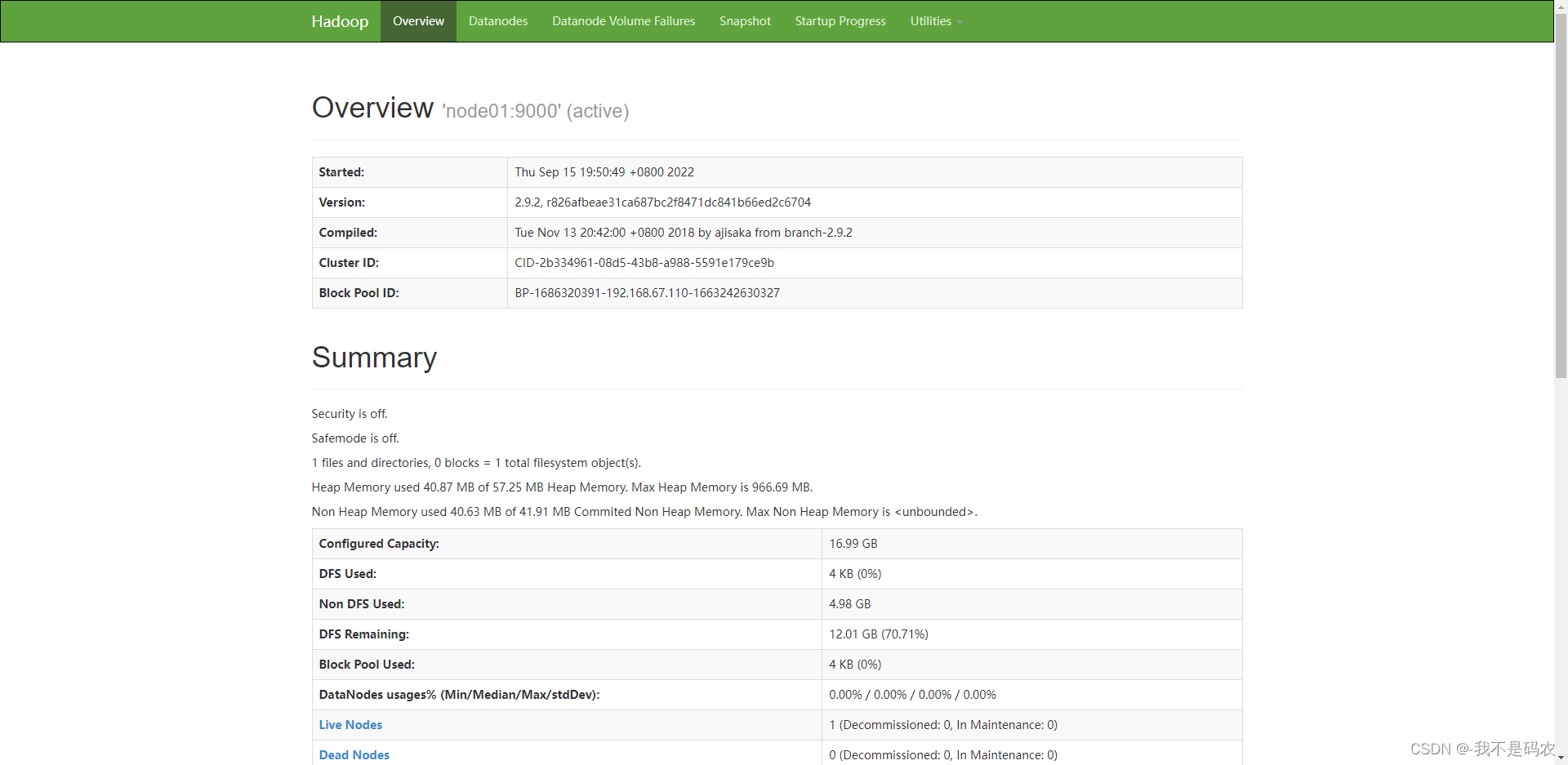
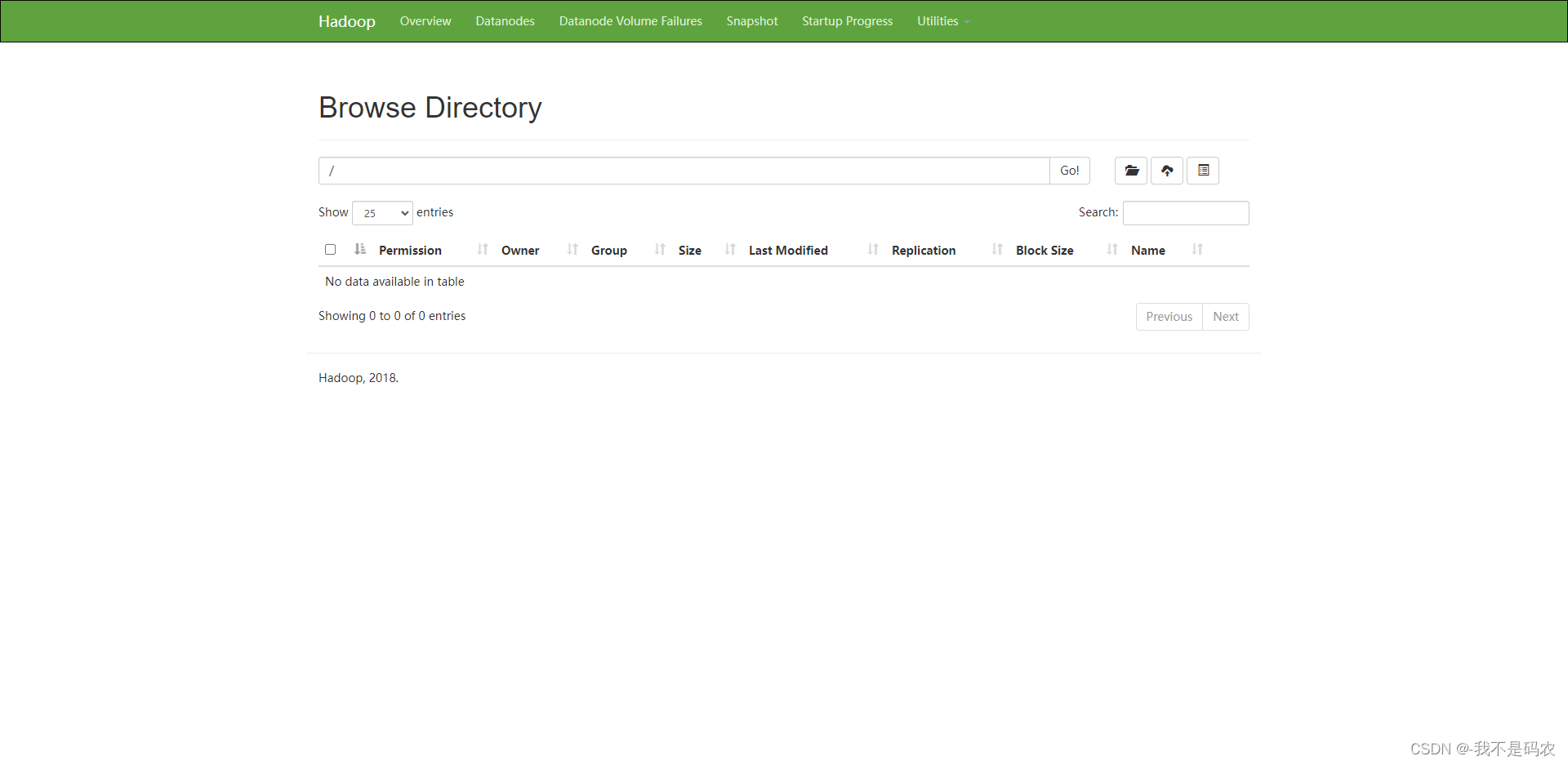
4.上传文件测试
----在node01的hadoop路径下创建目录(test)
cd /opt/software/hadoop/hadoop-2.9.2/etc/hadoop/
hdfs dfs -mkdir /test

----上传文件到node01
cd /opt/
mkdir testData
cd testData/
mkdir hdfs
cd hdfs
----rz #上传hadoop-2.9.2.tar.gz
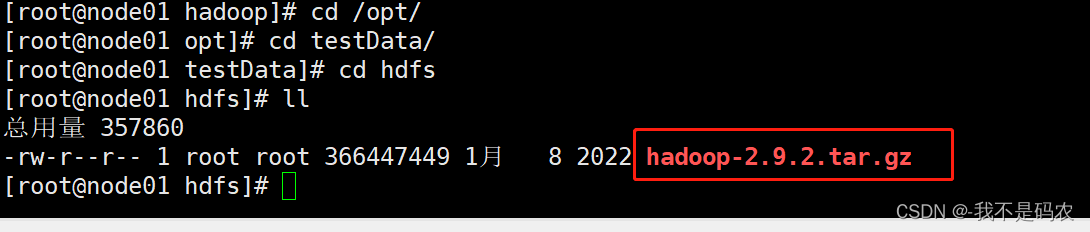
----把hadoop-2.9.2.tar.gz上传到分布式文件系统
hdfs dfs -put hadoop-2.9.2.tar.gz /test

----文件上传成功后查看节点情况

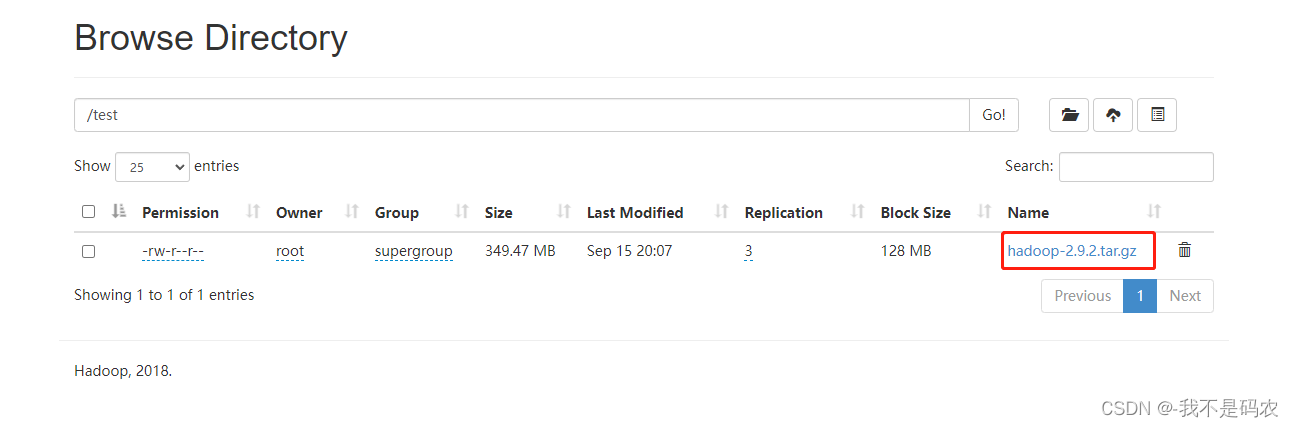
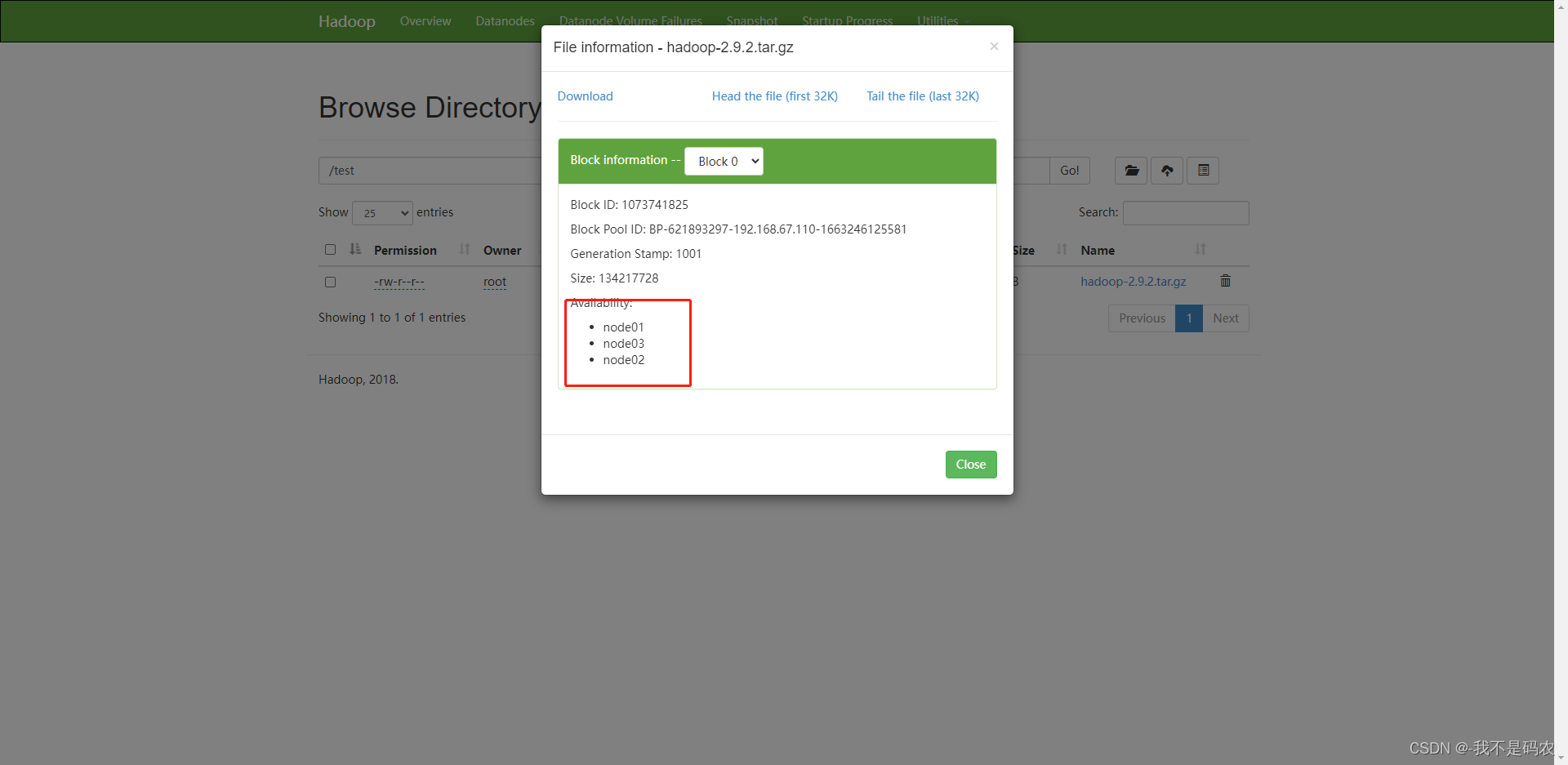
大功告成!!!!!!
四 HDFS完全分布式集群搭建过程中常见问题总结与解决方法
- jps后不显示DataNode的解决办法:(多次格式化也可能会导致此状况的出现)
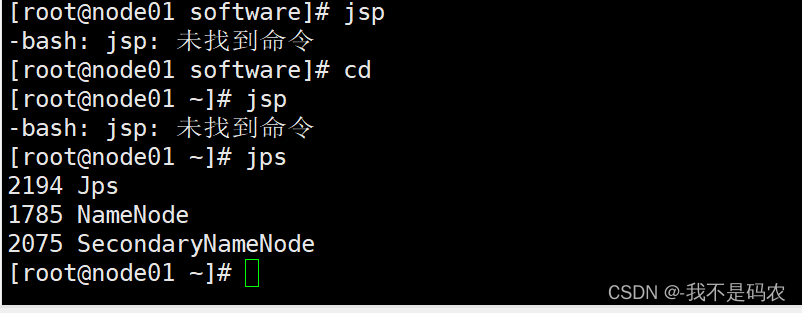
去到hadoop路径下,找到data后删除
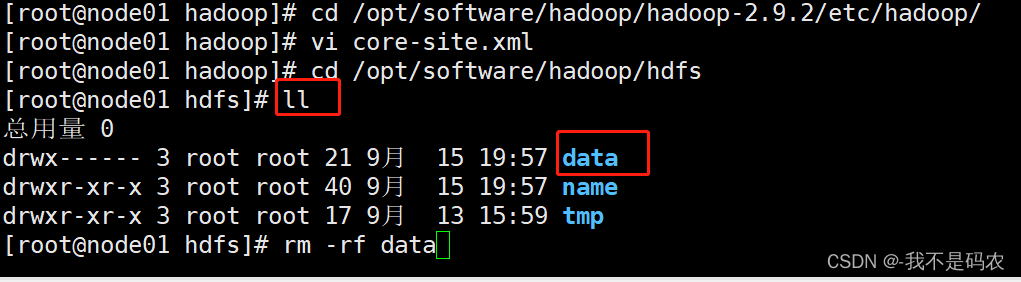
分别在node02,node03上分别执行上述操作;
执行完毕后在node01中重新执行格式化操作
hdfs namenode -format

在node01中启动集群,并再次键入jps查看
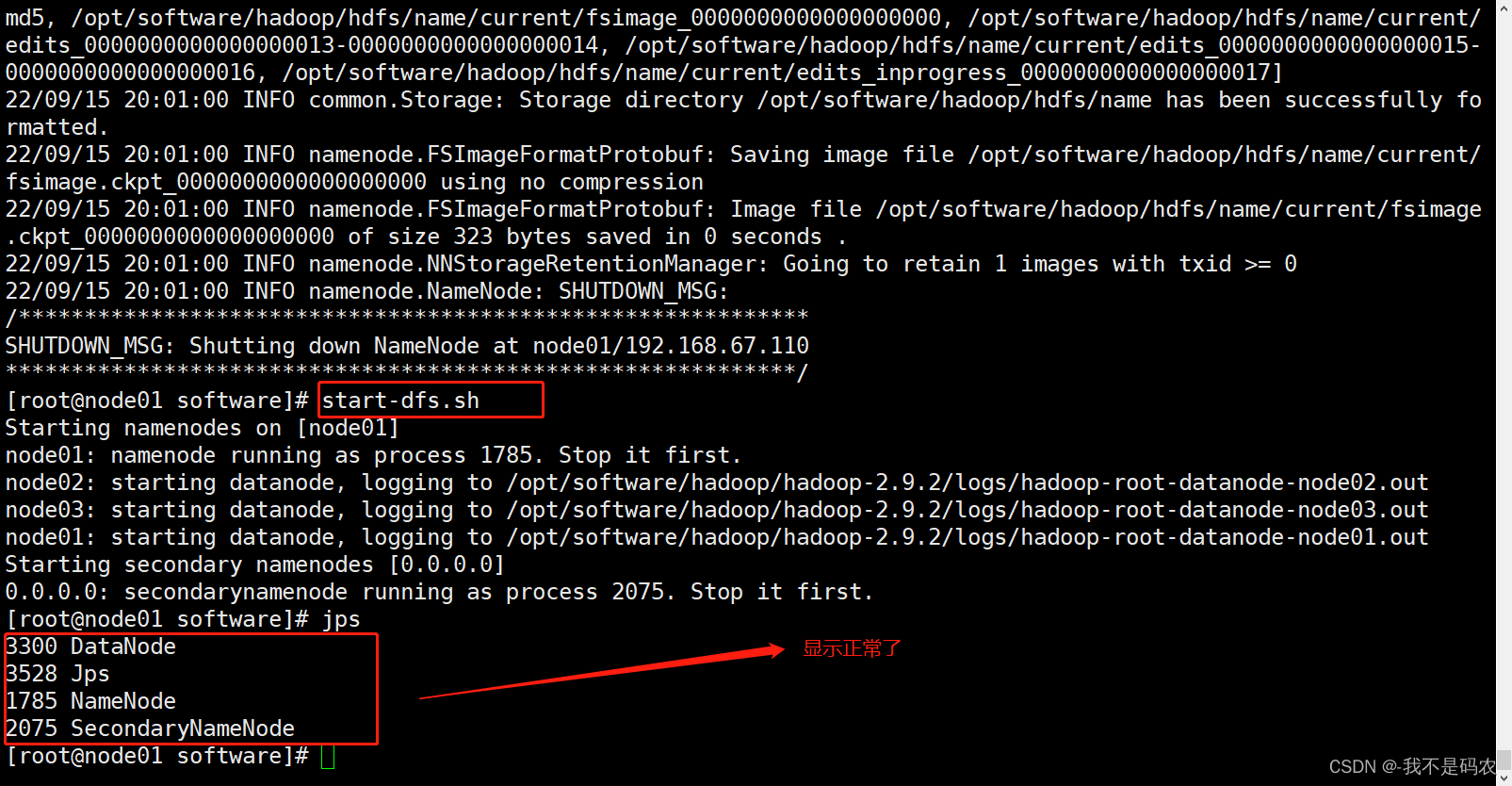
在node02和node03中也分别键入jps(正常结果如下图所示)
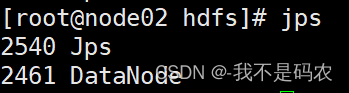
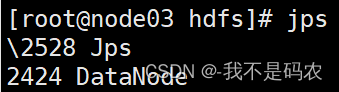
- 下载yum makecache出现拒绝连接问题
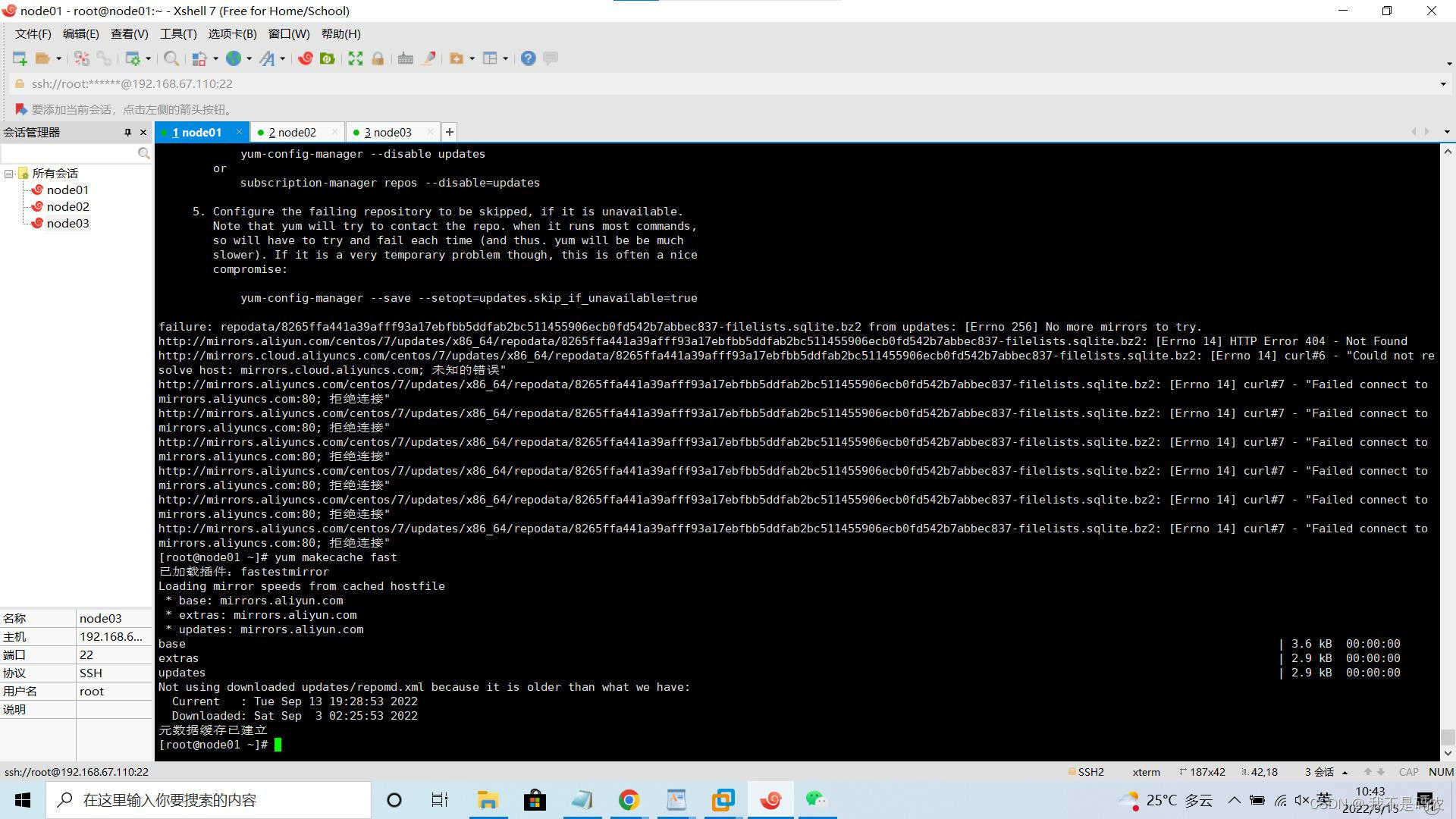
在命令行键入以下代码
yum makecache fast
显示元数据缓存以建立则表示问题解决。
本文转载自: https://blog.csdn.net/qq_53025556/article/details/126864631
版权归原作者 -我不是码农 所有, 如有侵权,请联系我们删除。
版权归原作者 -我不是码农 所有, 如有侵权,请联系我们删除。