
一、什么是Zookeper
Zookeper是一个可以作为注册中心、配置中心、分布式锁的分布式解决方案
二、数据一致性
一致性分为强一致性、弱一致性、最终一致性
Zookeper可以保持数据的强一致性(CP)
主要是解决写、集群节点的同步、读之间的关系
- 强一致性:在硬件层面可以不能完全保证同步在读之前完成,但可以通过加锁的方案,即写后同步前会获取锁,读前也需要去获取这个锁,从而保证在同步操作没有完成前,无法进行读这个操作。(这里就是CAP中满足CP)
- 弱一致性:不保证同步操作一定会顺利执行,可能一致读到的就是同步之前的数据。
- 最终一致性:在同步完成之前可以正常读,同步后读取的数据才是最终的正确的数据。(这里就是CAP中满足AP)
Zookeper和eureka的区别(CAP)

三、领导选举机制
一个Zookeper集群可以有多个服务器节点,一般为单数,进行领导选举
2.1 选举标准
节点在存储数据时会先生成日志,而每条日志都有一个id,根据这个id的大小判断哪个节点的数据更新,日志id大的更有机会成为leader
当两个节点的日志id一样时,节点id大的更有机会成为leader
2.2 选举流程
每个节点先给自己投票
节点之间建立socket连接,互相发送自己的投票信息,并根据日志id和节点id的比较修改投票信息(此时会将修改的投票信息重新生成一份放在节点数组中,而无需修改的投票信息也会重新生成一份,从而记录投票的次数)


四、写操作
请求会被转发给leader节点统一处理
leader节点先生成日志文件,先向自己发送ack->向其他节点发送日志->其他节点收到日志后持久化日志,然后发送ack->leader节点等待收到超过一半的ack后,本地提交,更新内存数据(此时,如果有观察者节点,会向观察者节点发送完成更新的信号)->向其他节点发送commit->其他节点收到commit后,更新内存
那么为什么Zookeper一般设置为奇数个节点呢?
因为leader节点需要收到超过一半的ack后(包括自己的)才会进行更新操作,
比如当节点为5个时,可允许宕机的节点个数为2(ack需要至少为3),
当节点为6个时,可允许宕机的节点个数为2(ack需要至少为4),那么在满足可用性时5和6个节点设置允许宕机的节点数是一样的,我们优先选5个
五、数据模型
文件类型–树结构
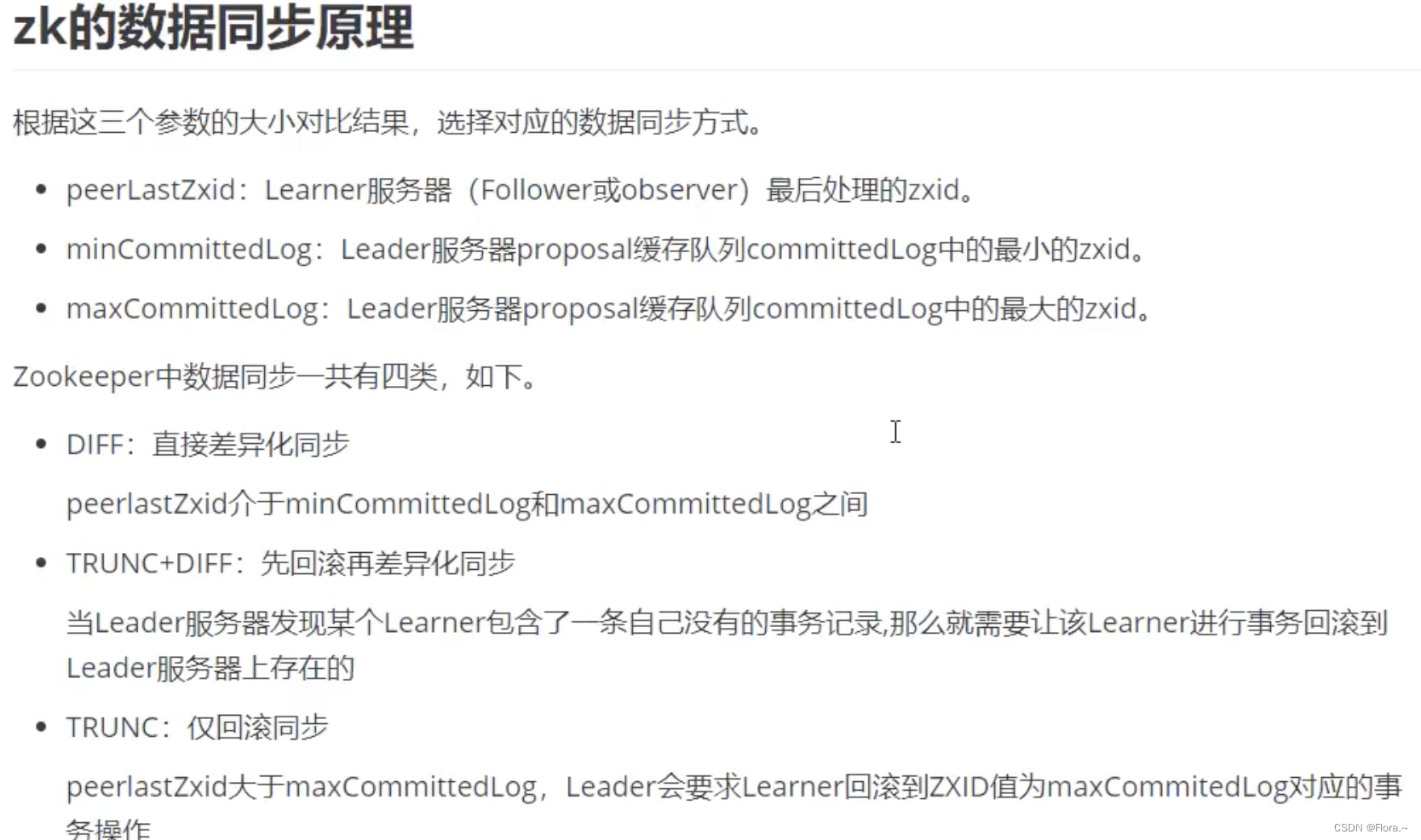
六、数据同步

七、watch机制(监听)
newZookeeper(String connectString,int sessionTimeout,Watcher watcher)// 这个Watcher将作为整个Zookeeper会话期间的上下文,一直被保存在客户端ZKWatchManager的defaultWatcher// 也可以动态添加watcher:getData(),exists, getChildren
串行同步,通过先进先出的队列实现,是同步过程,无需担心并发的问题


八、分布式锁
在单机下,可以使用synchronize实现锁(只能锁自己,锁不了其他节点)
而分布式下
可以使用数据库(利用唯一索引,加锁插入,解锁删除,容易死锁)或者Redis或者Zookeper
Zookeper:结合临时节点使用
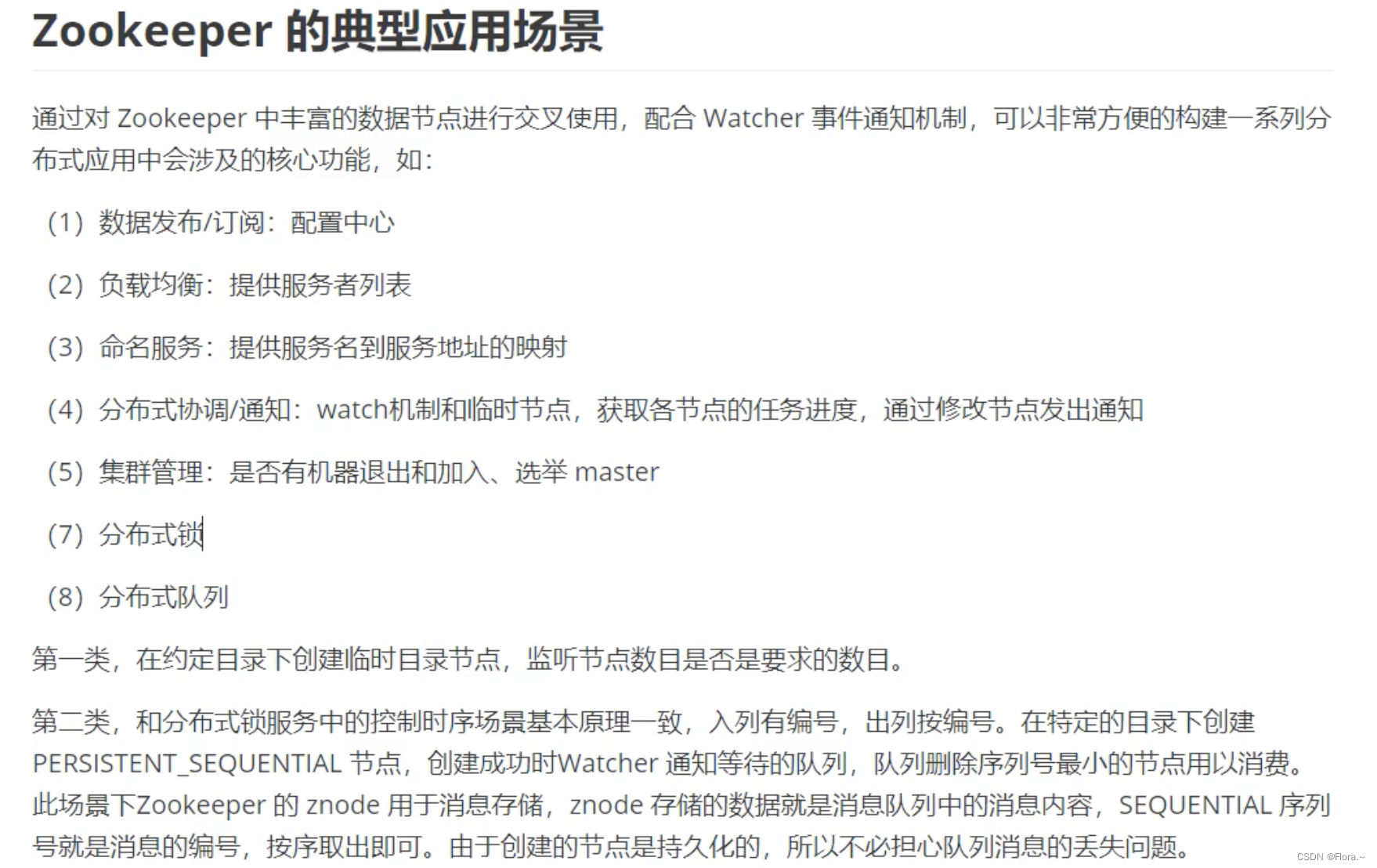
九、应用场景

十、 事务性

原理是通过version一致进行控制
十一、观察者机制
Zookeper中有三种节点:leader节点、follow节点、observer节点
其中observer节点不参加投票,不算在ack的半数节点范围内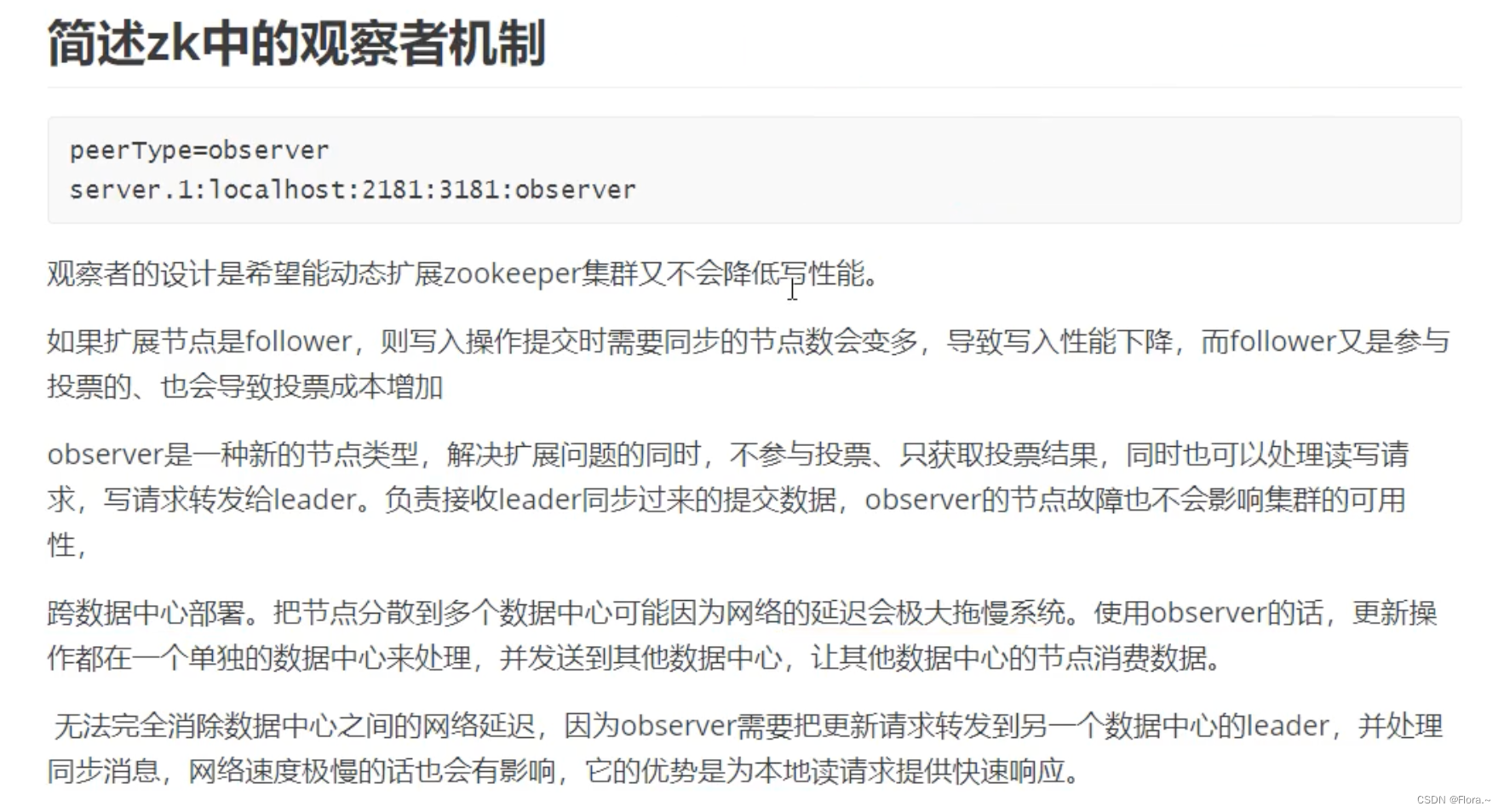
十二、session会话管理
会话过期前断开,会重新进行连接,连接成功后会继续使用之前的过期时间
要避免2个客户端共用一个sessionId的场景,会导致第二个连接成功后,第一个被动断开,互相抢占,无限重连

版权归原作者 Flora.~ 所有, 如有侵权,请联系我们删除。