
前言
随着大数据存储和处理需求的多样化,如何构建一个统一的数据湖存储,并在其上进行多种形式的数据分析成了企业构建大数据生态的一个重要方向。Netflix发起的Apache Iceberg项目具备ACID能力的表格式中间件成为大数据、数据湖领域炙手可热的方向。
Apache Iceberg的优势
Apache Iceberg作为一个数据湖解决方案,它支持ACID事务、修改和删除(基于Spark 2.4.5+以上)、独立于计算引擎、支持表结构和分区方式动态变更等特性,同时,为了支持流式数据的写入,引入Flink作为流式处理框架,并将Iceberg作为Flink sink的终表解决方案。
Apache Iceberg的主要优势如下。
(1)写入:支持事务,写入即可见,并提供upset/merge into的能力。
(2)读取:支持以流的方式读取增量数据。Flink Table Source及Spark结构化流都支持;不惧怕Schema的变化。
(3)计算:通过抽象不绑定任何引擎。提供原生的Java Native API,从生态上来讲,目前支持Spark、Flink、Presto、Hive。
(4)存储:对底层存储进行了抽象,不绑定于任何底层存储;支持隐藏分区和分区进化,方便业务进行数据分区策略;支持Parquet、ORC、Avro等格式来兼容行存储和列存储。
当然了,Iceberg并不支持行级update,仅支持insert into/overwrite,Iceberg团队在未来将致力于解决这个问题。
Apache Iceberg同时支持Apache Flink的DataStream API和Table API,以将记录写入Iceberg表。目前,只集成了Iceberg和Apache Flink 1.11.x。
目前已知在用的Iceberg的大厂如下。
(1)国外:Netflix、Apple、Linkined、Adobe、Dremio等。
(2)国内:腾讯、网易、阿里云等。
Apache Iceberg经典业务场景
那么,Flink可以与数据湖结合哪些经典应用场景呢?在这里,当讨论业务场景时,默认选择Apache Iceberg作为数据湖模型。
场景1:构建实时数据管道
首先,Flink+Iceberg最经典的场景是构建一个实时数据管道,如图所示。

业务端产生的大量日志数据被导入消息队列中,如Kafka。在使用Flink流计算引擎执行ETL之后,它被导入Apache Iceberg原始表中。一些业务场景需要直接运行分析作业来分析原始表的数据,而另一些场景则需要进一步净化数据,然后,可以启动一个新的Flink作业来使用来自Apache Iceberg表的增量数据,并在处理后将其写入经过处理的Iceberg表。此时,可能有业务需要进一步聚合数据,因此可以继续在Iceberg表上启动增量Flink作业,并将聚合的数据结果写入聚合表。
通过Flink+Iceberg构建的实时数据管道,可以借助Flink实现数据的精确一次性语义地入湖和出湖,并且新定稿的数据可以检查点周期内可见。
当然,这个场景也可以通过Flink+Hive实现,但是在Flink+Hive实现方案中,写入Hive的数据更多的是用于数据仓库的数据分析,而不是增量拉取。一般情况下,Hive按分区增量写时间大于15min。长时间高频率的Flink写入会导致分区膨胀。
而Iceberg允许1min甚至30s的增量写入,这可以极大地提高端到端数据的实时性能。上层的分析作业可以看到更新的数据,而下游的增量作业可以读取更新的数据。
场景2:实时分析RDBMS的变量日志
第2个经典场景是可以使用Flink+Iceberg来分析来自关系型数据库(如MySQL)的binlog,如图所示。
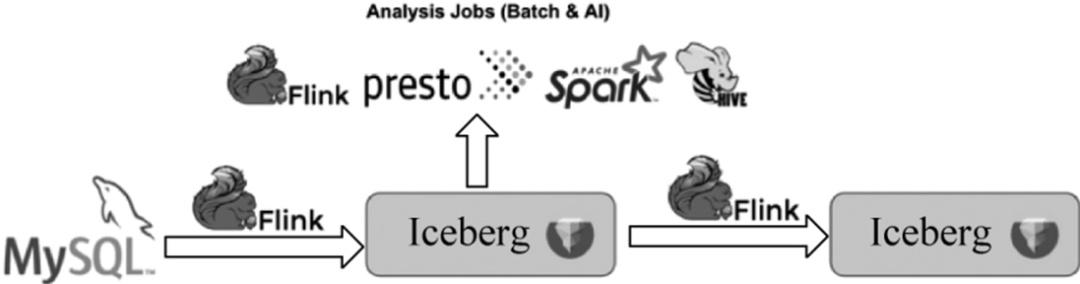
一方面,Apache Flink本身支持CDC数据解析。通过Flink CDC连接器拉出binlog数据后,自动转换为insert、delete和update,Flink运行时可以识别这些消息,供用户进行进一步的实时计算。
另一方面,Apache Iceberg完美地实现了相等删除功能,即用户定义要删除的记录,直接写入Apache Iceberg表中,这样便可删除相应的行,实现了数据湖的流删除。在未来的Iceberg版本中,用户将不需要设计任何额外的业务领域,只需编写几行代码就可以将binlog流传输到Apache Iceberg。
此外,当CDC数据成功输入Iceberg之后,还可以通过常见的计算引擎,如Presto、Spark、Hive等,实时读取Iceberg表中的最新数据。
场景3:近实时场景的流批统一
第3个经典场景是近实时场景的流批统一。
在常用的Lambda架构中,有实时处理模块和离线处理模块。实时模块一般由Flink、Kafka和HBase构建,离线模块一般由Parquet和Spark等组件构建,如图所示。
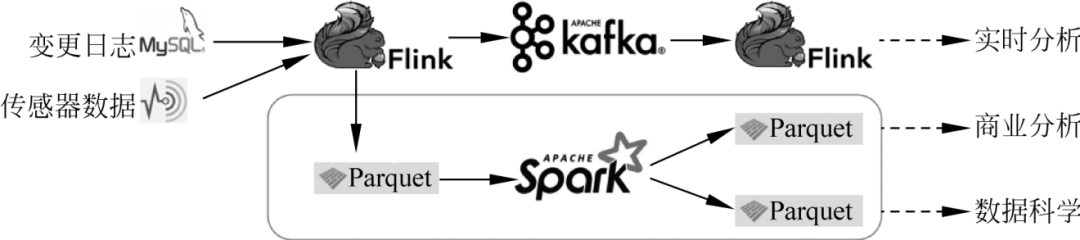
这种架构涉及的计算组件和存储组件很多,系统维护和业务开发成本非常高。
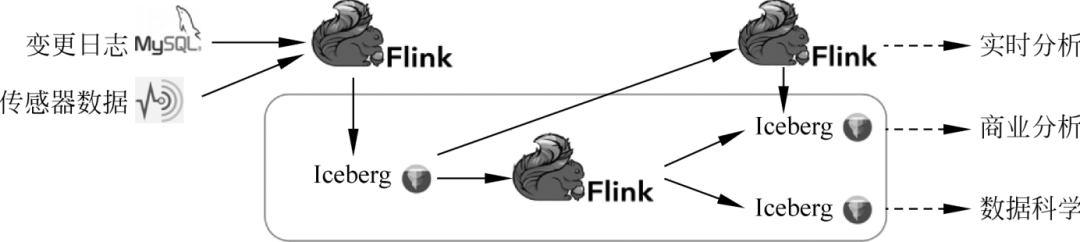
在实际应用中,有很多场景的实时性要求不是很苛刻,例如,可以放宽到分钟级的水平。这种场景称为近实时场景。可以使用Flink+Iceberg来优化整个架构,如图所示。
在这个优化后的架构中,实时数据通过Flink写入Iceberg表。近实时链路仍然可以通过Flink计算增量数据。离线链路还可以通过Flink批计算读取快照进行全局分析,并得到相应的分析结果,供用户在不同场景下进行读取和分析。经过这样的改进,我们将计算引擎统一到Flink中,将存储组件统一到Iceberg中,大大降低了整个系统的维护和开发成本。
场景4:使用Iceberg全量数据和Kafka增量数据引导新的Flink作业
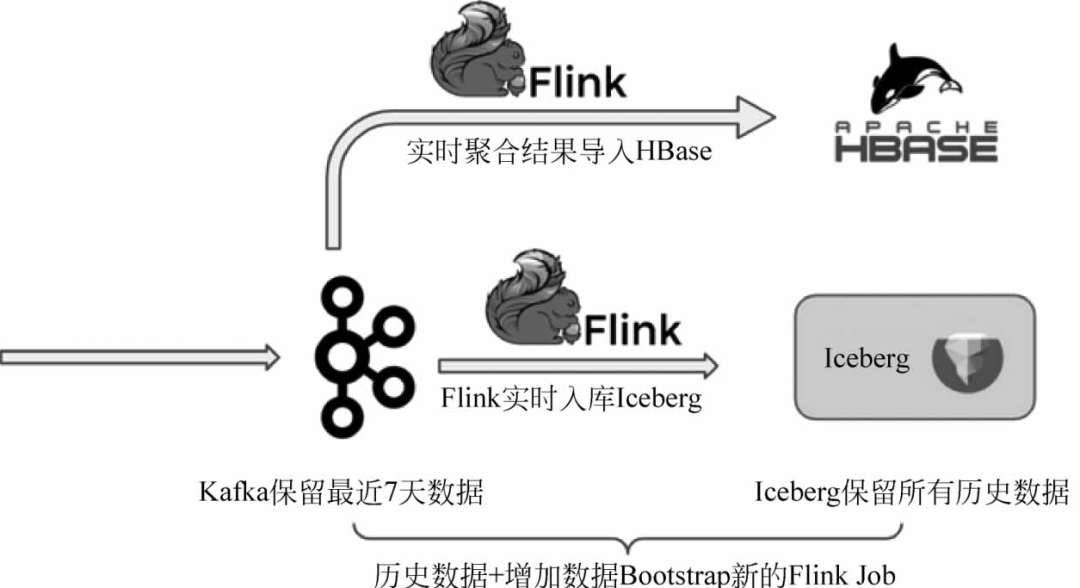
第4个场景使用Apache Iceberg全量数据和Kafka增量数据引导新的Flink作业。
例如,用户现有的流作业是在线运行的。突然有一天,一个客户提出他们遇到了一个新的计算场景,需要设计一个新的Flink作业。他们浏览了去年的历史数据,并接收了正在生成的Kafka增量数据。那么这时我们应该怎么做呢?
用户仍然可以使用通用的Lambda架构。离线链路通过Kafka→Flink→Iceberg同步写入数据湖。因为Kafka的成本较高,所以可以保留最近7天的数据。Iceberg存储成本低,可以存储全部历史数据(根据检查点划分多个数据间隔)。当启动一个新的Flink作业时,只需拉出Iceberg中的数据,然后在运行后顺利地接收Kafka的数据,架构如图所示。
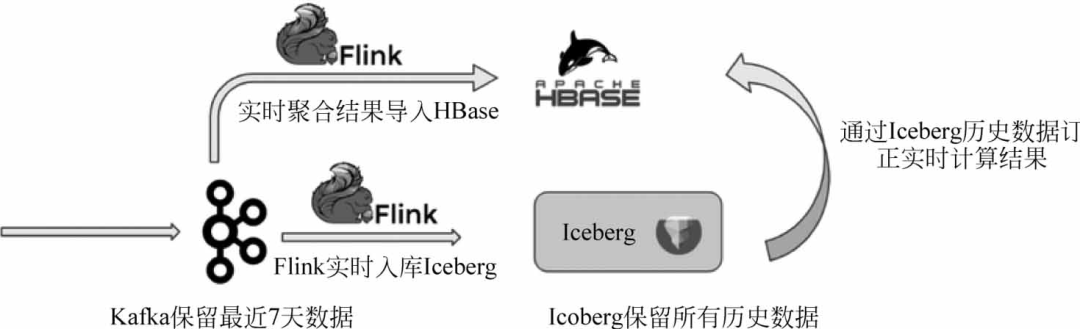
场景5:数据订正
第5个场景和第4个场景有点相似。还是在Lambda架构中,实时处理链路由于事件丢失或到达顺序的问题可能导致流计算的结果不一定完全准确,此时一般需要充分的历史数据来纠正实时计算的结果,而Apache Iceberg可以很好地发挥这个作用,通过它可以以高性价比管理历史数据,如图所示。
应用Apache Iceberg的准备工作
在使用Flink集成Iceberg之前,有几项准备工作要做。
Flink集成Iceberg

首先要从Apache Iceberg官网下载Iceberg的JAR包,如上图所示。
单击以上链接,下载iceberg-flink-runtime-0.12.0.jar包。Apache Iceberg使用嵌入式程序的方式工作,因此只需将下载的iceberg-flink-runtime-0.12.0.jar包复制到Flink安装的lib目录下,如图所示。
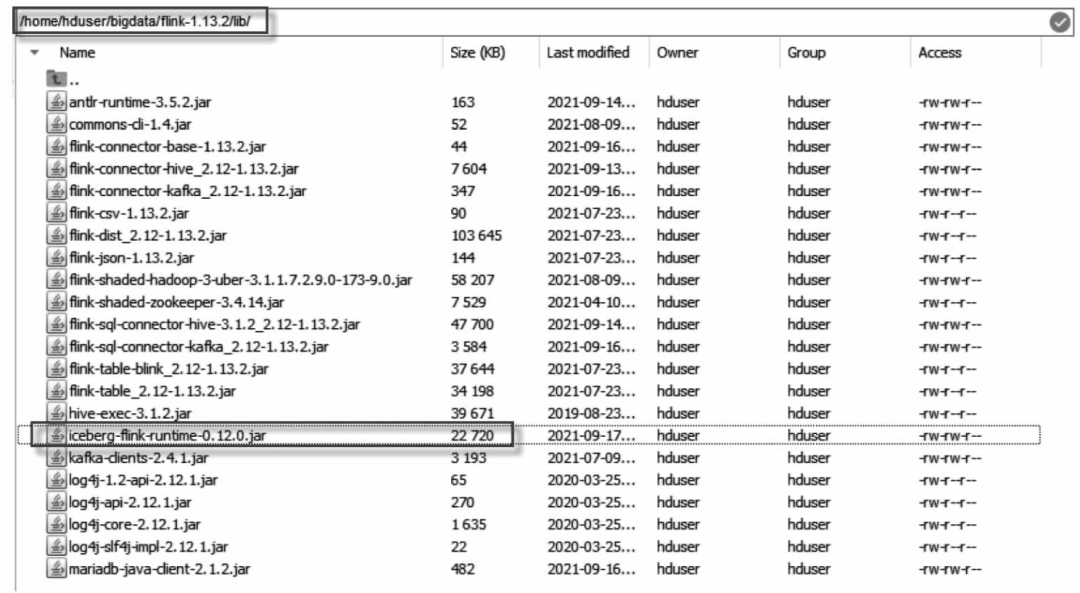
将下载的iceberg-flink-runtime-0.12.0.jar包并复制到Flink安装的lib目录下
在Flink中使用Apache Iceberg,不需要特定的安装。
Flink连接Hive
为了在Flink中创建Iceberg表,官方推荐使用Flink SQL Client。
默认情况下,Apache Iceberg包含了用于Hadoop Catalog的Hadoop JAR。如果想使用Hive Catalog,则需要在打开Flink SQL客户端时加载Hive JAR。
关于Flink集成Hive,可参考9.3.2节“集成Flink SQL CLI和Hive”。确保将所有Hive依赖项添加到Flink分布式安装的/lib目录下。这些依赖项包括:
(1)mariadb-Java-client-2.1.2.jar。
(2)hive-exec-3.1.2.jar。
(3)flink-connector-hive_2.12-1.13.2.jar。
(4)flink-sql-connector-hive-3.1.2_2.12-1.13.2.jar。
(5)flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar。
以上这些依赖,也可以在启动Flink SQL Client时通过-j选项动态指定,命令如下:
$ export HADOOP_CLASSPATH= 'hadoop classpath'$ ./bin/sql-client. sh embedded \- j <flink - runtime-directory>/iceberg-flink-runtime-0.12.0.jar\- j <hive-bundlded-jar-directory>/flink-sql-connector-hive-3.1.2_2.12 -1.13.2.jar \shell
Apache Iceberg的官方案例是通过Flink SQL Client实现的,这个客户端比较大,而且不是很好用(这是主要原因),所以建议使用Zeppelin而不是SQL Client。
在Zeppelin中使用Apache Iceberg时,首先要指定依赖包,命令如下:
%flink.confflink.execution.packages\org.apache.flink:flink-coonnector-kafka_2.12:1.13.2flink.execution.jars /home/dijie/iceberg/iceberg-flink-runtime-0.12.0.ja
Flink集成Apache Iceberg时,通常需要先创建Catalog。建立一个新的Catalog目录和指定Iceberg目录,命令如下:
% flink.ssqlCREATE CATALOG iceberg_catalog WITH ('type'= 'iceberg','catalog-type'= 'hive','uri'= 'thrift://localhost:9083','clients'= '5','property- version'= '1','warehouse'= 'hdfs://localhost:8020/user/hive/warehouse');
查看Catalog是否创建成功,执行的命令如下:
% flink.ssqlshow catalogs;
配置Flink检查点
最后,还需要配置Flink的checkpoint,因为目前Flink向Iceberg提交信息是在每次checkpoint时触发的。在Flink中配置checkpoint的方法如下。
在flink-conf.yaml添加如下配置:
# checkpoint间隔时间execution.checkpointing.interval:10s# checkpoint失败容忍次数execution. checkpointing.tolerable-failed-checkpoints:10
创建和使用Catalog
Apache Iceberg支持3种Catalog,分别是Hive Catalog、Hadoop Catalog和自定义Catalog。
Hive Catalog
使用Hive Catalog,可以将表结构持久存储到Hive的Metastore中。例如,创建一个名为hive_catalog的Iceberg Hive Catalog,代码如下:
CREATE CATALOG hive_catalog WITH ('type'= 'iceberg','catalog-type'= 'hive','uri'= 'thrift://localhost:9083','clients'= '5','property- version'= '1','warehouse'= 'hdfs://localhost:8020/user/hive/warehouse');
各个参数的解释如下。
(1)type:对于Iceberg表格式,只使用Iceberg(必选)。
(2)catalog-type:Iceberg当前支持Hive或Hadoop Catalog类型(必选)。
(3)uri:Hive Metastore的Thrift URI(必选)。
(4)clients:Hive Metastore客户端池大小,默认值为2(可选)。
(5)property-version:版本号,用于描述属性版本。如果属性格式改变,则此属性可用于向后兼容。当前的属性版本是1(可选)。
(6)warehouse:Hive Warehouse位置,如果既没有设置hive-conf-dir来指定包含hive-site.xml配置文件的位置,也没有将正确的hive-site.xml添加到classpath,则用户应该指定此路径。
(7)hive-conf-dir:包含hive-site.xml配置文件的目录路径,该配置文件将用于提供定制的Hive配置值。当创建Iceberg Catalog时如果在hive-conf-dir和warehouse都设置了,则来自<hive-conf-dir>/hive-site.xml(或classpath的Hive配置)的hive.metastore.warehouse.dir值将被warehouse的值覆盖。
(8)cache-enabled:是否启用Catalog缓存,默认值为true。
创建之后,可以使用show catalogs命令查看当前所有的Catalogs。
Hadoop Catalog
Apache Iceberg还支持HDFS中基于目录的Catalog,可以使用'catalog-type'='hadoop'来配置,代码如下:
CREATE CATALOG hadoop_catalog WITH('type'= 'iceberg','catalog-type'= 'hadoop','warehouse'= 'hdfs://localhost:8020/user/hive/warehouse','property-version'= '1');
其中warehouse是用于存放元数据文件和数据文件的HDFS目录(必选)。
自定义Catalog
Flink还支持通过指定catalog-impl属性来加载自定义的Iceberg Catalog实现。当设置catalog-impl时,将忽略catalog-type的值,代码如下:
CREATE CATALOG my_catalog WITH('type'= 'iceberg','catalog-impl'= 'com.my.custom.CatalogImpl','my-additional-catalog-config'= 'my-value'
通过YAML配置创建Catalog
可以在启动Flink SQL Client之前,在conf/sql-client-defaults.yaml配置文件中注册Catalog,内容如下:
catalogs: -name: my_catalog type: iceberg catalog-type:hadoop warehouse:hdfs://localhost:8020/warehouse/path
Iceberg DDL命令
Apache Iceberg支持如下常用的DDL命令。
CREATE DATABASE
默认情况下,Iceberg将使用Flink中的default数据库。如果不想在default数据库下创建表,则可以创建一个单独的数据库,例如,创建一个名为iceberg_db的数据库,代码如下:
create database iceberg_db;use iceberg_db;
CRE****ATE TABLE
表创建命令。使用方法如下:
CREATE TABLE hive_catalog.default.sample (id BIGINT COMMENT'unique id',data STRING);
创建表的create命令现在支持最常用的Flink create子句,包括:
(1)PARTITION BY(column1,column2,...)配置分区,Flink还不支持隐藏分区。
(2)COMMENT'table document'设置一个表描述。
(3)WITH('key'='value',...)设置将存储在Apache Iceberg表属性中的表配置。
目前不支持计算列、主键、水印定义等。
PARTITIONED BY
要创建分区表,使用PARTITIONED BY,代码如下:
CREATE TABLE hive_catalog.default.sample (id BIGINT COMMENT'unique id',data STRINGPARTITIONED BY(data);
Apache Iceberg支持隐藏分区,但Apache Flink不支持通过列上的函数进行分区,所以现在无法在Flink DDL中支持隐藏分区。
CREATE TABLE LIKE
要创建与另一个表具有相同模式、分区和表属性的表,可以使用CREATE TABLE LIKE,代码如下:
CREATE TABLE hive_catalog.default.sample (id BIGINT COMMENT'unique id',data STRING);CREATE TABLE hive_catalog.default.sample_like LIKE hive_catalog.default.sample;
ALTER TABLE
目前,Iceberg只支持在Flink 1.11中修改表属性。修改表属性的代码如下:
ALTER TABLE hive_catalog.default.sample SET('write.format.default'= 'avro')
ALTER TABLE...RENAME TO
对表重命名,代码如下:
ALTER TABLE hive_catalog.default.sample RENAME TO hive_catalog.default.new_sample;
DROP TABLE
删除表default.sample,代码如下:
DROP TABLE hive_catalog.default.sample;
Iceberg SQL查询
Apache Iceberg现在支持Flink中的流和批读取。用户可以执行以下SQL命令,将执行类型从streaming模式切换到batch模式,反之亦然,代码如下:
-- 以流模式为当前会话上下文执行Flink作业SET execution.type = streaming-- 以批处理模式为当前会话上下文执行Flink作业SET execution.type = batch
Flink批量读取
如果想通过提交Flink批处理作业检查Iceberg表中的所有行,则执行语句如下:
SET execution.type = batch;SELECT * FROM hive_catalog.default.sample;
Flink流式读取
Apache Iceberg支持Flink流作业中从历史快照id开始的增量数据处理,执行语句如下:
--设置当前会话以流模式提交Flink作业SET execution.type = streaming ;-- 启用此开关,因为流式读取SQL将在Flink SQL提示选项中提供一些作业选项SET table. dynamic-table-options.enabled = true;-- 从 Iceberg当前快照读取所有记录,然后从该快照开始读取增量数据SELECT * FROM sample /* + OPTIONS('streaming'= 'true', 'monitor-interval'= '1s')*/;-- 从 id 为"3821550127947089987"的快照开始读取所有增量数据(将排除该快照的记录)SELECT * FROM sample /* + OPTIONS('streaming'= 'true', 'monitor-interval'= '1s', 'start-snapshot-id'= '3821550127947089987') */;
这些是可以设置在Flink SQL提示选项中用于流作业的选项。
(1)monitor-interval:连续监控新提交数据文件的时间间隔(默认值:"1s")。
(2)start-snapshot-id:流作业开始的快照id。
Iceberg SQL写入
目前,Apache Iceberg在Flink 1.11中支持INSERT INTO和INSERT OVERWRITE语句。
INSERT INTO
要使用Flink流作业将新数据追加到表中,可使用INSERT INTO语句,代码如下:
INSERT INTO hive_catalog.default.sample VALUES (1,'a');INSERT INTO hive_catalog.default.sample SELECTid,data from other_kafka_table;insert into sample values (1,'testl');insert into sample values (2,'test2');insert into sample_partition PARTITION(data='city') SELECT 86;
INSERT OVERWRITE
若要用查询结果替换表中的数据,则可在批作业中使用INSERT OVERWRITE(Flink流作业不支持INSERT OVERWRITE)语句。对于Iceberg表来讲,覆盖是原子操作。
有由SELECT查询产生的行的分区将被替换,代码如下:
INSERT OVERWRITE sample VALUES (1,'a');
Apache Iceberg还支持通过select查询值覆盖给定的分区,代码如下:
INSERT OVERWRITE hive_catalog. default. sample PARTITION(data= 'a') SELECT 6;
对于Iceberg分区表,当所有的分区列在partition子句中设置了一个值时,它用于插入一个静态分区,否则如果部分分区列(所有分区列的前缀部分)在partition子句中设置了一个值,则它用于将查询结果写入一个动态分区。对于一个未分区的Iceberg表,它的数据将被INSERT OVERWRITE完全覆盖。
使用DataStream读取
Iceberg目前在Java API中支持流和批读取。
批读取
例如,从Iceberg表中读取所有记录,然后在Flink批作业中将其打印到标准输出控制台,代码如下:
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();TableLoader tableLoader = TableLoader.fromHadooptable("hdfs://localhost:8020/warehouse/path");DataStream <RowData> batch = FlinkSource.forRowData().env(env).tableLoader(loader).streaming(false).build();//将所有记录打印到标准输出batch. print();//提交并执行此批读取作业env.execute("Test Iceberg Batch Read");
流读取
例如,读取从snapshot-id'3821550127947089987'开始的增量记录,并在Flink流作业中打印到标准输出控制台,代码如下:
StreamExecutionEnvironment env= StreamExecutionEnvironment.createLocalEnvironment();TableLoader tableLoader= TableLoader.fromHadooptable("hdfs://localhost:8020/warehouse/path");DataStream<RowData> stream = FlinkSource.forRowData().env(env).tableLoader(loader).streaming(true).startSnapshotId(3821550127947089987).build();//将所有记录打印到标准输出stream.print();//提交并执行此流读取作业env.execute("Test Iceberg Batch Read");
使用DataStream写入
Apache Iceberg支持从不同的DataStream写入Iceberg表。
追加数据
它支持将DataStream <RowData>和DataStream <Row>写入Iceberg Sink表中。模板代码如下:
StreamExecutionEnvironment env =...;DataStream <RowData> input = ...;Configuration hadoopConf = new Configuration();TableLoader tableLoader= TableLoader.fromHadooptable("hdfs://localhost:8020/warehouse/path", hadoopConf);FlinkSink.forRowData(input).tableLoader(tableLoader).build();env.execute("Test Iceberg DataStream");
Iceberg API还允许用户将泛型化的DataStream <T>写入Iceberg表。
覆盖数据
为了动态地覆盖现有Iceberg表中的数据,可以在FlinkSink builder中设置overwrite标志。模板代码如下:
StreamExecutionEnvironment env =...;DataStream <RowData> input = ...;Configuration hadoopConf = new Configuration();TableLoader tableLoader= TableLoader.fromHadooptable("hdfs://localhost:8020/warehouse/path", hadoopConf);FlinkSink.forRowData(input).tableLoader(tableLoader).overwrite(true).build();env.execute("Test Iceberg DataStream");
重写文件操作
通过提交Flink批作业,Iceberg提供了将小文件改写为大文件的API。这个Flink操作的行为与Spark的rewriteDataFiles相同,代码如下:
import org.apache.iceberg.flink.actions.Actions;TableLoader tableLoader= TableLoader. fromHadooptable("hdfs://localhost:8020/warehouse/path");Table table = tableLoader.loadTable();RewriteDataFilesActionResult result = Actions.forTable(table).rewriteDataFiles().execute();
版权归原作者 之乎者也· 所有, 如有侵权,请联系我们删除。