
文章目录
导入
之前使用过opencv+tess4j实现对身份证识别的内容,但是这个方案的局限性很大,图片歪的还要调整图片的角度,而且识别的准确率不是很让人满意。然后就发这个基于深度学习框架的PaddleOCR,使用这个完全不需要担心图片歪与不歪的,只要不是歪得太离谱就可以了,发现这个正确率不是一般的高。以下是安装过程
PaddleOCR官网
PaddleOCR:飞桨PaddlePaddle-源于产业实践的开源深度学习平台
gitee地址:PaddleOCR: 基于飞桨的OCR工具库,包含总模型仅8.6M的超轻量级中文OCR,单模型支持中英文数字组合识别、竖排文本识别、长文本识别。同时支持多种文本检测、文本识别的训练算法。 (gitee.com)
看官网的简介:
github地址:GitHub - PaddlePaddle/PaddleOCR: Awesome multilingual OCR toolkits based on PaddlePaddle (practical ultra lightweight OCR system, support 80+ languages recognition, provide data annotation and synthesis tools, support training and deployment among server, mobile, embedded and IoT devices)
安装
这个安装过程网上一大堆,具体百度就能直接搜出来。这里我把自己的安装过程记录一下,方便以后能够用到。这里建议使用Anaconda进行安装,因为Anaconda内置了很多的工具类,而且官网也是建议使用Anaconda安装。具体的安装可以根据官网提供的教程进行安装:Windows 下的 Conda 安装-使用文档-PaddlePaddle深度学习平台 注意了,虽然我使用的是Anaconda,但是只是使用Anaconda安装Python的虚拟环境,激活虚拟环境之后,我都是使用pip进行安装的,跟官网这里不一样,之所以这样,是因为我发现如果一味跟官网一样使用conda安装,会有版本兼容问题。具体看后面我给的命令函就知道了。
安装Anaconda的过程这里就不放出来了,毕竟这个就是个软件的安装过程而已,就是安装的时候需要注意,记得勾选将Anaconda添加到系统环境变量中的选项,就可以了。要想看安装过程的话,这里我找到了一篇文章:超详细Anaconda安装教程_极小白的博客-CSDN博客

进入命令行,后输入如下内容,这里顺便验证一下Anaconda是否安装成功了。
创建虚拟环境
首先根据具体的 Python 版本创建 Anaconda 虚拟环境,PaddlePaddle 的 Anaconda 安装支持 3.7 - 3.11 版本的 Python 安装环境。Windows 下的 Conda 安装-使用文档-PaddlePaddle深度学习平台、开始使用_飞桨-源于产业实践的开源深度学习平台 (paddlepaddle.org.cn)
# 这里我使用了python3.10
conda create --name paddle_env2 python=3.10# 这里可以使用清华源,可以加速下载,推荐使用清华源下载
conda create --name paddle_env2 python=3.10--channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
从上面两个命令行可以看出,在需要下载的命令中,如果在命令行后面加入镜像源的地址,就是临时使用对应的镜像源进行下载,可以加速下载。如果不加镜像源可能下载会很慢,除非已经配置了Anaconda的全局镜像源为国内的,否则不添加临时镜像源真的会很慢!
# 这里可以使用清华源,可以加速下载,推荐使用清华源下载
conda create --name paddle_env2 python=3.10--channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/

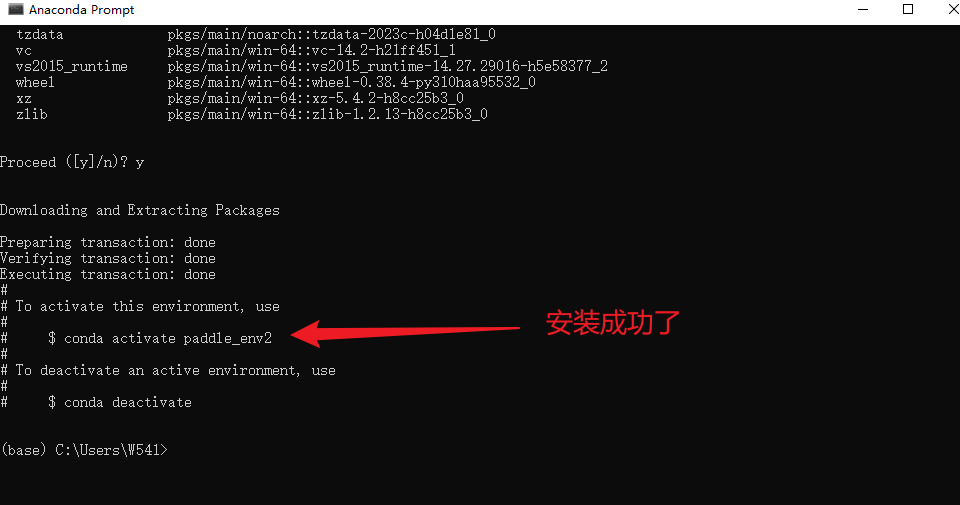
安装成功之后,我们可以在Anaconda的安装目录(Anaconda安装目录下的\envs)下找到对应的虚拟环境,如这里的paddle_env2
激活虚拟环境
激活刚创建的conda环境,在命令行中输入以下命令:具体详细看后面的截图就可以了
# 激活虚拟环境
conda activate paddle_env2
where python
# 进入对应的Python环境
python
看看一下对比图,在没有激活对应的虚拟环境之前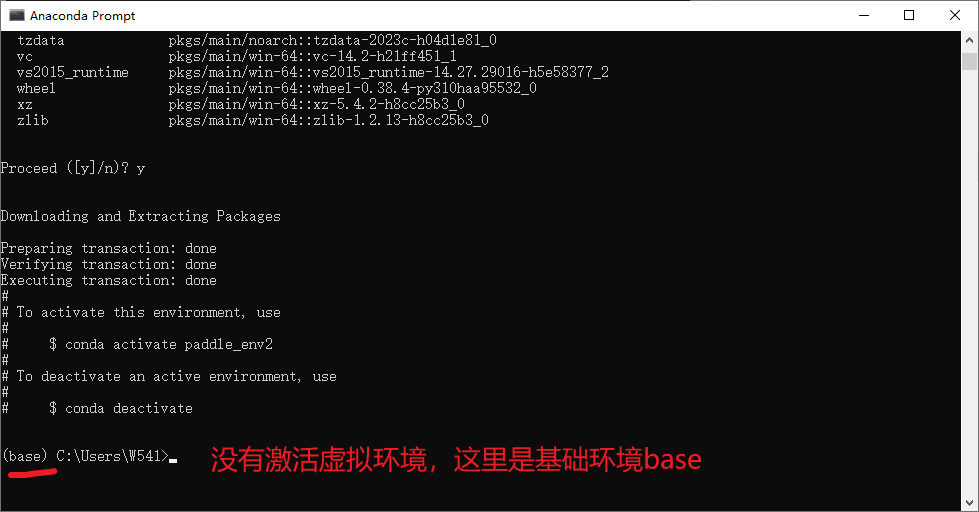

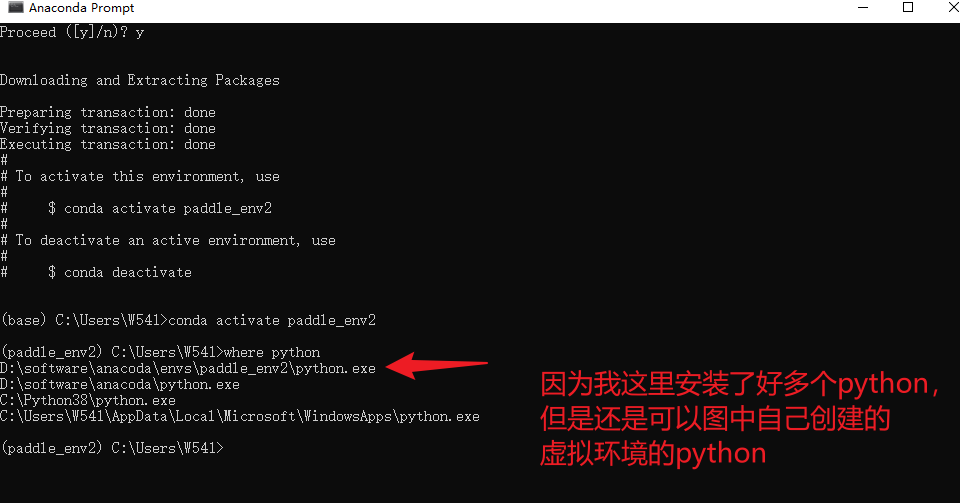
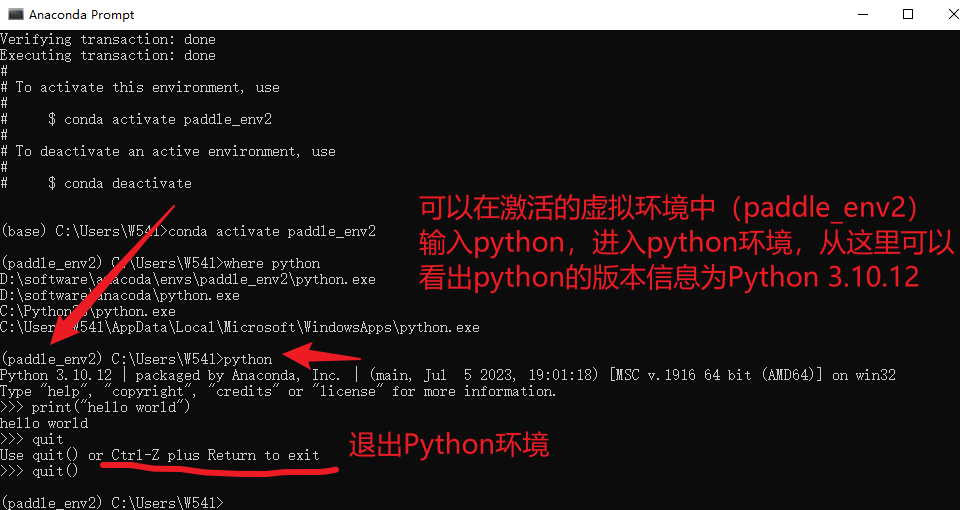
检查系统环境
确认 Python 和 pip 是 64bit,并且处理器架构是 x86_64(或称作 x64、Intel 64、AMD64)架构。下面的第一行输出的是”64bit”,第二行输出的是”x86_64(或 x64、AMD64)”即可:
python -c"import platform;print(platform.architecture()[0]);print(platform.machine())"
这里有说明:开始使用_飞桨-源于产业实践的开源深度学习平台 (paddlepaddle.org.cn)
激活虚拟环境方式2(了解)
如果我们想要把上面创建好的虚拟环境,直接复制到其他电脑,给其他人使用。则可以通过如下方式激活虚拟环境就可以了,其他人也可以正常使用。
如上面所说的,使用conda创建好虚拟环境之后,我们进入anaconda的安装目录,可以看到对应的虚拟环境,如果要在其他电脑上使用这个虚拟环境,就找到对应的虚拟环境目录复制到其他电脑上就可以了,如这里的paddle_env2等。
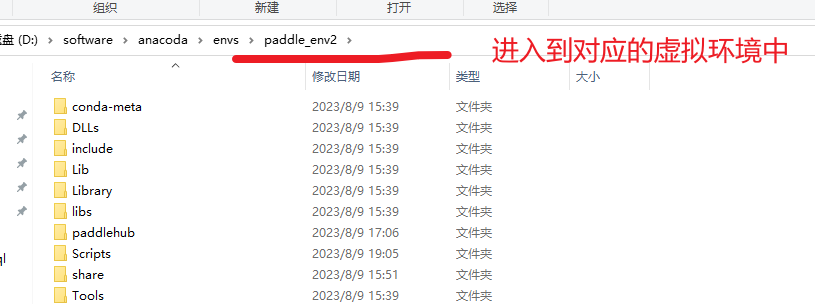

激活虚拟环境
# 激活虚拟环境,注意这里就是上面截图的文件夹paddle_env2名,同时也是上面创建的虚拟环境名
activate paddle_env2
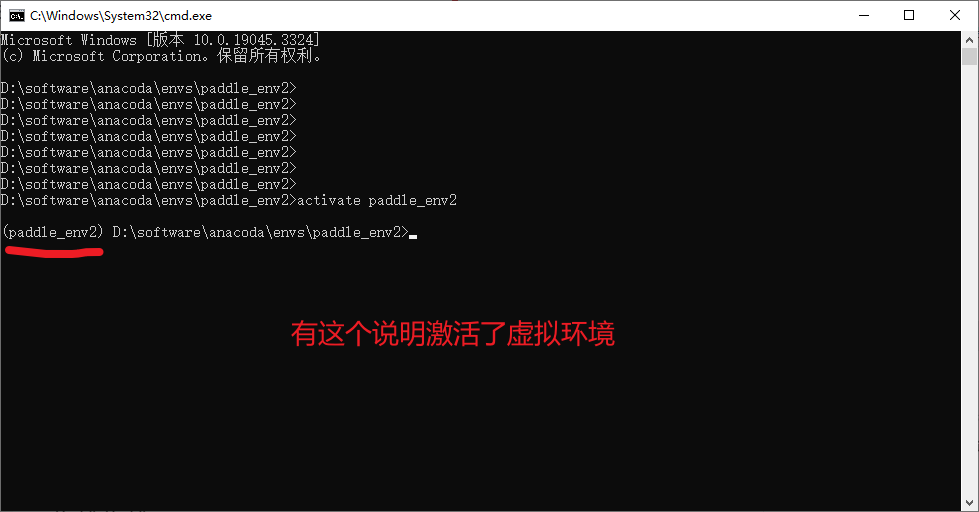

开始安装
CPU 版的 PaddlePaddle
如果您的计算机没有 NVIDIA® GPU,请安装 CPU 版的 PaddlePaddle,这里是CPU版本的PaddlePaddle
# 没有加版本号的,默认的就是新的 -i 后面跟的是百度镜像源
pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
# 加了版本号,注意是==,而不是=,至于只有一个=会出现什么问题,试一下就知道了!# -i 后面跟的是百度镜像源
pip installpaddlepaddle==2.5.1 -i https://mirror.baidu.com/pypi/simple
我这里使用没有添加版本号的
# 没有加版本号的,默认的就是新的 -i 后面跟的是百度镜像源
pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
出现Successfully installed。。。并且没有报错的情况下,说明安装成功了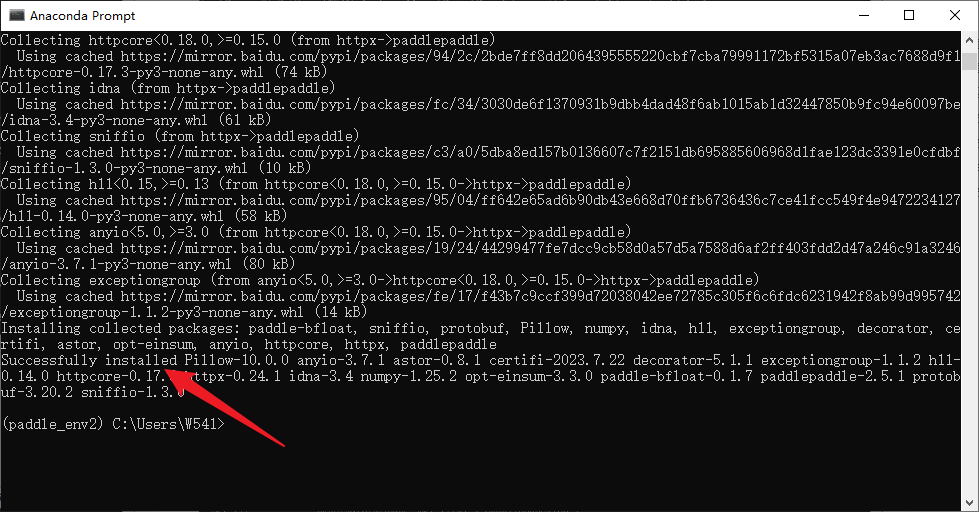 ### 验证安装
### 验证安装
安装完成后您可以使用
python
或
python3
进入 python 解释器,输入
import paddle
,再输入
paddle.utils.run_check()
如果出现
PaddlePaddle is installed successfully!
,说明您已成功安装。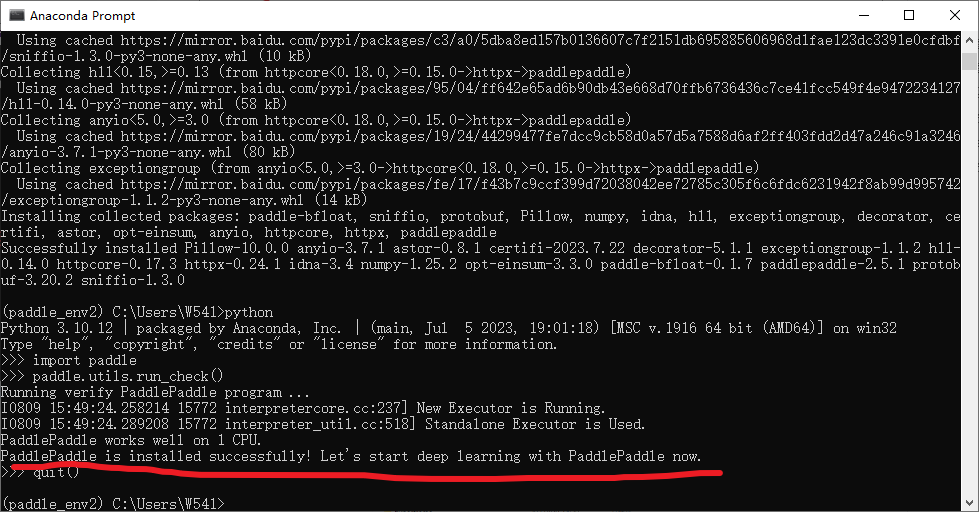
到这里PaddlePaddle就安装成功了。
安装完成后,我们可以在Anaconda安装目录的创建的虚拟环境的目录下的,Lib\site-packages下找到对应的内容
这里提一下(这里的两句不要运行),在命令行中,前面加一个–upgrade可以更新对应的内容,如下所示
pip install--upgrade paddlepaddle -i https://mirror.baidu.com/pypi/simple
如果是uninstall则是卸载对应的内容,nuinstall xxx 注意了后面,不跟镜像源。
不要运行下面这一句!不要运行下面这一句!不要运行下面这一句!不要运行下面这一句!
这里不要运行这句啊,不然运行了卸载,前面安装的paddlepaddle就白安装了,又要从新来。这里只是提一下而已。因为后面可能要用到。
pip uninstall paddlepaddle
这两个后面可能会用到!!!
PaddleOCR安装
这里有两种方式,一种是直接安装。另外一种是去官网下载解压包,然后本地进行安装。这里我两种方法都会讲到的。
直接(全局)安装PaddleOCR
这里,如果还是上面截图的Python环境,记得先退出Python环境,然后在虚拟环境中执行如下命令
pip install paddleocr -i https://mirror.baidu.com/pypi/simple
这种安装方式,相当于全局安装了,也就是在代码中可以直接导入对应的(python)包进行文字识别,注意是Python的.py文件,或者通过命令行的方式识别对应的内容。

到上面截图不动了,但是要记住,一定要等。不要关闭窗口,等待下载安装完成,出现Successfully installed …,并且没有任何报错的情况下,说明已经安装成功了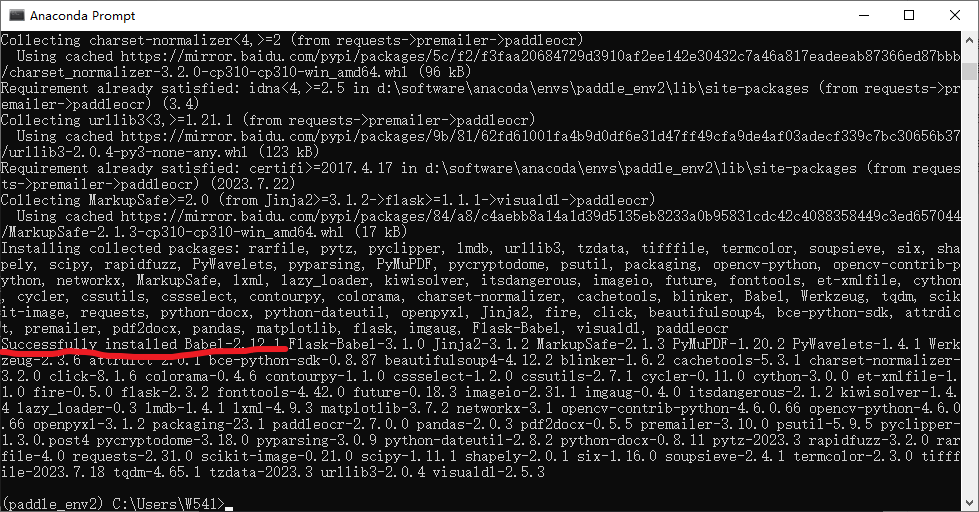
安装成功了
官方给出了两种模式,一是命令行执行,一是代码执行。准备一张带文字的图片,随便一张有文字的都行,这里不一定要是这张的。
注:图片来源于网络,如有不对的地方,请联系删除一下
命令行方式执行:
paddleocr --image_dir C:\Users\W541\Desktop\1111111111111111111111111111111111111111111\3.jpg --use_angle_clstrue--use_gpufalse
其中命令行中:C:\Users\W541\Desktop\1111111111111111111111111111111111111111111\3.jpg 这个是图片所在的路径(最好不要有中文)。–use_gpu false是不使用gpu,识别结果如下所示:
这里放一张歪的图片试一试:
paddleocr --image_dir C:\Users\W541\Desktop\1111111111111111111111111111111111111111111\4.jpg --use_angle_clstrue--use_gpufalse
其中命令行中:C:\Users\W541\Desktop\1111111111111111111111111111111111111111111\3.jpg 这个是图片所在的路径(最好不要有中文)。–use_gpu false是不使用gpu,识别结果如下所示:只要是文字,几乎都可以识别出来。如这里的相机水印,也识别出来了都
代码的方式:
python代码如下:
from paddleocr import PaddleOCR
ocr = PaddleOCR(use_angle_cls=True, use_gpu=False)# 注意这里是双斜杠,防止转义
img_path ='C:\\Users\\W541\\Desktop\\1111111111111111111111111111111111111111111\\3.jpg'
result = ocr.ocr(img_path, cls=True)for line in result:print(line)

建立Python文件之后,需要配置Python环境,就是刚才上面在anaconda中安装的虚拟环境
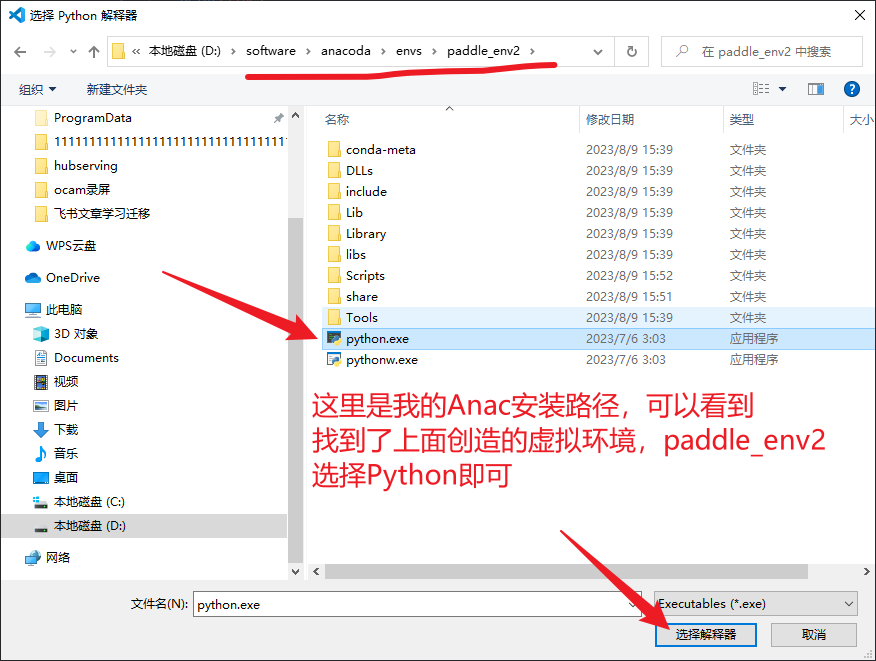
点击Vscode右下角的这里,配置为我们上面创建的虚拟环境


配置成功之后,看右下角
图片是这一张:
注:图片来源于网络,如有不对的地方,请联系删除一下





官方还提供一个标准的json结构输出数据,具体可以去官网看一下,或者百度一下。上面的数据都是列表的形式。
解压包安装(及基于PaddleHub Serving的服务部署)
在github或者gitee上面可以下载相关的解压包,解压安装包安装的目的是为了实现PaddleOCR的基于PaddleHub Serving的服务部署,让其可以通过web api的形式实现对图片文字的识别,也就是提供一个类似于RESTful API的接口,然后可以直接通过Java程序或者postman或者apifox直接将图片传入,然后识别内容的形式。
飞桨PaddlePaddle-源于产业实践的开源深度学习平台
这里使用Paddle Serving 的部署形式
gitee地址:PaddleOCR: 基于飞桨的OCR工具库,包含总模型仅8.6M的超轻量级中文OCR,单模型支持中英文数字组合识别、竖排文本识别、长文本识别。同时支持多种文本检测、文本识别的训练算法。 (gitee.com)
下载解压之后,进入到对应的文件内容中
在对应的目录下,cmd。


因为Anaconda已经配置好了系统环境变量了,所以这里可以直接使用
conda activate paddle_env2
激活我们上面安装的虚拟环境(paddle_env2)。想必这个已经很熟悉了吧
然后在当前路径下通过命令进行相关模块的安装
pip install-r requirements.txt -i https://mirror.baidu.com/pypi/simple
命令行中的requirements.txt,这里说明的是当前路径下有这个文件,也就是一个相对路径的说法。如果不是当前路径有这个,可以写绝对路径,具体看下面截图的关系说明,在下载的项目中,就有这个文件,而且cmd这里刚好也在这个目录下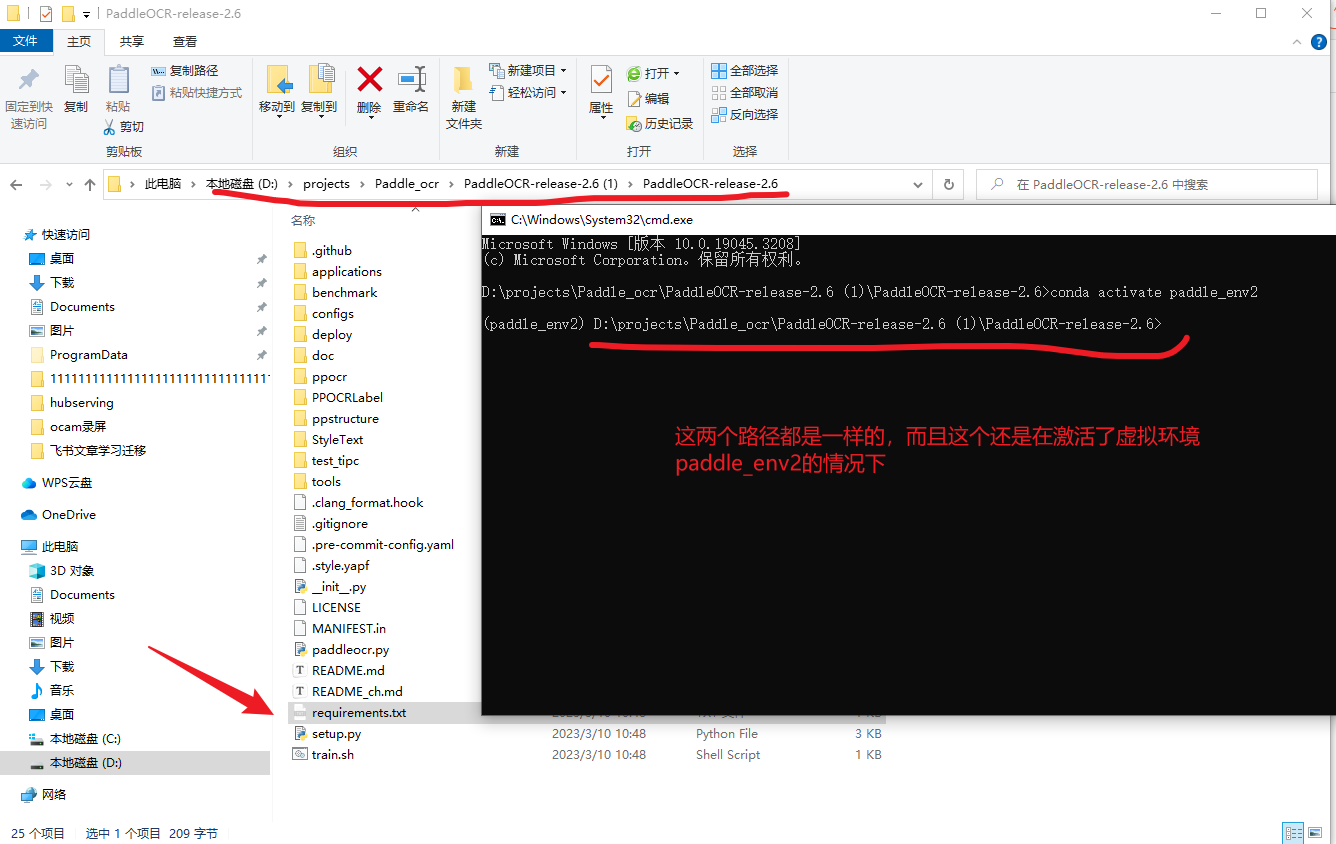
执行了上述命令之后,回车,然后就可以得到如下所示的内容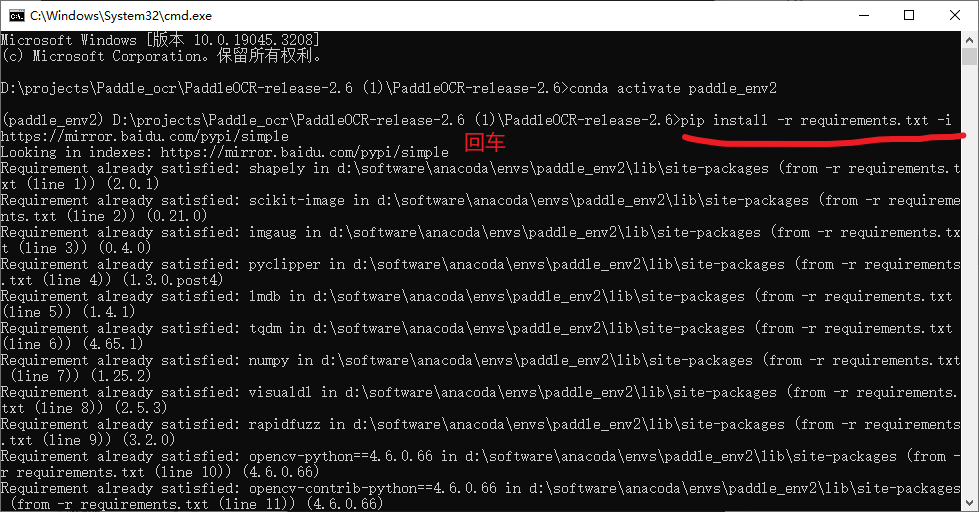
这里的安装过程可能会出现问题,这个问题还挺麻烦的。这个我后续会补充的,这个涉及到需要安装一些库内容。后续在补充吧!
注:如果出现如下所示的问题:
如发现如下报错:
No module named ‘Polygon’
直接搜索画线冒号后面那一句:
paddleocr 训练时缺少包模块Polygon · Issue #8543 · PaddlePaddle/PaddleOCR · GitHub

Microsoft Visual C++ 14.0 or greater is required. Get it with “Microsoft C++ Build Tools”:
这里说什么需要C++ 14.0的库之类的问题,我是通过Visual Studio installer这种方式解决的,加载对应的C++库


所以可能需要网络好一点了,这里下载安装好了之后,然后记得重启电脑!重启电脑!重启电脑!重启电脑!重启电脑!
重启完成之后,按照上面之前的步骤,从新到对应的位置,重新运行:一定要注意是否在之前创建的虚拟环境中,如果不在就激活到对应的虚拟环境中(
conda activate paddle_env2
),具体如下图所示的截图中有。
pip install-r requirements.txt -i https://mirror.baidu.com/pypi/simple
命令行中的requirements.txt,这里说明的是当前路径下有这个文件,也就是一个相对路径的说法。如果不是当前路径有这个,可以写绝对路径,具体看下面截图的关系说明,在下载的项目中,就有这个文件,而且cmd这里刚好也在这个目录下
执行了上述命令之后,回车,然后就可以得到如下所示的内容
当出现如下图所示的Successfully installed …就说明安装成功了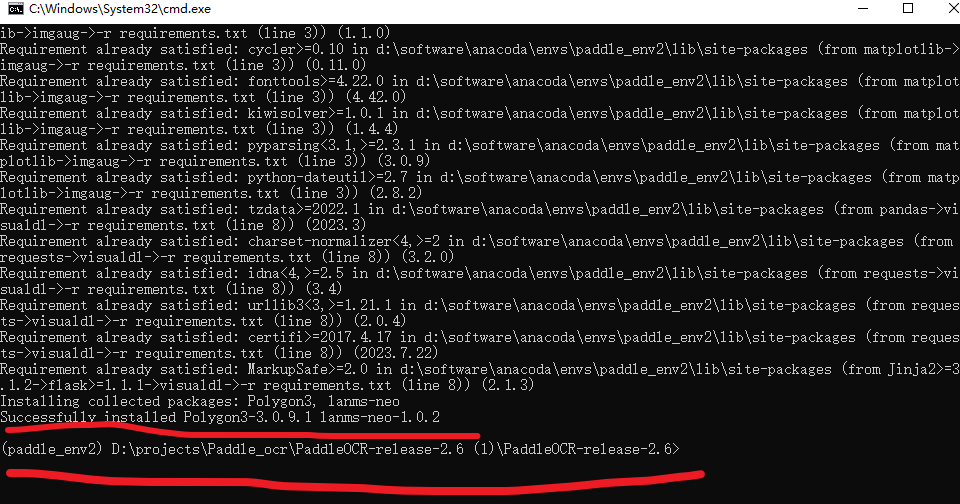
安装:安装Hub Serving
pip install paddlehub -i https://mirror.baidu.com/pypi/simple

不要关闭窗口,也不要对窗口进行任何操作,直到出现,出现Successfully installed。。。这个说明安装成功了,如下图所示: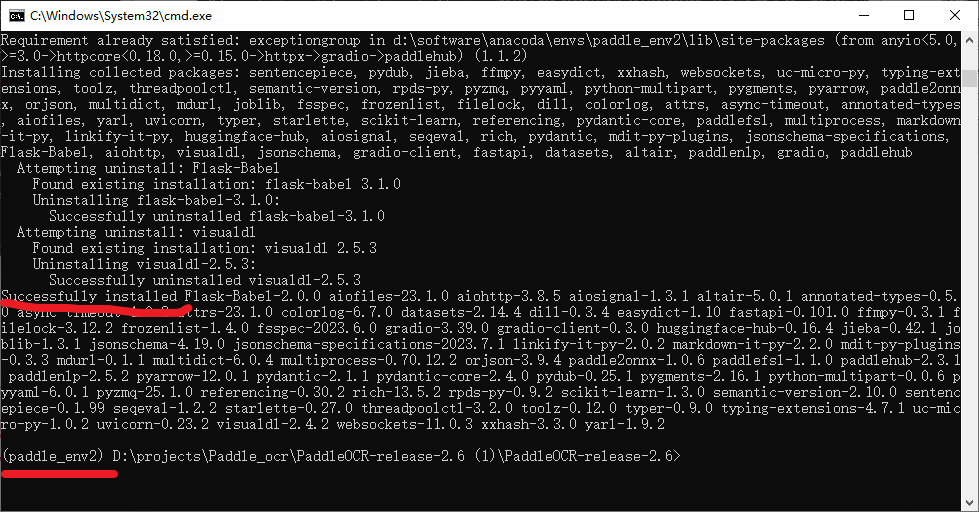
安装成功之后,可以到对应的虚拟环境中看一下对应的文件夹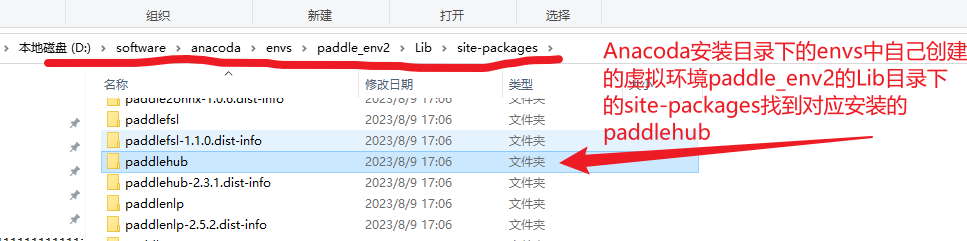
下载推理模型:
我们在解压的PaddleOCR包中,可以看到一个deploy目录,进去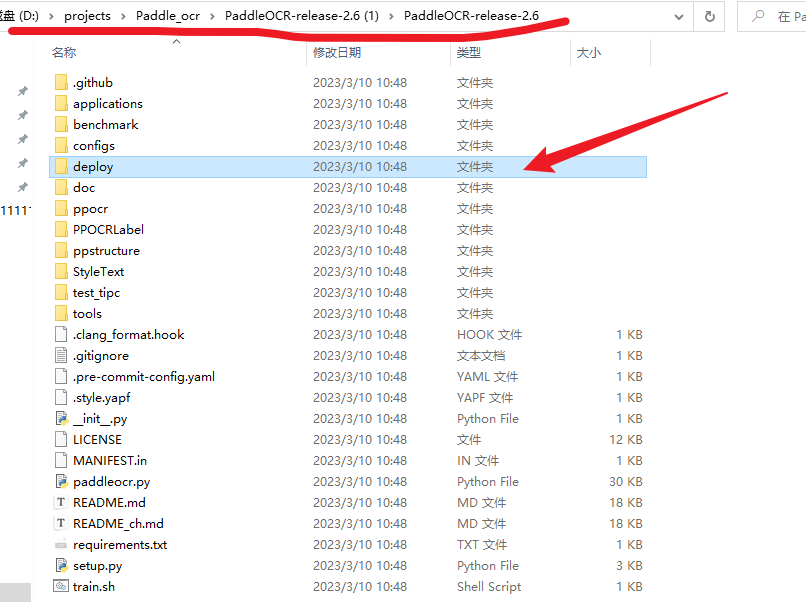
双击hubserving文件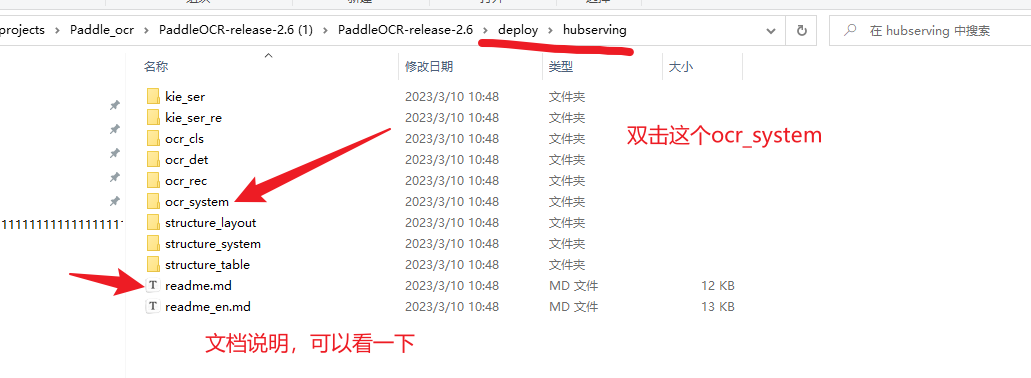
双击上面截图中的readme.md,这里有对应的部署过程,具体可以看一下
打开ocr_system
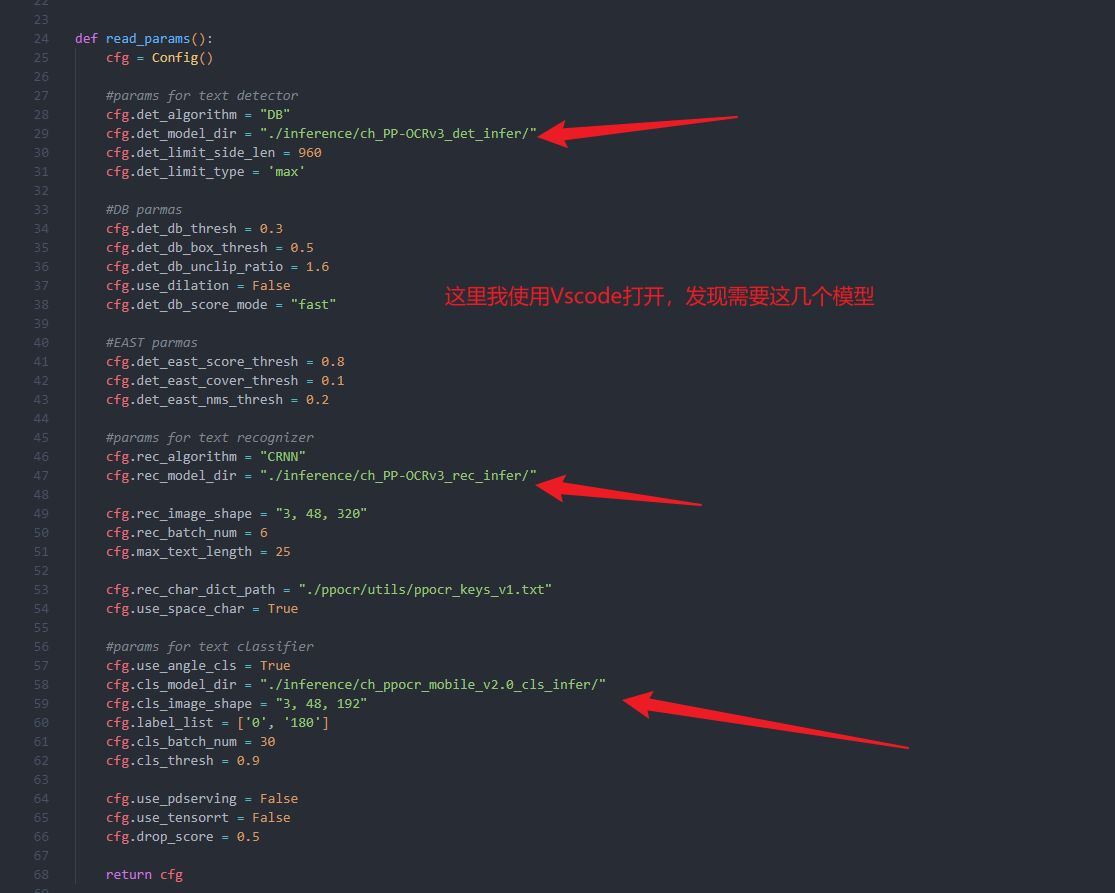
这里要特别注意了,上面截图中的./inference指的是与deploy同级的目录,所以需要在于deploy同级的目录中建立一个inferrnce文件夹,如下图所示: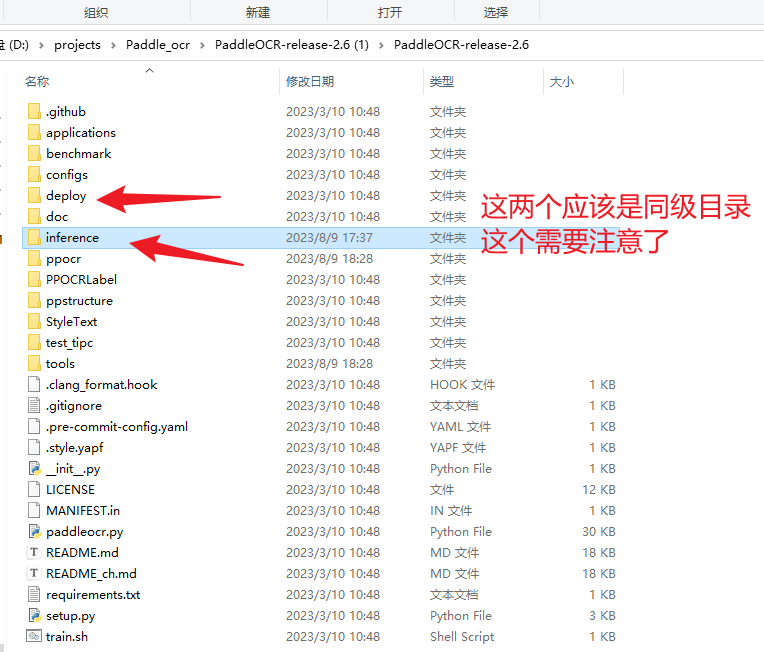
开始使用_飞桨-源于产业实践的开源深度学习平台 (paddlepaddle.org.cn)
模型库 - 飞桨AI Studio - 人工智能学习实训社区 (baidu.com)
飞桨AI Studio - 人工智能学习与实训社区 (baidu.com)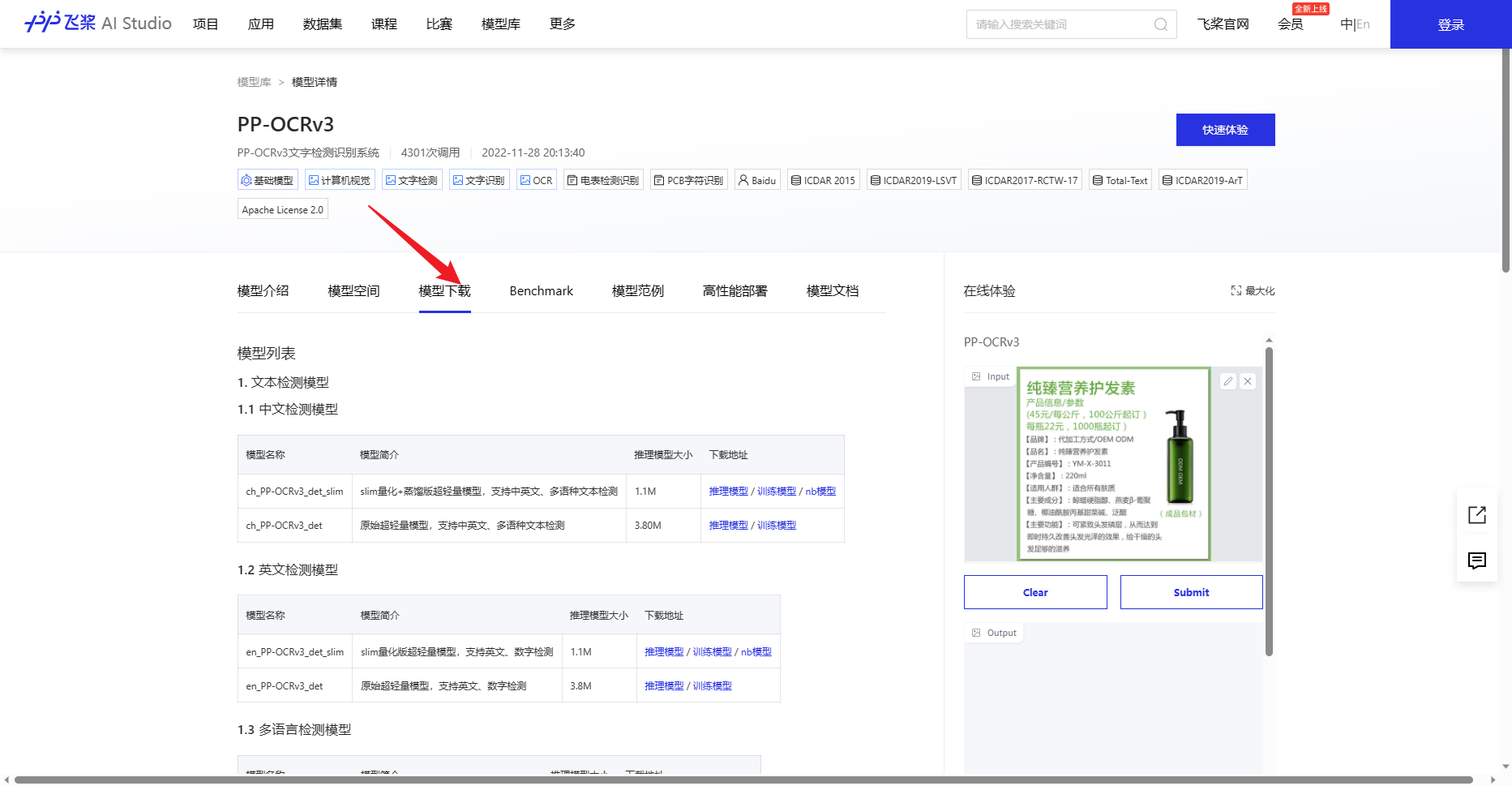
点击一下就可以下载了
点击一下就可以下载了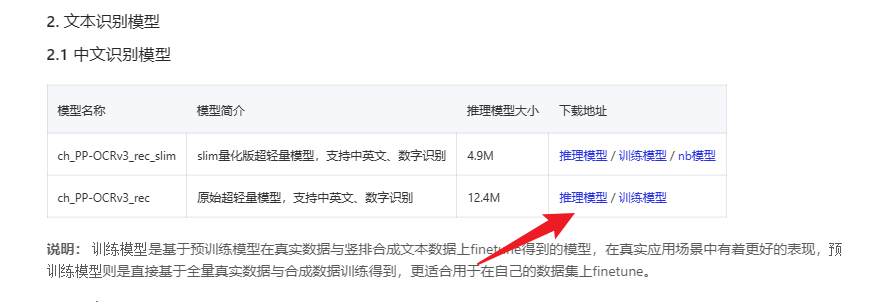
点击一下就可以下载了
下载好之后,在对应的PaddleOCR解压缩包的目录下新建
inference
文件夹,为什么文件要放到这里,文章后面有说明,往下看就会知道了。如下图所示,并将下载好的模型,放到这里,然后解压缩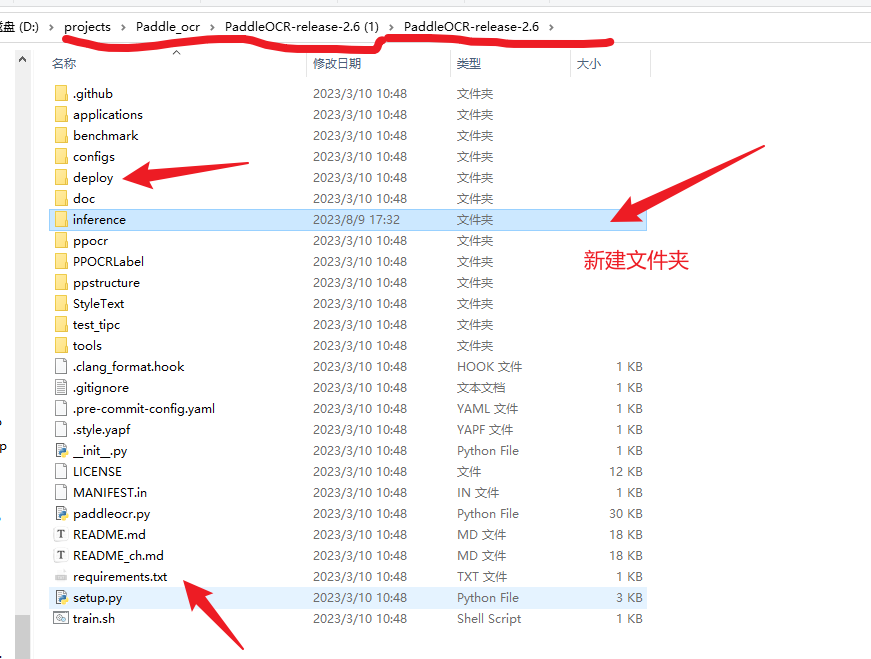
将下载好的模型复制到新建的
inference
文件夹中
解压



然后再去修改对应的params.py目录参数,将刚才放的文件位置以就对路径的形式进行,
相对路径的形式!!!相对路径的形式!!!相对路径的形式!!!相对路径的形式!!!
使用相对路径的形式的时候,有一个需要特别注意的地方,具体看如下截图,截图有说明需要特别注意的地方。不过推荐使用这个相对路径的形式。
这个文件在解压目录的deploy\hubserving\ocr_system下,上图中圈出来的三个名字,就是下面代码中配置相对路径的名字

这里推荐使用相对路径,相对路径!!!
绝对路径的形式!!!绝对路径的形式!!!绝对路径的形式!!!绝对路径的形式!!!
这里就是把刚才下载解压到新建
inference
文件夹的模型路径,以绝对路径的形式配置到这里而已,这个如果是以绝对路径的形式配置,就不需要这个模型的位置一定在某个文件夹目录下。这里建议使用相对路径的形式!!!
这个文件在解压目录的deploy\hubserving\ocr_system下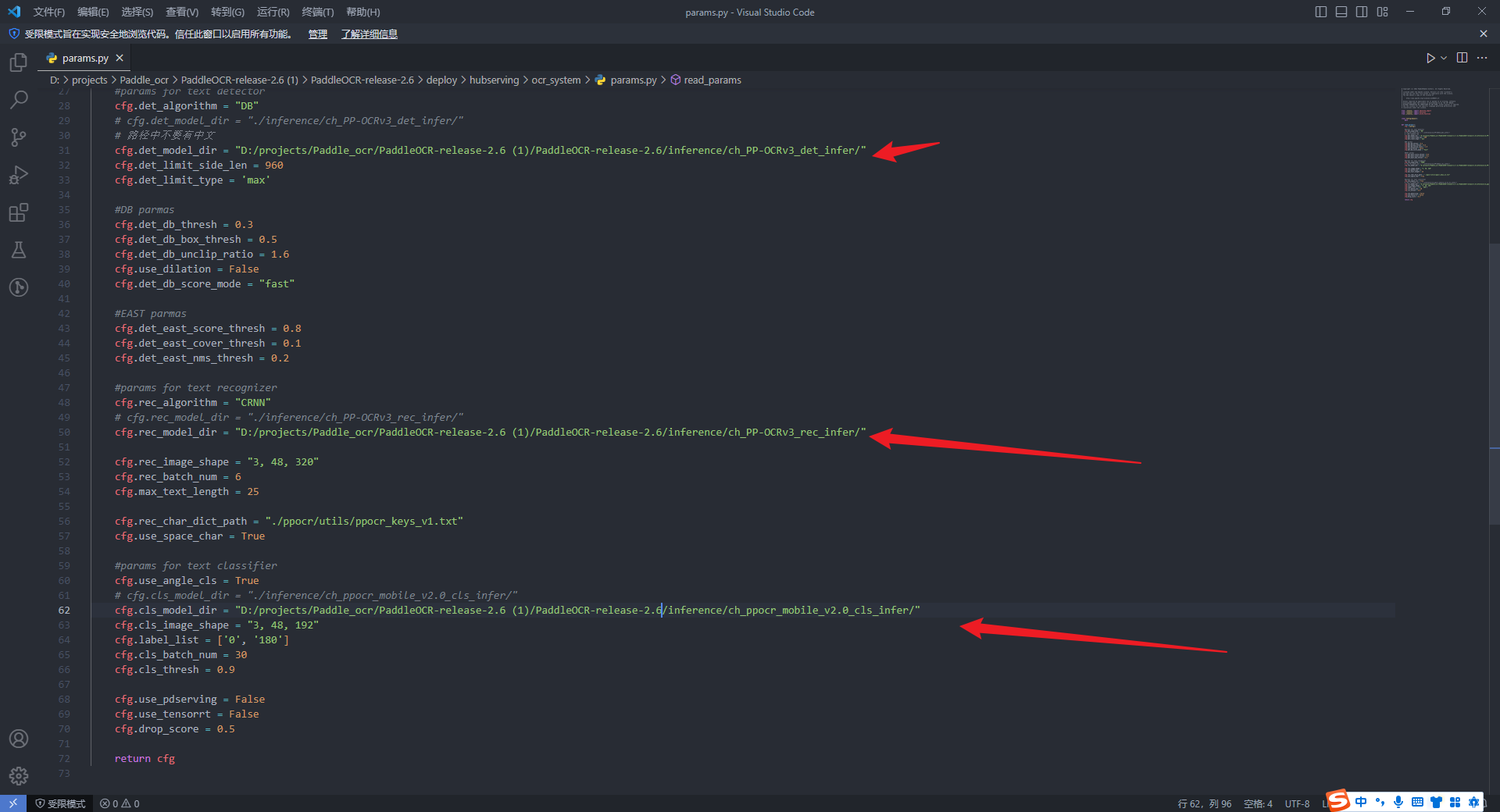
配置好了之后,进入对应的虚拟环境,然后输入
hub
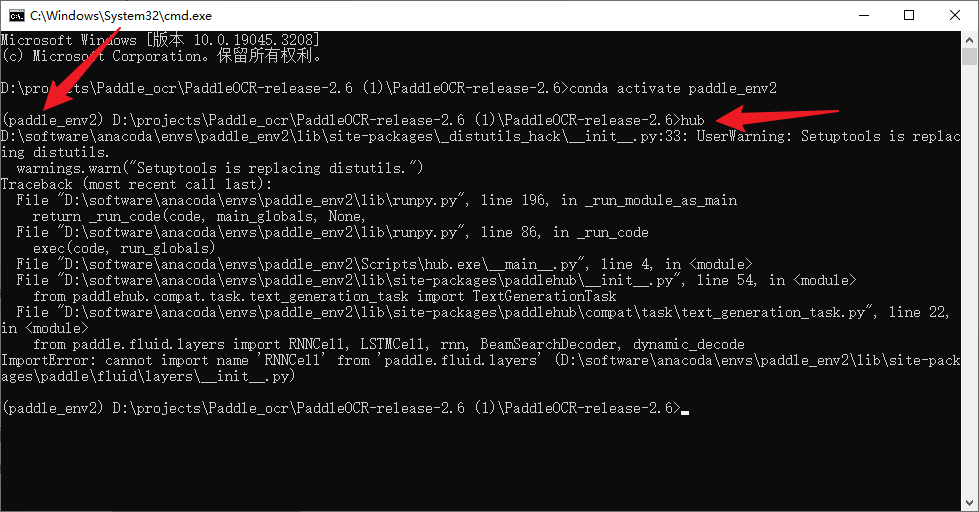
发现如下报错:
D:\software\anacoda\envs\paddle_env2\lib\site-packages_distutils_hack_init.py:33: UserWarning: Setuptools is replacing distutils.
warnings.warn(“Setuptools is replacing distutils.”)
Traceback (most recent call last):
File “D:\software\anacoda\envs\paddle_env2\lib\runpy.py”, line 196, in *run_module_as_main
return *run_code(code, main_globals, None,
File “D:\software\anacoda\envs\paddle_env2\lib\runpy.py”, line 86, in *run_code
exec(code, run_globals)
File "D:\software\anacoda\envs\paddle_env2\Scripts\hub.exemain.py", line 4, in
File "D:\software\anacoda\envs\paddle_env2\lib\site-packages\paddlehub_init.py", line 54, in
from paddlehub.compat.task.text_generation_task import TextGenerationTask
File “D:\software\anacoda\envs\paddle_env2\lib\site-packages\paddlehub\compat\task\text_generation_task.py”, line 22, in
from paddle.fluid.layers import RNNCell, LSTMCell, rnn, BeamSearchDecoder, dynamic_decode
ImportError: cannot import name ‘RNNCell’ from ‘paddle.fluid.layers’ (D:\software\anacoda\envs\paddle_env2\lib\site-packages\paddle\fluid\layers_init*.py)
特别是这个报错
ImportError: cannot import name ‘RNNCell’ from ‘paddle.fluid.layers’ (D:\software\anacoda\envs\paddle_env2\lib\site-packages\paddle\fluid\layers_init_.py)
我在这里找到了解决办法
Issues · PaddlePaddle/PaddleOCR · GitHub
Trouble serving layout model · Issue #10285 · PaddlePaddle/PaddleOCR · GitHub

Pip查看包版本详解_笔记大全_设计学院 (python100.com)
如何查看pip版本_笔记大全_设计学院 (python100.com)

这里的版本是2.5.1,所以只能换版本了啊
# 先卸载,后安装
pip uninstall paddlepaddle
pip installpaddlepaddle==2.4.2 -i https://mirror.baidu.com/pypi/simple

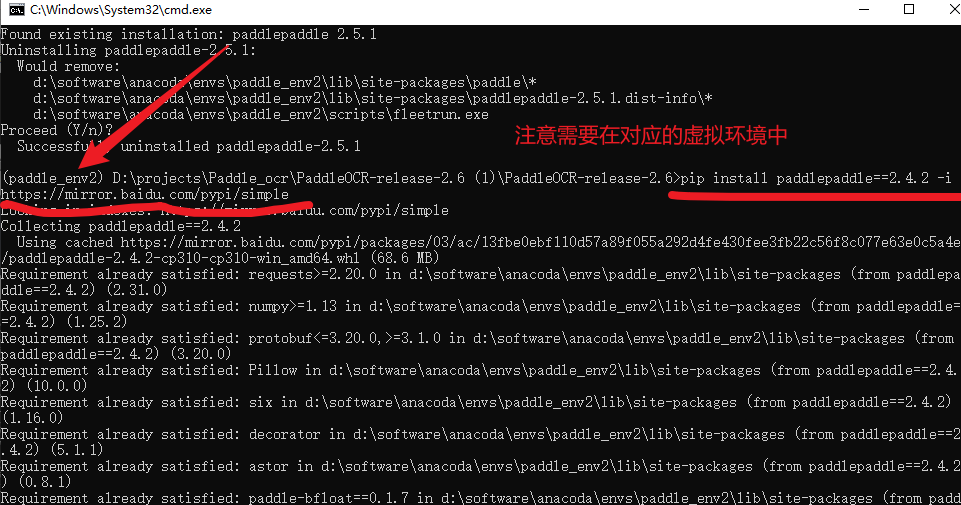
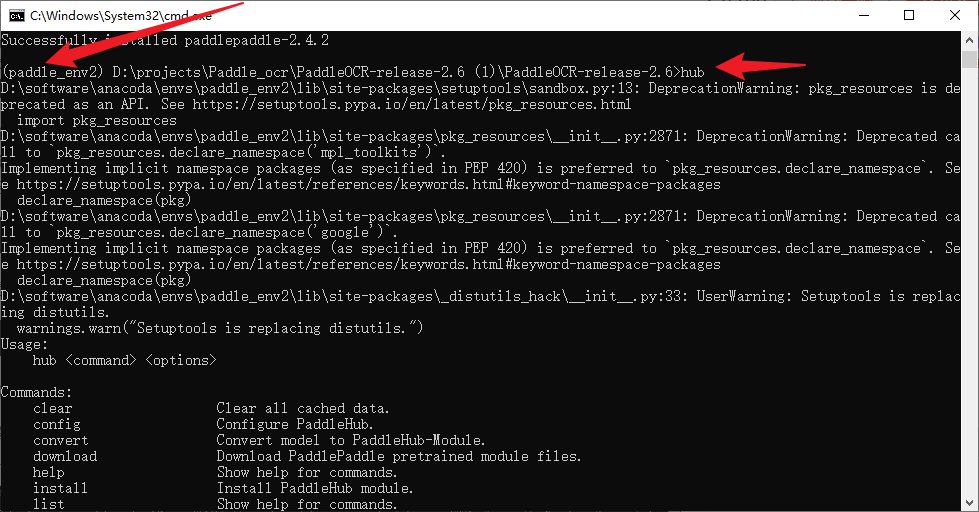
执行了上面的两句命令之后,出现如下图所示的内容说明PaddlePaddle2.4.2版本安装成功了
这里只是解释一下,里面设计到的命令不要执行就可以了。(我试过了,其实这里不卸载,直接运行下面的2.4.2的那一句也是可以的,会自动帮忙卸载2.5.1,然后下载安装2.4.1的。不过卸载再安装稳妥一点而已。如果是
pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
就不行了,不会卸载对应的版本,然后安装新的版本,要想更新直接这样就行了。这里扯远了
pip install--upgrade paddlepaddle -i https://mirror.baidu.com/pypi/simple
别升级啊,这里只是提一下而已)
然后再次输入
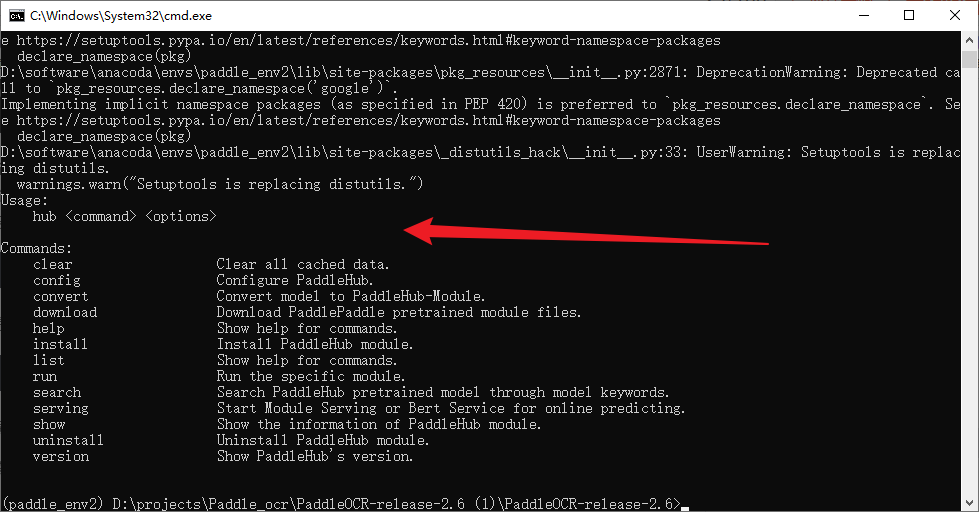
hub
看一下,出现下图所示的内容,就说明hub没问题了
然后找到如下所示的内容:
这个readme.md里面有详细的内容介绍,可以先看一下这篇文章的内容,然后再跟着后面的代码进行配置,以下是部分截图而已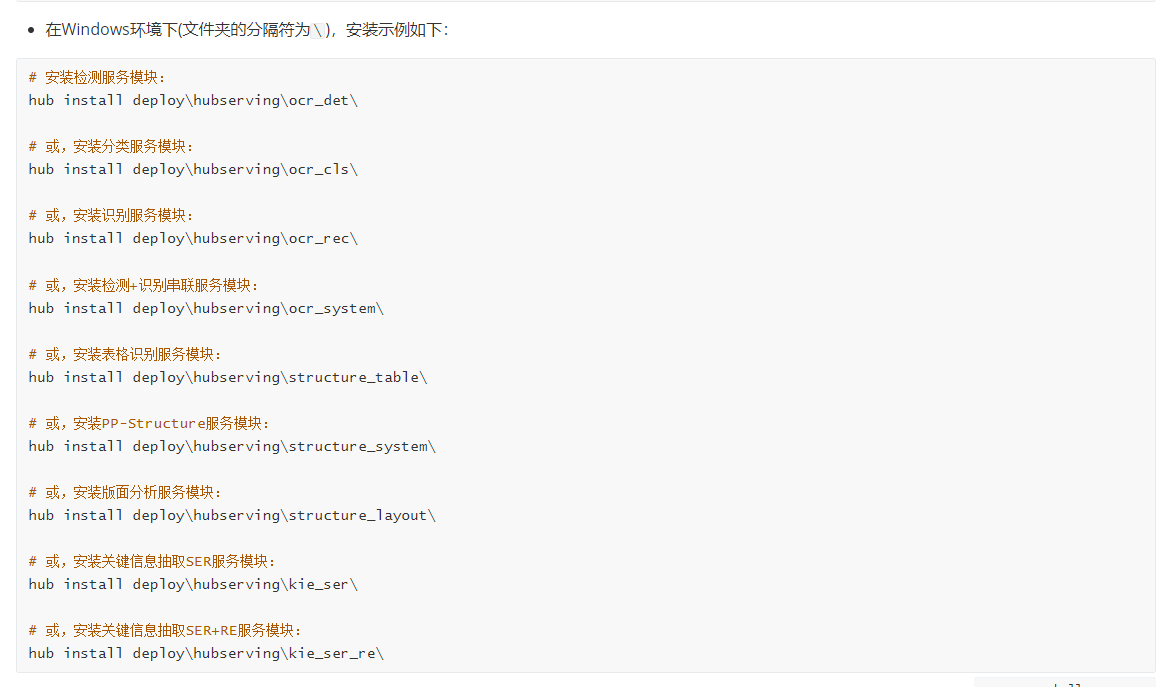
然后再命令行中输入
hub install deploy\hubserving\ocr_system\
注意文件之间的对应关系啊,deploy\hubserving\ocr_system\ 很明显就是相对路径啊,所以这个也是需要注意的,在命令行中的文件位置可能需要准确一些了。如这里: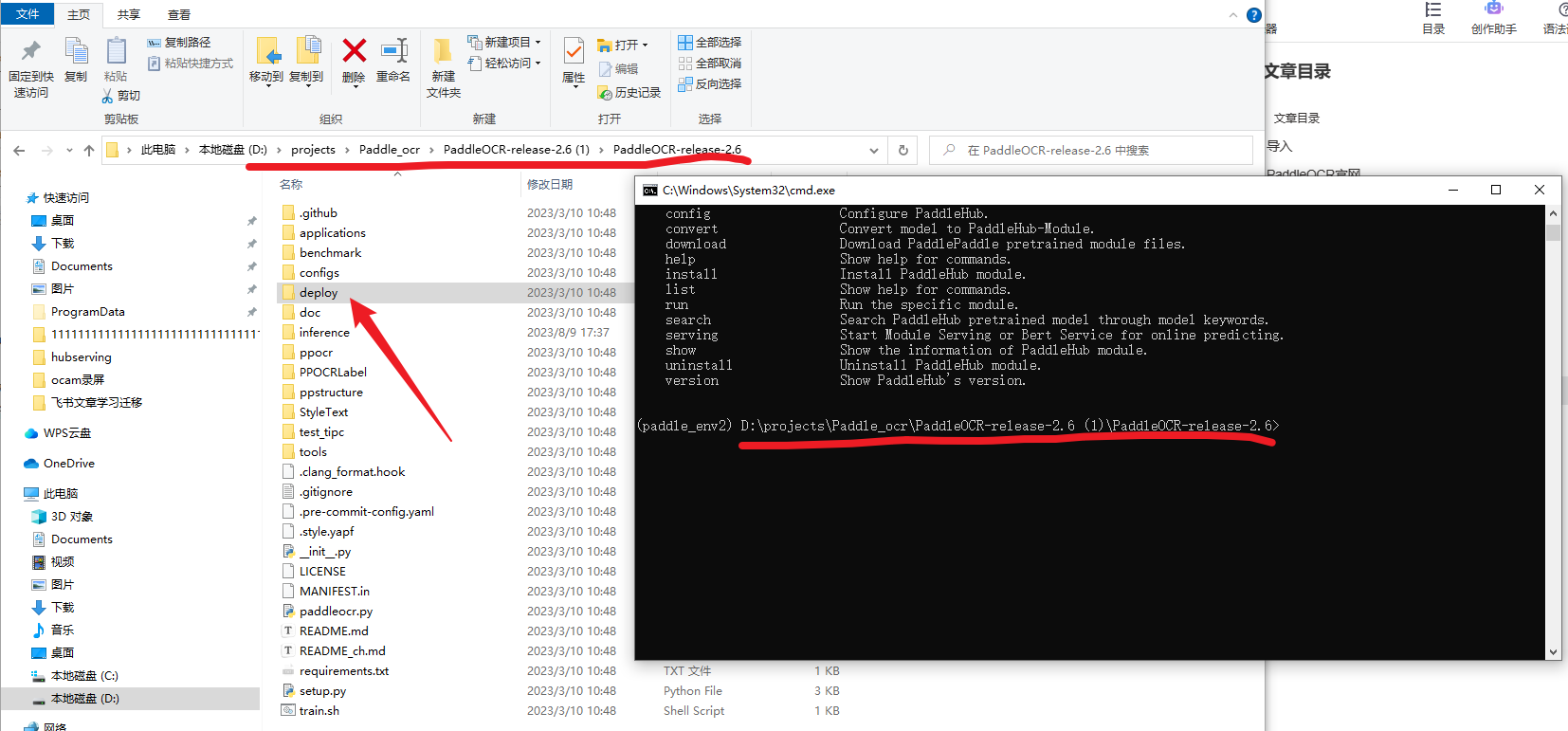
出现绿色的说明服务安装成功了,这个要时刻注意虚拟环境好吧
在启动服务前,还需要进行如下配置
我这里使用的是Vscode打开的

启动服务
hub serving start -c deploy\hubserving\ocr_system\config.json
这里还是有一个相对目录deploy\hubserving\ocr_system\config.json,所以要特别注意他们的对应关系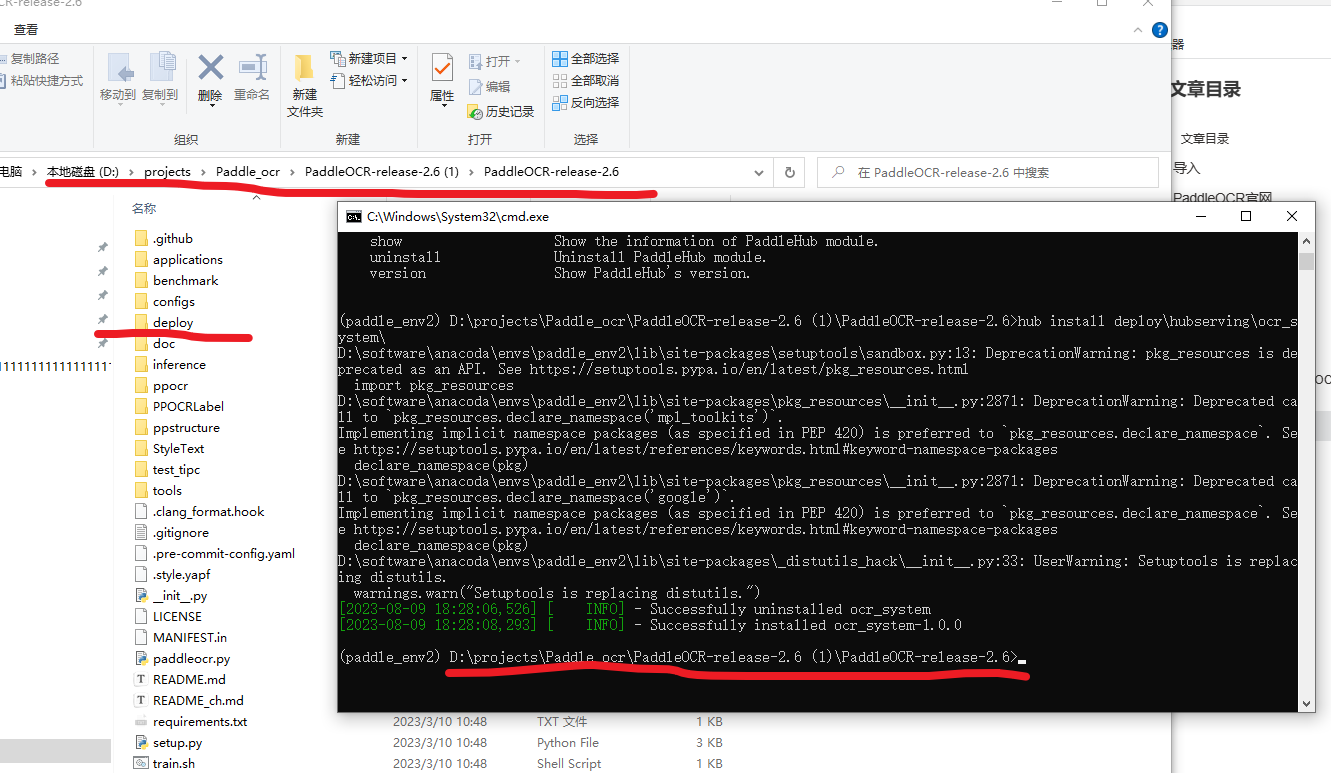
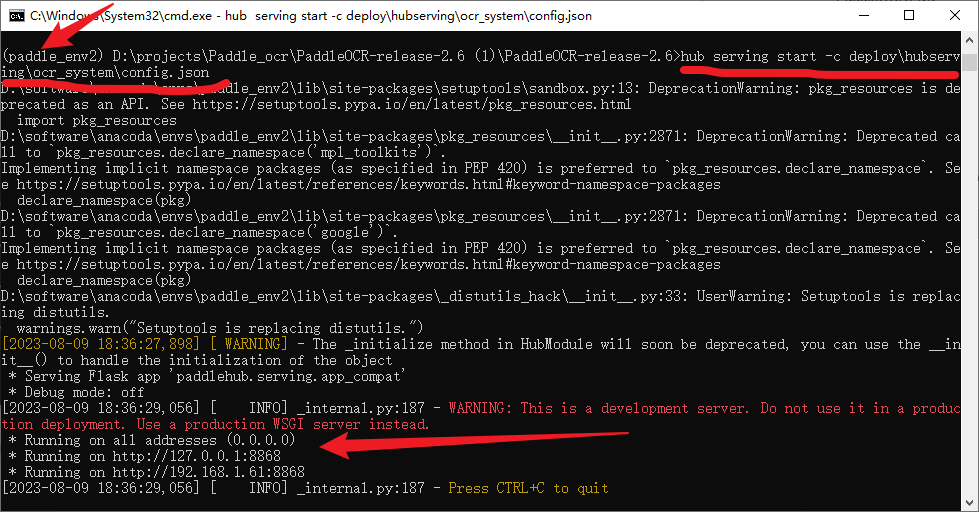
出现端口号,就说明启动成功了,第一次启动的时候可能会弹出如下的警告,允许一下就行了
这个就是图片识别的接口了:http://127.0.0.1:8868/predict/ocr_system
接口是post请求,需要传入的是图片的base64位,这里我利用了一些图片base64在线生成的工具,可以看一下。图片转换base64编码 在线图片Base64编码转换工具 iP138在线工具,整个过程看GIF图
apifox如下所示,这个
可以看到后台这里发送了一个请求,也是有记录的
好家伙,一顿操作猛如虎之后,结果一看战绩0-5,还是出错了!总不能这个时候放弃吧,都临门一脚了,没办法,只能是解决问题了,然而仔细看报错信息,就会发现,这里面还告诉了你解决办法。所以跟着这个报错走就对了,那就是把Numpy版本变成1.20
{
“msg”: “module ‘numpy’ has no attribute ‘int’.\nnp.intwas a deprecated alias for the builtin
int. To avoid this error in existing code, use
intby itself. Doing this will not modify any behavior and is safe. When replacing
np.int, you may wish to use e.g.
np.int64or
np.int32to specify the precision. If you wish to review your current use, check the release note link for additional information.\nThe aliases was originally deprecated in NumPy 1.20; for more details and guidance see the original release note at:\n https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations”,
“results”: “”,
“status”: “101”
}
百度翻译了一下:“消息”:模块“numpy”没有属性“int”。\n“np.int”是内置“int”的一个不推荐使用的别名。为了避免在现有代码中出现此错误,请单独使用“int”本身。这样做不会修改任何行为,而且是安全的。在替换“np.int”时,您可能希望使用例如“np.int64”或“np.int32”来指定精度。如果您希望查看当前的使用情况,请查看发行说明链接以获取更多信息tion。\别名最初在NumPy 1.20中被弃用;有关更多详细信息和指导,请参阅原始发行说明:\nhttps://numpy.org/devdocs/release/1.20.0-notes.html#deprecations“,
被启用了,那有什么办法,换版本呗!Ctrl + C停止服务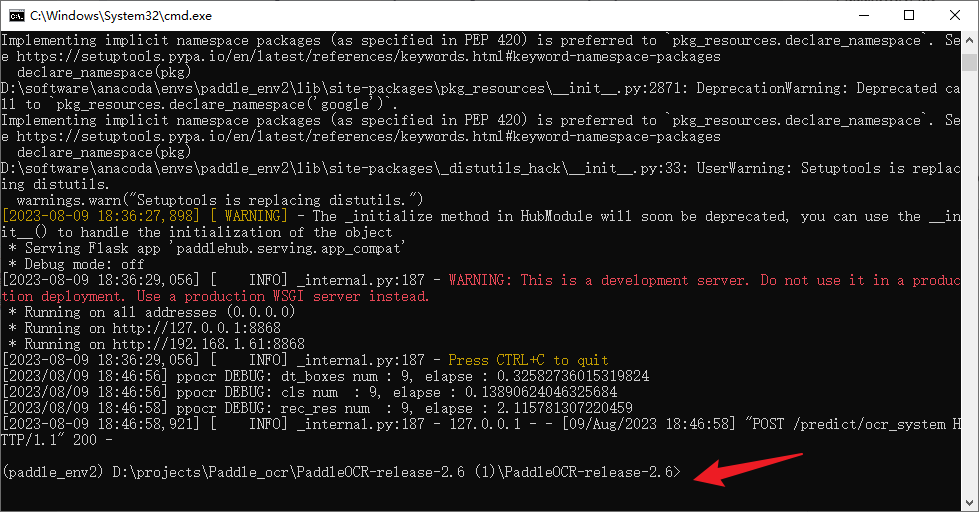
pip show numpy
发现这个numpy是1.25.2的版本,注意了我是在激活的虚拟环境的paddle_env2的情况下运行的,具体看截图就知道了 卸载它
卸载它
pip uninstall numpy

从新安装一个新的版本的numpy
pip installnumpy==1.22-i https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
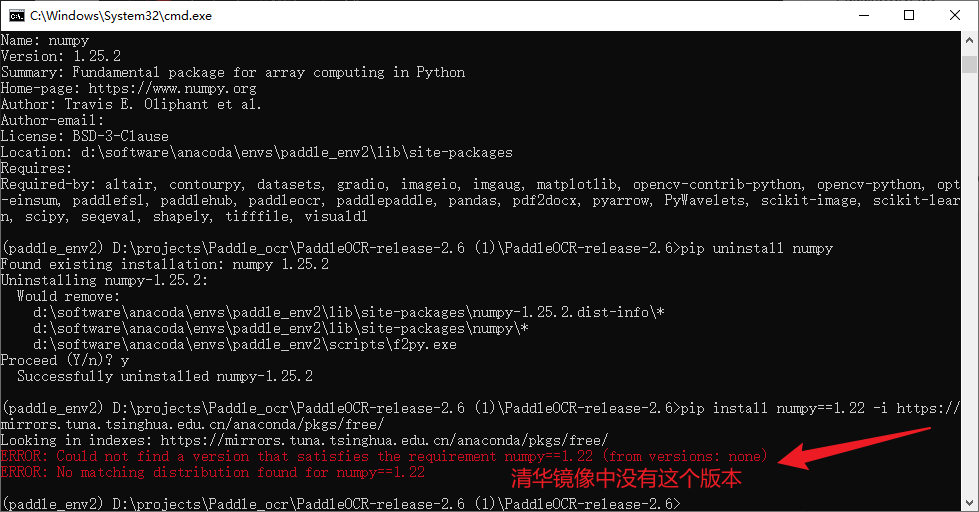
只能这样了
pip installnumpy==1.22
如下图所示:出现了,Successfully installed numpy-1.22.0就说明成功了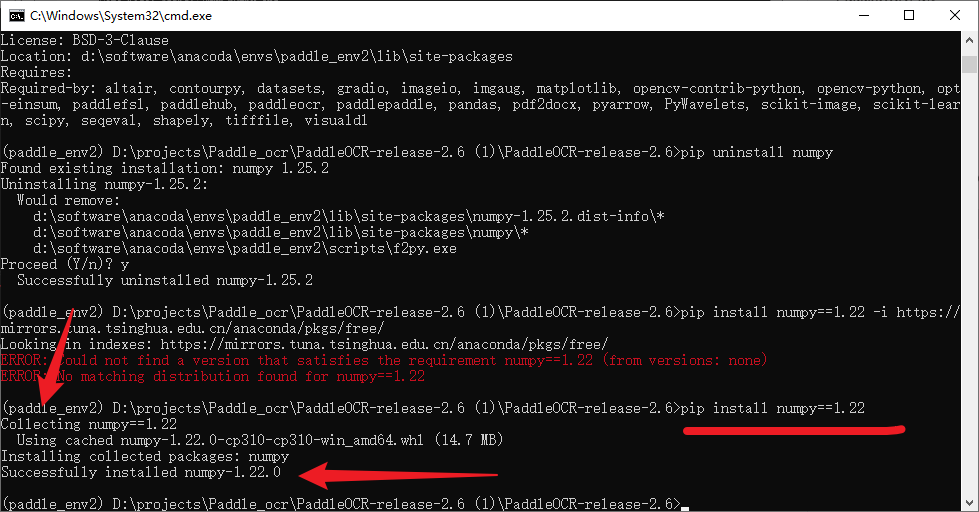
重新启动PaddleOCR的Paddle Serving 部署服务,要注意对应的文件关系,以及是否是上面创建的虚拟环境paddle_env2中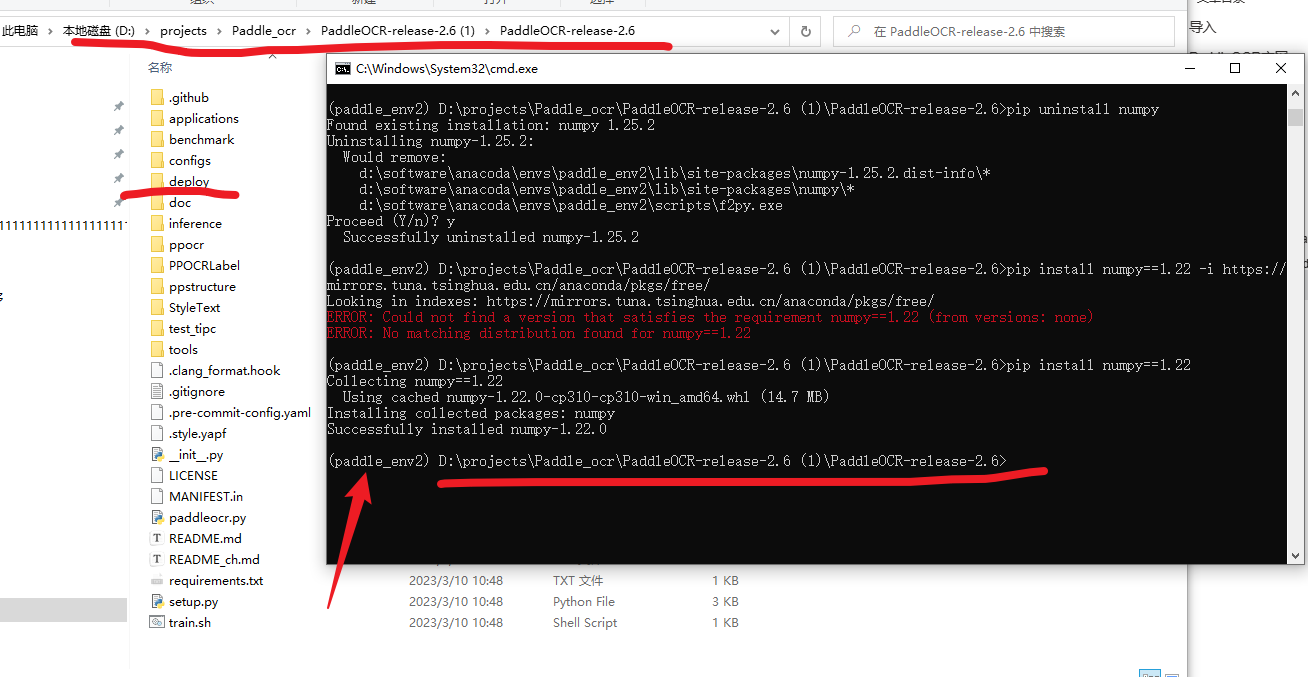
hub serving start -c deploy/hubserving/ocr_system/config.json

出现端口号,就说明成功了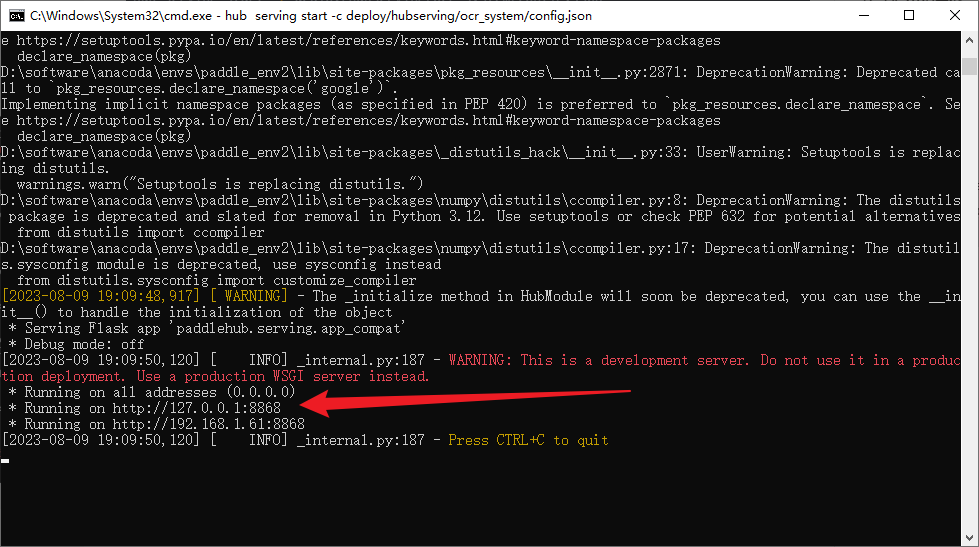
这个就是图片识别的接口了:http://127.0.0.1:8868/predict/ocr_system
接口是post请求,需要传入的是图片的base64位,这里我利用了一些图片base64在线生成的工具,可以看一下。图片转换base64编码 在线图片Base64编码转换工具 iP138在线工具,请求这里我使用的是apifox,整个过程看GIF图
图片是这个:

成功了,正不容易啊!!!
识别得到的内容结果如下所示,是一种json格式的内容
{"msg":"","results":[[{"confidence":0.9163883328437805,"text":"姓名代用名","text_region":[[49,69],[192,69],[192,92],[49,92]]},{"confidence":0.9161157011985779,"text":"性别男","text_region":[[50,119],[142,119],[142,140],[50,140]]},{"confidence":0.995164155960083,"text":"民族汉","text_region":[[191,119],[272,119],[272,140],[191,140]]},{"confidence":0.8806743025779724,"text":"出生2013年05月06","text_region":[[51,165],[315,165],[315,184],[51,184]]},{"confidence":0.9777846336364746,"text":"日","text_region":[[340,169],[359,169],[359,184],[340,184]]},{"confidence":0.9847420454025269,"text":"住址湖南省长沙市开福区巡道街","text_region":[[48,210],[383,212],[383,234],[48,232]]},{"confidence":0.9803442358970642,"text":"幸福小区居民组","text_region":[[116,240],[271,240],[271,263],[116,263]]},{"confidence":0.9728078246116638,"text":"公民身份证号码","text_region":[[51,336],[188,336],[188,353],[51,353]]},{"confidence":0.9199631214141846,"text":"430512198908131367","text_region":[[230,337],[553,337],[553,354],[230,354]]}]],"status":"000"}
换一张图片试试,歪的图片


{"msg":"","results":[[{"confidence":0.8086597323417664,"text":"姓名代用名","text_region":[[451,449],[811,385],[822,451],[462,515]]},{"confidence":0.9957382082939148,"text":"民族汉","text_region":[[815,504],[1023,463],[1034,522],[826,563]]},{"confidence":0.8644452691078186,"text":"性别男印","text_region":[[479,566],[851,500],[861,560],[489,626]]},{"confidence":0.9327426552772522,"text":"出生2013年05月06日","text_region":[[501,678],[1249,534],[1260,591],[512,735]]},{"confidence":0.930916965007782,"text":"住 址 湖南省长沙市开福区巡道街","text_region":[[515,787],[1322,630],[1333,693],[527,850]]},{"confidence":0.9655157923698425,"text":"幸福小区居民组","text_region":[[697,827],[1073,751],[1084,808],[708,884]]},{"confidence":0.8980772495269775,"text":"430512198908131367","text_region":[[1006,992],[1771,837],[1783,893],[1017,1049]]},{"confidence":0.9847748875617981,"text":"公民身份证号码","text_region":[[579,1081],[929,1011],[940,1068],[590,1138]]},{"confidence":0.9132032990455627,"text":"Shot on Y93s","text_region":[[211,1157],[435,1157],[435,1197],[211,1197]]},{"confidence":0.9631398916244507,"text":"vivo dual camera","text_region":[[203,1197],[503,1203],[502,1252],[202,1245]]},{"confidence":0.953616738319397,"text":"2023.07.1118:04","text_region":[[2362,1197],[2640,1197],[2640,1240],[2362,1240]]}]],"status":"000"}
再试一张图片


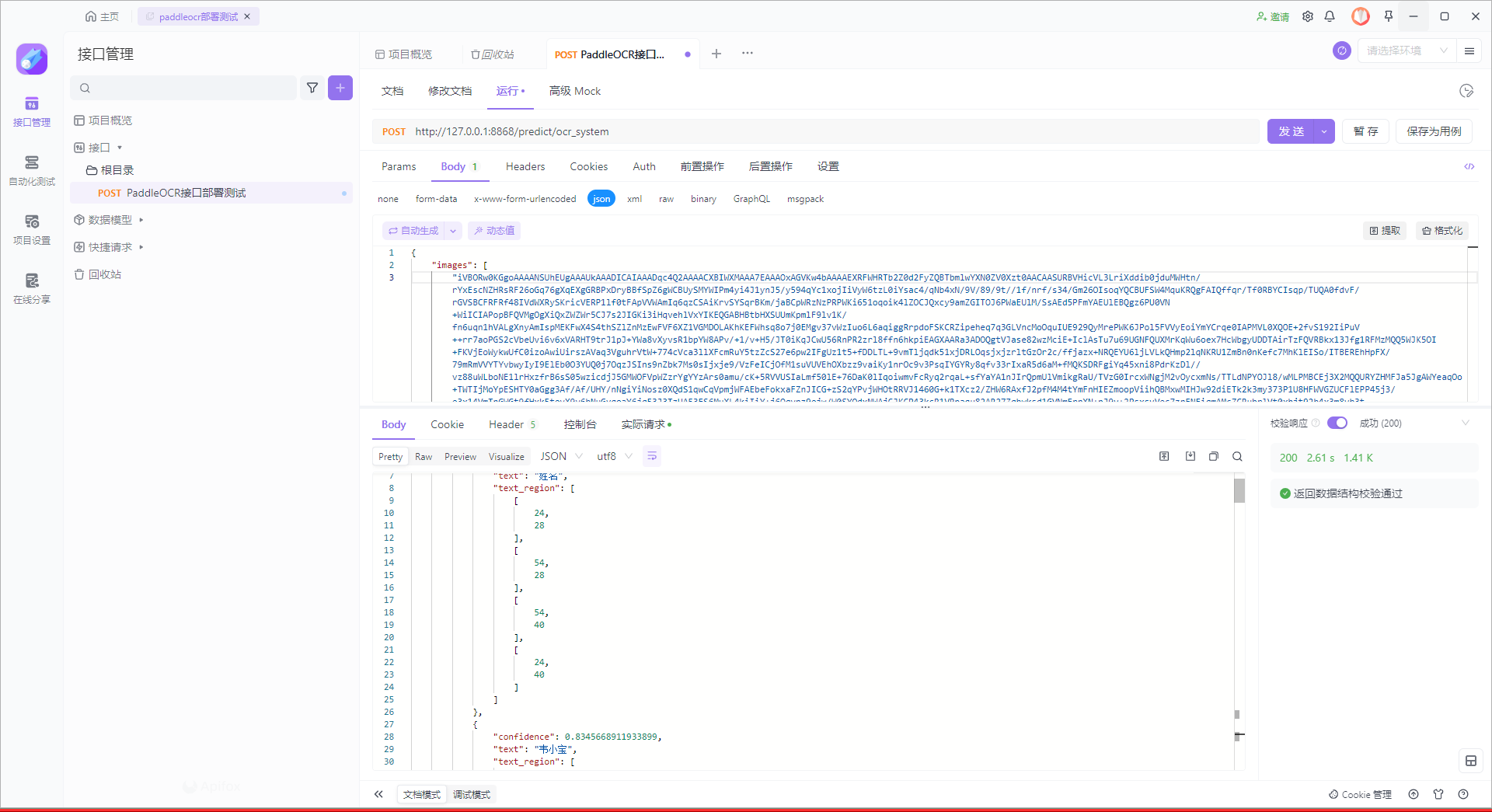
{"msg":"","results":[[{"confidence":0.996680498123169,"text":"姓名","text_region":[[24,28],[54,28],[54,40],[24,40]]},{"confidence":0.8345668911933899,"text":"韦小宝","text_region":[[62,23],[110,23],[110,41],[62,41]]},{"confidence":0.9825009703636169,"text":"性","text_region":[[25,53],[43,53],[43,65],[25,65]]},{"confidence":0.7548757195472717,"text":"别","text_region":[[41,55],[53,55],[53,62],[41,62]]},{"confidence":0.9996832609176636,"text":"男","text_region":[[66,54],[77,54],[77,64],[66,64]]},{"confidence":0.983100414276123,"text":"民族汉","text_region":[[97,52],[144,52],[144,66],[97,66]]},{"confidence":0.9346395134925842,"text":"1654年12月20日","text_region":[[63,77],[173,77],[173,91],[63,91]]},{"confidence":0.9760129451751709,"text":"住址","text_region":[[24,105],[60,105],[60,117],[24,117]]},{"confidence":0.8841278553009033,"text":"北京市东城区景山前街4号","text_region":[[61,104],[211,104],[211,118],[61,118]]},{"confidence":0.9278525710105896,"text":"紫禁城敬事房","text_region":[[62,126],[136,126],[136,141],[62,141]]},{"confidence":0.9618369936943054,"text":"公民身份证号码","text_region":[[25,171],[104,171],[104,184],[25,184]]},{"confidence":0.9530525207519531,"text":"11204416541220243X","text_region":[[114,171],[283,171],[283,184],[114,184]]}]],"status":"000"}
Java + PaddleOCR对身份证的识别
Java使用PaddleOCR识别身份证信息_m0_62317155的博客-CSDN博客
复制虚拟环境给其他电脑使用
通过上面方式创建的虚拟环境,可以直接复制对应的虚拟环境给其他电脑使用。如我这里没有两台电脑,我就使用两个不同的文件夹来表示不同的电脑吧,文件夹最好不要有中文。(我会放到百度网盘中的:方便以后自己直接使用!!!)
复制这个paddle_env2的虚拟环境到其他电脑或者文件夹



# 激活虚拟环境,注意这里就是上面截图的文件夹paddle_env2名,同时也是上面创建的虚拟环境名
activate paddle_env2

激活虚拟环境之后,我们可以试着使用里面的python环境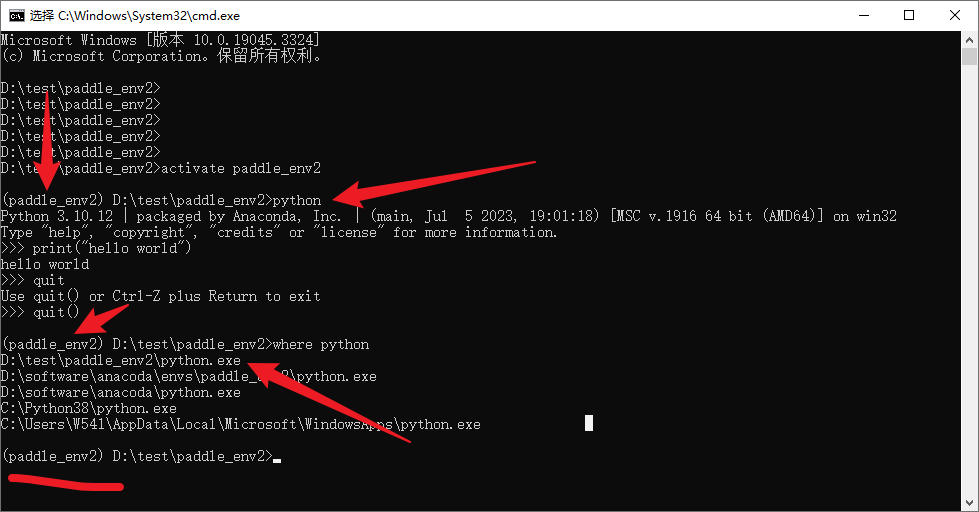
这个窗口暂时不要关闭,下面需要用到!!!然后到上面步骤(看文章目录:解压包安装(及基于PaddleHub Serving的服务部署))已经配置好的PaddleOCR模型代码复制到对应的文件夹中,下载好模型然后配置好对应的内容,看文章目录:解压包安装(及基于PaddleHub Serving的服务部署)!这里有,下面是直接使用根据文章上面的内容配置好的文件,直接压缩复制到对应的文件夹中!!!具体如下图所示的是根据上面文章配置好的PaddleOCR,然后打包而已。或者可以自己去gitee、GitHub上下载对应的内容,然后跟着这一节的内容解压包安装(及基于PaddleHub Serving的服务部署)配置一下就行了。

复制到对应的目录下:解压
解压完成之后,切换到对应的目录下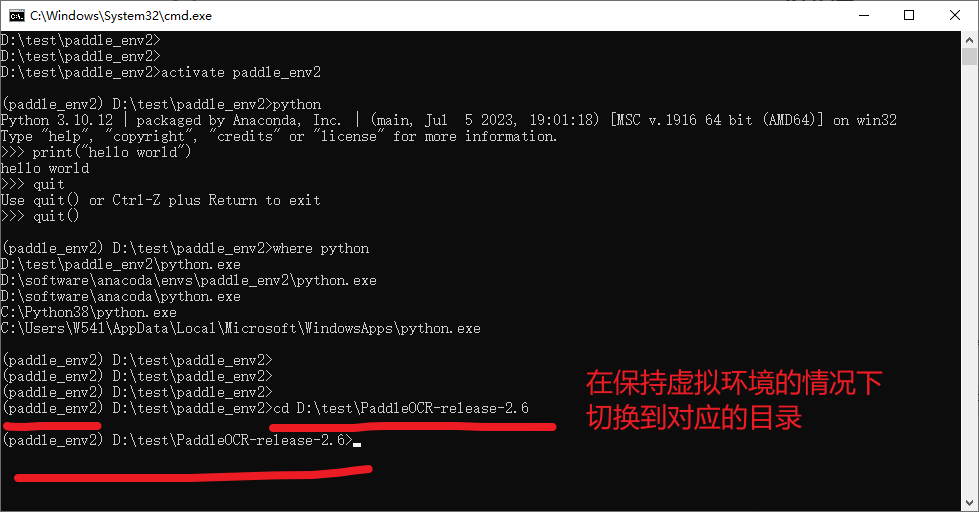
进入刚才解压的PaddleOCR文件中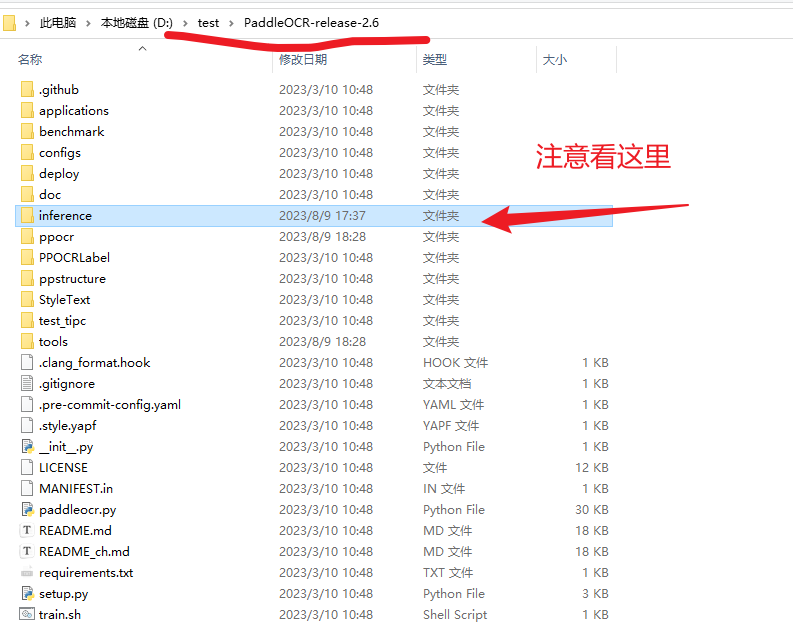


我这里使用Vscode打开它,我这里先使用绝对路径吧!!!
图片上面中粉红色的字说的相对路径./inference其实就是上文提到的与deploy目录的同级目录,我们可以看到这个在文件中,inference其实是跟deploy在同一级目录的,如下图所示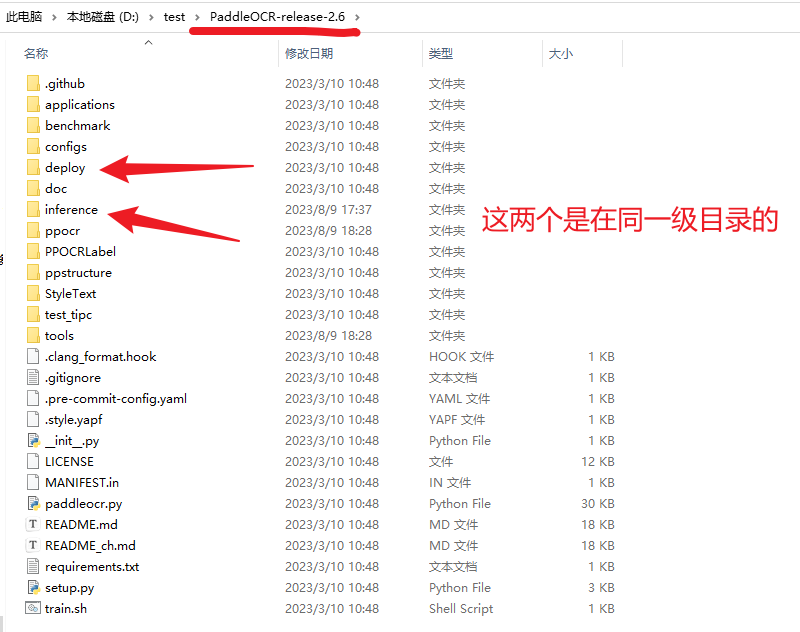
所以上图中params.py也可以是,如下所示,其实官网的给的案例就是相对路径的形式,如果使用相对路径的形式,我们只需要把模型放到特定的文件夹下就可以了。然后对一下模型的名字是否是对的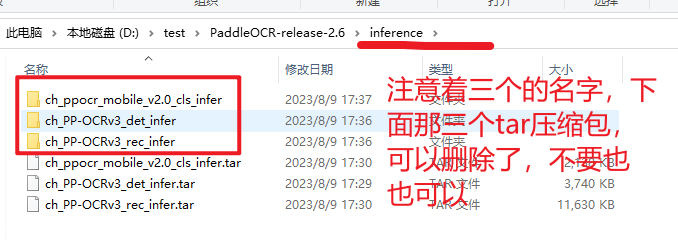
图中圈出来的三个名字,就是下面代码中配置相对路径的名字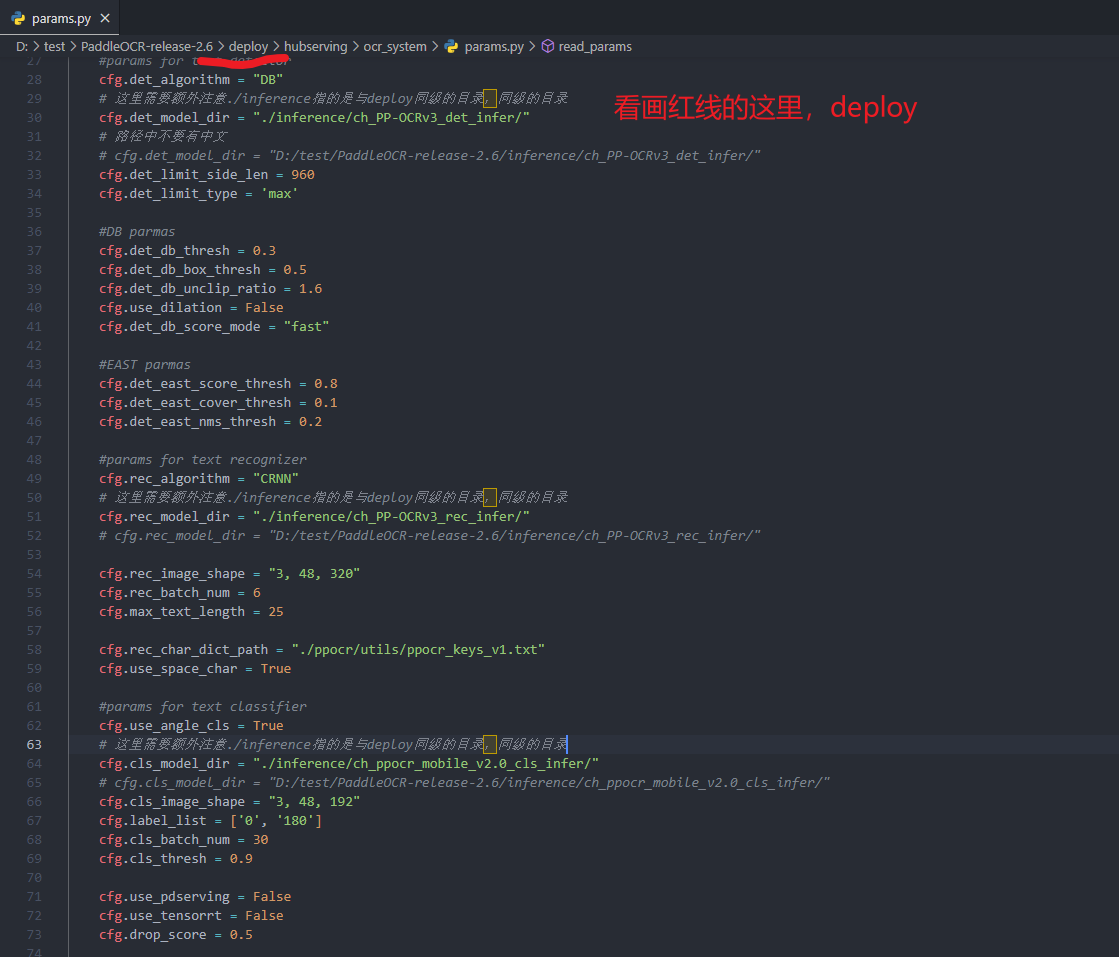
这里建议使用相对路径,方便一点,虽然使用相对路径也有可能需要大概看一下文件名对不对。但是使用相对路径之后,迁移到其他电脑时方便啊!!!我这里使用的是相对路径的形式,我只是把绝对路径写出来而已。

我这里也是使用Vscode打开的,注意了从文章开始,的配置我一直都是使用CPU版本的PaddleOCR。
hub serving start -c deploy\hubserving\ocr_system\config.json
出现端口号名启动成功了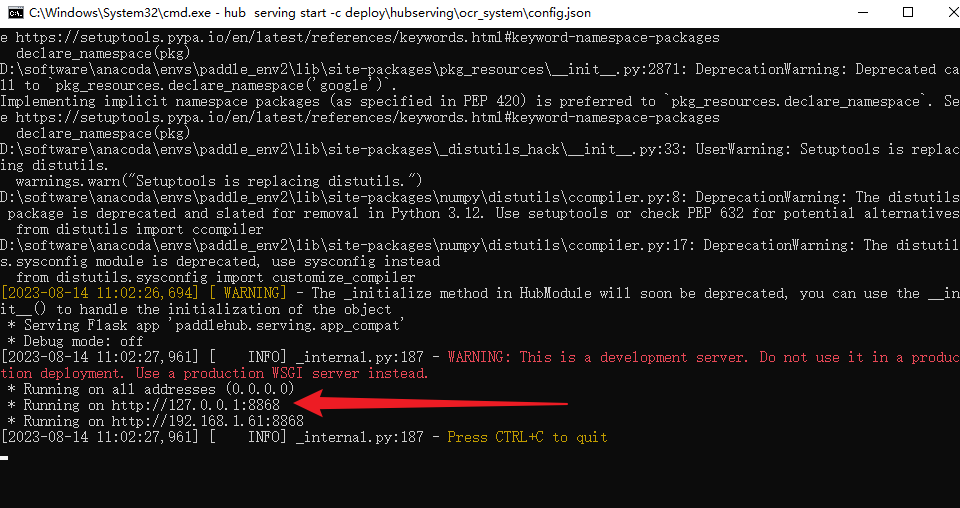
如果启动报错(没报错的不用看这一步,直接跳到下面使用Apifox访问那一节内容就可以了)
如果是按照上面的步骤安装,成功运行之后,说明改安装的包都安装好了,即使是缺少C++的一些库。所以按道理如果是直接
复制使用的虚拟环境是不会出现问题的,即使是你的电脑中没有对应的C++库,但是上面步骤中的虚拟环境安装时已经把对应的C++库安装好了的。所以一般会出错的,要是出错的话,看看是不是下面这些问题!!!
然后在当前路径下通过命令进行相关模块的安装
pip install-r requirements.txt -i https://mirror.baidu.com/pypi/simple
命令行中的requirements.txt,这里说明的是当前路径下有这个文件,也就是一个相对路径的说法。如果不是当前路径有这个,可以写绝对路径,具体看下面截图的关系说明,在下载的项目中,就有这个文件,而且cmd这里刚好也在这个目录下.。这一步可能会有一些错误提示,具体看后面的截图。

如果出现报错
注:如果出现如下所示的问题:
Microsoft Visual C++ 14.0 or greater is required. Get it with “Microsoft C++ Build Tools”:
这里说什么需要C++ 14.0的库之类的问题,我是通过Visual Studio installer这种方式解决的,加载对应的C++库
所以可能需要网络好一点了,这里下载安装好了之后,然后记得重启电脑!重启电脑!重启电脑!重启电脑!重启电脑!
重启完成之后,按照上面之前的步骤,从新到对应的位置,重新运行:一定要注意是否在之前的虚拟环境中,如果不在就激活到对应的虚拟环境中(
activate paddle_env2
),具体如下图所示的截图所示,然后重新执行如下命令
pip install-r requirements.txt -i https://mirror.baidu.com/pypi/simple
命令行中的requirements.txt,这里说明的是当前路径下有这个文件,也就是一个相对路径的说法。如果不是当前路径有这个,可以写绝对路径,具体看下面截图的关系说明,在下载的项目中,就有这个文件,而且cmd这里刚好也在这个目录下
这里如上图所示,没有出现任何报错之后,说明成功了。
之后再像上面步骤一样运行
hub serving start -c deploy\hubserving\ocr_system\config.json
然后启动它,有端口号即可
通过aipfox访问,测试服务接口
使用apifox访问一下http://127.0.0.1:8868/predict/ocr_system这个接口,post请求,传入的是base64位的图片,具体怎么使用apifox测试,文章上面有内容,具体看上面文章的内容即可!!!
接口是post请求,需要传入的是图片的base64位,这里我利用了一些图片base64在线生成的工具,可以看一下。图片转换base64编码 在线图片Base64编码转换工具 iP138在线工具,请求这里我使用的是apifox,整个过程看GIF图
图片是这个:

上面的可以正常运行的我已经放到我自己的百度网盘中了,就是为了以后方便自己可以直接使用!!!免得还要安装Anaconda这那的,怎么方便怎么来就行了!!!
极简部署
通过上面的说明,我们已经知道了可以直接复制对应的环境给其他电脑使用,然后进行部署就行了,但是部署过程还是有些繁琐。所以下面就是极简的部署了。如下图所示
只要双击startup.bat就可以了。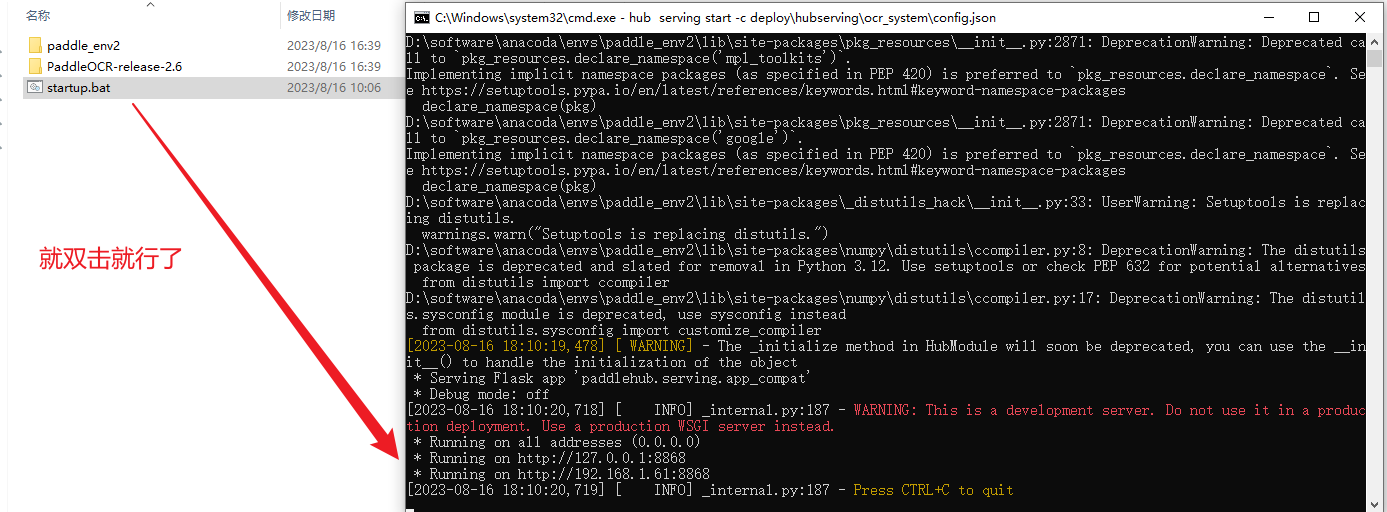
如果我们给其他电脑使用的话,就直接将这三项打包成一个压缩包,然后放到别的电脑上,然后解压。双击startup.bat即可完成部署。我把它放到百度网盘这里了,链接:链接:https://pan.baidu.com/s/1zReu87wC8pW1uUp-Our8Aw
–来自百度网盘超级会员V2的分享
下面是配置过程
先将虚拟环境paddle_env2和PaddleOCR-release-2.6放到同一个文件下,并在这个文件夹下,建立对应的文本文件txt,命名为startup.txt,然后在startup.txt中输入如下内容
@echo off // 开始标签
rem start cmd /k "cd %cd%\paddle_env2"
start cmd /k "cd %cd%\paddle_env2 && activate paddle_env2 && cd .. && cd PaddleOCR-release-2.6 && hub serving start -c deploy\hubserving\ocr_system\config.json
"
保存之后,将.txt的后缀名改成.bat即可
这里需要注意的是PaddleOCR-release-2.6目录的 inference 和 deploy 是在同一级目录下的,上面说过了!!!

然后
deploy\hubserving\ocr_system\
目录下的
params.py
使用的是相对路径,修改过的文件记得要保存一下

然后
deploy\hubserving\ocr_system\
目录下的
config.json
这里可以根据需求修改端口号,修改过的文件记得要保存一下

然后回到
startup.bat
所在的目录双击即可
只要双击startup.bat就可以了。
版权归原作者 m0_62317155 所有, 如有侵权,请联系我们删除。